优化器(Optimizers)
引言
一旦我们计算出了梯度,我们就可以使用这些信息来调整权重和偏差,以减少损失的度量。在之前的一个简单示例中,我们展示了如何成功地以这种方式减少神经元激活函数(ReLU)的输出。回想一下,我们减去了每个权重和偏差参数的梯度的一部分。虽然这种方法非常基础,但它仍然是一种被广泛使用的优化器,称为随机梯度下降(SGD)。如你将很快发现,大多数优化器只是SGD的变体。
1. 随机梯度下降/Stochastic Gradient Descent (SGD)
关于这个优化器的命名约定可能会让人感到困惑,让我们先来了解一下这些术语。你可能会听到以下名称:
- 随机梯度下降(Stochastic Gradient Descent, SGD)
- 原始梯度下降(Vanilla Gradient Descent)、梯度下降(Gradient Descent, GD)或批量梯度下降(Batch Gradient Descent, BGD)
- 小批量梯度下降(Mini-batch Gradient Descent, MBGD)
第一个名称,随机梯度下降,历史上指的是一次适配单个样本的优化器。第二个优化器,批量梯度下降,是用来一次适配整个数据集的优化器。最后一个优化器,小批量梯度下降,用于适配数据集的一部分,我们在这里称之为批次。这里的命名约定可能会因多种原因而令人困惑。
首先,在深度学习和本书的背景下,我们将数据的切片称为批次,而历史上,在随机梯度下降的背景下,用来指代数据切片的术语是小批量(mini-batches)。在我们的背景下,无论批次包含单个样本、数据集的一部分还是整个数据集,都称为数据批次。此外,根据当前的代码,我们正在适配整个数据集;按照这个命名约定,我们将使用批量梯度下降。在未来的章节中,我们将引入数据切片或批次,所以我们应该从使用小批量梯度下降优化器开始。尽管如此,当前的命名趋势和随机梯度下降在当今深度学习中的用法已经融合并规范了所有这些变体,到了我们将随机梯度下降优化器视为假定一批数据的程度,无论该批数据是单个样本、数据集中的每个样本,还是某个时间点的数据集的一部分。
在使用随机梯度下降的情况下,我们会选择一个学习率,例如1.0。然后我们会从实际参数值中减去 learning_rate · parameter_gradients。如果我们的学习率是1,那么我们就会从我们的参数中减去完整的梯度量。我们将从1开始,以查看结果,但我们很快就会更深入地讨论学习率。让我们创建 SGD 优化器类的代码。初始化方法将从学习率开始,暂时接受超参数,并将它们存储在类的属性中。update_params 方法,给定一个层对象,执行最基本的优化,与我们在前一章中执行的方式相同 — 它将层中存储的梯度与负学习率相乘,并将结果添加到层的参数中。看来,在上一章中,我们在不知不觉中执行了 SGD 优化。到目前为止的完整类如下:
class Optimizer_SGD:
# Initialize optimizer - set settings,
# learning rate of 1. is default for this optimizer
def __init__(self, learning_rate=1.0):
self.learning_rate = learning_rate
# Update parameters
def update_params(self, layer):
layer.weights += -self.learning_rate * layer.dweights
