使用 Pandas 进行数据可视化
使用Pandas进行数据可视化是以图形格式呈现数据。它通过以简单易懂的格式总结和呈现大量数据来帮助人们理解数据的重要性,并有助于清晰有效地传达信息。在本教程中,我们将探讨如何利用 Pandas 创建各种类型的图表,使您的数据分析更加直观和富有洞察力。
使用 Pandas 进行数据可视化
目录
- 安装 Pandas 进行数据可视化
- 使用 Python 进行 Pandas DataFrame 绘图
- 使用 Python 自定义 Pandas 图
- 使用 Pandas 可视化分组和分面图
- 使用 Pandas 可视化处理大型数据集
引入 Pandas 进行数据可视化
Pandas 是一个功能强大的 Python 开源数据分析和处理库。它提供了无缝处理结构化数据所需的数据结构和函数。该库特别适合处理标记数据,例如具有行和列的表格,这使其成为数据科学界的必备工具。
Pandas 数据可视化的主要特点:
Pandas 提供了多种功能,使其成为数据可视化的绝佳选择:
- 多种绘图类型:Pandas 支持多种绘图类型,包括线图、条形图、直方图、箱线图和散点图,满足不同的可视化需求。
- 定制:用户可以通过添加标题、标签和样式来定制图表,增强可视化的可读性和美感。
- 缺失数据处理:Pandas 可以有效地处理缺失数据,确保可视化准确地表示数据集而没有错误。
- 与 Matplotlib 集成:Pandas 与 Matplotlib 无缝集成,允许用户创建各种静态、动画和交互式图表。
安装 Pandas 进行数据可视化
在深入研究数据可视化之前,请确保已安装 Pandas。你可以使用 pip 安装它:
pip install pandas

安装 Pandas 进行数据可视化
使用 Python 进行 Pandas DataFrame 绘图
要使用 Pandas 执行基本绘图,我们可以利用内置 方法,它是 Matplotlib 绘图函数的包装器。您也可以直接调用 df.plot(kind='hist') 或将该 kind 参数替换为上面列表中显示的任何关键术语(例如“box”、“barh”等)。让我们开始通过示例进行介绍:plot()
将数据加载到 Pandas 中
在本教程中,让我们创建一个简单的 DataFrame 来使用(注意:线图的数据框会有所不同)
Python
import pandas as pd
# Defining the data as a dictionary, including the missing rows with made-up values
data = {
'Column1': [0.039762, 0.937288, 0.780504, 0.672717, 0.053829,
0.845678, 0.123456, 0.987654, 0.543210, 0.876543,
0.234567, 0.654321, 0.345678, 0.789012, 0.456789,
0.723456, 0.234567, 0.876543, 0.123456, 0.543210],
'Column2': [0.218517, 0.041567, 0.008948, 0.247870, 0.520124,
0.354321, 0.678912, 0.012345, 0.789012, 0.345678,
0.901234, 0.234567, 0.345678, 0.456789, 0.567890,
0.189234, 0.456789, 0.012345, 0.901234, 0.345678],
'Column3': [0.103423, 0.899125, 0.557808, 0.264071, 0.552264,
0.789012, 0.456789, 0.123456, 0.234567, 0.345678,
0.567890, 0.678901, 0.789012, 0.890123, 0.901234,
