最近小小地研究了一下SVM,发现这个算法还是相当有意思,今天来给大家讲讲其原理。

首先假设每个样本的特征值为X1、X2...到Xn,即有n个特征值。θ1、θ2、θ3...θn为对应权值。
那么要将上图两类红色的X和白色的O分类的话,最简单的方法就是找到合适的权值,使得:
当θ0+θ1*X1+θ2*X2+...θn*Xn>=0时 将样本分为第一类。当式子<0时,分为第二类。
将该式拓展一下可以变成θ0+θ1*f1+θ1*f2+...θn*fn,其中f1可以等于X1,f2可以等于X2等等,如图所示。通过加入高阶项我们可以得到更多的特征,但也使计算变得相当复杂。

因此我们引入更好的f函数。在上图坐标系中随机取三个点l1、l2、l3,给定一个样本X(有X1、X2两个特征),我们定义相似度函数:
f1=similarity(X,l1) 此表达式为X和l1的相似度函数=exp(-||X-l1||^2/2δ^2)
其中exp为以自然常数e为底的指数函数,||X-l1||代表X点到l1点的欧氏距离。
这个相似度函数就被称为高斯核函数。同理f2是X和l2的高斯核函数......

推广到一个样本的所有特征,f1=每个特征与l1的高斯核函数之和。 f2=每个特征与l2的高斯核函数之和。
也就是说,若是有m个l点,那么给你一个样本的话,便可以求出f1、f2...fm.
我们来看看为什么这个特征函数是有效的。
见上图,如果X点和l点距离很近的话,那么f=e的0次方,约等于1,。而若X与l点距离很远的话,f约等于e的负无穷次方为0。完成了很好的分类工作。
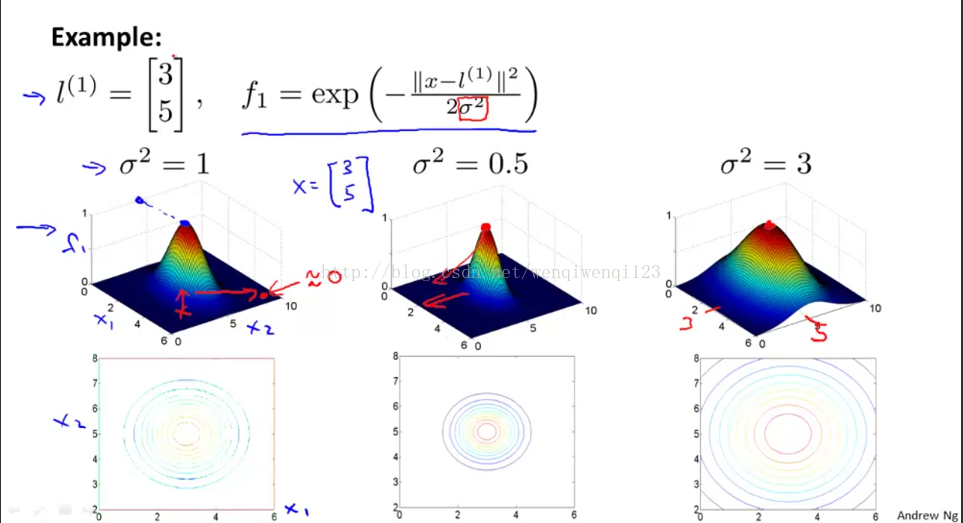
这就是高斯核函数的图像,在l点的时候值为1,越远离越接近0. 当δ值越小就越陡,越大就越缓。

让我们看看SVM是如何完成分类的。假设算法已经找到了最优的θ值,θ0=-0.5,θ1=1,θ2=1,θ3=0.
当θ0+θ1*f1+θ2*f2+θ3*f3>=0时,分为第一类,否则为第二类。
那么假设图中紫色的点,很接近l1,则计算出来该式等于0.5,分为第一类。
同理图中绿色的点也为第一类。
而青色的点算出来等于-0.5,分为第二类。所以SVM得出了图中红色边框的决策边界,与实际情况相同。
其中对于超参数的选择:

所以这就是高斯核函数,如果你想了解SVM如何选择标记点,以及引入核函数后的损失函数,建议你可以看下一篇文章。
机器学习--SVM(支持向量机)标记点选择与损失函数_wenqiwenqi123的博客-CSDN博客_支持向量机的损失函数