javascript和python这类动态语言是没有泛型机制的。
java和C#是静态编译型语言,传递参数的时候要求参数的类型必须是明确的。
泛型主要解决的问题:
1.参数不安全
2.重复编码
本次的示例通过实现一个栈(数据后进先出 push() pop()) (队列是先进先出)来讲述使用泛型的优势及相关用法
基础写法
新建一个StackInt类
package com.lin.why;
public class StackInt {
private int maxSize;
private int[] items;
private int top;
public StackInt(int maxSize){
this.maxSize = maxSize;
this.items = new int[maxSize];
this.top = -1;
}
public boolean isFull(){
return this.top == this.maxSize-1;
}
public boolean isNull(){
return this.top <= -1;
}
public boolean push(int value){
if(this.isFull()){
return false;
}
this.items[++this.top] = value;
return true;
}
public int pop(){
if(this.isNull()){
throw new RuntimeException("当前栈中无数据");
}
int value = this.items[top];
--top;
return value;
}
}
Main方法调用
public class Main {
public static void main(String[] args) {
// 栈 push pop
//这段代码的问题 太具体了不够抽象
StackInt stackInt = new StackInt(3);
System.out.println(stackInt.isFull());
System.out.println(stackInt.isNull());
stackInt.push(7);
stackInt.push(8);