0.612378, 0.345678, 0.765432, 0.234567, 0.876543],
'Column4': [0.957904, 0.977680, 0.797510, 0.444358, 0.190008,
0.876543, 0.234567, 0.345678, 0.456789, 0.567890,
0.678901, 0.789012, 0.890123, 0.901234, 0.123456,
0.876543, 0.901234, 0.543210, 0.876543, 0.123456]
df = pd.DataFrame(data)
1. 基本线图
线图是一种沿数轴显示数据频率的图表。当数据为时间序列时,最好使用线图。这是一种快速、简单的数据组织方法。
语法是:df.plot.line
Python
import pandas as pd
import matplotlib.pyplot as plt
data = {
'Year': [2015, 2016, 2017, 2018, 2019, 2020],
'Sales': [200, 250, 300, 350, 400, 450],
'Profit': [20, 30, 50, 70, 90, 110]
}
df = pd.DataFrame(data)
# Plotting both Sales and Profit over the years
ax = df.plot(x='Year', y='Sales', kind='line', marker='o', title='Sales and Profit Over Years')
df.plot(x='Year', y='Profit', kind='line', marker='s', ax=ax, secondary_y=True)
# Adding labels and grid
ax.set_ylabel('Sales')
ax.right_ax.set_ylabel('Profit')
ax.grid(True)
plt.show()
输出 :
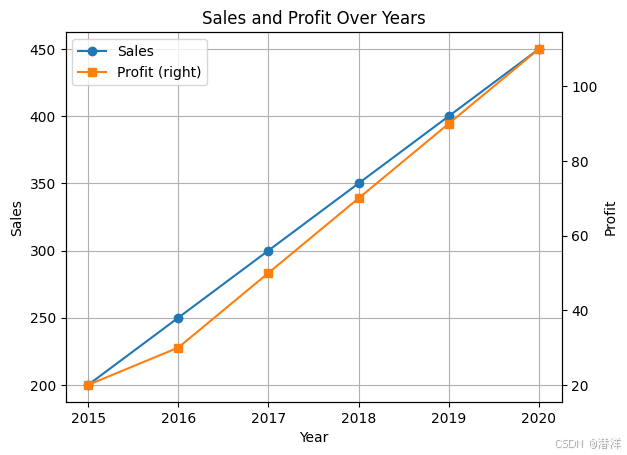
使用 Pandas 绘制线图
2. 条形图
条形图或条形图是一种图表或图形,它使用矩形条来呈现分类数据,矩形条的高度或长度与其所代表的值成比例。条形图可以垂直或水平绘制。垂直条形图有时称为折线图。
Python
df.plot.bar()
输出:
使用 Pandas 绘制条形图
我们还可以创建堆积条形图。堆积条形图是可视化分为不同类别的数据的绝佳方式。
- 它们可以让您看到类别的总体规模以及每个子类别的贡献。
- 每个条形的高度反映子类别的累计总数。
Python
df.plot.bar(stacked=True)
输出 :

堆叠条形图
3. 面积图
面积图或区域图以图形方式显示定量数据。它基于折线图。轴和线之间的区域通常用颜色、纹理和阴影线来强调。通常使用面积图比较两个或多个数量。
Python
df.plot.area(alpha=0.4)
输出 :
面积图
4.密度图-核密度估计(KDE)
要在 Pandas 中创建密度图,您可以使用 plot.kde() 或 plot.density() 方法,它们本质上可以互换,并使用核密度估计 (KDE) 来估计随机变量的概率密度函数 (PDF)。
KDE 是一种让您根据一组数据创建平滑曲线的技术。
- 如果您只想可视化某些数据的“形状”,这将很有用,作为离散直方图的一种连续替代。
- 它还可用于生成看起来像来自某个数据集的点——这种行为可以为简单的模拟提供动力,其中模拟对象是根据真实数据建模的。
Python
df['a'].plot.kde()
输出 :
核密度估计 (KDE) 图
示例:密度图
Python
df.plot.density()
输出 :
