文章系转载,方便整理和归档
作者:crabor
链接:https://www.jianshu.com/p/9e150d72ffc9
来源:简书
本文分为两个部分,第一是详细讲解Redis6的–bigkeys选项相关源码是怎样实现的,第二部分为自己对–bigkeys源码的优化项目redis-bigkey-online的介绍。redis-bigkey-online是自己开发的非常好用、高效的bigkey查找工具,因为是修改的源码,所以是直接整合在redis-cli程序中,由官方的
./redis-cli --bigkeys
改为
./redis-cli --bigkeys redis-bigkey-online.conf
即可使用,redis-bigkey-online.conf则保存了用户的个性化设定,包括需要输出哪些类型的bigkey、输出前N个bigkey、设定bigkey判断阈值等功能。并且,由于自己修改源码一直遵循“尽量少改、尽量集中改、尽量改的部分风格和源码统一”三个“尽量”的原则,所以该项目也十分容易的移植到其他版本的redis上。欢迎大家star和使用~
–bigkeys选项源码原理解析
首先我们从运行结果出发。首先通过脚本插入一些数据到redis中,然后执行redis-cli的–bigkeys选项
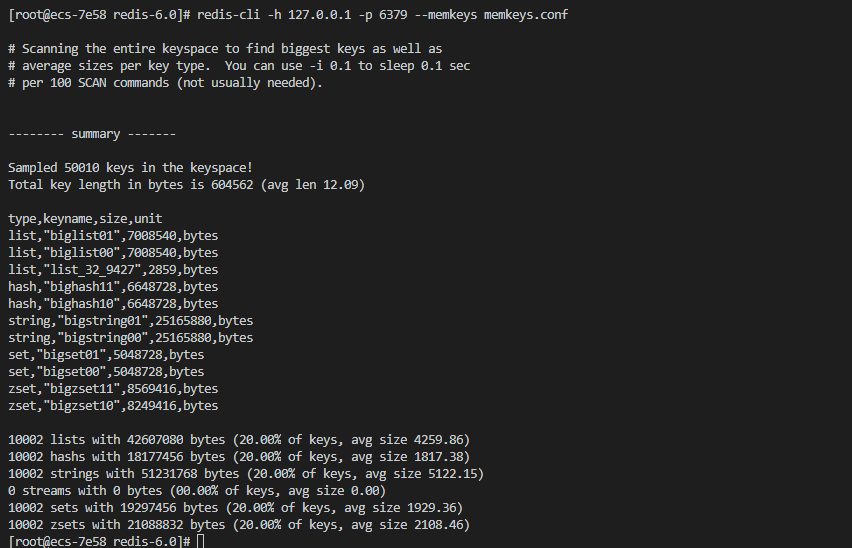
[root@ecs-7e58 add-nomal-key]# redis-cli --bigkeys -h 127.0.0.1 -p 6379
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest zset found so far '"zset_32_4769"' with 10 members
[00.00%] Biggest set found so far '"set_32_1808"' with 10 members
[00.00%] Biggest list found so far '"list_32_3402"' with 10 items
[00.00%] Biggest string found so far '"string_32_1957"' with 32 bytes
[00.00%] Biggest hash found so far '"hash_32_1481"' with 10 fields
-------- summary -------
Sampled 50000 keys in the keyspace!
Total key length in bytes is 604470 (avg len 12.09)
Biggest list found '"list_32_3402"' has 10 items
Biggest hash found '"hash_32_1481"' has 10 fields
Biggest string found '"string_32_1957"' has 32 bytes
Biggest set found '"set_32_1808"' has 10 members
Biggest zset found '"zset_32_4769"' has 10 members
10000 lists with 100000 items (20.00% of keys, avg size 10.00)
10000 hashs with 100000 fields (20.00% of keys, avg size 10.00)
10000 strings with 320000 bytes (20.00% of keys, avg size 32.00)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
10000 sets with 100000 members (20.00% of keys, avg size 10.00)
10000 zsets with 100000 members (20.00% of keys, avg size 10.00)
注意summary下面的信息,分别是总的key的统计信息,然后是每种数据类型中top1的那个key,最后是各种数据结构的统计数据。可以看到,虽然–bigkeys选项会扫描整个redis,但是只输出每种数据类型top1的那个key。但是实际却和我们找bigkey的需求相去甚远,实际我们可能需要前N个bigkey,并且bigkey的阈值也是可以自己设定的。所以我们有了改源码的需求,自然在改源码之前需要对源码的实现原理有所掌握才行。
由运行结果我们会猜想redis可能是维护了6个变量用来记录每种数据类型的topkey,如果遍历时遇到更大的就替换之前的,这和在数组中找到最大值的原理是一样的,而实际上redis确实也是这样做的。
redis找bigkey的函数是static void findBigKeys(int memkeys, unsigned memkeys_samples),因为–memkeys选项和–bigkeys选项是公用同一个函数,所以使用memkeys时会有额外两个参数memkeys、memkeys_sample,但这和–bigkeys选项没关系,所以不用理会。findBigKeys具体函数框架为:
findBigKeys:
1.申请6个变量用以统计6种数据类型的信息(每个变量记录该数据类型的key的总数量、bigkey是哪个等信息)
2.调用scan命令迭代地获取一批key(注意只是key的名称,类型和大小scan命令不返回)
3.对每个key获取它的数据类型(type)和key的大小(size)
4.对每个key更新对应数据类型的统计信息
5.如果key的大小大于已记录的最大值的key,则更新最大key的信息
6.回到步骤2,直到遍历完所有key
7.输出统计信息、最大key信息
1.申请6个变量用以统计各类型的统计信息
首先是第一步,申请6个变量:
dict *types_dict = dictCreate(&typeinfoDictType, NULL);
typeinfo_add(types_dict, "string", &type_string);
