摘要
本文介绍Kubernetes最流行的网络解决方案calico。
kubernetes中不同宿主上的pod需要相互通信,如果按TCP/IP协议分层进行分类:
-
二层方案:flannel的udp和vxlan模式
-
三层方案:flannel的host-gw模式;calico的IPIP模式与BGP模式;kube-router
本文我们学习calico具体是如何运作的。
引出
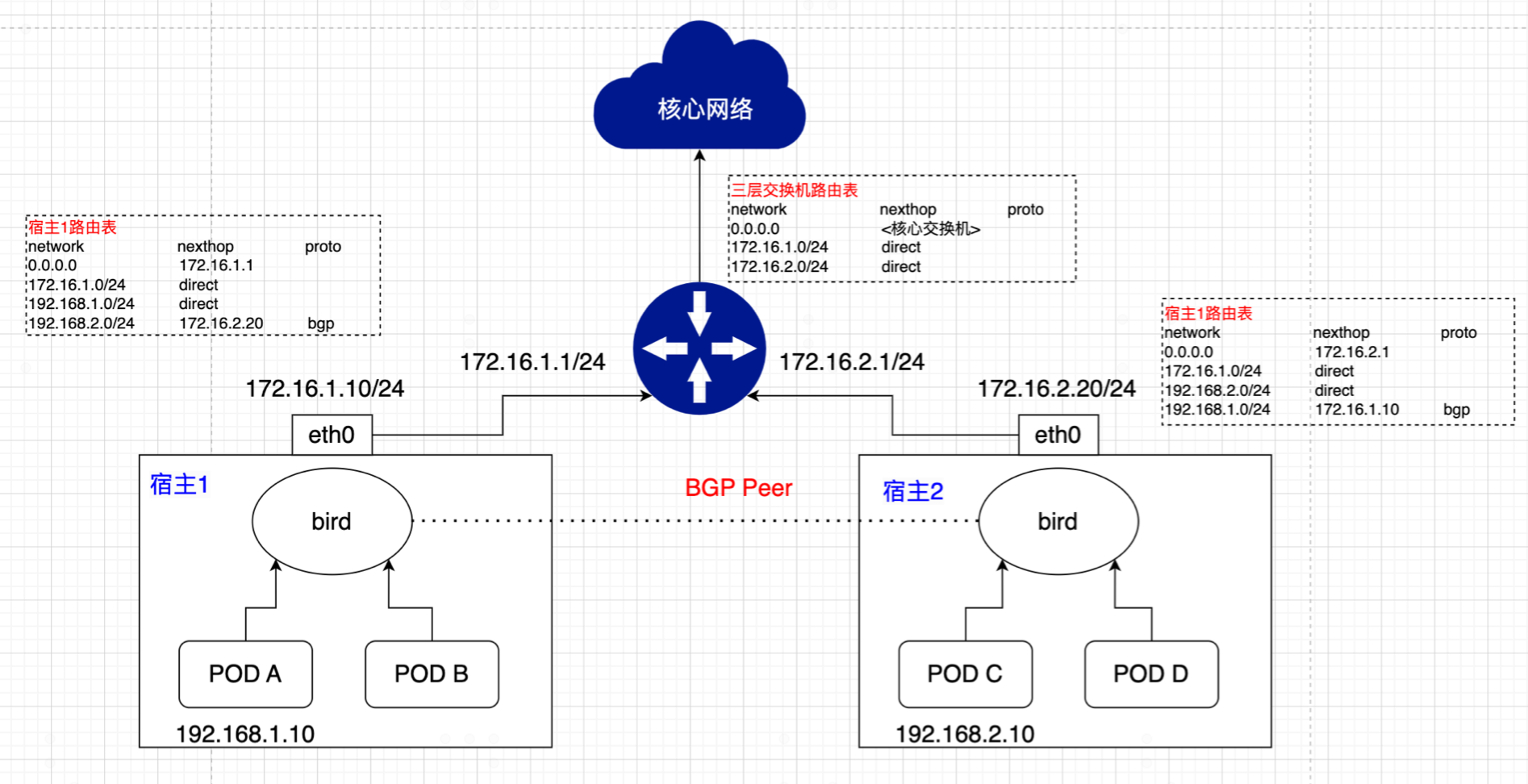
在介绍calico之前,先来看一个网络中最最常见也最简单的网络通信案例, 如图所示:
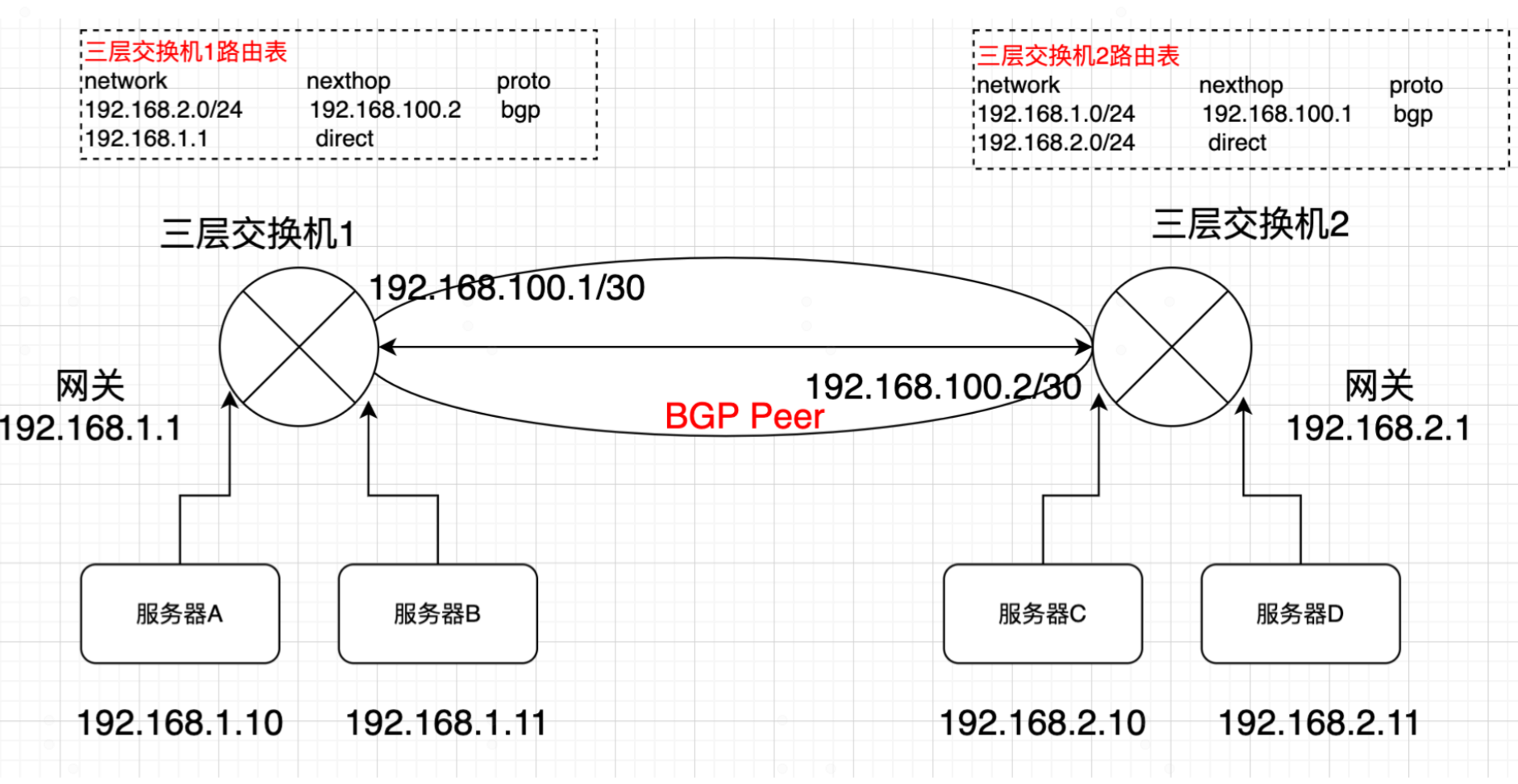
有2个三层交换机,每个交换机下面有一个网段,分别是192.168.1.0/24和192.168.2.0/24网段。同时每个交换机各自连接了2台服务器,各个服务器的IP如上图所示。为了实现服务器之前相互通信,可以这些实现:
1) 两个交换机运行三层路由协议比如ospf,bgp,进行相互路由学习。
2)各个服务器将网关指向对应的交换机。
当两个三层交换机路由协议完成邻接状态后,交换机A学习到,要去192.168.2.0/24网段,下一跳地址是交换机B。同理交换机B学习到,要去192.168.1.0/24网段,下一跳地址是交换机A。
这是如何服务器A需要与服务器C通信,路由是这样的:
- 服务器A先判断服务器C的IP地址,不是与其在同一网段,那么服务器A将数据包交给网关即交换机A ,数据包的格式:
|目的IP=192.168.2.10|源IP=192.168.1.10| DATA |
- 交换机收到数据包后,查询自己的路由表,发现数据包的目的IP是192.168.2.10,是属于192.168.2.0/24网段。进而从路由表查到下一跳是交换机B的互联地址192.168.100.2,于是数据包被传递给交换机B
- 交换机B收到数据包后,先查看数据包的目的IP是192.168.2.10,再查询交换机自己的路由表,查询到192.168.2.0/24是属于它的直连网段,于是交换机通过arp查询到服务器C的mac是CCCC.CCCC.CCCC.CCCC,于是将数据包通过二层转发给服务器C。至此,就完成了单边路由,同理回程路由也是一样的。
再多想一下,假如上图中的服务器演变是pod,而三层交换机演变为宿主中的一个运行了bgp路由协议的进程(bird),如下图:
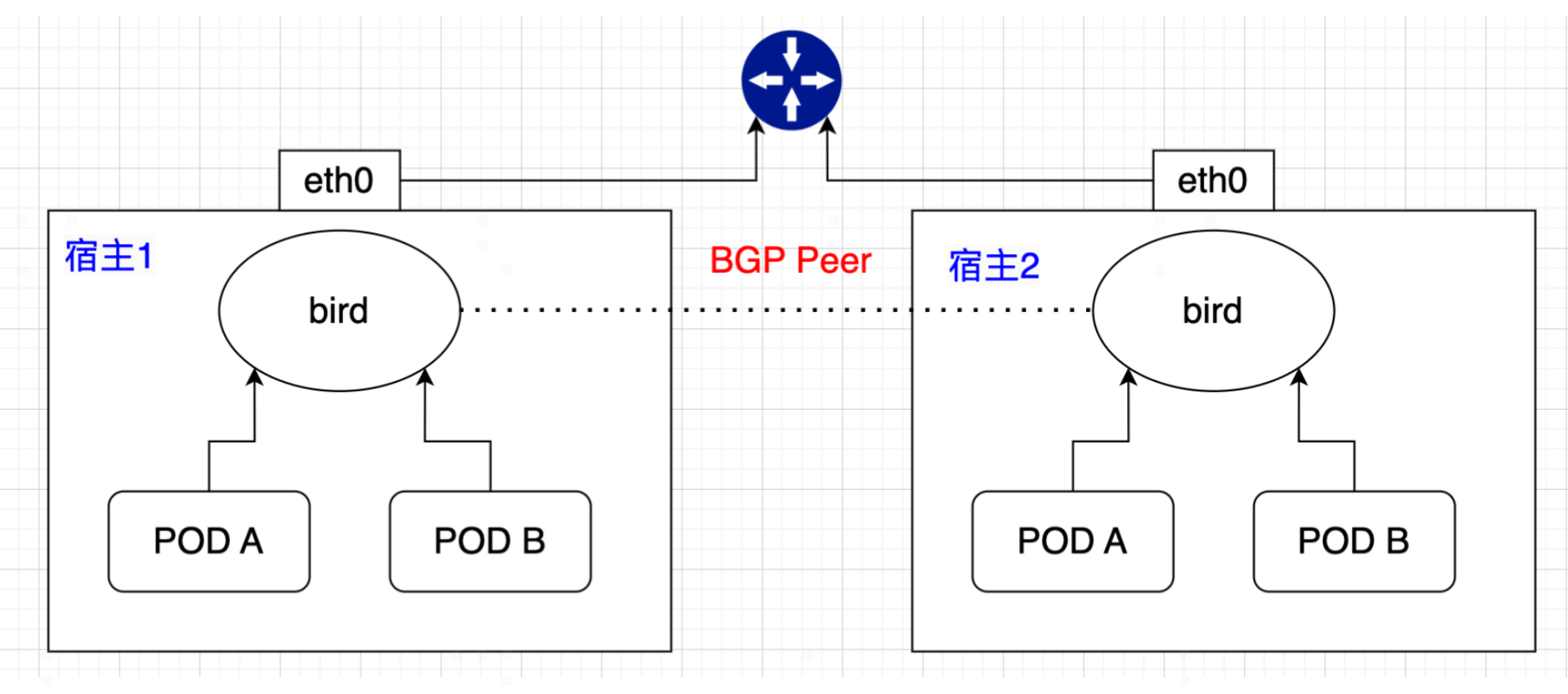
