Multi-Interest Network with Dynamic Routing for Recommendation at Tmall(学习)
目的
在RS排序阶段更好的检索用户感兴趣的项目(即召回)
此前方法的局限:Youtube-DNN在多兴趣召回上有bottlenect;DIN使用注意力机制(计算量巨大),只能用在精排(即ranking阶段)
问题分析
根据tuple
(
I
u
,
P
u
,
F
i
)
(I_u,P_u,F_i)
(Iu,Pu,Fi)得出用户多兴趣的表示
V
u
=
f
u
s
e
r
(
I
u
,
P
u
)
,
V
=
(
v
u
1
,
.
.
.
.
v
u
k
)
V_u = f_{user}(I_u,P_u),V = (v^{1}_u,....v^{k}_u)
Vu=fuser(Iu,Pu),V=(vu1,....vuk)
其中I是用户行为序列,P是用户个人信息,F是项目的特征值;此外再得到,项目的表示
e
i
=
f
i
t
e
m
(
F
i
)
e_i =f_{item}(F_i)
ei=fitem(Fi)
最终得到评分函数
f s c o r e ( V u , e i ) = m a x 1 < k < K ( e i ∗ v u ) f_{score}(V_u,e_i) = max_{1<k<K}(e_i*v_u) fscore(Vu,ei)=max1<k<K(ei∗vu)
模型结构
(training)多兴趣提取器+attention层+sample_softmax
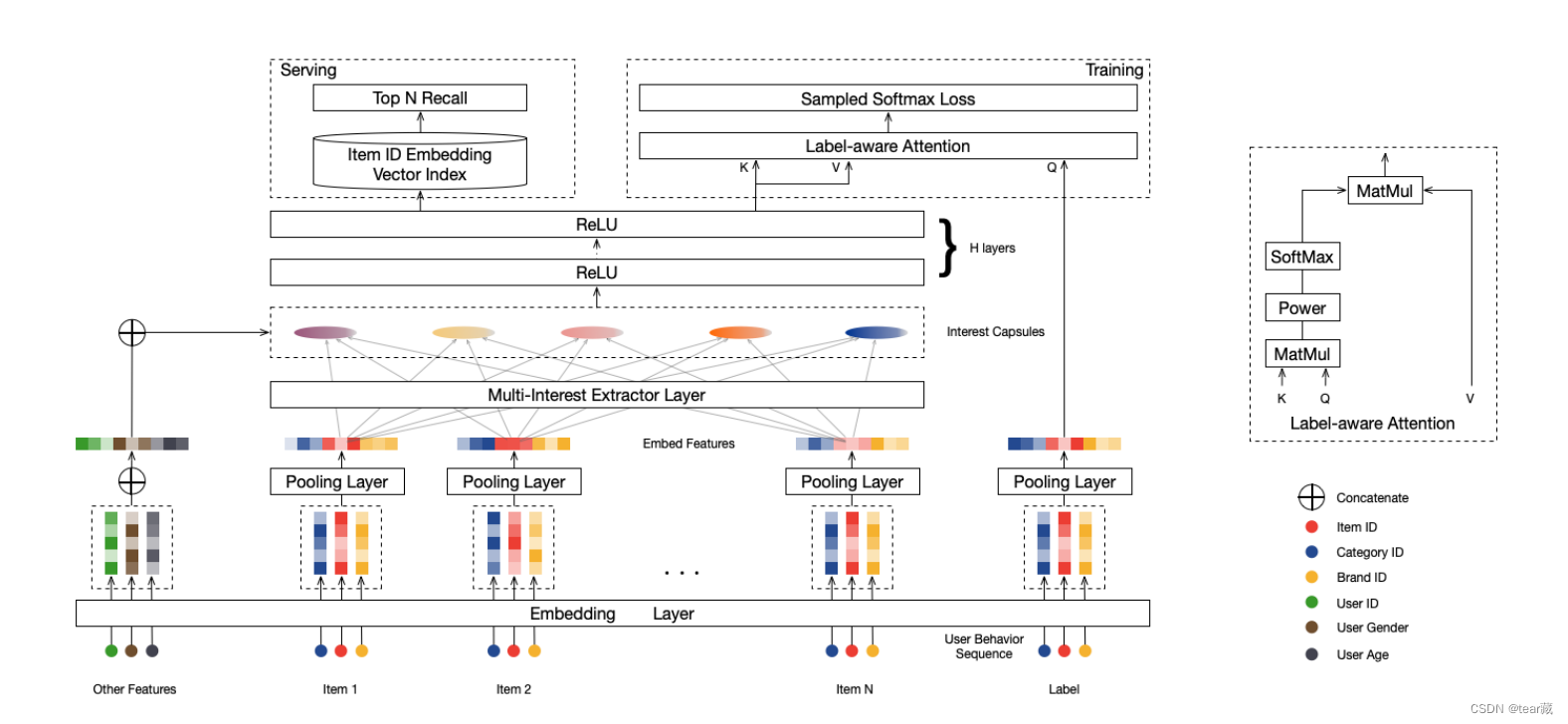
Embedding & Pooling Layer
用户(user pofile)的信息做embedding:
P
u
P_u
Pu
item的feature做embedding后concat再pooling得到item_label_embedding:
e
i
e_i
ei
交互序列做embedding得到:
e
j
e_j
ej
重点
Multi-Interest Extractor Layer
B2I Dynamic Routing
重点是使用新的胶囊神经网络,使用动态路由来更新
b
i
j
b_{ij}
bij
籍此来得出用户的多兴趣表示

其中K由,跟随用户序列变化而变化,或自定超参数
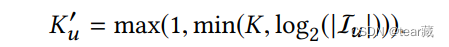
以下为原理公式
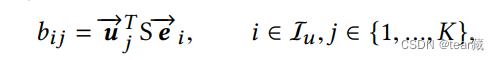