typeinfo_add(types_dict, "list", &type_list);
typeinfo_add(types_dict, "set", &type_set);
typeinfo_add(types_dict, "hash", &type_hash);
typeinfo_add(types_dict, "zset", &type_zset);
typeinfo_add(types_dict, "stream", &type_stream);
dictCreate函数创建了一个字典变量types_dict,然后通过typeinfo_add向这个字典中添加6个dictEntry结构。这里的dictEntry其实就是一个kv对结构,k保存数据类型名称,如记录string信息的dictEntry的key就是"string",而v才是真正用来保存统计信息的地方。不知道什么是dict的同学可以看下下面字典结构的示意图,dict是redis最基础的数据结构之一。
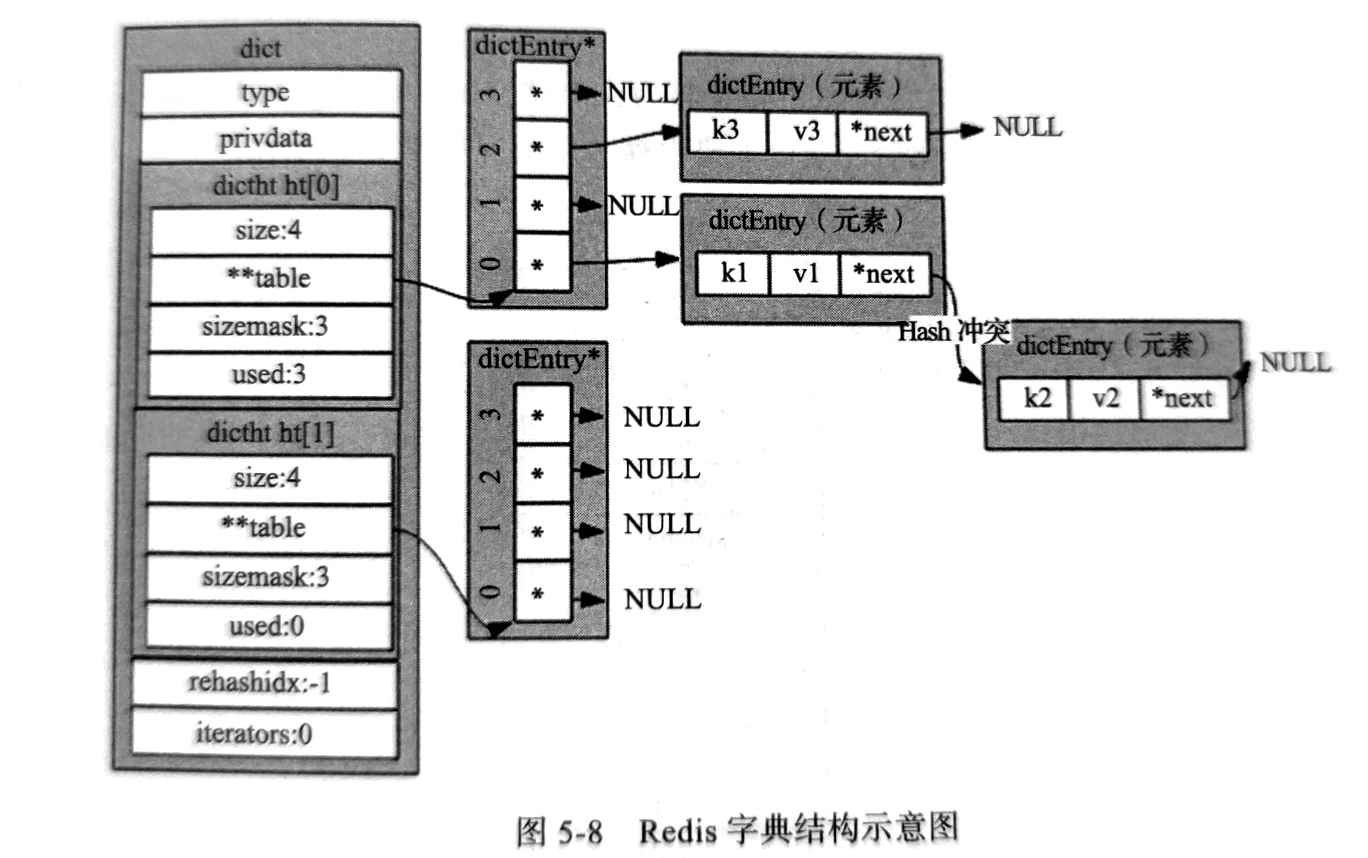
其实dictEntry的v字段是一个union变量,如下所示:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
如果v是整数就保存在v.u64或者v.s64,浮点数就保存在v.d,而如果v是复杂点的数据比如这里的6个dictEntry的v字段既要保存该数据类型的一些统计信息又要记录该数据类型的最大的key是谁,那么只有新建一种结构体typeinfo,并通过dictEntry的v.val字段指向typeinfo结构体。
字典types_dict里面保存了6个kv对(dictEntry),每个dictEntry的v的初始值为type_xxx常量,下面是typeinfo的结构定义以及各type_xxx的值:
typedef struct {
char *name;//数据类型,如string
char *sizecmd;//查询大小命令,如string会调用STRLEN
char *sizeunit;//单位,string类型为bytes,而hash为field
unsigned long long biggest;//最大key信息域,此数据类型最大key的大小,如string类型是多少bytes,hash为多少field
unsigned long long count;//统计信息域,此数据类型的key的总数
unsigned long long totalsize;//统计信息域,此数据类型的key的总大小,如string类型是全部string总共多少bytes,hash为全部hash总共多少field
sds biggest_key;//最大key信息域,此数据类型最大key的键名,之所以在数据结构末尾是考虑字节对齐
} typeinfo;
typeinfo type_string = { "string", "STRLEN", "bytes" };
typeinfo type_list = { "list", "LLEN", "items" };
typeinfo type_set = { "set", "SCARD", "members" };
typeinfo type_hash = { "hash", "HLEN", "fields" };
typeinfo type_zset = { "zset", "ZCARD", "members" };
typeinfo type_stream = { "stream", "XLEN", "entries" };
typeinfo type_other = { "other", NULL, "?" };
name字段是用来记录该结构体记录的那种数据类型,sizecmd用来记录对此种数据类型改用什么命令来查询其大小,sizeunit则是该数据类型的大小单位,而count、totalsize则是记录一些统计信息,遍历到某个key的时候,无论是不是bigkey,都会更新count和totalsize,biggest_key记录最大key是谁,biggest则记录这个最大key有多大。之所以type_string等常量只有前三个域的值,是因为biggest、count等域只有在遍历时才会产生并发生改变,初始是不知道的。
其实按效率上来讲可以完全不用dict结构,直接用一个大小为6的typeinfo数组就行,但是作者或许对自己的字典结构很自豪所以就不用其他数据结构了。事实当你了解字典结构的细节后也会爱上它**(●’◡’●)**。
紧接着是获取数据库总大小和输出一些前置消息:
/* Total keys pre scanning */
total_keys = getDbSize();
/* Status message */
printf("\n# Scanning the entire keyspace to find biggest keys as well as\n");
printf("# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec\n");
printf("# per 100 SCAN commands (not usually needed).\n\n");
total_keys保存数据库总key数
2.调用scan命令迭代地获取一批key
之所以用scan命令而不用keys命令是因为keys命令虽然可以一次性返回所有key,但是由于redis执行命令的时候是单线程模型,数据库过大的话会严重阻塞服务器,因而使用scan命令一次获取部分key然后再迭代获取下一批key这样更好。
/* SCAN loop */
do {
/* Calculate approximate percentage completion */
pct = 100 * (double)sampled/total_keys;//这里记录下扫描的进度
/* Grab some keys and point to the keys array */
reply = sendScan(&it);//这里发送SCAN命令,结果保存在reply中
keys = reply->element[1];//keys来保存这次scan获取的所有键名,注意只是键名,每个键的数据类型是不知道的。
......
