本文是对卷积神经网络(CNN)的简要介绍。本文详细介绍了PyTorch Lightning的优点,然后简要介绍了CNN组件的理论,并描述了使用PyTorch Lightning库从头开始编写的简单CNN架构的训练循环的实现。
为什么选择PyTorch Lightning?
PyTorch是一个灵活且用户友好的库。如果说PyTorch在研究方面非常优秀,我认为Lightning在工程方面更胜一筹。其主要优点包括:
代码量少。在运行机器学习项目时,很多事情可能会出错,因此将样板代码委托给库并专注于解决特定问题对我来说很有帮助。使用内置功能可以减少编写的代码量,从而降低错误的概率。开发(和调试)时间也减少了。
代码结构良好。
高效且训练速度快。Lightning还允许使用PyTorch的所有多进程和并行工作技巧(如DDP),而无需编写额外的代码。
内置开发工具,如健全性检查(用于验证和训练循环以及模型架构)、即时创建过拟合数据集、早停回调、最佳权重管理等。例如https://lightning.ai/docs/pytorch/stable/debug/debugging_basic.html
想要了解更多官方认可的原因,可以参考这里。
https://pytorch-lightning.readthedocs.io/en/0.10.0/introduction_guide.html#why-pytorch-lightning
简而言之,使用PyTorch Lightning我发现编写、阅读和调试都很容易。这些活动占据了我作为机器学习工程师大部分时间。此外,文档写得很好,包含许多教程,因此学习起来也很容易。
CNN模型回顾
LeNet是学习或复习计算机视觉深度学习架构的良好起点。LeNet是由Yann LeCun等人于1998年设计的第一个成功的卷积神经网络(CNN)架构,用于手写数字识别。
我们首先通过LeNet架构的组件来解释标准CNN模块的主要组成部分。
LeNet由三种类型的层组成:
卷积层
池化层
全连接层
1.卷积层
卷积层负责从输入层中提取特征。在CNN中,这个第一个“层”通常是图像。每个卷积层由一组可学习的滤波器(也称为“核”)组成,它们在输入层上滑动,应用一种称为“卷积”的操作。卷积执行滤波器与图像中的局部区域之间的逐元素乘法和求和。由于在输出特征图上应用了(非线性)激活函数,因此该输出也称为“激活”。在本文中,我们使用最流行的激活函数:ReLU,如下图所示。
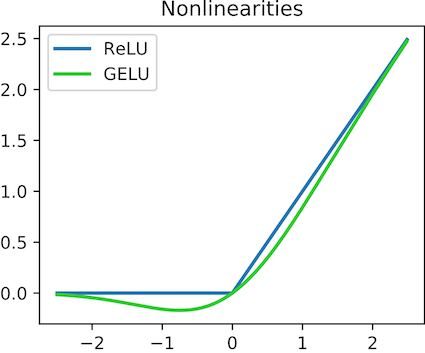
修正线性单元(ReLU)f(x)= max(0,x)及其变种GeLU。图像采用知识共享许可证。 每个卷积层后面主要跟着一个激活函数,以添加非线性。如果没有这样做,模型将像常规线性模型一样行为,而不考虑其深度。
关于卷积层的更多信息
接下来的部分将解释卷积层在CNN中的使用方式以及它们如何使CNN在各种计算机视觉任务中表现出色。简而言之,连续卷积层的分层性质使其非常适用于图像识别任务。单个卷积层效率不高,但是它们的堆叠则非常高效。
第一层使模型能够在输入图像的局部区域中发现简单且通用的模式,然后,更深层次的层能够掌握更复杂和抽象的表示。
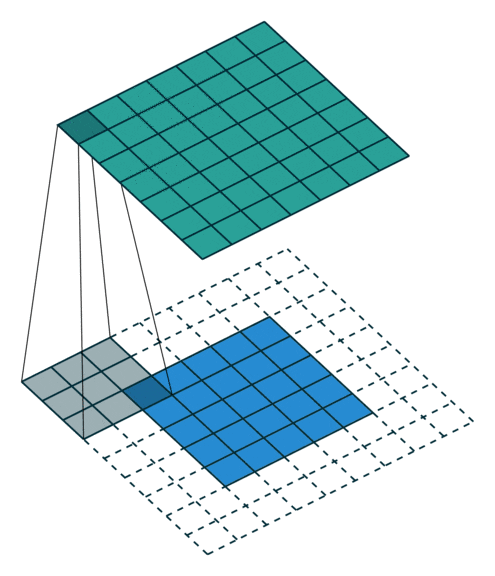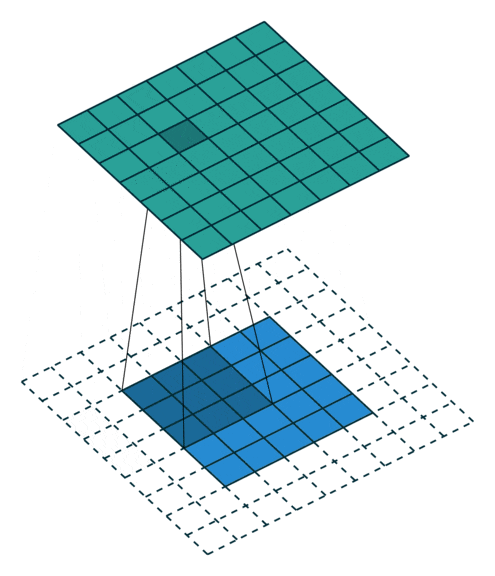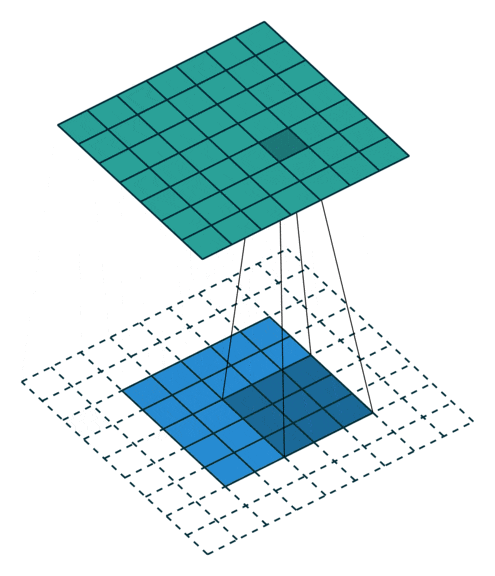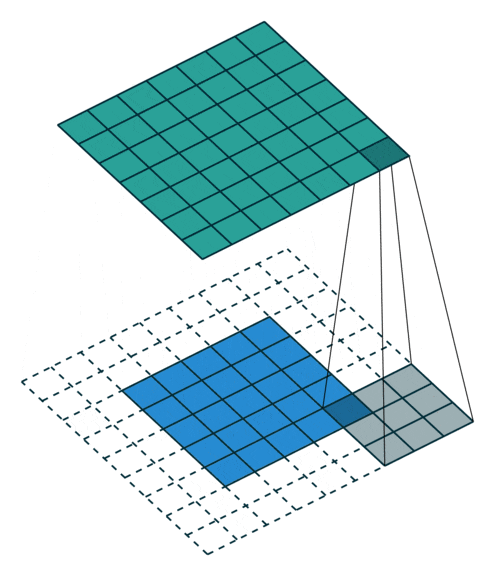
CNN的第一个卷积层通常具有较小的空间范围(例如VGG16的第一个卷积层为3x3像素,LeNet为5x5像素,AlexNet为11x11像素)。