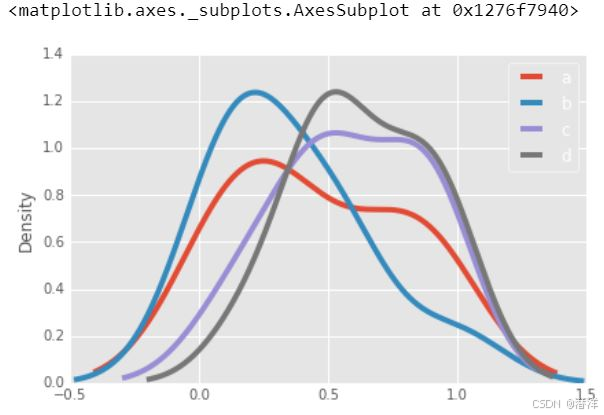
密度图
5. 使用 Pandas DataFrame 绘制直方图
直方图是一种让您发现并显示一组连续数据的基本频率分布(形状)的图。这允许检查数据的底层分布(例如正态分布)、异常值、偏度等。
Python
df['A'].plot.hist(bins=50)
输出 :
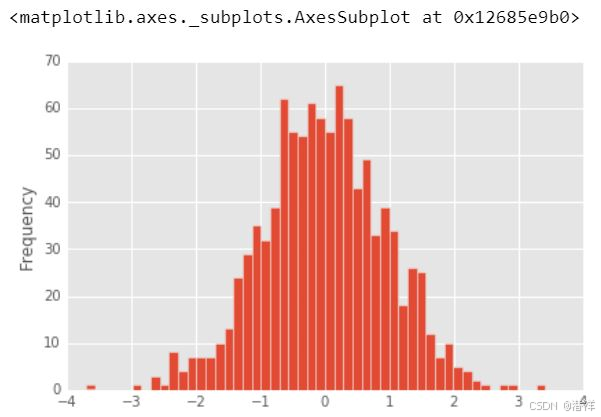
直方图
6.散点图
当您想要显示两个变量之间的关系时,可以使用 散点图。散点图有时也称为相关图,因为它们显示两个变量如何相关。
Python
df.plot.scatter(x='A', y='B')
输出 :
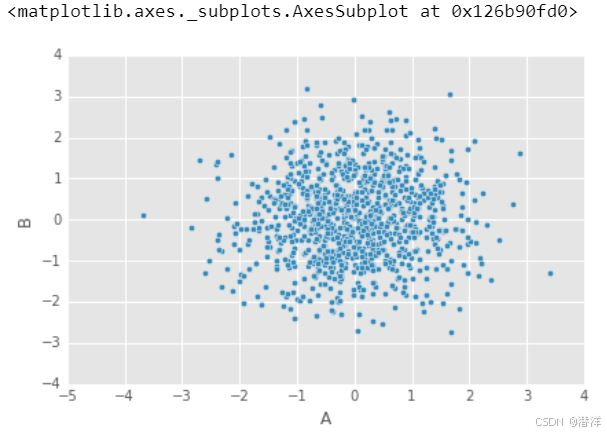
散点图
为了定制,我们可以使用 s 来指示基于另一列的大小。s参数需要是一个数组,而不仅仅是列的名称:
Python
df.plot.scatter(x ='A', y ='B', s = df1['C']*200)
输出 :
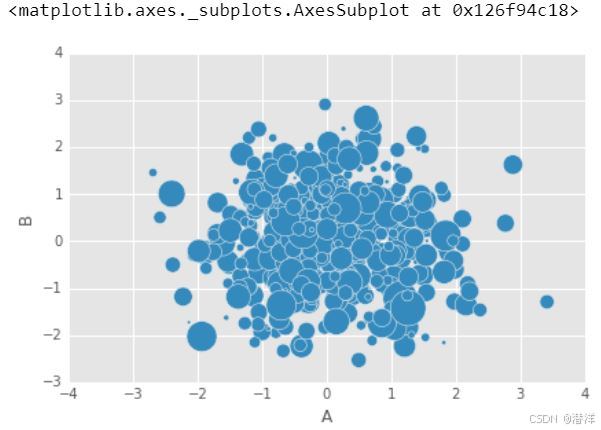
7. 使用 Pandas 绘制箱线图
箱线图是一种基于五数汇总(“最小值”、第一四分位数 (Q1)、中位数、第三四分位数 (Q3) 和“最大值”)显示数据分布的标准化方法。它可以告诉您异常值及其值。它还可以告诉您数据是否对称、数据分组的紧密程度以及数据是否以及如何倾斜。
Python
df.plot.box() # Can also pass a by = argument for groupby
输出:
箱线图
8. 六边形箱图
六边形分箱是另一种解决过多点开始重叠问题的方法。六边形分箱绘制的是密度,而不是点。
- 将点分成网格六边形,并使用六边形的颜色或面积显示分布(每个六边形的点数)。
- 适用于双变量数据,散点图的替代品。
Python
df = pd.DataFrame(np.random.randn(1000, 2), columns =['a', 'b'])
df.plot.hexbin(x ='a', y ='b', gridsize = 25, cmap ='Oranges')
输出 :
六边形图
使用 Python 自定义 Pandas 图
要使用各种技术(例如添加标题、标签和应用样式表)自定义 Pandas 中的图表,您可以直接使用 Pandas 的绘图功能,这些功能建立在 Matplotlib 之上。这样,您就可以在 Pandas 框架内工作时充分利用 Matplotlib 的样式和自定义选项的强大功能。
在 Pandas 中自定义绘图:
- 添加标题和标签:这可以增强可视化的清晰度和上下文。
- 使用样式表:应用样式表可以提高多个图表的一致性和可读性。
1. 添加标题和标签
- 添加标题和标签:在 Pandas 中,您可以使用方法 中的参数 轻松地为您的图表添加标题 。titleplot
- 轴标签:在 Pandas 中,您可以使用 绘图轴对象上的set_xlabel 和 方法设置轴标签。和分别用于标记 x 轴和 y 轴。自定义字体大小可以使标签更具可读性。set_ylabelFor adding labels, set_xlabel()set_ylabel()
以下是如何向 Pandas 图添加标题和标签的示例:
Python
import pandas as pd
import matplotlib.pyplot as plt
data = {
'Year': [2015, 2016, 2017, 2018, 2019, 2020],
'Sales': [200, 250, 300, 350, 400, 450],
'Profit': [20, 30, 50, 70, 90, 110]
}
df = pd.DataFrame(data)
