相关文章:
卷积神经网络(Convolutional Neural Networks,CNN)是一种深度学习模型,专为处理具有网格拓扑结构的数据而设计,最常见的应用场景是图像数据。CNN 通过卷积操作和权值共享机制,能够有效提取数据的局部特征,同时减少模型的参数量和计算复杂度,使其在图像分类、目标检测和自然语言处理等领域表现出色。
CNN基本结构:输入层,卷积层,池化层,全连接层(MLP过程),输出层
核心概念
1、卷积(Convolution)
卷积操作是CNN的核心,其作用是提取输入数据(如图像)的局部特征。
-
卷积核(Filter,过滤器):一个小尺寸的矩阵,用于扫描输入特征图,并计算点积以提取特定特征。
-
特征图(Feature Map):卷积操作的输出,表示输入数据中某种特征的激活情况。
-
步幅(Stride):卷积核在输入特征图上移动的步长,影响输出特征图的大小。
-
填充(Padding):为保持输出与输入尺寸一致,在输入边界周围添加零值(常用“same”或“valid”填充策略)。
2、池化(Pooling)
池化层通过对特征图进行降维,减少计算量并增强特征的鲁棒性。
-
最大池化:取池化窗口内的最大值。
-
平均池化:取池化窗口内的平均值。
-
全局池化:对整个特征图取全局最大或平均值。
3、权重和参数共享
-
卷积核的参数(权重)在整个输入特征图上共享,显著减少了参数量,提高了模型的训练效率。
4、Dropout
- 一种正则化技术,用于随机丢弃一部分神经元,防止过拟合。
什么是“卷积”
卷积(Convolution)是一种数学运算,广泛应用于信号处理、图像处理和深度学习中。它的核心思想是通过卷积核(filter)在输入数据上滑动,提取局部区域的特征。在卷积神经网络(CNN)中,卷积用于从输入数据(如图像)中提取空间特征。具体来说,卷积核与输入数据通过点积操作得到一个输出特征图(Feature Map)。
(一)卷积的操作过程
以二维图像卷积为例:
-
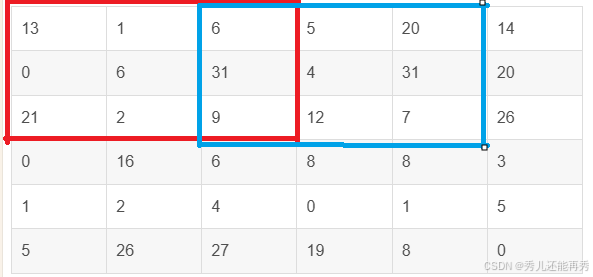
输入数据:通常是一个输入矩阵(比如,6×6的数字矩阵 ),表示图像的像素值(如灰度图的二维矩阵或RGB图像的三维矩阵)。为了保持输出特征图的尺寸与输入图像的尺寸相同,通常会在输入图像的边缘填充一些像素(常见的填充方式有“零填充”)
| 13 | 1 | 6 | 5 | 20 | 14 |
| 0 | 6 | 31 | 4 | 31 | 20 |
| 21 | 2 | 9 | 12 | 7 | 26 |
| 0 | 16 | 6 | 8 | 8 | 3 |
| 1 | 2 | 4 | 0 | 1 | 5 |
| 5 | 26 | 27 | 19 | 8 | 0 |
-
卷积核(Filter):可以理解为一个较小的矩阵(比输入矩阵小)窗口,包含需要学习的参数,常见尺寸为 3×3、5×5 等。每一个卷积核(Filter)都不一样,都含有特定的参数。在其他文章上看到,卷积核(Filter)又叫滤波器。
| w11 | w12 | w13 |
| w21 | w22 | w23 |
| w31 | w32 | w33 |
-
点积计算:将卷积核与输入数据对应位置的元素逐个相乘,然后求和,得到一个标量。
-
滑动窗口:卷积核以设定的步幅(假若Stride=2)在输入矩阵上逐点滑动。
-
输出特征图:每次点积结果组成的矩阵,表示提取到的特征。
输入矩阵通过一个卷积核(Filter)的滑动计算点积,输出一张特征图的过程,实际上达到了一种降维的效果。假如得到了特征图:
| 54 | 78 | 44 |
| 48 | 56 | 66 |
| 90 | 39 | 50 |
| 38 | 63 | 40 |
其中,该特征图的每一个元素(比如54)都是窗口在不同位置时通过点积计算得到的。
公式
二维卷积的数学表示为:
其中:
-
x(i,j):输入矩阵的像素值。
-
w(m,n):卷积核的权重。
-
y(i,j):输出特征图的值。
具体例子:

我们对每个对应位置进行相乘并求和:
S=(1×−1)+(2×0)+(3×1)+(4×−2)+(5×0)+(6×2)+(7×−1)+(8×0)+(9×1)=8
我们得到的特征图就是通过窗口滑动计算出来的多个 S 组成的矩阵。
步幅(Stride)不同,特征图尺寸就不同,往往特征图都比输入矩阵的尺寸小。
(二)卷积的特点
-
局部感受野(Receptive Field):卷积核只在局部范围内进行运算,能够捕捉输入数据的局部特征(如图像的边缘、纹理)。
-
参数共享:卷积核的参数在输入数据的整个区域上共享,从而大幅减少了模型的参数量。
-
稀疏连接:每次卷积操作只涉及输入数据的局部区域,而不是全连接方式的所有像素。
(三)卷积的作用
-
特征提取:通过卷积核可以提取输入数据的低级特征(如边缘、纹理)和高级特征(如形状、模式)。
-
降维:通过步幅,减少数据维度,降低计算复杂度。
-
增加数据的表达能力:每一层卷积提取不同层次的特征,逐步构建对数据的抽象表示。
(四)直观理解
假设我们有一个 3×3 的卷积核和一个 5×5 的输入图像:
-
将卷积核放在图像的左上角,与对应的 3×3 图像区域逐元素相乘并求和。
-
计算得到的值填入输出特征图的第一个位置。
-
移动卷积核,重复上述操作,直到覆盖整个输入图像。
什么是“池化”
池化(Pooling),又称为下采样(Down-sampling),目的是对特征图进行降维,减少数据的大小,同时保留关键信息。通过池化操作,模型可以增强特征的平移不变性,并降低计算复杂度。
(一)池化的核心思想
池化层从输入特征图中分块(窗口)操作,提取每个块的代表值(如最大值或平均值),形成新的、缩小的特征图。
(二)常见的池化方式
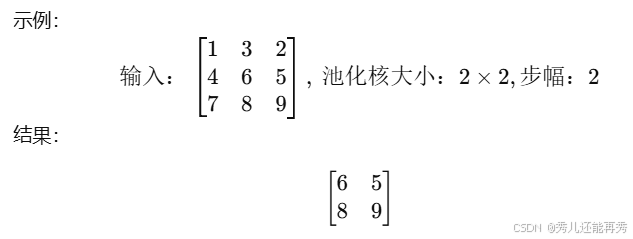
1、最大池化(Max Pooling)
-
提取池化窗口内的最大值。
-
作用:突出最显著的特征,适合捕捉边缘等局部强特征。
2、平均池化(Average Pooling)
-
计算池化窗口内所有值的平均值。
-
作用:保留特征整体的平均信息,减少噪声。
-
示例与上述类似,但每个窗口的值取平均值。
3、全局池化(Global Pooling)
-
直接对整个特征图进行全局操作,输出一个单一值(如全局最大值或全局平均值)。
-
应用:常用于替代全连接层,将二维特征图压缩为一维向量。
(三)池化的参数
1、池化窗口(Kernel Size)
-
池化操作的窗口大小,通常为 2×2 或 3×3。
2、步幅(Stride)
-
窗口在特征图上滑动的距离,步幅越大,输出特征图越小。
3、填充(Padding)
-
是否在特征图边缘填充值以适应池化操作(池化一般不需要填充)。
(四)池化的作用
1、降维:减少特征图的大小,从而降低计算复杂度和内存消耗。
2、提取主特征:通过聚合局部区域的信息,保留最重要的特征,忽略细节。
3、增强模型的鲁棒性:提升特征的平移不变性,即小范围的图像移动对池化结果影响较小。
(五)卷积和池化的对比
| 池化 | 卷积 |
|---|---|
| 无需学习参数 | 需要通过训练学习参数 |
