hive官方配置url: Configuration Properties - Apache Hive - Apache Software Foundation
1、调优方式
hive参数配置的意义: 开发Hive应用/调优时,不可避免地需要设定Hive的参数。设定Hive的参数可以调优HQL代码的执行效率,或帮助定位问题。然而实践中经常遇到的一个问题是,为什么我设定的参数没有起作用?这是对hive参数配置几种方式不了解导致的! hive参数设置范围(从大到小): 配置文件 > 命令行参数 > set参数声明 hive参数设置优先级(从高优先级到低优先级): set参数声明 > 命令行参数 > 配置文件 注意: 在工作中,推荐使用set参数声明,因为最简单最方便。而且同一个大数据集群除了你了还有其他的人或者项目组在使用。
2、hive数据压缩
Hive底层是运行MapReduce,所以Hive支持什么压缩格式本质上取决于MapReduce。
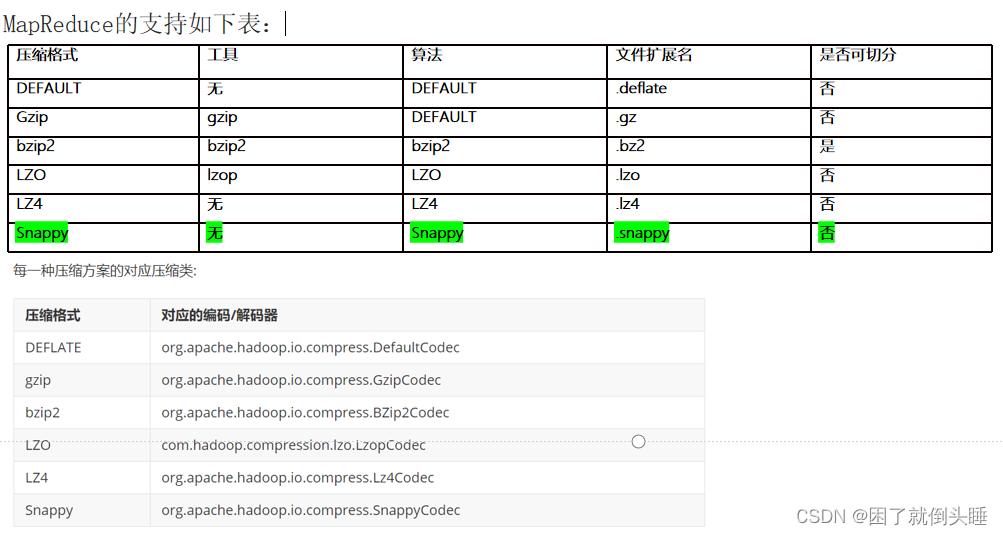
2.1 压缩对比
在后续可能会使用GZ(GZIP), 保证压缩后的数据更小, 同时压缩和解压的速度比较OK的,
但是大部分的选择主要会选择另一种压缩方案, snappy, 此种方案可以保证在合理的压缩比下, 拥有更高的解压缩的速度,在大数据领域中主要是关注数据的处理速度
snappy | A fast compressor/decompressor On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
2.2 开启压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量. 当Hive将输出写入到表中时,输出内容同样可以进行压缩。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
-- 创建数据库 create database hive05; -- 使用库 use hive05; -- 开启压缩(map阶段或者reduce阶段) --开启hive支持中间结果的压缩方案 set hive.exec.compress.intermediate; -- 查看默认 set hive.exec.compress.intermediate=true ; --开启hive支持最终结果压缩 set hive.exec.compress.output; -- 查看默认 set hive.exec.compress.output=true; --开启MR的map端压缩操作 set mapreduce.map.output.compress; -- 查看默认 set mapreduce.map.output.compress=true; --设置mapper端压缩的方案 set mapreduce.map.output.compress.codec; -- 查看默认 set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec; -- 开启MR的reduce端的压缩方案 set mapreduce.output.fileoutputformat.compress; -- 查看默认 set mapreduce.output.fileoutputformat.compress=true; -- 设置reduce端压缩的方案 set mapreduce.output.fileoutputformat.compress.codec; -- 查看默认 set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; --设置reduce的压缩类型 set mapreduce.output.fileoutputformat.compress.type; -- 查看默认 set mapreduce.output.fileoutputformat.compress.type=BLOCK;
3、hive数据存储
3.1 行列存储原理


行存储的特点: 将数据以行的形式整体进行存放
列存储的特点: 将相同字段的值作为整体放在一起进行存放
行存储:
优点: 如果要查询整行数据内容,速度比较快。适合进行数据的insert/update操作
缺点: 如果数据分析的时候,只想针对某几个字段进行处理,那么这个效率低。因为会将不需要的字段内容也会加载出来
使用: textfile和sequencefile
列存储:
优点: 如果数据分析的时候,只想针对某几个字段进行处理,那么效率高,因为你要什么,我就给你返回什么
缺点: 如果要查询整行数据内容,速度比较慢。不适合进行数据的insert/update操作
使用: orc和parquet。推荐使用orc
注意: 在工作中推荐ORC+Snappy压缩一起使用,更加能够减少HDFS的磁盘占用。
格式:
stored as orc -- 设置数据的存储格式
tblproperties ("orc.compress"="SNAPPY"); -- 设置数据的压缩格式
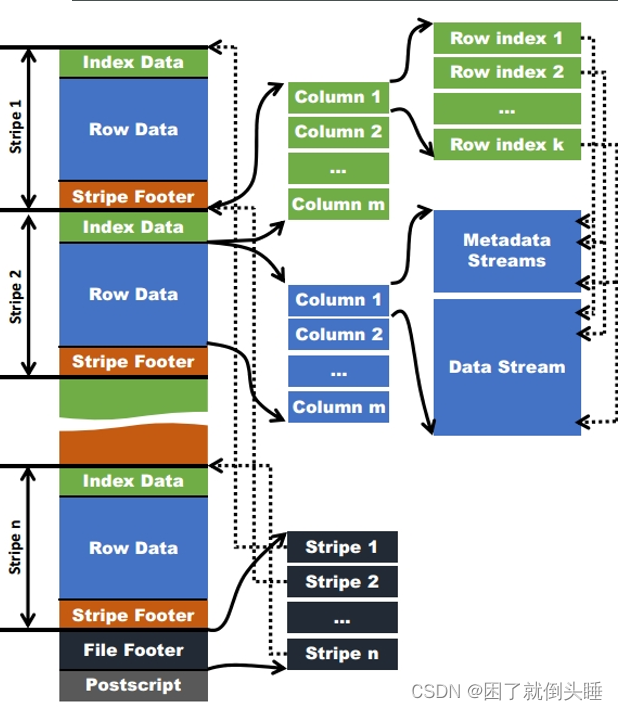
ORC原理图
3.2 存储压缩比
-- 数据的存储和压缩方式
-- textfile:占用空间18.13 MB(如果是HDFS需要乘以3)
create table log_text(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as textfile; -- 表默认的存储格式就是不压缩并且使用行式存储中的textfile存储
-- 导入数据
load data inpath '/dir/log.data' into table log_text;
-- 数据验证
select * from log_text;
select count(*) as cnt from log_text;
-- 列式存储:ORC,占用空间2.78 MB
create table log_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as orc;
-- 加载数据
insert overwrite table log_orc select * from log_text;
select count(*) as cnt from log_orc;
-- 列式存储:ORC+snappy。占用空间3.75 MB,这里相对ORC反而多占用了1MB空间,是因为数据量太小,同时压缩以后,压缩文件里面需要存储和压缩相关元数据信息(例如:使用的压缩算法具体是哪一个)
-- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as orc -- 设置数据的存储格式
tblproperties ("orc.compress"="SNAPPY"); -- 设置数据的压缩格式
-- 加载数据
insert overwrite table log_orc_snappy select * from log_text;
select count(*) as cnt from log_orc_snappy;
-- 列式存储:parquet。占用空间13.09MB
create table log_orc_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as parquet;
-- 加载数据
insert overwrite table log_orc_parquet select * from log_text;
select count(*) as cnt from log_orc_parquet;
拓展dfs -du -h
-- 查看hdfs文件大小除了去页面查看,还可以通过命令 dfs -du -h '/user/hive/warehouse/hive05.db/log_text/log.data' ; dfs -du -h '/user/hive/warehouse/hive05.db/log_orc/000000_0' ; dfs -du -h '/user/hive/warehouse/hive05.db/log_orc_snappy/000000_0' ; dfs -du -h '/user/hive/warehouse/hive05.db/log_parquet/000000_0' ;