} while(it != 0);
sampled记录已经遍历的key数量,pct则为百分比进度。reply保存scan命令的结果。为什么是reply->element[1]保存了所有键名呢?怕小伙伴忘记了scan命令,这里再解释下,scan命令返回值如下(后续很多地方会用到这里的运行结果):
127.0.0.1:6379> scan 0
1) "20480"
2) 1) "zset_32_4769"
2) "set_32_1808"
3) "zset_32_9252"
4) "list_32_3402"
5) "set_32_5036"
6) "string_32_1957"
7) "string_32_2471"
8) "hash_32_1481"
9) "hash_32_853"
10) "string_32_2945"
scan 0表示从数据库开头获取一批key,返回的第一个值是下一次迭代的值,下一次scan命令就是scan 20480,这样就可以保证获取的下一批key和这一批是不一样的,sendScan(&it)的it既是输入值也是输出值,比如上面输入的时候是0,执行完后是20480。同时reply->element[0]也为下次迭代的值,reply->element[1]则保存scan获取的所有键名。
这里在解释下reply的数据结构,以方便后续代码理解。reply的数据结构是redisReply:
/* This is the reply object returned by redisCommand() */
typedef struct redisReply {
int type; /* REDIS_REPLY_* */
long long integer; /* 当type为REDIS_REPLY_INTEGER,这里保存整数 */
double dval; /* 当type为REDIS_REPLY_DOUBLE,这里保存浮点数 */
size_t len; /* string的长度 */
char *str; /* Used for REDIS_REPLY_ERROR, REDIS_REPLY_STRING
and REDIS_REPLY_DOUBLE (in additionl to dval). */
char vtype[4]; /* Used for REDIS_REPLY_VERB, contains the null
terminated 3 character content type, such as "txt". */
size_t elements; /* elements的数量, for REDIS_REPLY_ARRAY */
struct redisReply **element; /* 当type为REDIS_REPLY_ARRAY,保存返回的向量 */
} redisReply;
type表示命令返回值的类型,如果命令返回的是整数,比如strlen命令返回值是整数,那么type的值就为REDIS_REPLY_INTEGER,而interger域则保存了这个整数。同理当type为REDIS_REPLY_ARRAY时,elements域保存该数组的长度,比如上面scan命令返回的reply->elements就是2,最后一个域struct redisReply **element可能有点难理解,其实就是一个指针数组,数组的每个元素是一个redisReply*指针,这里还是通过上面scan命令画出内存结构图:
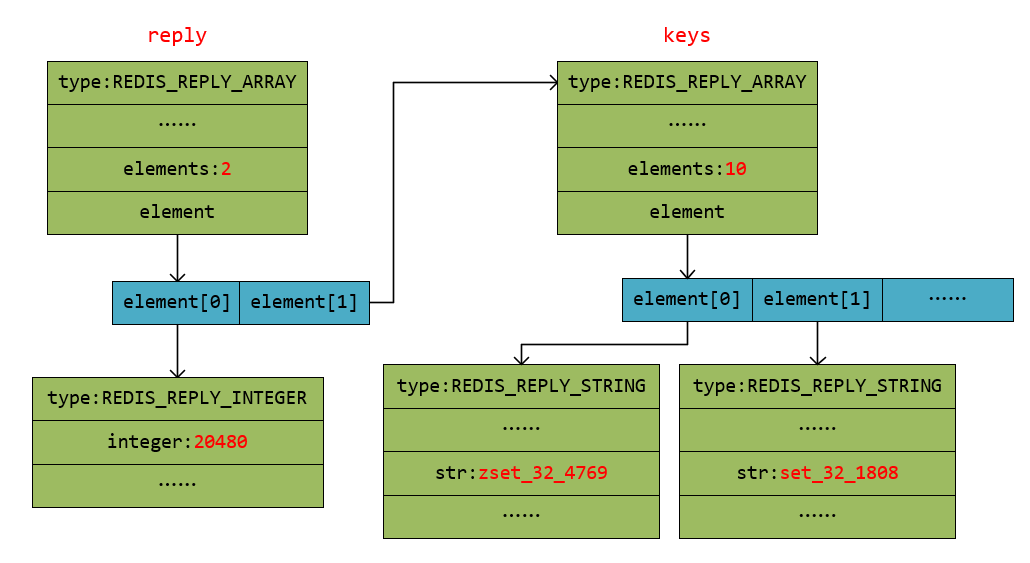
image-20210127130938852.png
这里可以很清楚地看到,reply->element[0]指向一个redisReply结构体,用以保存下一次scan的迭代值,而reply->element[1]也指向一个redisReply结构体,此结构体保存了本次scan获取的所有key的键名。
3.对每个key获取它的数据类型(type)和key的大小(size)
通过scan命令得到reply、keys = reply->element[1]得到这批键名后,就可以通过键名去获取它的类型(type)和大小(size):
/* Retrieve types and then sizes */
getKeyTypes(types_dict, keys, types);
getKeySizes(keys, types, sizes, memkeys, memkeys_samples);
types是一个typeinfo*的指针数组,sizes则为unsigned long long的数组。每个scan循环开始它们都是空的,如下图所示:
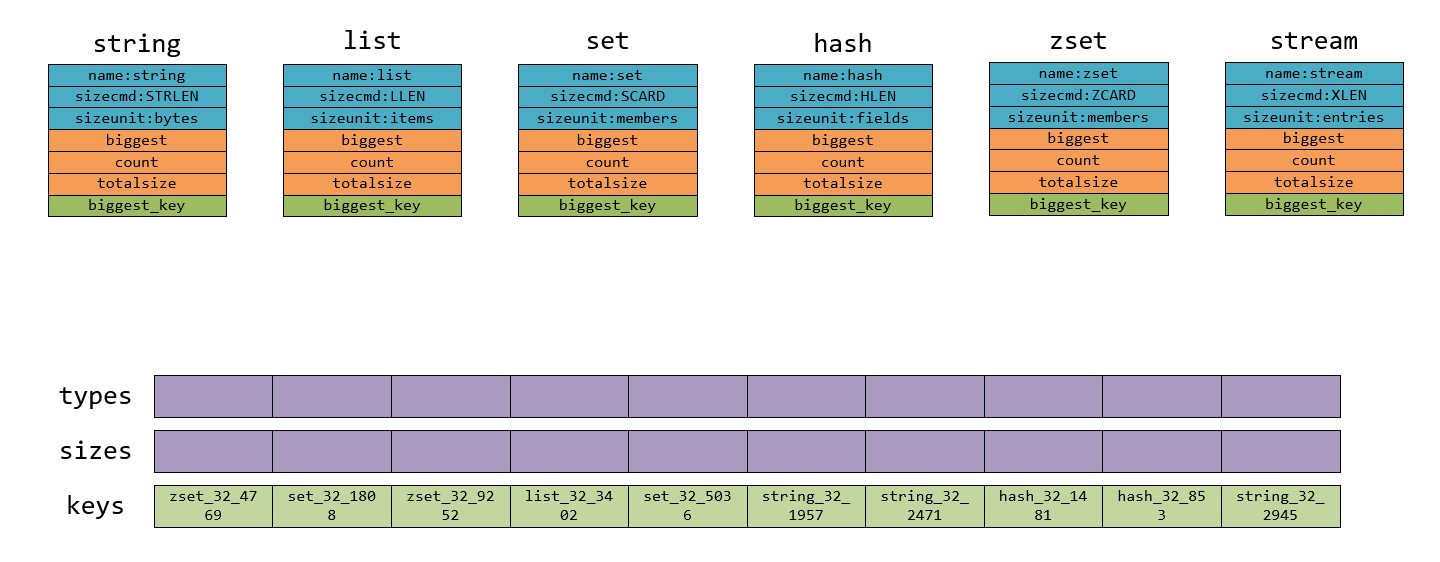
getKeyTypes(types_dict, keys, types)函数则是对keys中的每个key,通过TYPE {keyname}的形式获取该key的类型并使types中的元素指向对应的type_info结构体:
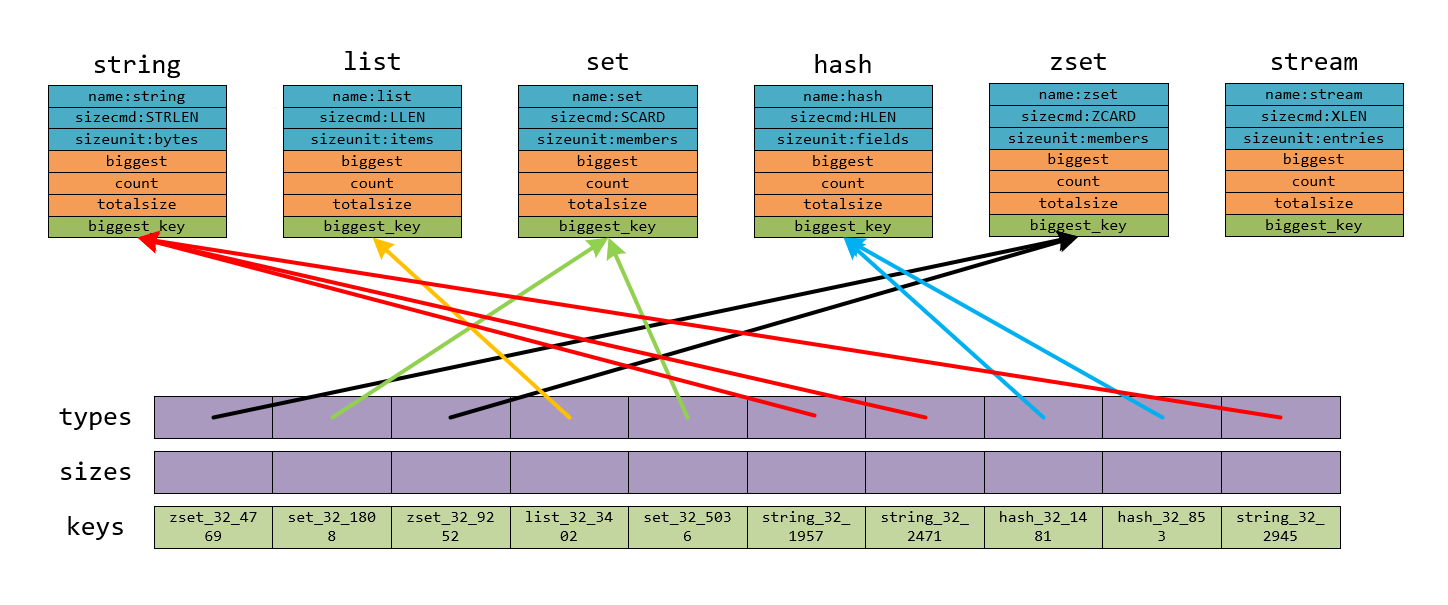
之后通过types就可以获得对应的sizecmd,于是getKeySizes(keys, types, sizes, memkeys, memkeys_samples)就是通过{sizecmd} {keyname}的形式获取每个key的大小,比如图中zset_32_4769这个key我们可以通过ZCARD zset_32_4769获取到它的size为10。结果如下:
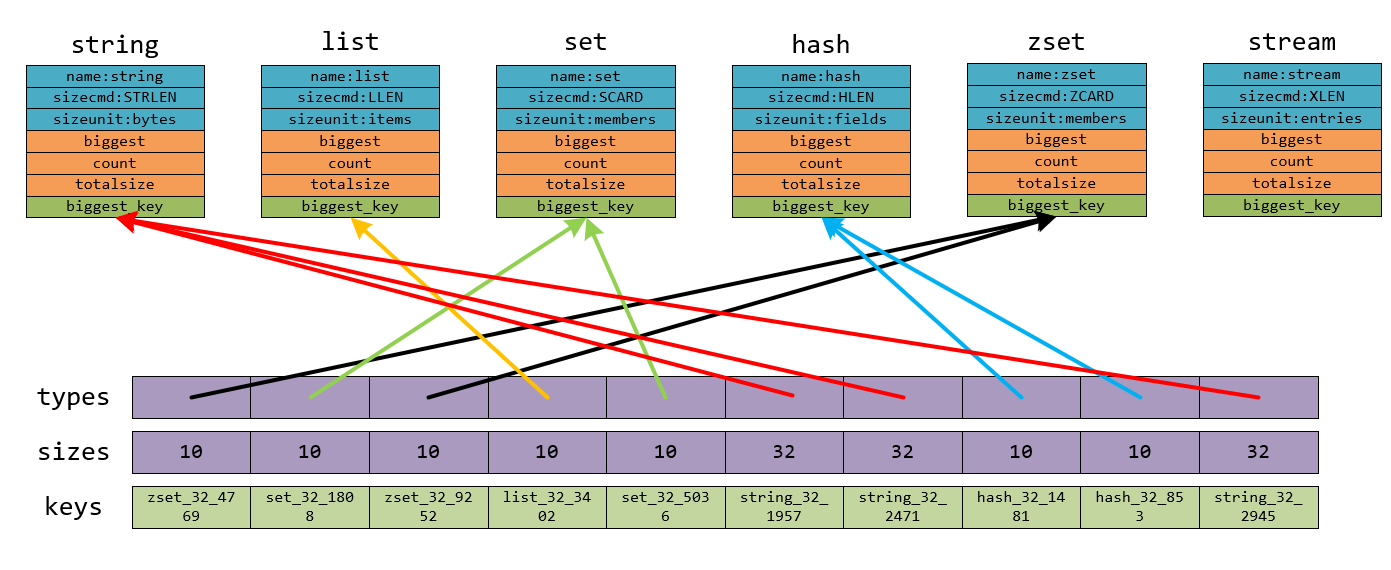
