1. 认识ProtoBuf
1.1 序列化概念
序列化和反序列化
- 序列化:把对象转换为字节序列(字符串)的过程称为对象的序列化。
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化。

例如上图中有一个User结构体,将u1对象转化成str字符串就是序列化,将str序列化转化成u1就是反序列化。
什么情况下需要序列化
- 存储数据:当你想把的内存中的对象状态保存到一个文件中或者存到数据库中时。
- 网络传输:网络直接传输数据,但是无法直接传输对象,所以要在传输前序列化,传输完成后反序列化成对象。例如我们之前学习过socket编程中发送与接收数据。
如何实现序列化
xml、json、protobuf
总结:protobuf是实现序列化与反序列化的一种手段。
1.2 ProtoBuf是什么
Protocol Buffers(全称为Protocol Buffer)是Google的一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers相比于XML,是一种灵活,高效,自动化机制的结构数据序列化方法,但是比XML更小、更快、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
简单来讲,ProtoBuf是让结构数据序列化的方法,其具有以下特点:
- 语言无关、平台无关:即ProtoBuf支持Java、C++、Python等多种语言,支持多个平台。
- 高效:即比XML更小、更快、更为简单。
- 扩展性、兼容性好:你可以更新数据结构,而不影响和破坏原有的旧程序。
1.3 ProtoBuf如何使用
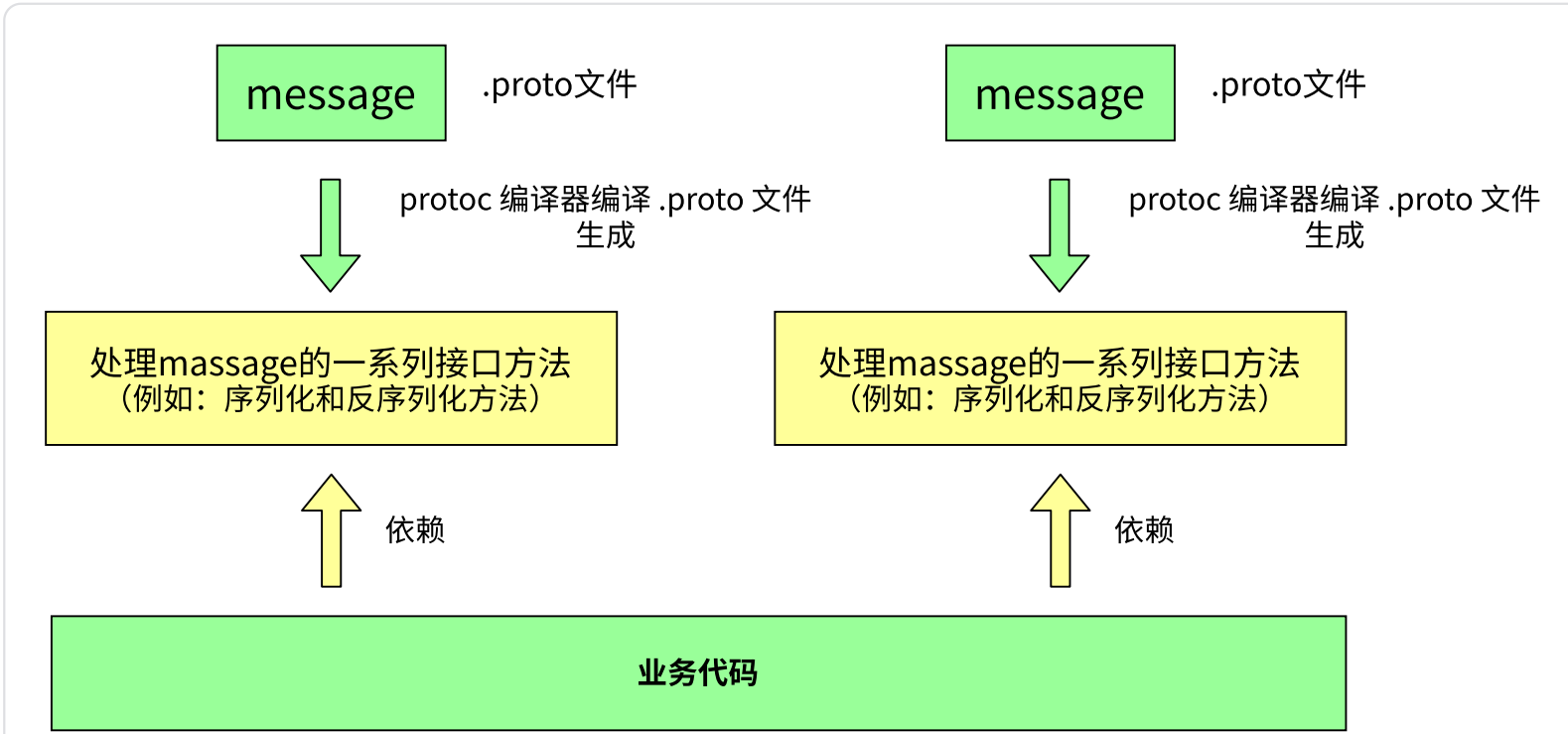
1. 编写一个.proto文件,目的是为了定义结构对象(message)及属性内容。
2. 使用protoc编译器编译.proto文件,生成一系列接口代码,存放在新生成头文件和源文件中。
3. 依赖生成的接口,将编译生成的头文件包含进我们的代码中,实现对.proto文件中定义的字段进行设置和获取,和对message对象进行序列化和反序列化。
总的来说:ProtoBuf是需要依赖通过编译生成的头文件和源文件来使用的。有了这种代码生成机制,开发人员再也不用编写那些协议解析的代码了。
2. 安装ProtoBuf
2.1 Windows平台下
下载地址:Releases · protocolbuffers/protobufReleases · protocolbuffers/protobufReleases · protocolbuffers/protobuf
以安装v21.11版本为例,找到v21.11版本,点击。
选择win64版本。
点击之后即可自动下载,下载完毕之后解压,解压完毕之后打开该文件夹,可以看到有一个bin文件夹和一个include文件夹。
我们将bin目录的地址复制下来。

打开环境变量配置,双击系统变量中的Path
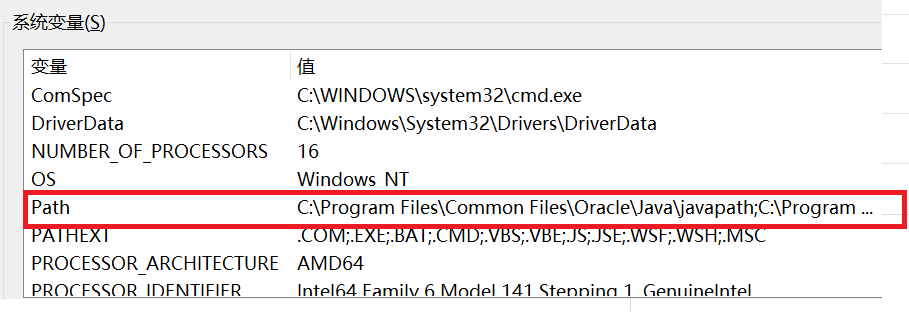
然后再点击新建,将刚才复制的地址填进去,最后点击确定即可。
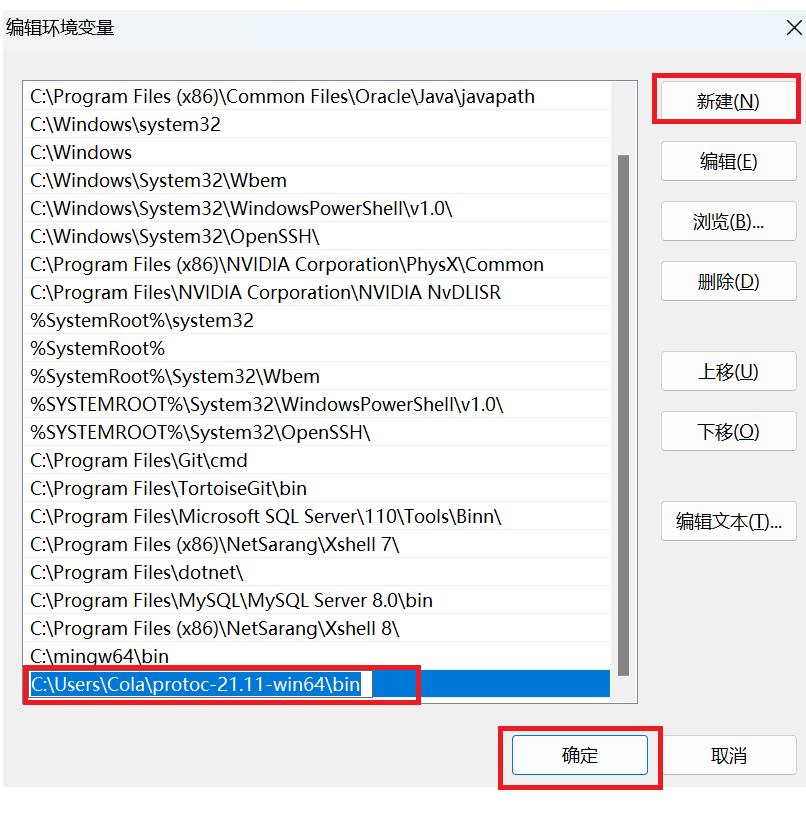
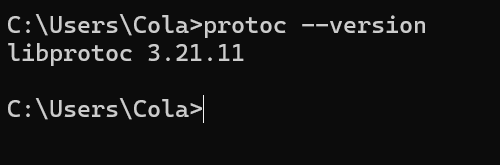
现在就已经安装完成了,我们使用cmd查看是否安装成功。
输入protoc --version,如果能正确显示版本则说明安装成功。
2.2 Linux平台下
下载ProtoBuf前要安装依赖库:autoconf automake libtool curl make g++ unzip如未安装,安装命令如下:
Ubuntu用户选择:
sudo apt-get install autoconf automake libtool curl make g++ unzip -yCentos用户选择:
sudo yum install autoconf automake libtool curl make gcc-c++ unzip -y下载完之后就可以正式来安装ProtoBuf了,下载地址:ProtoBuf下载
同样,还是以21.11版本演示:
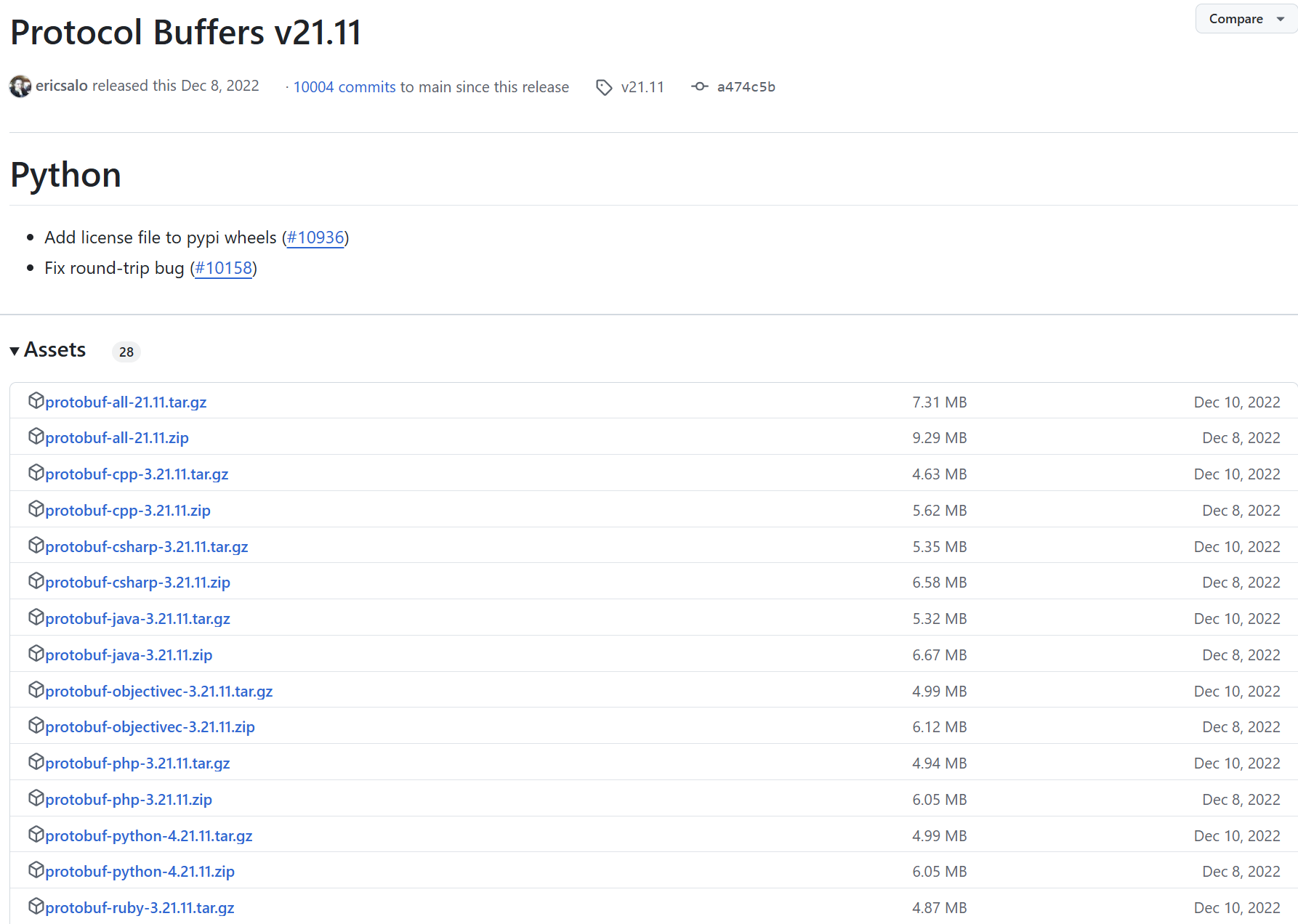
- 如果要在C++下使用ProtoBuf,可以选择cpp.zip;
- 如果要在JAVA下使用ProtoBuf,可以选择java.zip;
- 其他语言选择对应的链接即可。
- 希望支持全部语言,选择all.zip。
在这里我们希望支持全部语言,所以选择protobuf-all-21.11.zip,右键将下载链接复制出来。
下载命令:
wget https://github.com/protocolbuffers/protobuf/releases/download/v21.11/protobuf-all-21.11.zip下载完成后,解压zip包:
unzip protobuf-all-21.11.zip解压完成后,会生成protobuf-21.11文件,进入文件:
cd protobuf-21.11内容如下:
进入解压好的文件,执行以下命令:
1)第一步执行autogen.sh,但如果下载的是具体的某一门语言,不需要执行这⼀步
./autogen.sh2)第二步执行configure,有两种执行方式,任选其一即可,如下:
1、protobuf默认安装在 /usr/local 目录,lib、bin都是分散的
./configure2、修改安装目录,统一安装在/usr/local/protobuf下
./configure --prefix=/usr/local/protobuf再依次执行:
make
make check
sudo make install注意:在执行make check过程中可能会出现如下问题
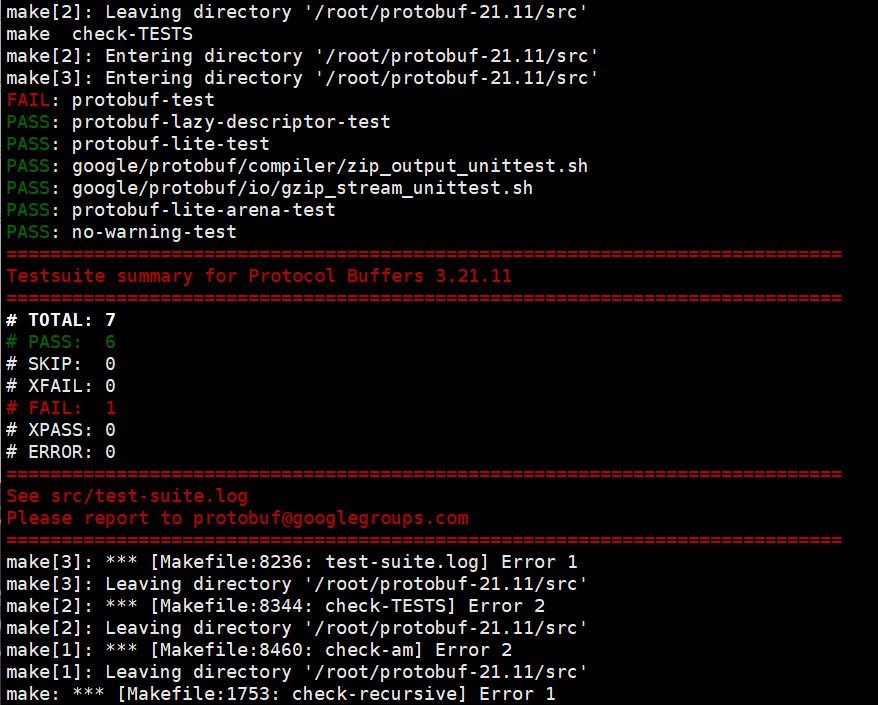
出现以上错误的原因是test的模块里面有非常多的测试用例,这些用例对服务器环境要求特别严格,需要增大下swap分区,具体操作可参考:Ubuntu 18.04 swap分区扩展_ubuntu18.04 如何查看swapfile文件路径-CSDN博客
(建议可以先扩大3G,再执行make check 。如果还是报错,再扩大到5G重新执行make check )
执行make check 后,出现以下内容就可以执行sudo make install。
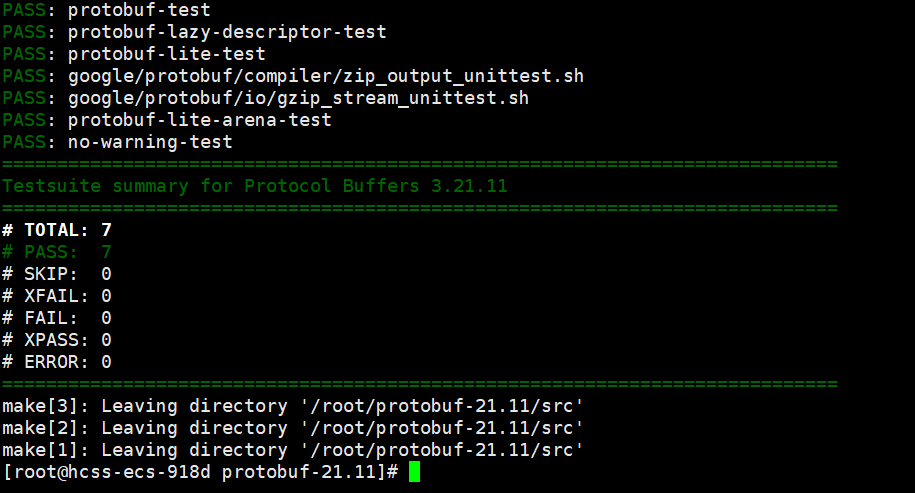
到此,需要你回忆⼀下在执行configure时,如果当时选择了第一种执行方式,也就是./configure ,那么到这就可以正常使用protobuf了。如果选择了第⼆种执行方式,即修改了安装⽬录,那么还需要在/etc/profile中添加⼀些内容:
sudo vim /etc/profile将下面内容添加进去
# 添加内容如下:
#(动态库搜索路径) 程序加载运⾏期间查找动态链接库时指定除了系统默认路径之外的其他路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/protobuf/lib/
#(静态库搜索路径) 程序编译期间查找动态链接库时指定查找共享库的路径
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/protobuf/lib/
#执⾏程序搜索路径
export PATH=$PATH:/usr/local/protobuf/bin/
#c程序头⽂件搜索路径
export C_INCLUDE_PATH=$C_INCLUDE_PATH:/usr/local/protobuf/include/
#c++程序头⽂件搜索路径
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:/usr/local/protobuf/include/
#pkg-config 路径
export PKG_CONFIG_PATH=/usr/local/protobuf/lib/pkgconfig/
最后⼀步,重新执行/etc/profile文件:
source /etc/profile检查是否安装成功
输入protoc --version查看版本,有显示说明安装成功。

