文章目录
并发和并行的概念
- 并发指的是在一段时间内同时处理多个任务或者事件,但这些任务或事件不一定同时开始或结束。在计算机系统中,可以使用多线程或多进程的方式实现并发。
- 并行则指的是同时执行多个任务或事件,这些任务或事件同时开始并在一段时间内同时结束。在计算机系统中,可以使用多核处理器或者分布式计算系统来实现并行。
- 简而言之,可以将并发看作多个任务在同一时间段内进行,而并行则指的是同一时间段内多个任务同时执行。并行是在硬件层面上实现的,而并发则是在软件层面上实现的。
- 需要注意的是,并发和并行是不同的概念,但有时会混淆使用。在某些情况下,可以同时实现并发和并行,例如在一个具有多个处理器的系统中运行多个进程。
多线程的使用场景
- I/O密集型应用:这种应用通常需要大量的输入输出操作,如读取文件、网络通信等。在这种情况下,多线程可以在等待I/O操作完成时执行其他任务,从而提高程序的效率。例如,在一个Web服务器中,可以使用多线程来处理多个客户端的请求。
- CPU密集型应用:这种应用需要大量的计算操作,如图像处理、数据分析等。在这种情况下,多线程可以在一个处理器上并行执行多个任务,从而提高程序的性能。例如,在一个数据分析应用中,可以使用多线程来同时处理多个数据集。
需要注意的是,多线程并不总是适合所有的应用场景。在一些情况下,多线程可能会导致资源竞争、死锁等问题,从而降低程序的性能和稳定性。因此,在使用多线程时,需要仔细评估应用的特点和需求,选择合适的线程模型和策略,确保程序的正确性和性能
线程池设计
线程数量并不是越多越好
在多线程编程中,线程数量的设置并不是越多越好。以下是一些需要考虑的问题:
- 线程的创建和销毁都是很"重"的操作。创建线程时需要从用户态切换到内核态,然后为每个线程初始化PCB(task_struct)用来控制线程的内核栈。销毁线程时,系统内核要回收PCB,因此创建和销毁线程的开销都比较大。为了避免频繁的创建和销毁线程,可以使用线程池来管理线程的生命周期,从而减少开销。
- 线程栈本身占用大量内存。在Linux下,每个线程都有自己的栈空间,默认情况下线程栈大小为8MB,而所有线程共享进程的地址空间。因此,如果创建了大量的线程,还没有做具体的任务,栈空间几乎会被占满,从而影响程序的执行。
- 线程的上下文切换需要占用大量时间。在线程调度过程中,需要进行上下文切换,这也会消耗一定的CPU时间。如果线程数量过多,上下文切换花费的CPU时间也会特别多,从而使得CPU分配给真正的业务执行时间变得更少。
- 大量线程同时唤醒,会使系统经常出现锯齿状负载或者瞬间负载量很大导致宕机等问题。这是因为多个线程同时竞争CPU资源,导致CPU负载不均衡。因此,在设置线程数量时需要避免过多的线程同时竞争CPU资源,从而保持系统的稳定性和可靠性。
一般情况下,可以按照当前CPU核心数量来确定线程数量。同时,使用多线程+IO复用的方式,可以有效提高程序的效率和响应速度。需要根据具体的应用场景和硬件条件来确定最优的线程数量,以达到最佳的性能和效率
为什么需要线程池
- 频繁地创建和销毁线程会给系统带来较大的开销,会降低系统的性能表现,影响业务的处理能力。因此,一种更加高效的方式是使用线程池。线程池在服务进程启动时,就预先创建好了一定数量的线程。当有业务流量到来时,线程池会从池中获取一个空闲线程,然后将业务任务分配给它来执行。任务执行完毕后,线程并不会被销毁,而是会归还给线程池,等待下一个任务的到来。
- 使用线程池的好处是显而易见的。首先,由于线程已经预先创建好了,因此,避免了频繁地创建和销毁线程所带来的开销,提高了系统的性能。其次,线程池能够合理地利用系统资源,避免了线程数量过多导致的系统崩溃,同时也避免了线程数量过少无法满足业务需求的问题。最后,线程池能够有效地控制线程的数量,避免了过多的线程竞争造成的上下文切换开销,提高了系统的整体性能表现。
- 总之,线程池是一种非常高效、可靠的线程管理方式。通过提前创建线程、复用线程以及对线程进行管理,线程池能够帮助系统充分利用系统资源,提高业务的处理效率,保证系统的稳定性和可靠性。