memkeys、 memkeys_samples参数,和–bigkeys无关,和–memkeys选项有关,这里不再赘述。
4.对每个key更新对应数据类型的统计信息
有了types和sizes后,就可以来更新各typeinfo结构体变量了。
/* Now update our stats */
for(i=0;i<keys->elements;i++) {
typeinfo *type = types[i];
/* Skip keys that disappeared between SCAN and TYPE */
if(!type)
continue;
//对每个key更新每种数据类型的统计信息
type->totalsize += sizes[i];//某数据类型(如string)的总大小增加
type->count++;//某数据类型的key数量增加
totlen += keys->element[i]->len;//totlen不针对某个具体数据类型,将所有key的键名的长度进行统计,注意只统计键名长度。
sampled++;//已经遍历的key数量
......//后续解析
/* Update overall progress */
if(sampled % 1000000 == 0) {
printf("[%05.2f%%] Sampled %llu keys so far\n", pct, sampled);
}
}
不管该key是不是bigkey,totalsize记录该类型的所有key的总大小,count则记录有多少key。而totlen变量不属于typrinfo结构体,它只是用来记录所有类型的所有key的键名的总长度,加入一个数据库只有两个key:string_1、hash_3,那么totlen就是8+6=14。sampled之前说过,就是来记录已经遍历到第几个key了,用来计算进度信息。
5.如果key的大小大于已记录的最大值的key,则更新最大key的信息
/* Now update our stats */
for(i=0;i<keys->elements;i++) {
......//前面已解析
//如果遍历到比记录值更大的key时
if(type->biggest<sizes[i]) {
/* Keep track of biggest key name for this type */
if (type->biggest_key)
sdsfree(type->biggest_key);
//更新最大key的键名
type->biggest_key = sdscatrepr(sdsempty(), keys->element[i]->str, keys->element[i]->len);
if(!type->biggest_key) {
fprintf(stderr, "Failed to allocate memory for key!\n");
exit(1);
}
//每当找到一个更大的key时则输出该key信息
printf(
"[%05.2f%%] Biggest %-6s found so far '%s' with %llu %s\n",
pct, type->name, type->biggest_key, sizes[i],
!memkeys? type->sizeunit: "bytes");
/* Keep track of the biggest size for this type */
//更新最大key的大小
type->biggest = sizes[i];
}
......//前面已解析
}
if(type->biggest<sizes[i])表示该typeinfo结构体已记录的最大key的大小如果小于正在遍历到的key的大小时,则进行更新替换。因为type->biggest_key是字符串指针,所以需要先free掉旧的字符串然后新建一个字符串并让type->biggest_key指向它。更新了type->biggest_key后便同时更新下type->biggest。
到这里一个scan循环还没结束,scan循环最后会执行以下代码:
/* Sleep if we've been directed to do so */
if(sampled && (sampled %100) == 0 && config.interval) {
usleep(config.interval);
}
如果设置了每次scan命令的间隔,则一次scan完后会睡眠一段时间再执行scan循环,呼应最开始的/* Status message */。
7.输出统计信息、最大key信息
2~5步为一个scan循环,直到最后一次scan返回的迭代值为0时结束。接着就可以进行结果是输出了:
/* We're done */
printf("\n-------- summary -------\n\n");
printf("Sampled %llu keys in the keyspace!\n", sampled);
printf("Total key length in bytes is %llu (avg len %.2f)\n\n",
totlen, totlen ? (double)totlen/sampled : 0);
首先输出总共扫描了多少个key、所有key的总长度是多少。
/* Output the biggest keys we found, for types we did find */
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
if(type->biggest_key) {
printf("Biggest %6s found '%s' has %llu %s\n", type->name, type->biggest_key,