layer.biases += -self.learning_rate * layer.dbiases
要使用这个,我们需要创建一个优化器对象:
optimizer = Optimizer_SGD()
然后使用以下方法计算梯度,更新网络层的参数:
optimizer.update_params(dense1)
optimizer.update_params(dense2)
回想一下,层对象包含其参数(权重和偏差),在这个阶段,还包括在反向传播期间计算的梯度。我们将这些存储在层的属性中,以便优化器可以利用它们。在我们的主神经网络代码中,我们会在反向传播之后引入优化。让我们创建一个1x64的全连接神经网络(1个隐藏层,包含64个神经元),并使用之前相同的数据集:
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create Dense layer with 2 input features and 64 output values
dense1 = Layer_Dense(2, 64)
# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()
# Create second Dense layer with 64 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()
下一步是创建优化器的对象:
# Create optimizer
optimizer = Optimizer_SGD()
然后对样本数据进行前向传递:
在这里插入代码片
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through activation function
# takes the output of first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second Dense layer
# takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y)
# Let's print loss value
print('loss:', loss)
# Calculate accuracy from output of activation2 and targets
# calculate values along first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions==y)
print('acc:', accuracy)
接下来,我们进行后向传递,也称为反向传播:
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dinputs)
activation1.backward(dense2.dinputs)
dense1.backward(activation1.dinputs)
然后我们最终使用优化器来更新权重和偏差:
# Update weights and biases
optimizer.update_params(dense1)
optimizer.update_params(dense2)