训练后,这些层将检测到类似于经典计算机视觉技术的边缘和角落等简单模式。
然后,中间卷积层中的滤波器变得更复杂。它们相对于输入层的大小更大,因此它们具有更多的上下文(因为它们看到的图像部分比前一个卷积层更广泛),并且它们可以开始检测更高级别的特征,如复杂纹理、形状和对象部分。
例如,在一张日式套餐的图像中,这些层可以检测到筷子、米饭碗和味噌汤。
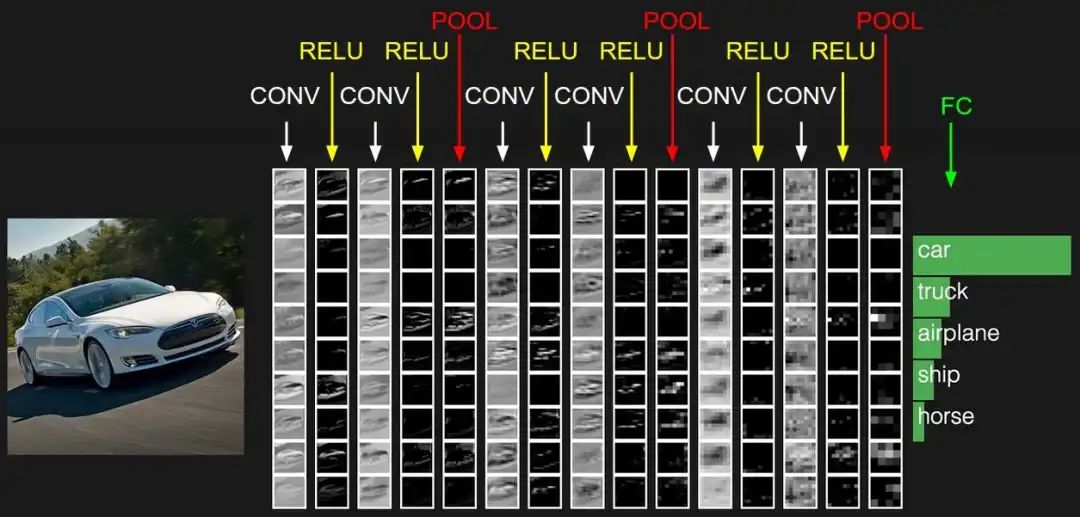
在最后的卷积层中,滤波器的空间范围更大(它们一次可以在输入层中看到更多上下文),并且比前面的边缘、颜色和对象部分的检测层更专业和抽象。它们代表高级特征,并且在图像识别任务中做出准确决策至关重要。它们用于编码复杂的对象表示并捕捉数据集中不同类别的显著特征。
例如,它可以识别日式套餐与法式午餐。
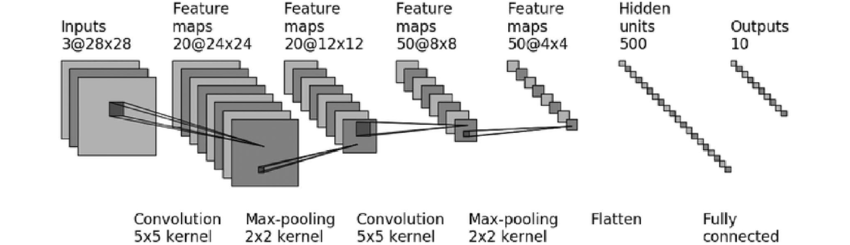
下图总结了每个层可以“看到”的内容。
池化层
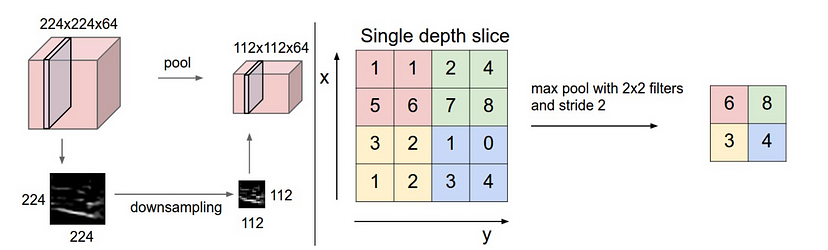
在两个连续的卷积层之间通常会添加一个池化层。池化层会对前一个卷积层得到的特征图进行下采样,降低数据的空间维度,同时保留重要信息。
为什么池化层有效呢?
它们缩小了特征图的大小,因此可以加快计算速度并降低内存需求。
这个信息聚合步骤减少了模型中的参数数量,同时也防止过拟合。
它们引入了一定程度的平移不变性,使得网络可以识别某些特征,即使它们在图像中稍微移动、旋转或变形。对空间变化具有鲁棒性有助于模型更好地泛化。
最常见的池化操作是MAX池化(从窗口覆盖的元素中选择最大值作为该窗口的值)和AVERAGE池化(相同,但取平均值)。
全连接层
全连接(FC)层是模型的最后几层。它们负责基于前面层提取的特征进行高级决策。与卷积滤波器只能局部看到输入层不同,FC层一次连接上一层的所有激活,从前一个输出特征图到下一个输出特征图的激活,就像常规神经网络中所见的那样。它基本上由矩阵乘法和偏置偏移组成。
在LeNet模型中,模型的最后有三个FC层。最后一层是用于分类任务的FC层。其维度为(上一层输出维度,类别数)。
其他经典架构,如AlexNet、VGG、ResNet和Inception,在架构的最后都包括一个FC层。然而,最近的架构取消了这一层,如MobileNet、YOLO、EfficientNet和Vision Transformers。
CNN架构中去除FC层的原因是:
减少参数数量(防止过拟合,特别是在较小的数据集上)。
FC丢弃了特征图中存在的空间信息。
灵活性。没有FC的CNN架构可以处理不同大小的输入,并且避免将输入图像调整为固定大小。
通用的CNN架构
CNN架构最常见的形式是一堆{卷积层+非线性激活函数}层,后跟{池化层},连续应用直到图像被空间缩小到更小的尺寸且通道更多。
最后,通常会有最终的FC层输出类别得分。
总之,CNN的结构如下:
Input -> [[[Conv-> ReLU] * N ] -> Pool?] * M -> [[FC+ReLU] * K] -> FC -> Scores通常为:
0 ≤ N ≤ 3堆叠的卷积。
M≥0的池化块。
0≤ K< 3 FC堆叠层。
模型约束(来源)
通常建议机器学习从业者使用现有的最先进的架构,而不是创建自己的架构。然而,在使用卷积网络时,了解空间约束是很重要的。例如,应用卷积层后,输入层大小(宽度或高度)为W,滤波器大小为F,填充大小为P,步幅大小为S,则输出特征图的大小为Output size = ((W -F + 2P) / S ) +1。对于每个卷积,需要选择参数W、F、P和S,使得输出大小为整数。通常添加填充可以解决大部分问题。
其他常见的约束条件包括:
输入图像应该可以被2整除多次,这取决于模型的深度。这个要求来自池化层。