| 固定操作(如最大值、平均值) | 可自定义卷积核操作 |
| 降维和增强特征鲁棒性 | 提取图像的复杂特征 |
CNN主要步骤
1. 输入层
输入数据: CNN 的输入通常是具有一定结构的数据,例如图像(二维或三维张量),由宽度、高度、通道数(RGB图像的三个通道)组成。
预处理:
-
标准化(Normalization):将像素值缩放到[0, 1] 或 [-1, 1]。
-
数据增强(Data Augmentation):通过旋转、缩放、裁剪等方式扩展训练数据。
-
批次加载(Batching):将数据分成小批次以加速训练。
2. 卷积层(Convolutional Layer)
核心功能: 提取局部特征。
操作流程:
-
滤波器操作:
-
使用多个小的卷积核(例如 3x3 或 5x5)在输入数据上滑动(通过步幅和填充确定滑动方式)。
-
卷积核与局部区域进行点积操作,提取特征。
-
-
输出特征图(Feature Map): 滑动完成后,生成的特征映射代表不同滤波器提取的特征。
超参数:
-
滤波器大小:决定卷积核的覆盖范围。
-
步幅(Stride):决定滑动步长,影响输出大小。
-
填充(Padding):决定是否在边缘补零,影响特征图尺寸。
3. 激活函数(Activation Function)
核心功能: 引入非线性,使模型能够表示复杂特征。
激活函数作用于卷积后的特征图,生成激活后的特征图。
4. 池化层(Pooling Layer)
核心功能: 下采样特征图,降低特征图尺寸,减少计算量和参数量。
滑动方式也由步幅和池化大小决定。
结果: 降低特征图分辨率的同时保留关键信息。
5、展平
将池化后的多维特征图展平成一维向量,作为全连接层的输入。
6、全连接层
MLP多层感知机详细过程看前一篇文章。
7、输出层
总结:输入层 → 卷积层 + 激活 → 池化层 → 卷积层 + 激活 → 池化层 → 展平 → 全连接层 → 输出层
卷积层数和池化层数根据具体情况而定。
CNN优缺点
优点
特征提取能力强:CNN通过卷积层自动提取图像的空间特征(如边缘、纹理、形状等),避免了手工设计特征的复杂性。层次化的结构能提取从低级特征(如边缘)到高级特征(如物体)的一系列特征。
参数共享:卷积核在图像上共享权重,显著减少了参数数量,与全连接网络相比更加高效。
局部连接:卷积操作利用图像的局部相关性,将计算集中在局部区域,提升模型的训练效率和性能。
对图像变换的鲁棒性:CNN对平移、缩放、旋转等变换具有较强的鲁棒性,尤其是通过数据增强和池化操作可以进一步提高这一特性。
广泛的应用领域:CNN不仅适用于图像处理,还可扩展到语音识别、文本处理、医学影像分析等领域。
缺点
对数据依赖较大:CNN需要大量标注数据进行训练,而高质量的大规模数据集通常很难获取。
计算成本高:卷积操作和反向传播的计算复杂度较高,训练CNN需要高性能的硬件(如GPU)。
解释性差:CNN是一个“黑箱模型”,其内部特征和决策过程较难直观解释,尤其是对于深层网络。
对图像位置和背景敏感“尽管有一定的鲁棒性,但CNN仍可能受到背景噪声或目标位置变化的影响。
超参数调整复杂:CNN模型设计需要设置多种超参数(如卷积核大小、层数、池化方式等),寻找最佳配置通常需要大量实验。
容易过拟合:CNN网络结构复杂,参数多,如果训练数据不足或数据分布不均匀,模型容易过拟合。
CNN以其强大的表现力和广泛的适用性在深度学习中占据了重要地位,但针对其缺点的优化也仍是研究热点。
# 若对大噶有帮助的话,希望点个赞支持一下叭!
# 文章若有错误,欢迎大家不吝赐教!