type->biggest, !memkeys? type->sizeunit: "bytes");
}
}
dictReleaseIterator(di);
di为字典迭代器,用以遍历types_dict里面的所有dictEntry。de = dictNext(di)则可以获取下一个dictEntry,de是指向dictEntry的指针。又因为typeinfo结构体保存在dictEntry的v域中,所以用dictGetVal获取。然后就是输出typeinfo结构体里面保存的最大key相关的数据,包括最大key的键名和大小。
di = dictGetIterator(types_dict);
while ((de = dictNext(di))) {
typeinfo *type = dictGetVal(de);
printf("%llu %ss with %llu %s (%05.2f%% of keys, avg size %.2f)\n",
type->count, type->name, type->totalsize, !memkeys? type->sizeunit: "bytes",
sampled ? 100 * (double)type->count/sampled : 0,
type->count ? (double)type->totalsize/type->count : 0);
}
dictReleaseIterator(di);
这里的dict操作和上一步类似,不在赘述。只是这个循环输出的是typeinfo结构体里面的统计信息而非最大key信息。
dictRelease(types_dict);
findBigKeys的最后再释放掉开头申请的字典,以结束整个找bigkey的流程。
redis-bigkey-online
终于将–bigkeys选项的源码讲完了~那么现在就开始正式介绍redis-bigkey-online项目,项目地址会放在文末。下面将从设计思路、具体代码、使用方法、性能比较四个方面进行讲解。
设计思路
设计思路其实很简单。看完了前面–bigkeys源码我们可以发现,redis作者本身其实就是用了5个typeinfo保存各数据类型的信息,但是遗憾的是作者只保存了每种数据类型top1的一个key,每次扫描到较大的key时会对旧的bigkey进行替换。所以我就想能不能保存前N个大key而不只是top1,自然第一时间想到了大/小顶堆。根据用户的设定维护一个长度N的大/小顶堆,当数据数量小于N时直接插入就好了,当数据满时将正在扫描的key和堆中最小值进行比较,如果小于堆中最小值就直接跳过,如果大于就先删除堆中最小值然后再将扫描的key插入。并且堆也十分适合用线性空间来实现,十分节省空间。
然而堆插入数据时,虽然空间复杂度小,但是插入元素时调整堆的时间复杂度时O(nlgn)。我在想有没有更快的带排序功能的数据结构,这时候就突然想到了redis自己的数据类型——zset!zset和set的区别在于set里的元素只是元素自身,而zset的每个元素还带有分数(score),zset会根据元素的score对元素进行自动排列,十分适合我的需求,score保存bigkey的大小、member保存该bigkey的键名!而zset的底层数据结构之一就是喜闻乐见的跳跃表!其插入元素的时间复杂度度为O(lgn)!虽然空间复杂度相较堆多了不少,但是我们找bigkey也就是想找其中的几个数据,不可能数据库全部数据都是bigkey!
关于跳表的介绍参照这篇博文:一文彻底搞懂跳表的各种时间复杂度、适用场景以及实现原理
skiplist作为zset的存储结构,整体存储结构如下图。核心点主要包括一个dict对象和一个skiplist对象。dict保存key/value,key为元素,value为分值;skiplist保存的有序的元素列表,每个元素包括元素和分值。skiplist和dict并不是独立的数据结构,skiplistNode的ele和dictEntry的key是指向了同一sds字符串,就是说skiplist主要负责各元素间的大小排列关系;而dict则负责键名和分数之间的映射关系,从而可以在O(1)的时间复杂度找到对应的数据。关键是,我还不用重新写zset数据类型的代码,直接使用源码的zset相关数据结构就行了!(❁´◡`❁)
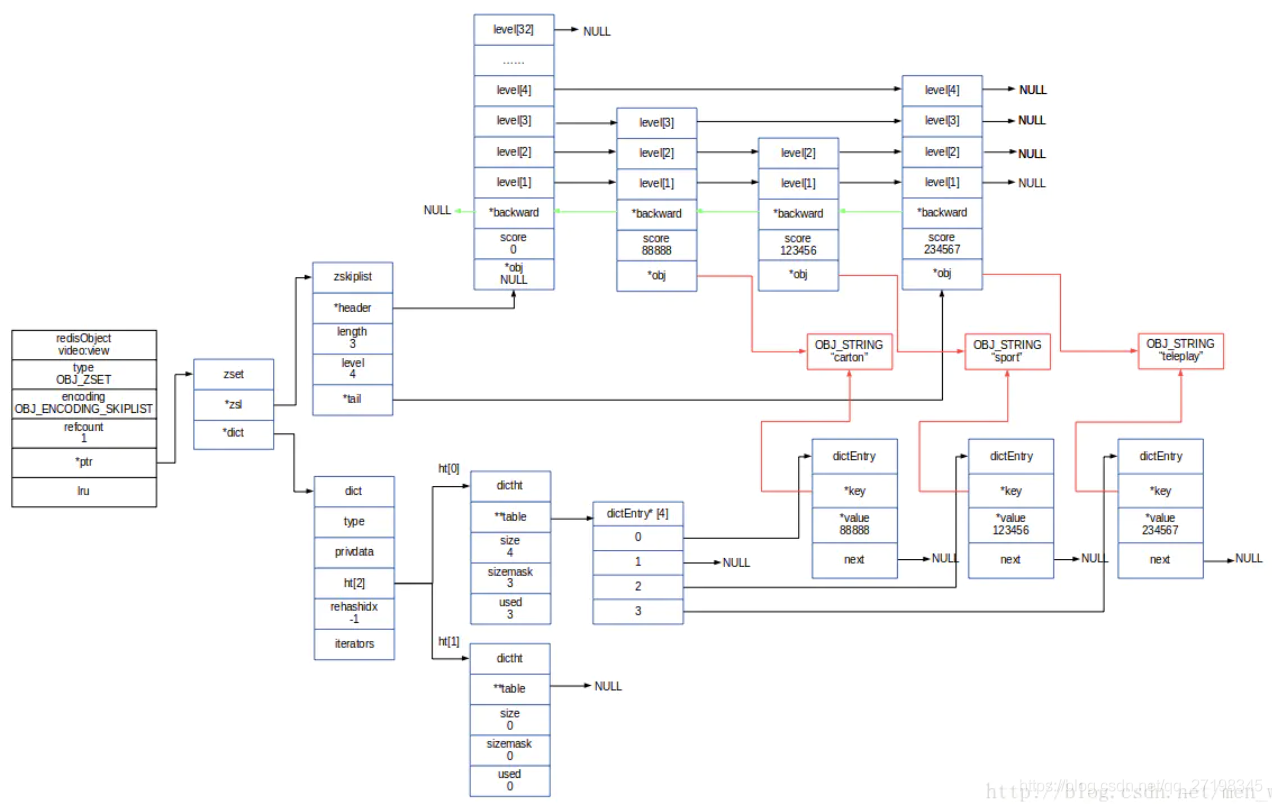
20200918235136825.png
具体代码
理想很丰满,现实却很残酷,zset相关源码确实可以用,但是不能直接用。redis里面有很多很优秀的数据结构,比如sds动态字符串、dict字典、ziplist压缩列表等等以及skiplist跳跃表。有些数据结构适用性很强比如sds、dict,不仅redis-server程序会用到,redis-cli程序也会用到,所以sds、dict相关代码单独形成一个文件sds.c、dict.c并且函数声明在sds.h和dict.h,server.c、redis-cli.c中只要#include "sds.h"、#include "dict.h"就可以使用该数据结构。然而有些数据结构就比如这里的skiplist,作者认为只有服务端程序redis-server会用到,客户端程序redis-cli不会用到,所以根本就没有skiplist.h和skiplist.c,skiplist的声明是直接写在server.h中,skiplist的函数实现则写在t_zset.c中。你或许会说,那redis-cli.c中你直接#include "server.h"并且makefile里面链接形成redis-cli程序时八t_zset.o链接进来不行吗?