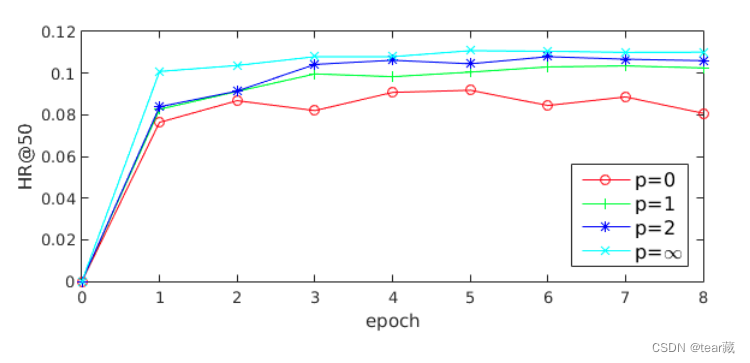
Label-aware Attention Layer
将项目label_embedding和用户多兴趣向量做attention(softmax中做p次幂),得到用户最终兴趣
这里讨论三种情况:
- p=0,即什么都不做,所有兴趣都会被注意到
- p>=1,乘积越大的兴趣被注意力就越大
- p趋于无穷,实际上对某一兴趣乘1,其他均为零
LOSS
training部分简单做一个放缩;
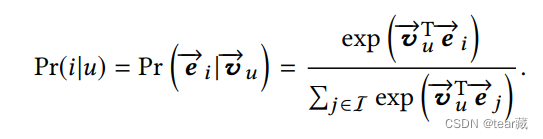
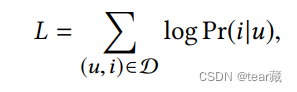
serving部分不做attention,直接把多兴趣用户向量做召回
实验部分
-
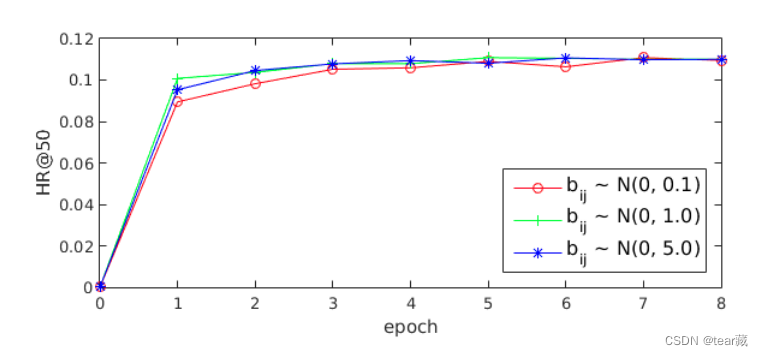
使用高斯分布对 b i j b_{ij} bij 进行初始化,不影响结果
-
-
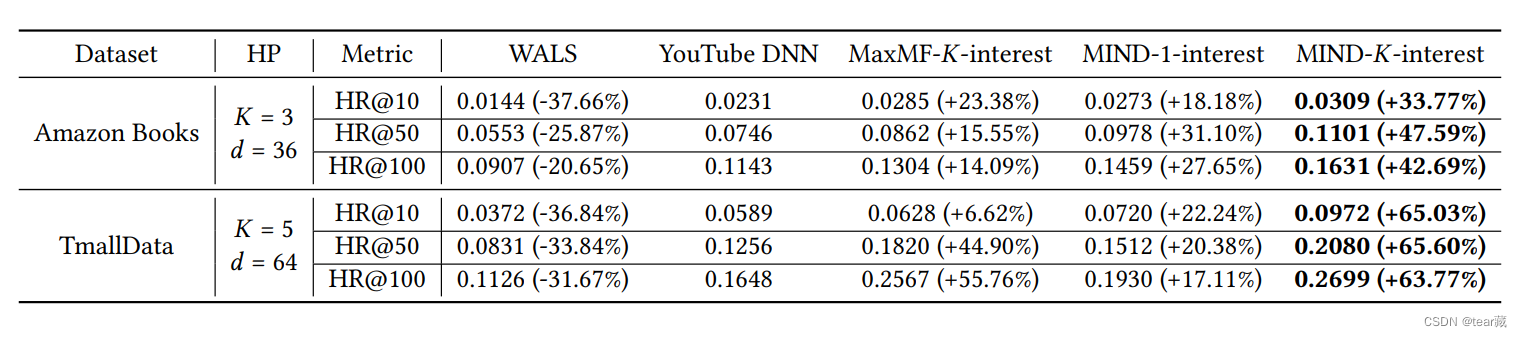
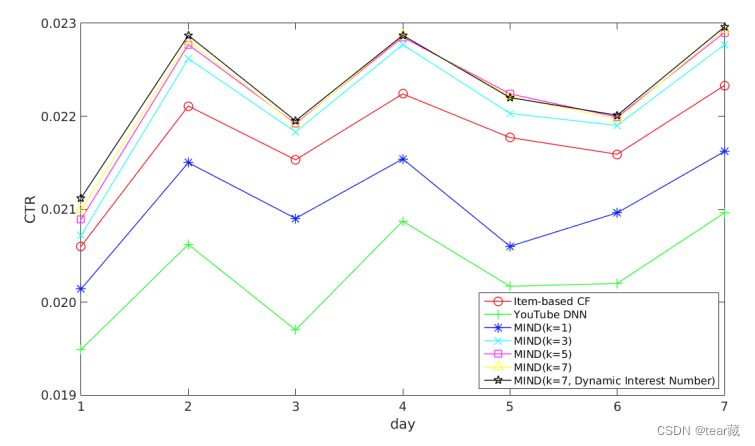
多兴趣的数量,k值3~5是表现最好