这就是我们训练模型所需的一切!但是,为什么我们只进行一次优化,当我们可以通过利用Python的循环功能多次进行优化呢?我们将反复执行前向传播、反向传播和优化,直到达到某个停止点。每完成一次对所有训练数据的完整传递称为一个周期(epoch)。在大多数深度学习任务中,神经网络将训练多个epoch,尽管理想情况是在只有一个epoch后就拥有一个具有理想权重和偏差的完美模型。为了将多个训练时代加入我们的代码,我们将初始化模型并围绕执行前向传播、反向传播和优化计算的所有代码运行一个循环:
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create Dense layer with 2 input features and 64 output values
dense1 = Layer_Dense(2, 64)
# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()
# Create second Dense layer with 64 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()
optimizer = Optimizer_SGD()
# Train in loop
for epoch in range(10001):
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through activation function
# takes the output of first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second Dense layer
# takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y)
# Calculate accuracy from output of activation2 and targets
# calculate values along first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions==y)
if not epoch % 100:
print(f'epoch: {epoch}, ' +
f'acc: {accuracy:.3f}, ' +
f'loss: {loss:.3f}')
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dinputs)
activation1.backward(dense2.dinputs)
dense1.backward(activation1.dinputs)
# Update weights and biases
optimizer.update_params(dense1)
optimizer.update_params(dense2)
这样我们每 100 个周期就会更新一次模型的当前状态(周期)、准确率和损失。最初,我们可以看到持续的改进:
>>>
epoch: 0, acc: 0.360, loss: 1.099
epoch: 100, acc: 0.400, loss: 1.087
epoch: 200, acc: 0.417, loss: 1.077
...
epoch: 1000, acc: 0.400, loss: 1.062
...
epoch: 2000, acc: 0.403, loss: 1.037