3. 快速上手
在快速上手中,会编写第一版本的通讯录1.0。在通讯录1.0版本中,将实现:
- 对⼀个联系人的信息使用ProtoBuf进行序列化,并将结果打印出来。
- 对序列化后的内容使用PB进行反序列,解析出联系人信息并打印出来。
- 联系人包含以下信息:姓名、年龄。
通过通讯录1.0,我们便能了解使用ProtoBuf初步要掌握的内容,以及体验到ProtoBuf的完整使用流程。
3.1 编写contacts.proto文件
在编写contacts.proto文件时需要注意以下几点
1)文件规范
- 创建.proto文件时,文件命名应该使用全小写字母命名,多个字母之间用_连接。例如:lower_snake_case.proto。
- 书写.proto文件代码时,应使用2个空格的缩进。
我们为通讯录1.0新建文件:contacts.proto
2)添加注释
向文件添加注释,可使用 // 或者 /* ... */
3)指定proto3语法
在.proto文件中,要使用 syntax = "proto3"; 来指定文件语法为proto3,并且必须写在除去注释内容的第一行。如果没有指定,编译器会使用proto2语法。
在通讯录1.0的contacts.proto文件中,可以为文件指定proto3语法,内容如下:
syntax = "proto3";4)package声明符
package是一个可选的声明符,能表示.proto文件的命名空间,在项目中要有唯一性。它的作用是为了避免我们定义的消息出现冲突。当设置了package之后,通过ProtoBuf编译器得到的.c和.h文件中的对象就是保存在该命名空间下。
在通讯录1.0的contacts.proto文件中,可以声明其命名空间,内容如下:
syntax = "proto3";
package contacts;5)定义消息(message)
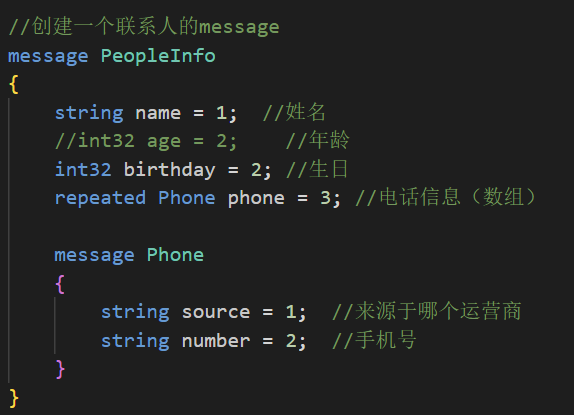
消息(message):要定义的结构化对象,我们可以给这个结构化对象中定义其对应的属性内容(类似于C语言中的结构体)。
所以ProtoBuf就是以message的方式来支持我们定制协议字段,后期帮助我们形成类和方法来使用。在通讯录1.0中我们就需要为联系人定义⼀个message,其中包括姓名和年龄字段,内容如下:
syntax = "proto3";
package contacts;
// 定义联系⼈消息
message PeopleInfo
{
}
6)定义消息字段
在message中我们可以定义其属性字段,字段定义格式为:字段类型字段名=字段唯⼀编号;
• 字段名称命名规范:全小写字母,多个字母之间用_连接。
• 字段类型分为:标量数据类型和特殊类型(包括枚举、其他消息类型等)。
• 字段唯一编号:用来标识字段,一旦开始使用就不能够再改变。
该表格展示了定义于消息体中的标量数据类型,以及编译.proto文件之后自动生成的类中与之对应的字段类型。在这里展示了与C++语言对应的类型。
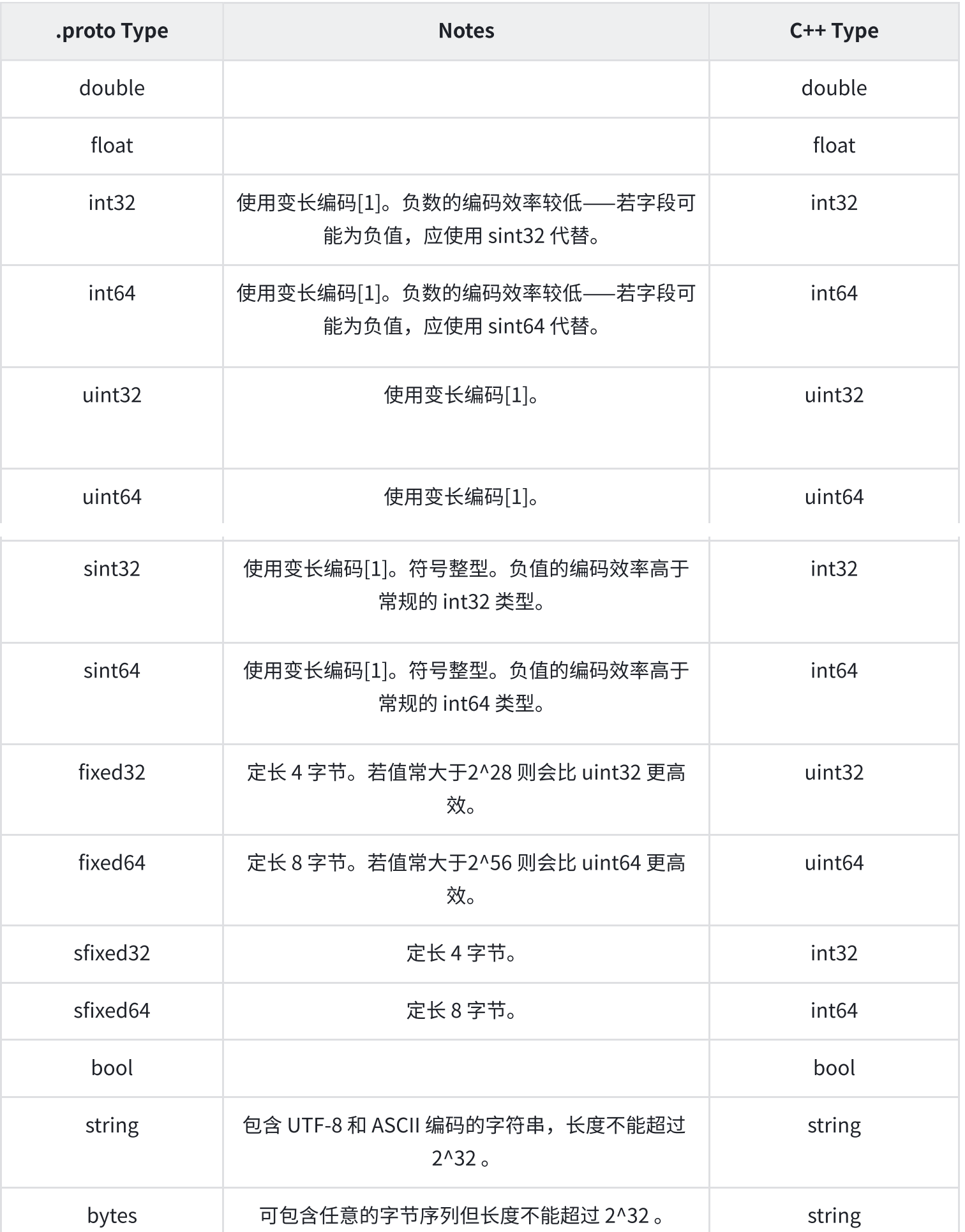
[1]变长编码是指:经过protobuf编码后,原本4字节或8字节的数可能会被变为其他字节数。
更新contacts.proto(通讯录1.0),新增姓名、年龄字段:
//指定proto3语法
syntax = "proto3";
//声明命名空间
package contacts;
//创建命为PeopleInfo的message对象
message PeopleInfo
{
string name = 1; //姓名
int32 age = 2; //年龄
}注意这里的 = 号并不是赋值的意思,而是给他们编号
在这里还要特别讲解一下字段唯一编号的范围:1~536,870,911(2^29-1),其中19000~19999不可用。
19000~19999不可用是因为:在Protobuf协议的实现中,对这些数进行了预留。如果非要在.proto文件中使用这些预留标识号,例如将name字段的编号设置为19000,编译时就会报警。
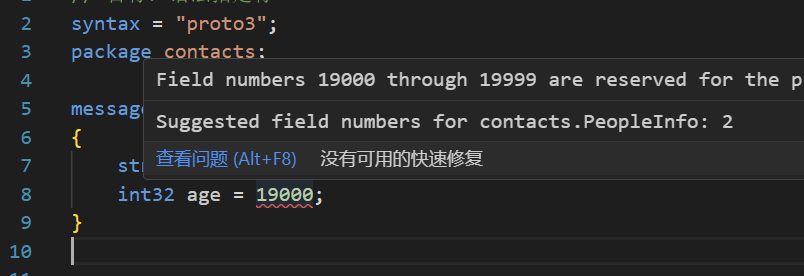
值得一提的是,范围为1~15的字段编号需要⼀个字节进行编码,16~2047内的数字需要两个字节进行编码。编码后的字节不仅只包含了编号,还包含了字段类型。所以1~15要用来标记出现非常频繁的字段,要为将来有可能添加的、频繁出现的字段预留⼀些出来。
3.2 编译contacts.proto文件,生成C++文件
编译的命令行格式为:
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
- protoc:Protocol Buffer 提供的命令行编译工具。
- --proto_path:指被编译的.proto文件所在目录,可多次指定。可简写成 -I。当某个.proto文件 import 其他.proto文件时,或需要编译的.proto文件不在当前目录下,这时就要用-I来指定搜索目录。
- IMPORT_PATH :如不指定该参数,则在当前目录进行搜索。
- --cpp_out= 指编译后的文件为 C++ ⽂件。
- OUT_DIR 编译后生成文件的目标路径。
- path/to/file.proto 要编译的.proto文件
编译contacts.proto⽂件命令如下:
protoc --cpp_out=. contacts.proto编译完成之后
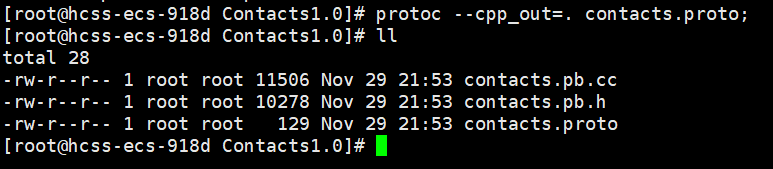
编译后生成了两个文件: contacts.pb.h contacts.pb.cc 。
对于编译生成的C++代码,包含了以下内容:
1)对于每个message,都会生成一个对应的消息类。
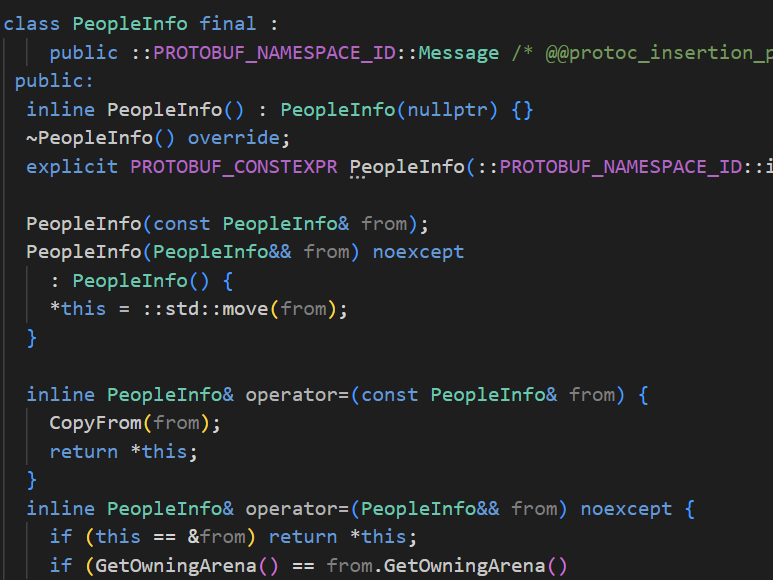
2)在消息类中,编译器为每个字段提供了获取和设置方法,以及⼀下其他能够操作字段的方法。
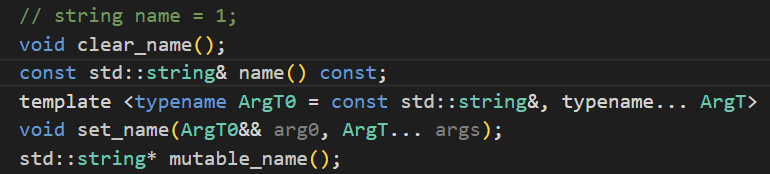
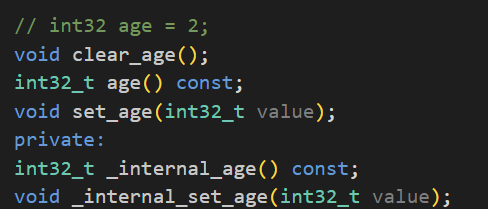
- 1) 其中的name()和age()会返回PeopleInfo对象中name和age的值
- 2) set_name()和set_age()用于设置PeopleInfo对象中的name和age的值
- 3) clear_name()和clear_age()用于清除name和age的值
- 4) mutable_xxx() :获取当前字段的地址,对于自定义类型来说protoc不会为其生成set_xxx()的方法来设置值,因为它没办法预测用户到底想如何给自定义类型设置值,但是它会生成对应的mutable_xxx()函数,利用mutable_xxx()函数我们可以获取到当前字段的地址,然后再利用字段的内置set_xxx()方法进行对自定义类型中的各个字段进行初始化,对于protobuf内置的类型protoc不会为其生成mutable_xxx()方法,当然string等除外,这些基本类型利用set_xxx()方法就能够设置值了。
3)编辑器会针对于每个 .proto 文件生成 .h 和 .cc 文件,分别用来存放类的声明与类的实现。
序列化和反序列化的代码放在消息类的父类 MessageLite 中,提供了读写消息实例的放法,包括序列化方法和反序列化方法。
.proto中各个元素对应生成的代码关系:
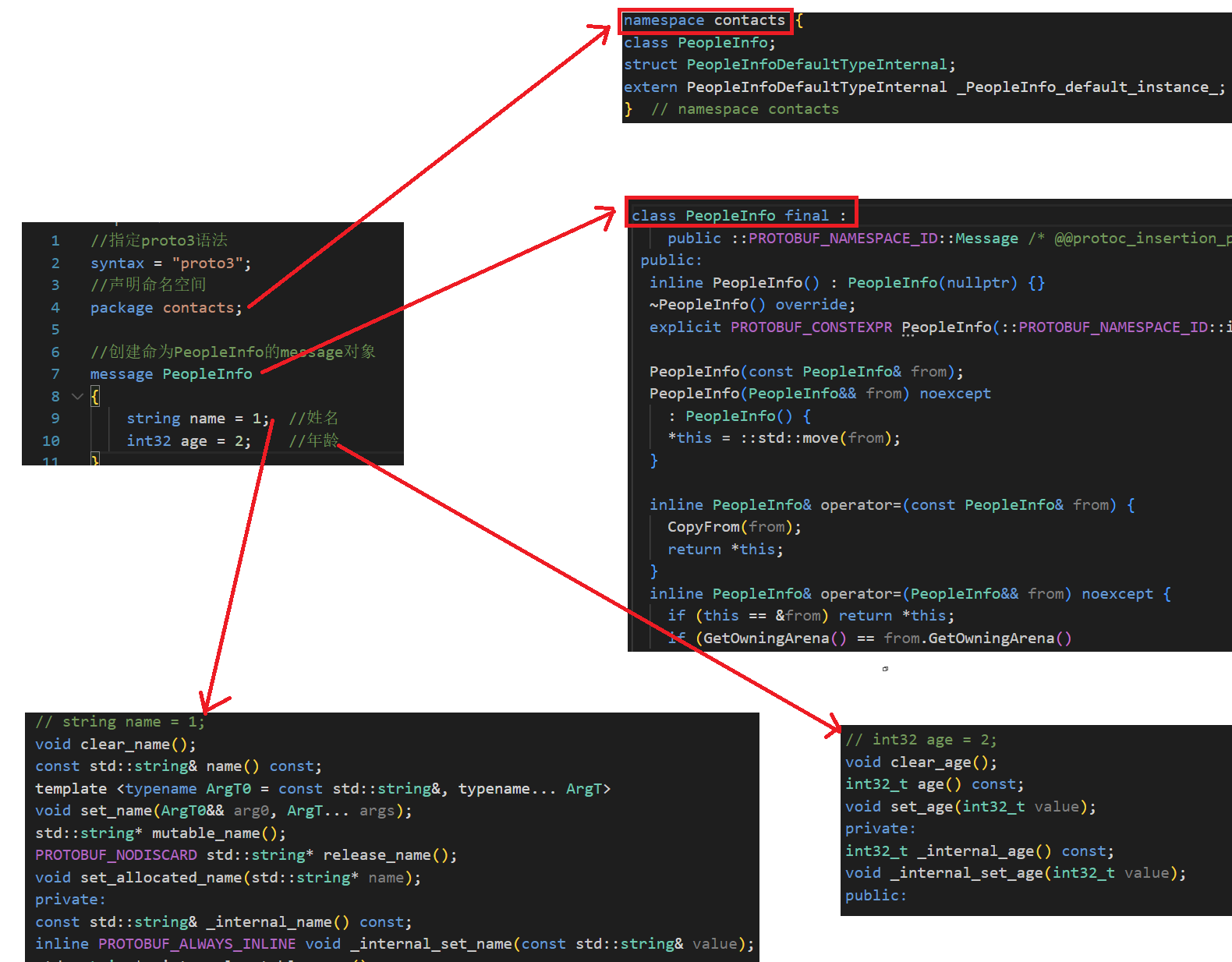
在查看.pb.h文件时,你可以看到PeopleInfo对象,以及其中的name和age字段,但是最重要的序列化和反序列化代码却找不到。
其中protobuf是通过继承的方式:让PeopleInfo继承Message对象,Message对象继承MessageLite对象,而MessageLite对象中包含很多序列化和反序列化的函数。

