线性表
1️⃣ 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表: 2️⃣ 顺序表、 3️⃣ 链表、栈、队列、字符串...
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
注:
1️⃣线性的意思是数据以连线的方式存储
2️⃣顺序表本质上就是数组。但是在此之上,顺序表要求存储的数据必须是从头开始、连续紧挨着的,不能跳跃间隔
3️⃣链表是用指针把一块一块内存链接起来
图示:
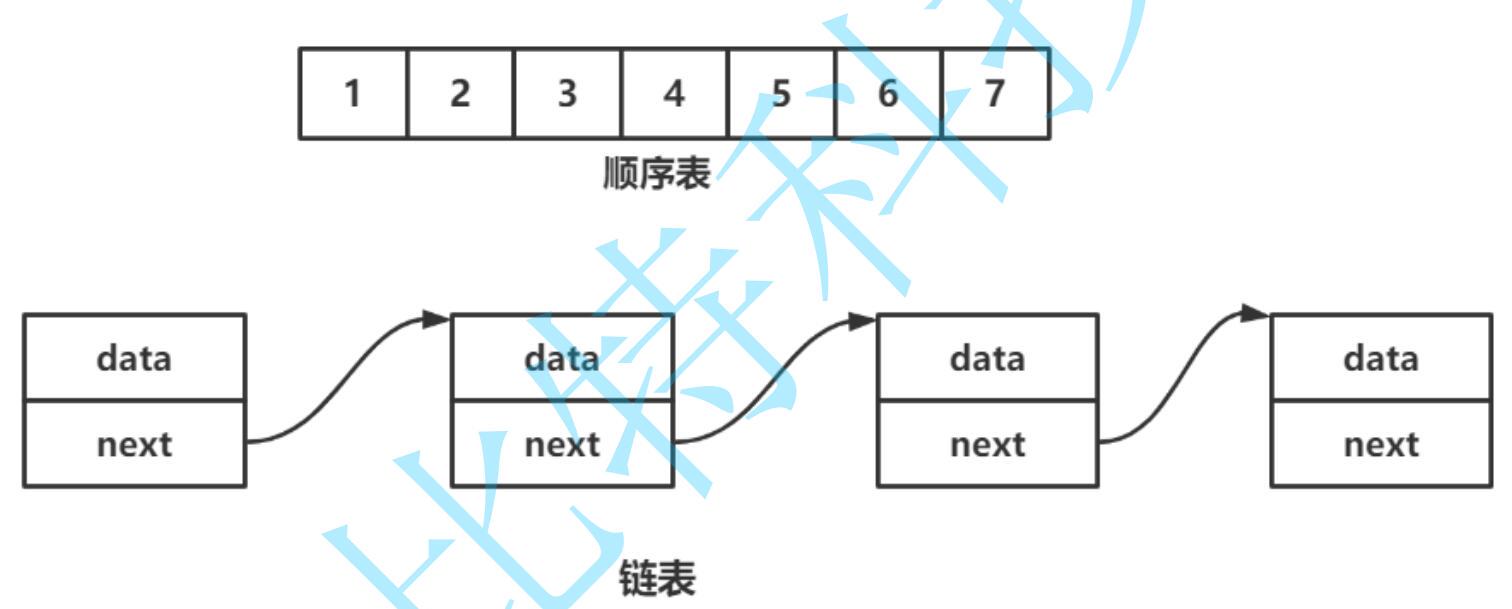
顺序表在逻辑结构上是连续的,物理结构上也是连续的;
链表在逻辑结构上是连续的,但是在物理结构上不是连续的。
顺序表
概念及结构
顺序表是 用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。 顺序表的物理结构和逻辑结构是一致的。
插:创建程序的时候,命名尽量用英文。因为日后在工作中各个源文件链接的时候,中文会出现转换问题,引来不必要的麻烦
顺序表一般可以分为:
1. 静态顺序表:使用 定长数组存储。 特点是如果满了就不让插入。 缺点是空间给多大合适呢?很难确定。N给小了不够用,给大了浪费
2. 动态顺序表:使用 动态开辟的数组存储。
静态顺序表:
//静态的顺序表,并不实用
#define N 100//一发,动全身
struct SeqList//SeqList:顺序表
{
int a[N];
int size;//表示数组中存储了多少个数据
};注:
用结构体的好处:不仅找到开辟的空间大小,还知道存储的数据个数
以后凡是涉及多个数据的,尽量考虑用结构体
缺点:
因为结构体中定义了数据类型为int,故后续想再插入其它类型的数据就不行了
改进一:可以修改存储的数据类型,插入其它类型的数据
#define N 100
typedef int SLDataType;//int重命名为SLDataType,即顺序表数据类型。以后想插入什么类型就把int改成什么类型
//例如插入double类型,即:typedef double SLDataType;
struct SeqList
{
SLDataType a[N];
int size;
};
void SeqListPushBack(struct SeqList* ps, int x);//SeqListPushBack,即顺序表尾部插入缺点:
struct SeqList太长,不方便
改进二:将struct SeqList重命名为SL,方便使用
#define N 100
typedef int SLDataType;//int重命名为SLDataType,即顺序表数据类型
typedef struct SeqList
{
SLDataType a[N];
int size;
}SL;
void SeqListPushBack(SL* ps, int x);
动态顺序表:
//顺序表的动态存储
typedef int SLDataType;
typedef struct SeqList
{
SLDataType* array; //把数组改成指针,意味着我们不再开辟一块固定大小的空间,而是指向一块空间
int size; //表示数组中存储了多少个数据
int capacity; //表示array指向的空间实际能够存数据的空间容量是多大
}SL;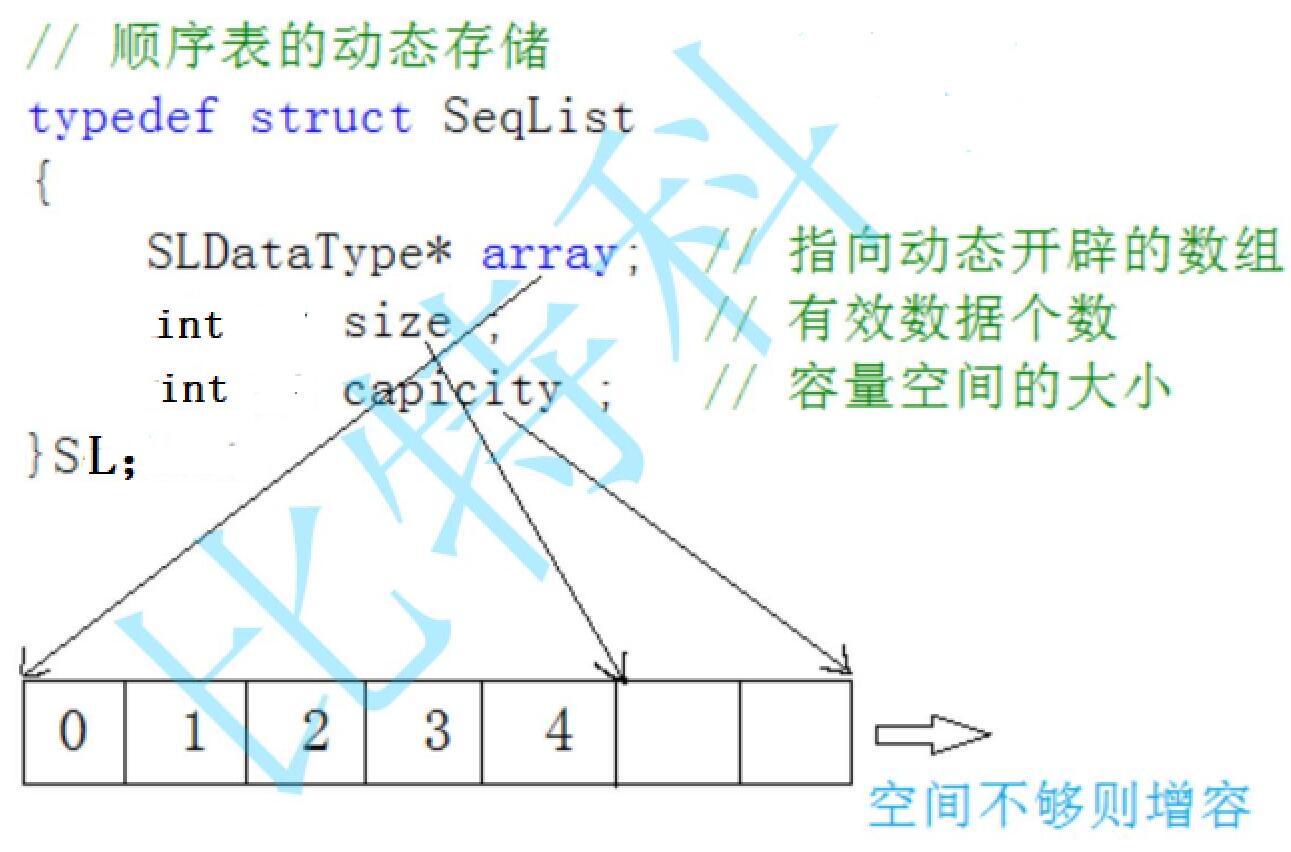
接口函数:
//尾插
void SeqListPushBack(SL* ps, SeqDataType x);
//头插
void SeqListPushFront(SL* ps, SeqDataType x);
//头删
void SeqListPopFront(SL* ps);
//尾删
void SeqListPopBack(SL* ps);
//查找
int SeqListFind(SL* ps, SeqDataType x);
//修改
void SeqListModify(SL* ps, int pos, SeqDataType x);
//中间位置插入
void SeqListInsert(SL* ps, int pos, SeqDataType x);
//中间位置删除
void SeqListErase(SL* ps, int pos);
//初始化
void SeqListInit(SL *ps);
//销毁
void SeqListDestory(SL *ps);
//打印
void SeqListPrint(SL* ps);
//扩容
void SeqCheckCapacity(SL* ps);注:这里接口函数取名是根据STL里的vector来取的,方便日后学习STL。
用处:
在通讯录中,我们输入了某个人的信息。那我们就可以调用所需要的接口函数,把这个信息插入到顺序表当中。顺便提一句,假如插入的信息数据类型是多样的,即结构体类型。那么我们就用 typedef 结构体名 Type;
接口实现
静态顺序表只适用于确定知道需要存多少数据的场景。静态顺序表的定长数组导致N定大了,空间开辟多了浪费,开辟少了不够用。所以现实中基本都是使用动态顺序表,根据需要动态的分配空间大小,所以下面我们实现动态顺序表。
示例一:尾插
Seqlist.h
#pragma once
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef int SeqDataType; //如果要修改则只需要修改这一处
typedef struct SeqList
{
SeqDataType* a;
int size; //表示a中有多少个有效数据
int capacity; //表示a的空间到底有多大
}SL, SEQ;
//初始化
void SeqListInit(SL* ps);
//尾插
void SeqListPushBack(SL* ps, SeqDataType x);
//扩容
void SeqCheckCapacity(SeqList* ps);
//打印
void SeqListPrint(SL* ps);
//销毁
void SeqListDestory(SL* ps);test.c:
#include "SeqList.h"
//测试尾插
void TestSeqList1()
{
SL s1;
SeqListInit(&s1);//看解释2
SeqListPushBack(&s1, 1);
SeqListPushBack(&s1, 2);
SeqListPushBack(&s1, 3);
SeqListPushBack(&s1, 4);
SeqListPushBack(&s1, 5);
SeqListPrint(&s1); //1 2 3 4 5
SeqListDestory(&s1);
}
int main()
{
TestSeqList1();
return 0;
}SL.c
#include "SeqList.h"//
//对顺序表的初始化
void SeqListInit(SL *ps)//看解释1
{
assert(ps);
ps->a = NULL;
ps->size = ps->capacity = 0;//看解释3
}
//扩容
void SeqCheckCapacity(SL* ps)
{
//如果没有空间或空间不足,则扩容
if (ps->size == ps->capacity)//有两种情况:1.刚初始化,指针为空,size=capacity=0 2.size=capacity≠0
{
//int newcapacity = ps->capacity * 2; //这样会存在问题,当一开始插入数据时,capacity为0,乘2后还是为0
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2; //如果capacity等于0了,则开辟4个空间
SeqDataType* newA = realloc(ps->a, sizeof(SeqDataType*) * newcapacity);//看解释8
if (newA == NULL)//看解释9
{
printf("realloc fail\n");
exit(-1);//看解释10
}
//程序能运行到这儿,说明realloc开辟空间成功
ps->a = newA;//把刚开辟的空间给它
ps->capacity = newcapacity;//把刚扩容的空间给它
}
}
//尾插
void SeqListPushBack(SL* ps, SeqDataType x)
{
assert(ps);
//扩容函数,检查空间是否足够,如果满了则扩容,反之直接插入数据:
SeqCheckCapacity(ps);//看解释6
//插入数据:
ps->a[ps->size] = x;//在有效个数后面放入要插入的数据x
ps->size++;//插入一个数据后有效个数加1
}
//打印
void SeqListPrint(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
}
//销毁
void SeqListDestory(SL* ps)
{
free(ps->a);
ps->a = NULL;//防止a成为野指针
ps->capacity = ps->size = 0;
}解释:
1️⃣如果void SeqListInit(SL *ps)初始化成功,则调用监视时,显示结果是这样的:

2️⃣ 对SeqListInit(&s1),为何用&s1而不用s1?
s1是我们定义的一个结构体类型变量,如果用s1,那么对应的void SeqListInit(SL ps)中的ps,属于传值调用。然而函数调用后的形参ps不是实参s1,而是s1的临时拷贝,形参的改变无法影响实参。那我们后续搞的尾插,头插,头删...毫无意义
所以我们要改成传址调用,传址调用是形参通过实参传递的地址访问实参的空间,并在其空间进行修改
3️⃣为什么该项目中对结构体成员的访问都是用的->而不是.?
因为我们函数调用采用的是传址调用,所以要用->
4️⃣动态顺序表的尾插是怎么实现的?
下图举例,插入数据5
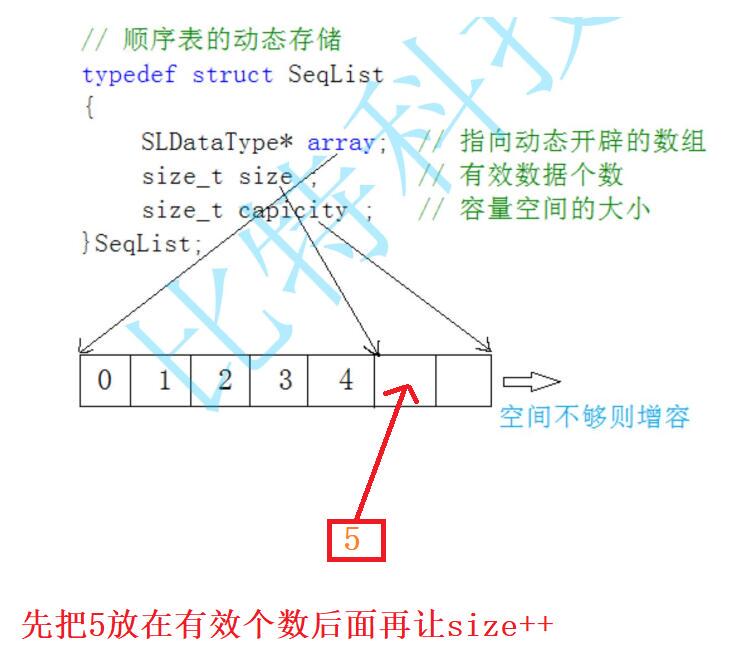
5️⃣动态顺序表尾插的三种情况:
整个顺序表都没有空间,处于刚初始化,空指针和无空间状态
空间不够,先扩容
空间足够,直接插入数据即可
6️⃣ 为什么会有SeqCheckCapacity(ps)?
因为接下来我们要在顺序表中插入数据,插入前就必须检查空间是否充足。如果充足,就数据就插入,否则要扩容再插入
7️⃣扩容时,我们不是扩一个插一个,效率低。而是一次扩现有容量空间的2倍
8️⃣这里用realloc的原因:
实际上,第一次进来的时候,指针变量为空指针、size=capacity=0。这时我们应该先开辟一块空间,再考虑之后的扩容。开辟空间,我们就需要用到malloc函数,而realloc是对已有空间扩容。但是,如果realloc指向的那块空间是空指针,那么realloc函数的功能等价于malloc函数,即开辟空间
9️⃣newA==NULL则表明上面的realloc分申请空间失败,返回NULL
🔟exit()详解:
头文件:stdlib.h
功能:为退出程序的函数
用法:
exit(1); 为异常退出 //只要括号内数字不为0都表示异常退出
exit(0); 为正常退出
注意:括号内的参数都将返回给操作系统;
return() 是返回到上一级主调函数,不一定会退出程序;
示例二:尾删
Seqlist.h
#pragma once
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef int SeqDataType; //如果要修改则只需要修改这一处
typedef struct SeqList
{
SeqDataType* a;
int size; //表示a中有多少个有效数据
int capacity; //表示a的空间到底有多大
}SL, SEQ;
//初始化
void SeqListInit(SL* ps);
//尾插
void SeqListPushBack(SL* ps, SeqDataType x);
//扩容
void SeqCheckCapacity(SeqList* ps);
//打印
void SeqListPrint(SL* ps);
//销毁
void SeqListDestory(SL* ps);test.c:
#include "SeqList.h"
//测试尾插
void TestSeqList1()
{
SL s1;
SeqListInit(&s1);
SeqListPushBack(&s1, 1);
SeqListPushBack(&s1, 2);
SeqListPushBack(&s1, 3);
SeqListPushBack(&s1, 4);
SeqListPushBack(&s1, 5);
SeqListPrint(&s1); //1 2 3 4 5
SeqListPopBack(&s1);
SeqListPopback(&s1);
SeqListPrint(&s1);
SeqListDestory(&s1);
}
int main()
{
TestSeqList1();
return 0;
}SL.c
#include "SeqList.h"//
//对顺序表的初始化
void SeqListInit(SL *ps)
{
assert(ps);
ps->a = NULL;
ps->size = ps->capacity = 0;
}
//扩容
void SeqCheckCapacity(SL* ps)
{
//如果没有空间或空间不足,则扩容
if (ps->size == ps->capacity)//有两种情况:1.刚初始化,指针为空,size=capacity=0 2.size=capacity≠0
{
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SeqDataType* newA = realloc(ps->a, sizeof(SeqDataType*) * newcapacity);
if (newA == NULL)
{
printf("realloc fail\n");
exit(-1);
}
//程序能运行到这儿,说明realloc开辟空间成功
ps->a = newA;
ps->capacity = newcapacity;
}
}
//尾删
void SeqListPopBack(SL* ps)
{
assert(ps);
assert(ps->size > 0); //看解释4
ps->size--;
//注意,不能把pq->size置0,这不叫删除,且万一该数据就是0呢
}
//打印
void SeqListPrint(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
}
//销毁
void SeqListDestory(SL* ps)
{
free(ps->a);
ps->a = NULL;//防止a成为野指针
ps->capacity = ps->size = 0;
}解释:
1️⃣尾删的错误写法:
//尾删
void SeqListPopBack(SL* ps)
{
//尾删思路:
//第一步:把size空间里最后那个位置上的数字赋为0
//第二步:把size减一,相当于有效空间减一
ps->a[ps->size-1]=0;//看解释2
ps->size--;看解释3
}
/*经过验证,我们发现:即使把第7行代码删掉,程序运行结果也不变
表明:给size的最后一个有效数字赋值为0没啥意义,它要是本身为0相当于啥都没做。而且删的对象是size的空间,跟你这个数是啥没啥关系
*/2️⃣a[ps->size-1]什么意思?
ps->size-1的作用是找到size空间的最后位置上的数的下标,又因为数组排序是从0开始,所以实际size大小要减一才能对应到数组中去
a[p->size-1]是定位到size空间的最后位置,即等效最后那个数。对它进行赋值就是对那个末位数进行赋值
3️⃣ps->size--的注意事项:
size不能想减多少就减多少,减到1是它的极限。因为一旦小于1,比如size=-2,那么之后再对a进行尾插时会发生非法访问,销毁时free作用下系统会检测出来并报警告
改进:
//尾删
void SeqListPopBack(SL* ps)
{
for(ps->size > 0)
{
ps->size--;
}//大于0时减一,小于等于0时,啥都不干
}4️⃣assert是比for更粗暴的方法,因为你要是用for条件判断的话,你不符合条件我只是不执行。但是assert是你一旦不满足条件,我就弹出警告,让你后面的尝试中断。
⏩for是温柔处理方式,assert是暴力处理方式
示例三:头插
Seqlist.h
#pragma once
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef int SeqDataType; //如果要修改则只需要修改这一处
typedef struct SeqList
{
SeqDataType* a;
int size; //表示a中有多少个有效数据
int capacity; //表示a的空间到底有多大
}SL, SEQ;
//初始化
void SeqListInit(SL* ps);
//尾插
void SeqListPushBack(SL* ps, SeqDataType x);
//扩容
void SeqCheckCapacity(SeqList* ps);
//打印
void SeqListPrint(SL* ps);
//销毁
void SeqListDestory(SL* ps);test.c:
#include "SeqList.h"
//测试尾插
void TestSeqList1()
{
SL s1;
SeqListInit(&s1);
SeqListPushBack(&s1, 1);
SeqListPushBack(&s1, 2);
SeqListPushBack(&s1, 3);
SeqListPushBack(&s1, 4);
SeqListPushBack(&s1, 5);
SeqListPrint(&s1); //1 2 3 4 5
SeqListPushFront(&s1,10);
SeqListPushFront(&s1,20);
SeqListPrint(&s1);
SeqListDestory(&s1);
}
int main()
{
TestSeqList1();
return 0;
}SL.c
#include "SeqList.h"//
//对顺序表的初始化
void SeqListInit(SL *ps)
{
assert(ps);
ps->a = NULL;
ps->size = ps->capacity = 0;
}
//扩容
void SeqCheckCapacity(SL* ps)
{
//如果没有空间或空间不足,则扩容
if (ps->size == ps->capacity)//有两种情况:1.刚初始化,指针为空,size=capacity=0 2.size=capacity≠0
{
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SeqDataType* newA = realloc(ps->a, sizeof(SeqDataType*) * newcapacity);
if (newA == NULL)
{
printf("realloc fail\n");
exit(-1);
}
//程序能运行到这儿,说明realloc开辟空间成功
ps->a = newA;
ps->capacity = newcapacity;
}
}
//头插
void SeqListPushFront(SL* ps,SLDataType x)
{
//检查空间是否充足,看解释1,2
SeqListCheckCapacity(ps);
//挪动数据,看解释1
int end = ps->size-1;
while(end>=0)
{
ps->a[end+1] = ps->a[end];
--end;
}
ps->a[0] = x;
ps->size++;
}
//打印
void SeqListPrint(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
}
//销毁
void SeqListDestory(SL* ps)
{
free(ps->a);
ps->a = NULL;//防止a成为野指针
ps->capacity = ps->size = 0;
}1️⃣思路:
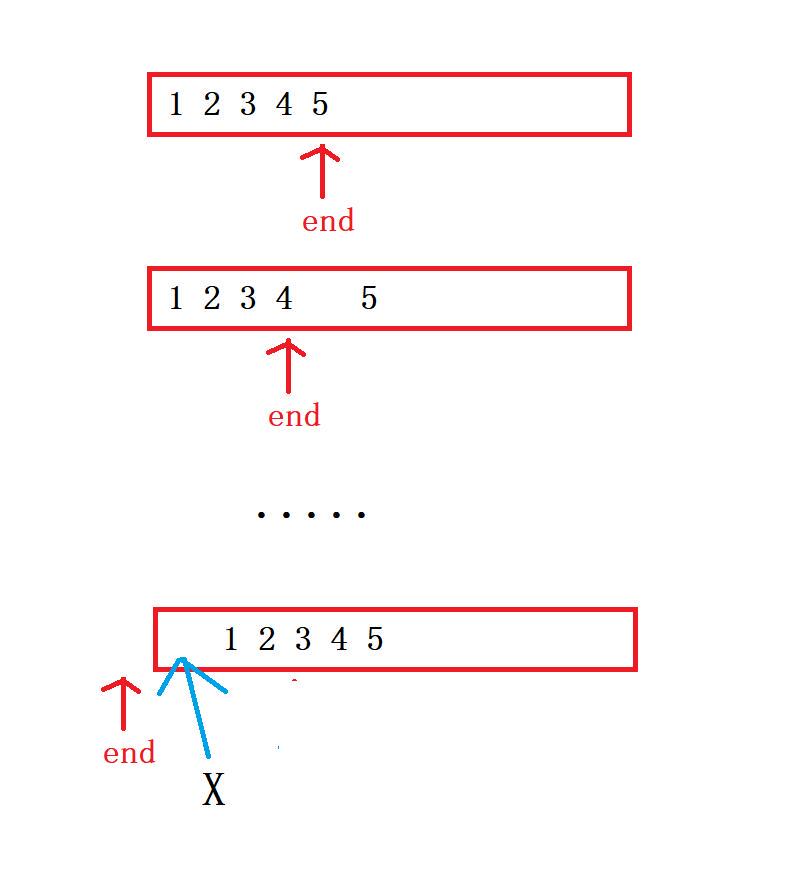
但是以上这个思路有个问题没有考虑到,那就是我把数据往后挪的时候,我压根没有考虑是否后面还有没有空间。如果没有空间又没有扩容就把数据往后移,是非法访问地址,销毁时free会查出这个错误并警告
2️⃣扩容时,分为两种扩容方式:原地扩容和异地扩容。
原地扩容:该空间后面还有足够的剩余空间,那就把原空间往后扩容
异地扩容:该空间后面没有足够的剩余空间了,那就在内存中重新开辟一块满足需求的新空间,并把原数据拷贝下来,然后再释放旧空间返回新空间地址。
所以,你知道我们为什么要用relloc开辟空间了吧?
示例四:头删
Seqlist.h
#pragma once
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef int SeqDataType; //如果要修改则只需要修改这一处
typedef struct SeqList
{
SeqDataType* a;
int size; //表示a中有多少个有效数据
int capacity; //表示a的空间到底有多大
}SL, SEQ;
//初始化
void SeqListInit(SL* ps);
//头删
void SeqListPopFront(SL* ps);
//打印
void SeqListPrint(SL* ps);
//销毁
void SeqListDestory(SL* ps);test.c:
#include "SeqList.h"
//测试尾插
void TestSeqList1()
{
SL s1;
SeqListInit(&s1);
SeqListPushBack(&s1, 1);
SeqListPushBack(&s1, 2);
SeqListPushBack(&s1, 3);
SeqListPushBack(&s1, 4);
SeqListPushBack(&s1, 5);
SeqListPrint(&s1); //1 2 3 4 5
SeqListPopFront(&s1);
SeqListPrint(&s1);
SeqListDestory(&s1);
}
int main()
{
TestSeqList1();
return 0;
}SL.c
#include "SeqList.h"//
//对顺序表的初始化
void SeqListInit(SL *ps)
{
assert(ps);
ps->a = NULL;
ps->size = ps->capacity = 0;
}
//头删
void SeqListPopFront(SL* ps)
{
assert(ps->size > 0);//还可以警告空间为空的情况
int begin=1;
//挪动数据
while(begin < ps->size)
{
ps->a[begin-1] = a[begin];
++begin;
}//看解释1
ps->size--;
}
//打印
void SeqListPrint(SL* ps)
{
assert(ps);
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
}
//销毁
void SeqListDestory(SL* ps)
{
free(ps->a);
ps->a = NULL;//防止a成为野指针
ps->capacity = ps->size = 0;
}1️⃣思路:
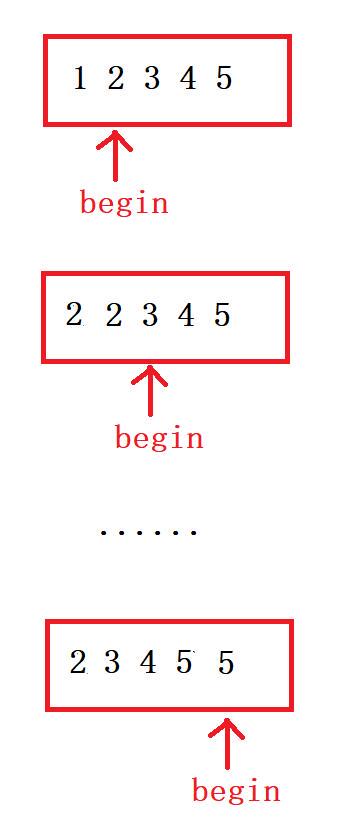
示例五:查找
int SeqListFind(SL* ps, SLDataType x)
{
for(int i=0; i<ps->size; i++)
{
if(ps->a[i]==x)
{
return i;
}
}
return -1;
}//找到了返回x位置下标,找不到返回-1示例六:插入
void SeqListInsert(SL* ps, int pos, SLDataType x)
{
/*温柔处理方式:
for(pos < 0 || pos > ps-> size)
{
printf("pos invalid\n");
return;
}*/
//暴力处理方式:
assert(pos >= 0 && pos < ps->size);//看解释2
SeqListCheckCapacity(ps);
int end=ps->size-1;
while (end >= pos)
{
ps->a[end + 1] = ps->[end];
end--;
}//看解释3
ps->a[pos] = x;
ps->size++;//看解释4
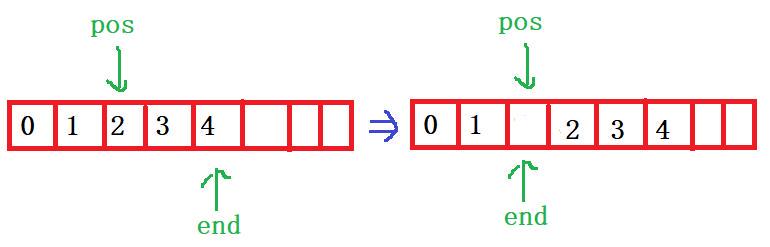
}//指定pos位置数据插入1️⃣思路:
限定插入范围
检查容量空间是否有剩余(只要capacity比size多1就行,反正只插入一个数),不足则扩容
把pos位置上及之后的元素往后挪1
最后用x覆盖pos位置
2️⃣限定插入的范围:必须在数组有效空间内