不行!达妹哟!
server.h里面有很多是服务器端程序会用到的函数声明比如usage()、mstime()、utime()等会和redis-cli.c里的同名函数发生函数冲突,并且t_zset.c中也使用了大量的server.c中的函数,如果链接程序时只链接t_zset.o会报错提示大量的函数未定义的错误!这时候再心存侥幸说链接形成redis-cli程序时把server.o也链接进来行不行?这样就更离谱了!server.c是服务端程序的主文件,里面有main函数入口!redis-cli.c是客户端程序的主文件,里面有main函数入口!这种低级函数冲突是不该犯的!
所以主要问题是zset和server.c的耦合性太高了!现在只能去阅读zset、skiplist相关源码,将重要的代码提炼出来,形成一个和server.c、redis-cli.c相互独立的一个文件,这样redis-cli.c就可以开开心心地去使用啦~也希望redis作者能将众数据结构代码进行解耦操作,不要只有sds和dict是独立的。
提取代码其实不麻烦,并不是所有有关代码都需要,并且绝大部分代码直接cv下来就行,我们只需要认真阅读源码,将zset的一些关键函数提炼出来就行。我将提炼的代码写在了zset.h和zset.c中:
//zset.h
//数据结构
#include "dict.h"
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
//函数声明
zskiplistNode *zslCreateNode(int level, double score, sds ele);
zskiplist *zslCreate(void);
void zslFreeNode(zskiplistNode *node);
void zslFree(zskiplist *zsl);
int zslRandomLevel(void);
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele);
zskiplistNode *zslUpdateScore(zskiplist *zsl, double curscore, sds ele, double newscore);
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update);
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node);
zset *zsetCreate(void);
void zsetFree(zset *zs);
unsigned long zsetLength(const zset *zs);
sds zsetMin(const zset *zs);
sds zsetMax(const zset *zs);
int zsetScore(zset *zs, sds member, double *score);
int zsetAdd(zset *zs, double score, sds ele);
int zsetDel(zset *zs, sds ele);
可以看到基本都是些增、删、改、查相关的函数,因为zset底层是skiplist和dict,dict因为作者已经做了解耦操作,所以直接#include "dict.h"就行,这里只是将跳表相关的数据结构提取了出来。在这里自己只还新增了zsetMin、zsetMax两个函数。zset底层编码有两种:skiplist和ziplist,这里将zset函数中所有ziplist相关的函数都进行了剔除工作,只保留了skiplist部分。仔细的同学会发现为什么skiplist相关函数没有zskiplistFind呢?这个问题很好回答,仔细看zset结构的编码,它包含一个zskiplist和dict,zskiplist只负责元素间的排序关系,而元素和分数的映射关系主要考dict,并且dict的查找复杂度是O(1)而skiplist的查找复杂度为O(lgn),所以zsetScore的实现就是通过dictFind来实现。
修改redis-cli.c
下面我们来看看对于源码redis-cli.c我们是如何做修改的:
首先是对typeinfo结构体的修改:
//old
typedef struct {
char *name;
char *sizecmd;
char *sizeunit;
unsigned long long biggest;
unsigned long long count;
unsigned long long totalsize;
sds biggest_key;
} typeinfo;
typeinfo type_string = { "string", "STRLEN", "bytes"};
typeinfo type_list = { "list", "LLEN", "items"};
typeinfo type_set = { "set", "SCARD", "members"};
typeinfo type_hash = { "hash", "HLEN", "fields"};
typeinfo type_zset = { "zset", "ZCARD", "members"};
typeinfo type_stream = { "stream", "XLEN", "entries"};
typeinfo type_other = { "other", NULL, "?" };
//new
typedef struct {
char *name;
char *sizecmd;
char *sizeunit;
int i_name;//数据类型(int)
unsigned long long count;
unsigned long long totalsize;
zset *bigkeys;
} typeinfo;
typeinfo type_string = { "string", "STRLEN", "bytes", BIT_STRING};
typeinfo type_list = { "list", "LLEN", "items", BIT_LIST};
typeinfo type_set = { "set", "SCARD", "members", BIT_SET};
typeinfo type_hash = { "hash", "HLEN", "fields", BIT_HASH};
typeinfo type_zset = { "zset", "ZCARD", "members", BIT_ZSET};
typeinfo type_stream = { "stream", "XLEN", "entries", BIT_STREAM};
typeinfo type_other = { "other", NULL, "?" ,BIT_OTHER};
旧的typeinfo只保存了biggest key的键名和大小,新的则将其删除,并增添一个zset指针来存储多个bigkey。其次还新增了int型的i_name变量,name是用字符串来表示该数据类型,而i_name则是用整数表示该数据类型,在后续查询对应数据类型配置信息时会用到。type_xxx常量的值也进行了改变,新增了BIT_XXX等值,从BIT_STRING到BIT_OTHER的是0~6。
其次,第一版程序支持对所有6种数据类型有以下功能:是否扫描该数据类型、输出最多多少个bigkey、bigkey阈值是啥三个功能。我定义了一个bigkeyConfig_t这种数据结构在zset.h中:
typedef struct bigkeyConfig_t{
uint64_t output_num;
uint32_t thro_size;
int need_scan;
}bigkeyConfig_t;
为了做到风格统一,因为redis服务器所有的配置信息都放在全局变量config中,所以我也将bigkeyConfig_t变量也放在config全局变量中:
static struct config {
char *hostip;
int hostport;
char *hostsocket;
......
