目录
一、缓冲区概念
缓冲区,本质就是一块内存区域。
设计缓冲区就是为了让本来要一次一次传的数据,都暂时传到缓冲区,让缓冲区刷新一次,这样只发生了一次传递,但是却完成了很多数据的传递。
实际上,Linux操作系统内核有缓冲区的设计,C语言也有缓冲区的设计。
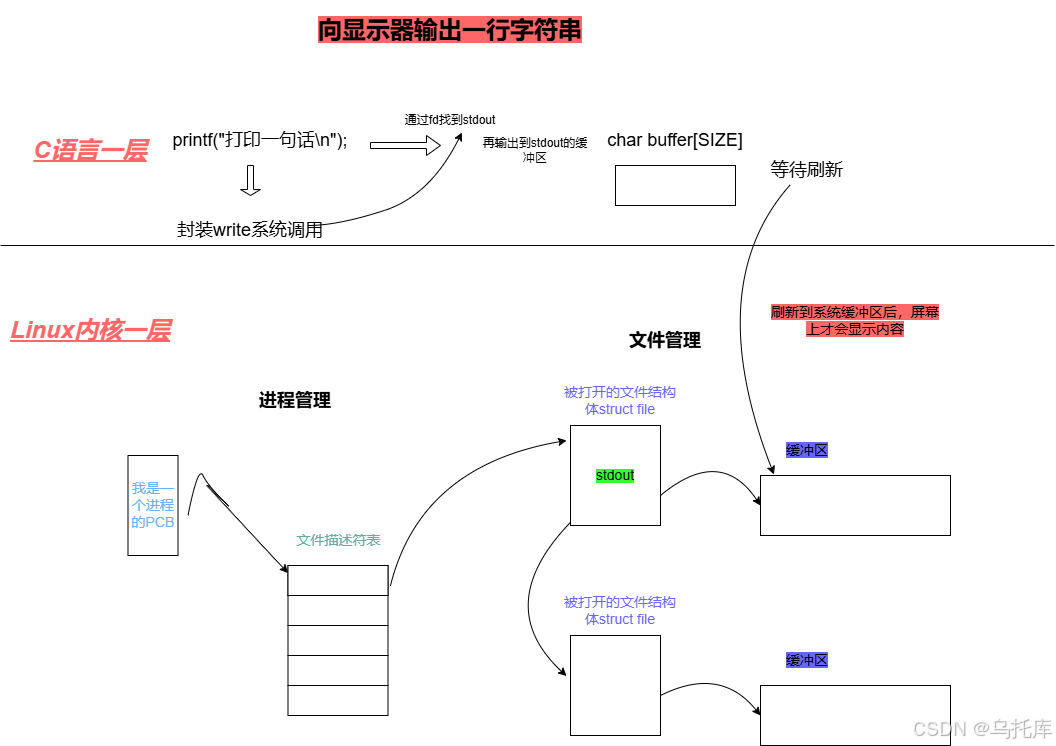
- C语言的printf语句,实际上是先将字符串输出到了C语言的缓冲区,而不是直接打印到了屏幕。
- 当C语言的缓冲区刷新后,需要打印的内容就被刷新到了系统的缓冲区,即stdout的系统缓冲区,从而显示到屏幕上。
具体来说。
- 在Linux系统内核中,每个被打开的文件都对应着一个file结构体变量,即都对应着一个系统缓冲区,屏幕这个文件也对应一个系统缓冲区。
- 在C语言层同样如此,每个被打开的文件都对应一个FILE类型结构体变量,FILE封装了文件描述符,还有C语言一层的缓冲区。
- printf内部通过fd找到stdout这个文件,先把要输出的字符串先输出到stdout的C语言缓冲区,等待刷新,刷新stdout的C语言缓冲区到stdout的系统缓冲区,至此,屏幕上显示了结果。
二、缓冲区刷新机制
C语言的缓冲区想要刷新到系统缓冲区中,可能是下面几种情况。
- 如果是显示器文件,则遇到\n就刷新,即行刷新。
- 普通文件的刷新机制,写满缓冲区才刷新,即全缓冲、全刷新。
- 调用相关接口强制刷新。
- 进程退出,自动刷新。
三、用缓冲区刷新解释下面现象。
#include <stdio.h>
#include <unistd.h>
int main(void)
{
//使用system call
const char* str1 = "i am write\n";
write(1,str1,strlen(str1));