int value = stackInt.pop();
System.out.println(value);
int value1 = stackInt.pop();
System.out.println(value1);
}
}
这种写法的缺点
这段代码存在的问题是太具体了,不够抽象。StackInt定义只能push进int,那么想push一个字符串就不行。这就是动态语言和静态语言最大的区别。java,C#这类静态语言这样强制参数类型,可以让我们写出更加安全的代码,动态语言写起来虽然简单但是非常难以维护。
用Object处理
package com.lin.why;
public class StackObject {
private int maxSize;
private Object[] items;
private int top;
public StackObject(int maxSize){
this.maxSize = maxSize;
this.items = new Object[maxSize];
this.top = -1;
}
public boolean isFull(){
return this.top == this.maxSize-1;
}
public boolean isNull(){
return this.top <= -1;
}
public boolean push(Object value){
if(this.isFull()){
return false;
}
this.items[++this.top] = value;
return true;
}
public Object pop(){
if(this.isNull()){
throw new RuntimeException("当前栈中无数据");
}
Object value = this.items[top];
--top;
return value;
}
}
main调用
public class Main {
public static void main(String[] args) {
// 栈 push pop
//这段代码的问题 太具体了不够抽象
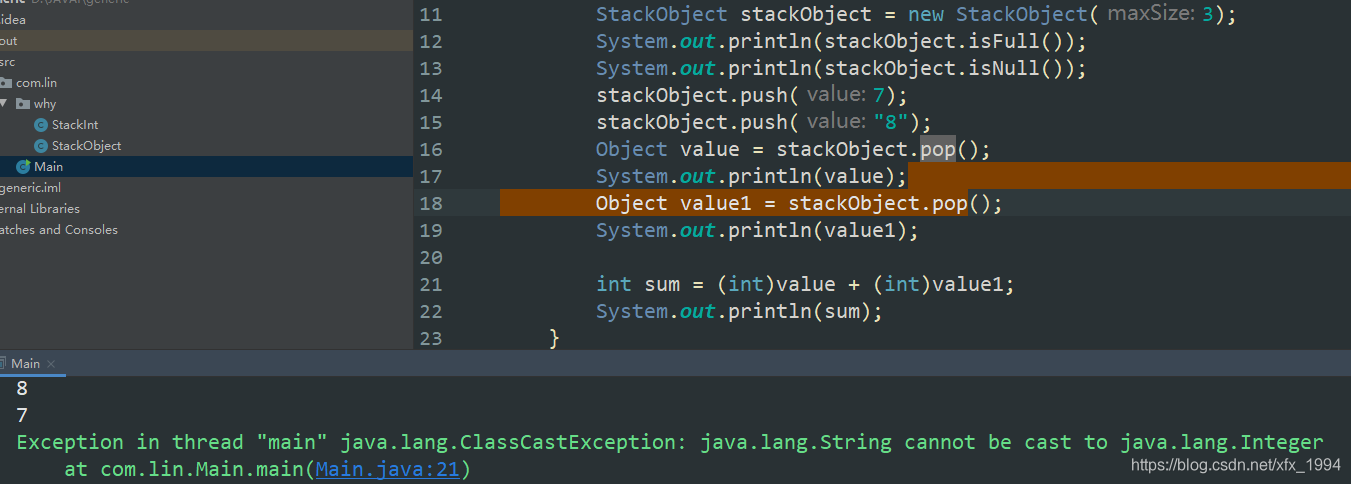