这就是calico的雏形。所以某种程度上说,calico看似很简单,就是将宿主节点当作虚拟路由vRouter,为POD做路由转发能力。
Calico的介绍
calico简介
Calico是一个开源的网络和网络安全解决方案,适用于容器、虚拟机和基于本机主机的工作负载。Calico支持多种平台,包括Kubernetes、OpenShift、Docker EE、OpenStack和裸机服务。 Calico将灵活的网络功能与随时随地运行的安全实施相结合,提供了具有本地Linux内核性能和真正的云本地可伸缩性的解决方案。Calico为开发人员和集群运营商提供一致的体验和功能集,无论是在公共云中运行还是在本地运行,都可以在单个节点上运行。 — calico官网
Calico 方案的特点:
- 由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的。
- Calico还能为通信实现网络控制策略,因为数据包直接走原生TCP/IP的协议栈,而TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
Calico优劣势
优势
-
更优的资源利用
二层网络通讯需要依赖广播消息机制,广播消息的开销与host的数量呈指数级增长,Calico使用的三层路由方法,则完全抑制了二层广播,减少了资源开销。此外,二层网络使用Vlan隔离技术,天生有4096个规格限制,即便可以使用Vxlan解决,但Vxlan又带来了隧道开销的问题。Calico不使用vlan或者vxlan技术,使资源利用率更高。 -
可扩展性
Calico使用与Internet类似的方案,Internet的网络比任何数据中心都大,Calico同样天然具有扩展性。 -
简单更容易调试
由于没有隧道,意味着workloads之间路径更短,配置更少,在host之间更容易进行debug调试。 -
更少的依赖
Calico仅依赖三层路由可达 -
可适配性
Calico较少的依赖性使它能适配所有的VM、Container、白盒或者混合环境场景。 -
支持网络策略
可以配合使用
Network Policy做 pod 和 pod 之前的访问控制
劣势
- 要求宿主机处于同一个2层网络下,也就是连在一台交换机上
- 路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至node的处理能力,从而限制了整个网络的扩张。(可以使用大规模方式解决)
- 每个node上会设置海量的iptables规则、路由,运维、排障难度大。
- 原理决定了它不可能支持VPC,容器只能从calico设置的网段中获取ip。