3️⃣
4️⃣ps->size++有什么意义?
插入数据x后,空间a的有效数据size就增加了1,所以最后要把它补上
示例七:插入的高级用法--任意元素替换
test.c:
#include "SeqList.h"
//测试尾插
void TestSeqList1()
{
SL s1;
SeqListInit(&s1);//看解释2
SeqListPushBack(&s1, 1);
SeqListPushBack(&s1, 2);
SeqListPushBack(&s1, 3);
SeqListPushBack(&s1, 4);
SeqListPushBack(&s1, 5);
SeqListPrint(&s1); //1 2 3 4 5
int pos=SeqListFind(&s1,4);
if(pos !=-1)
{
SeqListInsert(&s1,pos,40);
}//看解释1
SeqListPrint(&s1);
SeqListDestory(&s1);
}
int main()
{
TestSeqList1();
return 0;
}1️⃣找到元素4,并用40替换它
示例八:改进头插--复用插入
void SeqListPushFront(SL* ps,SLDataType x)
{
SeqListInsert(ps,0,x);
}示例九:改进尾插--复用插入
//尾插
void SeqListPushBack(SL* ps, SeqDataType x)
{
SeqListInsert(ps,ps->size,x);
}示例十:删除
指定pos位置数据删除
void SeqListErase(SL* ps, int pos)
{
assert(pos >= 0 && pos < ps->size);//看解释1
int begin = pos+1;
while (begin < ps->size)
{
ps->a[begin - 1] = ps->a[begin];
++begin;
}//看解释2
ps->size--;
}1️⃣为什么pos < ps->size,而不是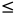
因为pos代表数组a的下标,从0开始到size-1。当pos=ps->size时,不再属于有效空间的范围

2️⃣思路:类似于插入,不同的是它是往前覆盖

示例十一:改进头删--复用删除
void seqListPopFront(SL* ps)
{
assert(ps->size > 0);
SeqListErase(ps,0);
}示例十二:改进尾删--复用删除
void SeqListPopBack(SL* ps)
{
assert(ps);
assert(ps->size > 0);
SeqListErase(ps,ps->size);
}示例十三:删除的高级用法--任意元素的删除
test.c:
#include "SeqList.h"
//测试尾插
void TestSeqList1()
{
SL s1;
SeqListInit(&s1);//看解释2
SeqListPushBack(&s1, 1);
SeqListPushBack(&s1, 2);
SeqListPushBack(&s1, 3);
SeqListPushBack(&s1, 4);
SeqListPushBack(&s1, 5);
SeqListPrint(&s1); //1 2 3 4 5
int pos=SeqListFind(&s1,5);//找到5的下标
if(pos !=-1)
{
SeqListErase(&s1,pos);
}//看解释1
SeqListPrint(&s1);
SeqListDestory(&s1);
}
int main()
{
TestSeqList1();
return 0;
}1️⃣找到数字5并删除它
示例十四:合并上述功能,写一个通讯录
Seqlist.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
// 要求:存储的数据从0开始,依次连续存储
// 静态的顺序表
// 问题:开小了,不够用。开大了,存在浪费。
//#define N 10000
//struct SeqList
//{
// int a[N];
// int size; // 记录存储了多少个数据
//};
typedef int SLDataType;
// 动态的顺序表
typedef struct SeqList
{
SLDataType* a;
int size; // 存储数据个数
int capacity; // 存储空间大小
}SL, SeqList;
void SeqListPrint(SeqList* psl);
//void SLInit(SeqList* psl);
void SeqListInit(SeqList* psl);
void SeqListDestroy(SeqList* psl);
void SeqListCheckCapacity(SeqList* psl);
// 时间复杂度是O(1)
void SeqListPushBack(SeqList* psl, SLDataType x);
void SeqListPopBack(SeqList* psl);
// 时间复杂度是O(N)
void SeqListPushFront(SeqList* psl, SLDataType x);
void SeqListPopFront(SeqList* psl);
// 在pos位置插入x
void SeqListInsert(SeqList* psl, size_t pos, SLDataType x);
// 删除pos位置的数据
void SeqListErase(SeqList* psl, size_t pos);
// 顺序表查找
int SeqListFind(SeqList* psl, SLDataType x);
test.c
#include "SeqList.h"
void TestSeqList1()
{
SeqList s;
SeqListInit(&s);
SeqListPushBack(&s, 1);
SeqListPushBack(&s, 2);
SeqListPushBack(&s, 3);
SeqListPushBack(&s, 4);
SeqListPushBack(&s, 5);
SeqListPushBack(&s, 0);
SeqListPrint(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPrint(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPrint(&s);
SeqListPushBack(&s, 10);
SeqListPushBack(&s, 20);
SeqListPrint(&s);
//SeqListPrint(NULL);
// 越界不一定能检查出来,越界是抽查
// 就像查酒驾一样。不一定会被查到,但是我们一定不能酒驾
//int a[10];
//a[10] = 1;
//a[11] = 1;
//a[12] = 1;
//a[100] = 1;
}
void TestSeqList2()
{
/*int* p = (int*)malloc(sizeof(int) * 10);
printf("%p\n", p);
int* p1 = (int*)realloc(p, sizeof(int) * 100);
printf("%p\n", p1);*/
SeqList s;
SeqListInit(&s);
SeqListPushBack(&s, 1);
SeqListPushBack(&s, 2);
SeqListPushBack(&s, 3);
SeqListPushBack(&s, 4);
SeqListPushFront(&s, 0);
SeqListPushFront(&s, -1);
SeqListPrint(&s);
SeqListPopFront(&s);
SeqListPopFront(&s);
SeqListPopFront(&s);
SeqListPopFront(&s);
SeqListPopFront(&s);
SeqListPrint(&s);
SeqListPopFront(&s);
SeqListPrint(&s);
SeqListPopFront(&s);
SeqListPopFront(&s);
SeqListPushFront(&s, 0);
SeqListPushFront(&s, -1);
SeqListPrint(&s);
}
void TestSeqList3()
{
SeqList s;
SeqListInit(&s);
SeqListPushBack(&s, 1);
SeqListPushBack(&s, 2);
SeqListPushBack(&s, 3);
SeqListPushBack(&s, 4);
SeqListPrint(&s);
SeqListInsert(&s, 10, 100);
SeqListInsert(&s, 1, 20);
SeqListInsert(&s, 5, 50);
SeqListInsert(&s, 0, 50);
SeqListPrint(&s);
SeqListDestroy(&s);
}
void TestSeqList4()
{
SeqList s;
SeqListInit(&s);
SeqListPushBack(&s, 1);
SeqListPushBack(&s, 2);
SeqListPushBack(&s, 3);
SeqListPushBack(&s, 4);
SeqListPushBack(&s, 5);
SeqListPrint(&s);
SeqListErase(&s, 4);
SeqListPrint(&s);
SeqListErase(&s, 0);
SeqListPrint(&s);
SeqListErase(&s, 1);
SeqListPrint(&s);
}
void TestSeqList5()
{
SeqList s;
SeqListInit(&s);
SeqListPushBack(&s, 1);
SeqListPushBack(&s, 2);
SeqListPushBack(&s, 3);
SeqListPushBack(&s, 4);
SeqListPushBack(&s, 5);
SeqListPushFront(&s, -1);
SeqListPushFront(&s, -2);
SeqListPrint(&s);
SeqListPopFront(&s);
SeqListPopFront(&s);
SeqListPopBack(&s);
SeqListPopBack(&s);
SeqListPrint(&s);
}
void menu()
{
printf("***********************************************\n");
printf("请选择你的操作:>\n");
printf("1.头插数据 2.头删数据\n");
printf("3.尾插数据 4.尾删数据\n");
printf("5.打印数据 6.查找数据\n");
printf("-1.退出 \n");
printf("***********************************************\n");
}
void MenuTest()
{
SL s;
SeqListInit(&s);
int input = 0;
int x = 0;
while (input != -1)
{
Menu();
scanf("%d", &input);
switch (input)
{
case 1:
printf("请输入你要头插的数据,以-1结束:\n");//缺点:为了设置一个标志,头插不了-1
sacnf("%d", &x);
while (x != -1)
{
SeqListPushFront (&s,x);
scanf("%d", &x);
}
break;
case 2:
printf("请输入你要头删的数据,以-1结束:\n");//缺点:为了设置一个标志,头删不了-1
sacnf("%d", &x);
while (x != -1)
{
SeqListPopFront(&s, x);
scanf("%d", &x);
}
break;
case 3:
printf("请输入你要尾插的数据,以-1结束:\n");//缺点:为了设置一个标志,尾插不了-1
sacnf("%d", &x);
while (x != -1)
{
SeqListPushBack(&s, x);
scanf("%d", &x);
}
break;
case 4:
SeqListPopBack(&s);
break;
case 5:
SeqListPrint(&s);
break;
case 6:
printf("请输入你要查找的数据,以-1结束:\n");//缺点:为了设置一个标志,尾插不了-1
sacnf("%d", &x);
while (x != -1)
{
SeqListFind(&s, x);
scanf("%d", &x);
}
break;
default:
printf("无此选项,请重新输入\n");
break;
}
}
SeqListDestory(&s);
}
int main()
{
MenuTest();
return 0;
}SL.c
#include "SeqList.h"
void SeqListPrint(SeqList* psl)
{
assert(psl);
for (int i = 0; i < psl->size; ++i)
{
printf("%d ", psl->a[i]);
}
printf("\n");
}
void SeqListInit(SeqList* psl)
{
assert(psl);
psl->a = NULL;
psl->size = 0;
psl->capacity = 0;
}
void SeqListDestroy(SeqList* psl)
{
assert(psl);
free(psl->a);
psl->a = NULL;
psl->capacity = psl->size = 0;
}
void SeqListCheckCapacity(SeqList* psl)
{
assert(psl);
// 如果满了,我们要扩容
if (psl->size == psl->capacity)
{
size_t newCapacity = psl->capacity == 0 ? 4 : psl->capacity * 2;
SLDataType* tmp = realloc(psl->a, sizeof(SLDataType)*newCapacity);
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
else
{
psl->a = tmp;
psl->capacity = newCapacity;
}
}
}
void SeqListPushBack(SeqList* psl, SLDataType x)
{
assert(psl);
/*SeqListCheckCapacity(psl);
psl->a[psl->size] = x;
psl->size++;*/
SeqListInsert(psl, psl->size, x);
}
void SeqListPopBack(SeqList* psl)
{
assert(psl);
//psl->a[psl->size - 1] = 0;
/*if (psl->size > 0)
{
psl->size--;
}*/
SeqListErase(psl, psl->size-1);
}
void SeqListPushFront(SeqList* psl, SLDataType x)
{
assert(psl);
//SeqListCheckCapacity(psl);
挪动数据,腾出头部空间
//int end = psl->size - 1;
//while (end >= 0)
//{
// psl->a[end + 1] = psl->a[end];
// --end;
//}
//psl->a[0] = x;
//psl->size++;
SeqListInsert(psl, 0, x);
}
void SeqListPopFront(SeqList* psl)
{
assert(psl);
// 挪动数据覆盖删除
/*if (psl->size > 0)
{
int begin = 1;
while (begin < psl->size)
{
psl->a[begin - 1] = psl->a[begin];
++begin;
}
--psl->size;
}*/
SeqListErase(psl, 0);
}
// 在pos位置插入x
//void SeqListInsert(SeqList* psl, int pos, SLDataType x)
void SeqListInsert(SeqList* psl, size_t pos, SLDataType x)
{
// 暴力检查
assert(psl);
// 温和检查
if (pos > psl->size)
{
printf("pos 越界:%d\n", pos);
return;
//exit(-1);
}
// 暴力检查
//assert(pos <= psl->size);
SeqListCheckCapacity(psl);
//int end = psl->size - 1;
//while (end >= (int)pos)
//{
// psl->a[end + 1] = psl->a[end];
// --end;
//}
size_t end = psl->size;
while (end > pos)
{
psl->a[end] = psl->a[end-1];
--end;
}
psl->a[pos] = x;
psl->size++;
}
// 删除pos位置的数据
void SeqListErase(SeqList* psl, size_t pos)
{
assert(psl);
assert(pos < psl->size);
size_t begin = pos + 1;
while (begin < psl->size)
{
psl->a[begin - 1] = psl->a[begin];
++begin;
}
psl->size--;
}
int SeqListFind(SeqList* psl, SLDataType x)
{
assert(psl);
for (int i = 0; i < psl->size; ++i)
{
if (psl->a[i] == x)
{
return i;
}
}
return -1;
}数组相关面试题:
面试题1:移除元素
题目描述:
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
思路一:从数组下标为0开始挨个检查,一旦发现这个数是等于val,那就让这个数后面的数依次往前覆盖挪1 (借鉴头删的思路)。挪完后,朝下一个下标重复上述操作
时间复杂度:O()
最坏的情况: 数组中的值全是等于val
运算: 覆盖第一个数,运行n-1次;运行第二个数,运行n-2次......即:
(n-1)+(n-2)+(n-3)+...+2+1=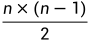
思路二: 一次遍历数组,把不是val的值,放到新开辟的数组tmp中,再把tmp数组的值拷贝回去
时间复杂度:O(2N)
运算: 遍历一遍N,拷贝回原数组时再遍历一遍N
空间复杂度:O(N) (以空间换取时间)

思路三:src挨个依次去找nums数组中不等于val的值,放到dst指向的位置去,再++src,++dst
时间复杂度:O(N)
空间复杂度:O(1)
运算: 在大段空间中只给了常数个变量,故可认为是O(1)

int removeElement(int* nums, int numsSize, int val)
{
int src=0,dst=0;//定义指向数组两侧的变量
while(src<numsSize)//限定src的范围
{
if(nums[src]!=val)
{
nums[dst]=nums[src];
src++;
dst++;
}
else
{
src++;
}
}
return dst;//dst就是输出的数据个数
}面试题2:删除有序数组中的重复项
题目描述:
给你一个升序排列的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
原理讲解:对数组设两个指针,分列两侧。当i

int removeDuplicates(int* nums, int numsSize){
if(numsSize==0)
{
return 0;
}
int i=0,j=0;
while(i<numsSize-1)
{
if(nums[i+1]!=nums[i])
{
nums[j]=nums[i];
i++;
j++;
}
else
{
i++;
}
}
nums[j]=nums[i];
j++;
return j;
}思路:如何用双指针考虑?
int removeDuplicates(int* nums, int numsSize)
{
//如果是空数组,直接返回0
if(numsSize== 0)
return 0;
int cur = 0;
int dst = 0;
int next = 1;
while(next < numsSize)
{
if(nums[cur] != nums[next])//前后不相等,直接把值赋给dst
{
nums[dst++] = nums[cur++];
next++;
}
else
{
//前后相等时,next继续往后找,直到两者不相等为止
//在该循环也需要限制next范围,否则容易出现越界
while(next < numsSize && nums[cur] == nums[next])
{
next++;
}
nums[dst] = nums[cur];
dst++;
cur = next; //cur跳过已经判断出相等的部分
next++;
}
}
if(cur < numsSize)//如果不进行判断,可能会出现越界访问
{
nums[dst] = nums[cur]; //把最后一个值赋给dst
dst++;
}
return dst;
}面试题3: 合并两个有序数组
题目描述:
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
时间复杂度:O(m+n)
空间复杂度:0(1) (因为我没有开辟额外的空间)
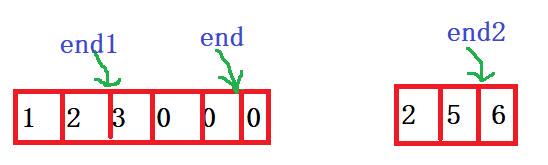
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{
int end1 = m - 1, end2 = n - 1;
int end = m + n - 1;//看解释1
while (end1 >= 0 && end2 >= 0)//看解释2
{
if (nums1[end1] > nums2[end2])
{
nums1[end--] = nums1[end1--];
}
else
{
nums1[end--] = nums2[end2--];
}
}//看解释3
while (end2 >= 0)
{
nums1[end--] = nums2[end2--];
}//看解释4
}1️⃣
2️⃣为什么要把循环条件设为&&而不是| |?
这个就属于数学中的逻辑问题了,我们这样想:是不是end1或end2其中一个<0,咱这个程序就不用比较大小,就循环结束收尾了?那反过来,我们要这个循环还在运行,那我们就得让这俩货都
3️⃣

4️⃣

此时只有end2还没有<0,就把end2剩余的全赋给end对应的空框框
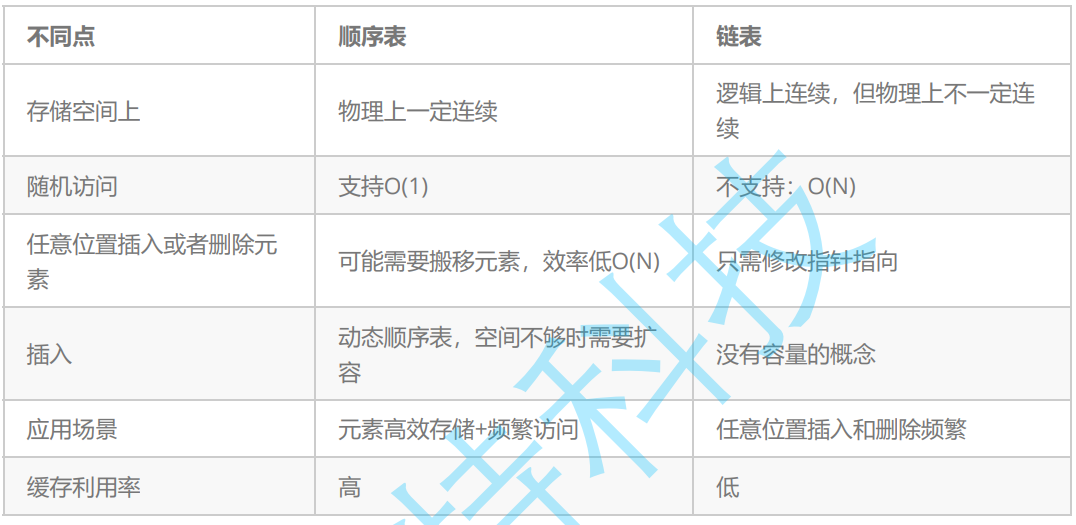
顺序表的缺陷
①内存不够需要扩容,扩容分为原地扩容和异地扩容,扩容需要付出代价(增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗)
原地扩容:
异地扩容:

②避免频繁扩容,我们满了基本都是扩2倍,可能就会导致一定的空间浪费(例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。)
③顺序表要求数据从开始位置连续存储,那么我们在头部或者中间位置插入删除数据就需要挪动数据,时间效率不高,时间复杂度为O(N)
注:针对顺序表的缺陷,就设计出了链表
顺序表的优点:
支持随机访问
cpu高速缓存命中率更高
链表
链表的概念
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表的优点:
按需申请空间,不用了就释放空间。(空间的使用更合理)
任意位置插入删除数据效率高,时间复杂度O(1),不需要挪动数据
不存在空间浪费
链表的缺点:
每存一个数据,都要存一个指针去链接后面数据的节点
不支持随机访问(用下标直接访问第i个)
链表存储一个值,同时要存储连接指针,也有一定的消耗
cpu高速缓存命中率更低
注:有些算法需要结构支持随机访问,比如二分查找、优化的快排等等
链表的结构