以下是一些比较常用的序列化和反序列化的方法。
class MessageLite
{
public:
//序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写⼊⽂件流
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进⾏反序列化动作
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};注意:
- 1)序列化的结果为二进制字节序列,而非文本格式。(所以序列化之后的结果往往是我们看不懂的)
- 2)以上三种序列化的方法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应用场景使用。
- 3)序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容,而是将序列化的结果保存到函数入参指定的地址中。
- 4)详细messageAPI可以参见完整列表
3.3 序列化与反序列化的使用
创建⼀个测试文件main.cc,方法中我们实现:
- 1)对一个联系人的信息使用PB进行序列化,并将结果打印出来。
- 2)对序列化后的内容使用PB进行反序列,解析出联系人信息并打印出来。
#include <iostream>
#include "contacts.pb.h"
using namespace std;
int main()
{
//存储序列化之后的结果 / 将序列化得到的字符串反序列化成对象
string people_message;
//1.对一个联系人的信息使用PB进行序列化,并将结果打印出来。
contacts::PeopleInfo people_out;
people_out.set_name("张三");
people_out.set_age(18);
//将序列化的结果保存至people_out_message中
if (people_out.SerializeToString(&people_message) == false)
{
cout << "序列化失败" << endl;
return -1;
}
cout << "序列化成功结果为:[" << people_message << "]" << endl;
//2.对序列化后的内容使用PB进行反序列,解析出联系人信息并打印出来。
contacts::PeopleInfo people_in;
//将people_message中的内容反序列化到对象中
if (people_in.ParseFromString(people_message) == false)
{
cout << "反序列化失败" << endl;
return -1;
}
cout << "反序列化成功" << endl;
cout << "name: " << people_in.name() << endl;
cout << "age: " << people_in.age() << endl;
return 0;
}
编写完代码之后,编译main.cc,生成可执行程序TestProtoBuf,编译命令如下:
g++ main.cc contacts.pb.cc -o TestProtoBuf -std=c++11 -lprotobuf注意:
- 1.不要忘记编译main.cc时需要带上contacts.pb.cc。
- 2.-lprotobuf:必加,不然会有链接错误。
- 3.std=c++11:必加,使用C++11语法。
当编译完成之后,生成了可执行程序TetsProtoBuf,我们来运行一下
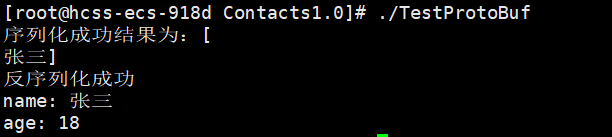
由于ProtoBuf是把联系人对象(PeopleInfo)序列化成了二进制序列,这里用string来作为接收二进制序列的容器。所以在终端打印的时候会有换行等⼀些乱码显示。
所以相对于xml和JSON来说,因为被编码成二进制,破解成本增大,ProtoBuf编码是相对安全的。
我们现在再回过头来看ProtoBuf如何使用那一节中的内容就有非常直观的体现了。
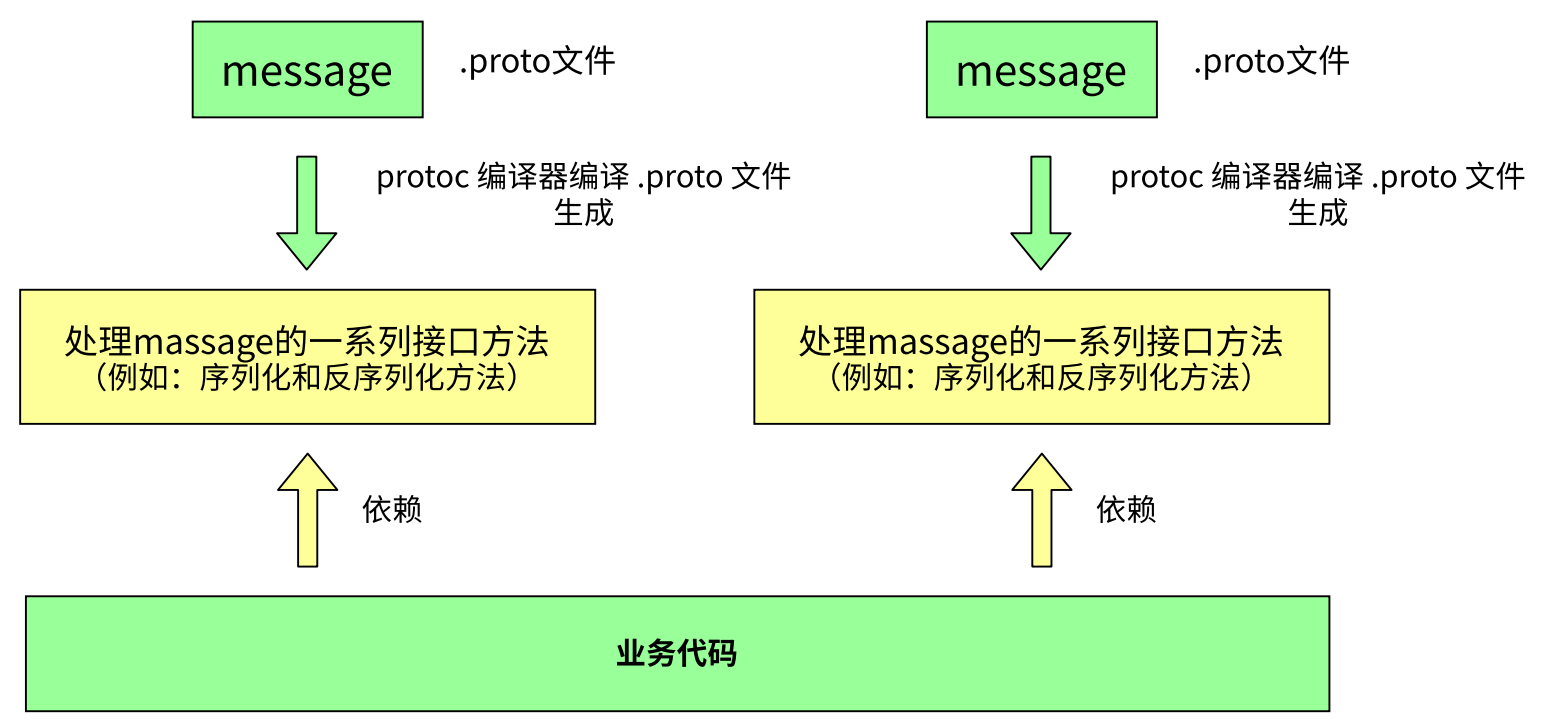
- 1. 编写.proto文件,目的是为了定义结构对象(message)及属性内容。
- 2. 使用protoc编译器编译.proto文件,生成⼀系列接口代码,存放在新生成头文件和源文件中。
- 3. 依赖生成的接口,将编译生成的头文件包含进我们的代码中,实现对.proto文件中定义的字段进行设置和获取,和对message对象进行序列化和反序列化。
4. proto3语法详解
在该部分内容中,会介绍proto3的一些常见语法,通过这些语法对通讯录进行多次升级,完成通讯录的2.0版本,最终将会升级如下内容:
- • 不再打印联系人的序列化结果,而是将通讯录序列化后并写入文件中。
- • 从文件中将通讯录解析出来,并进行打印。
- • 新增联系人属性,共包括:姓名、年龄、电话信息、地址、其他联系方式、备注。
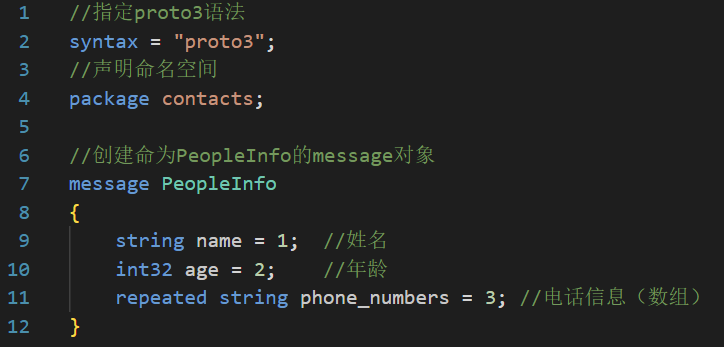
4.1 字段规则
消息的字段可以用下面两种规则来修饰:
- • singular:消息中可以包含该字段零次或一次(不超过一次)。proto3语法中,字段默认使用该
- 规则。
- • repeated:消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理
- 解为定义了一个数组。
在实际生活中,一个人可能会存在有多个手机号的情况,所以联系人中的手机号可以设置为repeated类型。
4.2 消息类型的定义与使用
在单个.proto文件中可以定义多个消息体,且支持定义嵌套类型的消息(任意多层)。每个消息体中的字段编号可以重复。
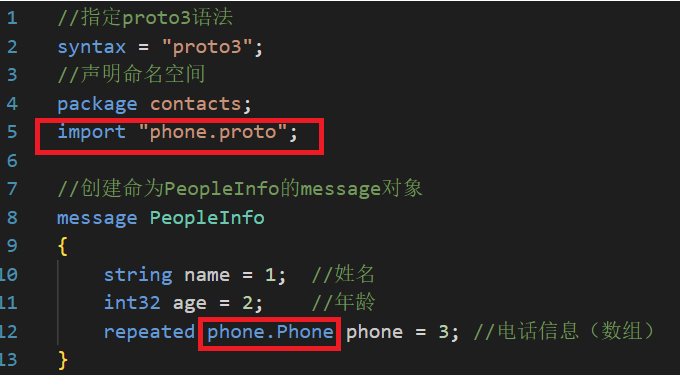
电话信息除了包含手机号还有可能包含其他内容,如这个手机号对应的运营商(移动,电信)等,那么我们在将phone_numbers设置为repeated的基础上,把他设置为一个message类型,这样他就可以表示更多信息。
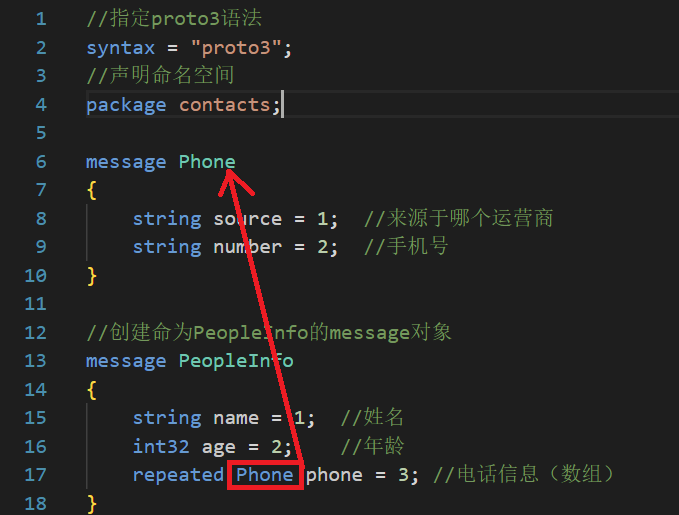
上面这种写法是非嵌套定义,protobuf还支持嵌套定义
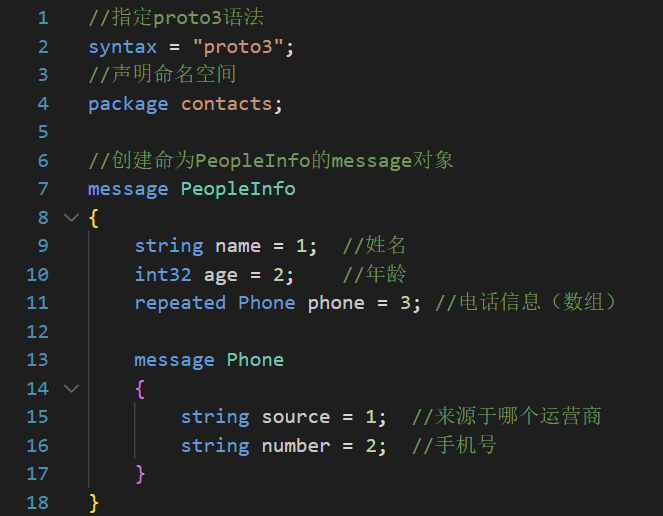
protobuf还可导入其他.proto文件的消息并使用
假如phone.proto中有一个Phone消息,我们想在contacts.proto文件中使用
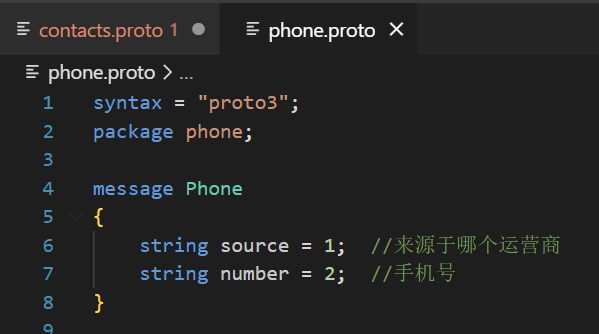
使用import导入phone.proto文件,并且不要忘记添加命名空间。
4.2.1 创建通讯录2.0版本
4.3.2.1 编写.proto文件
通讯录2.x的需求是向文件中写入通讯录列表,以上我们只是定义了一个联系人的消息,并不能存放通讯录列表,所以还需要添加一个通讯录列表message,在完善一下contacts.proto(终版通讯录2.0):
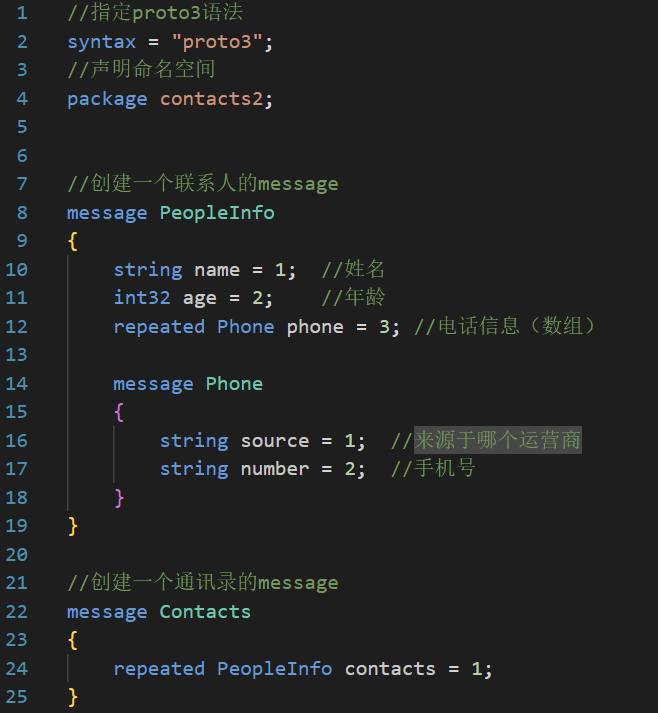
编写好了.proto文件,接下来编译生成.pb.cc文件和.pb.h文件。