calico的架构
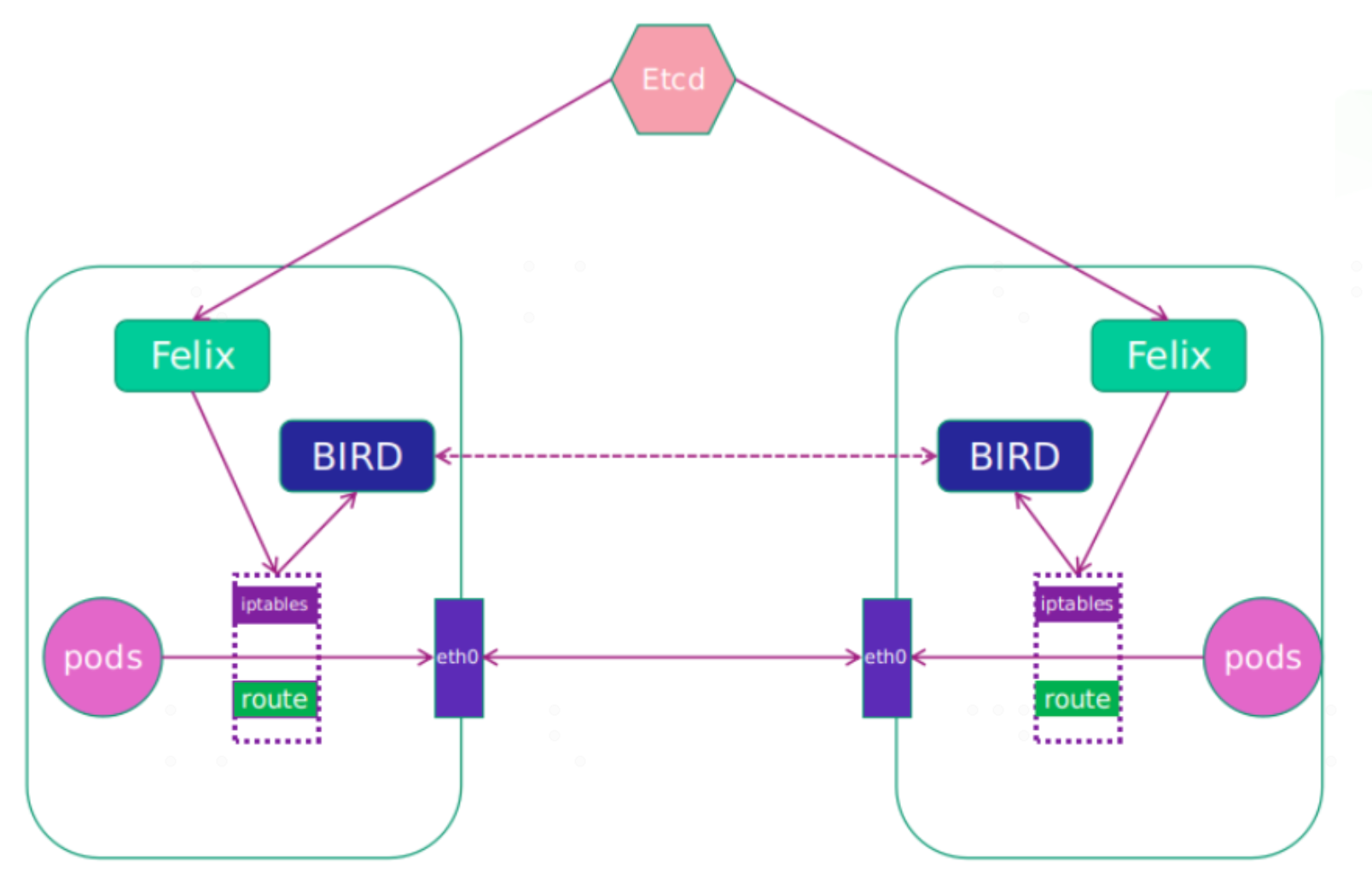
(图片来自网络,如有请求请联系作者)
Calico的主要工作组件包括:
Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。Felix会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是创建了一个容器等。用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。接口管理:Felix为内核编写一些接口信息,以便让内核能正确的处理主机endpoint的流量。特别是主机之间的ARP请求和处理ip转发。路由规则:Felix负责主机之间路由信息写到linux内核的FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。ACL规则:Felix负责将ACL策略写入到linux内核中,保证主机endpoint的为有效流量不能绕过calico的安全措施。状态报告:Felix负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入etcd,使其对网络的其他组件和操作人员可见。
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;BIRD:Calico 为每一台 Host 部署一个BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通。BGP Route Reflector:在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。Calicoctl:calico 命令行管理工具。Orchestrator plugin:协调器插件负责允许kubernetes或OpenStack等原生云平台方便管理Calico,可以通过各自的API来配置Calico网络实现无缝集成。如kubernetes的cni网络插件。
IPIP与BGP模式
- BGP
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。BGP路由模式使用直接路由,避免了数据包封装与解封,所以性能是最好的。
BGP模式使用的是直接路由方式,在kubernetes中,由于pod所在网段对于内网交换机是无法识别的,所以使用的BGP模式的前提是:宿主之间必须在同一个二层域内。(如果对网络不是特别熟悉的话,可能无法准确理解,后面我会单独分析。请见"补充")