链表的结构非常多样,大概可以分为八种结构:
带头还是不带头
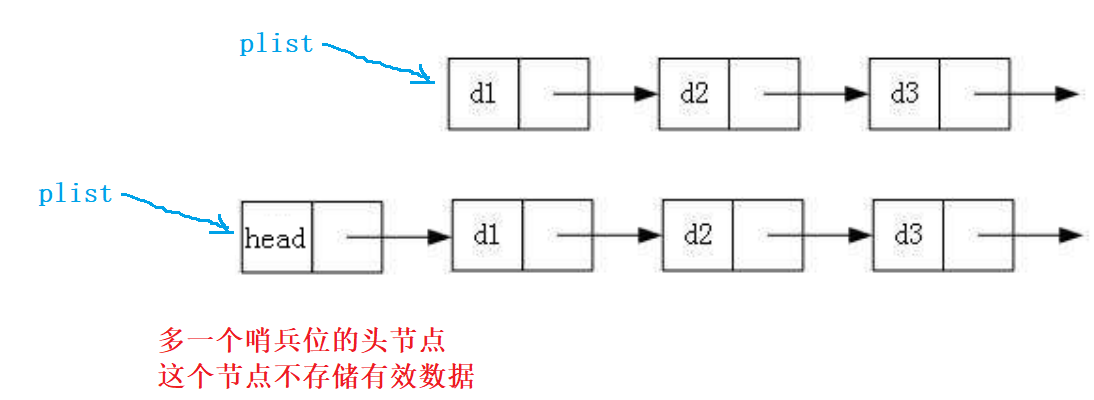
注:当遇到尾删把链表删完的情况,plist依旧指向哨兵位head,不需要改变plist(带头)
而plist需要改变(不带头)
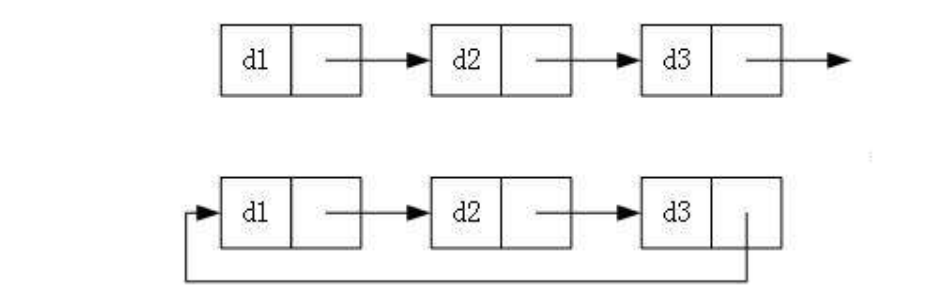
循环还是不循环
单向还是双向

虽然单链表的结构众多,但大部分常用的还是两种结构。无头单向不循环链表和带头双向循环链表
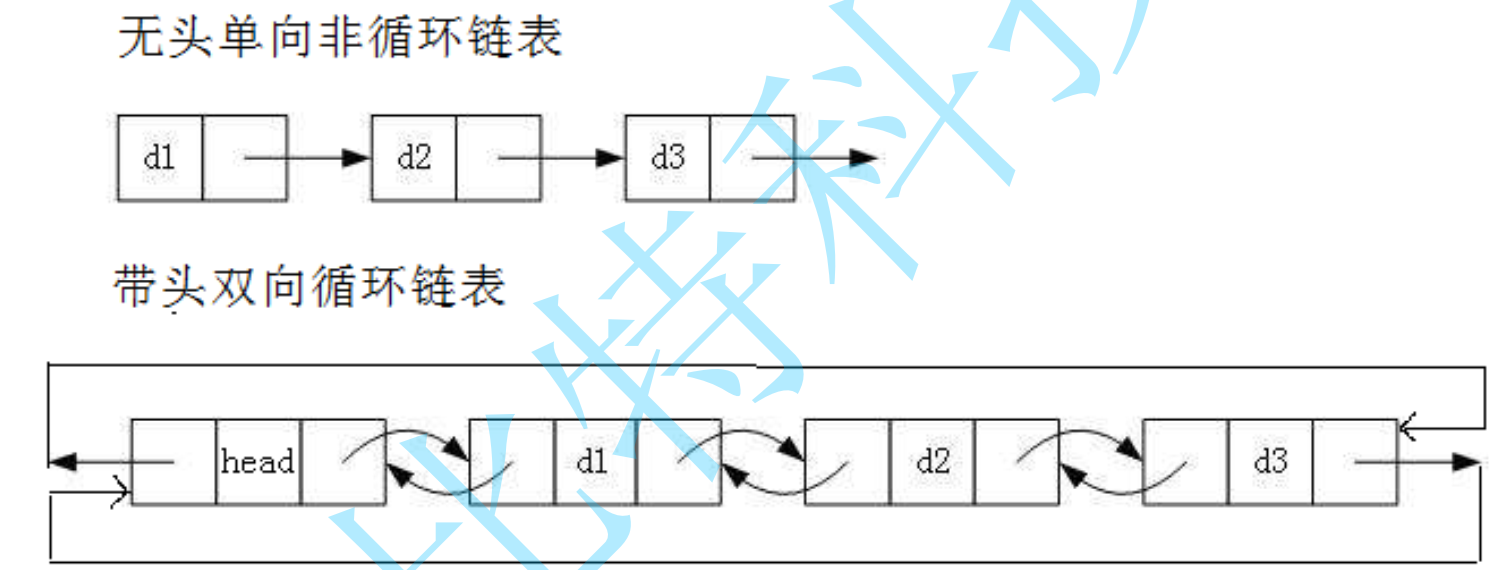
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
无头+单向+非循环链表接口实现

逻辑图/结构:想象出来的,形象方式表示

物理图/结构:在内存中实实在在如何存储的
定义链表的基本结构 ,节点(在头文件中定义)
typedef int SLTDataType;
typedef struct SLTNode
{
SLTDataType data;
struct SLTNode* next;//下一个节点的地址
}SLTNode;打印链表:
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;//看解释1
while (cur != NULL)
{
printf("%d->", cur->data);//看解释2
cur = cur->next;//看解释3
}
}1️⃣phead是个指针变量,存放的是第一个数据d1的地址,SLTNode* cur = phead就相当于把d1的地址给了cur

2️⃣cur->data是啥意思?
cur:存储了节点的地址
->:具有解引用的功能
data:对应节点的存储数据
=>cur存着节点的地址,访问节点的data,再解引用得到data存储的数据
3️⃣cur->next <=> cur访问next,并解引用next,得到d2的地址
cur=cur->next<=>cur接收右侧传过来的地址。此时cur存放的是d2的地址

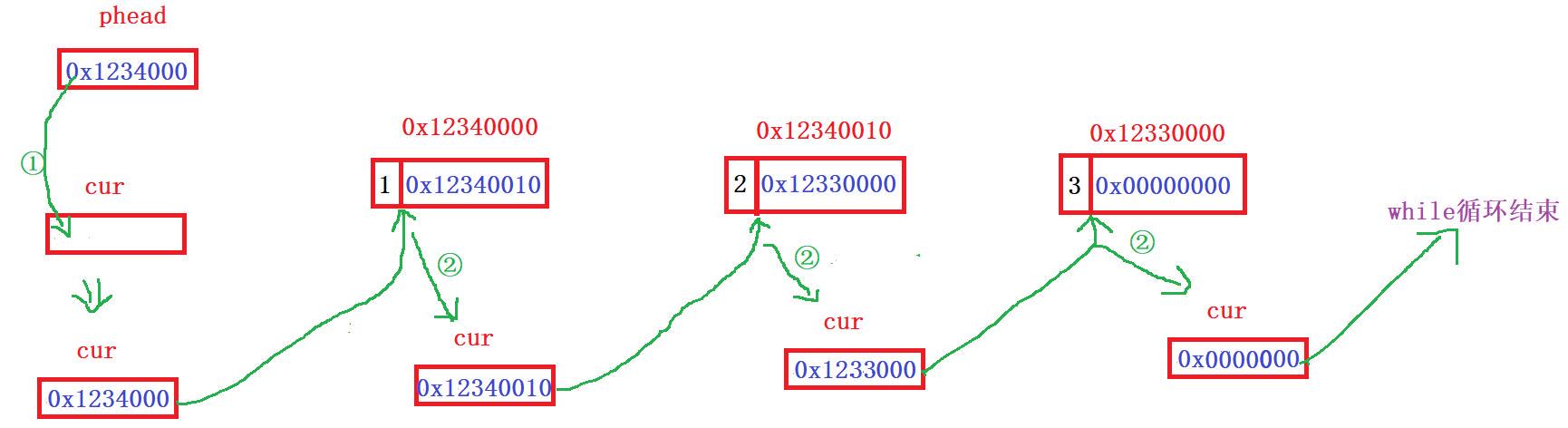
①SLTNode* cur = phead
②cur = cur->next
链表的尾插:
常见的错误写法:看解释5
void SeqListPushBack (SLTNode* phead,SLTDataType x)//看后面的完整尾插解释1
{
//找到尾节点
SLTNode* tail = phead;//看解释4
while (tail->next != NULL)//看解释3
{
tail = tail->next;
}//看解释4
//创建新节点,并给字点补充data和next
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//看解释2
newnode->data=x;
newnode->next=NULL;
//让尾节点的next包含的地址由NULL改成新节点的地址
tail->next=newnode;
}1️⃣思路:我现在要在现有的链表末尾插入一个节点newnode,就要先用malloc创建出这个节点并得到它的地址,然后给这个节点data赋值x和next赋空指针,给前一个节点即尾节点tail的next赋newnode的地址
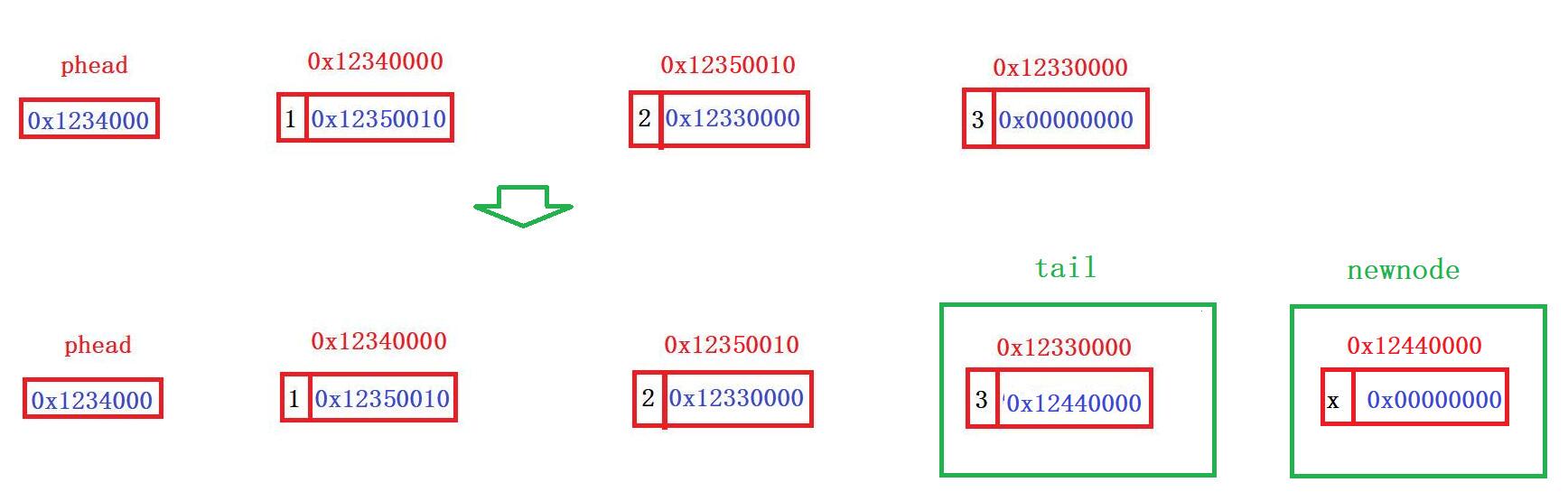
2️⃣SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)) 是啥意思?
malloc(sizeof(SLTNode)):给新节点开辟空间,开辟成功返回开辟空间地址,失败则返回NULL
(SLTNode*):新节点是SLTNode*类型,那么右边想把地址传过去,也必须强制类型转换成一样的类型
3️⃣循环结束的条件是tail->next = NULL,那么反之循环继续的条件便是tail->next != NULL
4️⃣找节点跟这个 SLTNode* tail = phead 有什么关系?
我们要找到尾节点tail,能想到的办法就是从第一个节点(phead有它的地址,∴SLTNode* tail = phead)开始,依次判断(用到while循环)它的next是否为0x0000000(即NULL),如果是则该节点一定是尾节点,反之则进入下一次循环继续判断。
5️⃣ 对SLTNode* tail = phead的理解:

同理,tail=phead和上述等价
5️⃣因为如果phead为空指针,那么tail->相当于解引用NULL空指针
空指针解引用:
C语言空指针的值为NULL。一般NULL指针指向进程的最小地址,通常这个值为0。试图通过空指针对数据进行访问,会导致运行时错误。当程序试图解引用一个期望非空但是实际为空的指针时,会发生空指针解引用错误。对空指针的解引用会导致未定义的行为。在很多平台上,解引用空指针可能会导致程序异常终止或拒绝服务。如:在 Linux 系统中访问空指针会产生 Segmentation fault 的错误。详细请参见CWEID 476: NULL Pointer Dereference ( http://cwe.mitre.org/data/definitions/476.html)。
正确的写法:
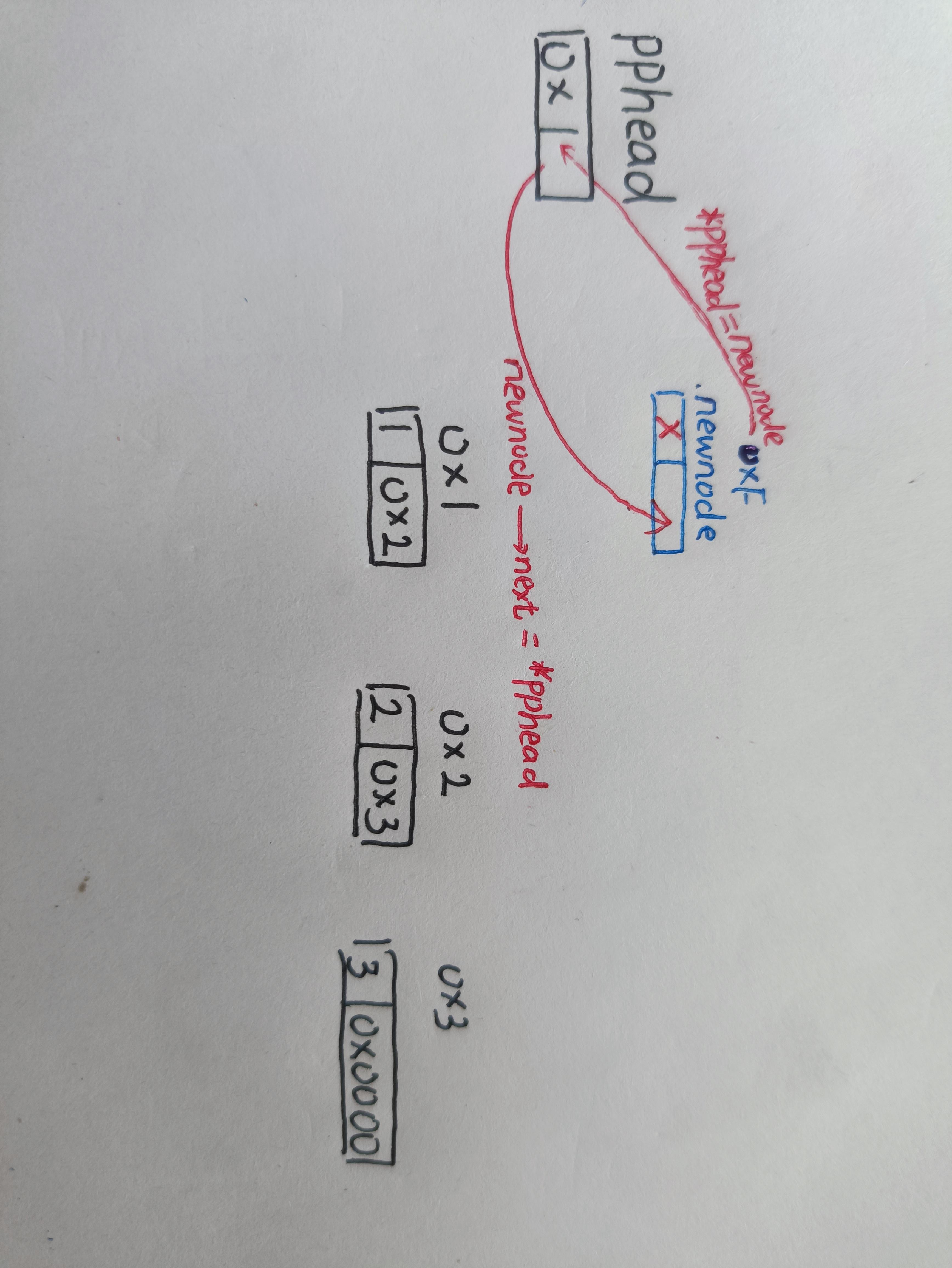
void SeqListPushBack (SLTNode** phead,SLTDataType x)//看解释2
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
if(*phead==NULL)
{
*phead=newnode;
}//看解释3
else
{
//找到尾节点
SLTNode* tail = phead;//看解释4
while (tail->next != NULL)//看解释3
{
tail = tail->next;
}//看解释4
//把新节点的位置放入之前的尾节点的next中
tail->next = newnode;
}
}1️⃣思路:和上面的错误写法基本一致,唯一不同的是对phead=NULL这一情况的处理。当phead=NULL时,没有链表,也就不存在什么尾节点,更没有去找尾节点这一行为。故直接把新节点newnode的地址传给phead。
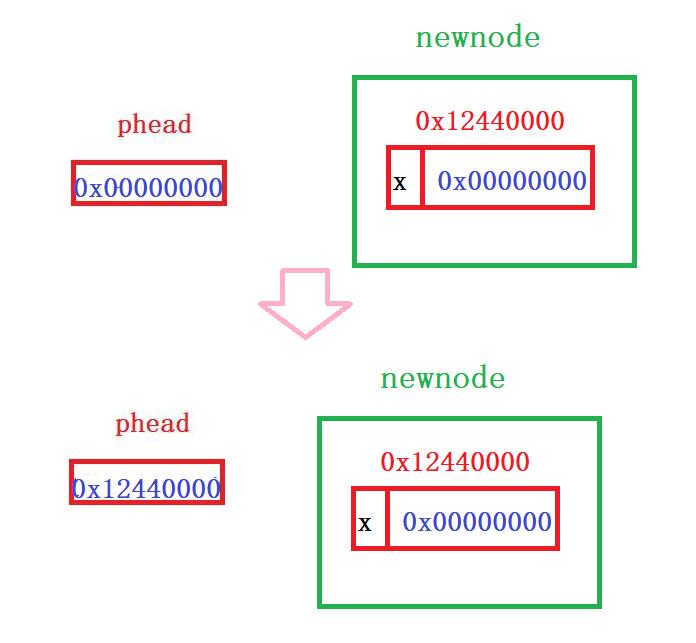
注:如果不想处理空链表的情况,那么只需要用assert(phead)即可。遇空链表警告
phead和plist的区别:都是指向第一个节点的地址,不过一个是形参一个是实参
2️⃣为什么会采用二级指针 SLTNode** phead ?
因为当链表不存在,只有一个头指针plist时,不存在找尾节点的行为。只需要把头指针接到新节点即可。接这个过程的本质是改变头指针内存储的地址NULL,把它变为新节点的地址。这属于形参的改变影响实参

尾插的完整写法:
SList.h
#include <stdio.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
//下面是函数的声明,不可省略
void SListPrint(SLTNode* phead);
void SeqListPushBack(SLTNode** pphead, SLTDataType x);Test.c
#include "SList.h"
void TestSList1()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);//看解释1、2
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 4);
SListPrint(plist);
}
int main()
{
TestSList1();
return 0;
}1️⃣phead和plist的区别:都是指向第一个节点的地址,不过一个是形参一个是实参
2️⃣为什么传参时要用&plist,plist本身就等于地址,为什么不直接用plist?
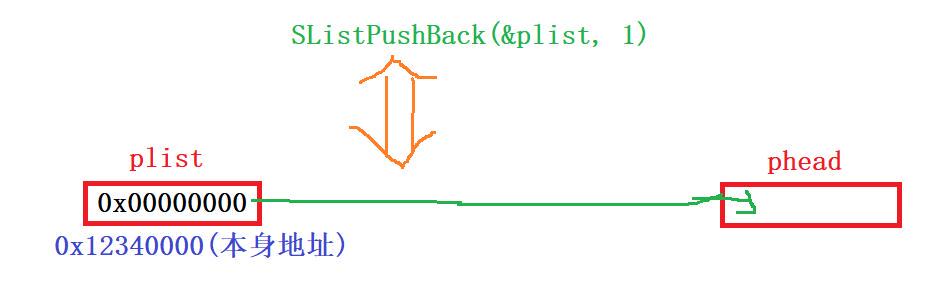
传的都不是plist本身地址,而是内容。phead的修改不会引起plist的改变,相当于就是传值调用
SList.c
#include <stdio.h>
#include "SList.h"
#include <stdlib.h>
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
}
void SListPushBack(SLTNode** pphead, SLTDataType x)//看解释1
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//找到尾节点
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
//把新节点的位置放入之前的尾节点的next中
tail->next = newnode;
}
}运行结果:

1️⃣回顾一下指针传参:

链表的头插:
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = *pphead;//pphead是它本身的地址,*pphead是它的内容:第一个节点的地址
*pphead = newnode;
}思路:
完整的头插:
SList.h
#pragma once
#include <stdio.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
void SListPrint(SLTNode* phead);
void SListPushBack(SLTNode** pphead, SLTDataType x);
void SListPushFront(SLTNode** pphead, SLTDataType x);Test.c
#include "SList.h"
void TestSList1()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 4);
SListPushFront(&plist, 0);
SListPrint(plist);
}
int main()
{
TestSList1();
return 0;
}SList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include "SList.h"
#include <stdlib.h>
//打印
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;//看解释1
while (cur != NULL)
{
printf("%d->", cur->data);//看解释2
cur = cur->next;//看解释3
}
printf("NULL\n");//为了把链表最终指向NULL这一情况表现出来。没有它输出就没有NULL
}
//尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
if (*pphead == NULL)
{
*pphead = newnode;
}//看解释1
else
{
//找到尾节点
SLTNode* tail = *pphead;//看解释4
while (tail->next != NULL)//看解释3
{
tail = tail->next;
}//看解释4
//把新节点的位置放入之前的尾节点的next中
tail->next = newnode;
}
}
//头插
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = *pphead;
*pphead = newnode;
}运行结果:

因为每次插的时候,都要创建一次新节点。所以干脆写一个创建新节点的函数:
//创建节点
SLTNode* BuyListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)//空间开辟失败
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}//看解释1
else
{
//找到尾节点
SLTNode* tail = *pphead;//看解释4
while (tail->next != NULL)//看解释3
{
tail = tail->next;
}//看解释4
//把新节点的位置放入之前的尾节点的next中
tail->next = newnode;
}
}链表的尾删:
错误写法:
void SListPopBack(SLTNode** pphead)//看解释1
{
SLTNode* tail = *pphead;
while (tail->next)//看解释2
{
tail = tail->next;
}
free(tail);//看解释3
tail = NULL;//看解释4
}1️⃣为什么尾删也需要用到二级指针,难道要该plist的内容吗?
对滴,当尾删到极限,即把链表全删完时。确实要把plist的next改为NULL
2️⃣while(tail->next)是个啥玩意?
while(tail->next)等价于while(tail->next != NULL)。NULl就等价于0,非0就是真。
指针,整型这些都可以作为循环判定依据
3️⃣free(tail)是什么意思?
free函数的作用是让系统回收括号内地址对应的空间,tail现在等于尾节点的空间地址,所以free(tail)就是系统回收尾节点空间或者说释放尾节点的空间
4️⃣tail = NULL是什么意思?
把尾节点置空
5️⃣为什么这个代码错了?
尾节点被释放置空了,然而尾节点前一个节点的next还指向已经被释放空间的尾节点,这就是一个经典的指向野指针问题。正确的做法是补充一个:把尾节点的前一个节点的next置空
改进写法--找尾节点的前一个节点:
方法一:
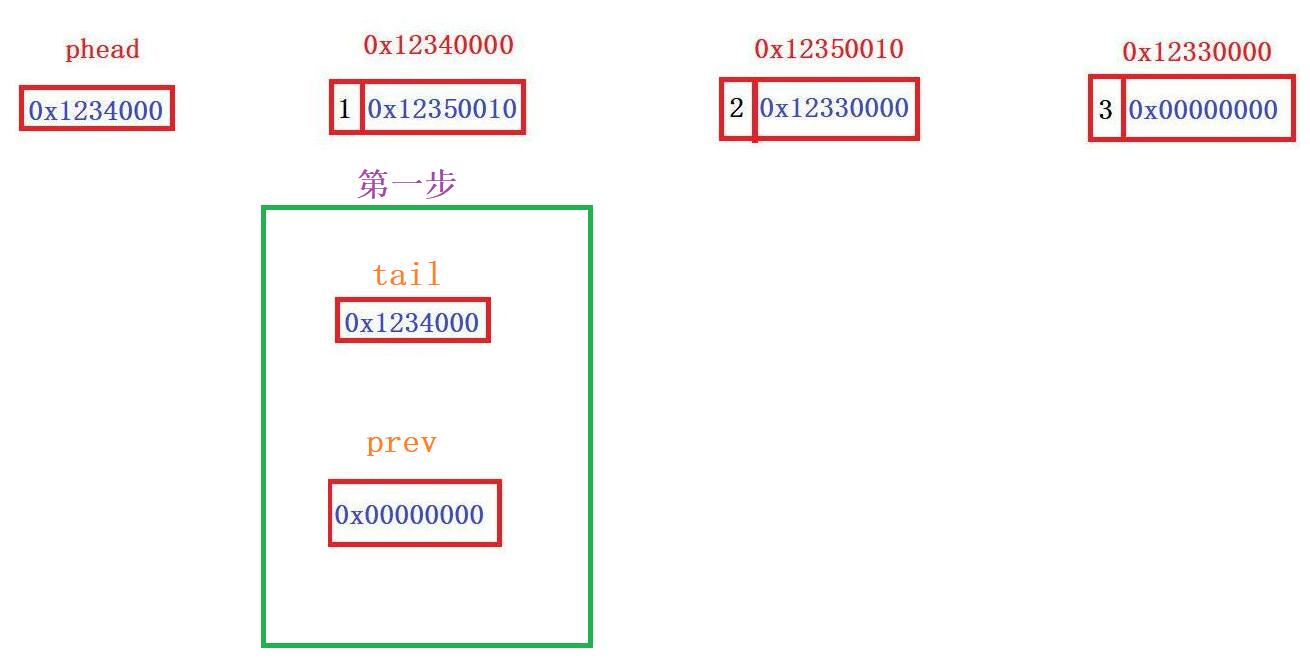
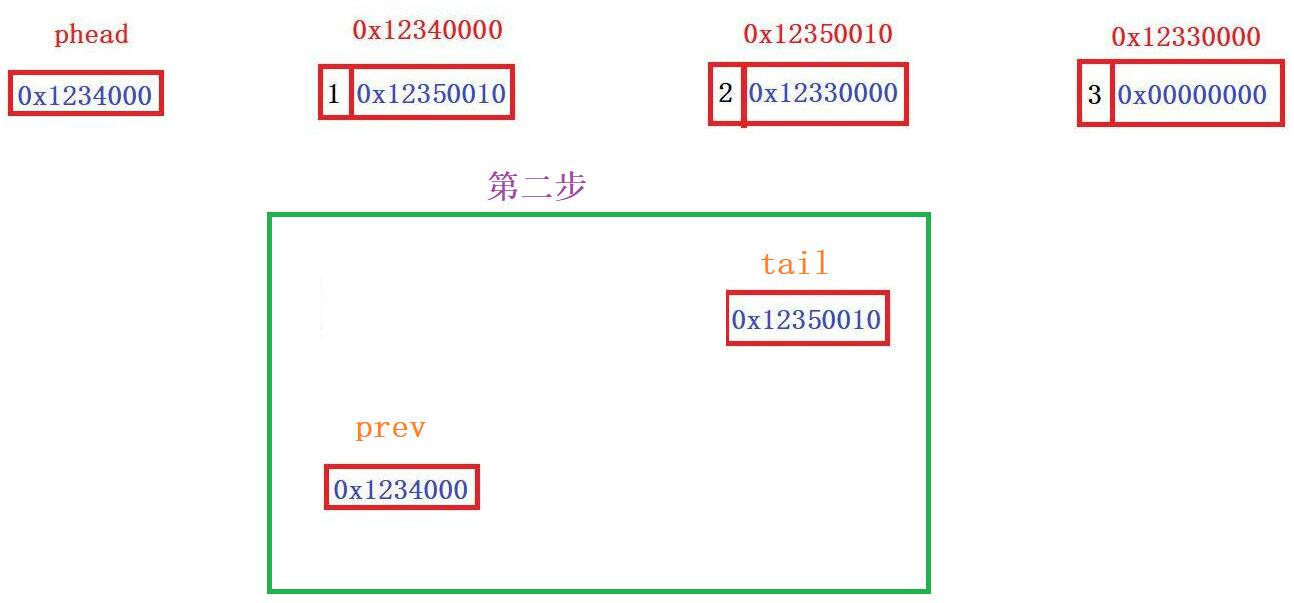
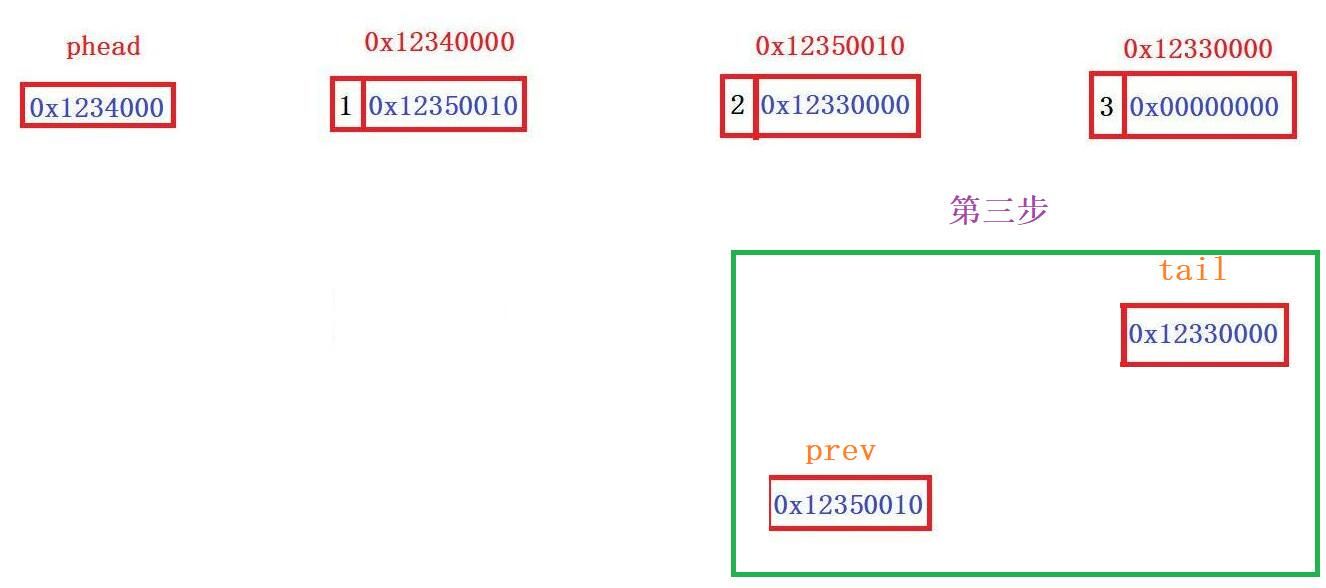
void SListPopBack(SLTNode** pphead)//看解释1
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
//找尾节点及其前一个节点
while (tail->next)
{
prev = tail;//把判定不是尾节点的地址将prev覆盖,确保prev总是在tail前一个节点
tail = tail->next;
}
//找到了,接下来把尾节点删掉,前一个节点prev的next接NULL
free(tail);
tail = NULL;
prev->next = NULL;//把尾节点的前一个节点置空变为尾节点
}1️⃣思路:
经while循环判断,第三步的tail指向尾节点,故此时的prev指向尾节点的前一个节点
方法二:
void SListPopBack(SLTNode** pphead)//看解释1
{
SLTNode* tail = *pphead;
while (tail->next->next)//此时的tail是倒数第三个节点
{
tail = tail->next;//此时的tail是倒数第二个节点
}
free(tail->next);//tail->next对应尾节点地址
tail->next = NULL;
}但是,上述两种写法依然有问题:当链表只有5个节点而我们要删除6个节点的时候,程序运行就会崩溃。因为发生了上述访问野指针的问题。
怎么发生的?分析一波:
当把最后一个节点回收置空后,plist依然存的是已经回收释放的第一个节点的地址。后续打印时,plist会访问该节点,造成访问野指针。故当出现尾删全部节点时,我们要把plist存放的地址置空。
void SListPopBack(SLTNode** pphead)//看解释1
{
/*//温柔一点
if (*pphead == NULL)
{
return;
}*/
//粗暴一点
assert(*pphead != NULL);
if ((*pphead)->next==NULL)
{
free(*pphead);//释放第一个节点的空间
*pphead = NULL;
}
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}思路:
当链表有两个及以上的节点时,走else--while依次删尾节点
当链表仅一个节点时,走if释放该节点,并把pphead置空
尾删的完整写法:
SList.h
#pragma once
#include <stdio.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
void SListPrint(SLTNode* phead);
void SListPushBack(SLTNode** pphead, SLTDataType x);
void SListPushFront(SLTNode** pphead, SLTDataType x);
void SListPopBack(SLTNode** pphead);Test.c
#include "SList.h"
void TestSList1()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 4);
SListPushFront(&plist, 0);
SListPrint(plist);
SListPopBack(&plist);
SListPopBack(&plist);
SListPopBack(&plist);
SListPopBack(&plist);
SListPopBack(&plist);
SListPrint(plist);
}
int main()
{
TestSList1();
return 0;
}SList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include "SList.h"
#include <stdlib.h>
#include <assert.h>
//打印
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
//创建节点
SLTNode* BuyListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//找到尾节点
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
//把新节点的位置放入之前的尾节点的next中
tail->next = newnode;
}
}
//头插
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
//尾删
void SListPopBack(SLTNode** pphead)
{
/*//温柔一点
if (*pphead == NULL)
{
return;
}*/
//粗暴一点
assert(*pphead != NULL);
if ((*pphead)->next==NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}链表的头删:
错误的代码:
void SListPopFront(SLTNode** pphead)
{
assert(*pphead);//假如链表为空,则删个屁!看解释1
SLTNode* FirstNode = *pphead->next;//看解释2
free(*pphead);//free(第一个节点地址),即把第一个节点空间释放
*pphead = FirstNode;
}1️⃣必须有它的原因:
该代码等价于assert(*pphead!=NULL),即假如pphead存储的是空指针,那么FirstNode->next会发生解引用空指针,引发警告。有两种情况pphead存储的是空指针而不是第一个节点的地址:
我多次头删,把链表都删没了,只剩下一个NULL覆盖pphead
本来链表就没有,pphead存的就是NULL
2️⃣该行代码等价于:
SLTNode* FirstNode = *pphead; //FirstNode是新的第一个节点
=>引入指针变量FirstNode,把第一个节点的地址传给它
*pphead = FirstNode->next;
=>用第二个节点的地址覆盖pphead的第一个节点地址
链表的查找:
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)//遍历链表
{
if (cur->data == x)
{
return cur;
}//找到了,返回该节点地址
else
{
cur = cur->next;
}//该节点不是我们要找的节点,往下一个节点判断
}
return NULL;//没找到,返回空指针
}这份代码有个缺陷:万一我要找的数字与多个节点的data都相等怎么办?
void TestSList2()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 2);
SListPushBack(&plist, 4);
SLTNode* pos1 = SListFind(plist, 2);//找到data为2的节点的地址
SLTNode* pos2 = NULL;
if (pos1 != NULL)
{
pos2 = SListFind(pos1->next, 2);//看解释1
}
}1️⃣找第二个对应相等的节点的地址肯定不能从头开始,不然又要得到pos1的地址。所以我们从pos1的下一个地址开始查找
这份代码也有个缺陷,那就是我要已知链表中有多少个对应相等的节点才能这么写。那有没有一种方法,就是我不知道链表中有多少个对应相等的节点,但是可以全部找出来?
void TestSList2()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 2);
SListPushBack(&plist, 4);
SListPushBack(&plist, 2);
SListPushBack(&plist, 2);
SListPushBack(&plist, 4);
SLTNode* pos = SListFind(plist, 2);
int i = 1;
while (pos)
{
printf("第%d个pos节点:%p->%d\n", i++, pos, pos->data);
pos = SListFind(pos->next, 2);
}
}运行结果:

链表的修改:
void TestSList2()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 2);
SListPushBack(&plist, 4);
SListPushBack(&plist, 2);
SListPushBack(&plist, 2);
SListPushBack(&plist, 4);
SLTNode* pos = SListFind(plist, 2);
int i = 1;
while (pos)
{
pos->data=30;//把2改为30
pos=SListFind(pos->next,2);
}//把链表中data为2的节点都改为data为30
}链表的插入--前插:
错误的写法:
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
//创建新节点
SLTNode* newnode = BuyListNode(x);
//找到pos的前一个节点
SLTNode* posPrev = *pphead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
posPrev->next = newnode;//用插入的节点的地址把前一个节点内pos的地址覆盖了
newnode->next = pos;//把pos的地址传给插入的节点的next
}
SLTNode* pos = SListFind(plist, 3);
if (pos)
{
SListInsert(&plist, pos, 30);//在data为3的节点前插入data为30的新节点
}
SListPrint(plist);该代码错误的原因是:当我们要在第一个节点前插入一个新节点时,我们会发现popPrev没有next。即头插失败
正确的写法:
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
//创建新节点
SLTNode* newnode = BuyListNode(x);
if (*pphead == pos)
{
newnode->next = *pphead;
*pphead = newnode;
}//头插写法
else
{
//找到pos的前一个节点
SLTNode* posPrev = *pphead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
posPrev->next = newnode;
newnode->next = pos;
}
}
SLTNode* pos = SListFind(plist, 3);
if (pos)
{
SlistInsert(&plist, pos, 30);
}
SListPrint(plist);前插的改进:让每个符合条件的节点前都插入
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
//创建新节点
SLTNode* newnode = BuyListNode(x);
if (*pphead == pos)
{
newnode->next = *pphead;
*pphead = newnode;
}//头插写法
else
{
//找到pos的前一个节点
SLTNode* posPrev = *pphead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
posPrev->next = newnode;
newnode->next = pos;
}
}
SLTNode* pos = SListFind(plist, 3);
while (pos)
{
SListInsert(&plist, pos, 30);
pos = SListFind(pos->next, 2);
}
SListPrint(plist);运行结果:每个2前面都插入了30

单链表的缺陷还是很多的,单纯的单链表增删查找意义不大。之所以要学,主要是以下几点:
很多OJ题考察的都是单链表
单链表更多的是作更复杂数据结构的子结构。比如哈希桶、邻接桶
链表的插入--后插
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
SLTNode* newnode = BuyListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}链表的删除:
void SListErase(SLTNode** pphead, SLTNode* pos)
{
//头删
if (*pphead == pos)
{
/*
*pphead = pos->next;
free(pos);
*/
SListPopFront(pphead);
}
//中间删
else
{
SLTNode* prev = NULL;
//找到pos前一个节点prev
while (prev->next != pos)
{
prev = prev->next;
}
//pos节点的两侧节点相连
prev->next = pos->next;
//删除节点
free(pos);
pos = NULL;//有没有这步无所谓
}
}链表的删除--删除pos后一个节点
void SListEraseAfter(SLTNode* pos)
{
assert(pos->next);
SLTNode* Next = pos->next;
pos->next = Next->next;
free(Next);
Next = NULL;//有没有这步无所谓
}注:以后写函数,凡是不为空的,都可以尝试加个assert
链表的销毁
错误的代码:
void SListDestory(SLTNode* pphead)
{
assert(pphead);
free(pphead);
}错误的原因:链表不是顺序表,顺序表是数组,申请一块地址,后续操作是对那一块地址的空间增减。释放该地址就释放了整个空间。而链表是内存中一块块四处分别的空间的组成,要想销毁链表,就得把每块空间都一一销毁了
正确的代码:
void SListDestory(SLTNode* pphead)
{
assert(pphead);
SLTNode* cur=*pphead;
while(cur)
{
SLTNode* Next=cur->next;
free(cur);
cur=Next;
}
*pphead=NULL;
}链表面试题:
面试题一:移除链表元素
题目描述:
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* prev=NULL,* cur=head;//看解释1
while(cur)//看解释2
{
if(cur->val==val)
{
//头删,看case2
if(cur==head)
{
head=cur->next;
free(cur);
cur=head;
}
//中间删除,看case1
else
{
prev->next=cur->next;
free(cur);
cur=prev->next;//把cur移向下一个节点,继续查找删除
}//删除
}
else
{
prev=cur;
cur=cur->next;
}//往后挪
}
return head;//看解释3
}思路:
case 1:头节点不符合删除条件
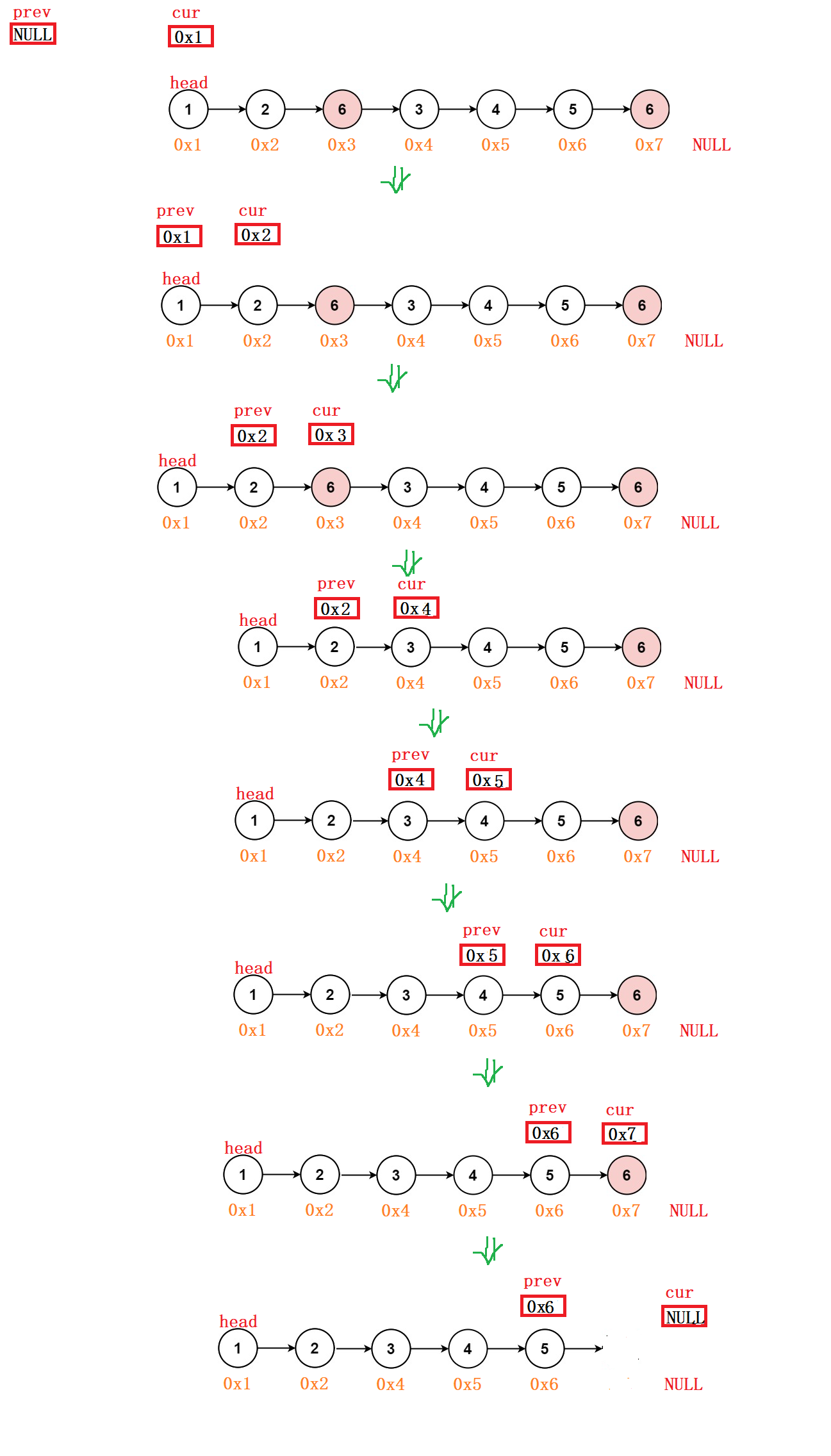
case 2:头节点符合删除条件,按case的删除处理不可以。因为最终我们要return head。head都销毁了,就是野指针了
解决方法:我们不销毁head,我们把head后的下一个节点地址传给head,再把存有head地址的cur给销毁了。最后把head内存储的第二个节点地址传给cur。如此一来,返回head时,链表就是从第二个节点开始,也就达到了删除的目的
1️⃣
创建两个指针,cur找和val相等的节点,prev找cur的前一个节点。
cur从head开始找,故首先存储head头节点的地址。prev要比head慢一步,故先存储NULL,避免成为野指针。
2️⃣循环结束意味着把链表中所有符合cur->val==val这一条件的节点都删除了,故肯定要遍历完链表,故结束标志是cur==NULL。故写成while(cur->next)就错了,因为当尾节点符合删除要求时,一下子while循环就结束了,根本来不及处理
3️⃣为什么是返回head?
因为函数类型是struct ListNode*,对应返回地址。而head就是头节点的地址
面试题二:反转链表
题目描述:给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
思路1:创建一个空的新链表,遍历原链表,将原链表的节点依次头插进新链表。
由于此题思路并不复杂,所以这里没有选择作图。
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* newHead = NULL;
struct ListNode* cur = head;
while (cur)
{
//先存一份next避免当前节点头插进新链表后无法继续遍历
struct ListNode* next = cur->next;
cur->next = newHead;
newHead = cur;
cur = next;
}
return newHead;
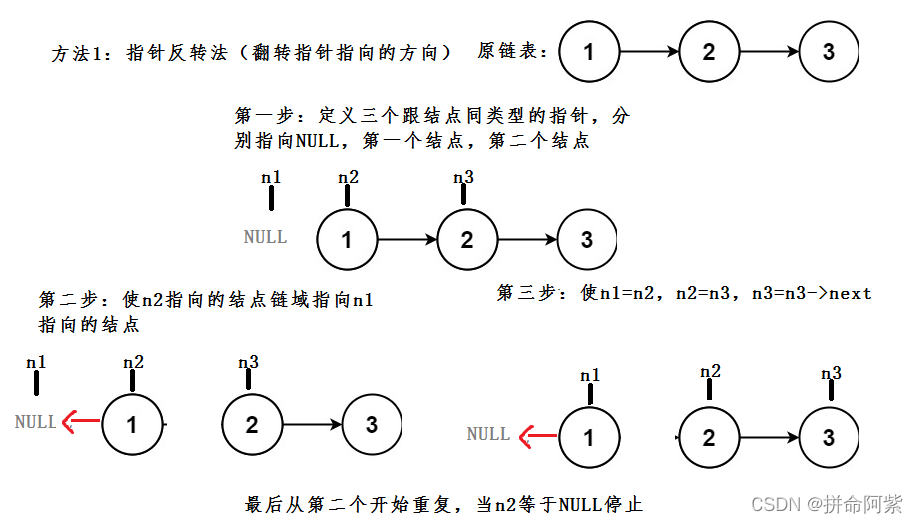
}思路2:翻转指针方向
逻辑过程:
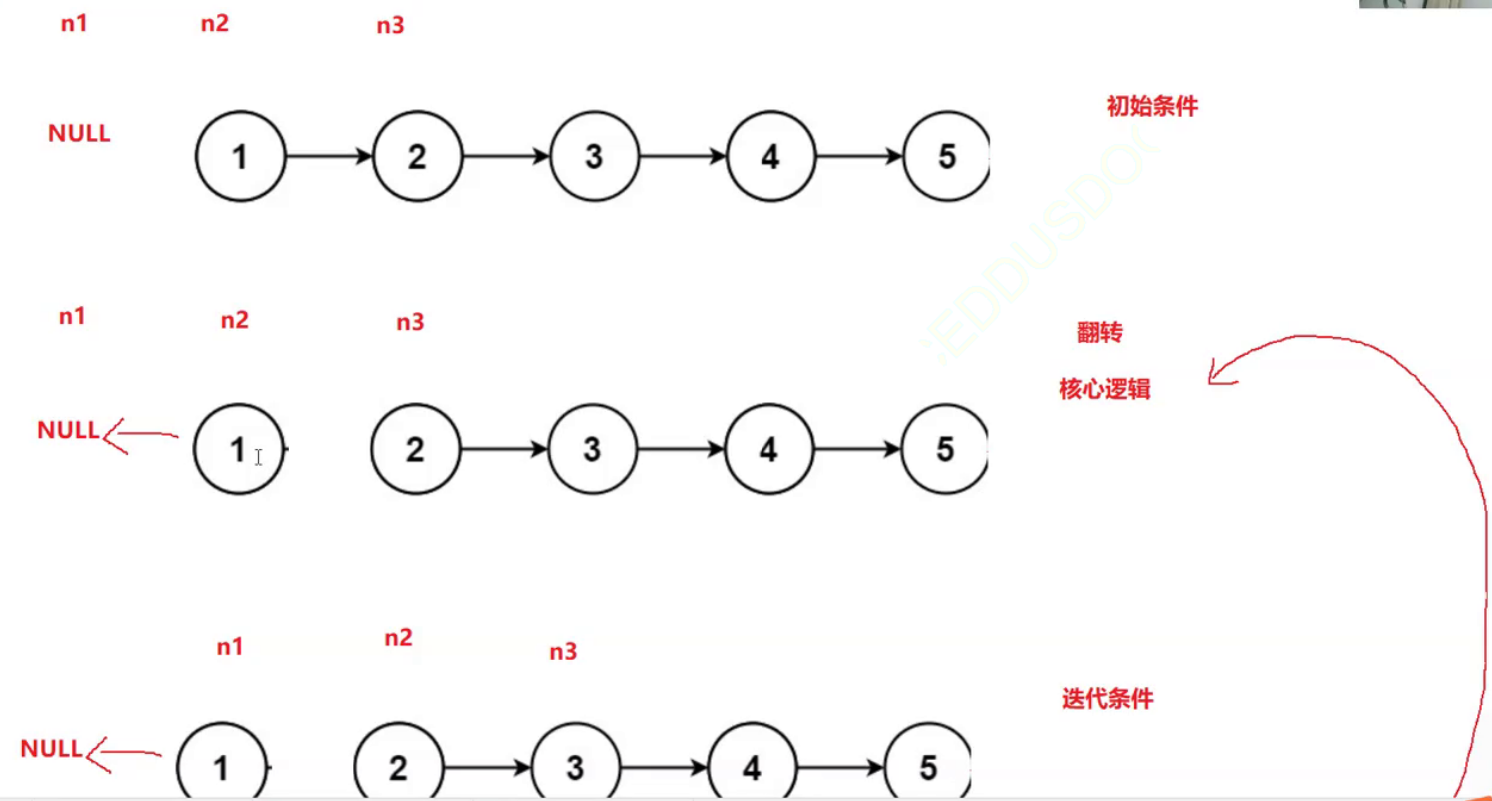
即:
疑问1:为什么不是n3==NULL停止循环了???
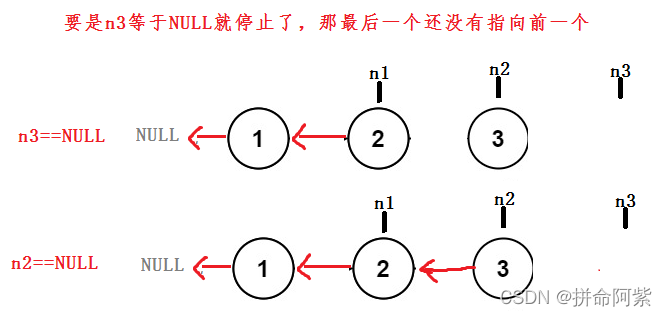
疑问2:要是链表为空了
答:要是链表为空了,直接返回NULL
注:重复的过程一般是用循环解决
循环三要素:初始值,迭代过程,结束条件
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
if(head==NULL)
return NULL;
//初始化
struct ListNode* n1 = NULL,*n2 = head,*n3 = n2->next;
//结束条件
while(n2)
{
//翻转
n2->next = n1;
//迭代过程(重复过程),即迭代往后走
n1 = n2;
n2 = n3;
if(n3)//最后一步时,n3为空
n3 = n3->next;
}
return n1;
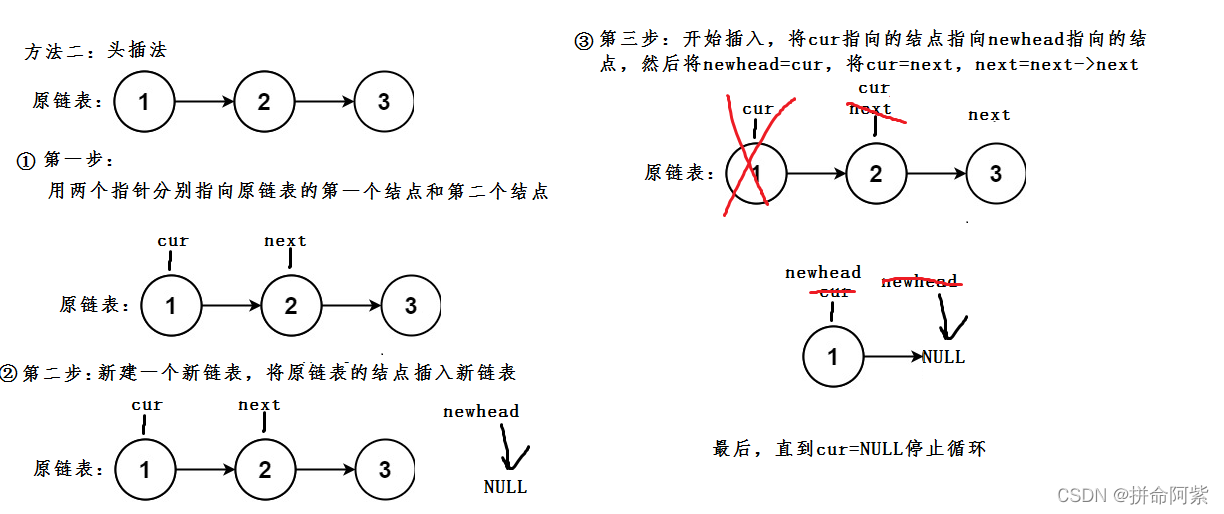
} 思路3:头插法,取原链表中的节点,头插到newhead中
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
if(head==NULL)
{
return NULL;
}
struct ListNode *cur = head,*next = cur->next;
struct ListNode* newhead = NULL;
while(cur)
{
//头插
cur->next = newhead;
newhead = cur;
cur = next;
if(next)
next = next->next;
}
return newhead;
}面试题三:链表的中间结点
题目描述:
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
思路1:
先遍历数组,得到链表节点数count
利用(count/2)+1得到再次遍历数组时,遍历的第几个对应中间节点
再次遍历链表,直到遍历至(count/2)+1
时间复杂度:O(N)
分析:先遍历链表,得到count,时间复杂度为O(N)。你再次遍历,得到中间节点,时间复杂度为O(N/2),总的时间复杂度为O(3N/2),去掉系数后,为O(N)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* middleNode(struct ListNode* head)
{
//遍历链表,得到节点总数
struct ListNode* cur=head;
int count=0;
while(cur->next)
{
cur=cur->next;
count++;
}
//遍历得到的节点数会比实际数少1
count++;
//节点总数得到了,现在得到再一次需要遍历的个数
int times=(count/2)+1;
//重置cur的指向,让它从头开始
cur=head;
//接下来遍历
int i=0;
while(i<times-1)
{
cur=cur->next;
i++;
}
//此时得到的cur便是中间节点的地址
return cur;
}思路2:快慢指针法
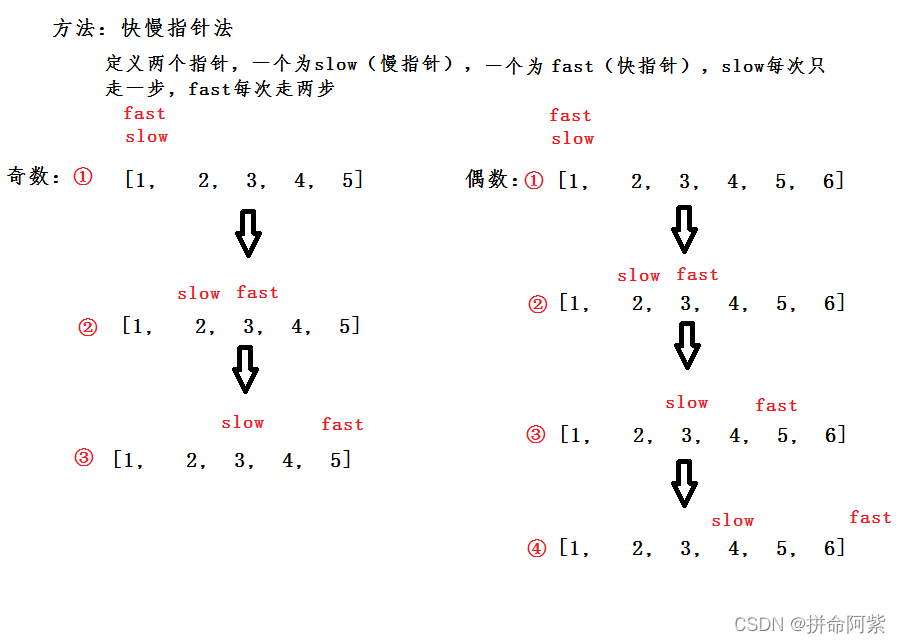
大家从上面的思路中也可以看出它也是迭代的过程,初始条件是slow,fast都指向第一个结点,迭代过程,slow走一步,fast走两步,结束条件fast->next,fast只要有一个为空就结束。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* middleNode(struct ListNode* head){
struct ListNode *slow = head,*fast = head;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}面试题四:链表中倒数第k个结点
题目描述:输入一个链表,输出该链表中倒数第k个结点。
思路:快慢指针法
fast先走k步
slow再和fast一起走,fast==NULL时,slow就是倒数第k个

struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
struct ListNode* fast,*slow;
fast=slow=pListHead;
//while(--k)// k-1步
while(k--)//k步
{
//1.传过来的是空链表
//2.k>=结点数
if(fast==NULL)
{
return NULL;
}
fast=fast->next;
}
while(fast)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}
思路2:
先遍历数组,得到链表节点数count
利用count-k+1得到再次遍历数组时,遍历的第几个对应倒数第k个节点
再次遍历链表,直到遍历至count-k+1,对应倒数第k个节点的地址
不完善的写法:
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
#include <assert.h>
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
//遍历链表,得到节点总数
struct ListNode* cur=pListHead;
int count=0;
while(cur->next)
{
cur=cur->next;
count++;
}
//遍历得到的节点数会比实际数少1
count++;
assert(k<=count);//看解释1
//倒数第k个节点对应的times为count-k+1
int times=count-k+1;
//重置cur的指向,让它从头开始
cur=pListHead;
//接下来遍历
int i=0;
while(i<times-1)
{
cur=cur->next;
i++;
}
return cur;
}运行结果:
1️⃣提交后,我们会发现就是当k大于节点数时,我们这个代码就处理不了了。于是就想到用assert。但是:
注:OJ题不要用断言!!!😩
因为这样做是把问题抛给Leetcode,它才不会帮你解决
注:如果遇到运行失败时,可以在代码中加入printf()函数,在自测输入那里输入特例观察
2️⃣错误的原因是不完善,对k大于节点数已经链表为空的情况没有补充到解决方案
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
/**
*
* @param pListHead ListNode类
* @param k int整型
* @return ListNode类
*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
//遍历链表,得到节点总数
struct ListNode* cur=pListHead;
int count=0;
if(cur==NULL)//针对链表为空的情况
{
return NULL;
}
else
{
while(cur->next)
{
cur=cur->next;
count++;
}
//遍历得到的节点数会比实际数少1
count++;
if(k>count)//针对k>count,输出为空的情况
{
return NULL;
}
else
{
//倒数第k个节点对应的times为count-k+1
int times=count-k+1;
//重置cur的指向,让它从头开始
cur=pListHead;
//接下来遍历
int i=0;
while(i<times-1)
{
cur=cur->next;
i++;
}
return cur;
}
}
}面试题五: 合并两个有序链表
题目描述:
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
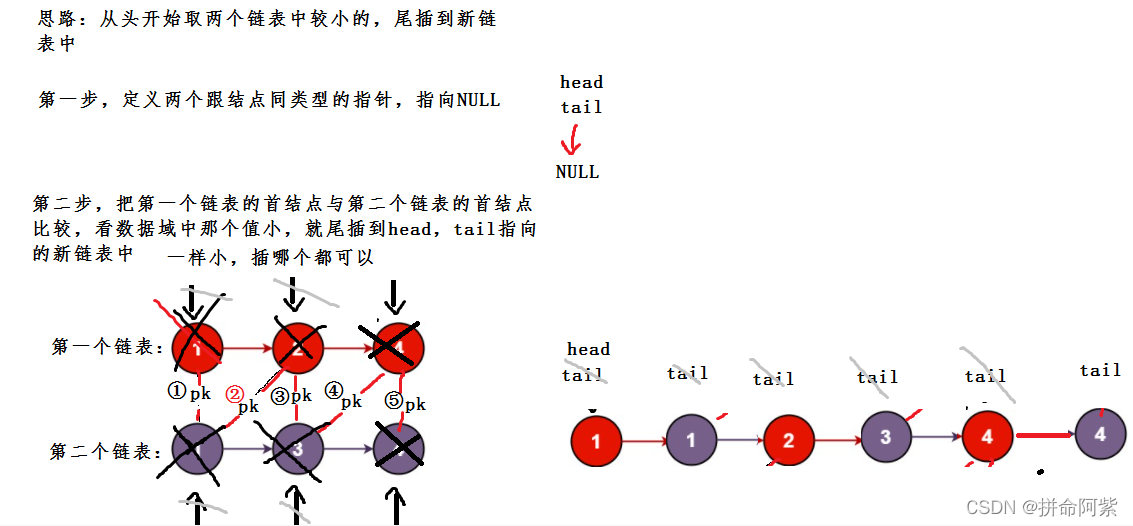
思路:类似于合并两个有序数组,创建两个指针分别指向两个链表,将两个指针指向的val分别进行比较,取小的尾插到另一个大的节点后面,并且创建一个尾指针来维护新链表的末尾
考虑链表为空的情况:可能链表一为空链表二不为空,也可能链表二为空链表一不为空,也可能两者都为空
以示例1为例分析:
第一步:先取一个较小的节点做新链表的第一个节点,方便后面尾插(前提是两指针不为空)
假设当cur2指向的元素大于cur1指向的元素时,将cur1所指元素尾插至新链表后,否则将cur2所指元素尾插至新链表后
cur1指向红色链表,cur2指向紫色链表,此时cur1指向的1等于cur2指向的1,所以将cur2指向的1作为头部将cur1指向的1尾插至cur2指向的1之后
同时让新链表的头部phead指向紫色链表的节点1,方便之后返回结果

分离得到:
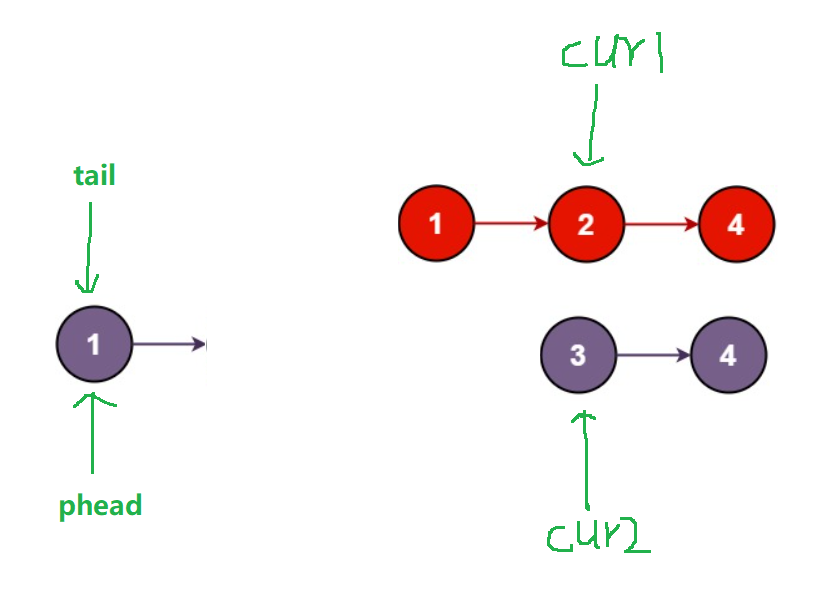
要设置指针保存指向紫色链表3的位置,才能再尾插,也就是使 cur2 = cur2->next
我们发现实际上我们并没有创建新链表,而是将其中一个作为新链表
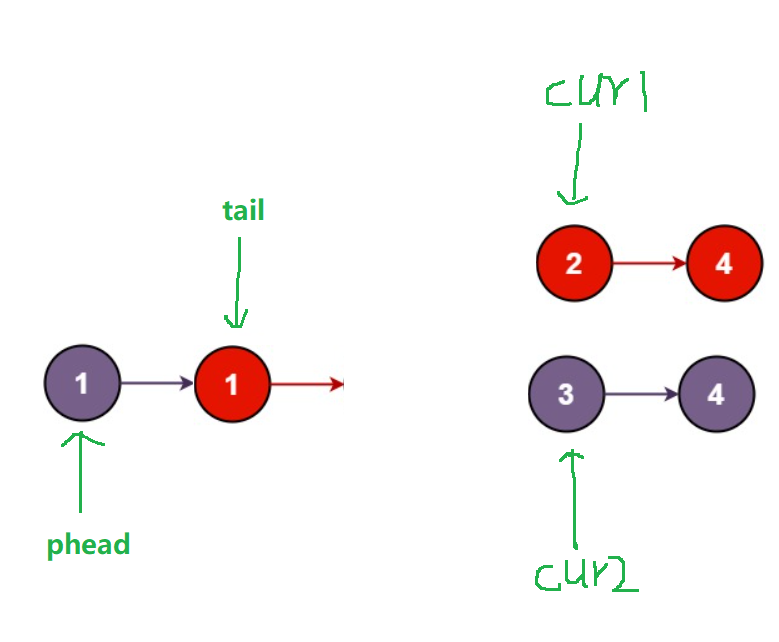
第二步:比较cur1指向1与cur2指向的3,1<3,所以将节点1尾插至新链表的后面,并且使cu1 = cur1->next,tail此时也指向红色节点1

得到结果:
第三步:比较cur1指向2与cur2指向的3,2<3,所以将节点2尾插至新链表的后面,并且使cu1 = cur1->next,tail此时也指向红色节点2
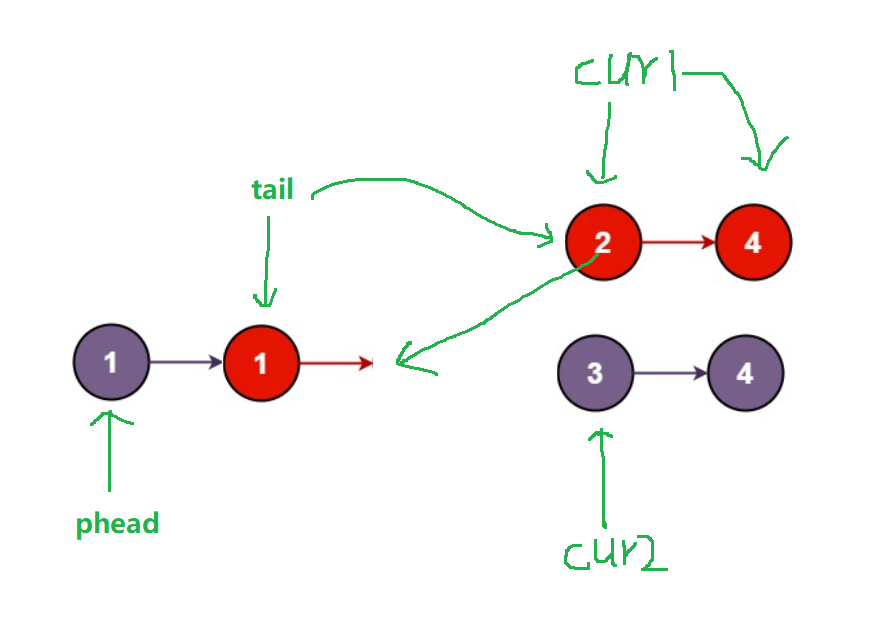
得到结果:

第四步:比较cur1指向4与cur2指向的3,3<4,所以将节点3尾插至新链表的后面,并且使cu2 = cur2->next,tail此时也指向紫色节点3
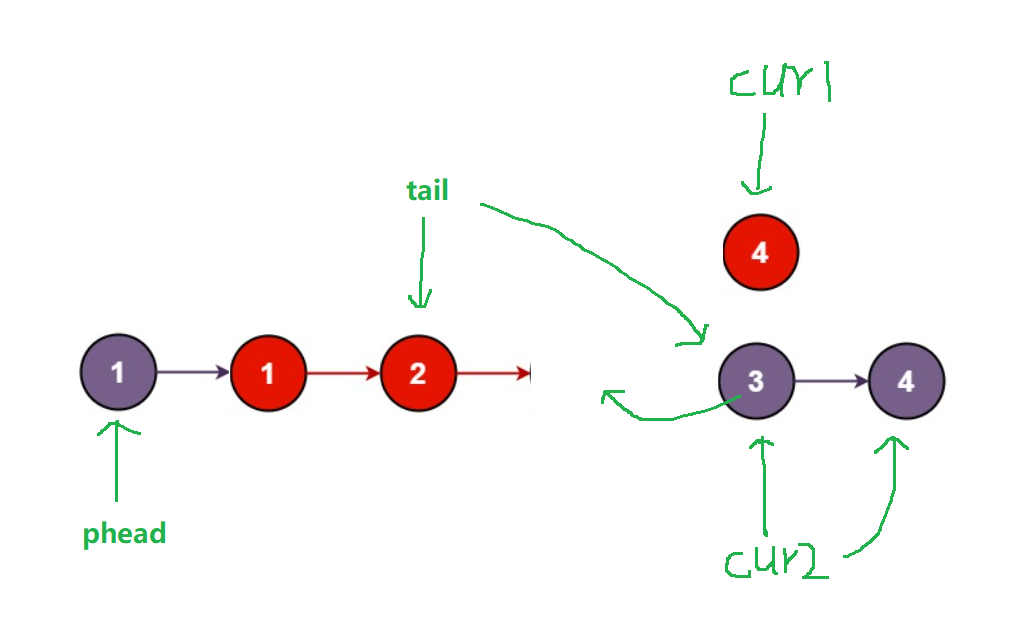
得到结果:

第五步:比较cur1指向4与cur2指向的4,cur2指向的4不大于cur1指向的4,所以将节点4尾插至新链表的后面,并且使cu2 = cur2->next,tail此时也指向紫色节点4
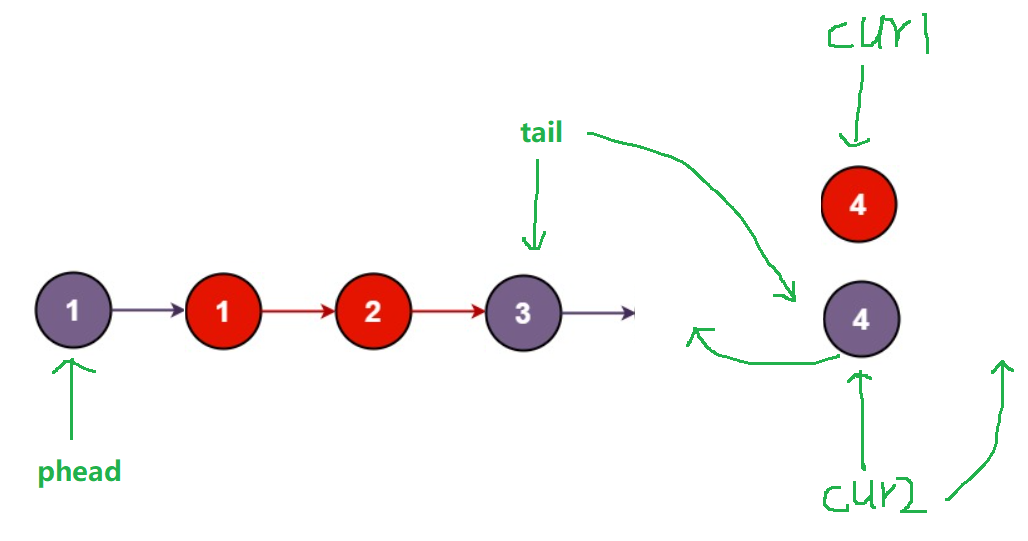
得到结果:
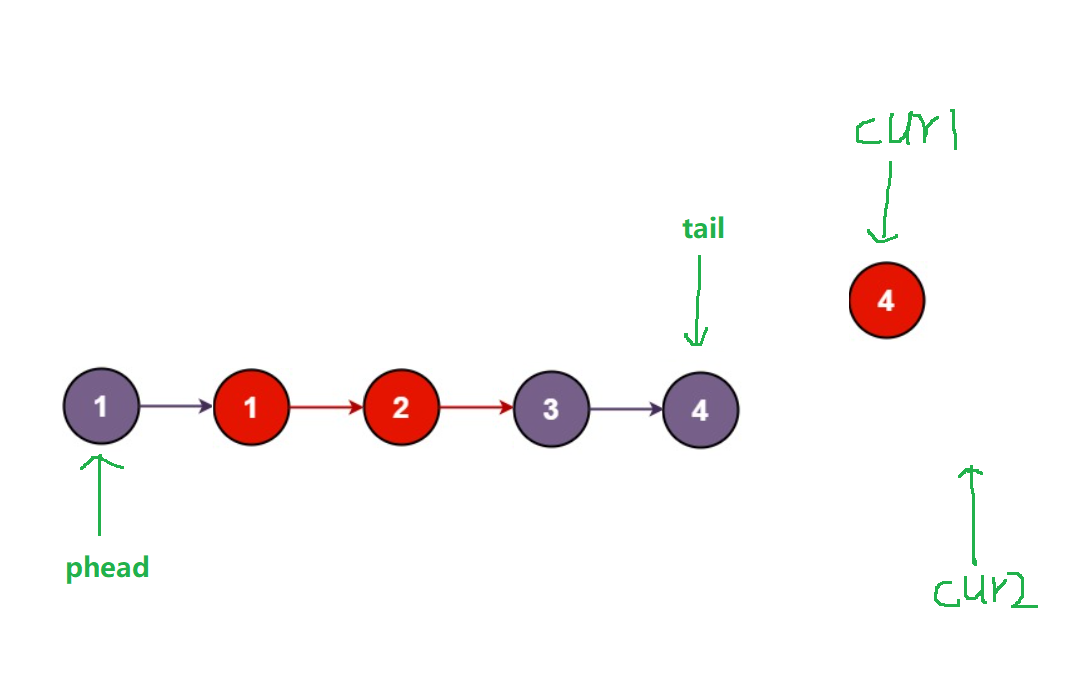
第六步:cur2已经指向空了,再将另一个链表剩下的节点插至新链表后即可,注意,这里只需要连接一次,因为圣血的节点本就是相连的
代码(只实现函数):
上述分析中的cur1,cur2在代码中是l1,l2
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
if(list1==NULL)
{
return list2;
}
if(list2==NULL)
{
return list1;
}
struct ListNode *head = NULL,*tail = NULL;
while(list1 != NULL && list2 != NULL)
{
if(list1->val < list2->val)
{
if(tail == NULL)
{
head = tail = list1;
}
else
{
tail->next = list1;
tail = tail->next;
}
list1=list1->next;
}
else
{
if(tail == NULL)
{
head = tail = list2;
}
else
{
tail->next = list2;
tail=tail->next;
}
list2=list2->next;
}
}
//list1还没结束
if(list1)
{
tail->next = list1;
}
//list2还没结束
if(list2)
{
tail->next = list2;
}
return head;
} 还有一种哨兵解法,就是创建一个新节点,同样也是取小的尾插至新节点之后,省去了判断两个链表是否为空的情况,但返回前需要free掉该空间
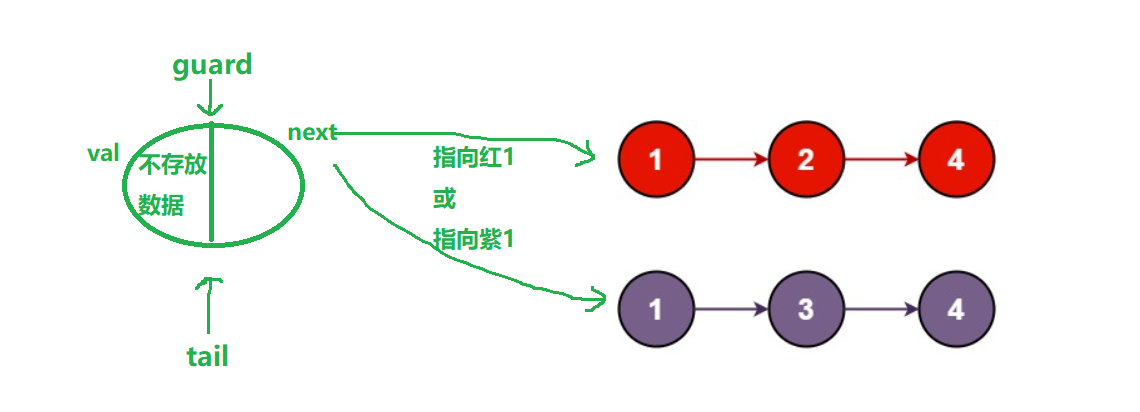
struct ListNode {
int val;
struct ListNode* next;
};
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2) {
//创建哨兵
struct ListNode* guard = (struct ListNode*)malloc(sizeof(struct ListNode));
//维护新空间的尾部
struct ListNode* tail = guard;
while (l1 != NULL && l2 != NULL)
{
if (l2->val > l1->val)
{
tail->next = l1;
tail = tail->next;
l1 = l1->next;
}
else
{
tail->next = l2;
tail = tail->next;
l2 = l2->next;
}
}
//拷贝剩下的节点
if (l2 == NULL)
{
tail->next = l1;
}
else
{
tail->next = l2;
}
//释放哨兵空间
struct ListNode* tmp = guard->next;//记得是存放guard->next
free(guard);
guard = NULL;
return tmp;
}
面试题六:链表分割
题目描述:现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
思路:
创建两条链表,小于x的放入小链表,大于等于x的放入大链表,然后通过尾结点指针将两条链表合并起来。
1.判断极端条件,如果链表为空,既给定值也无法分割,直接返回空。
2.创建大链表bigger,存放所有大于等于x的结点。创建小链表samller,存放所有小于x的结点。但二者的指向都只是一个假结点是存放了一个无效值的头结点,从它们的next结点才开始存放旧链表中的值。因为这样可以更好的使尾指针进行运作。
3.因为需要搬运结点以及链接两链表,所以各自建立一个尾指针,作为搬运工,并初始化为各自头指针的指向。
4.创建当前结点cur,为循环判断条件,优先级最高,并初始化为链表首结点。
5.通过判断当前指针的有效性来决定是否继续执行循环逻辑。如果不为空,进行判定逻辑:
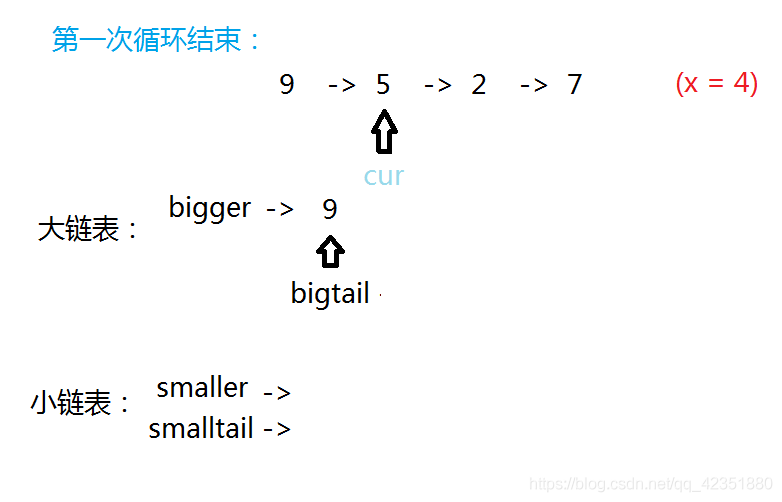
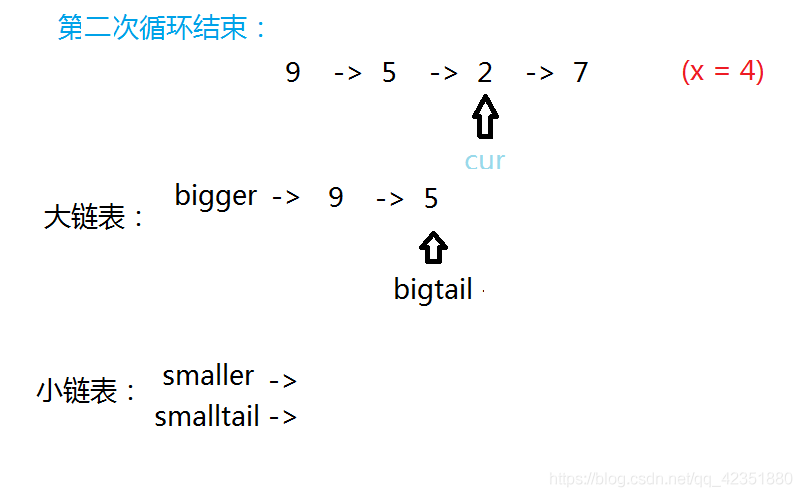
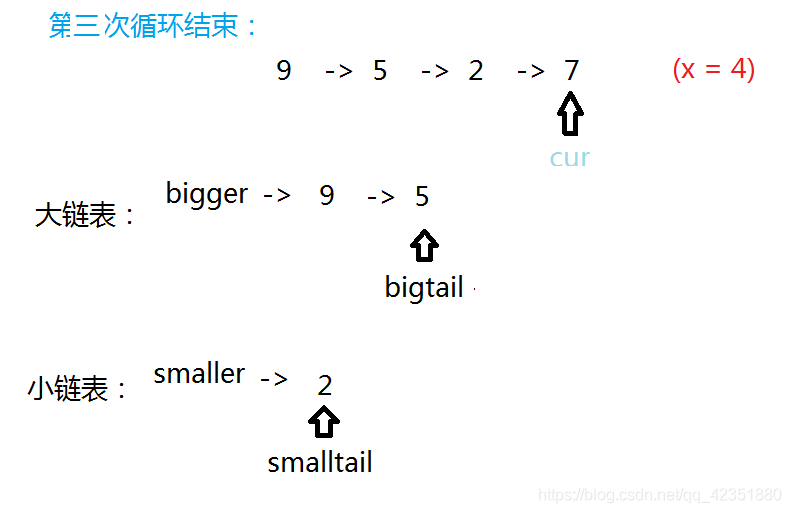
若当前结点值小于给定值,将它尾插入小链表,并更新小链表尾结点及当前指针的指向。
若当前结点值大于等于给定值,将它尾插入大链表,并更新大链表尾结点及当前指针的指向。
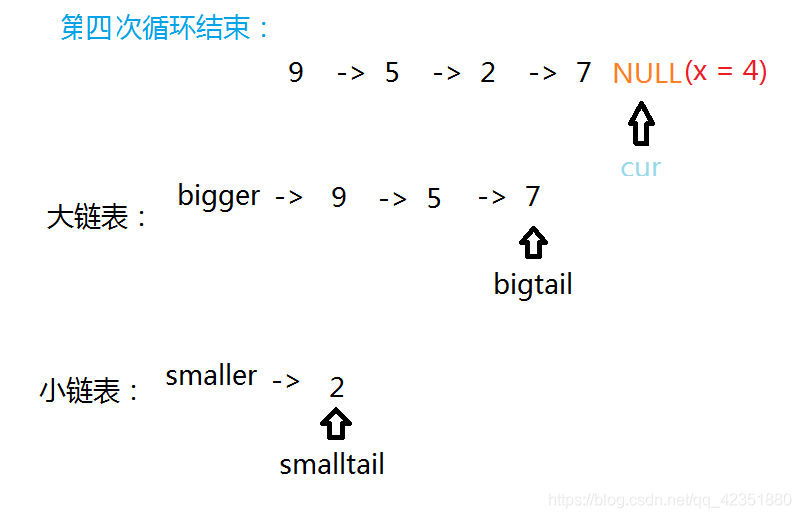
6.最后执行链接逻辑,手动将小链表的尾指针smalltail的next指向大链表的bigger的next结点。将大链表的尾结点置为NULL,保证链表的有限性。

7.最终忽略假结点,返回小链表的smaller的next结点即可。
struct ListNode* partition(ListNode* pHead, int x)
{
//搞两组链表,一组存储比x小的节点,一组存储比x大或等于的节点
struct ListNode* lessHead, *lessTail, *greaterHead, *greaterTail;
//开个哨兵位头节点,方便尾插
lessHead = lessTail = (struct ListNode*)malloc(sizeof(struct ListNode));
lessTail->next = NULL; //相当于lessTail->next=lessHead->next=NULL;
//同理:
greaterHead = greaterTail = (struct ListNode*)malloc(sizeof(struct ListNode));
greaterTail->next = NULL;
//新建指针cur,让它去遍历链表
struct ListNode* cur = pHead;
//遍历链表
while (cur)
{
//存储比x小的的节点的尾插
if (cur->val < x)
{
lessTail->next = cur; //cur对应的节点接在lessTail后面
lessTail = cur; //lessTail往后挪1
}
//存储>=x的节点的尾插
else
{
//同理
greaterHead->next = cur;
greaterHead = cur;
}
//无论遇到的节点大于小于还是等于x,cur都要往后挪1
cur = cur->next;
}
//把两个新链表连接起来,小于x的链表的尾节点接到>=x的链表的头节点前
lessTail->next = greaterHead->next;
//此时greatertail还连着lessTail,如果不解决,就会陷入死循环
greaterTail->next=NULL;
//回收销毁两个新链表前,要把连起来的两个链表的头节点位置存储起来
struct ListNode* newHead = lessHead->next;
//回收链表
free(lessHead);
free(greaterHead);
//置不置空无所谓,反正也没有访问它
return newHead;
}注:以后遇到代码运行失败,找不到原因。可以使用屏蔽法排除错误
面试题七:链表的回文结构
题目描述:
对于一个链表,请设计一个时间复杂度为O(n),额外空间复杂度为O(1)的算法,判断其是否为回文结构。
给定一个链表的头指针A,请返回一个bool值,代表其是否为回文结构。保证链表长度小于等于900。
解决方案:
1、采用头插法将链表逆置,将整个链表反转过来,判断是否与原链表一样即可
2、升级版:既然它要是回文结构,我们只需要将链表的一半逆置即可,采用双指针遍历的方式,一个从前往后,一个从后往前,同时遍历并比较链表元素是否相等即可。
在这里我来说一下第二种方法的具体思路
(1) 第一步,先求出链表的总长度
(2) 第二步,找到中间节点
(3) 第三步,逆置链表后半部分节点
(4) 第四步,判断链表是否是回文结构
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
//得到中间节点地址的函数
struct ListNode* middleNode(struct ListNode* head) {
struct ListNode* slow = head, *fast = head;
while (fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
}
return slow;//返回中间节点
}
//反转链表
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode* newHead = NULL;
struct ListNode* cur = head;
while (cur) {
//先存一份next避免当前节点头插进新链表后无法继续遍历
struct ListNode* next = cur->next;
cur->next = newHead;
newHead = cur;
cur = next;
}
return newHead;
}
class PalindromeList {
public:
bool chkPalindrome(ListNode* A)
{
// write code here
struct ListNode* mid = middleNode(A); //得到中间节点
struct ListNode* rHead =reverseList(mid);//将mid之后的链表反转
//创建两个指针,分别指向链表两部分的头节点,为遍历做准备
struct ListNode*curA=A;
struct ListNode*curR=rHead;
//遍历
while(curA&&curR)//结束条件是curA或curR其中之一走到next为NULL
{
if(curA->val!=curR->val)
{
return false;
}
else
{
curA=curA->next;
curR=curR->next;
}
}
return true;
}
};注:牛客可以在规定函数外写函数。
面试题八:相交链表
题目描述:
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
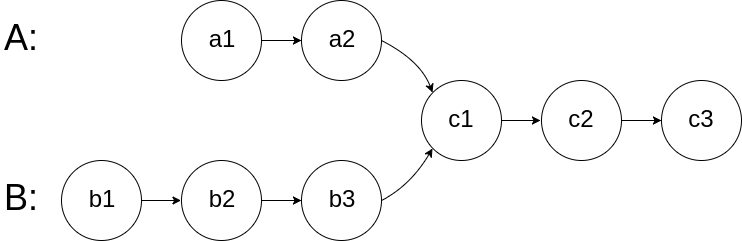
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
思路1:暴力求解/穷举法(把所有可能都走一遍)
依次取A链表中的每个节点跟B链表中的所有节点比较
如果有地址相同的节点,则相交
时间复杂度:O(
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
//新建两个指针,用来分别遍历两个链表
struct ListNode* curA=headA;
struct ListNode* curB=headB;
//遍历前判断一下两链表是否为空:如果为空,肯定不相交。反正,可能相交,参与遍历
if(curA==NULL||curB==NULL)
{
return NULL;
}
//遍历
while(curA&&curB)
{
//A上的节点,按顺序依次分别比较B的所有节点
//如果curA=curB,则找到了。否则将curB往后挪,直到比较完所有的curB
while(curA!=curB)
{
curB=curB->next;
//如果curB从尾节点挪动到NULL,按照判断条件,还有继续参与循环,直到遇到解引用空指针警告,所有我们要剔除这一可能
if(curB==NULL)
{
goto flag;
}
}
flag:
//出了循环要么没找到,要么找到了
if(curA==curB)
{
//找到了
return curA;
}
//没找到,A往后挪1
curA=curA->next;
//如果不把curB的存储内容重新置换为headB的话,本次循环一结束,curB依旧存储的是NULL
curB=headB;
}
//没找到
return NULL;
}思路2:
尾节点相同就相交,否则不相交
求交点:长的链表先走长度差步,再同时走,第一个相同就是交点
时间复杂度:O(N)
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
struct ListNode* tailA, *tailB;
tailA = headA;
tailB = headB;
int lenA = 1; // 存放A链表的长度
int lenB = 1; // 存放B链表的长度
// A链表找尾节点及链表长度
while (tailA->next)
{
tailA = tailA->next;
++lenA;
}
// B链表找尾节点及链表长度
while (tailB->next)
{
tailB = tailB->next;
++lenB;
}
// 如果相交,它们的尾节点一定相等。如果不相等就返回NULL
if (tailA != tailB)
{
return NULL;
}
// 相交,求交点,长的先走"差距步", 然后一起走
struct ListNode* shortList = headA; // 假设A短
struct ListNode* longList = headB; // 假设B长
// 如果A的长度大于B
if (lenA > lenB)
{
// 那么就交换一下
longList = headA;
shortList = headB;
}
// 求出差距步
int gap = abs(lenA - lenB); // abs是求绝对值的函数
// 长的先走差距步
while (gap--)
{
longList = longList->next;
}
// 然后同时走
while (shortList && longList)
{
if (shortList == longList)
{
return shortList;
}
shortList = shortList->next;
longList = longList->next;
}
// 要加这个,不然会显示[编译出错]
return NULL;
}
面试题九:环形链表
题目描述:
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
面试题十:复制带随机指针的链表
题目描述:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000
-104 <= Node.val <= 104
Node.random 为 null 或指向链表中的节点。
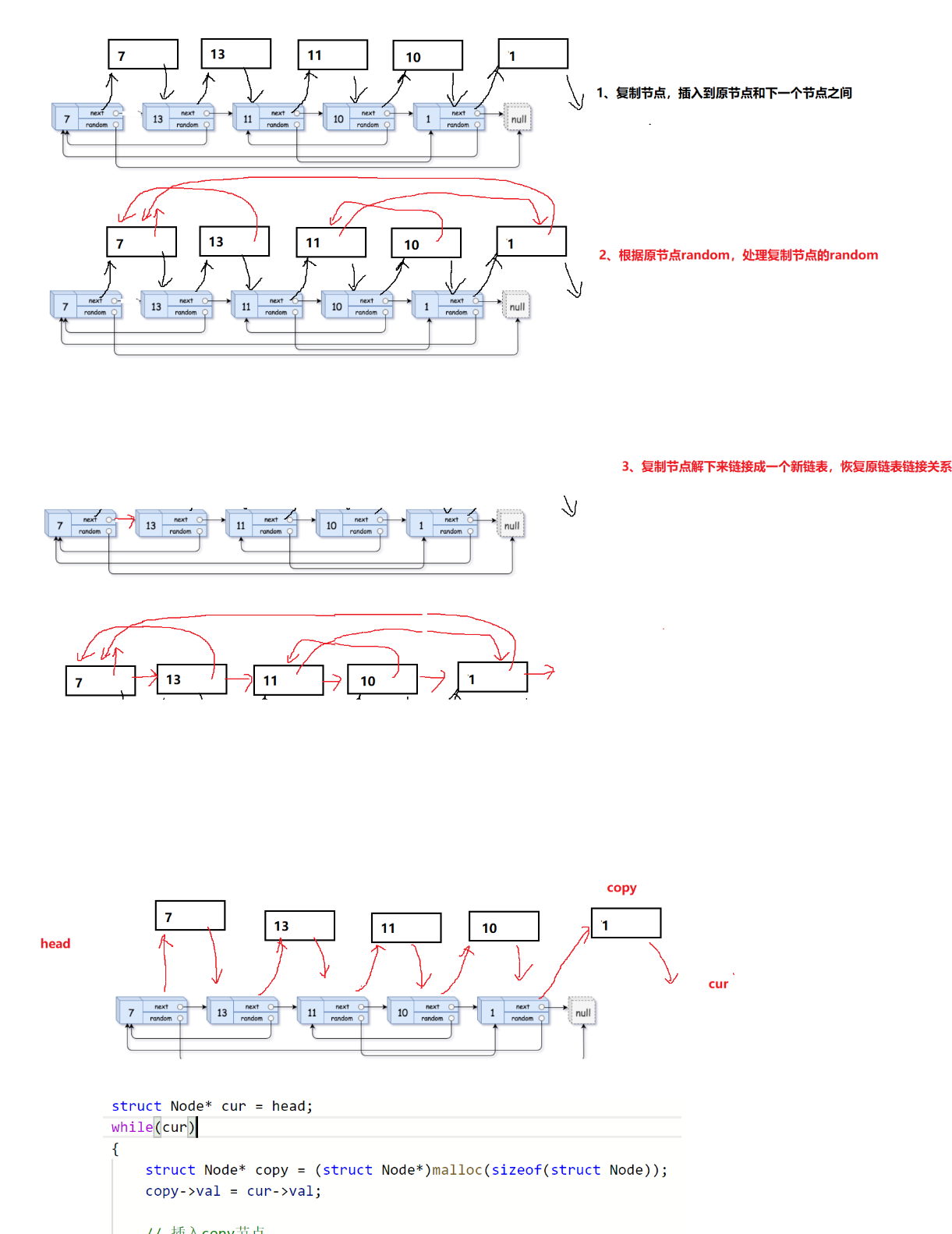
图片解释:
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head)
{
//将copy插入每一个原节点的后边
struct Node* cur = head;
while(cur)
{
struct Node* copy = (struct Node*)malloc(sizeof(struct Node));
copy->val = cur->val;
copy->next = cur->next;
cur->next = copy;
cur = copy->next;
}
//拷贝原节点中random的指向位置
cur = head;
while(cur)
{
struct Node* copy = cur->next;
if(cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;
}
cur = copy->next;
}
//将copy从原节点上取出并连接 再将原节点进行连接
struct Node*copyhead = NULL,*copytail = NULL;
cur = head;
while(cur)
{
struct Node*copy = cur->next;
struct Node*next = copy->next;
if(copytail == NULL)
{
copyhead = copytail = copy;
}
else
{
copytail->next = copy;
copytail = copy;
}
cur->next = next;
cur = next;
}
return copyhead;
}带头+双向+循环链表:
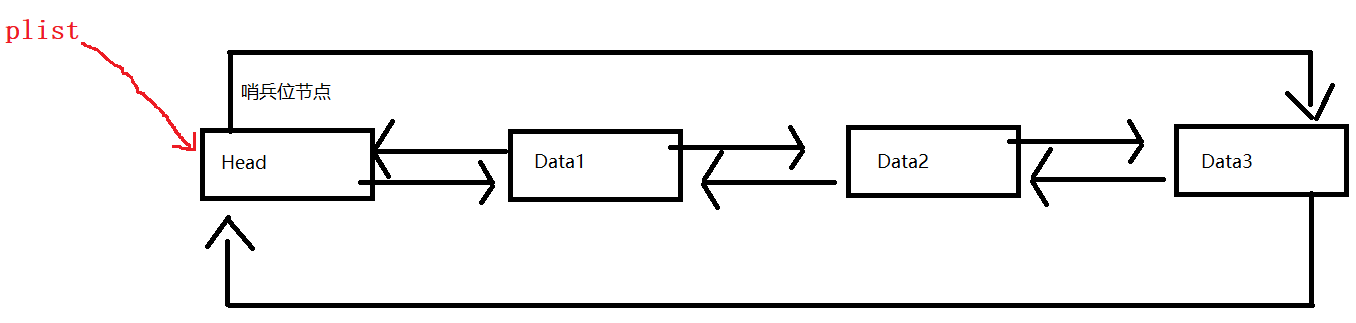
结构体创建:

typedef int LTDataType;
typedef struct ListNode
{
//值域
LTDataType data;
//前址域
struct ListNode* prev;
//后址域
struct ListNode* next;
}LTNode;这里的节点成员包含三个:值域,前址域,后址域
初始化:
要想得到并带出动态开辟的链表空间地址有两个方案:
1.设计传入参数为链表指针的地址,只有传入指针的地址,才能修改指针的内容,即改成动态开辟的链表地址将之带出函数
2.设计返回类型为节点指针,返回动态开辟的链表节点指针,使之在函数外就能够接受到改地址
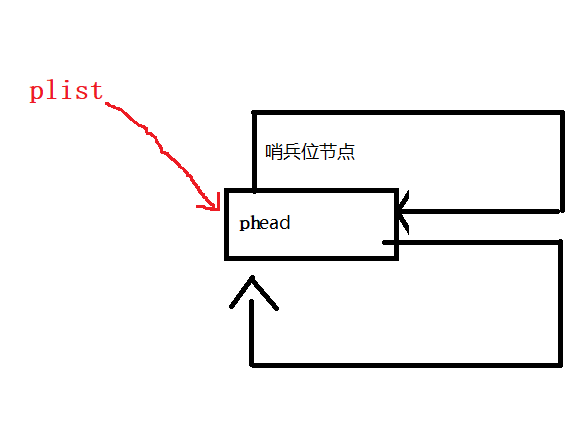
过程:
由于刚开始只有一个节点,也就是头结点,又要构成双向循环,所以头结点的prev和next都指向的是头结点自己
这里初始化没有传二级指针,而是采取了返回头结点的方式。所以需要先malloc申请一个头结点phead
然后将phead的prev和next都指向phead自己,初始化就大功告成了。
方法一:
void ListInint(LTNode** pphead)
{
*pphead = (LTNode*)malloc(sizeof(LTNode));
(*pphead)->next = (*pphead);
(*pphead)->prev = (*pphead);
}
void TestList1()
{
//头指针指向哨兵位
LTNode* plist ;
ListInit(&plist);
}方法二:
LTNode* ListInit()
{
//哨兵位头节点
LTNode* phead = (LTNode*)malloc(sizeof(LTNode));
phead->next = phead;
phead->prev = phead;
//返回哨兵位的地址
return phead;
}
void TestList1()
{
//头指针指向哨兵位
LTNode* plist = ListInit();//看解释1
}1️⃣这种写法给我们打开了一个思路:
任何传二级指针的调用都可以写成这种地址接收的形式
创建新节点:
LTNode* BuyListNode(LTDataType x)
{
//开辟哨兵位头节点
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
//初始化哨兵卫头结点值域和址域
newnode->prev = NULL;
newnode->next = NULL;
newnode->data = x;
return newnode;
}尾插:
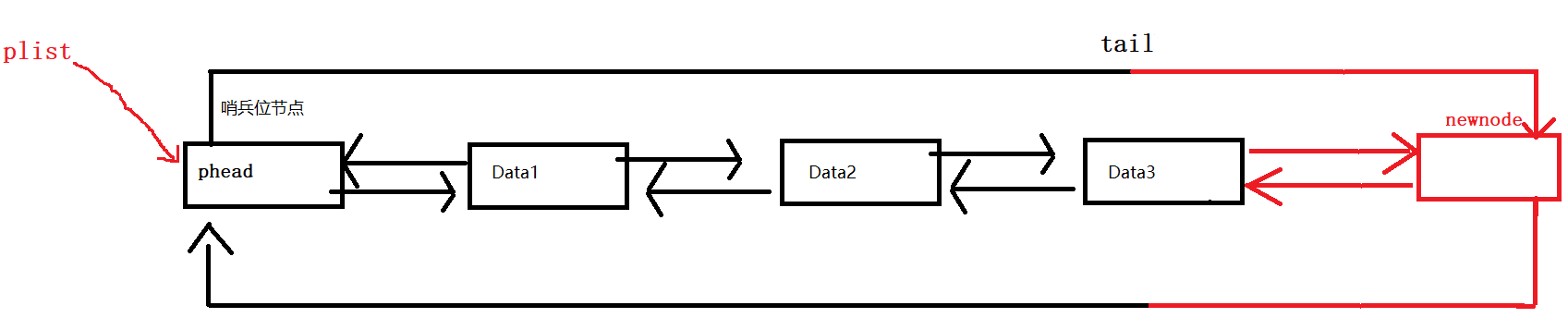
尾插首先要找到尾节点,这里的尾节点很容易找到,就是头节点的prev指向的节点。如下:
这里的尾插也满足空表情况下进行尾插。所以该代码没问题
过程:
比起单链表的尾插,带头双向循环链表进行尾插就十分容易,因为它不用遍历寻找尾结点,头结点phead的prev指向的就是尾结点
先断言防止链表为初始化而为空链表
再使用BuyListNode函数申请一个新节点NewNode,通过头节点的prev找到尾结点
将尾结点tail的next链接上NewNode,再将NewNode的prev指向tail
此时NewNode为新的尾结点,将其next指向头结点phead,再将phead的prev指向新的尾结点NewNode,尾插就完成了
当然之后完成ListInsert以后就可以直接调用它完成尾插
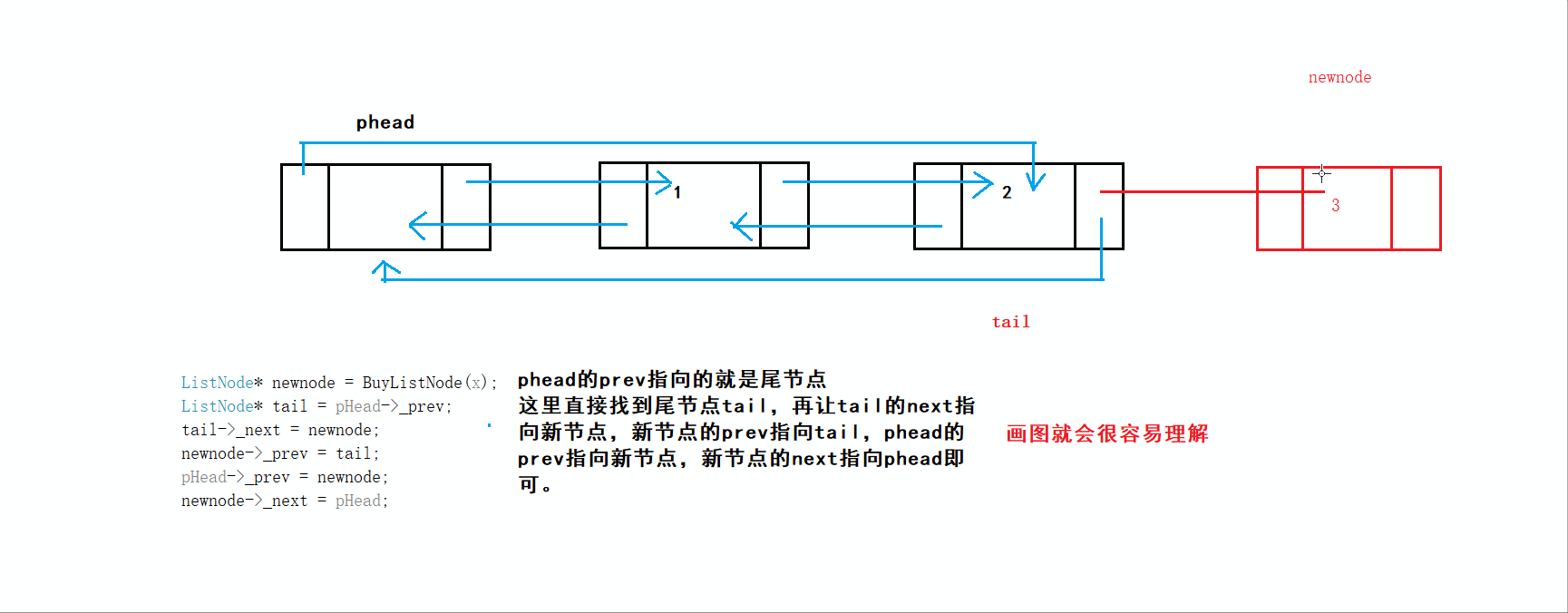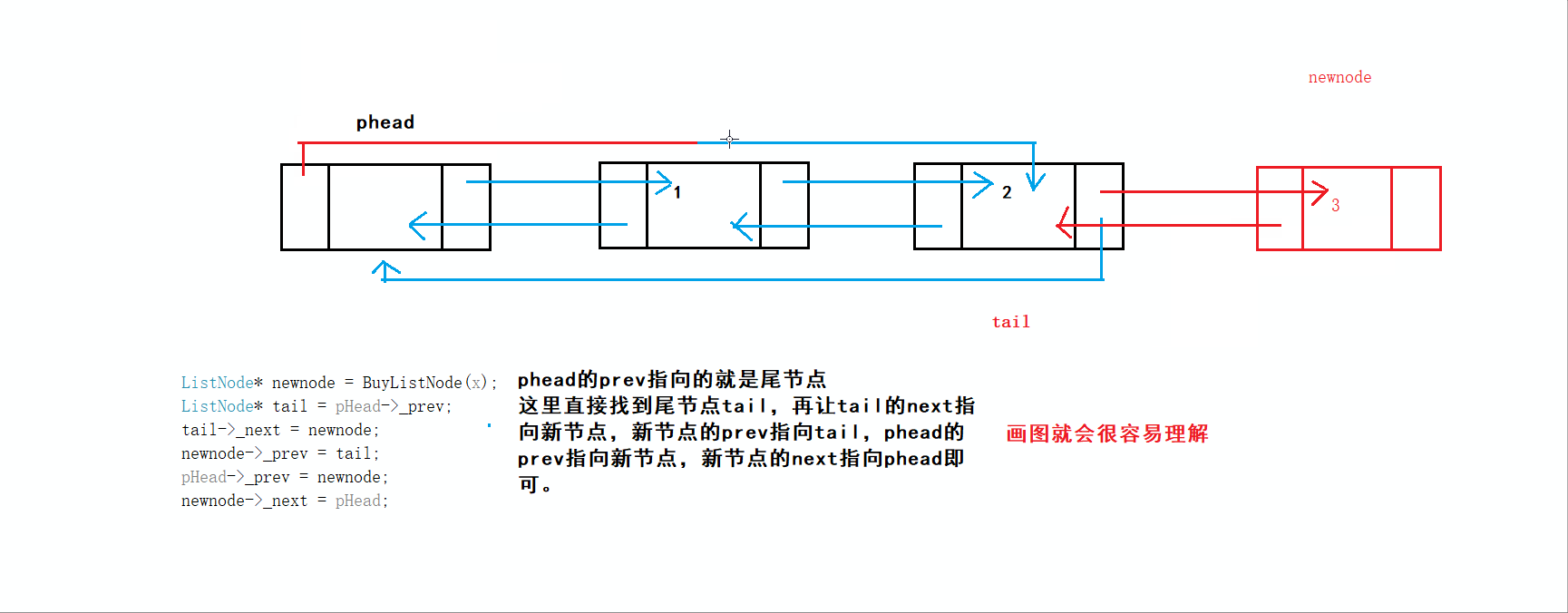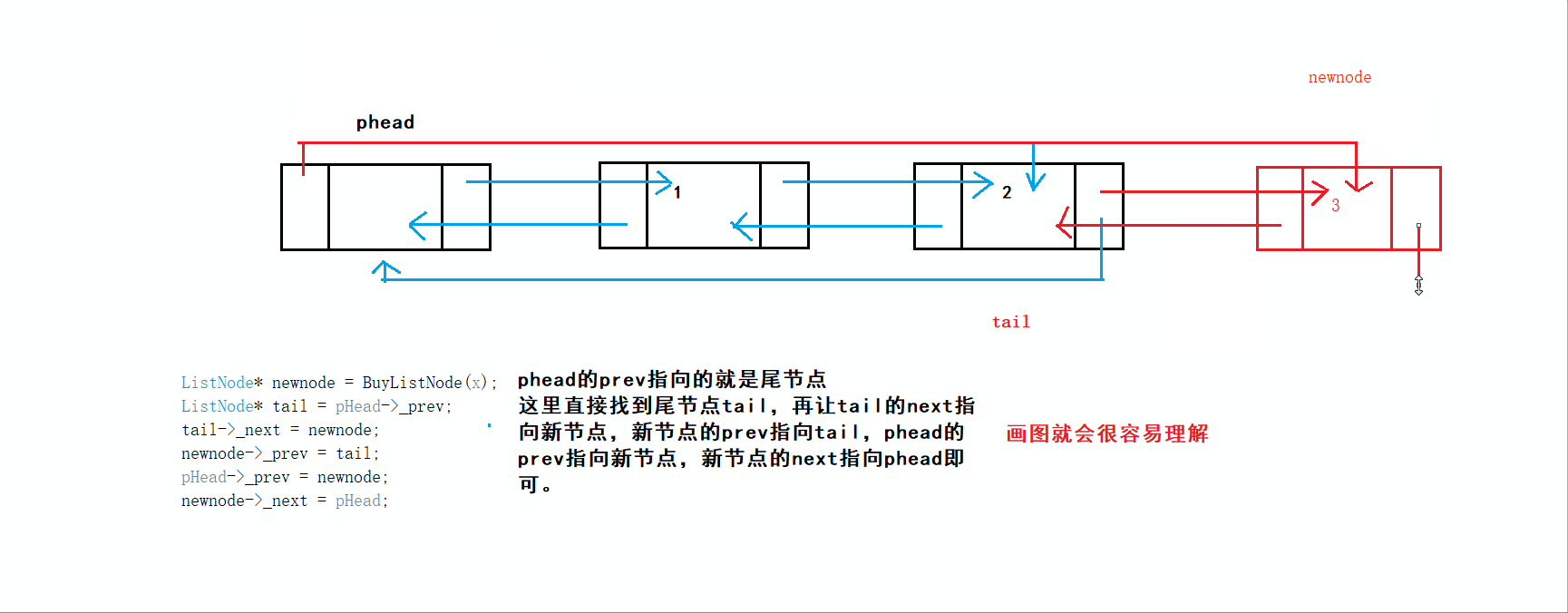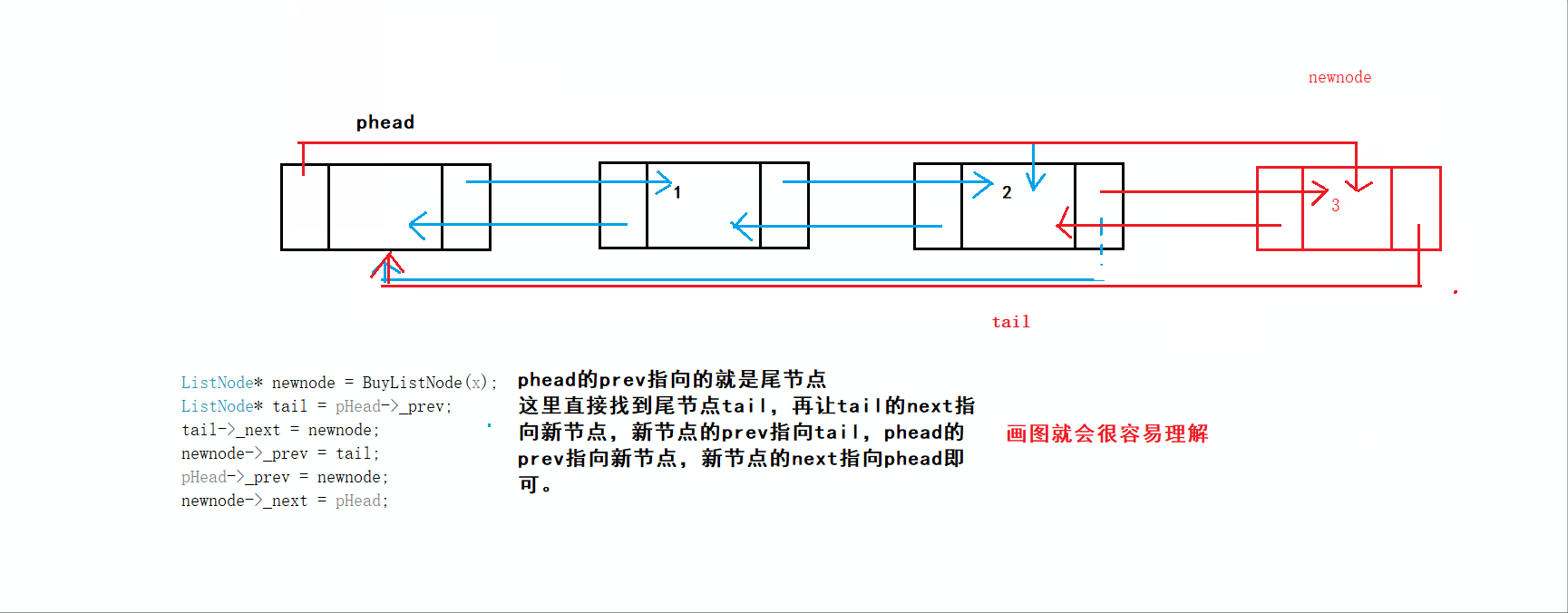
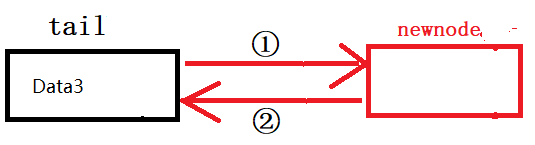
void ListPushBack(ListNode* phead,LTDataType x)//看解释1
{
assert(phead);//看解释2
ListNode* newnode = BuyListNode(x);
ListNode* tail = phead->prev;//看解释3
tail->next = newnode;//新节点尾节点连接,看解释4-①
newnode->prev = tail;//尾节点跟新节点连接,看解释4-②
newnode->next = phead;
phead->prev = newnode;
}1️⃣为什么这里phead传的不是二级指针?
因为该链表有哨兵位,插入是从哨兵位的后面开始的,而不是头指针。故不需要对头指针的内容做出修改,因而不需要传二级指针
2️⃣assert(phead)等价于assert(phead !=NULL),phead哨兵位绝不可能为空,因为你就算把链表删完了也不会删掉哨兵位,只剩哨兵位时,哨兵位会自己连自己
3️⃣图解:

4️⃣图解:
打印:
1.循环遍历链表打印数据
2.以哨兵卫头节点地址作为遍历结束标记
首先先断言链表不为空,为空就不用打印了
然后就是利用cur指针从头节点的下一个节点遍历链表(头结点不存储有效数据)节点打印数据域data,问题是终止条件是什么
单链表时在cur为为NULL时就到尾了,可是带头双向链表没有指向NULL的节点
其实也很简单,当cur再次为头结点phead时说明已经遍历链表一遍了,这就是终止条件
// 双向链表打印
void ListPrint(LTNode* phead)
{
//断言传入指针不为NULL
assert(phead);
//创建寻址指针
LTNode* cur = phead->next;
//循环遍历链表
while (cur != phead)
{
//打印数据
printf("%d->", cur->data);
//找到下一个节点
cur = cur->next;
}
return;
}尾删:
经典的错误:
void ListPopBack(LTNode* phead)
{
LTNode* tail = phead->prev;
free(phead->prev);//看解释1
tail->prev->next = phead;//看解释1
phead->prev=tail->prev;
}1️⃣phead->prev和tail指向的是同一块地址,用free把phead->prev释放以后,你再用tail->就是访问野指针了
改进的写法:
void ListPopBack(LTNode* phead)
{
LTNode* tail = phead->prev;
LTNode* tailprev = tail->prev;
free(tail);
tailPrev->next = phead;
phead->prev=tailPrev;
}这种写法依然有问题,因为这种尾删可以删掉哨兵位,这是非常危险的
正确的写法:
1.考虑节点只剩哨兵卫的情况
2.尾删前记录前一节点的地址
3.注意构建节点关系的逻辑
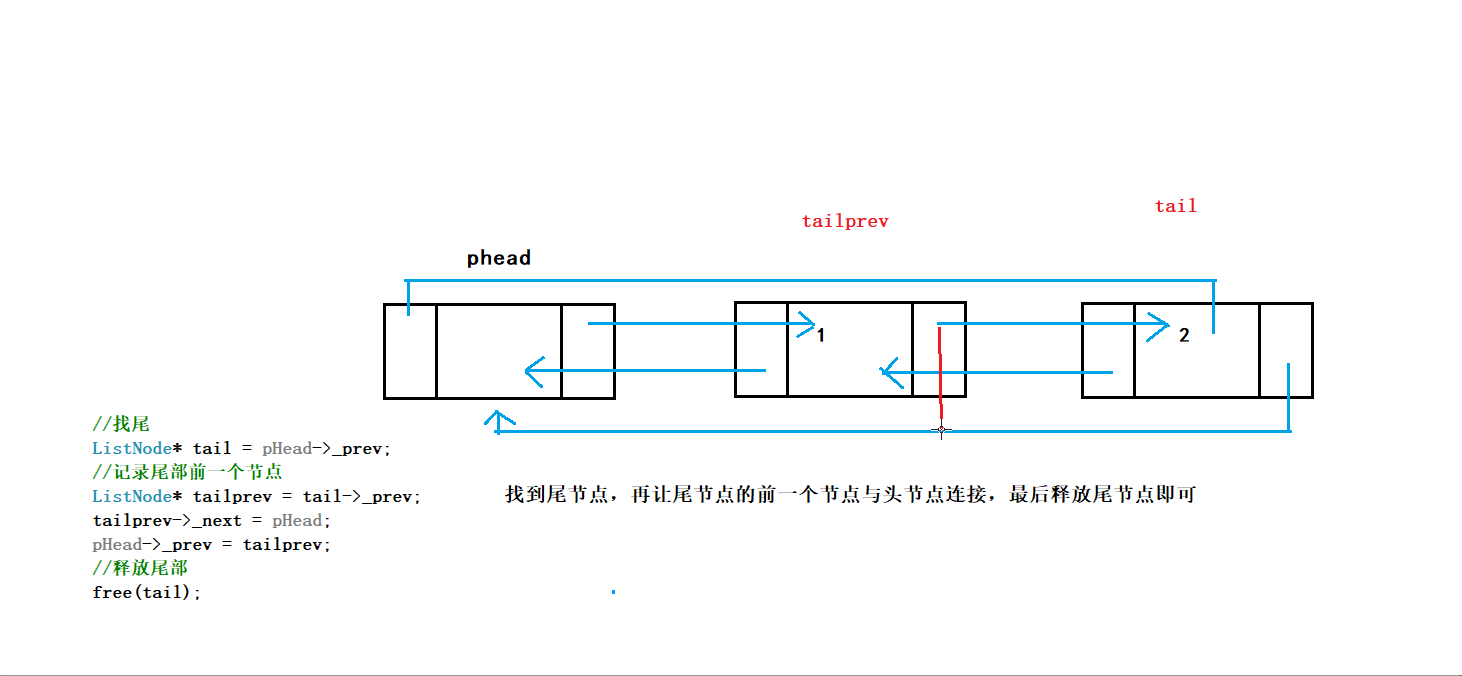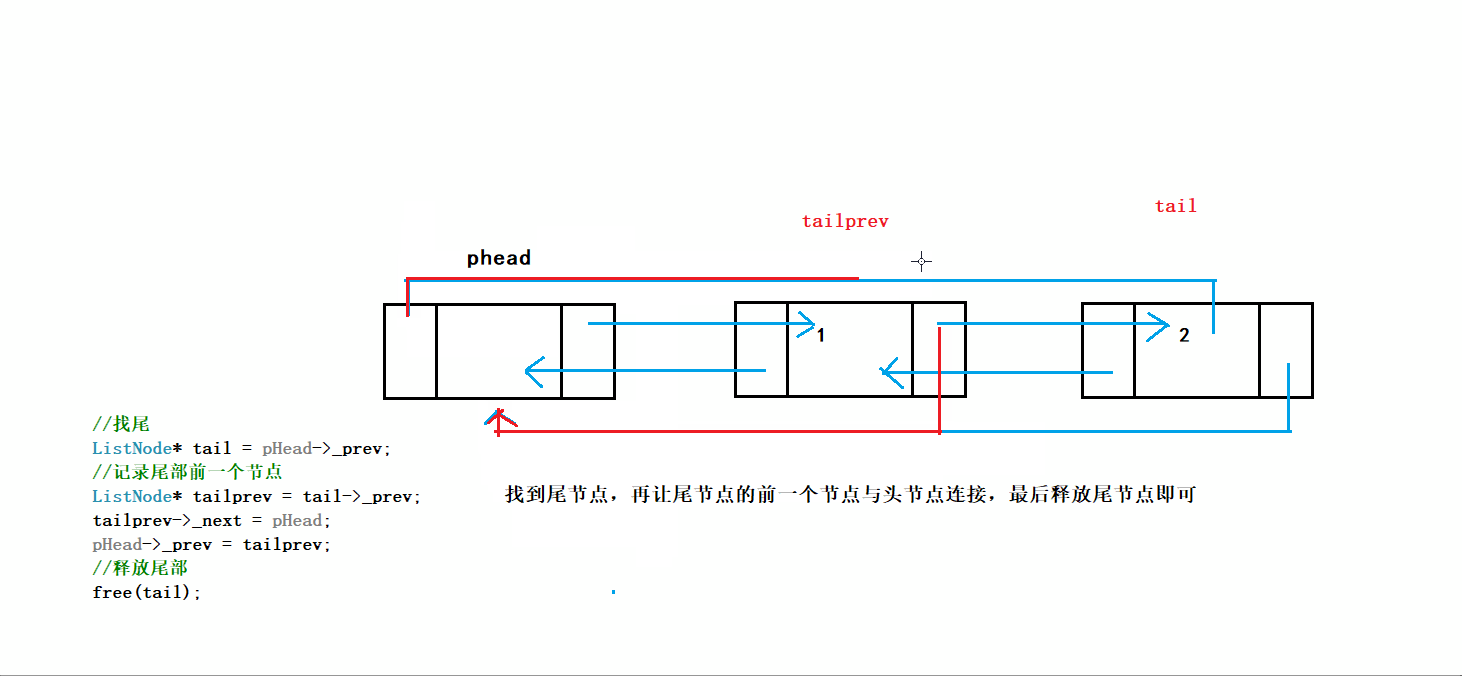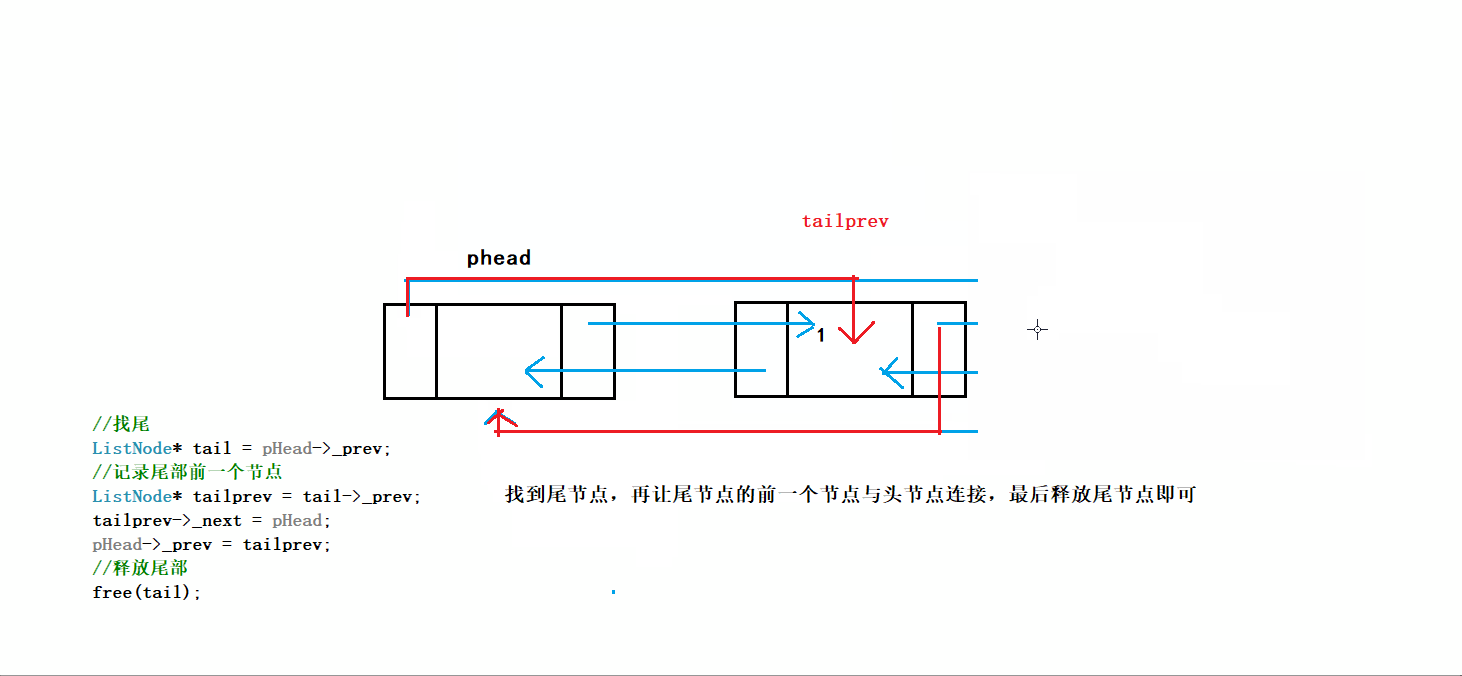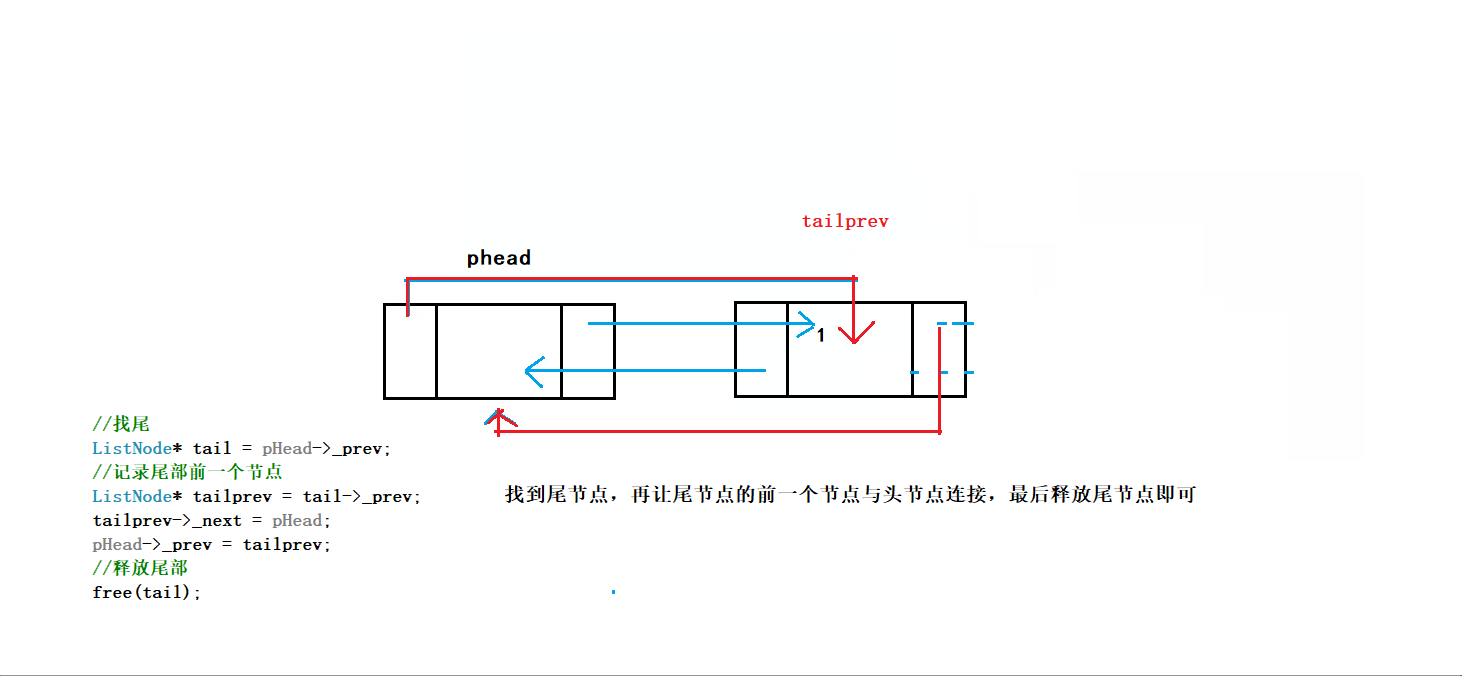
过程:
进行尾删时我们不仅要断言链表不为空,并且要断言链表不能只有头节点,因为我们不希望将头结点也删除
之后通过phead的prev找到尾结点tail,创建变量tailprev指向tail的上一个节点
因为tail节点要被释放,所以tailprev是尾删后链表的新尾节点
将tailprev的next指向头结点phead,phead的prev指向tailprev
最后释放tail节点,就完成了尾删
完成ListErase后可以直接调用完成尾删
// 双向链表尾删
void ListPopBack(LTNode* phead)
{
//断言传入指针不为NULL
assert(phead);
//只剩哨兵卫头结点的情况
if (phead->next == phead)//看解释1
return;
//记录尾节点及其前一节点
LTNode* tail = phead->prev;
LTNode* tailprev = tail->prev;
//释放尾节点
free(tail);
//构建尾节点前一节点与哨兵卫头结点的关系
tailprev->next = phead;
phead->prev = tailprev;
return;
}1️⃣phead->next==phead表示链表为空,不能再删了,这里写成暴力的形式assert(phead->next!=phead)更方便
那我要是不用tailPrev,怎么办?
void ListPopBack(LTNode* phead)
{
//断言传入指针不为NULL
assert(phead);
//只剩哨兵卫头结点的情况
assert(phead->next!=phead);
//记录尾节点及其前一节点
LTNode* tail = phead->prev;
//构建尾节点与哨兵卫头结点的关系
phead->prev=tail->prev;
tail->prev->next=phead;
//释放尾节点
free(tail);
return;
}头插:
头插的实现在这里也很简单,先找到有效节点的头节点(即PHead的next指向的第一个节点),然后将新节点的next指向该节点,该节点的prev指向新节点,再让PHead的next指向新节点,新节点的prev指向PHead即可。(看起来可能有些乱,但是画图就特别容易理解)
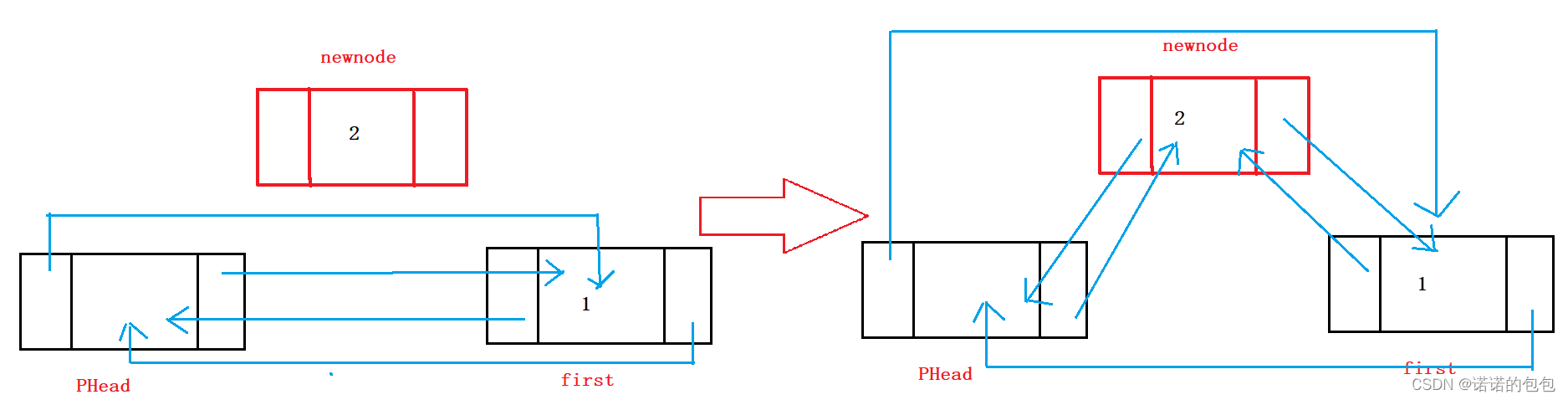
1.头插前记录哨兵卫头节点的下一节点
2.注意构建节点关系的逻辑
过程:
这里说是头插但并不是在头结点phead前面插入,无论如何phead都是头节点,它就是个哨兵,起的站岗作用,所以头插其实是在头结点phead后面进行插入
创建变量next指向第二个节点就是头结点的下一个节点,之后在next前面进行插入新节点
之后的工作就是将phead的next指向NewNode,NewNode的prev指向phead
NewNode的next指向next,next的prev指向NewNode完成双向链接
完成ListInsert以后就可以直接调用它完成头插
void ListPushFront(LTNode* phead, LTDataType x)
{
//断言传入指针不为NULL
assert(phead);
//创建节点
LTNode* newnode = BuyListNode(x);
//记录哨兵卫头结点的下一节点
LTNode* next = phead->next;
//构建各节点之间的关系
phead->next = newnode;
newnode->prev = phead;
newnode->next = next;
next->prev = newnode;
}头删
头删的实现与尾删异曲同工,找到有效节点的头节点,保存下一个节点,将PHead与之连接,然后再释放有效节点的头节点即可。
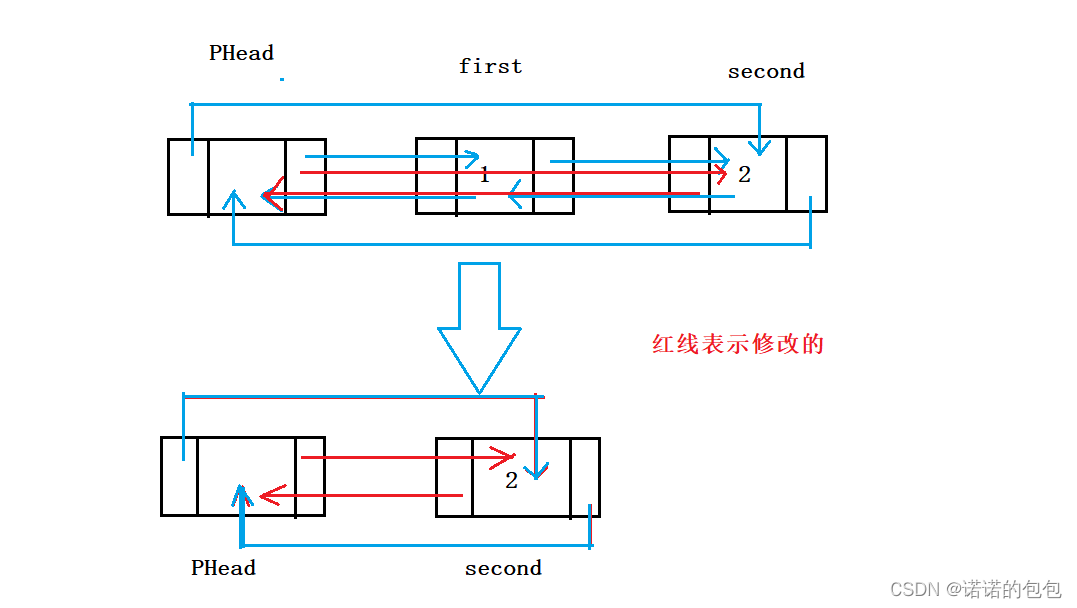
这里依然要注意,空表情况不能进行删除
1.考虑只剩哨兵卫头结点的情况
2.头删前保存节点地址
3.注意节点关系的构建
过程:
进行头删时我们不仅要断言链表不为空,并且要断言链表不能只有头节点,因为我们不希望将头结点也删除
并且头删删除的也并不是头节点,是头节点的下一个节点
之后通过phead的next找到要删除的结点next,创建变量Nextnext指向next的下一个节点
然后将Nextnext和头节点phead进行链接,具体实现不赘述了
最后释放next节点,就完成了头删
完成ListErase后可以直接调用完成头删
void ListPopFront(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
//记录哨兵卫头结点下一节点及其的下一节点
LTNode* next = phead->next;
LTNode* nextNext = next->next;
//构建关系以及释放节点
phead->next = nextNext;
nextNext->prev = phead;
free(next);
}查找
1.循环遍历链表,以哨兵卫头节点地址作为结束遍历
2.没找到则返回NULL,找到就返回其地址
过程:
这个函数很少单独使用,更多的是为了辅助ListInsert,ListErase这两个函数,通过ListFind找到要插入删除的节点,然后将其地址传给ListInsert,ListErase进行插入或删除
实现也很简单,使用cur指针遍历链表,对比每一个节点data的值和x的值,x代表使用者想要查找的值
如果相等就返回节点地址,如果找不到就返回NULL
通过ListFind还可以实现链表元素的修改
LTNode* ListFind(LTNode* phead, LTDataType x)
{
//断言传入指针不为NULL
assert(phead);
//创建寻址指针
LTNode* cur = phead->next;
while (cur != phead)
{
//比较数据
if (cur->data == x)
return cur;
//找到下一个节点
cur = cur->next;
}
//没找到则返回NULL
return NULL;
}链表pos位置前插
这里与头插的操作相比,两者其实也没啥区别。头插是找有效节点的头节点,在这里我们把pos看作该节点,把pos的prev指向的节点看作是PHead节点,这样的话,原理就与头插相同了。
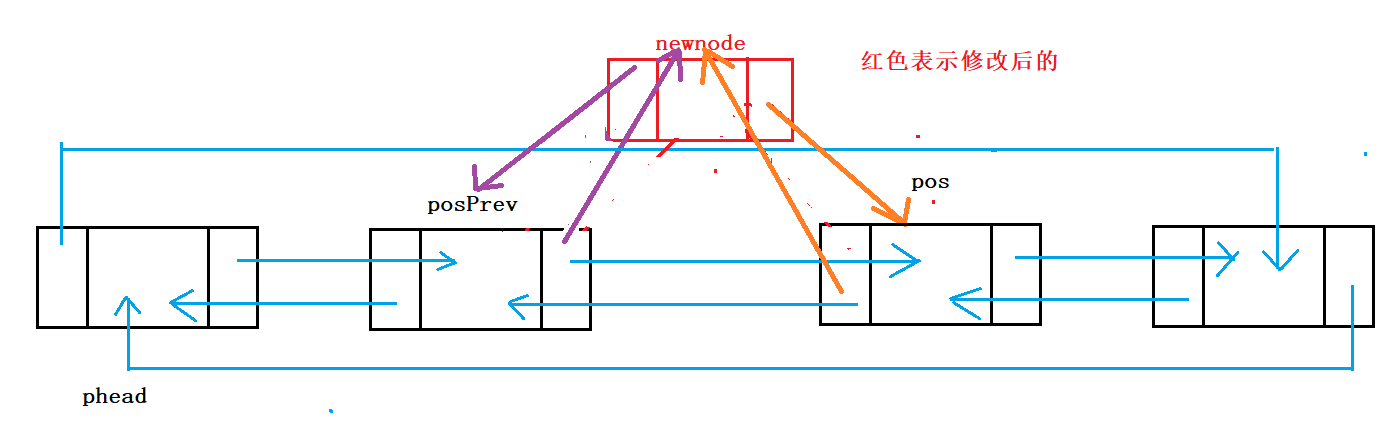
1.前插前保存前一节点地址
2.注意构建节点关系的逻辑
过程:
pos参数一般是基于ListFind查找而来,故这两个函数经常搭配使用
之后创建变量posprev指向pos的上一个节点,申请新节点将其prev指向posprev,将其next指向pos
posprev的next指向新节点NewNode,pos的prev指向NewNode
这样pos位置之前的插入就完成了,并且可以替代头插尾插
// 双向链表在pos的前面进行插入
void ListInsert(LTNode* pos, LTDataType x)
{
//断言传入指针不为NULL
assert(pos);
//创建新节点
LTNode* newnode = BuyListNode(x);
//记录pos节点的前一节点
LTNode* posPrev = pos->prev;
//构建节点之间的关系
//紫色区:
posPrev->next = newnode;
newnode->prev = posPrev;
//橙色区:
newnode->next = pos;
pos->prev = newnode;
return;
}改进尾插--复用插入
void ListPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
ListInsert(phead->prev,x);
}改进头插--复用插入
void ListPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
ListInsert(phead->next,x);
}pos删除:
1.删除前保存前节点和后节点地址
2.注意节点关系的构建
过程:
pos参数一般是基于ListFind查找而来,故这两个函数经常搭配使用
之后创建变量posprev指向pos的上一个节点,创建变量posnext指向pos的下一个节点
将posprev与posnext链接,释放pos,就完成pos位置的删除了,并且可以替代掉尾删头删
// 双向链表删除pos位置的节点
void ListErase(LTNode* pos)
{
//断言传入指针不为NULL
assert(pos);
//记录pos的前一节点和后一节点
LTNode* posPrev = pos->prev;
LTNode* posNext = pos->next;
//释放节点并构建关系
free(pos);
pos=NULL;
posPrev->next = posNext;
posNext->prev = posPrev;
return;
}
void TestList1()
{
//头指针指向哨兵位
LTNode* plist = ListInit();
//尾插
ListPushBack(plist, 1);
ListPushBack(plist, 2);
ListPushBack(plist, 3);
ListPushBack(plist, 4);
ListPrint(plist);
LTNode* pos=ListFind(plist,2);
if(pos)
{
ListErase(pos);
}
ListPrintf(plist);
}改进尾删--复用删除
void ListPopBack(LTNode* phead)
{
//断言传入指针不为NULL
assert(phead);
//只剩哨兵卫头结点的情况
assert(phead->next!=phead);
ListErase(phead->prev);
}改进头删--复用删除
void ListPopFront(LTNode* phead)
{
//断言传入指针不为NULL
assert(phead);
//只剩哨兵卫头结点的情况
assert(phead->next!=phead);
ListErase(phead->next);
}销毁:
过程:
最后是销毁链表,这里有个很容易犯的错误就是直接free(phead),这样只是释放了头节点,链表的其它节点并未释放,会造成内存泄露。
所以我们需要通过cur遍历链表所有节点一个一个进行释放,并且防止释放了cur找不到cur的下一个节点,需要先创建临时变量进行保存
最后将phead置为空指针代表链表为空,即销毁完成。
void ListDestroy(LTNode* phead)
{
assert(phead);
LTNode* cur=phead->next;
while(cur !=phead)
{
LTNode* next=cur->next;
free(cur);
cur=next;
}
free(phead);
phead=NULL;
}
void TestList1()
{
//头指针指向哨兵位
LTNode* plist = ListInit();
//尾插
ListPushBack(plist, 1);
ListPushBack(plist, 2);
ListPushBack(plist, 3);
ListPushBack(plist, 4);
ListPrint(plist);
ListDestroy(plist);
plist=NULL;
}总结
该链表用起来真的很爽,能直接找到头尾节点,并且因为有哨兵位的存在,就不需要考虑是否为空表的情况下的插入,就不用改变phead,所以就不用像之前的单链表一样,得传二级指针。真的是链表中的完美存在,不过在进行删除操作时,一定要考虑空表情况下不可进行删除。因此要加个assert进行断言。
顺序表和链表的区别
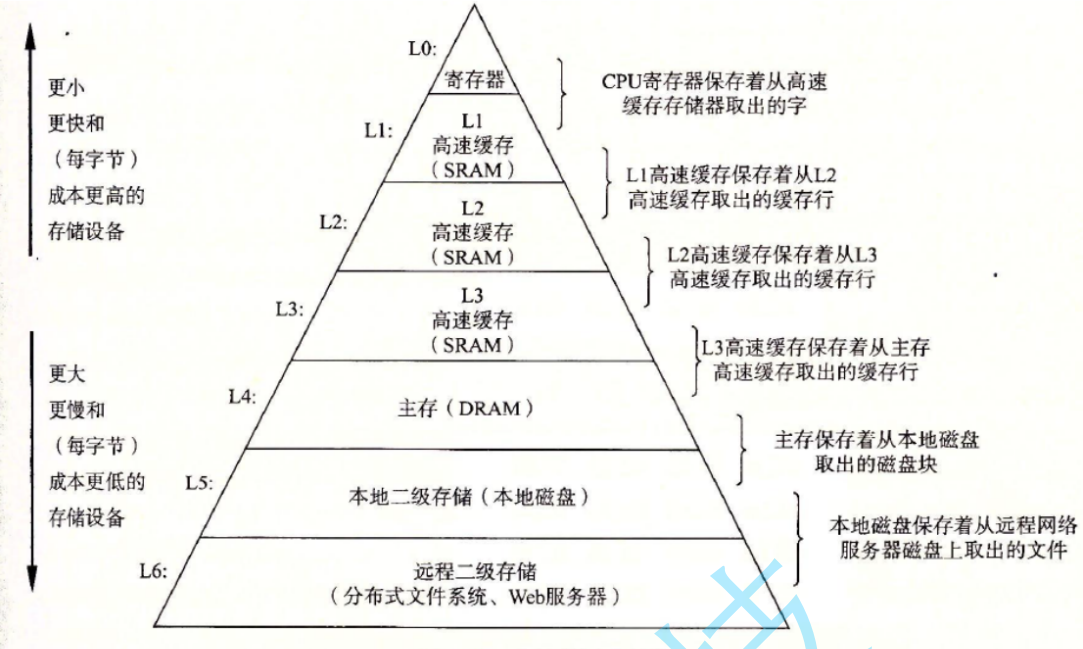
假设写了一个程序,实现分别对顺序表和链表上的每个数据+1,那么这个程序会编译成指令,然后CPU再执行
CPU运算的速度很快,那内存的速度跟不上,CPU一般就不会直接访问内存,而是把要访问的数据先加载到缓存体系,如果是 ≤ 8byte的数据 (寄存器一般是8byte),会直接到寄存器;而大的数据,会到三级缓存,CPU直接跟缓存交互。
CPU执行指令运算要访问内存,先要取0x10 (假设) 的数据,拿0x10去缓存中找,发现没有 (不命中) ,这时会把主存中这个地址 开始的一段空间都读进来 (缓存)。
假设不命中,一次加载20byte空间到缓存 (具体加载多大byte,取决于硬件体系)
如果是整型数组,下一次访问0x14、0x18… 就会命中
如果是链表,先取第1个节点0x60,不命中;再取第2个0x90,不命中…。会不断把周围的空间加载到缓存,这样会造成一定的缓存污染