我们打开.pb.h文件,可以三个message被转化成了C++中的类
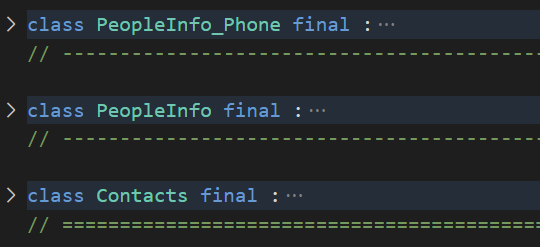
我们重点来看一下PeopleInfo中的phone对象。
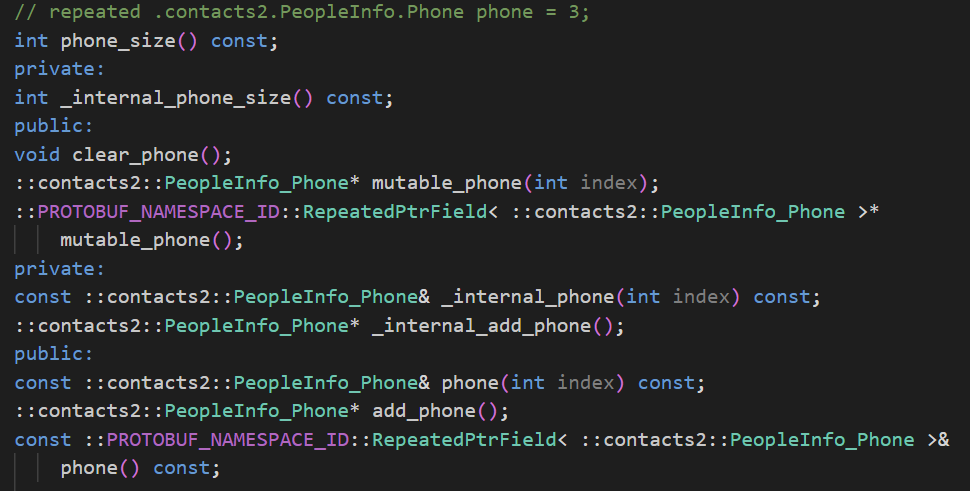
因为phone可以看成一个数组,所以和前面介绍的name和age的接口不太一样。
- phone_size():返回数组的大小
- clear_phone():清空数组
- add_phone():返回一个已经开辟好的空间(数组内部会插入一个新创建的PeopleInfo_Phone对象,并将该对象的地址返回,我们直接修改该对象的属性字段即可)。
- mutable_phone(int index):返回index下标对应的空间,返回值同add_phone()(将对象插入到数组index下标位置处)
- phone(int index):返回index下标的元素值
- phone():返回整个数组
通讯录类中的contacts和上面PeopleInfo中的phone对象接口是一样的,这里不过多赘述了。
4.3.2.2 通讯录2.0写入实现
接下来我们实现通讯录2.0版本,内容如下:
- • 不再打印联系人的序列化结果,而是将通讯录序列化后并写入文件中。
- • 从文件中将通讯录解析出来,并进行打印。
- • 新增联系人属性,共包括:姓名、年龄、电话信息(包括电话号码和运营商)。
先实现从文件中将通讯录解析出来并放到contacts对象中,然后添加联系人,最后写回文件中。
#include <iostream>
#include <fstream>
#include <string>
#include "contacts.pb.h"
using namespace std;
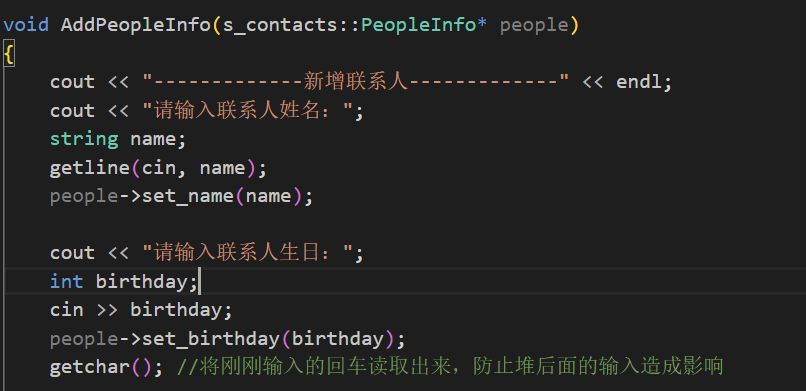
void AddPeopleInfo(contacts2::PeopleInfo* people)
{
cout << "-------------新增联系人-------------" << endl;
cout << "请输入联系人姓名:";
string name;
getline(cin, name);
people->set_name(name);
cout << "请输入联系人年龄:";
int age;
cin >> age;
people->set_age(age);
getchar(); //将刚刚输入的回车读取出来,防止堆后面的输入造成影响
for (int i = 1; ; i++)
{
cout << "请输入联系人电话" << i << "(只输入回车完成电话新增):";
string number;
getline(cin, number);
if (number.empty())
{
break;
}
cout << "请输入联系人电话" << i << "的运营商:";
string source;
getline(cin, source);
contacts2::PeopleInfo_Phone* phone = people->add_phone();
phone->set_number(number);
phone->set_source(source);
}
cout << "-----------添加联系人成功-----------" << endl;
}
int main()
{
//通讯录对象
contacts2::Contacts contacts;
//将contacts.bin文件中的内容反序列化到contacts对象中
fstream input("contacts.bin", ios::in | ios::binary);
if (!input)
{
cout << "未找到contacts.bin文件, 创建一个新文件" << endl;
}
else if (!contacts.ParsePartialFromIstream(&input)) //通过文件流反序列化到contacts
{
cout << "反序列化失败" << endl;
input.close();
return -1;
}
//添加一个联系人
AddPeopleInfo(contacts.add_contacts()); //返回一个创建好的PeopleInfo*空间,直接填充字段
//将contacts写回文件当中
fstream output("contacts.bin", ios::out | ios::trunc | ios::binary);
if (!contacts.SerializePartialToOstream(&output)) //将contacts序列化写入文件中
{
cout << "序列化失败" << endl;
input.close();
output.close();
return -2;
}
//序列化成功
cout << "序列化成功" << endl;
input.close();
output.close();
return 0;
}写完代码之后,测试一下
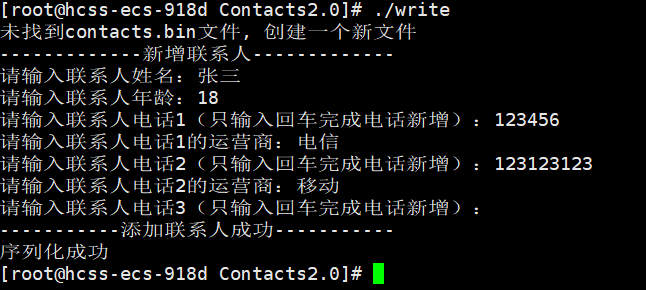
最后显示将结果写入到了contacts.bin文件中,那么我们就查看一下该文件。
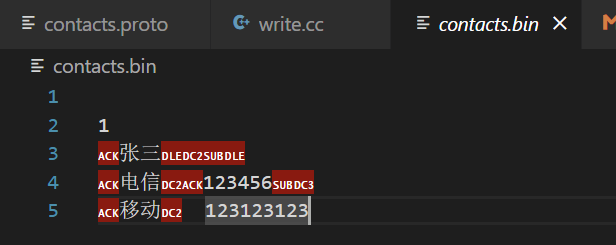
我们可以使用hexdump将二进制文件转化成十六进制来看看。
hexdump:是Linux下的一个二进制文件查看工具,它可以将二进制文件转换为ASCII、八进制、十进制、十六进制格式进行查看。
-C: 表示每个字节显示为16进制和相应的ASCII字符。