- IPIP
IPIP模式是把 IP 层封装到 IP 层的一个 tunnel。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。ipip 是由linx内核实现,的源代码在内核 net/ipv4/ipip.c 中可以找到。
IPIP模式是calico默认的模式,无论宿主是否在同一二层域都可以。缺点是经过IPIP封装与解封,性能有稍微损失。性能对比请详解文章:calico的两种网络模式BGP和IP-IP性能分析。
特别说明:IPIP模式下,宿主上的bird进程仍然会跑BGP,只是POD to POD 通信的数据包会被,宿主利用隧道进行封装。
- 混合模式
从上面可以看出IPIP模式的优点是只要宿主之间三层互通即可,而BGP模式需要宿主之间必须在一个二层域内。但BGP使用直接路由,性能又是最好的。 所以calico的混合模式,可以动态的自行选择模式:即如果两宿主在同一二层域就选择BGP模式,不再同一二层域就选择IPIP模式。
calico模式调整
接下来介绍如何修改calico的网络模式:
kubectl edit ippool
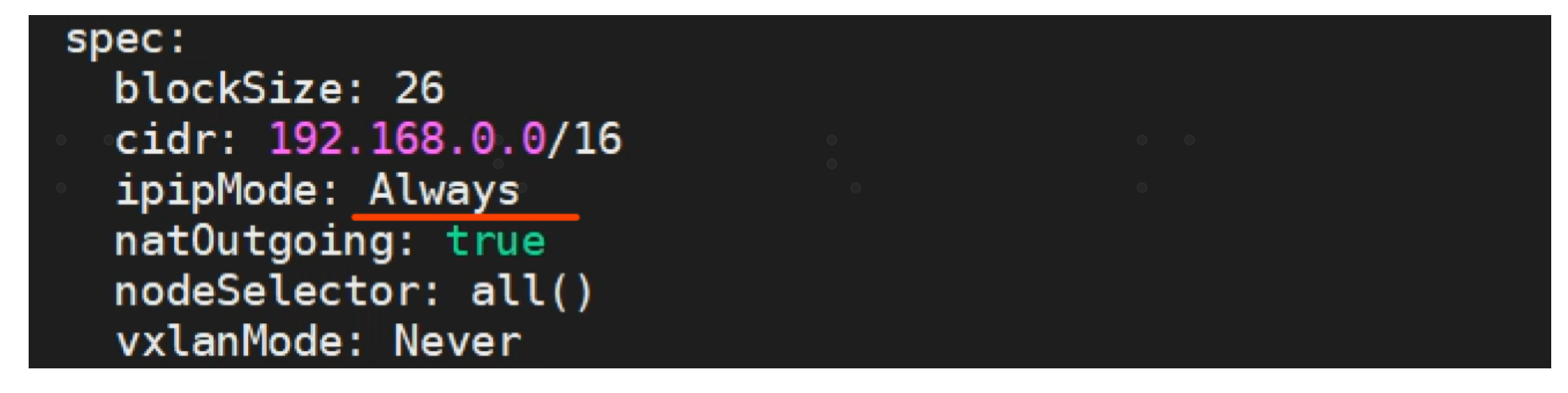
ipipMode: Always 为默认值,即使用IPIP模式。如果要修改为BPG模式,需要将值改Never。另外,可以将值修改为CrossSubnet,表示如果两宿主节点在同一个二层网络使用BGP模式,而不在同一二层模式这使用IPIP模式
如下图,我们将calico网络模式修改为混合模式后,观察路由表如下:
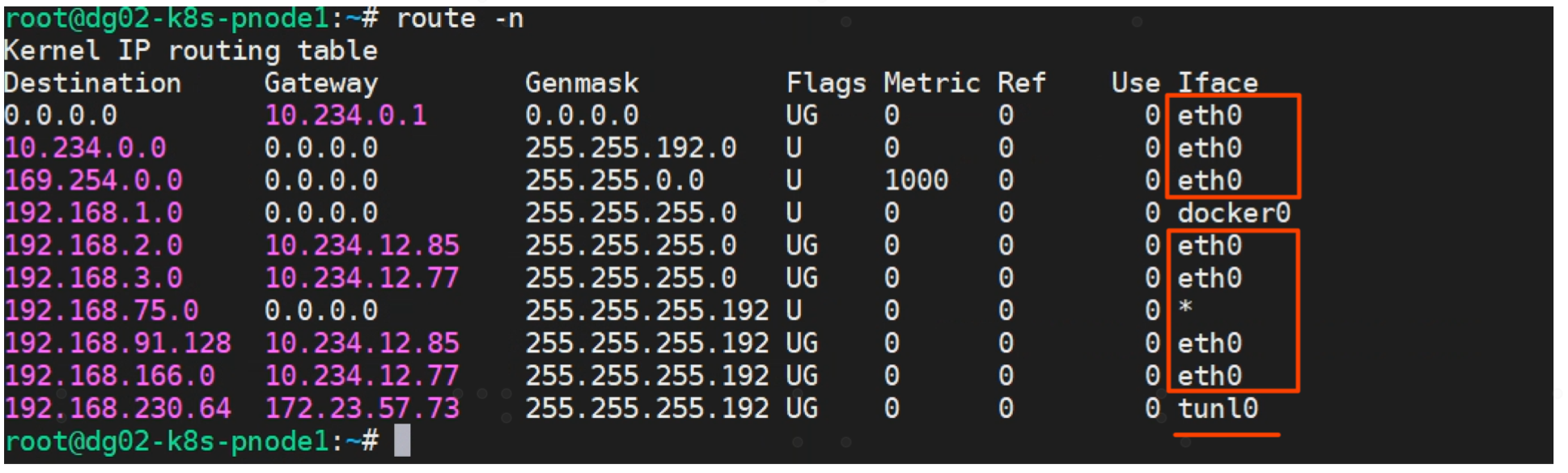
可以看到如果目的宿主10.234.12.77/85与本宿主10.234.12.78在同一网段,那么使用的是直接路由即BGP模式,如果目的宿主172.23.67.73与本宿主10.234.12.78不在同一网段,使用的IPIP模式(走的隧道tunl0)。
代理ARP
calico方案中,将veth pair一段插入pod,另一端插入宿主内核协议栈中,无需为宿主段的veth配置IP,也无需接入bridge.借用代理arp,将pod的默认路由都转发到宿主的网络协议栈,借助宿主进行路由转发。
进入Pod,可以看到pod的默认路由是走169.254.1.1
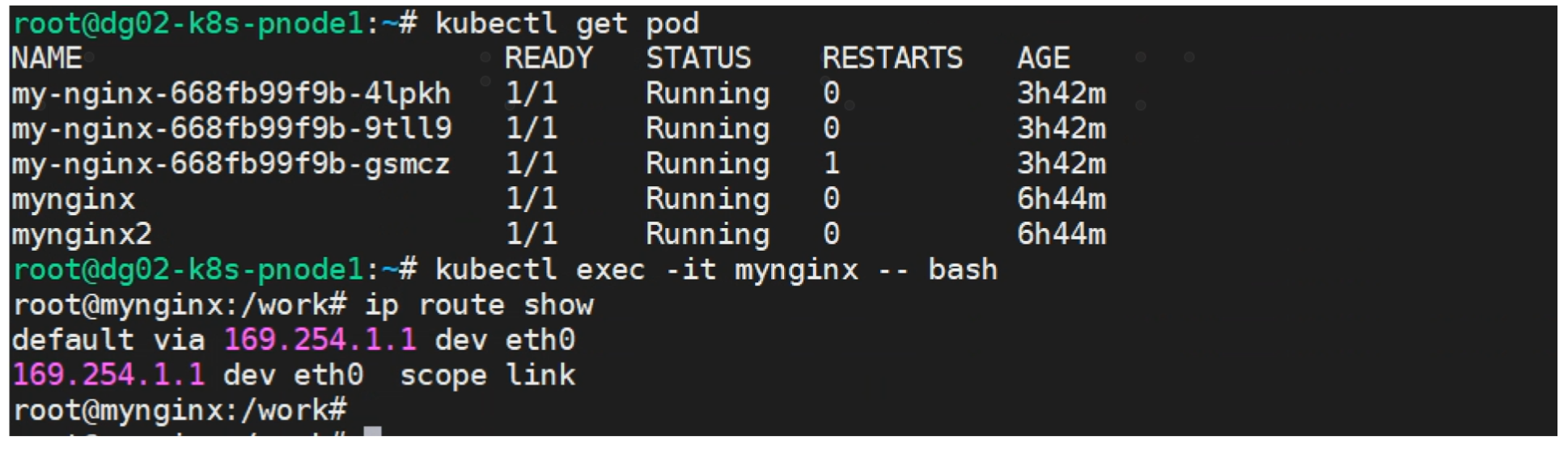
pod的mac地址
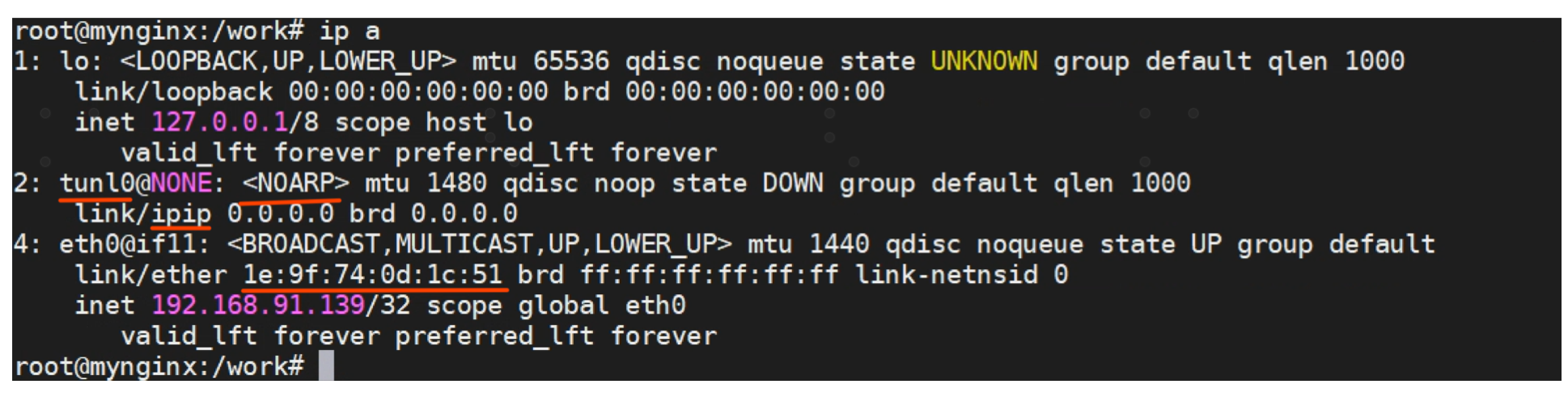