//使用C函数
const char* str2 = "i am fprintf\n";
fprintf(stdout,"%s",str2);
const char* str3 = "i am fwrite\n";
fwrite(str3,strlen(str3),1,stdout);
//
fork();
return 0;
}
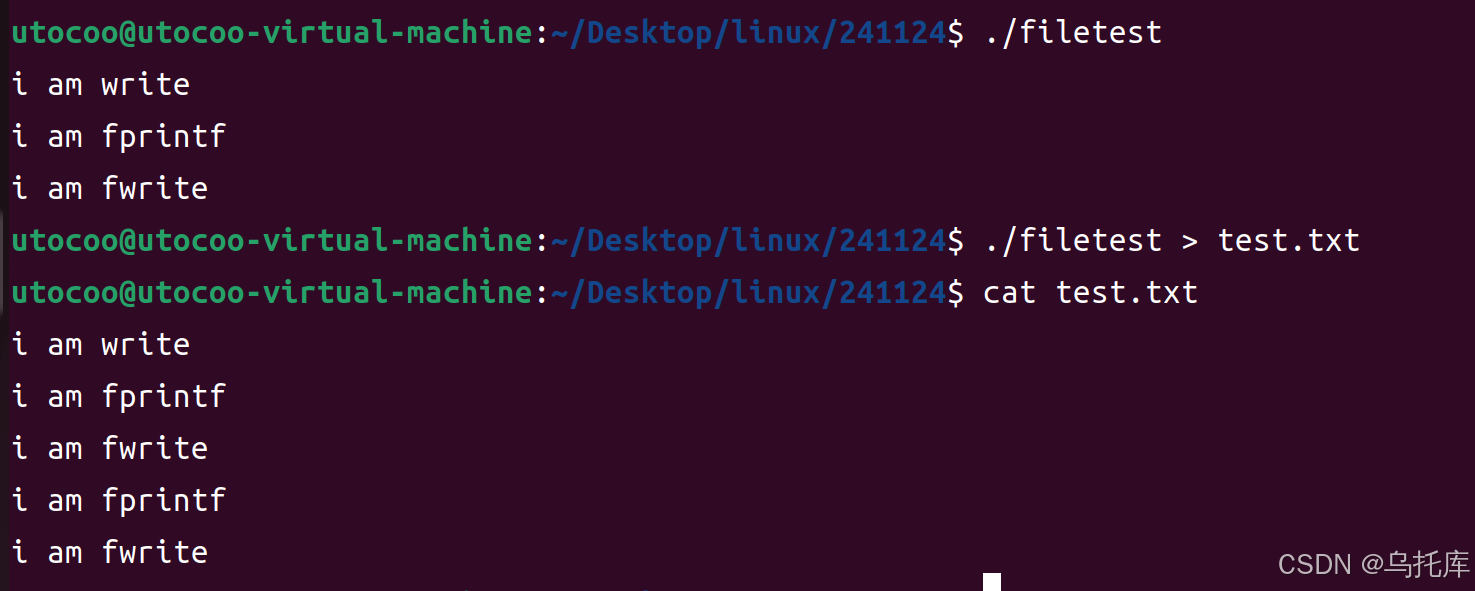
- 直接运行,是将打印结果输出到屏幕,由于每句打印都有换行符,因此每一个打印语句执行完毕后,打印内容都已经刷新到了系统缓冲区。
- 将打印结果重定向到一个普通文件时,第一个打印语句为系统调用,不需要将结果暂存到test.txt的C语言缓冲区,直接打印到了系统缓冲区。
- 剩下两句打印都是先暂存到了C语言缓冲区。

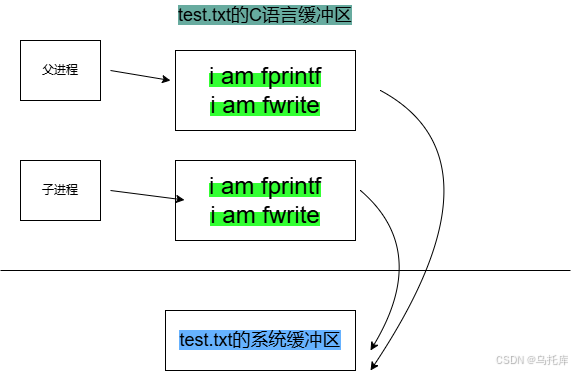
- fork创建出子进程。
- 当代码全部执行完毕时,子进程开始退出,故需要刷新缓冲区,刷新缓冲区后要清空缓冲区,等于对数据做修改,因此要先做写时拷贝给子进程,于是子进程拷贝了父进程管理的test.txt的C语言缓冲区。
- 子进程退出,刷新C语言缓冲区到test.txt的系统缓冲区,新增了两行打印。父进程退出,刷新C语言缓冲区到test.txt的系统缓冲区,也新增了两行打印。
C语言的缓冲区,将多次传递集中到一次传递,提高了效率,不仅如此。要知道我们定义的变量比如int a = 12345,打印到显示器的时候,显示器解析的其实是字符,即打印了五个字符,'1' 、'2'、'3'、'4'、'5',printf之所以称为格式化打印,就是将整型变量int这样的类型格式化为显示器的字符类型,才能被显示出来,而C语言的缓冲区就是用来存储格式化后的值。