由于我们将联系人的信息都写进文件当中,所以重新打开程序,联系人的信息也不会消失。我们再额外添加一个联系人。
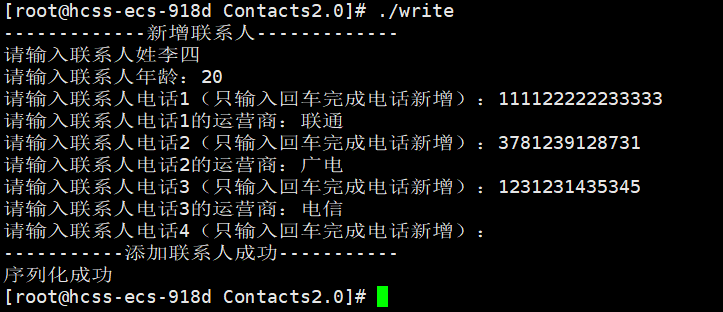
contacts.bin文件内容如下:
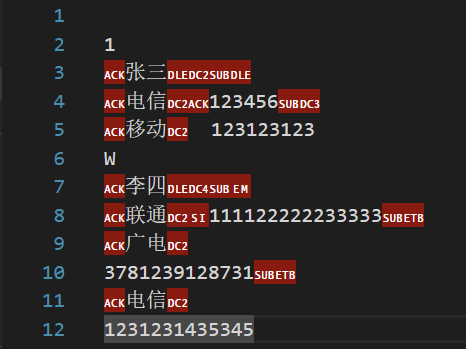
可以看到张三的信息还在,李四的信息也成功添加进去了。
4.3.2.3 通讯录2.0读取实现
上面像通讯录中添加联系人的过程,现在我们还需要读取通讯录。
只需要将文件中的内容读取到contacts对象中,然后写一个打印函数即可。
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
void PrintContacts(contacts2::Contacts contacts)
{
for (int i = 0; i < contacts.contacts_size(); i++)
{
contacts2::PeopleInfo people = contacts.contacts(i);
cout << "------------联系人" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
for (int j = 0; j < people.phone_size(); j++)
{
cout << "电话" << j+1 << ":" << people.phone(j).number() << " 运营商:" << people.phone(j).source() << endl;
}
cout << endl << endl;
}
}
int main()
{
//通讯录对象
contacts2::Contacts contacts;
//读取contacts.bin文件,将内容反序列化到contacts对象中
fstream input("contacts.bin", ios::in | ios::binary);
if (!input.is_open())
{
cout << "打开文件失败" << endl;
return -1;
}
else if (!contacts.ParsePartialFromIstream(&input))
{
cout << "反序列化失败" << endl;
input.close();
return -2;
}
//打印通讯录->所有用户信息
PrintContacts(contacts);
input.close();
return 0;
}编译成功之后直接运行。
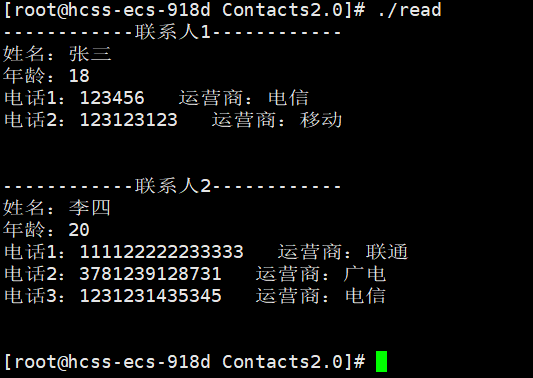
可以看到我们刚刚写的内容被成功展示出来了。
4.3.2.4 decode
如果觉得编写读取的代码太麻烦,可以使用protobuf提供的命令来展示二进制文本。
我们可以用 protoc -h 命令来查看ProtoBuf为我们提供的所有命令option。
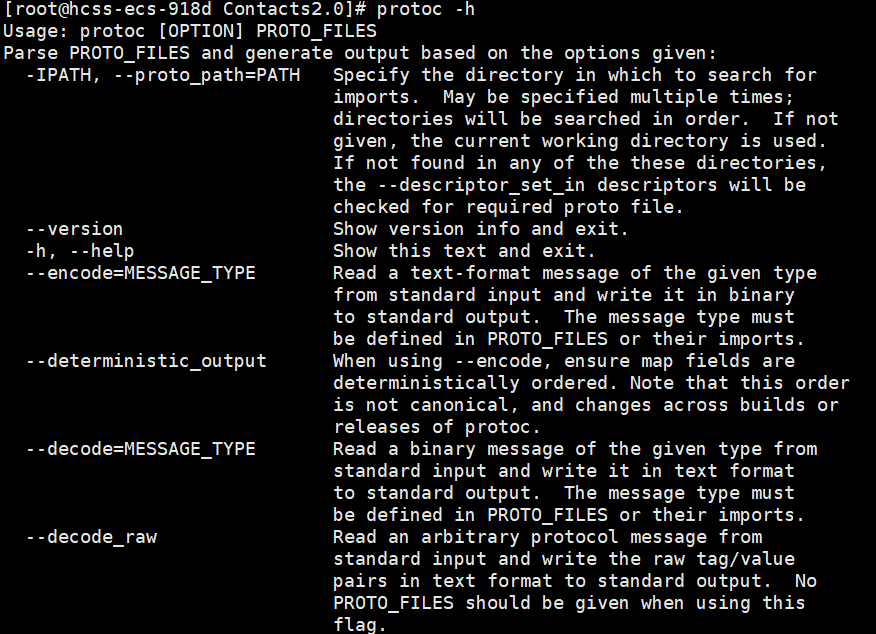
其中ProtoBuf提供⼀个命令选项 --decode ,表示从标准输入中读取给定类型的二进制消息,并将其以文本格式写入标准输出。消息类型必须在.proto文件或导入的文件中定义。
protoc --decode=contacts2.Contacts contacts.proto < contacts.bin
使用该命令就能成功将二进制文本显示出来。
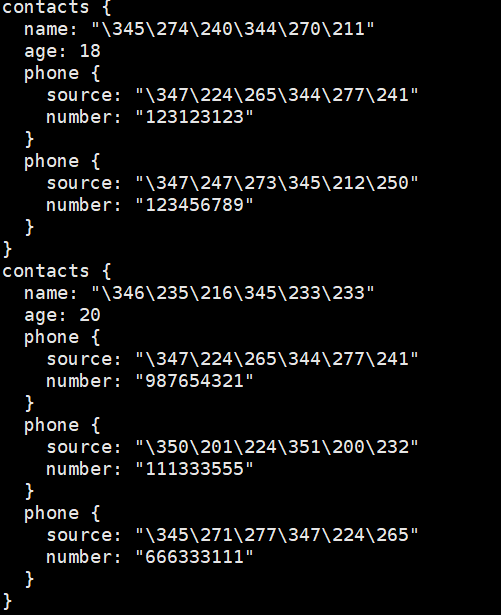
4.3 enum类型
我们可以定义一个名为PhoneType的枚举类型,定义如下:

要注意枚举类型的定义有以下几种规则:
- 1. 0值常量必须存在,且要作为第一个元素。这是为了与proto2的语义兼容:第一个元素作为默认值,且值为0。
- 2. 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
- 3. 枚举的常量值在32位整数的范围内。但因负值无效因而不建议使用(与编码规则有关)。
定义时需要注意以下问题:
将两个具有相同枚举常量名称的枚举类型放在单个.proto文件下测试时,编译后会报错:某某某常量已经被定义!所以这要注意:
- 同级(同层)的枚举类型,各个枚举类型中的常量不能重名(同层的两个枚举类型中,也不能出现同名的枚举常量)。
- 单个.proto文件下,最外层枚举类型和嵌套枚举类型,不算同级。
- 多个.proto文件下,若一个文件引入了其他文件,且每个文件都未声明package,每个proto文件中的枚举类型都在最外层,算同级,会编译报错。
- 多个.proto文件下,若一个文件引入了其他文件,且每个文件都声明了package,不算同级,不会编译报错。
4.3.1 通讯录2.1版本
在2.0版本中,我们将运营商的类型设置为string类型是不太合理的,因为运营商总共就那么几个,所以我们将他改成枚举类型。

默认值为常量值为0的那个枚举常量,如果有一个Phone类型的对象没有设置source那么他的source值就默认为CT。
编译完成之后我们打开.pb.h文件查看生成的枚举类型长什么样子。
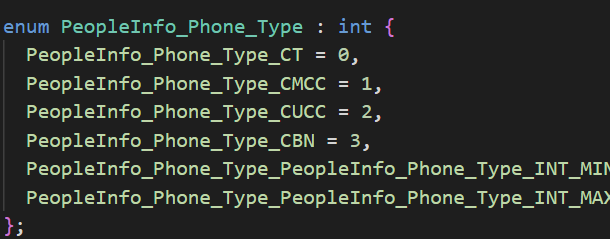
我们再来查看以下枚举对象有哪些函数。
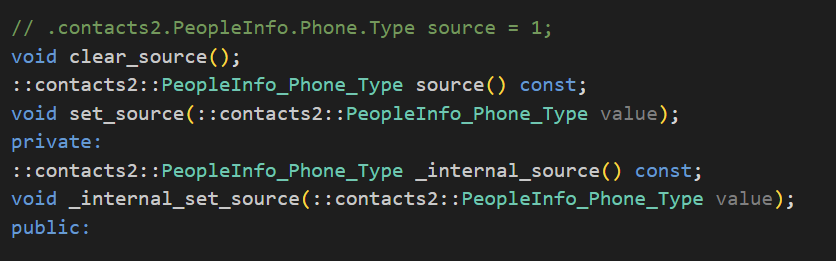
- clear_source():清空枚举字段
- source():获取枚举值
- set_source():设置枚举值
在通讯录2.0的基础上,修改以下AddPeopleInfo函数即可。
void AddPeopleInfo(contacts2::PeopleInfo* people)
{
cout << "-------------新增联系人-------------" << endl;
cout << "请输入联系人姓名:";
string name;
getline(cin, name);
people->set_name(name);
cout << "请输入联系人年龄:";
int age;
cin >> age;
people->set_age(age);
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
for (int i = 1; ; i++)
{
cout << "请输入联系人电话" << i << "(只输入回车完成电话新增):";
string number;
getline(cin, number);
if (number.empty())
{
break;
}
contacts2::PeopleInfo_Phone* phone = people->add_phone();
phone->set_number(number);
RCHOISE:
cout << "请输入运营商: 1.电信 2.移动 3.联通 4.广电" << endl;
int source;
cin >> source;
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
switch(source)
{
case 1 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CT);
break;
case 2 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CMCC);
break;
case 3 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CUCC);
break;
case 4 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CBN);
break;
default :
cout << "输入失败,请重新输入" << endl;
goto RCHOISE;
break;
}
}
cout << "-----------添加联系人成功-----------" << endl;
}同样的读取通讯录的代码也需要修改。
void PrintContacts(contacts2::Contacts contacts)
{
for (int i = 0; i < contacts.contacts_size(); i++)
{
contacts2::PeopleInfo people = contacts.contacts(i);
cout << "------------联系人" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
for (int j = 0; j < people.phone_size(); j++)
{
contacts2::PeopleInfo_Phone phone = people.phone(j);
cout << "电话" << j+1 << ":" << phone.number()
<< " 运营商:" << phone.Type_Name(phone.source()) << endl;
//phone.source会返回枚举值(int类型)可通过Type_Name函数将int类型转化成字符串
}
cout << endl << endl;
}
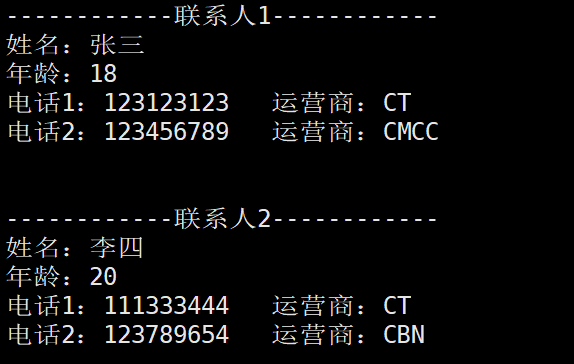
}修改完之后,再次运行代码,可以看到运营商栏目就修改成了4个可选项,如果选择其他的就会出错,并让你重新输入。

读取函数修改完之后,如下所示:
4.4 Any类型
字段还可以声明为Any类型,可以理解为泛型类型。使用时可以在Any中存储任意消息类型。Any类型的字段也用repeated来修饰。
Any类型是google已经帮我们定义好的类型,在安装ProtoBuf时,其中的include目录下查找所有google已经定义好的.proto文件。
我们打开any.proto查看,可以看到Any其实就是一个message。
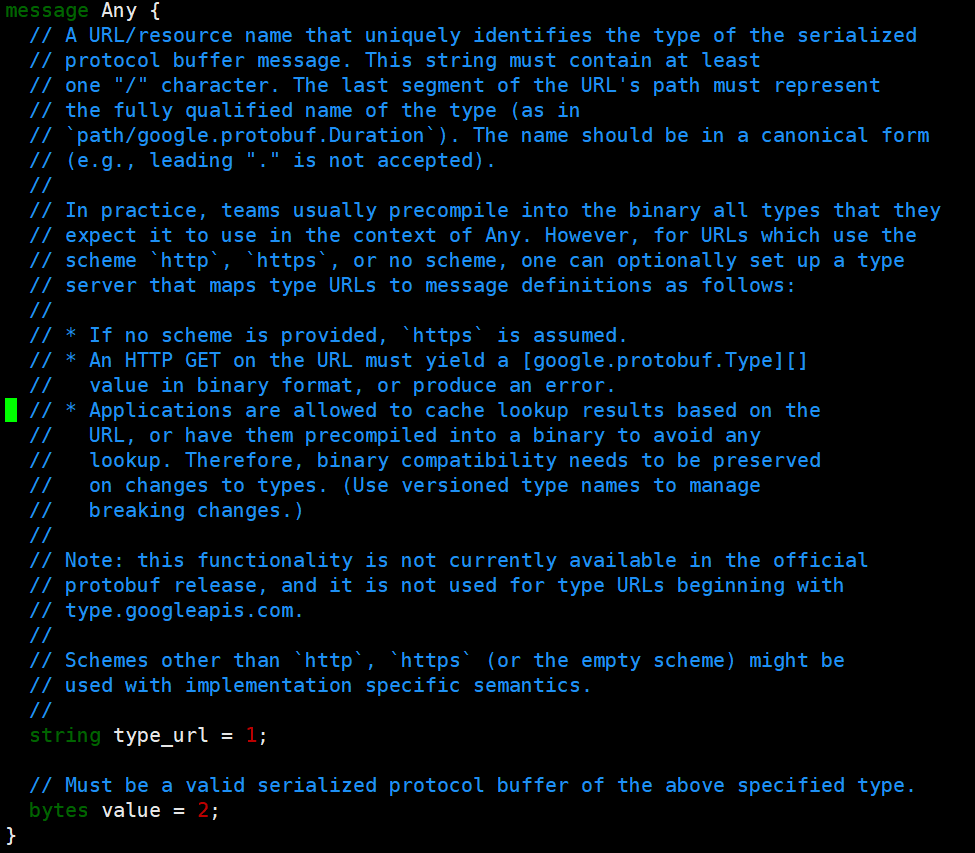
接下来我将会给通讯录添加一个any字段表示地址,地址有家庭住址和单位地址,所以地址其实要设置为一个message,通讯录的版本也升级到了2.2
4.4.1 通讯录2.2版本
修改后的.proto文件内容如下:
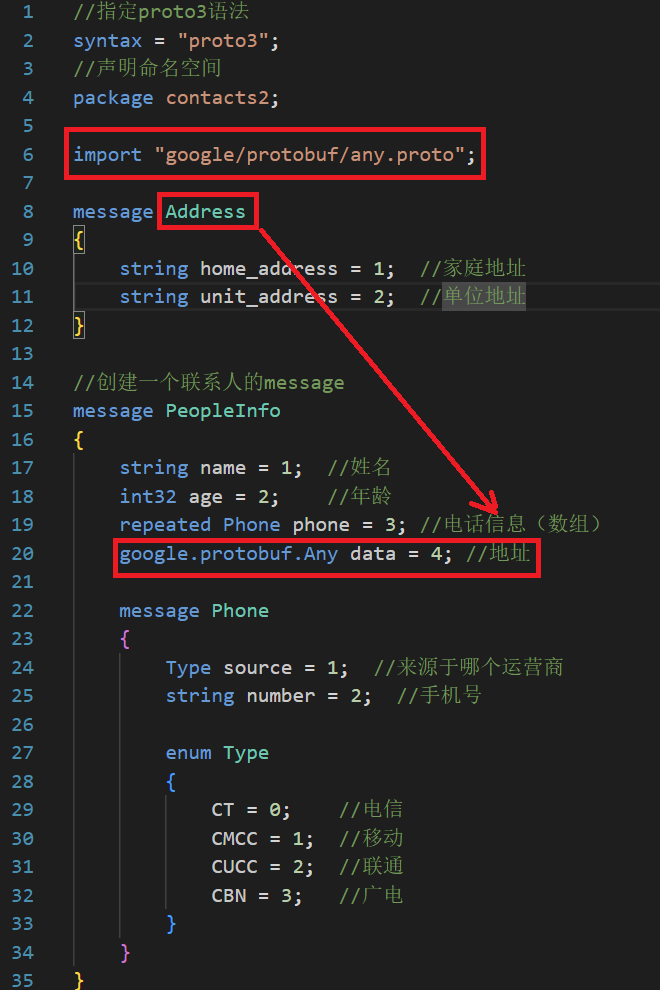
- 不要忘记要导入any类型对应的文件
- data字段设置为any,表示它可以存储任意类型,后续我们使用Address对象给data赋值
我们再来查看一下编译完成之后的data字段。
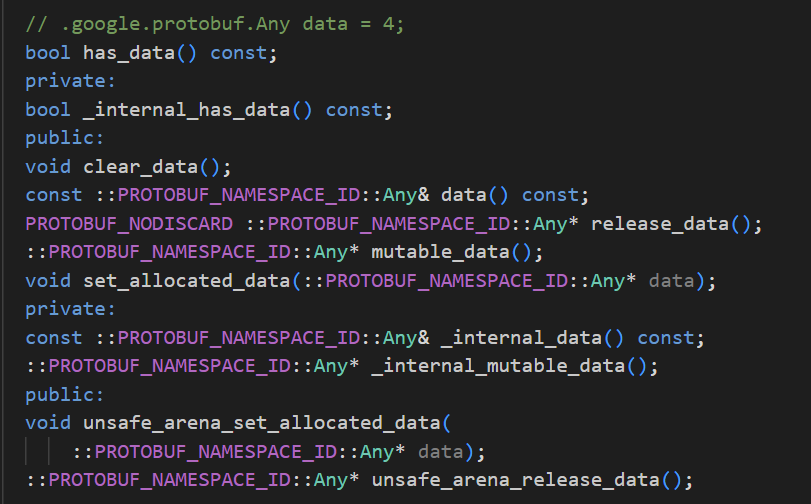
- has_data():判断data字段是否被设置
- clear_data():清空data字段
- data():返回一个Any类型的指针
- mutable_data():返回一块已经开辟好的空间,可以对该空间进行操作
我们再来查看一下Any类型的定义。
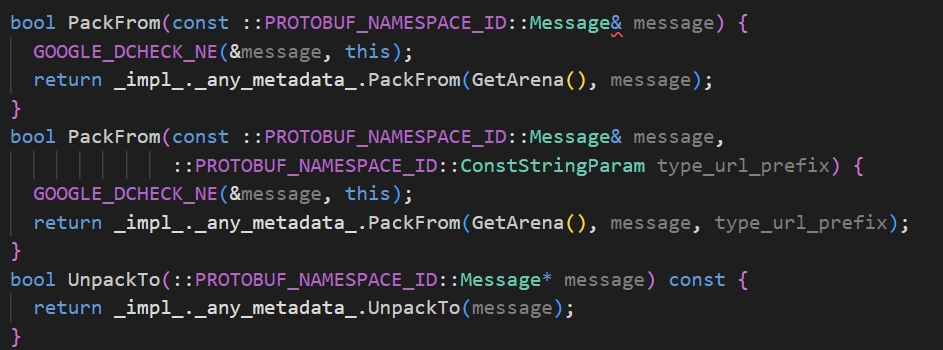