//redis-bigkey-online
FILE *bk_pFile;//输出位置
bigkeyConfig_t *bk_config;//配置信息
} config;
我新增了两个变量放在config的末尾,bk_pFile是文件指针,表示用户想将程序结果输出在标准输出中还是文件中,这个可在配置文件bigkeys.conf进行设置;bk_config为bigkeyConfig_t*类型的指针,指向6个bigkeyConfig_t结构体,每一个结构体都表示对应一种数据类型的配置信息。
以上便是所有结构体的改动,下面我们跟着服务器启动的顺序来看下如何发挥作用:
1.main函数开头,对config进行默认初始化
2.main中,执行parseOptions对命令行参数进行解析
3.parseOptions中,执行loadBigKeyConfig对用户配置文件进行解析
3.回到main,执行findBigKeys开始找bigkeys
-
main函数入口,对
config全局变量进行默认初始化:int main(int argc, char **argv) { int firstarg; //redis-bigkey-online default config config.bk_pFile = stdout; config.bk_config = NULL; config.hostip = sdsnew("127.0.0.1"); config.hostport = 6379; config.hostsocket = NULL; config.repeat = 1; config.interval = 0; config.dbnum = 0; ......同时我们也为新增的域进行了默认设置,文件输出位置默认为stdout,配置信息指向NULL。
-
接着程序对redis-cli的命令行参数进行配置:
firstarg = parseOptions(argc,argv);static int parseOptions(int argc, char **argv) { int i; for (i = 1; i < argc; i++) { int lastarg = i==argc-1; if (!strcmp(argv[i],"-h") && !lastarg) { sdsfree(config.hostip); config.hostip = sdsnew(argv[++i]); } else if (!strcmp(argv[i],"-h") && lastarg) { usage(); } else if (!strcmp(argv[i],"--help")) { usage(); } else if (!strcmp(argv[i],"-x")) { config.stdinarg = 1; } else if (!strcmp(argv[i],"-p") && !lastarg) { config.hostport = atoi(argv[++i]); } else if (!strcmp(argv[i],"-s") && !lastarg) { config.hostsocket = argv[++i]; } ...... else if (!strcmp(argv[i],"--bigkeys")) { config.bigkeys = 1; loadBigKeyConfig(argv[++i],0); }parseOptions函数会对命令行参数进行解析,如用户输入redis-cli -h 127.0.0.1 -p 6379时则会对config中的地址和端口进行赋值。当程序识别到用户输入--bigkeys选项时,会让config.bigkeys标志位为1,注意此标志位是系统本来就有的,不是我新增的。我新增的是后面的loadBigKeyConfig()函数。旧的--bigkeys选项是没有后续参数的,因为我新增了找bigkey的配置文件,需要用户从redis-cli --bigkeys变为redis-cli --bigkeys bigkeys,conf,所以loadBigKeyConfig(argv[++i],0)就是加载后续参数对应的配置文件并进行解析: -
对用户设置的配置文件进行解析:
loadBigKeyConfig()函数是参照了server.c中的loadServerConfig()函数。首先给config.bk_config分配6个结构体大小的内存,然后打开配置文件,如果打开文件成功就将配置文件的所有内容一行一行地追加到字符串变量config_str当中:void loadBigKeyConfig(const char *filename,int memkeys){ sds config_str = sdsempty(); char buf[CONFIG_MAX_LINE+1]; char *err = NULL; int linenum = 0, totlines, i; long int config_val; sds *lines; config.bk_config = zmalloc(6*sizeof(bigkeyConfig_t)); /* Load the file content */ if (filename) { FILE *fp; if ((fp = fopen(filename,"r")) == NULL) { printf("Fatal error, can't open config file '%s': %s", filename, strerror(errno)); exit(1); } while(fgets(buf,CONFIG_MAX_LINE+1,fp) != NULL) config_str = sdscat(config_str,buf); fclose(fp); } ...... }当配置文件全部追加到
config_str变量后,调用sdssplitlen()函数将config_str以换行符为界进行切割,将各行依次存入lines字符串数组中。紧接着就是对每行内容进行处理,包括跳过空行、检查配置信息格式是否正确、将正确配置信息存入config.bk_config中等等:void loadBigKeyConfig(const char *filename,int memkeys){ ...... lines = sdssplitlen(config_str,strlen(config_str),"\n",1,&totlines); for(i=0;i<totlines;++i){ sds *argv; int argc; linenum = i+1; lines[i] = sdstrim(lines[i]," \t\r\n"); /* Skip comments and blank lines */ if (lines[i][0] == '#' || lines[i][0] == '\0') continue; /* Split into arguments */ argv = sdssplitargs(lines[i],&argc); if (argv == NULL) { err = "Unbalanced quotes in configuration line"; goto loaderr; } ...... } sdsfreesplitres(argv,argc); } sdsfreesplitres(lines,totlines); sdsfree(config_str); return; }加载、解析完用户的配置文件后,便可以继续往下走了。
-
执行
findBigKeys()函数当用户的配置文件解析完(
loadBigKeyConfig)回到redis-cli的解析命令行参数函数中(parseOptions),当所有命令行参数都解析完后就回到主函数中(main)继续向下运行:int main(int argc, char **argv) { ...... /* Find big keys */ if (config.bigkeys) { if (cliConnect(0) == REDIS_ERR) exit(1); findBigKeys(0, 0); } ...... }如果
config.bigkeys标志位被设置了,那就执行findBigKeys函数。 -
findBigKeys()具体流程此函数最开头已经分析过了,这里只讲变化的部分,首先是所有的printf函数变成fprintf函数,根据
config.bk_pFile的值决定输出位置,如://old /* Status message */ printf("\n# Scanning the entire keyspace to find biggest keys as well as\n"); printf("# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec\n"); printf("# per 100 SCAN commands (not usually needed).\n\n"); //new /* Status message */ fprintf(config.bk_pFile,"\n# Scanning the entire keyspace to find biggest keys as well as\n"); fprintf(config.bk_pFile,"# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec\n"); fprintf(config.bk_pFile,"# per 100 SCAN commands (not usually needed).\n\n");其次就是判断bigkey及其处理过程,旧程序是用