ax = df.plot(x='Year', y='Sales', kind='line', title='Sales Over Years', legend=True, marker='o')
# Adding title and axis labels
ax.set_title('Sales and Profit Over Years', fontsize=14, fontweight='bold')
ax.set_xlabel('Year', fontsize=12)
ax.set_ylabel('Sales', fontsize=12)
plt.show()
输出:
添加标题和标签
2.添加辅助 Y 轴
使用为“利润”数据创建辅助 y 轴,允许在同一张图上表示双重数据。这有助于以不同的比例可视化两个相关的数据系列。ax.twinx()
Python
import pandas as pd
import matplotlib.pyplot as plt
# Sample DataFrame
data = {
'Year': [2015, 2016, 2017, 2018, 2019, 2020],
'Sales': [200, 250, 300, 350, 400, 450],
'Profit': [20, 30, 50, 70, 90, 110]
}
df = pd.DataFrame(data)
ax = df.plot(x='Year', y='Sales', kind='line', title='Sales Over Years', legend=True, marker='o')
# Adding a secondary y-axis for Profit
ax2 = ax.twinx()
df.plot(x='Year', y='Profit', kind='line', ax=ax2, color='r',legend=False, marker='s')
ax2.set_ylabel('Profit', fontsize=12)
plt.show()
输出:
带次轴
3. 使用 Pandas 进行其他自定义
要使用 Pandas 进一步自定义绘图,您可以利用其他功能,例如调整线条样式、设置颜色、修改绘图大小、添加网格线、自定义刻度线等。让我们通过直接使用 Pandas 的绘图功能进行更多自定义来扩展之前提供的示例。
- 改变线条样式和颜色:调整线条样式和颜色,使图表看起来更加清晰。
- 修改绘图大小:更改绘图大小以更好地适应演示或分析内容。
- 自定义刻度标记:自定义刻度标记以获得更好的精度和呈现效果。
- 添加注释:包括注释以突出显示特定的兴趣点。
- 更改字体属性:自定义字体以提高可读性或匹配演示风格。
Python
import pandas as pd
import matplotlib.pyplot as plt
data = {
'Year': [2015, 2016, 2017, 2018, 2019, 2020],
'Sales': [200, 250, 300, 350, 400, 450],
'Profit': [20, 30, 50, 70, 90, 110]
}
df = pd.DataFrame(data)
plt.figure(figsize=(10, 6))
# Creating a plot with more customization
ax = df.plot(
x='Year',
y='Sales',
kind='line',
linestyle='--', # Dashed line style
color='blue', # Line color
marker='o', # Circle markers
markersize=8, # Size of the markers
title='Sales and Profit Over Years',
legend=True
)
# Adding gridlines
ax.grid(which='both', linestyle='--', linewidth=0.7)
# Customizing tick marks
ax.set_xticks(df['Year']) # Set custom ticks for x-axis
ax.tick_params(axis='x', rotation=45, labelsize=12)
ax.tick_params(axis='y', labelsize=12)
ax2.tick_params(axis='y', labelsize=12)
# Adding annotations
for i, txt in enumerate(df['Sales']):
ax.annotate(txt, (df['Year'][i], df['Sales'][i]), textcoords="offset points", xytext=(0,5), ha='center', fontsize=10, color='blue')
# for i, txt in enumerate(df['Profit']):
ax2.annotate(txt, (df['Year'][i], df['Profit'][i]), textcoords="offset points", xytext=(0,5), ha='center', fontsize=10, color='red')
plt.show()
输出:
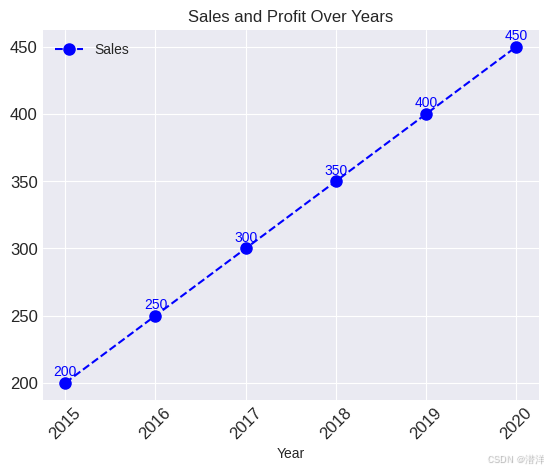
使用 Pandas 自定义绘图
通过结合这些定制,您可以使用 Pandas 创建更复杂、信息丰富的图表,从而增强可视化的可读性和美感。
使用 Pandas 可视化分组和分面图
分组和分面图是强大的可视化技术,用于比较多个类别或组中的不同数据子集。
- 分组图可让您在同一轴上可视化来自多个类别的数据,从而更容易地查看比较和趋势。
- 另一方面,多面图涉及创建一个图网格,其中每个图代表数据的一个子集,从而可以轻松地跨不同组或类别进行视觉比较。
1. 分组条形图
分组条形图允许您比较每个组的不同类别的值。
例如,如果您有不同地区和不同产品类别的销售数据,则可以使用分组条形图来可视化各地区每个产品类别的销售数据。
Python
import pandas as pd
import matplotlib.pyplot as plt
data = {
'Region': ['North', 'North', 'South', 'South', 'East', 'East', 'West', 'West'],
'Category': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'B'],
'Sales': [100, 150, 200, 250, 300, 350, 400, 450]
}
df = pd.DataFrame(data)
# Create a pivot table
pivot_df = df.pivot(index='Region', columns='Category', values='Sales')
# Plot grouped bar plot
pivot_df.plot(kind='bar', stacked=False)
plt.title('Sales by Region and Category')
plt.xlabel('Region')
plt.ylabel('Sales')
plt.show()
输出:
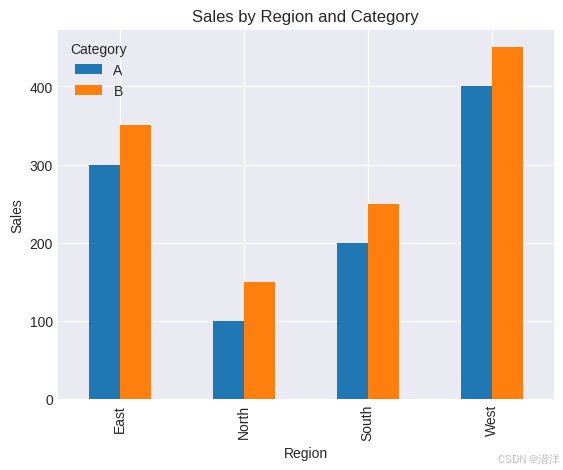
分组条形图
- 在此示例中,该pivot()函数重塑了 DataFrame,并plot(kind='bar', stacked=False)创建了分组条形图。
- 每个条形组代表不同的地区,每个组内的条形代表不同的类别。
2. 分面线图