- PackFrom函数用于将任意类型转化成Any类型。
- UnpackTo函数用于将Any类型转化成任意类型。
- Is函数用于判断保存的是不是T类型。
更新一下AddPeopleInfo函数,新增内容:输入时要额外输入家庭住址和单位住址,将这两个值保存在Address中,再将Address转化成Any类型的data。
void AddPeopleInfo(contacts2::PeopleInfo* people)
{
cout << "-------------新增联系人-------------" << endl;
cout << "请输入联系人姓名:";
string name;
getline(cin, name);
people->set_name(name);
cout << "请输入联系人年龄:";
int age;
cin >> age;
people->set_age(age);
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
for (int i = 1; ; i++)
{
cout << "请输入联系人电话" << i << "(只输入回车完成电话新增):";
string number;
getline(cin, number);
if (number.empty())
{
break;
}
contacts2::PeopleInfo_Phone* phone = people->add_phone();
phone->set_number(number);
RCHOISE:
cout << "请输入运营商(1.电信 2.移动 3.联通 4.广电):";
int source;
cin >> source;
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
switch(source)
{
case 1 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CT);
break;
case 2 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CMCC);
break;
case 3 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CUCC);
break;
case 4 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CBN);
break;
default :
cout << "输入失败,请重新输入" << endl;
goto RCHOISE;
break;
}
}
//1.定义一个Address对象
contacts2::Address address;
cout << "请输入联系人家庭地址:";
string home_address;
getline(cin, home_address);
cout << "请输入联系人单元地址:";
string unit_address;
getline(cin, unit_address);
address.set_home_address(home_address);
address.set_unit_address(unit_address);
//2.将address转化成any类型
//PackFrom函数会将address转化成any类型并保存在mutable_data返回的空间中
people->mutable_data()->PackFrom(address);
cout << "-----------添加联系人成功-----------" << endl;
}再更新一下PrintContacts函数,新增内容:将data转化成Address类型,打印其中的home_address和unit_address。
void PrintContacts(contacts2::Contacts contacts)
{
for (int i = 0; i < contacts.contacts_size(); i++)
{
contacts2::PeopleInfo people = contacts.contacts(i);
cout << "------------联系人" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
for (int j = 0; j < people.phone_size(); j++)
{
contacts2::PeopleInfo_Phone phone = people.phone(j);
cout << "电话" << j+1 << ":" << phone.number()
<< " 运营商:" << phone.Type_Name(phone.source()) << endl;
}
//判断data对象是否设置了值,并且该值为Address类型
if (people.has_data() && people.data().Is<contacts2::Address>())
{
//将data类型转化成address类型
contacts2::Address address;
people.data().UnpackTo(&address);
//打印一下值
if (!address.home_address().empty())
cout << "家庭地址:" << address.home_address() << endl;
if (!address.unit_address().empty())
cout << "单位地址:" << address.unit_address() << endl;
}
cout << endl;
}
}运行之后,额外添加两个输入信息:家庭地址和单位地址

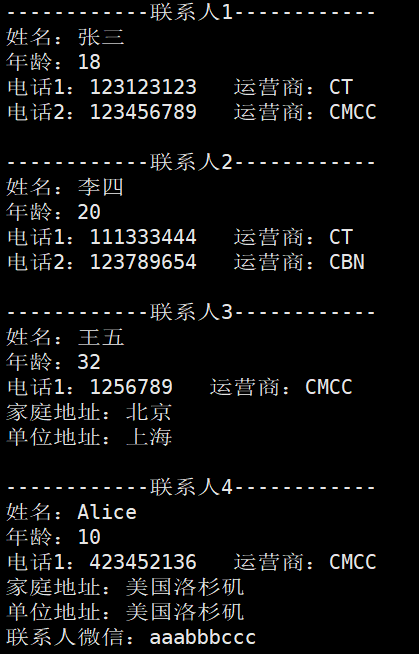
打印结果如下所示,张三和李四是通讯录2.1版本添加的,不存在地址,所以不会打印。
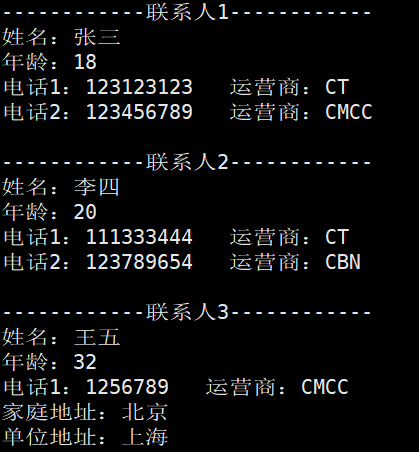
4.5 oneof类型
如果消息中有很多可选字段,并且将来同时只有一个字段会被设置,那么就可以使用 oneof 加强这个行为,也能有节约内存的效果。
我们使用会在通讯录中添加一个“其他联系方式”字段(通过qq或者微信),我们的通讯录版本将升级为2.3版本。
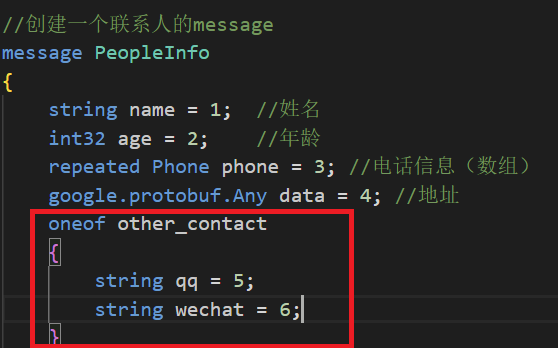
注意:
- 1)oneof中的字段编号不能与同级下其他编号相同,否则会产生冲突导致编译报错。
- 2)oneof中的字段不能设置为repeated。
- 3)设置oneof字段中值时,如果将oneof中的字段设置多个,那么只会保留最后一次设置的成员,之前设置的oneof成员会自动清除。
4.5.1 通讯录2.3版本
.proto文件内容如下:
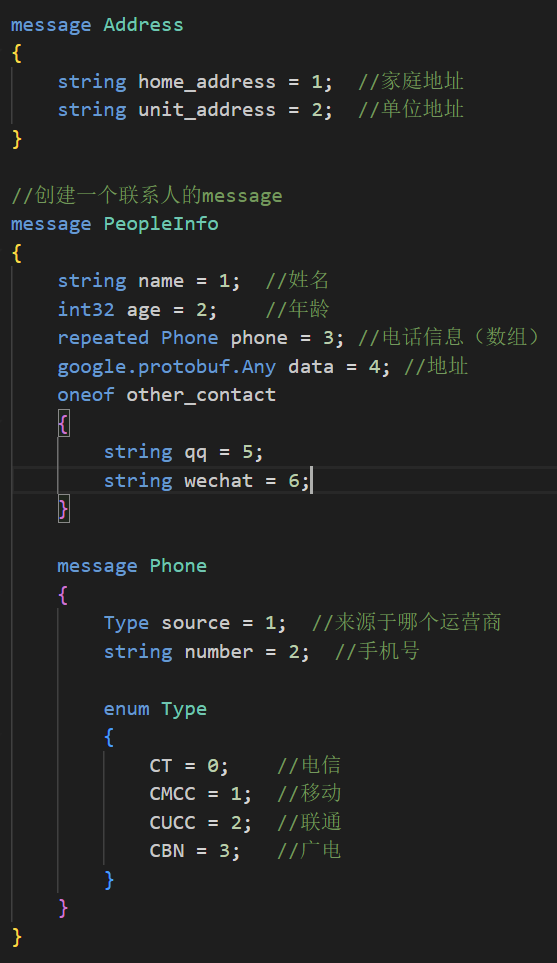
来查看以下编译之后的.h文件
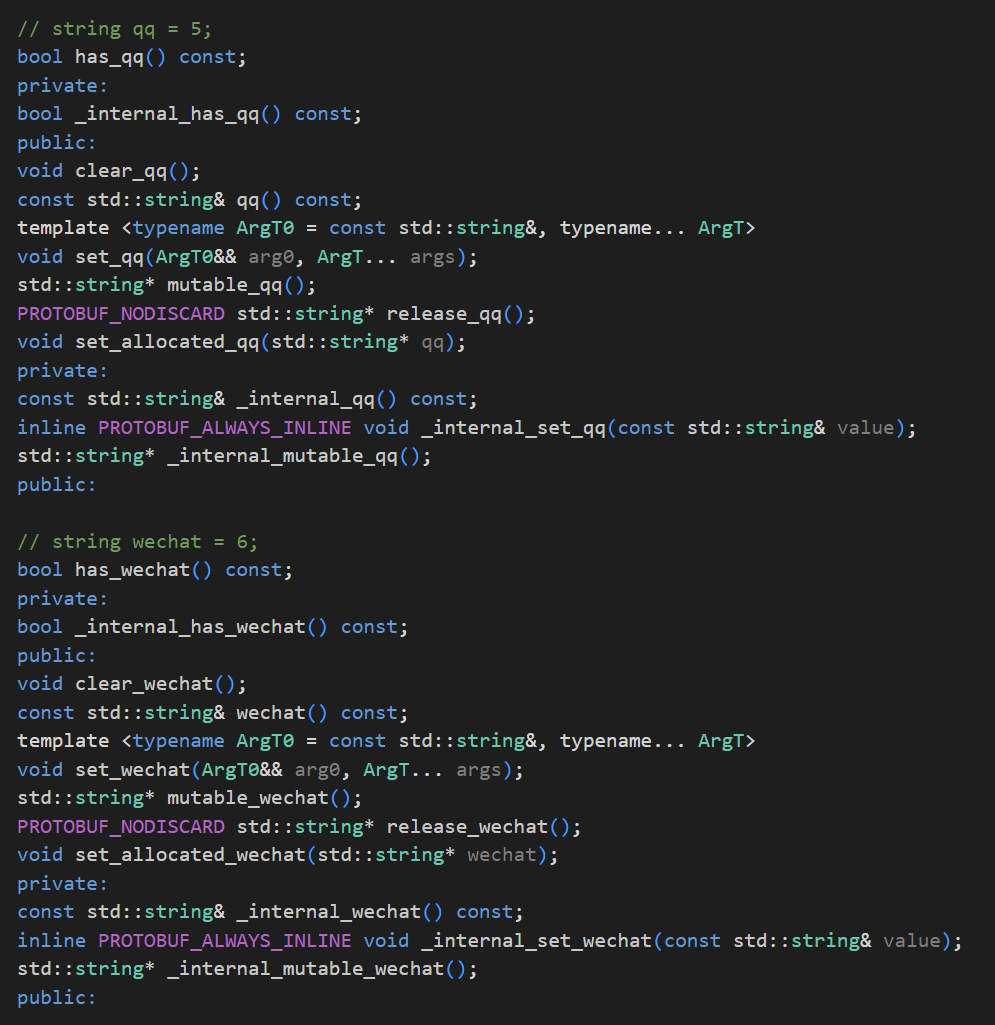
其中qq和wechat多了一个has函数,用于判断是否设置了该字段。
下面还有两个关于other_contact的函数。