fixed模式和cached模式
- fixed模式线程池一般在应用程序启动时创建,其中线程的数量固定不变,一般是根据当前CPU核心数量指定。这种线程池的优点在于可以保证线程的数量不会无限增长,从而避免线程过多带来的上下文切换开销和内存占用过高的问题。然而,由于线程数量是固定的,当任务队列中的任务数量超过线程数量时,线程池将无法处理所有的任务,从而导致性能下降。
- cached模式线程池相对于fixed模式线程池更加灵活。线程池中线程的数量可以根据任务的数量动态增长,当任务数量增加时,线程池会自动创建新的线程来处理任务。而当任务数量减少时,线程池会自动关闭部分线程,从而避免线程数量过多导致的资源浪费。这种线程池的一个优点是可以根据实际情况调整线程数量,从而保证任务能够得到快速的处理。然而,由于线程的动态增长和销毁需要进行大量的线程创建和销毁操作,因此可能会带来一定的开销。另外,需要设置一个线程数量的阈值,任务处理完成后,如果动态增长的线程空闲了一定时间(如10秒)还没有处理其他任务,那么就会关闭线程,保持线程池中的初始数量即可。
线程同步
线程同步是指协调不同线程之间的执行,保证线程之间的数据同步和有序执行。线程同步常常使用线程互斥和信号量机制来实现。
线程互斥
线程互斥是一种保护共享资源的方式,防止多个线程同时对共享资源进行访问和修改,导致数据不一致的情况。互斥量(mutex)是一种常用的线程同步机制,可以用于保证对共享资源的互斥访问。当一个线程获取到互斥锁时,其他线程无法访问该资源,直到该线程释放互斥锁。
另外,为了避免手动管理互斥锁资源而出现问题,可以使用C++11中提供的lock_guard来自动管理互斥量资源,保证在临界区代码内抛出异常时,mutex能够被正确释放。
原子类型是一种保证原子操作的数据类型。atomic原子类型基于CAS(Compare-and-Swap)算法实现,使用总线锁保证某些简单操作(如++,–)的原子性,不会改变线程的状态。相比于mutex,atomic原子类型更加轻量,对于简单的计数操作,使用atomic原子类型比mutex更加高效。
竞态条件是多个线程同时执行的代码段,在不同的执行顺序下可能会产生不同的结果。为了避免竞态条件,需要保证这段代码是原子的,可以使用线程互斥的方法,保证对共享资源的访问是互斥的。如果代码段是可重入的,即在多线程环境下不会出现竞态条件,多个线程可以同时执行。如果代码段不是可重入的,即在多线程环境下存在竞态条件,不允许多个线程同时执行。
线程通信
线程通信是指在多线程编程中,不同线程之间的交互。常见的线程通信方式包括条件变量(condition_variable)和信号量(semaphore)。
- 条件变量可以用来阻塞一个或多个线程,直到某个线程满足特定条件并通知其他线程为止。在使用条件变量时,需要先获得一个unique_lock,然后调用wait方法释放锁并进入等待状态,等待条件变量满足后再次获取锁并执行后续操作。
- 信号量则可以看做资源计数器,允许多个线程同时访问共享资源,但在资源计数为0时,需要等待其他线程释放资源后才能继续执行。C++20中引入了信号量semaphore来支持多线程编程。与互斥锁相比,信号量更加灵活,允许不同线程在不同的时刻获取和释放信号量,因此可以用来进行更加复杂的同步和互斥操作。
线程池设计图
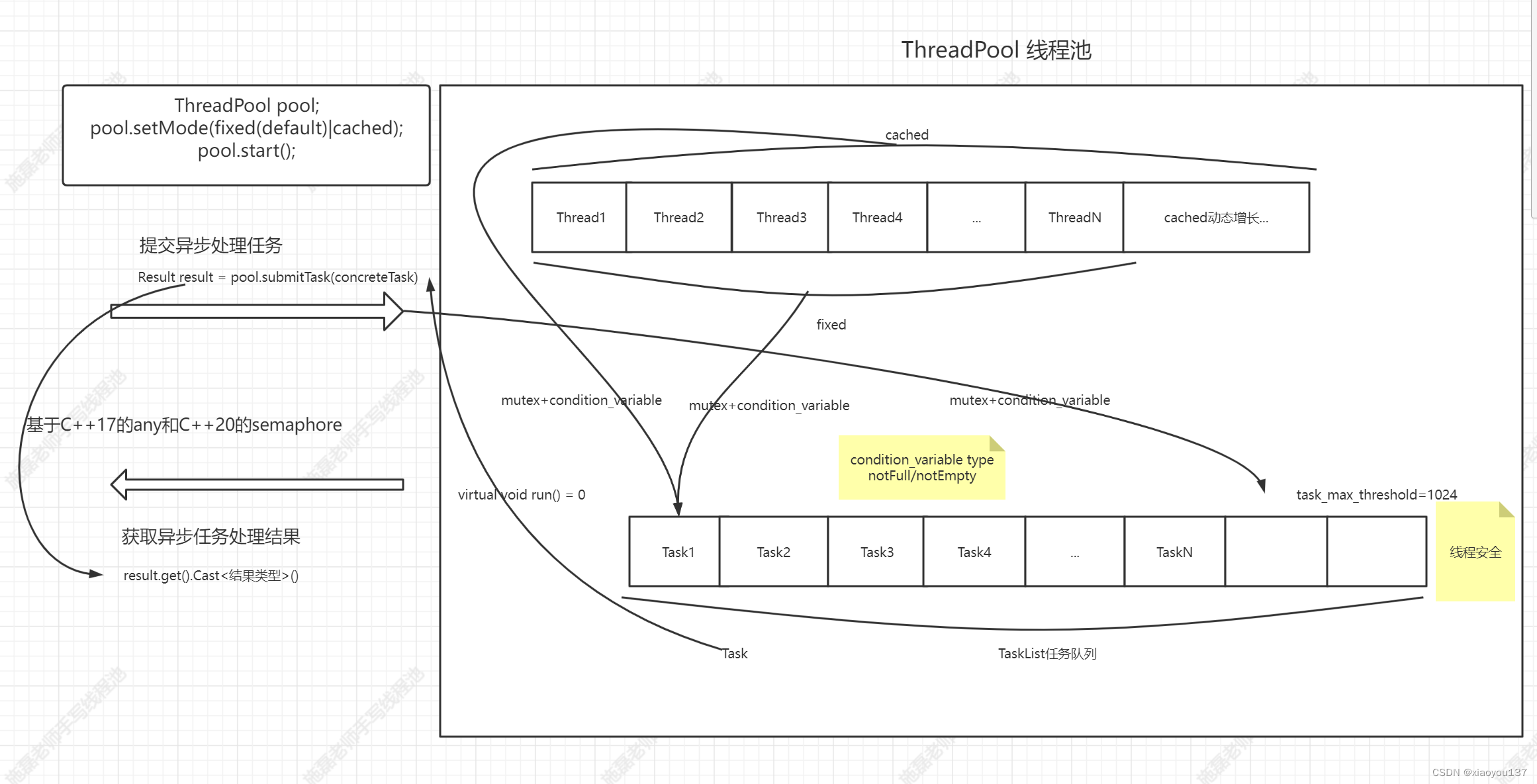
如何设计任务对象的run函数的返回值,可以表示任意类型
1.实现可以接收任意类型的万能容器Any类
实现万能容器Any类,可以接收任意类型的对象。可以考虑使用类型擦除技术实现,将不同类型的对象存储在同一个容器中,同时能够安全地访问这些对象。
在实现Any类之前,需要了解类型擦除技术。类型擦除可以在运行时隐藏模板类型信息,从而将不同类型的对象存储在同一个容器中。实现类型擦除的方式有很多,比如使用虚函数、模板类、模板函数等方式。
在实现Any类中,可以使用模板类和虚函数的方式来实现类型擦除,模板类Any用于存储对象.