- 多面线图允许您创建多个线图,每个线图代表基于分类变量的数据子集。
- 该技术对于可视化不同群体随时间变化的趋势或模式很有用。
Python
import pandas as pd
import matplotlib.pyplot as plt
data = {
'Date': pd.date_range(start='2024-01-01', periods=10, freq='D'),
'Sales_A': [100, 120, 150, 130, 160, 180, 200, 220, 210, 230],
'Sales_B': [90, 110, 130, 125, 155, 175, 190, 210, 205, 225],
'Category': ['A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B']
}
df = pd.DataFrame(data)
# Facet plot
categories = df['Category'].unique()
fig, axes = plt.subplots(nrows=1, ncols=len(categories), figsize=(10, 4), sharey=True)
for i, category in enumerate(categories):
subset = df[df['Category'] == category]
axes[i].plot(subset['Date'], subset['Sales_A'], label='Sales A')
axes[i].plot(subset['Date'], subset['Sales_B'], label='Sales B')
axes[i].set_title(f'Category {category}')
axes[i].set_xlabel('Date')
if i == 0:
axes[i].set_ylabel('Sales')
axes[i].legend()
plt.tight_layout()
plt.show()
输出:

多面图
在此示例中,数据集包含两个类别(“A”和“B”)随时间变化的销售数据。使用,我们为每个类别创建一个子图,以便我们比较这两个类别随时间变化的销售趋势。通过利用 Pandas 与 Matplotlib 的集成,我们可以轻松创建这些图来比较多个类别或子组、分析随时间变化的趋势并可视化分布。plt.subplots()
使用 Pandas 可视化处理大型数据集
处理大型数据集时,可视化较小的代表性样本或使用聚合数据以避免过度绘图并保持性能通常很有用。
Pandas 提供了多种有效处理大型数据集的策略。这些策略包括下采样、聚合和使用代表性样本来减少计算负荷并提高可视化的可读性。
本节将详细探讨这些技术,并提供如何在 Pandas 中实现它们的示例。
1. 使用 Pandas 进行下采样
下采样涉及对数据集进行随机抽样以可视化子集,这有助于理解总体趋势,而无需绘制每个数据点。
Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Simulate a large dataset with 1,000,000 points
np.random.seed(0)
data = {
'x': np.random.rand(1000000),
'y': np.random.rand(1000000)
}
df = pd.DataFrame(data)
# Downsample by taking a random sample of 1% of the data
df_sample = df.sample(frac=0.01)
ax = df_sample.plot.scatter(x='x', y='y', alpha=0.5, color='blue')