- 1) clear_other_contact()函数用于清理设置的字段。
- 2) other_contact_case()通过返回值可以判断我们设置的是oneof中的哪一个字段。
其中OtherContactCase的定义如下:
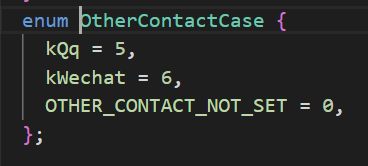
kQq表示设置了qq,kWechat表示设置了微信,OTHER_CONTACT_NOT_SET表示什么都没设置。
所以说oneof定义的多个字段最终会转化成枚举类型。
现在更新一下AddPeopleInfo函数,增加联系人其他联系方式,可选择qq或者微信。
void AddPeopleInfo(contacts2::PeopleInfo* people)
{
cout << "-------------新增联系人-------------" << endl;
cout << "请输入联系人姓名:";
string name;
getline(cin, name);
people->set_name(name);
cout << "请输入联系人年龄:";
int age;
cin >> age;
people->set_age(age);
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
for (int i = 1; ; i++)
{
cout << "请输入联系人电话" << i << "(只输入回车完成电话新增):";
string number;
getline(cin, number);
if (number.empty())
{
break;
}
contacts2::PeopleInfo_Phone* phone = people->add_phone();
phone->set_number(number);
RCHOISE:
cout << "请输入运营商(1.电信 2.移动 3.联通 4.广电):";
int source;
cin >> source;
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
switch(source)
{
case 1 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CT);
break;
case 2 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CMCC);
break;
case 3 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CUCC);
break;
case 4 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CBN);
break;
default :
cout << "输入失败,请重新输入" << endl;
goto RCHOISE;
break;
}
}
//1.定义一个Address对象
contacts2::Address address;
cout << "请输入联系人家庭地址:";
string home_address;
getline(cin, home_address);
cout << "请输入联系人单元地址:";
string unit_address;
getline(cin, unit_address);
address.set_home_address(home_address);
address.set_unit_address(unit_address);
//2.将address转化成any类型
//PackFrom函数会将address转化成any类型并保存在mutable_data返回的空间中
people->mutable_data()->PackFrom(address);
cout << "请输入要添加的其他联系方式(1.QQ 2.微信):";
int other_contact;
cin >> other_contact;
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
if (other_contact == 1)
{
cout << "请输入联系人QQ号:";
string qq;
getline(cin, qq);
people->set_qq(qq);
}
else if (other_contact == 2)
{
cout << "请输入联系人微信号:";
string wechat;
getline(cin, wechat);
people->set_wechat(wechat);
}
else
{
cout << "输入失败,其他联系方式未设置" << endl;
}
cout << "-----------添加联系人成功-----------" << endl;
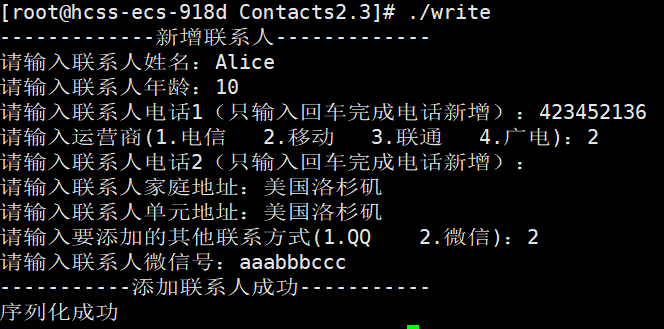
}在PrintContacts函数中额外添加了一个打印QQ号或者是微信号的函数。
void PrintContacts(contacts2::Contacts contacts)
{
for (int i = 0; i < contacts.contacts_size(); i++)
{
contacts2::PeopleInfo people = contacts.contacts(i);
cout << "------------联系人" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
for (int j = 0; j < people.phone_size(); j++)
{
contacts2::PeopleInfo_Phone phone = people.phone(j);
cout << "电话" << j+1 << ":" << phone.number()
<< " 运营商:" << phone.Type_Name(phone.source()) << endl;
}
//判断data对象是否设置了值,并且该值为Address类型
if (people.has_data() && people.data().Is<contacts2::Address>())
{
//将data类型转化成address类型
contacts2::Address address;
people.data().UnpackTo(&address);
//打印一下值
if (!address.home_address().empty())
cout << "家庭地址:" << address.home_address() << endl;
if (!address.unit_address().empty())
cout << "单位地址:" << address.unit_address() << endl;
}
//返回已设置的oneof值。
switch(people.other_contact_case())
{
case contacts2::PeopleInfo::OtherContactCase::kQq:
cout << "联系人QQ:" << people.qq() << endl;
break;
case contacts2::PeopleInfo::OtherContactCase::kWechat:
cout << "联系人微信:" << people.wechat() << endl;
break;
default:
break;
}
cout << endl;
}
}运行效果:
读取结果:
4.6 may类型
语法支持创建一个关联映射字段,也就是可以使用map类型去声明字段类型,格式为:
map<key_type, value_type> map_field = N;may类型类似于C++中的map(红黑树)。
要注意的是:
- • key_type 是除了float和bytes类型以外的任意标量类型。 value_type 可以是任意类型。
- • map字段不可以用repeated修饰
- • map中存入的元素是无序的
4.6.1 通讯录2.4版本
通讯录2.4版本想新增联系人的备注信息,我们可以使用map类型的字段来存储备注信息。更新contacts.proto(通讯录2.4),更新内容如下:
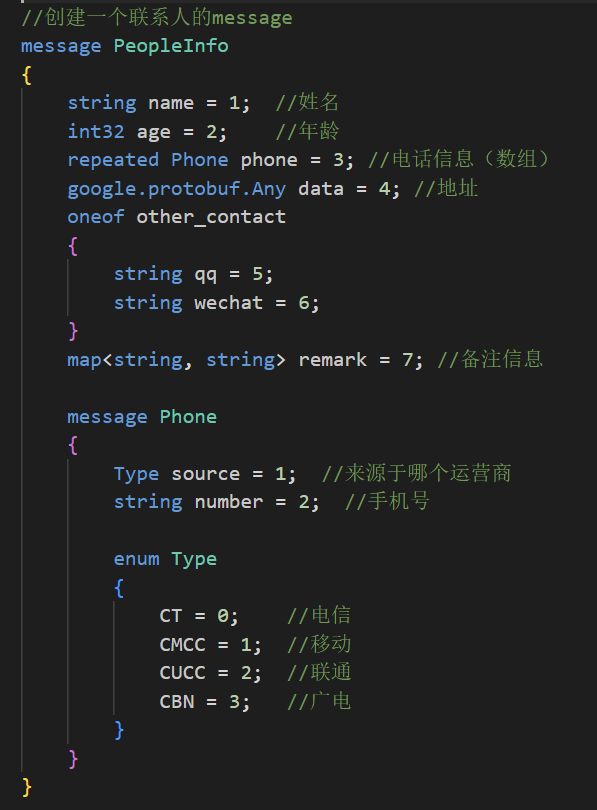
我们再来看一下may类型有哪些处理函数吧。
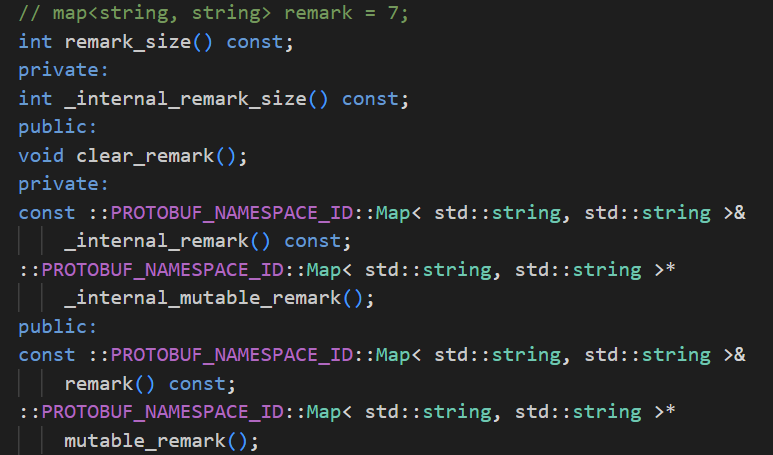
- 1)remark_size():返回map的大小
- 2)clear_size():清除map
- 3)remark():返回一个Map的引用
- 4)mutable_remrk():返回一个开辟好的Map对象,可以直接设置该对象的值
修改AddPeopleInfo函数,添加备注信息字段。
void AddPeopleInfo(contacts2::PeopleInfo* people)
{
cout << "-------------新增联系人-------------" << endl;
cout << "请输入联系人姓名:";
string name;
getline(cin, name);
people->set_name(name);
cout << "请输入联系人年龄:";
int age;
cin >> age;
people->set_age(age);
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
for (int i = 1; ; i++)
{
cout << "请输入联系人电话" << i << "(只输入回车完成电话新增):";
string number;
getline(cin, number);
if (number.empty())
{
break;
}
contacts2::PeopleInfo_Phone* phone = people->add_phone();
phone->set_number(number);
RCHOISE:
cout << "请输入运营商(1.电信 2.移动 3.联通 4.广电):";
int source;
cin >> source;
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
switch(source)
{
case 1 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CT);
break;
case 2 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CMCC);
break;
case 3 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CUCC);
break;
case 4 :
phone->set_source(contacts2::PeopleInfo_Phone_Type::PeopleInfo_Phone_Type_CBN);
break;
default :
cout << "输入失败,请重新输入" << endl;
goto RCHOISE;
break;
}
}
//1.定义一个Address对象
contacts2::Address address;
cout << "请输入联系人家庭地址:";
string home_address;
getline(cin, home_address);
cout << "请输入联系人单元地址:";
string unit_address;
getline(cin, unit_address);
address.set_home_address(home_address);
address.set_unit_address(unit_address);
//2.将address转化成any类型
//PackFrom函数会将address转化成any类型并保存在mutable_data返回的空间中
people->mutable_data()->PackFrom(address);
cout << "请输入要添加的其他联系方式(1.QQ 2.微信):";
int other_contact;
cin >> other_contact;
getchar(); //将刚刚输入的回车读取出来,防止对后面的输入造成影响
if (other_contact == 1)
{
cout << "请输入联系人QQ号:";
string qq;
getline(cin, qq);
people->set_qq(qq);
}
else if (other_contact == 2)
{
cout << "请输入联系人微信号:";
string wechat;
getline(cin, wechat);
people->set_wechat(wechat);
}
else
{
cout << "输入失败,其他联系方式未设置" << endl;
}
for (int i = 0;; i++)
{
cout << "请输入备注" << i + 1 << "标题(只输入回车完成备注新增):";
string remark_key;
getline(cin, remark_key);
if (remark_key.empty())
break;
cout << "请输入备注" << i + 1 << "的内容:";
string remark_value;
getline(cin, remark_value);
people->mutable_remark()->insert({remark_key, remark_value});
}
cout << "-----------添加联系人成功-----------" << endl;
}
people->mutable_remark()函数可以返回一个Map,对这个Map进行insert就可以成功插入键值对信息。
PrintContacts修改如下:遍历Map使用迭代器进行。
void PrintContacts(contacts2::Contacts contacts)
{
for (int i = 0; i < contacts.contacts_size(); i++)
{
contacts2::PeopleInfo people = contacts.contacts(i);
cout << "------------联系人" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
for (int j = 0; j < people.phone_size(); j++)
{
contacts2::PeopleInfo_Phone phone = people.phone(j);
cout << "电话" << j+1 << ":" << phone.number()
<< " 运营商:" << phone.Type_Name(phone.source()) << endl;
}
//判断data对象是否设置了值,并且该值为Address类型
if (people.has_data() && people.data().Is<contacts2::Address>())
{
//将data类型转化成address类型
contacts2::Address address;
people.data().UnpackTo(&address);
//打印一下值
if (!address.home_address().empty())
cout << "家庭地址:" << address.home_address() << endl;
if (!address.unit_address().empty())
cout << "单位地址:" << address.unit_address() << endl;
}
//返回已设置的oneof值。
switch(people.other_contact_case())
{
case contacts2::PeopleInfo::OtherContactCase::kQq:
cout << "联系人QQ:" << people.qq() << endl;
break;
case contacts2::PeopleInfo::OtherContactCase::kWechat:
cout << "联系人微信:" << people.wechat() << endl;
break;
default:
break;
}
//打印备注信息
if (people.remark_size())
{
int j = 0;
for (auto it : people.remark())
{
cout << "备注信息" << ++j << " " << it.first << ": " << it.second << endl;
}
}
cout << endl;
}
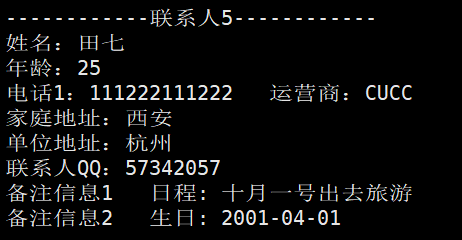
}结果:

打印结果:
4.7 默认值
反序列化消息时,如果被反序列化的⼆进制序列中不包含某个字段,反序列化对象中相应字段时,就会设置为该字段的默认值。不同的类型对应的默认值不同:
- 对于字符串,默认值为空字符串。
- 对于字节,默认值为空字节。
- 对于布尔值,默认值为false。
- 对于数值类型,默认值为0。
- 对于枚举,默认值是第⼀个定义的枚举值,必须为0。
- 对于消息字段,未设置该字段。它的取值是依赖于语言。
- 对于设置了repeated的字段的默认值是空的(通常是相应语言的⼀个空列表)。
- 对于 消息字段 、 oneof字段 和 any字段 ,C++和Java语言中都有has_方法来检测当前字段是否被设置。
对于标量数据类型,在proto3语法下,没有生成has_方法。

例如我们使用上面的message创建一个对象,然后填充其中的a=1和b=2,并将他序列化成二进制序列,在反序列化时,因为c没有设置,所以会一个默认值为0,此时我们就无法判断这个c=0是手动设置的还是没有设置取的默认值。
其实这个问题不是很重要,如果c表示的是银行卡余额,没有设置银行卡余额和银行卡余额默认为0区别不大。
4.8. 更新消息
4.8.1 新增
如果现有的消息类型已经不再满足我们的需求,例如需要扩展⼀个字段,在不破坏任何现有代码的情况下更新消息类型非常简单。遵循如下规则即可:
- 1.禁止修改任何已有字段的字段编号。
- 2.若是移除老字段,要保证不再使用移除字段的字段编号。正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使用。不建议直接删除或注释掉字段。
- 3.int32,uint32,int64,uint64和bool是完全兼容的。可以从这些类型中的一个改为另一个,而不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采用与C++一致的处理方案(例如,若将64位整数当做32位进行读取,它将被截断为32位)。
- 4.sint32和sint64相互兼容但不与其他的整型兼容。
- 5.string和bytes在合法UTF-8字节前提下也是兼容的。
- 6.bytes包含消息编码版本的情况下,嵌套消息与bytes也是兼容的。
- 7.fixed32与sfixed32兼容,fixed64与sfixed64兼容。
- 8.enum与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序列化消息时会根据语言采用不同的处理方案:例如,未识别的proto3枚举类型会被保存在消息中,但是当消息反序列化时如何表示是依赖于编程语言的。整型字段总是会保持其的值。
- 9.oneof:
- 1)将一个单独的值更改为新oneof类型成员之一是安全和二进制兼容的。
- 2)若确定没有代码一次性设置多个值那么将多个字段移入一个新oneof类型也是可行的。
- 3)将任何字段移入已存在的oneof类型是不安全的。
- 2)若确定没有代码一次性设置多个值那么将多个字段移入一个新oneof类型也是可行的。
- 1)将一个单独的值更改为新oneof类型成员之一是安全和二进制兼容的。
4.8.2 删除
如果通过删除或注释掉字段来更新消息类型,未来的用户在添加新字段时,有可能会使用以前已经存在,但已经被删除或注释掉的字段编号。将来使用该.proto的旧版本时的程序会引发很多问题:数据损坏、隐私错误等等。
先演示一下删除一个老字段会产生什么效果:
我们将通讯录的版本更新到3.0,在这个版本中有一个客户端一个服务端。server用于新增联系人,client用于读取通讯录中所有的联系人。
server.cc就是原来的write.cc文件,client.cc就是原来的read.cc文件。
与原来不同的是,client和server各自拥有独立的一份.proto文件,也就是说他们包含的是不同的头文件了,3.0版本是在通讯录2.0版本的基础上(只包含姓名,年龄,电话信息)内容,并且目前两个.proto文件内容是一样的。
在sever下添加联系人:
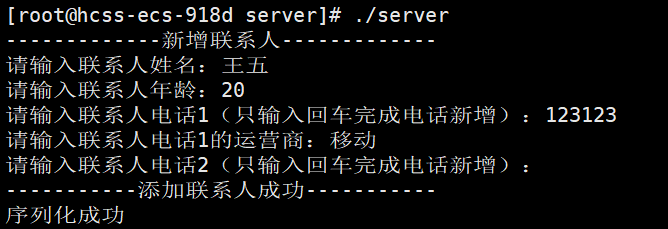
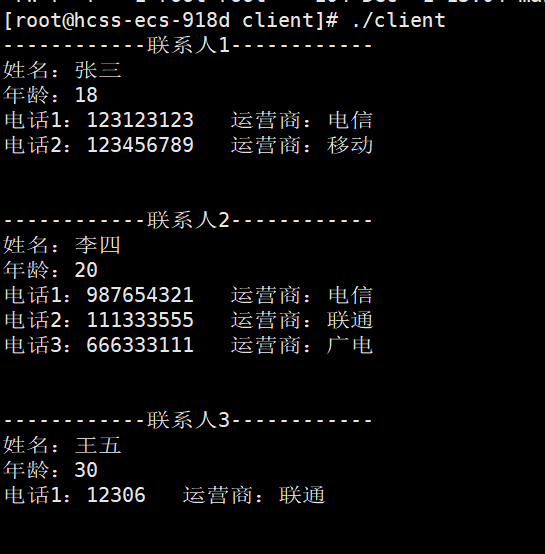
在client下读取联系人:
现在重点来了,server中的.proto文件中的age字段不想要了,我们现在想新增一个birthday字段。
同样还要修改AddPeopleInfo中的接口和参数
cient我们不做任何修改,打印的还是age。
新增了如下联系人:

我们输入的是生日,也就是说没有填写年龄字段。那么在client进行打印时,我们期望的结果是在打印年龄字段时给个默认值0。
然而在实际打印中,会将生日字段填充到年龄上。

产生这个错误的原因是:原来的age编号为2已经被设置过了,在反序列化时会将值设置到相同字段编号的值上,也就是将birthday的值设置到编号为2的字段上,即age变成了1221。
总结:如果要删除老字段,要保证不使用已经被删除或者已经被注释掉的字段编号。
确保不会使用已经删除或已经被注释的字段编号的一种方法是:使用 reserved 将指定字段的编号或名称设置为保留项。当我们再使用这些编号或名称时,protocolbuffer的编译器将会警告这些编号或名称不可用。举个例子:
我们不想要age了,为了防止后续忘记2编号已经被使用过,我们将可以使用reserved指定2编号为保留项。
在编译时,会报错,报错内容是:birthday使用了保留编号2