卷积层应该使用小的滤波器和小的步幅。
建议使用“相同大小”的填充。如果在应用卷积前后保持相同的特征大小,我们就把所有的缩小操作都委托给池化层,架构就变得更容易理解了。
LeNet模型实现
理论已经足够,现在我们将使用PyTorch Lightning实现LetNet CNN。由于其简单性和小型尺寸,选择了LeNet作为示例。
模型实现
在PyTorch中,新模块继承自pytorch.nn.Module。在PyTorch Lighthing中,模型类继承自ligthning.pytorch.LightningModule。
你可以像使用 nn.Module 类一样使用 ligthning.pytorch.LightningModule,只是它包含了更多的功能。
模型的模块接受两个参数:
输入通道的数量(对于灰度图像为 1,对于 RGB 图像为 3)。
分类器中的类别数量(对于 MNIST 数据集为 10)。
在 PyTorch 中,模型分为两部分 init() 和 forward()。init() 声明了每个具有可学习参数的组件作为初始化方法。它还可以包含更多的声明,如激活函数。然后,forward() 方法在输入图像上连续应用所有的层和函数。
LeNet 架构由两个堆叠的卷积块组成,每个后面都跟着一个池化层。然后将结果传递给连续的全连接(FC)层,它们输出一个尺寸为 (batch_size, out_channels) 的张量,其中 out_channels 表示类别数量。
在下面的实现块中,首先初始化了一些杂项属性:
用于在运行 print(model) 时显示每个层之间张量大小模拟的 example_input_array 张量。
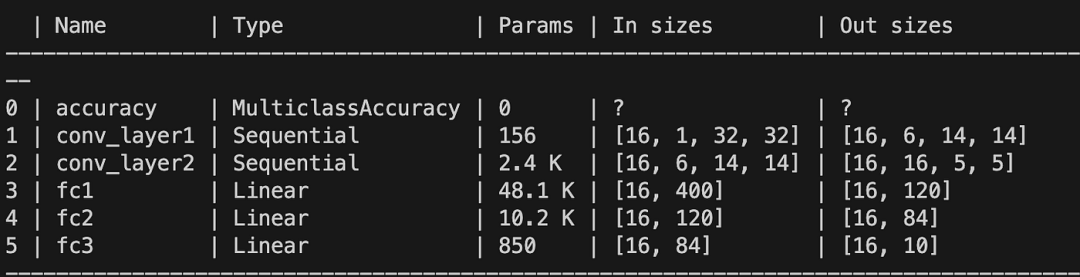
运行 print(model) 时自动记录模型。作者提供的图片。 从上表中,我们可以确认输出张量的大小为 (batch_size=16, num_classes=10)。
训练和验证期间将使用 TheAccuracy() 指标。
具有可学习参数的层也被初始化。首先是两个{卷积 + 最大池化}块,然后是全连接层。
# models/detection/lenet.py
"""
PyTorch reference: https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html
"""
from __future__ import annotations
import lightning.pytorch as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchmetrics
class LeNet(pl.LightningModule):
def __init__(self, in_channels: int, out_channels: int, lr: float = 2e-4):
"""
Args:
- in_channels: One for grayscale input image (which is the case for MNIST), 3 for RGB input image.
- out_channels: Number of classes of the classifier. 10 for MNIST.
"""
super().__init__()
# Debugging tool to display intermediate input/output size of all your layer (called before fit)
self.example_input_array = torch.Tensor(16, in_channels, 32, 32)