StackObject stackObject = new StackObject(3);
System.out.println(stackObject.isFull());
System.out.println(stackObject.isNull());
stackObject.push(7);
stackObject.push(8);
Object value = stackObject.pop();
System.out.println(value);
Object value1 = stackObject.pop();
System.out.println(value1);
}
}
用Object改写完的是变得比较抽象了,不像StackInt那么具体了,可以push进各种类型的数据。
用Object表示的缺点
1.用Object表示的对象是非常抽象的,失去了类型的特点。 在做具体运算的时候可能会需要频繁拆箱和装箱,性能较低。Object表示的数据类型过于模糊,没有具体数据类型的意义了。
int sum = (int)value + (int)value1;
2.Object是一种不安全的数据结构
当push进字符串“8”时程序编译的时候不会报错,但是在运行的时候会抛出异常。java的优势就在于可以在编译的阶段就尽可能找到代码里潜在的错误,如果我们的一些做法不能让程序在编译阶段就发现这些错误,就会把错误留到运行阶段,java就失去了它的优势。如果把错误留到运行阶段发现和解决,解决成本会远远高于在编译阶段发现这个错误。
用泛型处理
泛型 简单来说就是一种类型的约定。
解决使用Object时需要频繁拆箱装箱和类型不安全的问题。
泛型类定义是在类后边加<> 相当于类型的约定,如
定义泛型类
StackT<T>
T现在是不确定具体是什么类型的,什么类型是调用方在实例化时指定的,T可以代表我们要存储数据的类型。
实例化时需要指定泛型类型。泛型不能传入基本类型,需要传入包装类型。
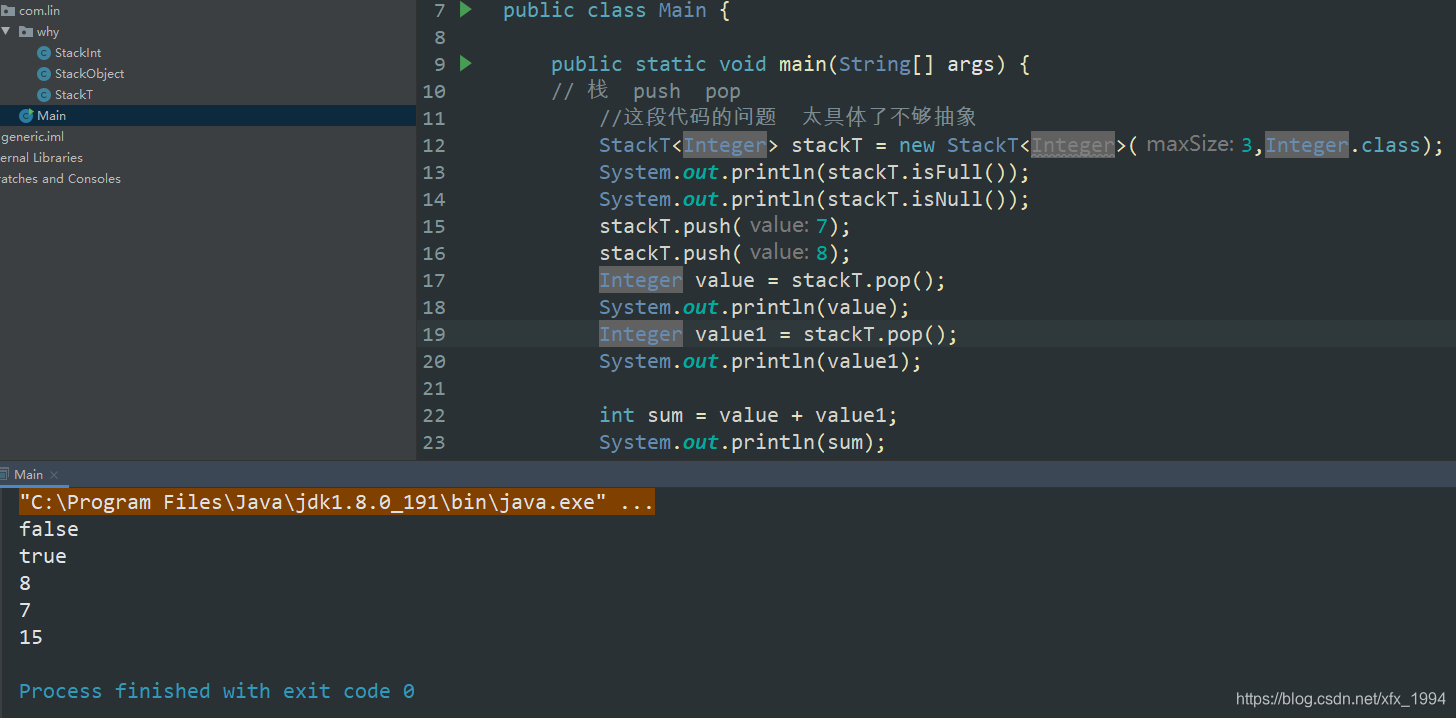
StackT stackT = new StackT<Integer>(3);