具体实现方式如下:
// 万能容器Any类
class Any
{
public:
// 默认构造函数和析构函数, 删除拷贝构造函数和拷贝赋值函数, 允许右值移动构造函数和右值移动赋值函数
Any() = default;
~Any() = default;
Any(const Any &) = delete;
Any(Any &&) = default;
Any &operator=(const Any &) = delete;
Any &operator=(Any &&) = default;
// 构造函数, 接受任意类型参数, 构造Derived<T>对象存储于base_成员中
template <typename T>
Any(T data) : base_(std::make_unique<Derived<T>>(data))
{
}
// 模板函数cast_, 可以强制类型转换为指定类型
// 将base_成员中的Derived<T>对象强制类型转换为T类型
// 如果类型不匹配则抛出异常
template <typename T>
T cast_()
{
Derived<T> *pd = dynamic_cast<Derived<T> *>(base_.get());
if (pd == nullptr)
{
throw "type is not matched!";
}
else
{
return pd->data_;
}
}
private:
// 嵌套类Base作为万能容器Any的基类, 可以存储任意类型
// 析构函数设为虚函数, 方便在派生类中定义析构函数
class Base
{
public:
virtual ~Base() = default;
};
// 嵌套类Derived, 继承自Base, 实现具体类型的存储
// 存储类型为T的数据, 并在构造函数中进行初始化
template <typename T>
class Derived : public Base
{
public:
Derived(T data) : data_(data) {}
T data_;
};
// base_成员指向Base类型的智能指针, 可以指向任意类型的Derived对象
std::unique_ptr<Base> base_;
};
在Any类的实现中,包括了模板类型派生类Derived和虚基类Base。
在模板类型派生类Derived中,使用模板类型参数T来存储对象的值。在构造函数中,将对象的值保存到data_成员变量中。
在Any类中,使用模板构造函数,可以将任意类型的对象存储在Any类中。在cast函数中,使用dynamic_cast运算符将指针转换成Derived*类型的指针,然后返回 data_成员
2.使用mutex和condition_variable实现semphore信号量
在C++20中,已经引入了信号量(semaphore)作为一种新的同步原语。不过,在早期的C++标准中,并没有提供对信号量的原生支持。但是,我们可以使用mutex和condition_variable来模拟信号量(semaphore)。实现方法如下:
// 实现一个信号量
class Semaphore
{
public:
Semaphore(int limit = 0)
: resLimit_(limit)
{}
~Semaphore() = default;
// 获取一个信号量
void wait()
{
std::unique_lock<std::mutex> lock(mtx_);
cond_.wait(lock, [&]() { return resLimit_ > 0; });
resLimit_--;
}
// 增加一个信号量
void post()
{
std::unique_lock<std::mutex> lock(mtx_);
resLimit_++;
cond_.notify_all();
}
private:
int resLimit_;
std::mutex mtx_;
std::condition_variable cond_;
};
这里我们定义了一个Semaphore类,构造函数中可以指定信号量的初值。在Semaphore中,有两个方法 : post()和wait()。
当一个线程调用post()时,信号量的值会加1,同时会唤醒至少一个在等待队列中的线程。
当一个线程调用wait()时,如果信号量的值大于0,该线程可以继续执行,同时信号量的值减1。否则,该线程就会被阻塞,等待其他线程调用notify()方法唤醒它。
在多线程环境中,Semaphore可以用于控制并发的数量。例如,在线程池中,可以使用Semaphore来控制同时运行的任务数量。在任务完成后,可以调用Semaphore的post()方法,以便其他任务可以开始执行。在主线程中,可以调用Semaphore的wait()方法,以便等待所有任务完成后再继续执行下一步操作。
Semaphore的好处是,wait() 和 post()方法可以在不同的线程中调用。可以用于从主线程获取子线程中task执行结果时的线程通信。
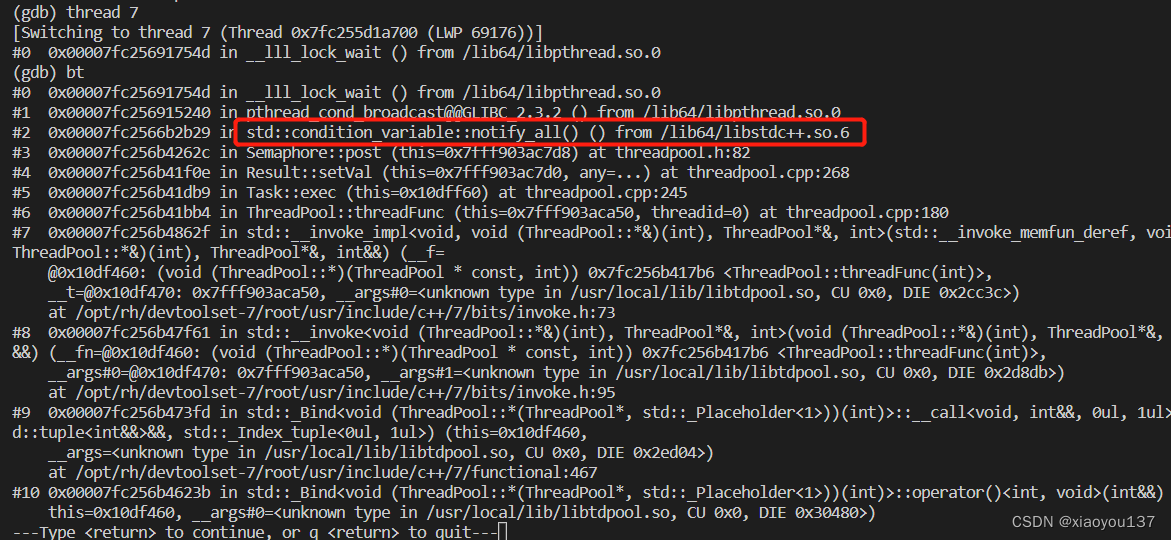
遇到的跨平台死锁问题
在windows平台下运行良好的线程池代码,在linux下却遇到死锁问题
在该问题中,Windows平台下的线程池代码可以正常运行,而在Linux平台下的特定情况下,所有子线程都被阻塞在lock_wait状态。进一步分析发现,当用户不使用Result的get方法获取线程执行任务结果时,线程池过早析构,导致所有子线程都阻塞住了,无法退出。
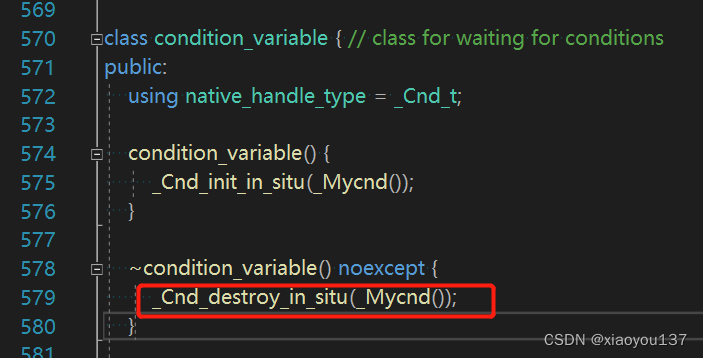
通过调用堆栈信息发现,子线程都阻塞在Semaphore::post()方法中的cond_.notify_all()里面,而正常情况下,notify_all()不会造成阻塞。查看condition_variable的源码得知,在Windows下,condition_variable析构时会释放掉它所有管理的资源,析构后当post()方法中再次调用cond_.notify_all()时,notify_all()不做任何事情,所以不会阻塞。而在Linux下,condition_variable的实现中,析构时并没有做任何事情,而当用户在主线程中定义的Result析构后,子线程中仍然可以通过传递的指针操作Result中的Semaphore进行post操作,从而调用到cond_.notify_all(),但此时所管理的mutex对象已经析构,所以子线程才会都阻塞在notify_all()的调用当中。
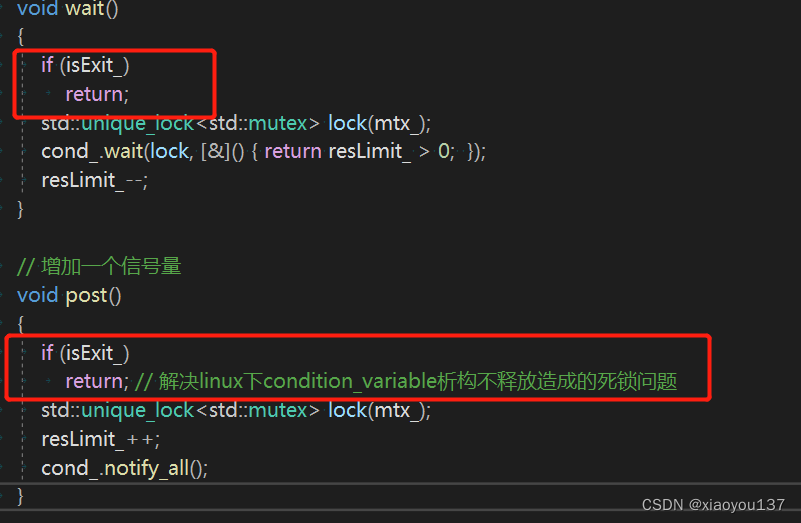
为了解决这个问题,可以在Semaphore中添加一个标志变量,如果Semaphore析构,则post和wait直接返回。这样就可以避免由于条件变量在析构后仍然被使用而导致的死锁问题。此外,在使用跨平台的线程库时,应该仔细分析线程库的具体实现,在代码中加入必要的判断和兼容性处理,以确保代码在不同的平台上都可以正常运行。


代码version一:使用自定义Any类和自定义信号量获取任务执行结果的版本
需要使用支持C++17的编译器编译
threadpool.h
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include <thread>
#include <vector>
#include <queue>
#include <memory>
#include <atomic>
#include <condition_variable>
#include <functional>
#include <unordered_map>
// 万能容器Any类
class Any
{
public:
// 默认构造函数和析构函数, 删除拷贝构造函数和拷贝赋值函数, 允许右值移动构造函数和右值移动赋值函数
Any() = default;
~Any() = default;
Any(const Any &) = delete;
Any(Any &&) = default;
Any &operator=(const Any &) = delete;
Any &operator=(Any &&) = default;
// 构造函数, 接受任意类型参数, 构造Derived<T>对象存储于base_成员中
template <typename T>
Any(T data) : base_(std::make_unique<Derived<T>>(data))
{
}
// 模板函数cast_, 可以强制类型转换为指定类型
// 将base_成员中的Derived<T>对象强制类型转换为T类型
// 如果类型不匹配则抛出异常
template <typename T>
