【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
论文1:Show-o: One Single Transformer to Unify Multimodal Understanding and Generation [ICLR 2025]
https://arxiv.org/pdf/2408.12528
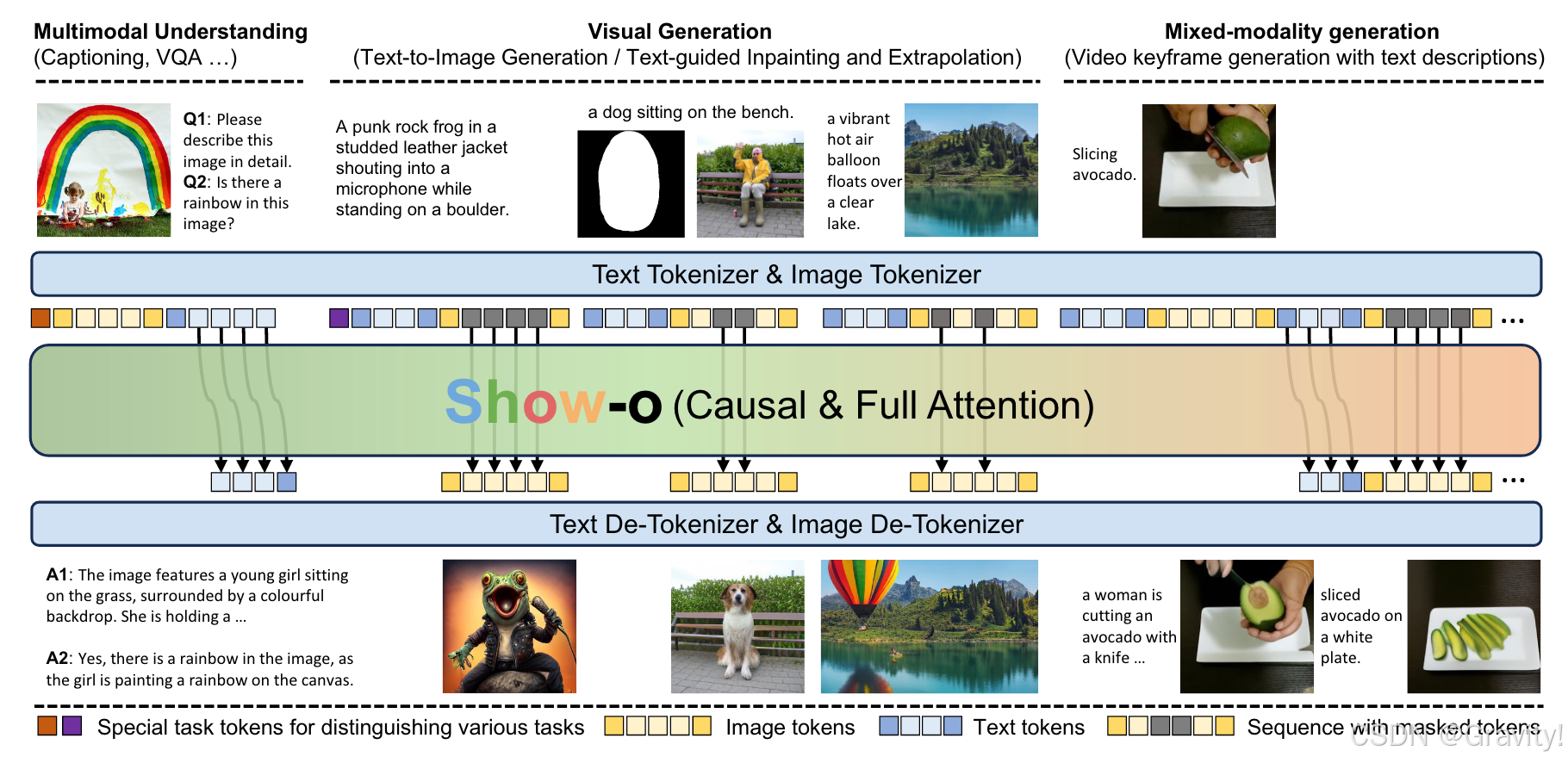
- 核心思想:用单一 Transformer 同时处理多模态理解(自回归)和生成(扩散)
- Show-O是如何实现统一自回归和扩散方法的?
- 自回归:文本用Next Token Prediction方式生成,按照序列一个token一个token地预测
- 扩散:图像用Mask Token Prediction,在每个时间t,随机将部分离散图像token替换为 [MASK] ,模型根据其他token和上下文信息预测 [MASK] (和MaskGIT思路类似)
- 通过Attention Mask的设计,将这两种预测方式统一到一个Transformer中
- 文本和图像都是离散Token
- 模型部分:
- Base大模型:Phi-1.5 [微软]
- 分词器 Tokenization:
- 文本分词:大模型自带分词器
- 图像分词:使用 MAGVIT-v2,将图像编码为离散图像token(图像被编码为 16×16 的离散token,每个token在codebook中查询对应特征,codebook_size=8192)
- 架构 Architecture:
- 保留LLM 的架构,仅在每个注意力层前添加了 QK-Norm 操作【归一化Query和Key的点积,稳定数值】
- 嵌入层扩展:给LLM的词汇表增加8192个图像词汇
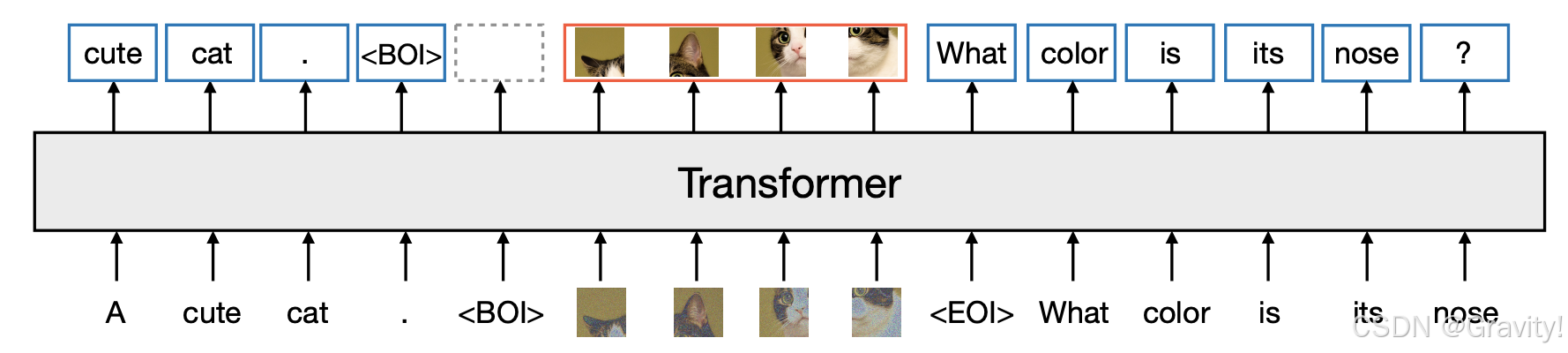
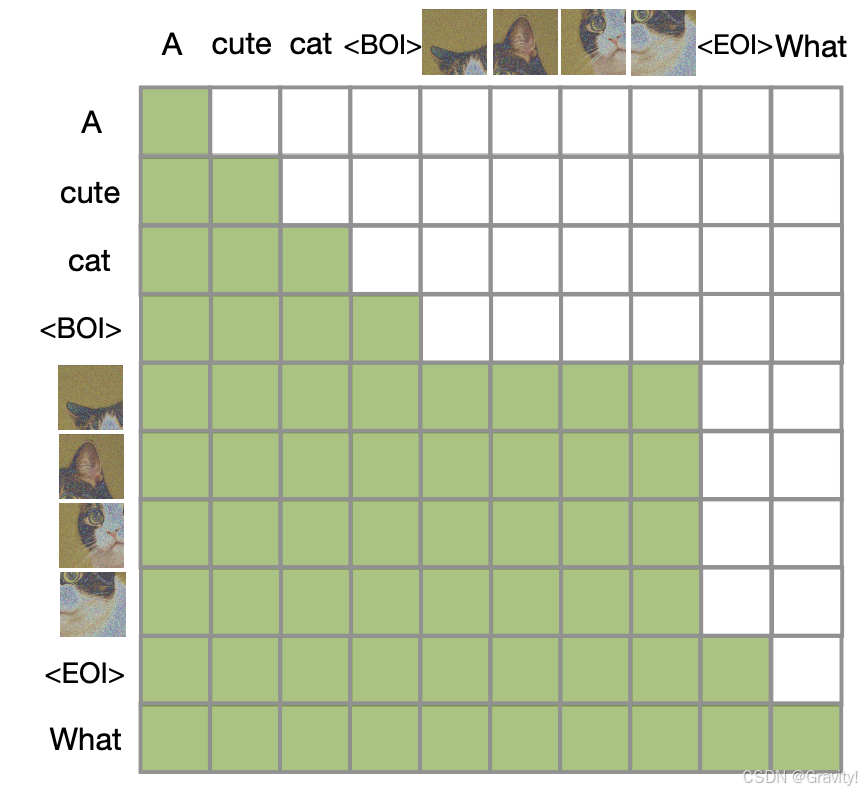
- Omni-Attention 注意力机制
- 文本使用因果注意力Causal Attention(通过因果掩码Causal Mask实现)
- 图像使用全注意力
- 详细的掩码设计解释见:多模态大模型掩码梳理笔记:因果掩码,视觉-语言任务掩码设计-CSDN博客
- 离散扩散实现:
- 扩散过程:从初始图像开始,每个时间 t 逐渐增加噪声(通过mask schedule设置每个时刻的掩码率),噪声为 [MASK] token
- (训练)逆扩散过程:通过 掩码标记预测(Mask Token Prediction)实现,根据其他token和上下文信息预测 [MASK]
- (推理)逆扩散过程:从随机噪声开始,逐步去除噪声生成图像;每步用一部分预测结果替换 [MASK],比率由mask schedule设计
论文2:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model [MetaAI]
https://arxiv.org/pdf/2408.11039 (与Show-o同期相似的工作)
- 核心思想:用单一的 Transformer 模型,同时处理离散文本Token和连续图像向量,统一Next Token Prediction和扩散模型,从而实现多模态数据的统一生成
- 与Show-o的不同:Transfusion的图像用连续表示,Show-o用离散表示
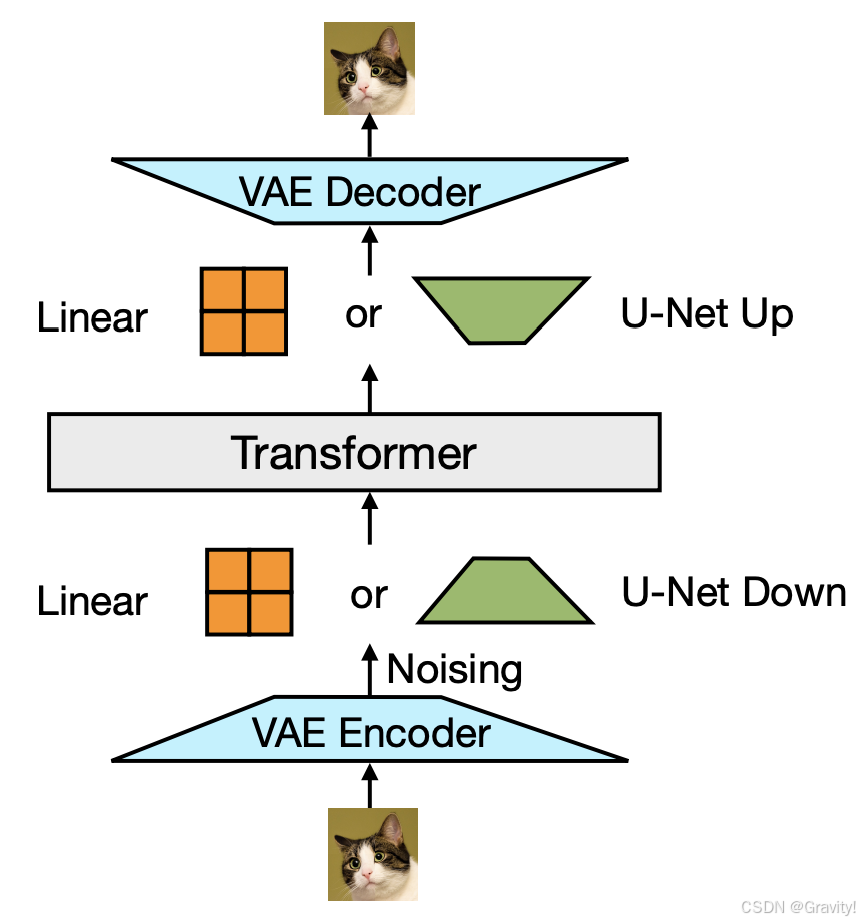
- 图像编码方法:
- VAE编码 → 编码后的图像分割成多个patch → 线性层或U-Net把patch转换为 Transformer可以处理的空间
- VAE编码 → 编码后的图像分割成多个patch → 线性层或U-Net把patch转换为 Transformer可以处理的空间
- 模型架构:
- 文本使用因果注意力
- 图像使用双向注意力:1. 图像内注意力机制【图像patch可以相互传递信息,捕捉图像的内部结构】2. 跨模态注意力【可以访问文本或其他图像的patch,实现跨模态交互】