ax.set_title('Scatter Plot of Downsampled Data')
plt.show()
输出:
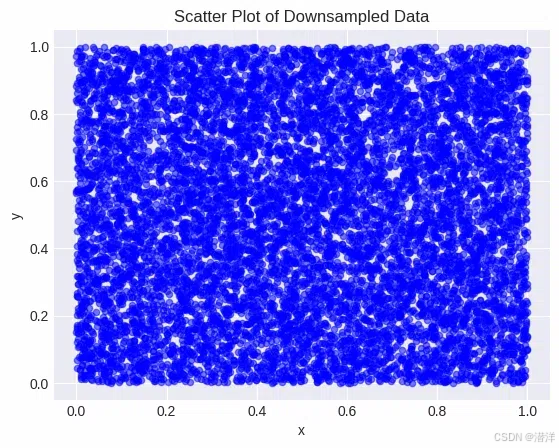
使用 Pandas 可视化处理大型数据集
在此示例中:
- 我们创建了一个包含 100 万行随机值的大型数据集。
- 我们.sample(frac=0.01)随机选择 1% 的数据进行可视化。
- 散点图是使用 Pandas 的内置plot.scatter方法创建的。
2. 使用 Pandas 进行聚合
聚合涉及通过分组和计算聚合统计数据(例如平均值、中位数或总和)来汇总数据。当您想要可视化随时间变化的趋势或分类数据中的趋势时,这尤其有用。
Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
date_range = pd.date_range(start='2024-01-01', periods=1000000, freq='T') # 1 million minutes
data = {
'timestamp': date_range,
'value': np.random.rand(len(date_range))
}
df = pd.DataFrame(data)
# Aggregate data by day and calculate the mean value for each day
df['date'] = df['timestamp'].dt.date
df_agg = df.groupby('date')['value'].mean().reset_index()
ax = df_agg.plot(x='date', y='value', kind='line', figsize=(12, 6))
ax.set_title('Daily Average Values Over Time')
ax.set_xlabel('Date')
ax.set_ylabel('Average Value')
plt.show()
输出:
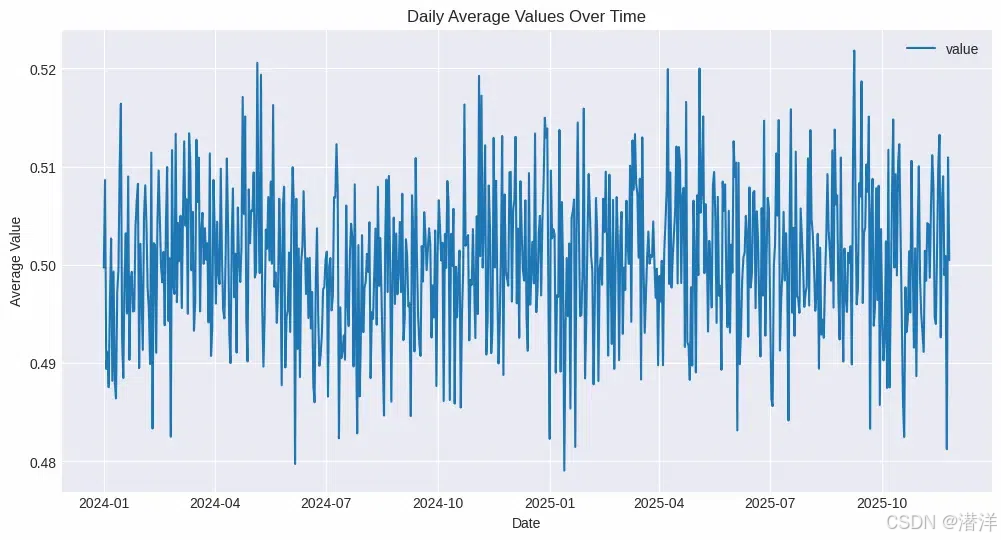
使用 Pandas 可视化处理大型数据集
在此示例中:
- 我们创建了一个包含 100 万行的时间序列数据集,代表每分钟记录的数据点。
- groupby我们按天汇总数据,使用和计算每天的平均值mean。
- 将得到的每日平均值绘制为线图,以显示随时间变化的趋势。
最后:
使用 Pandas 进行数据可视化是一种强大的工具,可以以清晰、有洞察力的方式呈现数据。通过利用 Pandas 与 Matplotlib 的集成及其内置绘图功能,您可以创建各种各样的图表来有效地探索和传达您的数据。
使用 Pandas 进行数据可视化 – 常见问题解答
Pandas 如何处理可视化中的缺失数据?
Pandas 通过在可视化中忽略缺失数据或提供填充或插入缺失值的选项来有效处理缺失数据。这可确保可视化准确表示数据集且不会出现错误。
如何将 Pandas DataFrame 可视化?
要可视化 Pandas DataFrame,请使用该df.plot()方法。该方法利用 Matplotlib 创建各种绘图类型,如线图、条形图、直方图和散点图。使用标题、标签和样式自定义绘图,以增加清晰度。
为什么 Pandas 是 Python 中数据可视化的热门选择?
Pandas 是 Python 中流行的数据可视化工具,因为它提供了一个简单的界面,可以直接从 DataFrames 创建图表。它还可以与 Matplotlib 和 Seaborn 等其他库很好地集成,使其既适用于基本可视化,也适用于复杂的可视化。
我可以用 Pandas 创建交互式图表吗?
虽然 Pandas 本身主要用于静态绘图,但它可以与 Plotly 或 Bokeh 等库结合使用,以创建交互式可视化。这些库提供了用于交互和动态数据探索的附加功能。