T cast_()
{
Derived<T> *pd = dynamic_cast<Derived<T> *>(base_.get());
if (pd == nullptr)
{
throw "type is not matched!";
}
else
{
return pd->data_;
}
}
private:
// 嵌套类Base作为万能容器Any的基类, 可以存储任意类型
// 析构函数设为虚函数, 方便在派生类中定义析构函数
class Base
{
public:
virtual ~Base() = default;
};
// 嵌套类Derived, 继承自Base, 实现具体类型的存储
// 存储类型为T的数据, 并在构造函数中进行初始化
template <typename T>
class Derived : public Base
{
public:
Derived(T data) : data_(data) {}
T data_;
};
// base_成员指向Base类型的智能指针, 可以指向任意类型的Derived对象
std::unique_ptr<Base> base_;
};
class Semaphore
{
public:
Semaphore(int limit = 0) // 构造函数
: resLimit_(limit),
isExit_(false)
{
}
~Semaphore() // 析构函数
{
isExit_ = true; // 线程池停止运行,设置 isExit_ 为 true
}
// 获取一个信号量
void wait() // 等待信号量
{
if (isExit_) // 如果线程池已经停止运行,则直接返回
return;
std::unique_lock<std::mutex> lock(mtx_); // 构造互斥锁
cond_.wait(lock, [&]()
{ return resLimit_ > 0; }); // 等待条件变量,直到 resLimit_ 大于 0
resLimit_--; // 获取信号量,将资源数量减一
}
// 增加一个信号量
void post() // 释放信号量
{
if (isExit_) // 如果线程池已经停止运行,则直接返回
return;
std::unique_lock<std::mutex> lock(mtx_); // 构造互斥锁
resLimit_++; // 增加资源数量
cond_.notify_all(); // 通知等待该条件变量的线程
}
private:
std::atomic_bool isExit_; // 是否停止运行
int resLimit_; // 资源数量
std::mutex mtx_; // 互斥锁
std::condition_variable cond_; // 条件变量
};
class Task;
// 实现接受task执行后的返回值类Result
class Result
{
public:
Result(std::shared_ptr<Task> task, bool isValid = true); // 构造函数
~Result() = default; // 默认析构函数
// 设置 any_
void setVal(Any any); // 设置任务执行结果
// 获取任务执行结果
Any get(); // 获取任务执行结果
private:
Any any_; // 任务执行结果
Semaphore sem_; // 信号量,用于线程通信
std::shared_ptr<Task> task_; // 指向对应的任务对象
std::atomic_bool isValid_; // 返回值是否有效
};
// 任务抽象基类
class Task
{
public:
Task(); // 构造函数
~Task(); // 析构函数
// 用户可以自定义任意任务类型,从 Task 继承,重写 run 方法
virtual Any run() = 0; // 抽象方法,表示执行任务
void exec(); // 执行任务
// 设置结果对象 result_
void setResult(Result *p); // 设置任务执行结果
private:
Result *result_; // 任务执行结果
};
// 线程类
class Thread
{
public:
using ThreadFunc = std::function<void(int)>; // 线程入口函数类型定义为std::function对象
Thread(ThreadFunc); // 构造函数,传入线程入口函数
~Thread(); // 析构函数
// 启动线程
void start();
// 获取线程id
int getId() const;
private:
ThreadFunc func_; // 线程入口函数
static int generateId_; // 用于自动生成线程id
int threadId_; // 线程id
};
// 线程池模式enum类
enum class PoolMode
{
MODE_FIXED, // 固定大小线程池模式
MODE_CACHED // 缓存线程池模式
};
/*
example:
ThreadPool pool;
pool.start(4);
class MyTask : public Task
{
void run()
{
//...线程代码
}
};
pool.submitTask(std::make_shared<MyTask>());
*/
// 线程池类
class ThreadPool
{
public:
ThreadPool();
~ThreadPool();
ThreadPool(const ThreadPool &) = delete;
ThreadPool &operator=(const ThreadPool &) = delete;
// 设置线程池模式
void setMode(PoolMode mode);
// 开启线程池
void start(size_t initThreadSize = std::thread::hardware_concurrency());
// 设置任务数量上限
void setTaskQueMaxThreshold(size_t taskQueMaxThreshold);
// 设置cached模式下线程数量上限
void setThreadMaxThreshold(size_t threshold);
// 提交任务对象 用户调用该接口,传入自定义任务对象
Result submitTask(std::shared_ptr<Task> sp);
// 线程入口函数
void threadFunc(int threadid);
private:
// std::vector<std::unique_ptr<Thread> > threads_; // 线程池队列
std::unordered_map<int, std::unique_ptr<Thread>> threads_; // 线程池队列
size_t initThreadSize_; // 初始线程数
std::atomic_int curThreadSize_; // 当前线程数量
size_t threadSizeThreshold_; // 线程数量上限
std::atomic_int idleThreadSize_; // 空闲线程数量
std::queue<std::shared_ptr<Task>> taskQue_; // 任务队列
std::atomic_int taskSize_; // 任务数量
size_t taskQueMaxThreshold_; // 任务数量上限
std::mutex taskQueMtx_; // 任务队列锁,保证线程安全
std::condition_variable notFull_; // 表示任务队列不满
std::condition_variable notEmpty_; // 表示任务队列不空
std::condition_variable exitCond_; // 等待线程资源全部回收
PoolMode poolMode_; // 线程池模式
std::atomic_bool isPoolRunning_; // 线程池是否运行
bool checkRunningState();
};
#endif
threadpool.cpp
#include "threadpool.h"
#include <iostream>
const int TASK_MAX_THRESHOLD = 1024;
const int THREAD_MAX_THRESHOLD = 100;
const int THREAD_MAX_IDLE_TIME = 60;