epoch: 2100, acc: 0.457, loss: 1.022
epoch: 2200, acc: 0.493, loss: 1.020
epoch: 2300, acc: 0.443, loss: 1.002
epoch: 2400, acc: 0.480, loss: 0.994
epoch: 2500, acc: 0.490, loss: 1.009
...
epoch: 9500, acc: 0.607, loss: 0.844
epoch: 9600, acc: 0.607, loss: 0.864
epoch: 9700, acc: 0.607, loss: 0.881
epoch: 9800, acc: 0.600, loss: 0.926
epoch: 9900, acc: 0.610, loss: 0.915
epoch: 10000, acc: 0.647, loss: 0.874
此外,我们准备了动画来帮助可视化训练过程并传达各种优化器及其超参数的影响。动画画布的左侧包含点,其中颜色代表数据的3个类别,坐标是特征,背景颜色显示模型预测区域。理想情况下,点的颜色和背景应该匹配,如果模型分类正确的话。周围区域也应该遵循数据的“趋势”——这就是我们所说的泛化——模型正确预测未见数据的能力。右侧的彩色方块显示权重和偏置——红色代表正值,蓝色代表负值。位于Dense 1条下方和紧邻Dense 2条的相应区域显示优化器对层的更新。更新可能看起来比权重和偏置强得多,但这是因为我们已将它们视觉上标准化为最大值,否则由于更新每次都相当小,它们几乎是看不见的。其他三个图表显示了与训练时间相关的损失、准确率和当前学习率值,在这种情况下是时代。
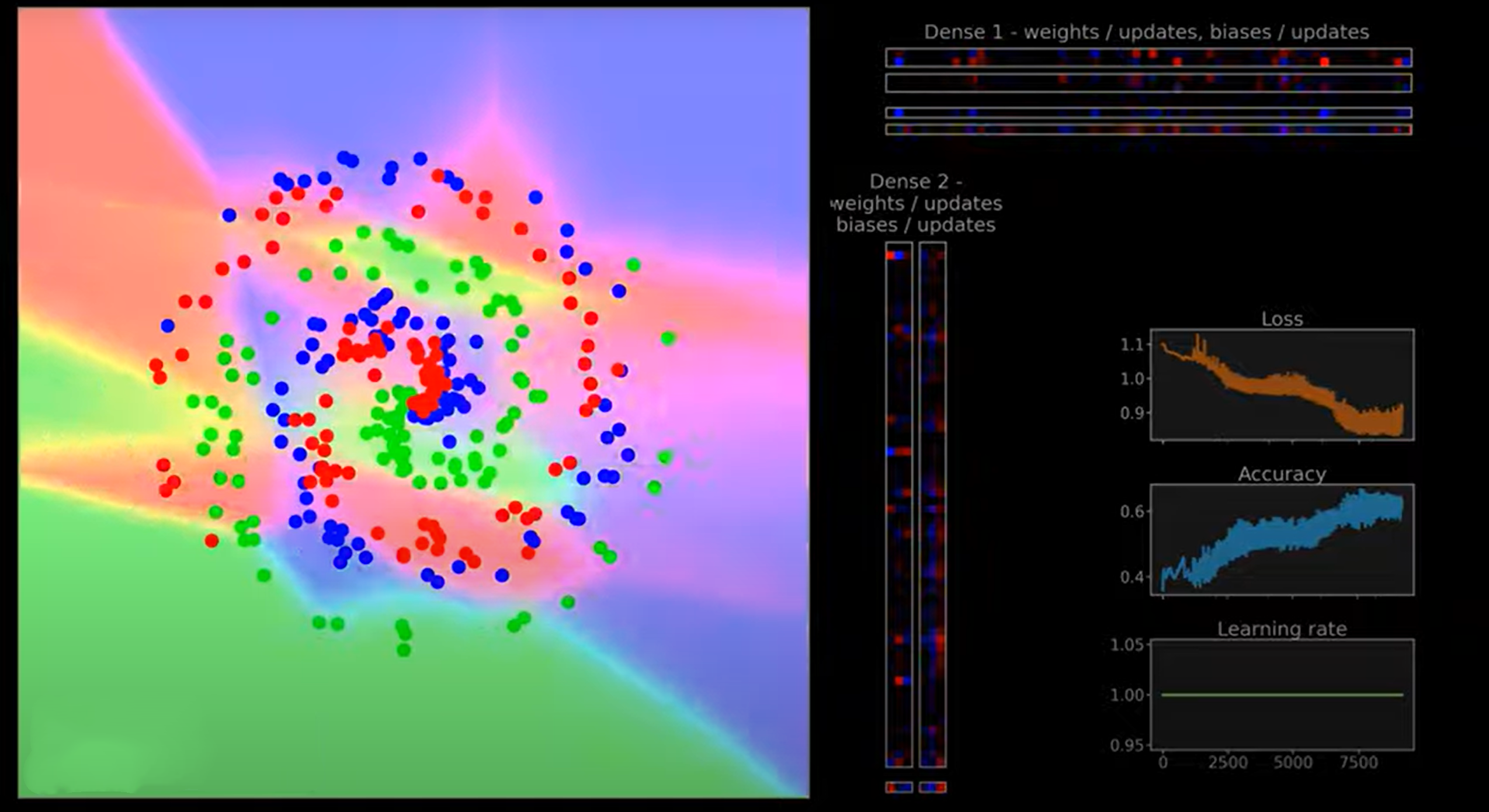
我们的神经网络损失值大多停留在1左右,后来是0.85-0.9,准确率大约为0.60。动画还有一种“闪烁摇摆”的效果,这很可能意味着我们选择了过高的学习率。鉴于损失几乎没有减少,我们可以假设这个学习率太高,也导致模型陷入了局部最小值,我们很快将了解更多。在这一点上,迭代更多的时代似乎没有帮助,这告诉我们我们可能被我们的优化卡住了。这是否意味着这是我们能从优化器在这个数据集上得到的最多的东西?
回想一下,我们通过应用某个分数(在这种情况下是1.0)来调整权重和偏差,并从权重和偏差中减去这个分数。这个分数被称为学习率(LR),是优化器减少损失时的主要可调参数。为了获得调整、规划或最初设置学习率的直觉,我们首先应该理解学习率如何影响优化器和损失函数的输出。
代码可视化:https://nnfs.io/pup
2. 学习率(Learning Rate)
到目前为止,我们已经得到了模型及其损失函数对所有参数的梯度,我们希望将这个梯度的一部分应用到参数上以降低损失值。
在大多数情况下,我们不会直接应用负梯度,因为函数最陡下降的方向会持续变化,而且这些值通常对于模型的有效改进来说太大了。相反,我们希望进行小步调整——计算梯度,通过负梯度的一部分更新参数,并在循环中重复这个过程。小步骤确保我们遵循最陡峭的下降方向,但这些步骤也可能太小,导致学习停滞——我们很快会解释这一点。
暂时忘记我们正在执行一个 n 维函数(我们的损失函数)的梯度下降,其中 n 是模型包含的参数(权重和偏置)数量,假设我们的损失函数只有一个维度(单一输入)。我们接下来的图像和动画的目标是可视化一些概念并获得直观理解;因此,我们不会使用或展示某些优化器设置,而是将以更一般的术语考虑问题。也就是说,我们已经使用了一个真实的 SGD 优化器在一个真实的函数上准备了所有以下的示例。这里是我们想要确定输入到它的什么会产生最低可能输出的函数:
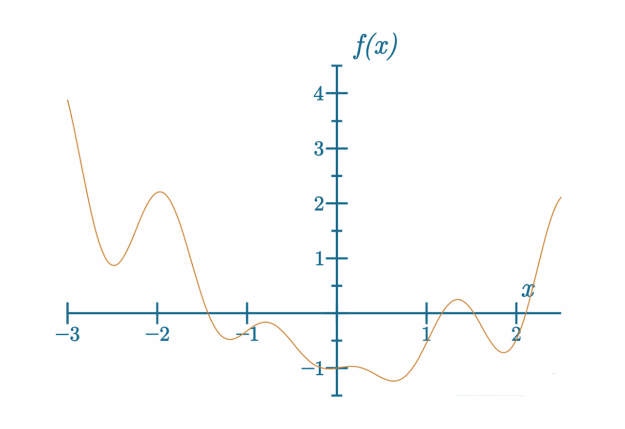
我们可以看到这个函数的全局最小值,即这个函数可能输出的最低 y 值。这是目标——最小化函数的输出以找到全局最小值。在这种情况下,轴的值并不重要。目标仅是展示函数和学习率的概念。同时,请记住,这个一维函数的例子仅用于帮助可视化。使用比解决神经网络的更大的 n 维损失函数所需的数学更简单的方法来解决这个函数将会很容易,其中 n(即权重和偏置的数量)可以达到百万甚至十亿(或更多)。当我们有百万或更多维度时,梯度下降是寻找全局最小值的最著名方法。
我们将从这个图表的左侧开始下降。以一个示例学习率:
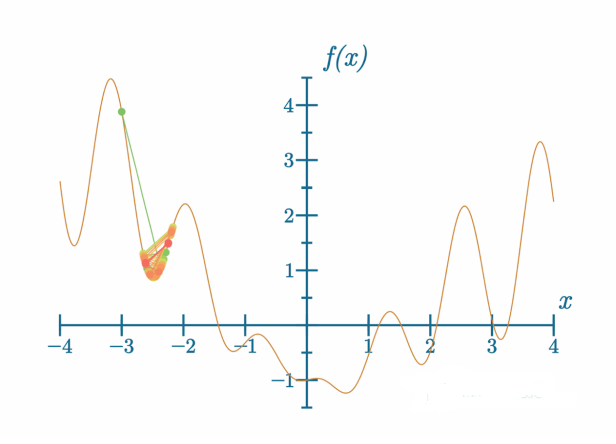
代码可视化:https://nnfs.io/and
学习率太小了。参数的小幅更新导致模型学习停滞——模型卡在了局部最小值。局部最小值是在我们查找附近的最小值,但不一定是全局最小值,全局最小值是函数的绝对最低点。在这里的例子以及优化完整神经网络时,我们不知道全局最小值在哪里。我们如何知道我们是否已经达到全局最小值或至少接近了呢?损失函数衡量模型的预测与真实目标值的接近程度,因此,只要损失值不是0或非常接近0,而且模型停止学习,我们就处于某个局部最小值。实际上,我们几乎从未接近损失值0,这是由于各种原因。其中一个原因可能是神经网络超参数不完善。另一个原因可能是数据不足。如果你的神经网络达到了0的损失值,你应该对此感到怀疑,我们将在本书后面的内容中讨论这些原因。
我们可以尝试修改学习率:
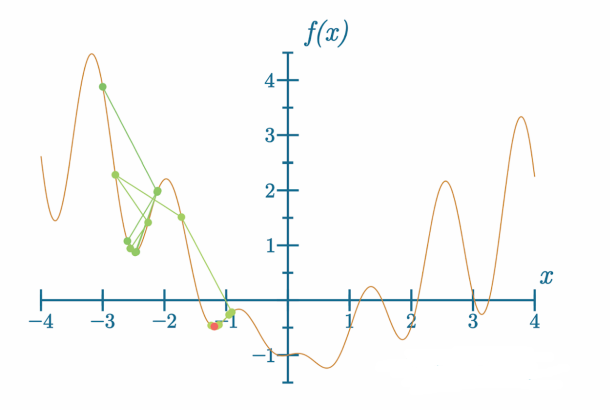
代码可视化:https://nnfs.io/xor
这一次,模型摆脱了这个局部最小值,但却陷入了另一个局部最小值。让我们再看一个学习率变化后的例子:
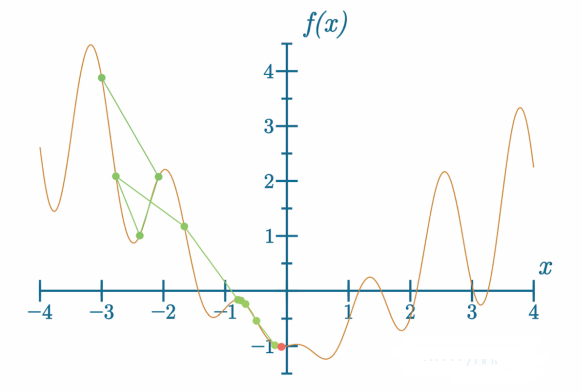
代码可视化:https://nnfs.io/tho
这一次,模型卡在了一个接近全局最小值的局部最小值处。模型能够逃离更“深”的局部最小值,因此它为什么会在这里卡住可能会让人感觉不符合直觉。记住,无论下降有多大或多小,模型都遵循损失函数最陡峭的下降方向。因此,我们将引入动量和其他技术来防止此类情况。
在优化器中,动量增加了梯度,这在物理世界中我们可以称之为惯性(inertia)——例如,我们可以把一个球扔向山坡上,如果山坡足够小或施加的力足够大,球可以滚过山坡的另一边。让我们看看这可能在模型训练中是怎样的:
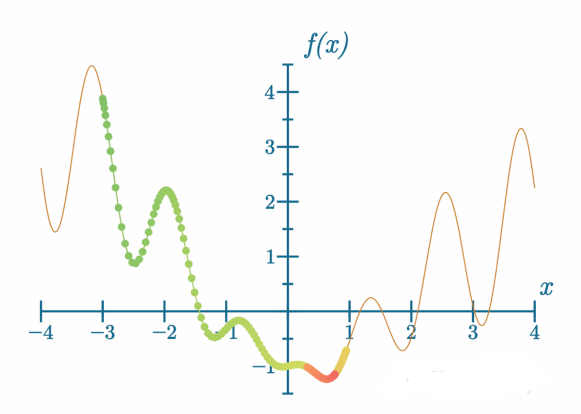
代码可视化:https://nnfs.io/pog
在这里,我们使用了非常小的学习率和较大的动量。颜色从绿色、橙色变为红色展示了梯度下降过程的进展,也就是步骤。我们可以看到,模型实现了目标并找到了全局最小值,但这需要许多步骤。这可以做得更好吗?
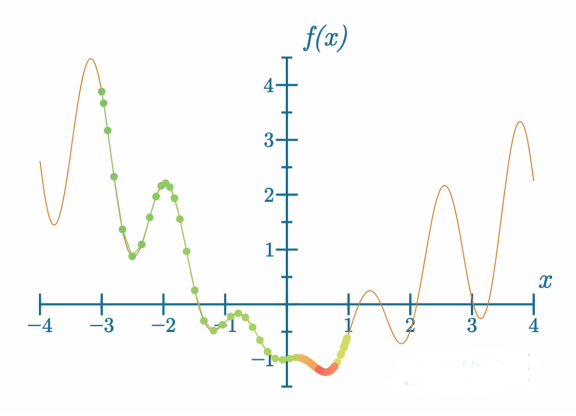
代码可视化:https://nnfs.io/jog
甚至更进一步:
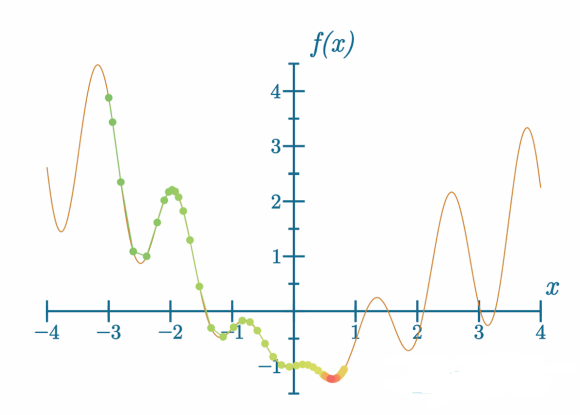
代码可视化:https://nnfs.io/mog
通过调整学习率和动量,我们分别在大约200步、100步和50步内找到了全局最小值。通过调整优化器的参数,可以显著缩短训练时间。然而,我们必须小心这些超参数的调整,因为这并不总是能帮助模型:
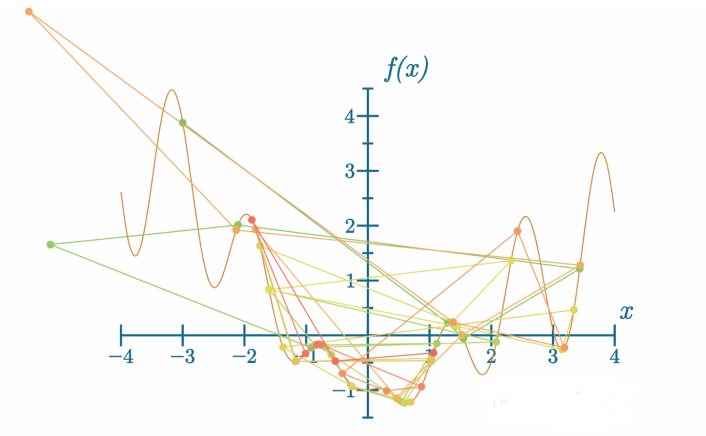
代码可视化:https://nnfs.io/log
当学习率设定过高时,模型可能无法找到全局最小值。甚至在某些时候,如果它确实找到了,进一步的调整可能会导致它跳出这个最小值。我们将在本章稍后看到这种行为——请仔细观察结果,看看你是否能发现我们描述的问题,以及当我们逐一讨论不同的优化器时所遇到的其他问题。
在这种情况下,模型在某个最小值周围“跳动”,这可能意味着我们应该尝试降低学习率、提高动量,或者可能应用学习率衰减(在训练期间降低学习率),我们将在本章中描述这个方法。如果我们将学习率设定得过高:
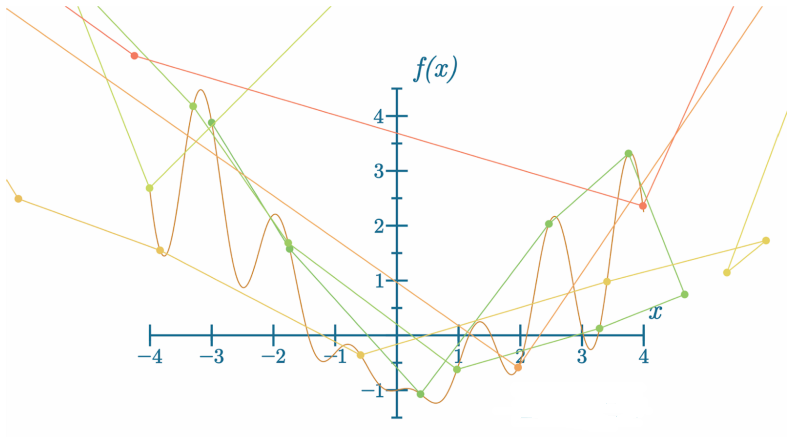
代码可视化:https://nnfs.io/sog
在这种情况下,模型开始在周围“跳动”,并以我们可能观察到的随机方向移动。这是一个“超调”的例子,每一步的改变方向是正确的,但应用的梯度量太大了。在极端情况下,我们可能导致梯度爆炸:
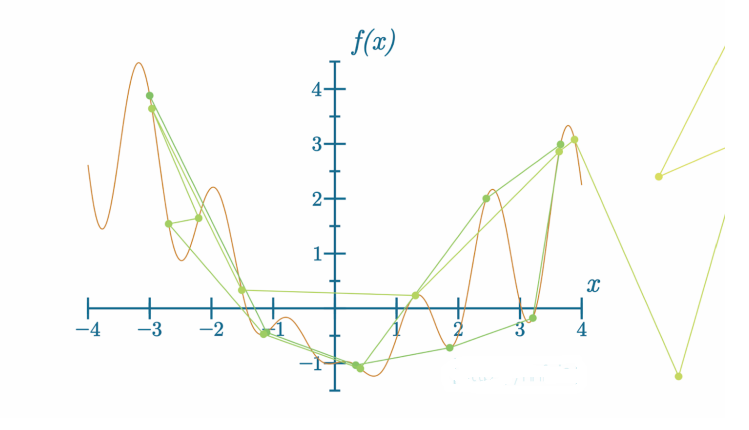
代码可视化:https://nnfs.io/bog
梯度爆炸是一种情况,其中参数更新导致函数的输出上升而不是下降,并且,每一步中,损失值和梯度都会变得更大。在某个点上,由于浮点变量的限制,它无法再容纳这种大小的值,导致溢出,模型将无法继续训练。在训练过程中识别这种情况形成是至关重要的,尤其是对于大型模型,其训练可能需要数天、数周甚至更长时间。及时调整模型的超参数是有可能的,以保存模型并继续训练。
当我们正确选择学习率和其他超参数时,学习过程可以相对较快:
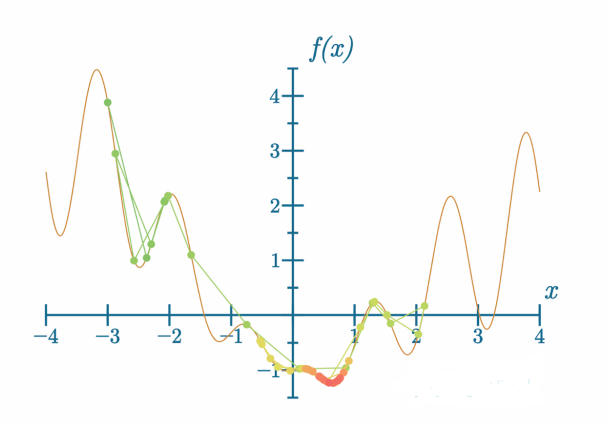
代码可视化:https://nnfs.io/cog
这一次,模型找到全局最小值所需的时间大大减少,但它总能做得更好:
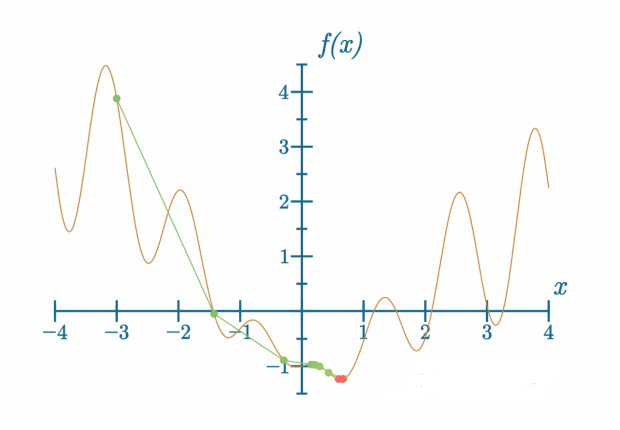
代码可视化:https://nnfs.io/rog
这次模型只需要几步就能找到全局最小值。挑战在于正确选择超参数,这并不总是一项容易的任务。通常最好从优化器的默认设置开始,执行几个步骤,调整不同的设置时观察训练过程。在短时间内看到有意义的结果并不总是可能的,在这种情况下,能够在训练期间更新优化器的设置是很好的。如何选择学习率和其他超参数取决于模型、数据,包括数据量、参数初始化方法等。没有单一最佳方式来设置超参数,但经验通常会有所帮助。正如我们提到的,训练神经网络模型的一个挑战是选择正确的设置。不同设置的影响可能从模型根本不学习到学习得非常好都有可能。
关于学习率的总结——如果我们沿着步骤轴绘制损失图:
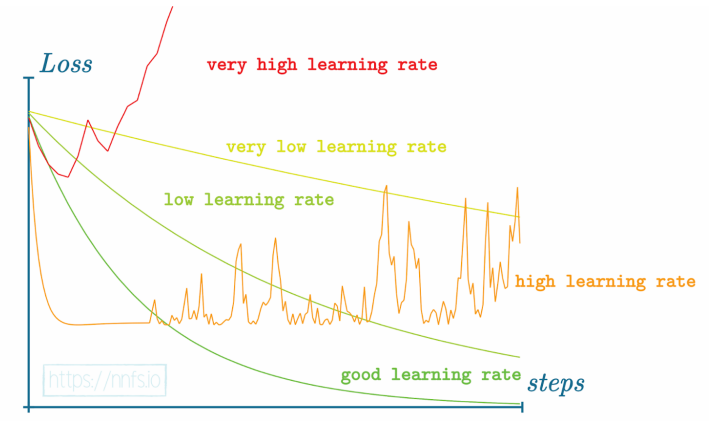
我们可以看到各种不同的相对学习率的例子,以及理想情况下,随着训练时间(步数)的增加,损失如何在图表上表现出来。
要知道什么样的学习率能让你的训练过程发挥最大效用是不可能的,但一个好的规则是,你的初期训练将从较大的学习率中受益,以便更快地进行初步步骤。如果你以太小的步骤开始,你可能会陷入局部最小值,并且由于没有对参数进行足够大的更新,你可能无法离开它。
例如,如果我们将SGD优化器的学习率设为0.85而不是1.0会怎样?
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create Dense layer with 2 input features and 64 output values
dense1 = Layer_Dense(2, 64)
# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()
# Create second Dense layer with 64 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()
# Create optimizer
learning_rate=.85
optimizer = Optimizer_SGD(learning_rate=learning_rate)
# Train in loop
for epoch in range(10001):
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through activation function
# takes the output of first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second Dense layer
# takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y)
# Calculate accuracy from output of activation2 and targets
# calculate values along first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions==y)
if not epoch % 100:
print(f'epoch: {epoch}, ' +
f'acc: {accuracy:.3f}, ' +
f'loss: {loss:.3f}')
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dinputs)
activation1.backward(dense2.dinputs)
dense1.backward(activation1.dinputs)
# Update weights and biases
optimizer.update_params(dense1)
optimizer.update_params(dense2)
>>>
>>>
epoch: 0, acc: 0.360, loss: 1.099
epoch: 100, acc: 0.403, loss: 1.091
...
epoch: 2000, acc: 0.407, loss: 1.037
epoch: 2100, acc: 0.440, loss: 1.027
epoch: 2200, acc: 0.457, loss: 1.038
epoch: 2300, acc: 0.447, loss: 1.042
epoch: 2400, acc: 0.537, loss: 0.986
epoch: 2500, acc: 0.427, loss: 1.009
epoch: 2600, acc: 0.487, loss: 1.029
epoch: 2700, acc: 0.530, loss: 0.986
...