pod里面查看arp表, 169.254.1.1对应的mac是特殊的地址ee:ee:ee:ee:ee:ee

登录宿主可以看到,去往pod的接口是cali5ef7fb336ae

宿主上可以看到 cali5ef7fb336ae 没有配置IP地址

Pod 与 宿主互联的示意图
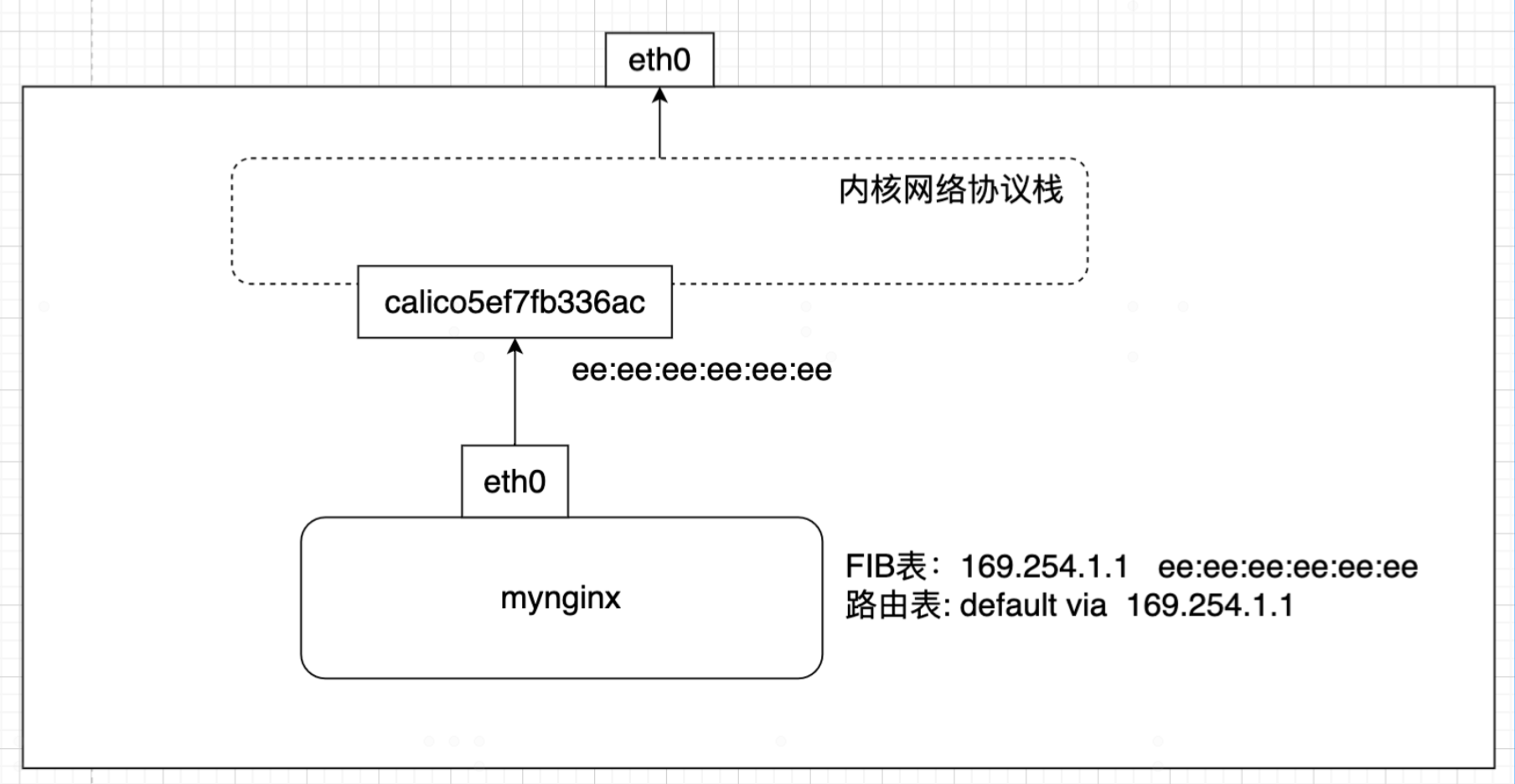
169.254.1.1 是一个特殊的 IP 。不过这里这个 IP 并不重要,只是为了防止冲突才选择了这个特殊值。当 Pod 要访问其他 IP 时,如果该 IP 在同一个网段,那就需要获取该 IP 的 MAC 地址。如果目的IP不在一个网段,那么根据路由表,就要获取网关的 IP 地址。所以无论如何,arp 请求都会到达上图中的 calico5e7fb336ac。因为宿主开启了代理ARP功能 proxy_arp=1,所以宿主就会返回自己的 MAC 地址ee:ee:ee:ee:ee:ee,然后 Pod 的流量就发到了主机的网络协议栈。到达网络协议栈之后,被可以被宿主转发到对端的主机上。
calico路由反射器
为何需要路由反射器
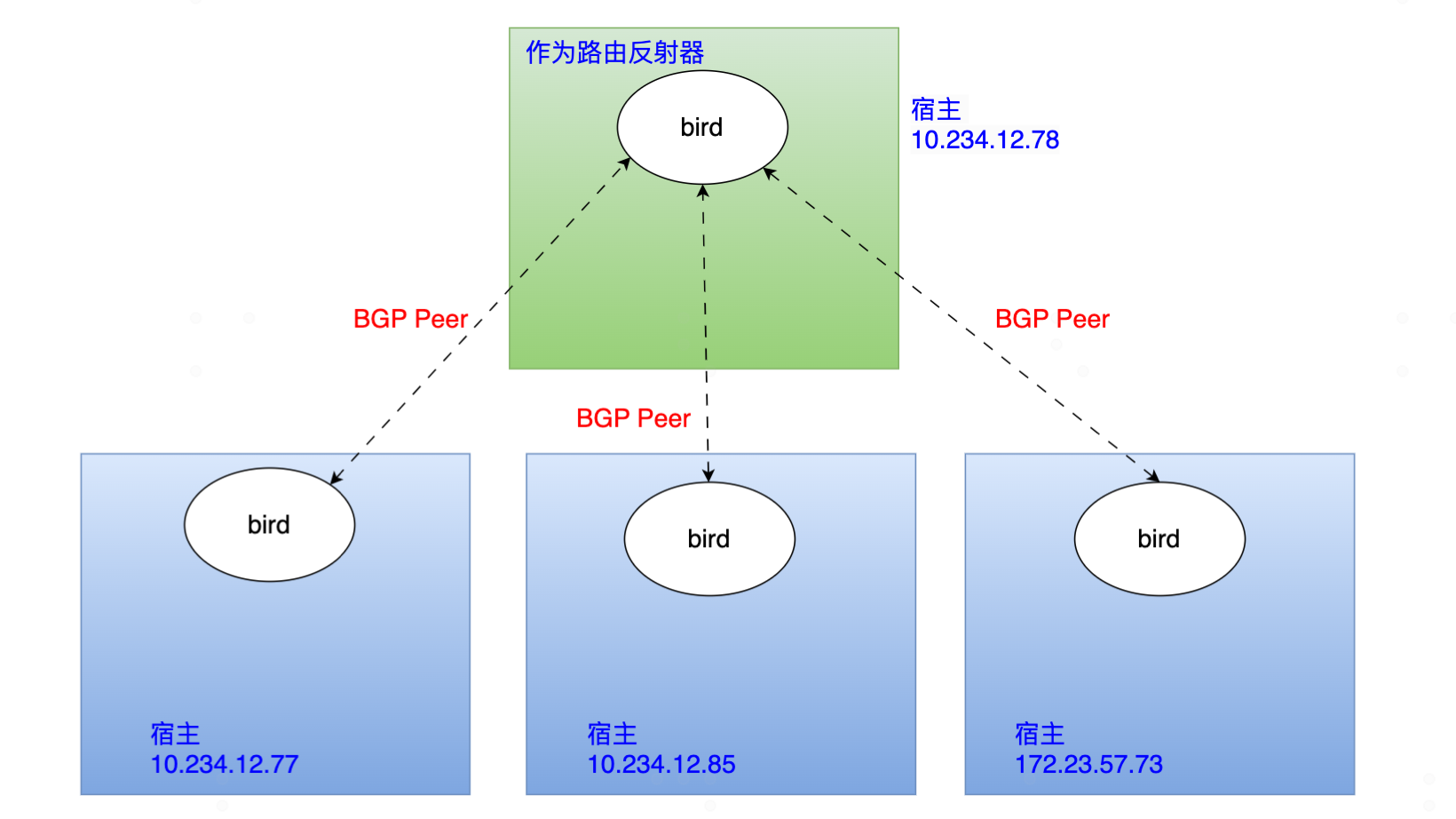
默认情况下calico的BGP建立 peer 关系是node to node mesh,见下图PEER TYPE。Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。确定一个或多个Calico节点充当路由反射器,让其他节点从这个RR节点获取路由信息。
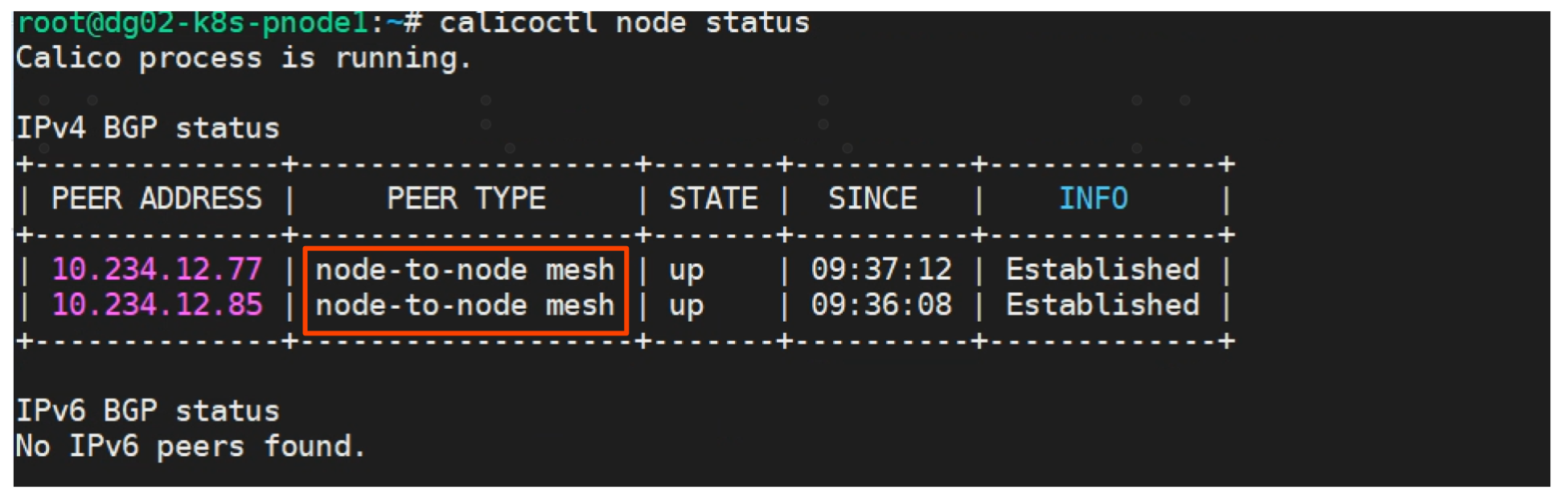
路由反射器的实战
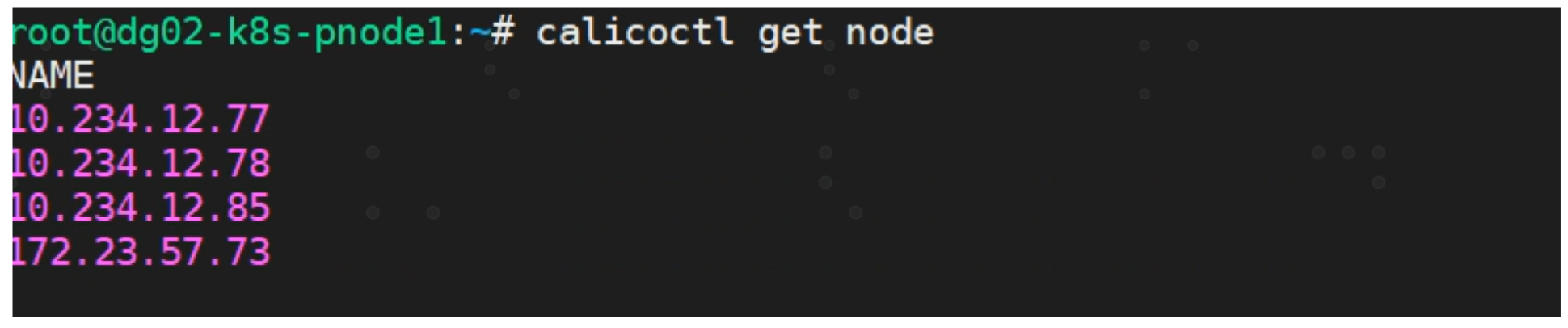
实验环境有4个 calico node节点。 默认情况下,他们使用 node to node mesh 即全互联模式。我们的目标是使用10.234.12.78选做一台路由反射器RR。RR会与其他所有calico node 建立BGP peer, 而calico node 只会与 RR 建立 BGP Peer关系。
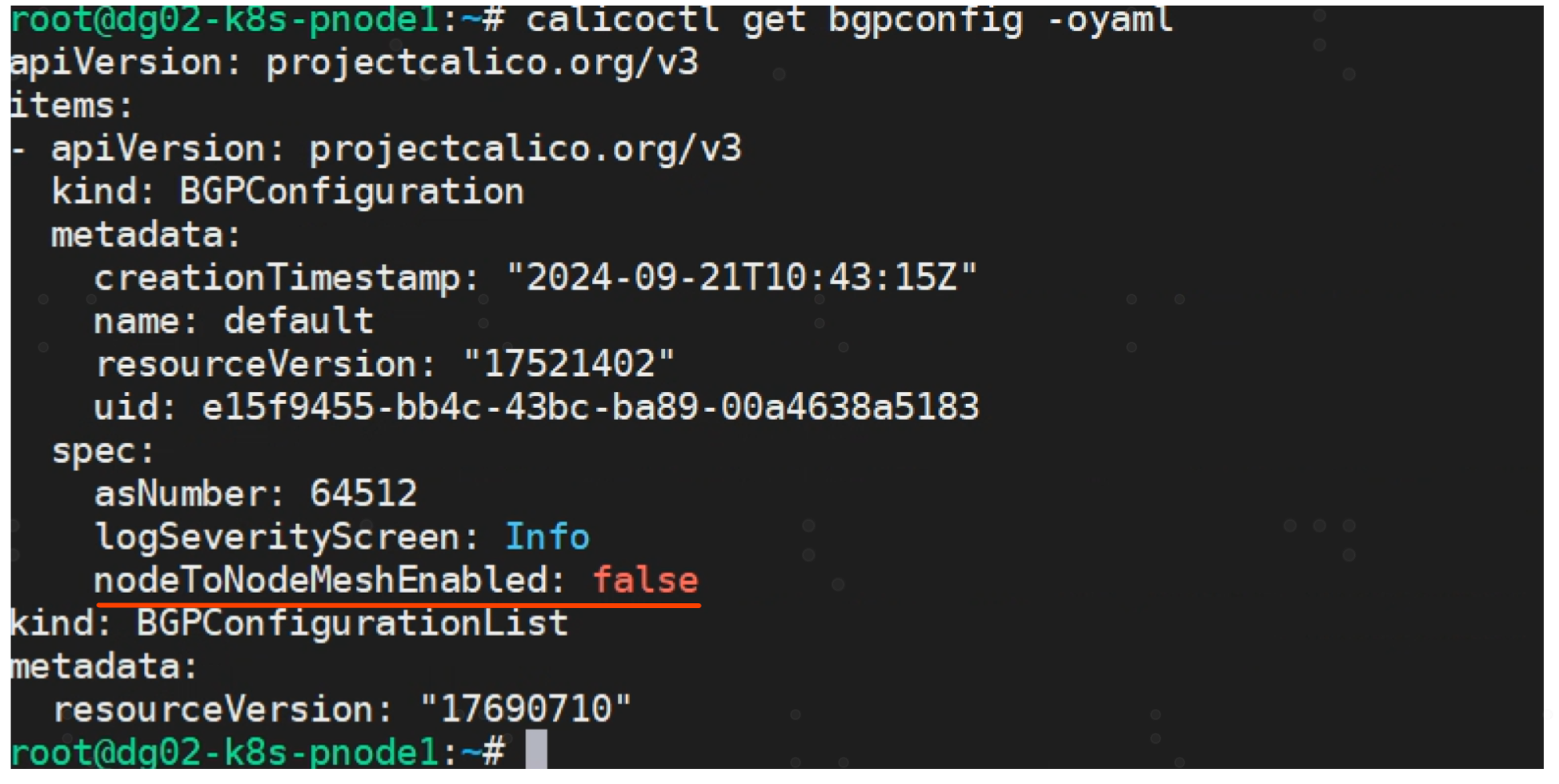
1) 先禁用nodetonode mesh模式,将nodeToNodeMeshEnabled对应值改为false
$ cat << EOF | calicoctl create -f -
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
logSeverityScreen: Info
nodeToNodeMeshEnabled: false
asNumber: 64512
EOF
2) 配置 BGP node 与 Route Reflector 的连接建立规则
$ cat << EOF | calicoctl create -f -
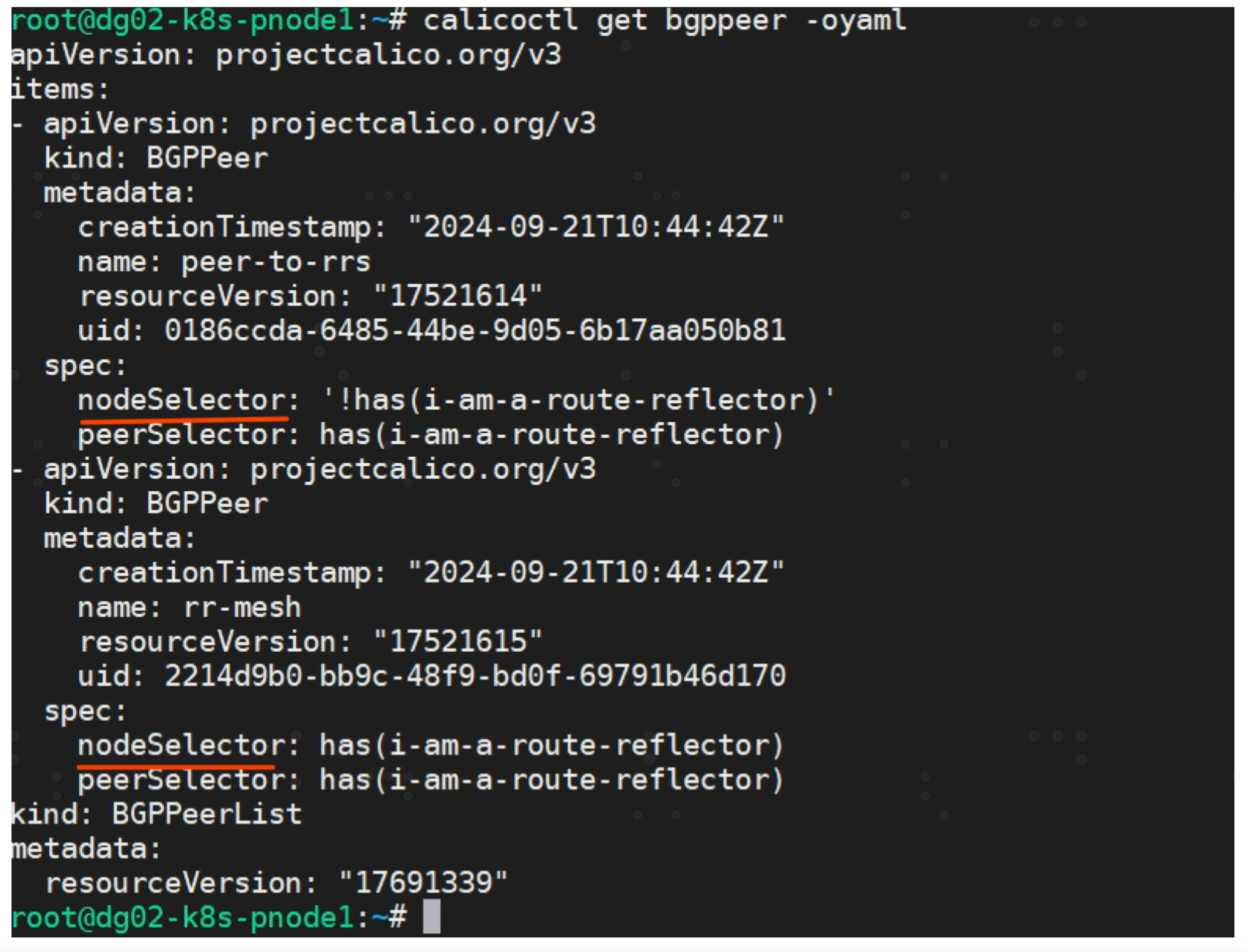
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: peer-to-rrs
spec:
# 规则1:普通 bgp node 与 rr 建立连接
nodeSelector: "!has(i-am-a-route-reflector)"
peerSelector: has(i-am-a-route-reflector)
---
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: rr-mesh
spec:
# 规则2:route reflectors 之间也建立连接
nodeSelector: has(i-am-a-route-reflector)
peerSelector: has(i-am-a-route-reflector)
EOF
nodeSelector 表示这个规则针对谁生效的。
peerSelector 表示与谁建立peer关系
3) 选择并配置 Route Reflector 节点
Save the node YAML.
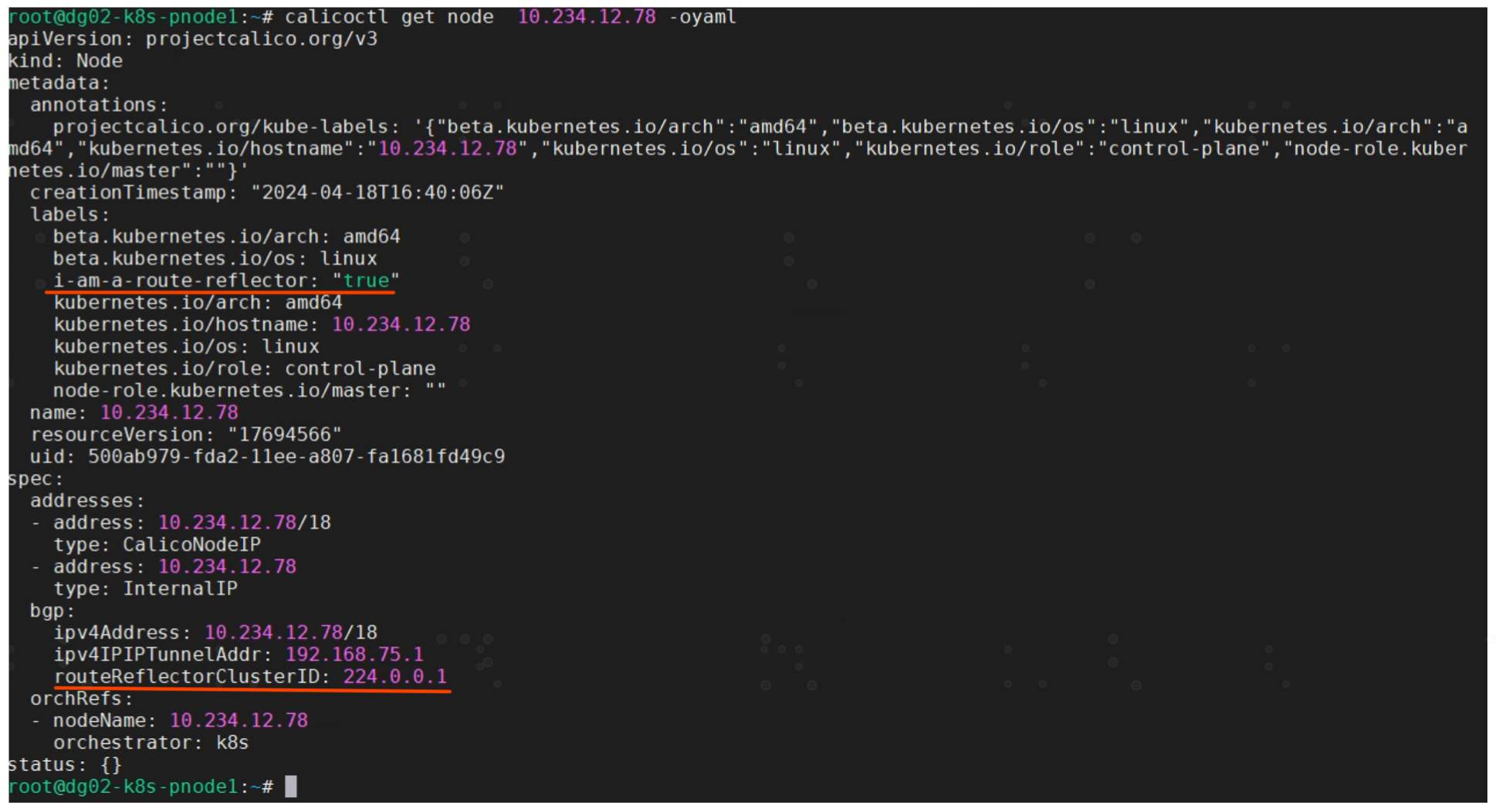
$ calicoctl get node 10.234.12.78 -o yaml --export > node.yaml
Edit the YAML to add
metadata:
labels:
# 设置标签, 表示本节点作为 rr 角色
i-am-a-route-reflector: true
spec:
bgp:
# 设置集群ID
routeReflectorClusterID: 224.0.0.1
Reapply the YAML
$ calicoctl apply -f node.yaml
Reapply 之后查询 calico node 信息。
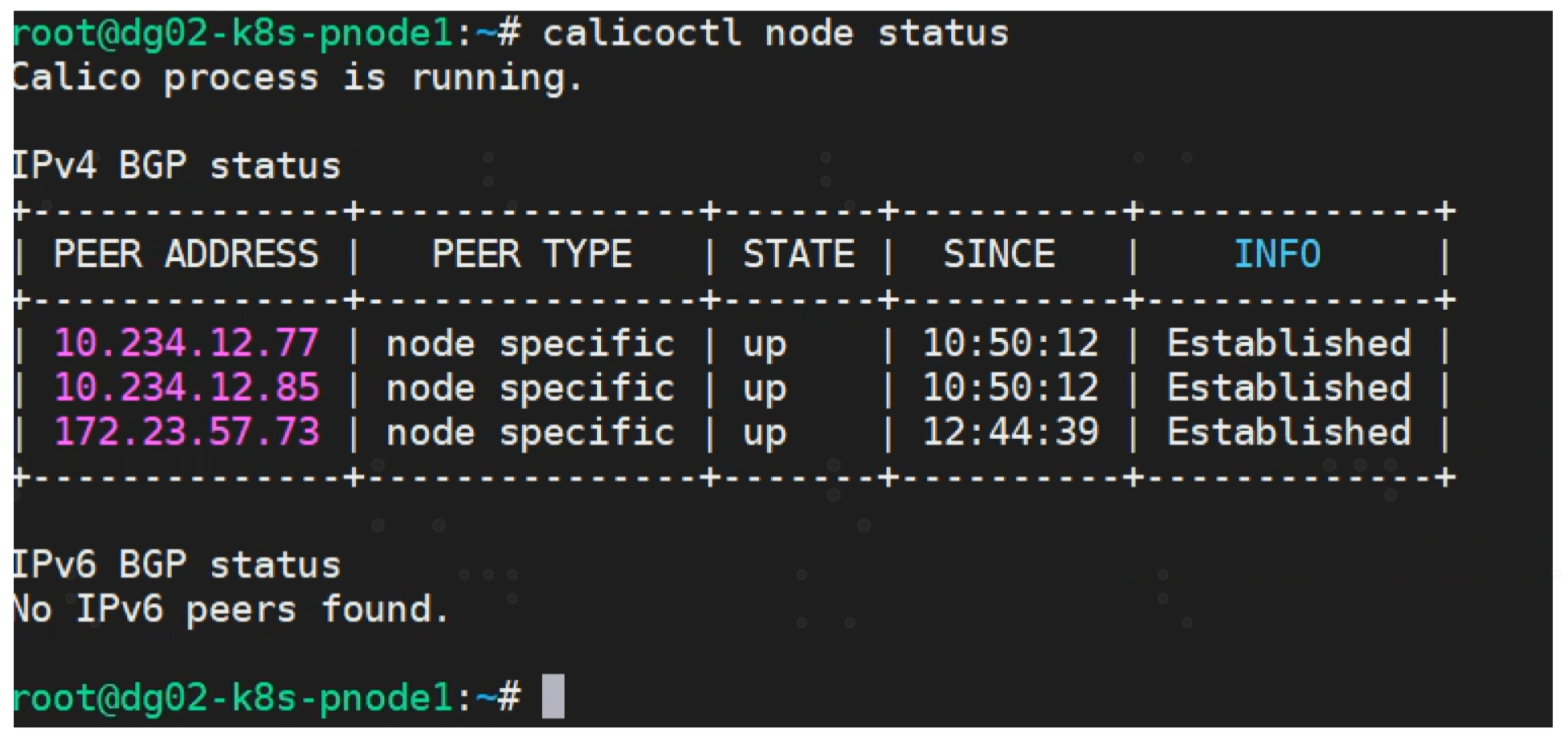
4) 确认 RR peer 状态
当完成使用路由反射器建立BGP邻居关系后,PEER TYPE 将显示为 “node specific”,下图是RR上执行命令结果,可以看到 RR 与 其他calico node 都建立了 PEER关系。
另一台calico node 只与 RR 建立 PEER关系
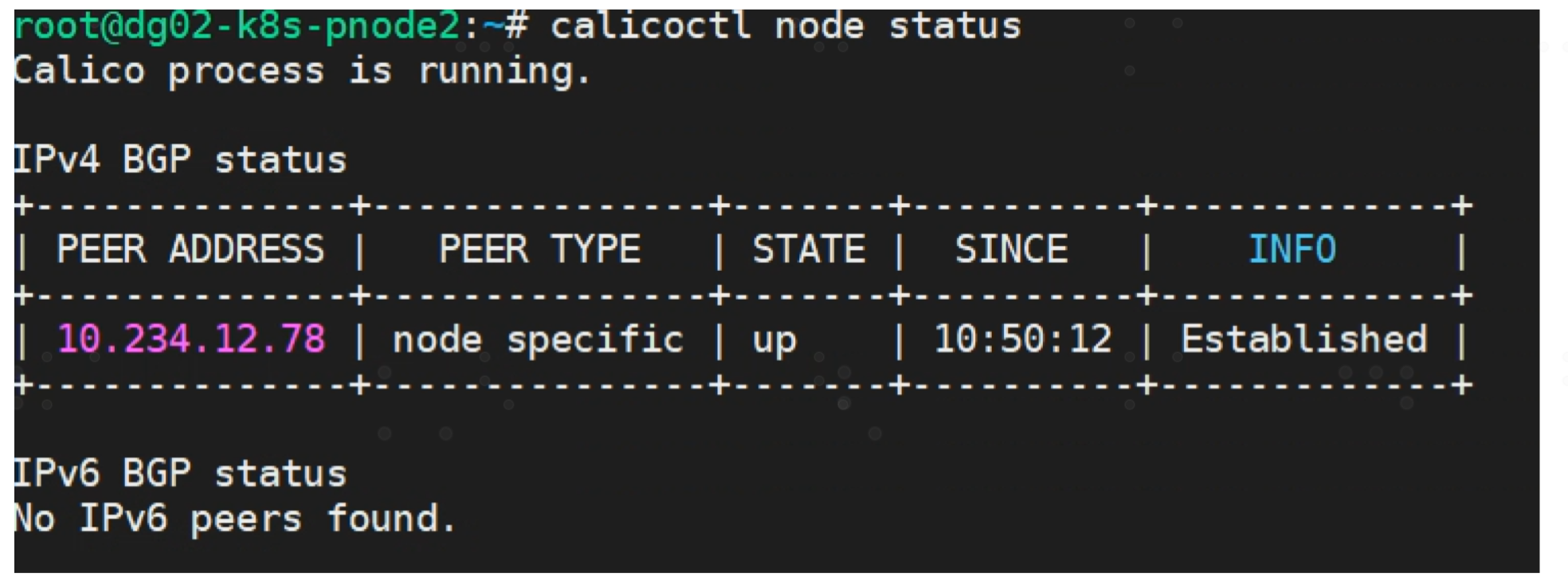
另一台calico node 只与 RR 建立 PEER关系
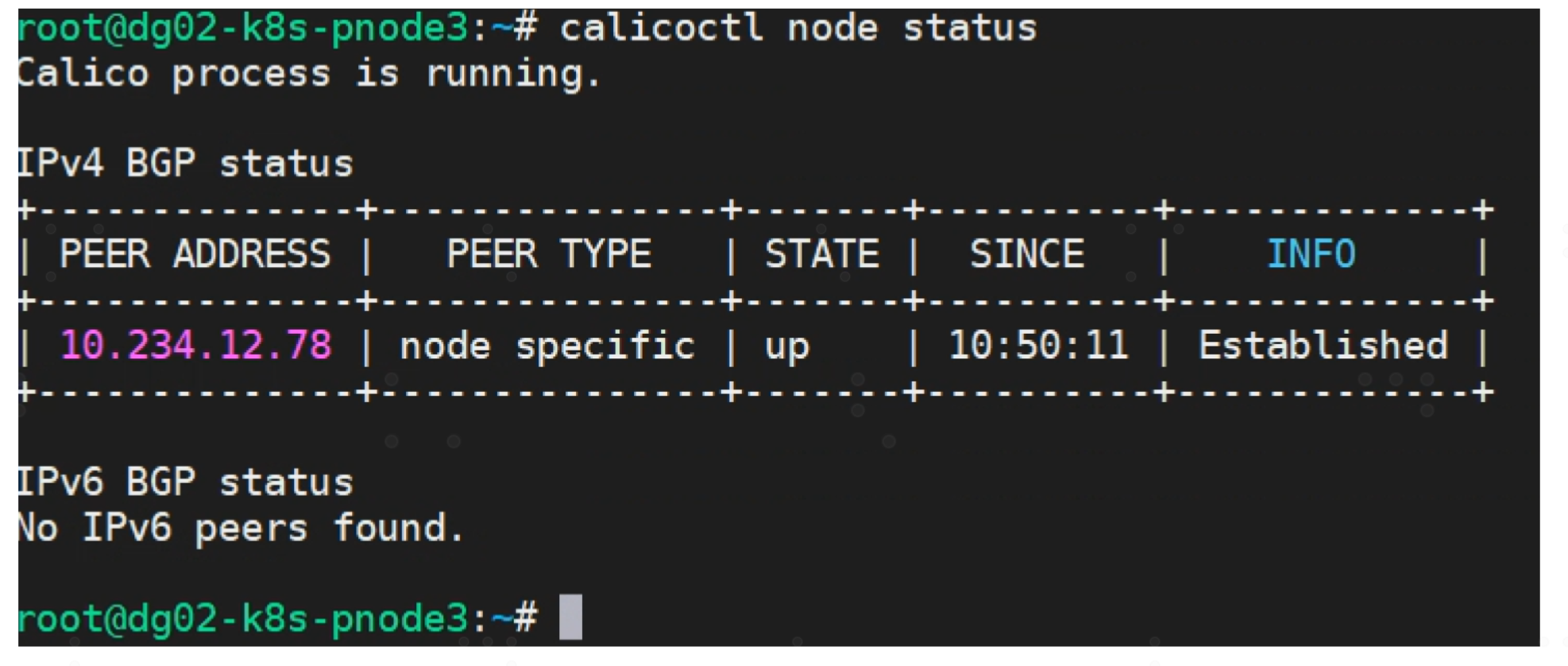
RR 上查看 BGPPEER

说明:对于生产环境为了保证高可用性,在节点数较多的K8S集群建议配置3-4个 RR 节点。
关于路由反射器的使用,还可详解官方文档configure-bgp-peering
补充
calicoctl的安装与使用
- 安装 calicoctl
curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.14.2/calicoctl
chmod +x calicoctl
mv calicoctl /usr/local/bin/
- 设置 calicoctl 配置文件
# 设置 calicoctl 配置文件
$ vim /etc/calico/calicoctl.cfg
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "kubernetes"
kubeconfig: "/path/to/.kube/config"
# pod 的网络endpoints
$ calicoctl get workloadendpoints
# 查看 calico 节点
$ calicoctl get nodes
# 查看 IPAM的IP地址池以及IPIP模式
$ calicoctl get ippool -o wide
# 查看 calico node 详细信息
$ calicoctl get node -oyaml
# 查看bgp网络配置情况, 可调整是否启用路由反射器
$ calicoctl get bgpconfig -oyaml
# 查看ASN号,一个编号就是一个自治系统
$ calicoctl get nodes -owide
# 查看 bgp peer
$ calicoctl get bgppeer
详情可参考calicao官网config calicoctl
为何BGP模式下要求宿主在同一个二层域内
在同一个二层域内的宿主,可以通过mac地址通信,无需借助三层路由器中转数据包。
假设两台宿主分别连接到一个三层路由器,注意三层路由器具有二层和三层能力,这里特别说明下,这里三层交换机划分了2个二层域,也就是2个网段,一个网段连接宿主1,一个网段连接宿主2。
两个宿主上运行calico,使用BGP模式。宿主之间建立BGP Peer,因为BGP建立邻居关系是通过TCP,所以即使两个宿主在不同网段也是可以建立BGP Peer的。所以宿主1与宿主2也能相互学习到对方”下挂“的容器所在网段。当完成路由学习后,两宿主与交换机的路由表如上图。
- 下面我们看看POD A访问POD C会出现什么问题。
-
POD A访问 POD C,数据包如下:
|目的IP=192.168.2.10|源IP=192.168.1.10| DATA |
-
POD A发现目的IP所在网段与自己不是同一网段,所以POD A把数据包交给宿主1,宿主1由于之前通过BIRD学习到目的IP在宿主2,通俗的说即要去往192.168.2.0/24网段,下一跳是172.16.2.20。于是宿主1查询本地路由表,要去往172.16.2.20,需要把数据包交给三层交换机172.16.1.1。
-
交换机收到数据包后,查询数据包的目的IP是192.168.2.20,这时问题来了,由于三层交换机没有通过路由协议与宿主2进行路由交换路由信息,所以交换机不知道192.168.2.0/24网段是需要去往宿主2。这时交换机由于从自己路由表匹配到目标网段。所以
被迫选择0.0.0.0作为下一跳,于是将数据包错误地发往核心网络中。最终导致了数据包无法到达POD C。
- 那么问题又来了,如何解决这种问题呢?
方法一: 将交换机参与与宿主之间的BGP路由交换,交换机就可以学习到宿主下的容器网段。这种方法也就是把kubernetes的容器网段同步内网中去,所以要求kubernetes的网段得整体规划,不能与现有内网网段冲突,如下图所示。想要具体如何实现可参考文档:使用Calico的BGP发布Kubernetes Service IP路由
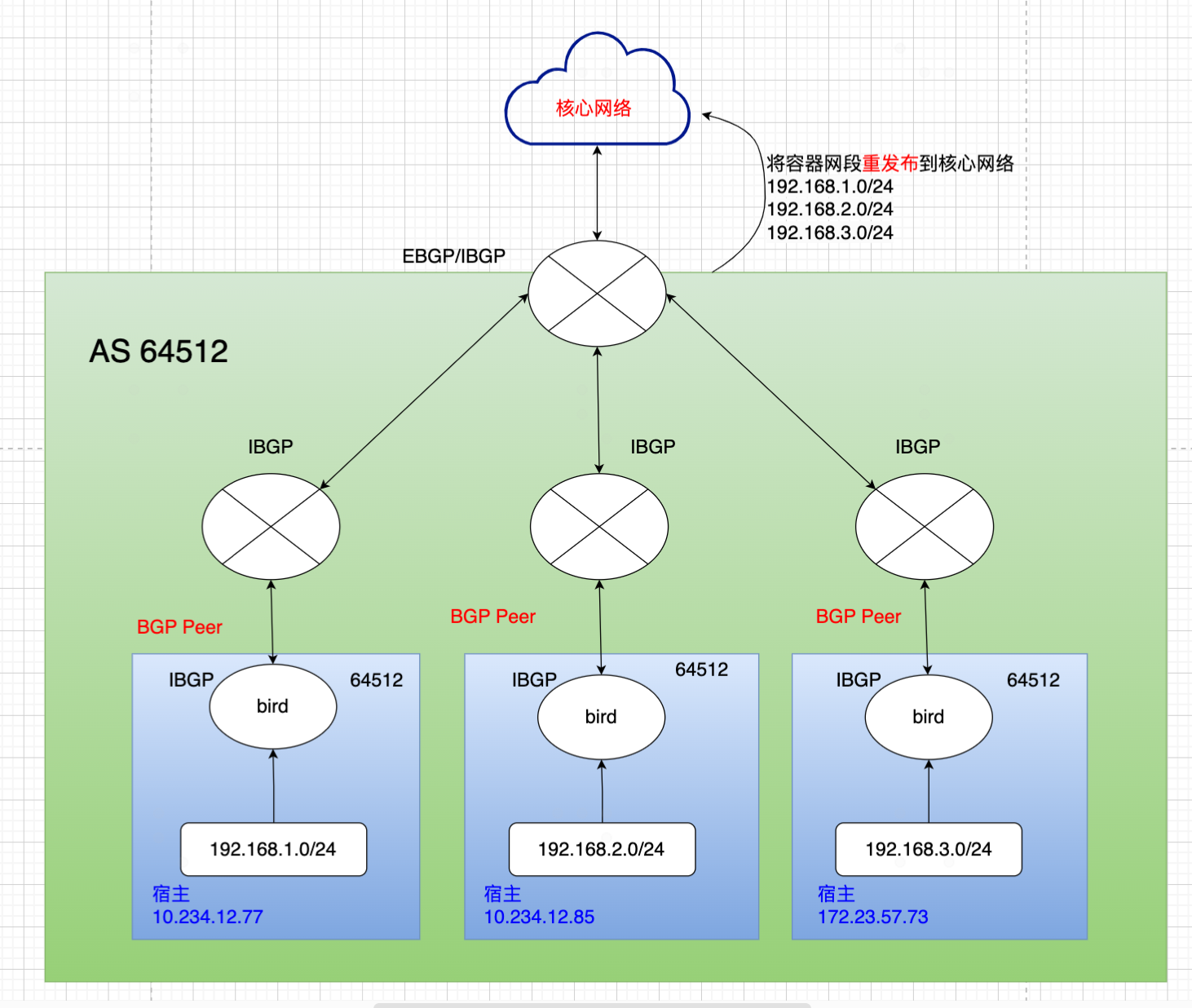
方法二:改用IPIP模式。即数据包到达宿主1后,calico的IPIP模式,会将数据包进行封装,在原数据包基础上加一层IP包头。封装后的IP包如下:
|外层目的IP=172.16.2.20|外层源IP=172.16.1.10|目的IP=192.168.1.10|源IP=192.168.2.10| DATA |
这样经过封装后,交换机收到数据包后,查询看外层目的IP是172.16.2.20,于是就能将数据包发到宿主2,宿主2收到数据包,先将数据包接封装,解封装后里层的数据包的目的IP是192.168.2.20,于是就能将数据包发往POD C。