self.learning_rate = lr
self.train_accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=out_channels)
self.val_accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=out_channels)
self.test_accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=out_channels)
# [img_size] 32 -> conv -> 32 -> (max_pool) -> 16
# with 6 output activation maps
self.conv_layer1 = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=6,
kernel_size=5,
stride=1,
# Either resize (28x28) MNIST images to (32x32) or pad the imput to be 32x32
# padding=2,
),
nn.MaxPool2d(kernel_size=2),
)
# [img_size] 16 -> (conv) -> 10 -> (max pool) 5
self.conv_layer2 = nn.Sequential(
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# The activation size (number of values after passing through one layer) is getting gradually smaller and smaller.
# The output is flatten and then used as a long input into the next dense layers.
self.fc1 = nn.Linear(in_features=16 * 5 * 5, out_features=120) # 5 from the image dimension
self.fc2 = nn.Linear(in_features=120, out_features=84)
# "Softmax" layer = Linear + Softmax.
self.fc3 = nn.Linear(in_features=84, out_features=out_channels)上述实现的一些注释
有关卷积层的注释
为了简化前向调用,通常将堆叠的层表示为 nn.Sequential() 子模块。
第一个卷积层接收尺寸为 (32x32) 的图像,并在池化层中将尺寸除以 2 后输出尺寸为 (16x16) 的图像。
LeNet 期望输入图像尺寸为 (32x32),但现有的 MNIST 数据集图像尺寸为 (28x28)。你可以将图像调整大小,或者增加第一个卷积层的填充大小(如评论中所述)。否则,在两次下采样之后,最后一个卷积层输出的激活与第一个全连接(FC)层的矩阵乘法(其维度如下所示)之间存在尺寸不匹配:
self.fc1 = nn.Linear(in_features=16 * 5 * 5, out_features=120) # 5 from the image dimension
self.fc2 = nn.Linear(in_features=120, out_features=84)