/**********************************************************************************
ThreadPool 的 方法实现
**********************************************************************************/
ThreadPool::ThreadPool()
: initThreadSize_(0),
taskSize_(0),
taskQueMaxThreshold_(TASK_MAX_THRESHOLD),
threadSizeThreshold_(THREAD_MAX_THRESHOLD),
poolMode_(PoolMode::MODE_FIXED),
isPoolRunning_(false),
idleThreadSize_(0),
curThreadSize_(0)
{
}
ThreadPool::~ThreadPool()
{
isPoolRunning_ = false;
// 等待线程池所有线程返回
// 阻塞状态和正在执行任务中
std::unique_lock<std::mutex> lock(taskQueMtx_);
notEmpty_.notify_all();
exitCond_.wait(lock, [&]()->bool { return threads_.size() == 0; });
}
void ThreadPool::setMode(PoolMode mode)
{
if (checkRunningState())
return;
poolMode_ = mode;
}
void ThreadPool::start(size_t initThreadSize)
{
// 设置初始线程个数
initThreadSize_ = initThreadSize;
curThreadSize_ = initThreadSize;
isPoolRunning_ = true;
// 创建线程对象
for (size_t i = 0; i < initThreadSize_; i++)
{
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadid = ptr->getId();
threads_.emplace(threadid, std::move(ptr));
}
// 启动所有线程
for (size_t i = 0; i < initThreadSize_; i++)
{
threads_[i]->start();
idleThreadSize_++;
}
}
void ThreadPool::setTaskQueMaxThreshold(size_t taskQueMaxThreshold)
{
if (checkRunningState())
return;
taskQueMaxThreshold_ = taskQueMaxThreshold;
}
void ThreadPool::setThreadMaxThreshold(size_t threshold)
{
if (checkRunningState())
return;
threadSizeThreshold_ = threshold;
}
Result ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
// 获取任务队列锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
// 等待任务队列不满的条件达成
if (!notFull_.wait_for(lock, std::chrono::seconds(1), [&]() { return taskQue_.size() < TASK_MAX_THRESHOLD; }))
{
// 等待超过1s,提交task失败,返回
std::cerr << " task queue is full, submit task failed!" << std::endl;
return Result(sp, false);
}
// 把任务放入队列
taskQue_.emplace(sp);
taskSize_++;
// 在notEmpty上通知消费线程
notEmpty_.notify_all();
if (poolMode_ == PoolMode::MODE_CACHED && taskSize_ > idleThreadSize_
&& curThreadSize_ < (int)threadSizeThreshold_)
{
std::cout << "create new thread " << std::endl;
// 创建新线程
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadid = ptr->getId();
threads_.emplace(threadid, std::move(ptr));
threads_[threadid]->start();
curThreadSize_++;
idleThreadSize_++;
}
return Result(sp);
}
void ThreadPool::threadFunc(int threadid)
{
auto lastTime = std::chrono::high_resolution_clock().now();
while (true)
{
std::shared_ptr<Task> task;
{
// 获取锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
std::cout << std::this_thread::get_id() << " 尝试获取任务..." << std::endl;
// 每一秒返回一次, 区分超时返回和有任务执行返回
while (taskQue_.size() == 0)
{
// 线程池要结束,回收线程
if (!isPoolRunning_) {
threads_.erase(threadid);
std::cout << "threadid:" << std::this_thread::get_id() << " exit!!!" << std::endl;
exitCond_.notify_all();
return;
}
if (poolMode_ == PoolMode::MODE_CACHED)
{
// 超时返回
// cached模式下,有可能创建了很多线程,应该把空闲超过60s的线程回收掉
if (std::cv_status::no_timeout == notEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
auto now = std::chrono::high_resolution_clock().now();
auto dur = std::chrono::duration_cast<std::chrono::seconds>(now - lastTime);
if (dur.count() >= THREAD_MAX_IDLE_TIME && curThreadSize_ > (int)initThreadSize_)
{
// 回收当前线程
// 记录线程数量相关变量修改
// 把线程对象从队列中删除
threads_.erase(threadid);
curThreadSize_--;
idleThreadSize_--;
std::cout << "threadid:" << std::this_thread::get_id() << " exit!!!" << std::endl;
}
}
}
else
{
// 等待notEmpty条件满足
notEmpty_.wait(lock);
}
}
idleThreadSize_--;
// 从任务队列取一个任务出来
task = taskQue_.front();
taskQue_.pop();
taskSize_--;
std::cout << std::this_thread::get_id() << " 获取任务成功..." << std::endl;
// 在notFull_上通知
notFull_.notify_all();
} //释放锁
// 执行task
if (task != nullptr)
task->exec();
idleThreadSize_++;
//更新线程调度执行完任务的时间
lastTime = std::chrono::high_resolution_clock().now();
}