java不能在类内部获取到泛型的类型,对于java泛型来说当编译阶段过后泛型T已经被擦除了,在运行阶段已经丢失了T这个类型的具体信息。而去实例化一个对象的时候,比如T c = new T();发生时机是在运行时,在运行阶段想new T()就必须知道T的具体类型和相关信息,但是泛型会被擦除掉。简单来说,当StackT被编译了之后T已经被替换成了现在的Integer,所以再去new T() ,JVM是不认识这个T的。
解决上面不能直接new来实例化T的问题
通过类的原类Class
public StackT(int maxSize,Class<T> clazz){
this.maxSize = maxSize;
this.items = this.createArray(clazz);
this.top = -1;
}
//创建数组
private T[] createArray(Class<T> clazz){
T[] array = (T[]) Array.newInstance(clazz, this.maxSize);
return array;
}
调用
StackT<Integer> stackT = new StackT<Integer>(3,Integer.class);
使用泛型的好处
1.如果push的类型不对编译时就会报错
2.不需要频繁拆箱和装箱
3.泛型具备通用性
既保证了数据安全又可以只用一个StackT应用于各种各样的数据类型。
通过前面演进的示例,StackInt——>StackObject——>StackT这样重构的方式理解泛型的优势。


泛型不仅可以只有一个泛型类型还可以有多个
public class StackT<T,E,K> {
泛型方法
在方法名后面加泛型参数,可以返回void也可以返回泛型类型的实例
public <E> void test(){}
public <E> E test(Class<E> clazz) throws IllegalAccessException, InstantiationException {
return clazz.newInstance();
}
如果只是在参数列表中带有泛型并不是泛型方法
//不是泛型方法
public void test(ArrayList<String> s){}
泛型方法没有泛型类使用场景多
泛型通配符
通配符通常是用于泛型类在被当做参数传递到其他方法或构造函数时的类型限定的。(不是泛型类的定义)