# "Softmax" layer = Linear + Softmax.
self.fc3 = nn.Linear(in_features=84, out_features=out_channels)第二个卷积层的输入与第一个卷积层的输出滤波器数量相同(为 6)。
ReLU 和 MaxPool 的顺序在这里无关紧要。
与前面部分提到的不同,ReLU 激活函数在池化之前不会被调用。在这个实现中,ReLU 激活函数只在 forward() 调用中被调用。
卷积层应始终跟随一个激活函数以添加非线性。但是,如果卷积层之后也跟随一个池化层,顺序就无关紧要了。两种操作都是可交换的 MaxPool(Relu(x)) = Relu(MaxPool(x))。事实上,我们可以取局部区域的最大值,并将所有负值设置为 0,或者将所有负值设置为 0,并取每个局部区域的最大值。
有关全连接(FC)层的注意事项。
第一个 FC 层接收尺寸为 (number_output_filter_from_conv2 * previous_activation_width * previous_activation_height) 的张量。输出激活的尺寸通过三个 FC 层逐渐减小。
所有这些层都在前向传播中被调用:
# Method of LetNet class in models/detection/lenet.py
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = F.relu(self.conv_layer1(x))
x = F.relu(self.conv_layer2(x))
x = torch.flatten(x, 1) # flatten all dimensions except the batch dimension
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x自动定义了计算梯度的 backward 函数,当使用 autograd 时。
在大多数 PyTorch 实现中,最后一层(有时也称为 softmax 层)输出原始激活值,其中每个数字对应一个分数。这里 softmax 函数在前向传播中未被调用,而是内置在交叉熵损失函数中。
实现训练、验证和测试步骤
在与之前相同的文件中,在类 LeNet(pl.LightningModule) 下覆盖了所有核心函数。
优化器和调度器:configure_optimizers()
def configure_optimizers(self) -> torch.optim.Adam:
return torch.optim.Adam(self.parameters(), lr=self.learning_rate)训练循环:training_step()
验证循环:validation_step()
# Methods in LeNet class in models/detection.lenet.py
###############################
# --- For Pytorch Lightning ---
###############################
def validation_step(
self,
batch: list[torch.Tensor, torch.Tensor],
batch_idx: int,
verbose: bool = True,
) -> torch.Tensor:
"""Function called when using `trainer.validate()` with trainer a
lightning `Trainer` instance."""
x, y = batch
logit_preds = self(x)
loss = F.cross_entropy(logit_preds, y)
self.val_accuracy.update(torch.argmax(logit_preds, dim=1), y)
self.log("val_loss", loss)
self.log("val_acc_step", self.val_accuracy, on_epoch=True)
return loss
def training_step(
self,
batch: list[torch.Tensor, torch.Tensor],
batch_idx: int,
) -> torch.Tensor:
"""Function called when using `trainer.fit()` with trainer a
lightning `Trainer` instance."""
x, y = batch
logit_preds = self(x)
loss = F.cross_entropy(logit_preds, y)
self.train_accuracy.update(torch.argmax(logit_preds, dim=1), y)
self.log("train_acc_step", self.train_accuracy, on_step=True, on_epoch=True, logger=True)
# logs metrics for each training_step,
# and the average across the epoch, to the progress bar and logger
self.log("train_loss", loss, on_step=True, on_epoch=True, logger=True)
return loss正如你可能注意到的那样,上述函数非常简短。无需将变量移到 to(device) ,也不需要使用 optimizer.zero_grad() 删除梯度,也不需要使用 loss.backward() 计算新梯度。模型模式的切换也由 PyTorch Lightning 库自己处理 model.eval() ,model.train() 。
你可以注意到这里调用了 log() 方法。该方法在适当时保存和显示结果。
如果要自定义它,文档很好地解释了如何正确使用日志记录:
log() 方法有几个选项:
on_step(在训练中的那一步记录指标)
n_epoch(在epoch结束时自动累积并记录)
prog_bar(进度条)
logger(日志)
根据 log() 的调用位置不同,Lightning 会自动确定正确的模式。当然,你也可以通过手动设置标志来覆盖默认行为。
PyTorch Lightning 的另一个好功能是验证健全性检查:
你可能注意到了记录的“验证健全性检查”一词。这是因为 Lightning 在开始训练之前运行了 2 个批次的验证。这是一种单元测试,用于确保如果在验证循环中有 bug,你不需要等待一个完整的 epoch 才能发现。
最后,测试和预测的方法也是在同一个类下实现的:
测试循环:test_step()
预测循环:predict_step()
模型可以从检查点加载权重,或者如果在训练循环之后调用,则模型会自动获取最后一轮或最佳(如果已实现回调)时期的权重。
def test_step(
self,
batch: list[torch.Tensor, torch.Tensor],
batch_idx: int,
):
"""Function called when using `trainer.test()` with trainer a
lightning `Trainer` instance."""