如果想设置多个保留字段,可以使用逗号分隔,也可以使用to指定一段范围。
并且reserved还支持保留字段名称,其他字段不可设置为已保留字段名称。

前面出现的错误是因为birthday设置为了已经使用过的编号,那我们将他设置为没使用过的编号呢?
我们将birthday的编号设置为4。

重新编译生成.pb.h和.pb.cc文件。
我们设置联系人周七的生日为2121,并没有设置他的年龄。

现在在读取时就不会读到birthday了,而是设置 一个默认值0

4.9 未知字段
在前面我们说到客户端中只会读取年龄字段,也就是说在反序列化时,只会读取到编号为2个字段。
但是在server中我们删除了编号为2的字段,并且新增了一个编号为4的字段;那么client在进行反序列化周七这个联系人时,会读取到一个不认识的编号4的字段,它不会将该字段删除,而是保存在未知字段中。
未知字段:解析结构良好的protocolbuffer已序列化数据中的未识别字段的表示方式。例如,当旧程序解析带有新字段的数据时,这些新字段就会成为旧程序的未知字段。
本来,proto3在解析消息时总是会丢弃未知字段,但在3.5版本中重新引入了对未知字段的保留机制。所以在3.5或更高版本中,未知字段在反序列化时会被保留,同时也会包含在序列化的结果中。
4.9.1 未知字段从哪获取
了解相关类关系图
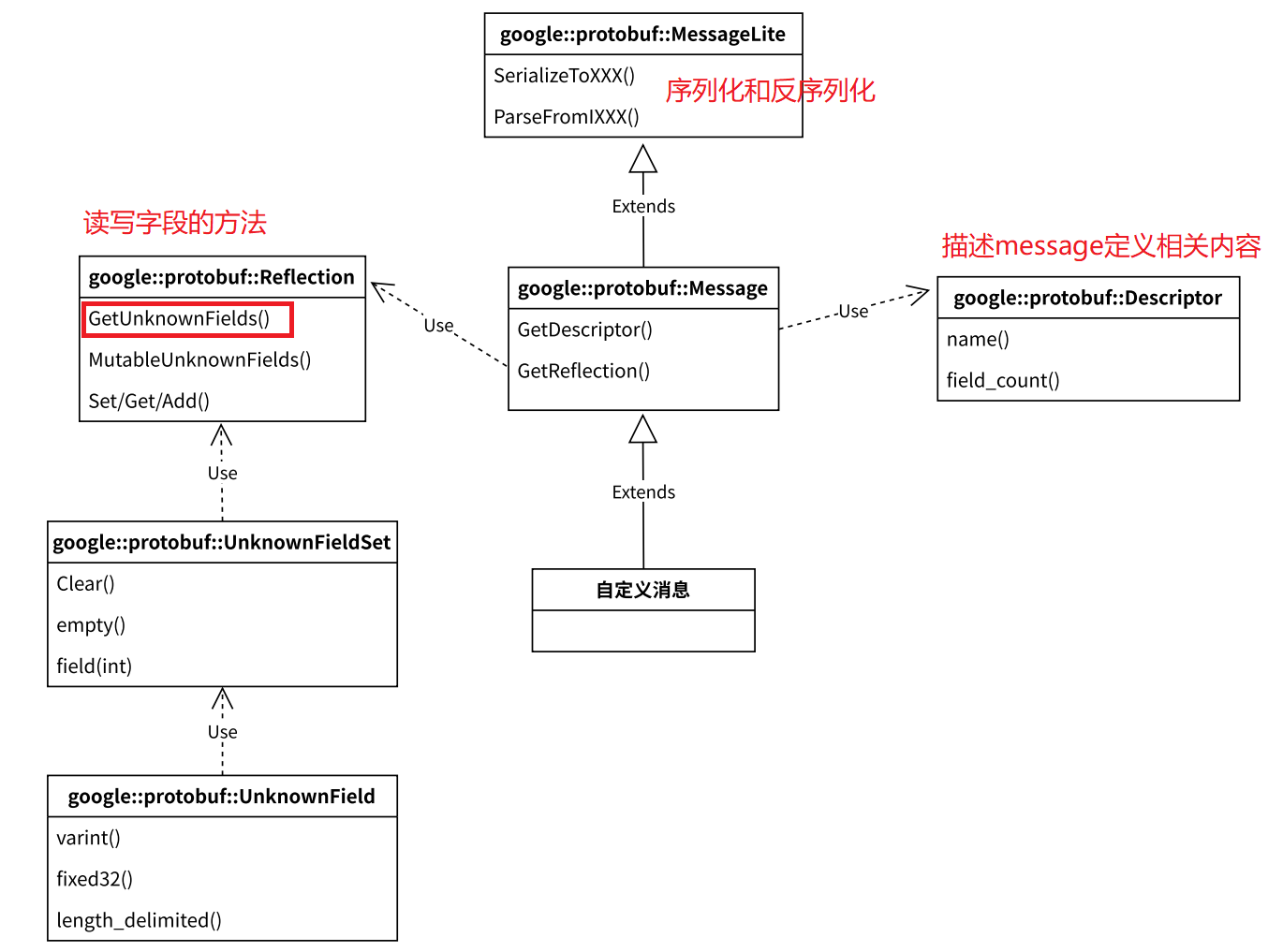
其中UnknownField就是未知字段,而GetUnknownFields()用于获取所有的未知信息,返回的是UnknownFieldSet类型,该类型保存多个UnknownField字段(未知字段),通过未知字段中的函数可以获取未知字段的类型以及值。
上图中所有类介绍:
1.MessageLite类介绍
- MessageLite从名字看是轻量级的message,仅仅提供序列化、反序列化功能。
- 类定义在google提供的message_lite.h中。
2.Message类介绍
- 我们自定义的message类,都是继承自Message。
- Message最重要的两个接GetDescriptor/GetReflection,可以获取该类型对应的Descriptor对象指针和Reflection对象指针。
- 类定义在google提供的message.h中。
3.Descriptor类介绍
- Descriptor:是对message类型定义的描述,包括message的名字、所有字段的描述、原始的proto文件内容等。
- 类定义在google提供的descriptor.h中
4.Reflection类介绍
- Reflection接口类,主要提供了动态读写消息字段的接口,对消息对象的自动读写主要通过该类完成。
- 提供方法来动态访问/修改message中的字段,对每种类型,Reflection都提供了⼀个单独的接口用于读写字段对应的值。
1)针对所有不同的field类型 FieldDescriptor::TYPE_* ,需要使用不同的 Get*()/Set*()/Add*() 接口;
2)repeated类型需要使用 GetRepeated*()/SetRepeated*() 接口,不可以和非repeated类型接口混用;
3)message对象只可以被由它自身的 reflection(message.GetReflection()) 来操作;
- 类中还包含了访问/修改未知字段的方法。
- 类定义在google提供的message.h中。
5.UnknownFieldSet类介绍
- UnknownFieldSet包含在分析消息时遇到但未由其类型定义的所有字段。
- 若要将UnknownFieldSet附加到任何消息,请调用Reflection::GetUnknownFields()。
- 类定义在unknown_field_set.h中。
6.UnknownField类介绍
- 表示未知字段集中的一个字段。
- 类定义在unknown_field_set.h中。
4.9.2 通讯录3.1版本
这个版本在3.0的基础上对未知消息进行验证。
更新client.cc(通讯录3.1),在这个版本中,需要打印出未知字段的内容。
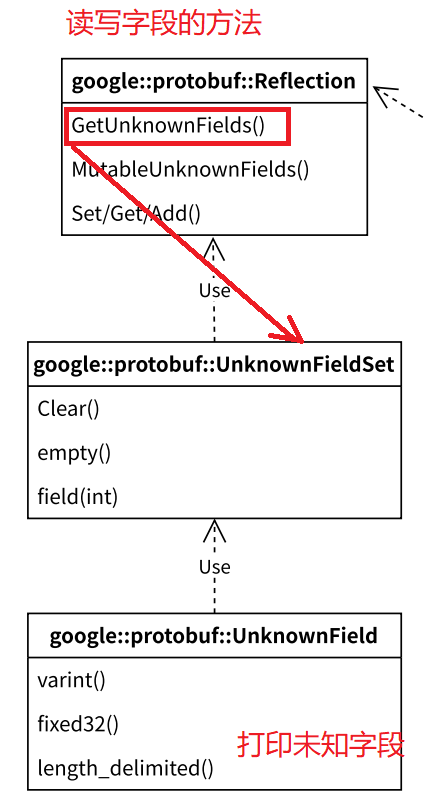
根据上图,我们总结一下大概流程:
- 1.创建一个Reflection对象。
- 2.通过Reflection对象调用GetUnknownField()函数获取UnknownFiledSet对象。
- 3.遍历UnknownFiledSet对象获取所有的未知字段。
其中UnknownField就是未知字段,其部分定义如下:
class PROTOBUF_EXPORT UnknownField {
public:
enum Type {
TYPE_VARINT,
TYPE_FIXED32,
TYPE_FIXED64,
TYPE_LENGTH_DELIMITED,
TYPE_GROUP
};
// The field's field number, as seen on the wire.
inline int number() const;
// The field type.
inline Type type() const;
// Accessors -------------------------------------------------------
// Each method works only for UnknownFields of the corresponding type.
inline uint64_t varint() const;
inline uint32_t fixed32() const;
inline uint64_t fixed64() const;
inline const std::string& length_delimited() const;
inline const UnknownFieldSet& group() const;
inline void set_varint(uint64_t value);
inline void set_fixed32(uint32_t value);
inline void set_fixed64(uint64_t value);
inline void set_length_delimited(const std::string& value);
inline std::string* mutable_length_delimited();
inline UnknownFieldSet* mutable_group();
}- number():返回未知字段的编号
- type():返回一个Type枚举类型,通过type返回的并不是未知字段原来的类型,而是被转化成了一个枚举类型,例如原来的int32类型会被转化为TYPE_VARINT返回。
- TYPE_VARINT对应:
int32、int64、uint32、uint64、sint32、sint64、bool以及enum- TYPE_FIXED32对应:
fixed32和sfixed32- TYPE_FIXED64对应:
fixed64和sfixed64- TYPE_LENGTH_DELIMITED对应:
string、bytes- TYPE_GROUP对应:
group
- varint()、fixed32()、fixed64().....:获取未知字段的值,是哪个类型就调用哪一个函数。
- set_variint()、set_fixed32()......:设置对应类型的值
client代码修改如下:
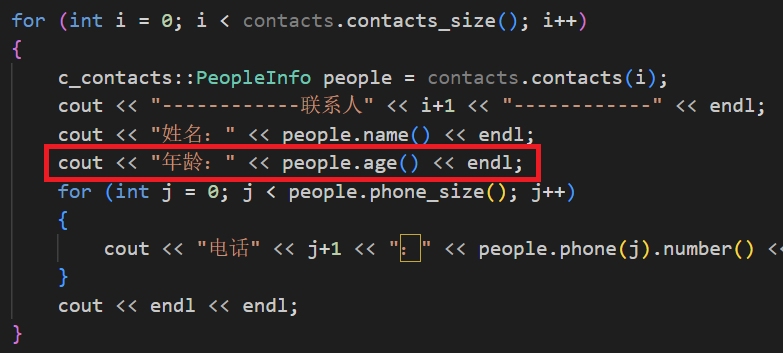
void PrintContacts(c_contacts::Contacts contacts)
{
for (int i = 0; i < contacts.contacts_size(); i++)
{
c_contacts::PeopleInfo people = contacts.contacts(i);
cout << "------------联系人" << i+1 << "------------" << endl;
cout << "姓名:" << people.name() << endl;
cout << "年龄:" << people.age() << endl;
for (int j = 0; j < people.phone_size(); j++)
{
cout << "电话" << j+1 << ":" << people.phone(j).number() << " 运营商:" << people.phone(j).source() << endl;
}
//打印未知字段
//1.获取Reflection
const google::protobuf::Reflection* reflection = c_contacts::PeopleInfo::GetReflection();
//2.获取UnknowFieldSet对象
const google::protobuf::UnknownFieldSet& set = reflection->GetUnknownFields(people);
//3.遍历set获取未知元素
for (int j = 0; j < set.field_count(); j++)
{
//获取第i个未知字段
const google::protobuf::UnknownField& unknown_field = set.field(j);
//打印未知字段的类型以及对应值
cout << "未知字段" << j+1 << ": " << "编号: " << unknown_field.number();
//根据未知字段的type调用不同的函数
switch(unknown_field.type())
{
case google::protobuf::UnknownField::TYPE_VARINT:
cout << " 值: " << unknown_field.varint() << endl;
break;
case google::protobuf::UnknownField::TYPE_FIXED32:
cout << " 值: " << unknown_field.varint() << endl;
break;
case google::protobuf::UnknownField::TYPE_FIXED64:
cout << " 值: " << unknown_field.varint() << endl;
break;
case google::protobuf::UnknownField::TYPE_LENGTH_DELIMITED:
cout << " 值: " << unknown_field.varint() << endl;
break;
}
}
cout << endl << endl;
}
}修改之后,周七的Birthday字段(未知字段)就成功被识别出来了,成功打印了他的编号以及值。

4.9.3 前后兼容性
根据上述的例子可以得出,pb是具有向前兼容的。为了叙述方便,把增加了“生日”属性的service称为“新模块”;未做变动的client称为“老模块”。
- • 向前兼容:老模块能够正确识别新模块生成或发出的协议。这时新增加的“生日”属性会被当作未知字段(pb3.5版本及之后)。
- • 向后兼容:新模块也能够正确识别老模块生成或发出的协议。
前后兼容的作用:当我们维护一个很庞大的分布式系统时,由于你无法同时升级所有模块,为了保证在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼容”。
4.10 option选项
.proto文件中可以声明许多选项,使用 option 标注。选项能影响proto编译器的某些处理方式。
4.10.1 option选项分类
选项的完整列表在google/protobuf/descriptor.proto中定义。部分代码:
syntax = "proto2"; // descriptor.proto 使⽤ proto2 语法版本
message FileOptions { ... } // ⽂件选项 定义在 FileOptions 消息中
message MessageOptions { ... } // 消息类型选项 定义在 MessageOptions 消息中
message FieldOptions { ... } // 消息字段选项 定义在 FieldOptions 消息中
message OneofOptions { ... } // oneof字段选项 定义在 OneofOptions 消息中
message EnumOptions { ... } // 枚举类型选项 定义在 EnumOptions 消息中
message EnumValueOptions { .. } // 枚举值选项 定义在 EnumValueOptions 消息中
message ServiceOptions { ... } // 服务选项 定义在 ServiceOptions 消息中
message MethodOptions { ... } // 服务⽅法选项 定义在 MethodOptions 消息中
...由此可见,选项分为文件级、消息级、字段级等等,但并没有一种选项能作用于所有的类型。
4.10.2 常用选项列举
optimize_for:该选项为文件选项,可以设置protoc编译器的优化级别,分别为 SPEED 、CODE_SIZE 、 LITE_RUNTIME 。受该选项影响,设置不同的优化级别,编译.proto文件后生成的代码内容不同。
- SPEED :protoc编译器将生成的代码是高度优化的,代码运行效率高,但是由此生成的代码编译后会占用更多的空间。 SPEED 是默认选项。
- CODE_SIZE :proto编译器将生成最少的类,会占用更少的空间,是依赖基于反射的代码来实现序列化、反序列化和各种其他操作。但和 SPEED 恰恰相反,它的代码运行效率较低。这种方式适合用在包含大量的.proto文件,但并不盲目追求速度的应用中。
- LITE_RUNTIME :生成的代码执行效率高,同时生成代码编译后的所占用的空间也是非常少。这是以牺牲ProtocolBuffer提供的反射功能为代价的,仅仅提供encoding+序列化功能,所以我们在链接BP库时仅需链接libprotobuf-lite,而非libprotobuf。这种模式通常用于资源有限的平台,例如移动手机平台中。
option optimize_for = LITE_RUNTIME;allow_alias:允许将相同的常量值分配给不同的枚举常量,用来定义别名。该选项为枚举选项。
举个例子:
enum PhoneType
{
option allow_alias = true;
MP = 0;
TEL = 1;
LANDLINE = 1; // 若不加 option allow_alias = true; 这⼀⾏会编译报错
}