// 线程池要结束,回收线程
}
bool ThreadPool::checkRunningState()
{
return isPoolRunning_;
}
/**********************************************************************************
Thread 的 方法实现
**********************************************************************************/
int Thread::generateId_ = 0;
Thread::Thread(ThreadFunc func)
: func_(func),
threadId_(generateId_++)
{
}
Thread::~Thread()
{
}
void Thread::start()
{
std::thread t(func_, threadId_); // 启动线程
t.detach(); // 分离线程
}
int Thread::getId() const
{
return threadId_;
}
/**********************************************************************************
Task 的 方法实现
**********************************************************************************/
Task::Task()
: result_(nullptr)
{
}
Task::~Task()
{
}
void Task::exec()
{
if (result_ != nullptr)
{
result_->setVal(run());
}
}
void Task::setResult(Result* p)
{
result_ = p;
}
/**********************************************************************************
Result 的 方法实现
**********************************************************************************/
Result::Result(std::shared_ptr<Task> task, bool isValid)
: task_(task),
isValid_(isValid)
{
task_->setResult(this);
}
void Result::setVal(Any any)
{
this->any_ = std::move(any);
sem_.post();
}
Any Result::get()
{
if (!isValid_) {
return Any();
}
sem_.wait();
return std::move(any_);
}
test.cpp
#include "threadpool.h"
#include <iostream>
using uLong = unsigned long long;
class MyTask : public Task
{
public:
MyTask(int begin, int end) : begin_(begin), end_(end)
{}
Any run()
{
//std::cout << "start thread tid: " << std::this_thread::get_id() << std::endl;
//std::this_thread::sleep_for(std::chrono::seconds(3));
//std::cout << "end thread tid: " << std::this_thread::get_id() << std::endl;
uLong sum = 0;
for (uLong i = begin_; i <= end_; i++)
{
sum += i;
}
return sum;
}
private:
int begin_;
int end_;
};
int main()
{
{
ThreadPool pool;
// 用户设置线程池的工作模式
pool.setMode(PoolMode::MODE_CACHED);
pool.start(4);
//std::this_thread::sleep_for(std::chrono::seconds(2));
Result res1 = pool.submitTask(std::make_shared<MyTask>(1, 100000000));
Result res2 = pool.submitTask(std::make_shared<MyTask>(100000001, 200000000));
Result res3 = pool.submitTask(std::make_shared<MyTask>(200000001, 300000000));
Result res4 = pool.submitTask(std::make_shared<MyTask>(200000001, 300000000));
Result res5 = pool.submitTask(std::make_shared<MyTask>(200000001, 300000000));
Result res6 = pool.submitTask(std::make_shared<MyTask>(200000001, 300000000));
// master-slave
uLong sum1 = res1.get().cast_<uLong>();
uLong sum2 = res2.get().cast_<uLong>();
uLong sum3 = res3.get().cast_<uLong>();
uLong sum4 = res4.get().cast_<uLong>();
uLong sum5 = res5.get().cast_<uLong>();
uLong sum6 = res6.get().cast_<uLong>();
std::cout << sum1 + sum2 + sum3 + sum4 + sum5 + sum6 << std::endl;
}
std::cout << " main thread over!" << std::endl;
return 0;
}
使用packaged_task和future机制,重构代码
通过使用C++11提供的packaged_task和future机制,我们可以对代码进行重构,将Task类替换为packaged_task,将Result类替换为future,这样可以节省很多代码。
在实现submitTask函数时,我们可以使用可变参数模板编程,让submitTask可以接受任意任务函数和任意数量的参数。这样,我们可以更加灵活地使用submitTask函数,满足不同的需求。
使用packaged_task和future机制可以使我们的代码更加简洁、可读性更高、可维护性更好。同时,这种方法还可以使我们的代码更加高效,因为它避免了线程之间不必要的同步操作,从而减少了线程间的竞争和冲突。
总之,使用C++11提供的packaged_task和future机制,可以大大提高我们的代码的效率和可维护性,让我们的程序更加健壮和可靠
template<typename Func, typename... Args>
auto submitTask(Func&& func, Args&&... args)->std::future<decltype(func(args...))>
{
// 打包任务,放入任务队列里
using RType = decltype(func(args...));
auto task = std::make_shared<std::packaged_task<RType()>>(
std::bind(std::forward<Func>(func), std::forward<Args>(args)...));
std::future<RType> result = task->get_future();
// 获取任务队列锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
// 等待任务队列不满的条件达成
if (!notFull_.wait_for(lock, std::chrono::seconds(1), [&]() { return taskQue_.size() < TASK_MAX_THRESHOLD; }))