x, y = batch
logit_preds = self(x)
loss = F.cross_entropy(logit_preds, y)
self.test_accuracy.update(torch.argmax(logit_preds, dim=1), y)
self.log_dict({"test_loss": loss, "test_acc": self.test_accuracy})
def predict_step(
self, batch: list[torch.Tensor, torch.Tensor], batch_idx: int
) -> tuple[torch.Tensor, torch.Tensor]:
"""Function called when using `trainer.predict()` with trainer a
lightning `Trainer` instance."""
x, _ = batch
logit_preds = self(x)
softmax_preds = F.softmax(logit_preds, dim=1)
return x, softmax_preds管理 MNIST 数据集
你可以使用常规的 PyTorch DataLoader 类或 PyTorch Lightning DataModule。在本文中,我使用 PyTorch Lightning DataModule 实现了数据集和数据加载。它旨在将所有相对于一个数据集的信息集中在一个单一文件中。它包括数据下载、数据拆分、数据加载等功能。
在本教程中,我们使用大小为 28x28 的图像组成的 MNIST。

这里是管理 MNIST 数据集的数据模块的实现。它包括设置标准参数:
数据目录的路径
批处理大小
张量转换
以及下载和处理功能在 prepare_data() 和 setup() 中。
# datasets/mnist.py
"""
More at https://lightning.ai/docs/pytorch/stable/data/datamodule.html
"""
import logging
from pathlib import Path
import lightning.pytorch as pl
from torch.utils.data import DataLoader, random_split
from torchvision import transforms
from torchvision.datasets import MNIST
# Create a logger
logger = logging.getLogger(Path(__file__).stem)
logger.setLevel(logging.INFO)
_DEFAULT_MNIST_BATCH_SIZE = 32
_DEFAULT_RESIZE_SIZE = 32
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str, batch_size: int = _DEFAULT_MNIST_BATCH_SIZE):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Resize((_DEFAULT_RESIZE_SIZE, _DEFAULT_RESIZE_SIZE)),
transforms.Normalize((0.1307,), (0.3081,)),
]
)
def prepare_data(self):
"""Ensure we download using one process only on CPU and avoid data corruption when downloading the data.
It's recommended to avoid creating class attributes `self.*` because the state won't be available for
other processes.
"""
MNIST(self.data_dir, train=True, download=True, transform=self.transform)
MNIST(self.data_dir, train=False, download=True, transform=self.transform)
def setup(self, stage: str):
"""Is called from every process across all nodes.
It also uses every GPUs to perform data processing and state assignement.
`teardown` is its counterpart used to clean the states.
"""
logger.info(f"Stage: {stage}")
if stage == "test" or stage == "predict":
self.mnist_test = MNIST(self.data_dir, train=False, download=True, transform=self.transform)
elif stage == "fit" or stage == "validate":
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])开始训练时,按照以下顺序调用这些函数:
DataModule 的 prepare_data() 和 setup() 方法。prepare_data() 方法在一个 CPU 上运行,用于在本地下载数据。而 setup() 方法是一个并行进程,可以运行数据处理作业。这些方法在每次调用训练器的方法时都会被调用,比如 trainer.fit()、trainer.validate() 等等。
pl.LightningModule configure_optimizers() 初始化优化器。
然后,在同一个类 MNISTDataModule 中,我们实现了不同的数据加载器:
def train_dataloader(self) -> DataLoader:
"""Called by Trainer `.fit` method"""
return DataLoader(self.mnist_train, batch_size=self.batch_size)
def val_dataloader(self) -> DataLoader:
"""Called by Trainer `validate()` and `validate()` method."""
return DataLoader(self.mnist_val, batch_size=self.batch_size)
def test_dataloader(self) -> DataLoader:
"""Called by Trainer `test()` method."""
return DataLoader(self.mnist_test, batch_size=self.batch_size)
def predict_dataloader(self) -> DataLoader:
"""Called by Trainer `predict()` method. Use the same data as the test_dataloader."""
return DataLoader(self.mnist_test, batch_size=self.batch_size, num_workers=3)DataModule 的 train_dataloader() 检索训练 DataLoader。
pl.LightningModule training_step() 在从训练 DataLoader 获得的小批量上运行前向传播和反向传播。该方法重复调用,直到训练 DataLoader 中的所有样本都被看到一次。
pl.LightningModule validation_step() 计算验证数据集上的损失和指标。
当达到最大 epoch 数或验证损失停止下降(提前停止)时,训练停止。
实现训练循环
最后,唯一缺失的部分是训练脚本本身。
训练脚本包括:
解析 CLI 参数并调用主函数
if __name__ == "__main__":
parser = ArgumentParser(description=__doc__)
parser.add_argument("--model", default="lenet", type=str, help="Provide an implemented model.")
parser.add_argument("--device", default=0, type=int, help="Select a CUDA device.")
parser.add_argument("--max-epoch", default=10, type=int, help="Max number of epochs.")
parser.add_argument("--out-dir", type=Path, help="Path to output directory")
parser.add_argument(
"--early-stopping", action="store_true", help="If True, stops the training if validation loss stops decreasing."