当方法需要接受StackT这样一个泛型的类,参数列表如果写成(StackT stackT)运行是没有问题的,但是失去了泛型的限定。此时stackT.pop()出来的对象又变成了Object这种模糊的类型。
上面的示例改写
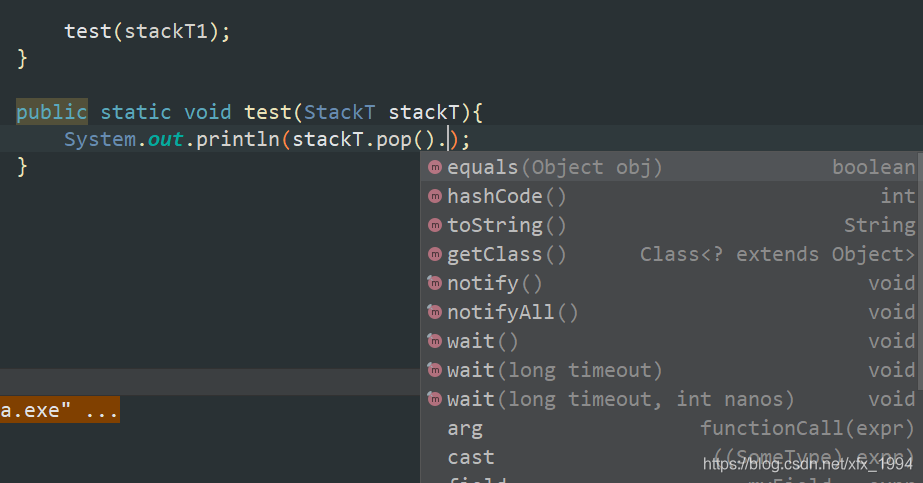
test(stackT1);
public static void test(StackT stackT){
System.out.println(stackT.pop());
}
参数列表如果写成(StackT<String> stackT) 此时pop()出来的元素是被String约束的。此时test()传入StackT就会报错
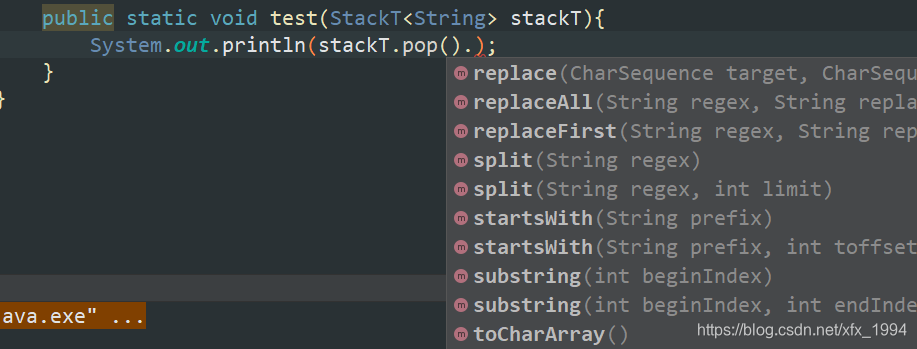
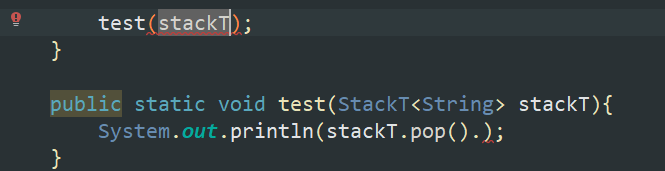
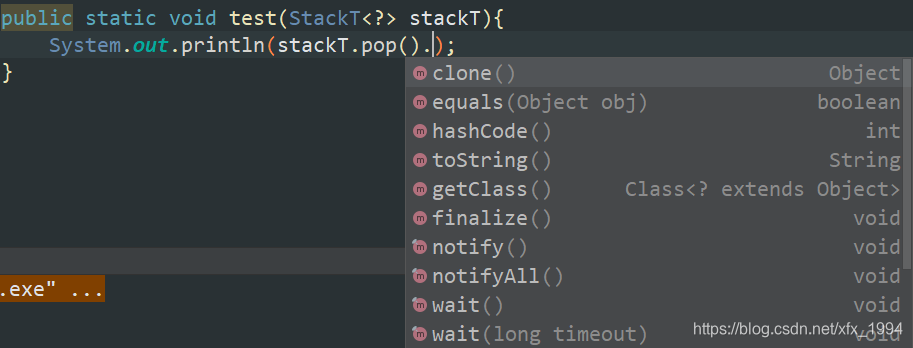
无界通配符(StackT<?> stackT)
这样使用泛型通配符也还是失去了类型的特点。
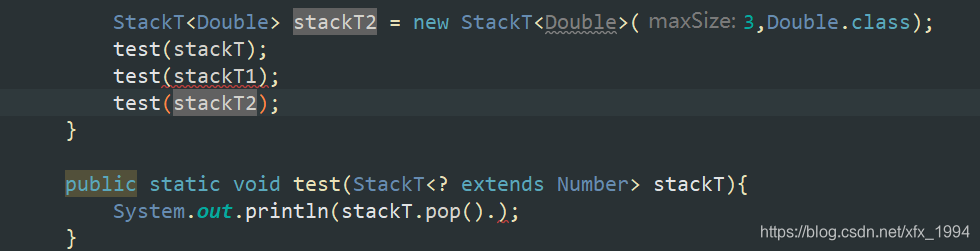
上边界通配符(StackT<? extends Number> stackT)
Number是Integer,Float,Double这些数值类型的父类,当想接收泛型类的时候接收StackT的类型可以是一切Number的子类,不可以接收Number的父类就要用到上边界通配符。
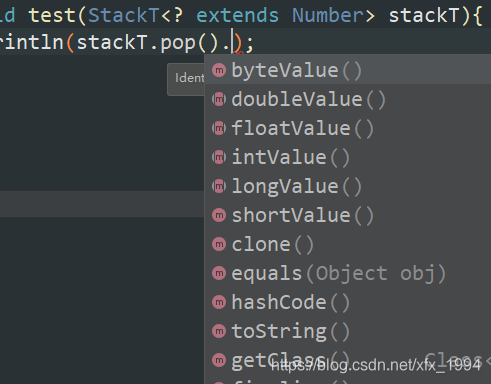
public static void test(StackT<? extends Number> stackT){
System.out.println(stackT.pop().);
}
此时pop()出来的元素是Number类型的
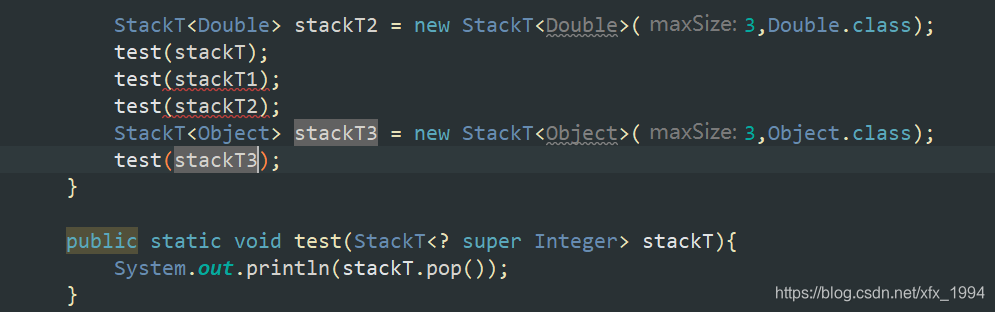
下边界通配符(StackT<? super Integer> stackT)
当想接收泛型类StackT的类型是Integer的父类时就要用到下边界通配符
总结
当我们在写一些框架的时候不知道使用者的使用场景,这时候泛型的高级语法就非常有用了。泛型既保证了数据安全又可以只用一个StackT 应用于各种各样的数据类型。