{
// 等待超过1s,提交task失败,返回
std::cerr << " task queue is full, submit task failed!" << std::endl;
auto task = std::make_shared<std::packaged_task<RType()>>(
[]()->RType { return RType(); });
(*task)();
return task->get_future();
}
// task进入队列,包一层lambda函数以符合类型
taskQue_.emplace([task]() {(*task)(); });
taskSize_++;
// 在notEmpty上通知消费线程
notEmpty_.notify_all();
if (poolMode_ == PoolMode::MODE_CACHED && taskSize_ > idleThreadSize_
&& curThreadSize_ < (int)threadSizeThreshold_)
{
std::cout << "create new thread " << std::endl;
// 创建新线程
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadid = ptr->getId();
threads_.emplace(threadid, std::move(ptr));
threads_[threadid]->start();
curThreadSize_++;
idleThreadSize_++;
}
return result;
}
代码version二 重构后的版本
threadpool.h
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include <thread>
#include <vector>
#include <queue>
#include <memory>
#include <atomic>
#include <condition_variable>
#include <functional>
#include <unordered_map>
#include <future>
#include <iostream>
const int TASK_MAX_THRESHOLD = 1024;
const int THREAD_MAX_THRESHOLD = 100;
const int THREAD_MAX_IDLE_TIME = 60;
// 线程类
class Thread
{
public:
using ThreadFunc = std::function<void(int)>;
Thread(ThreadFunc func)
: func_(func),
threadId_(generateId_++)
{}
~Thread()
{}
// 启动线程
void start()
{
std::thread t(func_, threadId_); // 启动线程
t.detach(); // 分离线程
}
// 获取线程id
int getId() const
{
return threadId_;
}
private:
ThreadFunc func_; // 线程的入口函数
static int generateId_;
int threadId_; // 线程id
};
int Thread::generateId_ = 0;
// 线程池模式enum类
enum class PoolMode
{
MODE_FIXED,
MODE_CACHED
};
/*
example:
ThreadPool pool;
pool.start(4);
class MyTask : public Task
{
void run()
{
//...线程代码
}
};
pool.submitTask(std::make_shared<MyTask>());
*/
// 线程池类
class ThreadPool
{
public:
ThreadPool()
: initThreadSize_(0),
taskSize_(0),
taskQueMaxThreshold_(TASK_MAX_THRESHOLD),
threadSizeThreshold_(THREAD_MAX_THRESHOLD),
poolMode_(PoolMode::MODE_FIXED),
isPoolRunning_(false),
idleThreadSize_(0),
curThreadSize_(0)
{
}
~ThreadPool()
{
isPoolRunning_ = false;
// 等待线程池所有线程返回
// 阻塞状态和正在执行任务中
std::unique_lock<std::mutex> lock(taskQueMtx_);
notEmpty_.notify_all();
exitCond_.wait(lock, [&]()->bool { return threads_.size() == 0; });
}
ThreadPool(const ThreadPool&) = delete;
ThreadPool& operator=(const ThreadPool&) = delete;
// 设置线程池模式
void setMode(PoolMode mode)
{
if (checkRunningState())
return;
poolMode_ = mode;
}
// 开启线程池
void start(size_t initThreadSize = std::thread::hardware_concurrency())
{
// 设置初始线程个数
initThreadSize_ = initThreadSize;
curThreadSize_ = initThreadSize;
isPoolRunning_ = true;
// 创建线程对象
for (size_t i = 0; i < initThreadSize_; i++)
{
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadid = ptr->getId();
threads_.emplace(threadid, std::move(ptr));
}
// 启动所有线程
for (size_t i = 0; i < initThreadSize_; i++)
{
threads_[i]->start();
idleThreadSize_++;
}
}
// 设置任务数量上限
void setTaskQueMaxThreshold(size_t taskQueMaxThreshold)
{
if (checkRunningState())
return;
taskQueMaxThreshold_ = taskQueMaxThreshold;
}
// 设置cached模式下线程数量上限
void setThreadMaxThreshold(size_t threshold)
{
if (checkRunningState())
return;
threadSizeThreshold_ = threshold;
}
template<typename Func, typename... Args>
auto submitTask(Func&& func, Args&&... args)->std::future<decltype(func(args...))>
{
// 打包任务,放入任务队列里
using RType = decltype(func(args...));
auto task = std::make_shared<std::packaged_task<RType()>>(
std::bind(std::forward<Func>(func), std::forward<Args>(args)...));
std::future<RType> result = task->get_future();
// 获取任务队列锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
// 等待任务队列不满的条件达成
if (!notFull_.wait_for(lock, std::chrono::seconds(1), [&]() { return taskQue_.size() < TASK_MAX_THRESHOLD; }))
{
// 等待超过1s,提交task失败,返回
std::cerr << " task queue is full, submit task failed!" << std::endl;