)
args = parser.parse_args()
main(
model_choice=args.model,
device=args.device,
max_epoch=args.max_epoch,
out_dir=args.out_dir,
early_stopping=args.early_stopping,
)主函数包括模型选择、早停回调的创建,以及对训练器的调用:trainer.fit(model, datamodule=data_module)、验证 trainer.validate(datamodule=data_module)、测试 trainer.test(datamodule=data_module) 和预测 output_preds = trainer.predict(datamodule=data_module, ckpt_path=”best”)。
def main(
model_choice: str,
device: int,
max_epoch: int,
out_dir: Path | None,
early_stopping: bool | None,
):
accelerator = "gpu" if torch.cuda.is_available() else "cpu"
if out_dir is None:
out_dir = Path(__file__).parent / "output"
out_dir.mkdir(parents=True, exist_ok=True)
# Select architecture
if model_choice == "lenet":
model = LeNet(in_channels=1, out_channels=10)
data_module = MNISTDataModule(data_dir=_PATH_DATASETS, batch_size=_BATCH_SIZE)
else:
raise NotImplementedError(f"{model_choice} is not implemented!")
callbacks = (
[
EarlyStopping(
monitor="val_loss",
min_delta=0.00,
patience=_EARLY_STOPPING_PATIENCE,
verbose=True,
mode="min",
)
]
if early_stopping
else []
)
# If your machine has GPUs, it will use the GPU Accelerator for training.
trainer = L.Trainer(
accelerator=accelerator,
devices=[device],
strategy="auto",
max_epochs=max_epoch,
callbacks=callbacks,
default_root_dir=out_dir,
)
# Train the model ⚡
# data_module.setup(stage="fit") # Is called by trainer.fit().
# Call training_step + validation_step for all the epochs.
trainer.fit(model, datamodule=data_module)
# Validate
trainer.validate(datamodule=data_module)
# Automatically auto-loads the best weights from the previous run.
# data_module.setup(stage="test") # Is called by trainer.test().
# The checkpoint path is logged on the terminal.
trainer.test(datamodule=data_module)
# Run the prediction on the test set and save a subset of the resulting prediction along with the
# original image.
output_preds = trainer.predict(datamodule=data_module, ckpt_path="best")
img_tensors, softmax_preds = zip(*output_preds)
out_dir_imgs = out_dir / "test_images"
out_dir_imgs.mkdir(exist_ok=True, parents=True)
save_results(
img_tensors=img_tensors,
output_tensors=softmax_preds,
out_dir=out_dir_imgs,
)保存预测图像的函数(主要用于调试)。
def save_results(
img_tensors: list[torch.Tensor], output_tensors: list[torch.Tensor], out_dir: Path, max_number_of_imgs: int = 10
):
"""Save test results as images in the provided output directory.
Args:
img_tensors: List of the tensors containing the input images.
output_tensors: List of softmax activation from the trained model.
out_dir: Path to output directory.
max_number_of_imgs: Maximum number of images to output from the provided images. The images will be selected randomly.
"""
selected_img_indices = random.sample(range(len(img_tensors)), min(max_number_of_imgs, len(img_tensors)))
for img_indice in selected_img_indices:
# Take the first instance of the batch (index 0)
img_filepath = out_dir / f"{img_indice}_predicted_{torch.argmax(output_tensors[img_indice], dim=1)[0]}.png"
torchvision.utils.save_image(img_tensors[img_indice][0], fp=img_filepath)加上导入和常量声明,脚本如下所示:
# Train.py script
#!/usr/bin/python3
"""Example training script to fit a model on MNIST dataset."""
from __future__ import annotations # Enable PEP 563 for Python 3.7
from argparse import ArgumentParser
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
from pathlib import Path
import lightning as L
import os
import random
import torch
import torchvision
from datasets.mnist import MNISTDataModule
from models import AlexNet, LeNet
_PATH_DATASETS = os.environ.get("PATH_DATASETS", ".")
_BATCH_SIZE = 64 if torch.cuda.is_available() else 32
_EARLY_STOPPING_PATIENCE = 4 # epochs
def save_results(
img_tensors: list[torch.Tensor], output_tensors: list[torch.Tensor], out_dir: Path, max_number_of_imgs: int = 10
):
"""Save test results as images in the provided output directory.