typeinfo结构体记录的最大key和目前正在遍历的key作比较,目前遍历到的key更大的话就替换typeinfo结构体里面原本的最大key信息(biggest和biggest_key)。新版代码会先判断config.bk_config的配置信息,看该类型的key是否需要记录,不需要直接跳过。接着判断该key是否大于该类型的阈值,大于的话只能说明它是个bigkey,但是还要进一步判断是否超过了我们需要的bigkey数量。如果数量还没到上限则直接将该bigkey插入typeinfo结构体的zset里面,如果达到上限的话和zset的最小值进行比较,大于最小值就先删除最小值再将此key插入,如果小于最小值那就直接舍弃此key://old if(type->biggest<sizes[i]) { /* Keep track of biggest key name for this type */ if (type->biggest_key) sdsfree(type->biggest_key); type->biggest_key = sdscatrepr(sdsempty(), keys->element[i]->str, keys->element[i]->len); if(!type->biggest_key) { fprintf(stderr, "Failed to allocate memory for key!\n"); exit(1); } /* Keep track of the biggest size for this type */ type->biggest = sizes[i]; } //new //如果不是所需要输出的类型,跳过分析 if(!config.bk_config[type->i_name].need_scan) continue; //如果key大于对应类型的阈值 if(sizes[i] >= config.bk_config[type->i_name].thro_size) { sds keyname = sdscatrepr(sdsempty(), keys->element[i]->str, keys->element[i]->len); if(!keyname) { fprintf(stderr, "Failed to allocate memory for key!\n"); exit(1); } //统计的大key数量还没到上限 if(zsetLength(type->bigkeys) < config.bk_config[type->i_name].output_num){ zsetAdd(type->bigkeys,sizes[i],keyname); }else{ double score; sds min_key = zsetMin(type->bigkeys); zsetScore(type->bigkeys,min_key,&score); //如果key的大小大于已记录的大key的最小值 if(sizes[i] > (unsigned long long)score){ zsetDel(type->bigkeys,min_key); zsetAdd(type->bigkeys,sizes[i],keyname); } } sdsfree(keyname); }然后就是输出统计信息,输出完后释放各种用到的结构体内存然后回到main函数。以上就是整个解析流程了。
性能比较
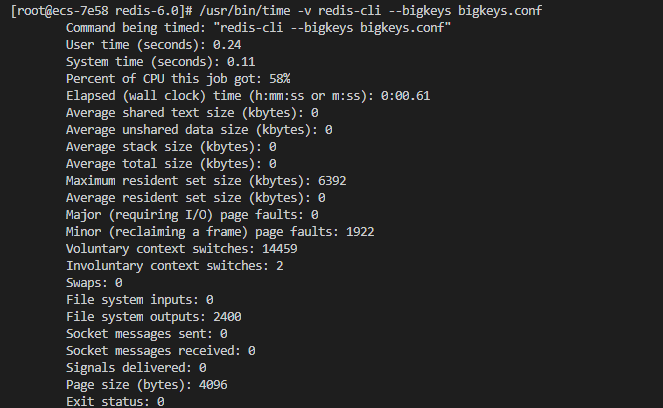
这里比较解析能力,就把bigkey阈值设为0,输出数量也设为无上限,并且全部数据类型都要解析。事先通过脚本向redis服务中string、list、set、zset、hash中各插入10000个normalkey和2两个bigkey,stream类型不插入数据。并且通过/usr/bin/time -v获取进程执行时间、cpu利用率等信息。
redis-bigkey-online
可以看到用户运行时间为0.24秒,系统运行时间为0.11秒,cpu占用率为58%,最大占用内存为6392字节。
python脚本
import sys
import redis
if __name__ == '__main__':
if len(sys.argv) != 4:
print('Usage: python ', sys.argv[0], ' host port outputfile ')
exit(1)
host = sys.argv[1]
port = sys.argv[2]
outputfile = sys.argv[3]
r = redis.StrictRedis(host=host, port=int(port))
f = open(outputfile, "w")
for k in r.scan_iter():
length = 0
try:
type = r.type(k)
if type == b'string':
length = r.strlen(k)
elif type == b'hash':
length = r.hlen(k)
elif type == b'list':
length = r.llen(k)
elif type == b'set':
length = r.scard(k)
elif type == b'zset':
length = r.zcard(k)
elif type == b'stream':
length = r.xlen(k)
except:
sys.exit(1)
if length > 0:
print(k, type, length, file=f)
虽然代码足够精简,但是可以看到用户运行时间为4.99秒,系统运行时间为1.27秒,cpu占用率为79%,最大占用内存为13060字节。
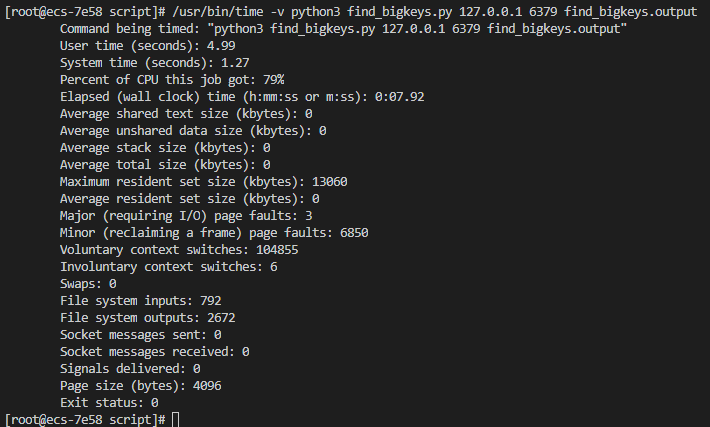
redis-rdb-tools(已安装python-lzf)
redis-rdb-tools是github非常受欢迎的一款分析rdb文件的工具,有4k+的star数。并且由于其是离线方式分析redis的持久化文件,避免了客户端命令查询的网络IO消耗,理论上速度是快于脚本的。redis-rdb-tools的-c justkeys选项是其最快的解析命令,只输出键名不输出其他信息,下面为测试结果:
惨不忍睹!可以看到用户运行时间为18.55秒,系统运行时间为0.16秒,cpu占用率为99%,最大占用内存为60548字节。由于redis-rdb-tools实现的功能过于冗杂繁多,所以反而导致其速度远低于存python脚本。
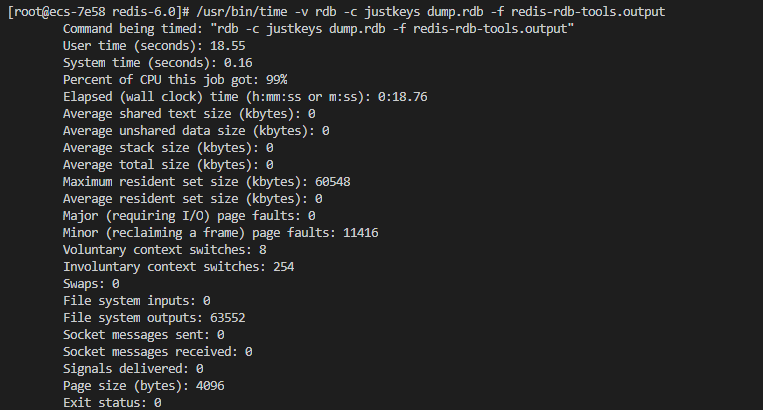
image-20210202152132722.png
常见问题
-
你的项目这么好,有什么缺陷吗?
这个项目和所有在线脚本一样,因为
--bigkeys选项的源码本质就是客户端不断发送命令给服务器进行查询信息实现的,所以尽量避免在远程的客户端运行该选项,尽量在服务器本地执行程序 -
为什么不实现输出bigkey时同时将该key属于哪个数据库的信息也输出?
这里不是没想到,是没必要。因为redis-cli本身就实现了这个功能。我们加入我们想找3号数据库的bigkey,就使用
./redis-cli -h 127.0.0.1 -p 6379 -n 3 --bigkeys bigkeys.conf如果不输入
-n选项就是默认连接0号数据库。这样还有个好处就是你可以建立一个脚本开多线程,每个线程分析一个数据库,这样可以最大限度地利用CPU资源。 -
为什么不实现输出bigkey时同时将该key的expire(过期时间)信息也输出?
后续版本支持。
-
你为啥不也去实现个rdb版本的bigkey查找程序?
然而事实是我之前实现过,在之前实习期间mentor就叫我实现个找bigkey的程序。当时就是深入了解redis源码后用纯C实现了redis-rdb-bigkey项目,性能上也是吊打
redis-rdb-tools。而这次修改源码的动力之一也是我曾经做过的redis-rdb-bigkey项目。 -
通过命令查询的方式有个缺陷就是只知道比如hash的field数量是多少而不能确定整个hash数据占用的内存是多少!
淦!就等你问这句话了!!! 确实拿hash来说,field数量多不代表它占用的内存就大,field数量少也不一定代表它占用内存就小,比如一个hash只有两个field,但是每个field大小有一个G!这无疑是一个bigkey,所以只通过HLEN命令获取它的field数量来判断是不是bigkey很偏颇。
但是如果你仔细看
findBigKeys(int memkeys, unsigned memkeys_samples)会发现它有两个参数memkeys、memkeys_samples,这两个参数是和--memkeys选项有关的,如果你运行的时–memkey的话,那么memkeys的值就为1,那findBigKeys()函数查询单个key的命令就变成了MEMORY USAGE {keyname},从而可以获得每一个key的实际内存占用大小!对源程序稍加改变就可以实现--memkeys选项的个性化使用,现版本已支持如下命令:./redis-cli -h 127.0.0.1 -p 6379 --memkeys memkeys.confmemkeys.conf和bigkeys.conf唯一不同的就是xx_thro_size都变成了带单位的阈值,比如hash_thro_size 30KB。以下是一次运行结果: