起因
有人反馈说SR,在系统资源还有空闲的时候,被操作系统杀掉了。没有日志,怀疑是bug,如果要解决这个bug。据说在网上查到要升级。请我准备一下升级。
质疑
StarRocks是一款分析型数据库,2021年正式开源,虽然起步晚,但是能听过且有不少应用的也不会有非常致命的问题。我觉得如果真的像上面说的,那就是比较严重的问题。但是我不认为这个反馈是对的。
现实工作中有太多事情,反馈的和实际的简直相差很大。比如有人说数据库写入慢。按说除了那种互联网大厂,一般企业的数据库什么时候写入能成为瓶颈?一去看就是insert into select 这样。而select又写的是个全表查询。所以不是insert慢,其实是查询慢。而查询通过索引或者改写正确的逻辑后,不仅不慢,反而能让反馈的人吃,怎么会这么快?
本来就是使用不当。这里我就说很多企业(除了那种互联网大厂真的没有有几千万的业务订单)好好写设计逻辑和写SQL的话,根本没有大数据的场景。还是本身没用好。
分析
本次是be进程,那么就去查be的log。因为有两次。
第一次是:看上去是访问内存错误。

第二次是:看上去应该是资源不足了。

从这个信息来看,这两次都不是一回事。
之所以第一次说是内存错误,是因为StarRocks在出问题时候做了coredump。
我也是尝试着去用gdb解析一下。得到效果如下:
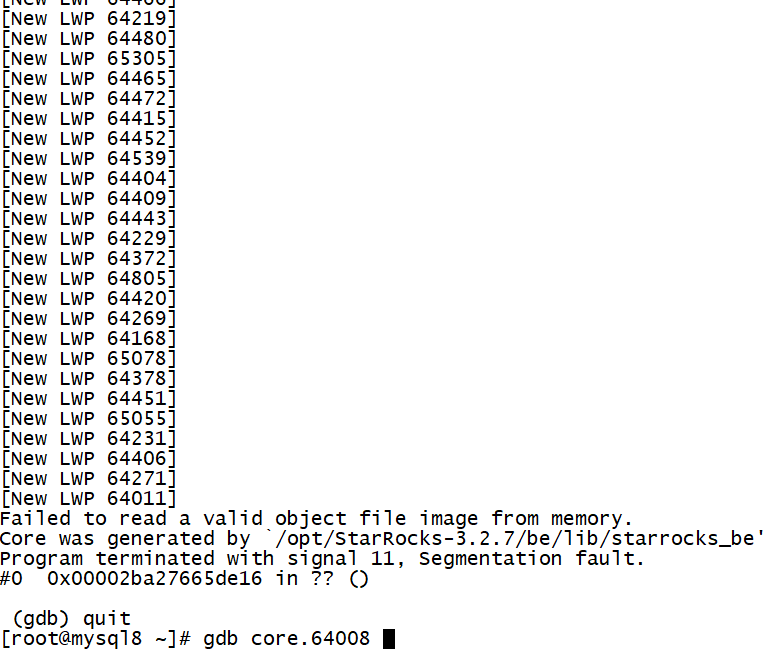
有一句结论:Failed to read a valid object file image from memory.
以我浅薄的认知,我觉得是去访问内存上遇到问题。为什么遇到问题这里遇到平时没有问题?我猜测还是应用肆无忌惮的查询,在处理过程中内存不足或者处理上出现问题。
我个人认为都是使用上不当所致。和bug关系不大。SR的使用也是有规范的。SQL的规范。
这个场景是业务人员使用托拉拽的工具访问SR,听到这里可能你就能理解。各种表和SQL在这种无代码的工具下使用就会导致SQL的低效进而引发很多问题。
低代码和无代码的区别是,低代码面向的是开发和运维人员,简化工作。
无代码面对的是业务人员,降低技术使用难度。
但是重点是,我认为降低的是使用门槛,不代表降低业务分析人员的分析门槛。
首先要具备分析师的技能和素质吧?不能什么都不懂的就是过来玩一样,指望这样碰撞出来能有什么有价值的东西吧?
印证
那么这些都已经这样报错了,还会是反馈的那样,系统没压力,SR就不工作了吗?
不是的。
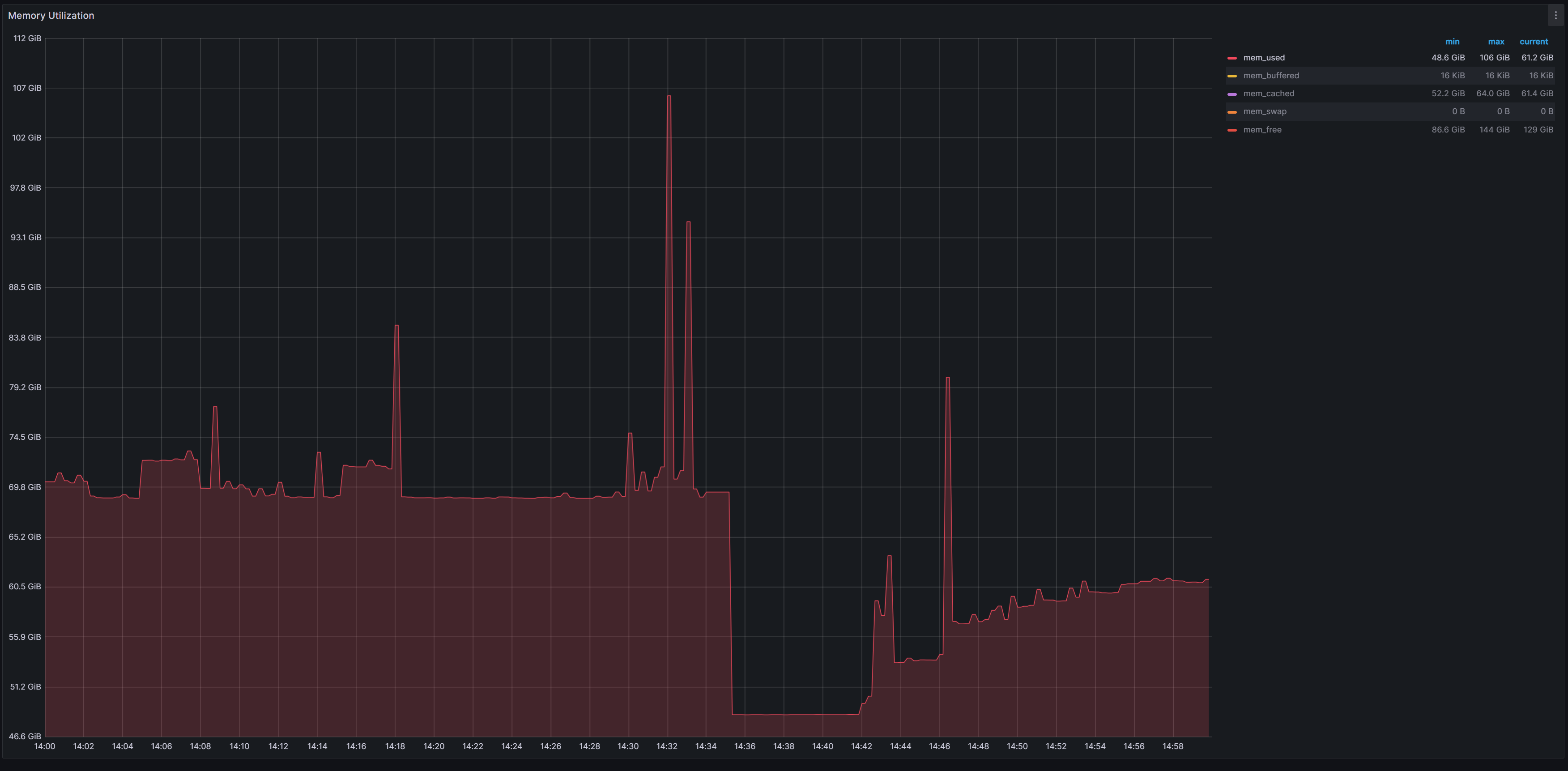
通过日志定位的时间。反查监控。这个数值还是非常震惊的。对比出问题前后和出问题之中的数据,显而易见的平坦与峰值。
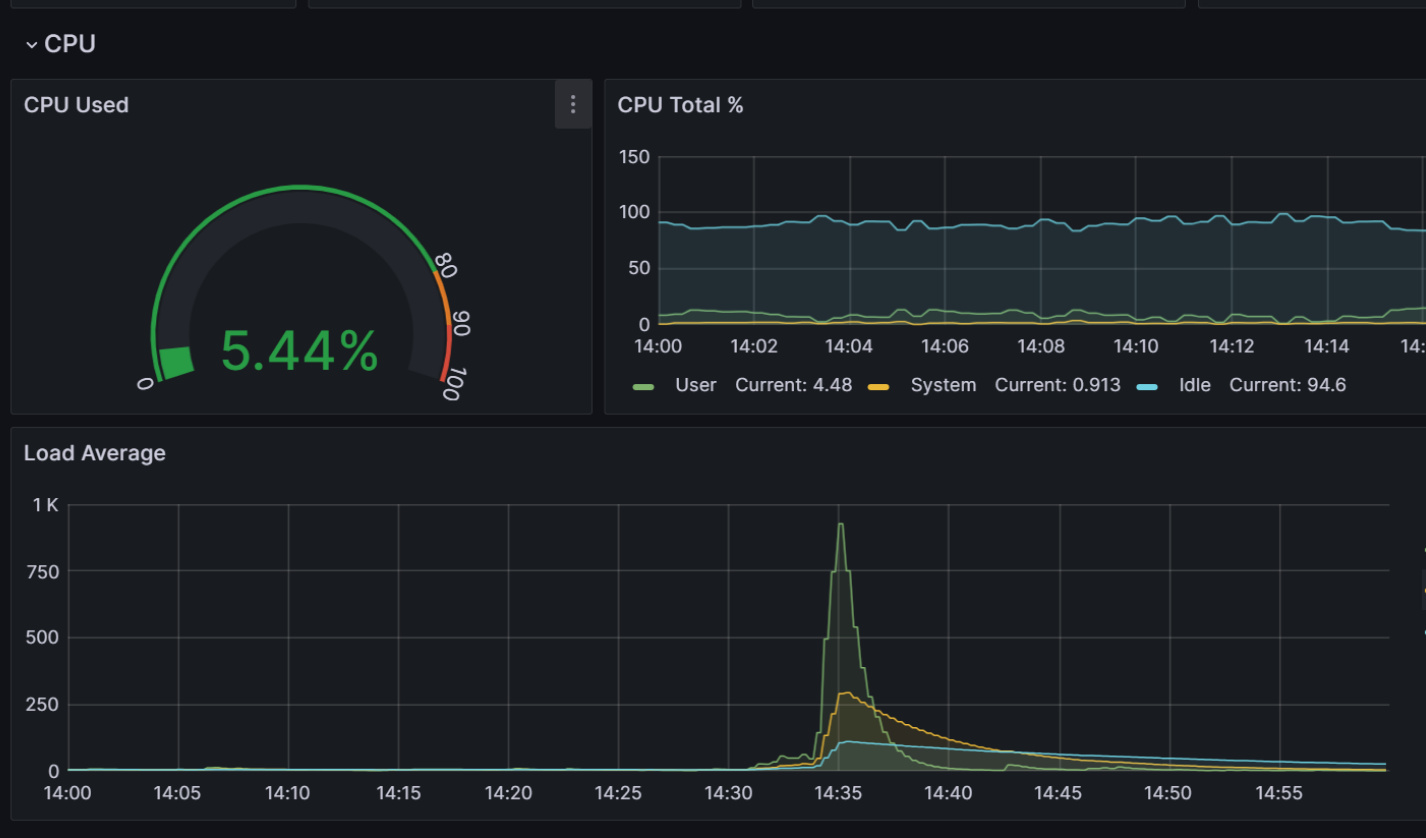
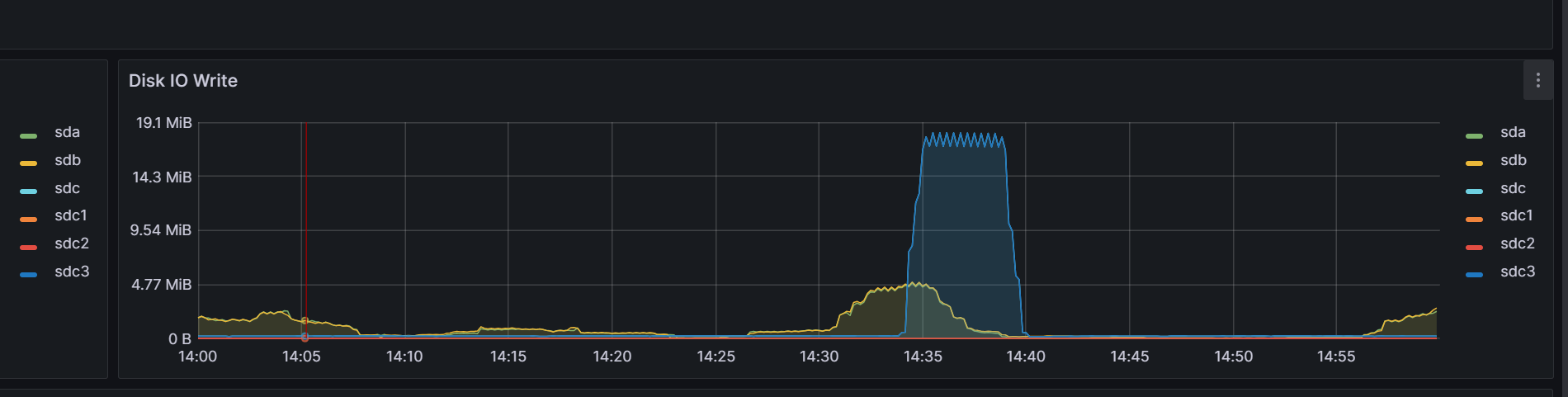
这就彻底说明反馈的和实际情况违背。
结论
不是StarRocks的bug,不用升级。
明显是使用不当所致。无代码对该分析场景使用者的专业素质有非常高的要求。要求是专业的分析人员。这种在一个企业中应该是极少数。
其次由于托拉拽的基础表的选择其实又是一个架构问题。如果能清晰的指导业务逻辑,应该是CDC汇聚过来的业务基表。而不是经过Hadoop全家桶处理过的大宽表。
我经常看到打开一个页面100个报表。每个报表至于多少个复杂SQL就不得而知了。而使用者可能只用这里的1个报表。即要看百分之一的图表,但是要同时把100个运行一下。
方显大数据,方显的大负荷,非大数据不能处理也。