Args:
img_tensors: List of the tensors containing the input images.
output_tensors: List of softmax activation from the trained model.
out_dir: Path to output directory.
max_number_of_imgs: Maximum number of images to output from the provided images. The images will be selected randomly.
"""
selected_img_indices = random.sample(range(len(img_tensors)), min(max_number_of_imgs, len(img_tensors)))
for img_indice in selected_img_indices:
# Take the first instance of the batch (index 0)
img_filepath = out_dir / f"{img_indice}_predicted_{torch.argmax(output_tensors[img_indice], dim=1)[0]}.png"
torchvision.utils.save_image(img_tensors[img_indice][0], fp=img_filepath)
def main(
model_choice: str,
device: int,
max_epoch: int,
out_dir: Path | None,
early_stopping: bool | None,
):
accelerator = "gpu" if torch.cuda.is_available() else "cpu"
if out_dir is None:
out_dir = Path(__file__).parent / "output"
out_dir.mkdir(parents=True, exist_ok=True)
# Select architecture
if model_choice == "lenet":
model = LeNet(in_channels=1, out_channels=10)
data_module = MNISTDataModule(data_dir=_PATH_DATASETS, batch_size=_BATCH_SIZE)
else:
raise NotImplementedError(f"{model_choice} is not implemented!")
callbacks = (
[
EarlyStopping(
monitor="val_loss",
min_delta=0.00,
patience=_EARLY_STOPPING_PATIENCE,
verbose=True,
mode="min",
)
]
if early_stopping
else []
)
# If your machine has GPUs, it will use the GPU Accelerator for training.
trainer = L.Trainer(
accelerator=accelerator,
devices=[device],
strategy="auto",
max_epochs=max_epoch,
callbacks=callbacks,
default_root_dir=out_dir,
)
# Train the model ⚡
# data_module.setup(stage="fit") # Is called by trainer.fit().
# Call training_step + validation_step for all the epochs.
trainer.fit(model, datamodule=data_module)
# Validate
trainer.validate(datamodule=data_module)
# Automatically auto-loads the best weights from the previous run.
# data_module.setup(stage="test") # Is called by trainer.test().
# The checkpoint path is logged on the terminal.
trainer.test(datamodule=data_module)
# Run the prediction on the test set and save a subset of the resulting prediction along with the
# original image.
output_preds = trainer.predict(datamodule=data_module, ckpt_path="best")
img_tensors, softmax_preds = zip(*output_preds)
out_dir_imgs = out_dir / "test_images"
out_dir_imgs.mkdir(exist_ok=True, parents=True)
save_results(
img_tensors=img_tensors,
output_tensors=softmax_preds,
out_dir=out_dir_imgs,
)
if __name__ == "__main__":
parser = ArgumentParser(description=__doc__)
parser.add_argument("--model", default="lenet", type=str, help="Provide an implemented model.")
parser.add_argument("--device", default=0, type=int, help="Select a CUDA device.")
parser.add_argument("--max-epoch", default=10, type=int, help="Max number of epochs.")
parser.add_argument("--out-dir", type=Path, help="Path to output directory")
parser.add_argument(
"--early-stopping", action="store_true", help="If True, stops the training if validation loss stops decreasing."
)
args = parser.parse_args()
main(
model_choice=args.model,
device=args.device,
max_epoch=args.max_epoch,
out_dir=args.out_dir,
early_stopping=args.early_stopping,
)结果
在我的配备了 NVIDIA GeForce RTX 3070 GPU 的计算机上,运行 python -m train --early-stopping 进行 10 轮训练(批量大小为 64)不到两分钟。
当训练达到默认的最大 epoch 数(10)时,PyTorch Lightning 分别在验证集和测试集上输出损失和准确率的结果:
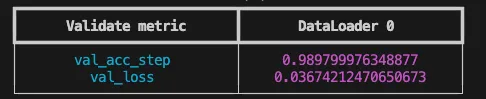

10 轮训练后模型在未见数据上的结果。 经过训练的模型在未见数据上获得了近 99% 的准确率。
脚本还保存了来自测试集的 10 张图像以及预测的类别:

结论
在本文中,我们发现了 PyTorch Lightning 的魔力,然后复习了 CNN 的关键技术概念,并从头开始演示了一个简单 CNN 结构的完整实现训练循环。
希望这篇入门级文章能够帮助你快速可靠地实现基本架构,并帮助你在学习过程中建立更坚实的基础。你可以查看我的公共深度学习仓库获取更多内容 https://github.com/bledem/deep-learning。
参考资料
斯坦福计算机视觉课程
Andrew NG https://www.youtube.com/watch?v=c1RBQzKsDCk&list=PLpFsSf5Dm-pd5d3rjNtIXUHT-v7bdaEIe&index=115&ab_channel=DeepLearningAI
PyTorch Lightning 文档 https://www.pytorchlightning.ai/tutorials
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