auto task = std::make_shared<std::packaged_task<RType()>>(
[]()->RType { return RType(); });
(*task)();
return task->get_future();
}
// task进入队列,包一层lambda函数以符合类型
taskQue_.emplace([task]() {(*task)(); });
taskSize_++;
// 在notEmpty上通知消费线程
notEmpty_.notify_all();
if (poolMode_ == PoolMode::MODE_CACHED && taskSize_ > idleThreadSize_
&& curThreadSize_ < (int)threadSizeThreshold_)
{
std::cout << "create new thread " << std::endl;
// 创建新线程
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadid = ptr->getId();
threads_.emplace(threadid, std::move(ptr));
threads_[threadid]->start();
curThreadSize_++;
idleThreadSize_++;
}
return result;
}
// 线程入口函数
void threadFunc(int threadid)
{
auto lastTime = std::chrono::high_resolution_clock().now();
while (true)
{
Task task;
{
// 获取锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
std::cout << std::this_thread::get_id() << " 尝试获取任务..." << std::endl;
// 每一秒返回一次, 区分超时返回和有任务执行返回
while (taskQue_.size() == 0)
{
// 线程池要结束,回收线程
if (!isPoolRunning_) {
threads_.erase(threadid);
std::cout << "threadid:" << std::this_thread::get_id() << " exit!!!" << std::endl;
exitCond_.notify_all();
return;
}
if (poolMode_ == PoolMode::MODE_CACHED)
{
// 超时返回
// cached模式下,有可能创建了很多线程,应该把空闲超过60s的线程回收掉
if (std::cv_status::no_timeout == notEmpty_.wait_for(lock, std::chrono::seconds(1)))
{
auto now = std::chrono::high_resolution_clock().now();
auto dur = std::chrono::duration_cast<std::chrono::seconds>(now - lastTime);
if (dur.count() >= THREAD_MAX_IDLE_TIME && curThreadSize_ > (int)initThreadSize_)
{
// 回收当前线程
// 记录线程数量相关变量修改
// 把线程对象从队列中删除
threads_.erase(threadid);
curThreadSize_--;
idleThreadSize_--;
std::cout << "threadid:" << std::this_thread::get_id() << " exit!!!" << std::endl;
}
}
}
else
{
// 等待notEmpty条件满足
notEmpty_.wait(lock);
}
}
idleThreadSize_--;
// 从任务队列取一个任务出来
task = taskQue_.front();
taskQue_.pop();
taskSize_--;
std::cout << std::this_thread::get_id() << " 获取任务成功..." << std::endl;
// 在notFull_上通知
notFull_.notify_all();
} //释放锁
// 执行task
if (task != nullptr)
task();
idleThreadSize_++;
//更新线程调度执行完任务的时间
lastTime = std::chrono::high_resolution_clock().now();
}
}
private:
//std::vector<std::unique_ptr<Thread> > threads_; // 线程池队列
std::unordered_map<int, std::unique_ptr<Thread> > threads_;
size_t initThreadSize_; // 初始线程数
std::atomic_int curThreadSize_; // 当前线程数量
size_t threadSizeThreshold_; // 线程数量上限
std::atomic_int idleThreadSize_; // 空闲线程数量
using Task = std::function<void()>;
std::queue<Task> taskQue_; // 任务队列
std::atomic_int taskSize_; // 任务数量
size_t taskQueMaxThreshold_; // 任务数量上限
std::mutex taskQueMtx_; // 任务队列锁,保证线程安全
std::condition_variable notFull_; // 表示任务队列不满
std::condition_variable notEmpty_; // 表示任务队列不空
std::condition_variable exitCond_; // 等待线程资源全部回收
PoolMode poolMode_; // 线程池模式
std::atomic_bool isPoolRunning_; // 线程池是否运行
bool checkRunningState()
{
return isPoolRunning_;
}
};
#endif
test.cpp
#include <iostream>
#include "threadpool.h"
unsigned long long sum1(int a, int b)
{
unsigned long long sum = 0;
for (int i = a; i <= b; i++)
{
sum += i;
}
return sum;
}
int main()
{
ThreadPool pool;
pool.setMode(PoolMode::MODE_CACHED);
pool.start(2);
std::future<unsigned long long> r1 = pool.submitTask(sum1, 1, 1000000000);
std::future<unsigned long long> r2 = pool.submitTask(sum1, 1000000001, 2000000000);
std::future<unsigned long long> r3 = pool.submitTask(sum1, 2000000001, 3000000000);
std::future<unsigned long long> r4 = pool.submitTask(sum1, 3000000001, 4000000000);
//std::future<unsigned long long> r5 = pool.submitTask(sum1, 4000000001, 5000000000);
//std::future<unsigned long long> r6 = pool.submitTask(sum1, 5000000001, 6000000000);
//std::future<unsigned long long> r7 = pool.submitTask(sum1, 6000000001, 7000000000);
unsigned long long res = r1.get() + r2.get() + r3.get() + r4.get();
std::cout << "最终计算结果: " << res << std::endl;
return 0;
}