epoch: 7100, acc: 0.567, loss: 0.917
epoch: 7200, acc: 0.587, loss: 0.969
epoch: 7300, acc: 0.553, loss: 0.947
epoch: 7400, acc: 0.610, loss: 0.953
epoch: 7500, acc: 0.573, loss: 0.953
epoch: 7600, acc: 0.537, loss: 0.935
epoch: 7700, acc: 0.547, loss: 0.979
...
epoch: 9100, acc: 0.583, loss: 0.929
epoch: 9200, acc: 0.583, loss: 0.929
...
epoch: 10000, acc: 0.603, loss: 0.942
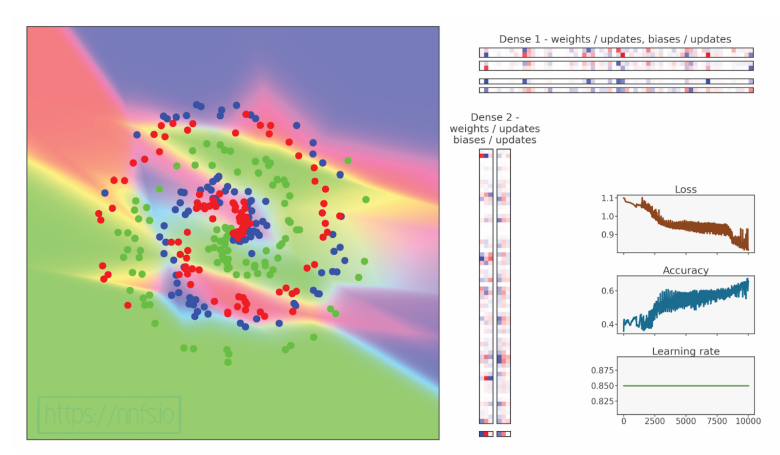
代码可视化:https://nnfs.io/cup
正如你所看到的,神经网络在准确性方面并没有提高,而且损失也没有变的更好;但是我们要记住,较低的损失并不总是与更高的准确性相关联。 记住,即使我们希望我们的模型达到最佳的准确性,优化器的任务是减少损失,而不是直接提高准确性。损失是所有样本损失的平均值,其中一些可能会显著下降,而其他一些可能只会略微上升,同时将它们的预测从正确类别改为错误类别。这会导致总体上较低的平均损失,但同时也会导致更多预测不正确的样本,这同时会降低准确性。这种模型准确性较低的可能原因是它偶然找到了另一个局部最小值——由于采取了较小的步骤,下降路径发生了变化。在这两个模型的直接比较训练中,不同的学习率并没有显示出这个学习率值越低越好。在大多数情况下,我们希望从较大的学习率开始,并随着时间/步骤逐渐降低学习率。
一个常用的解决方案是实施学习率衰减,以保持初始更新的大幅度并在训练期间探索各种学习率。
3. 学习率衰减(Learning Rate Decay)
学习率衰减的概念是从较大的学习率开始,例如我们的案例中是1.0,然后在训练过程中逐渐减小它。有几种方法可以做到这一点。其中一种是根据跨越多个训练周期的损失来降低学习率——例如,如果损失开始趋于平稳/达到平台期或开始“跳跃”大幅度变化。你可以逻辑地编程监控这种行为,或者简单地跟踪随时间的损失并在你认为适当时手动降低学习率。另一个选项,我们将要实施的,是编程一个衰减率,它会稳定地按每个批次或周期降低学习率。
我们计划按步骤衰减。这也可以称为1/t衰减或指数衰减。基本上,我们将在每个步骤中按步数的倒数更新学习率。这个倒数是我们将添加到优化器中的一个新的超参数,称为学习率衰减。衰减的工作原理是它取步骤和衰减比例并将它们相乘。训练越深入,步骤就越大,这个乘积的结果也就越大。然后我们取其倒数(训练越深入,该值就越低)并将初始学习率乘以它。添加的1确保最终算法永远不会提高学习率。例如,对于第一步,我们可能会用学习率除以1,例如0.001,这将导致当前学习率为1000。这绝对不是我们想要的。1除以1+比例确保结果,即起始学习率的一部分,始终小于或等于1,随时间减小。这是期望的结果——从当前学习率开始,随时间使其变小。确定当前衰减率的代码如下:
starting_learning_rate = 1.
learning_rate_decay = 0.1
step = 1
learning_rate = starting_learning_rate * (1. / (1 + learning_rate_decay * step))
print(learning_rate)
>>>
0.9090909090909091
在实践中,0.1 会被认为是一个相当激进的衰减率,但这应该能让你对这一概念有所了解。如果我们在第 20 步:
starting_learning_rate = 1.
learning_rate_decay = 0.1
step = 20
learning_rate = starting_learning_rate * (1. / (1 + learning_rate_decay * step))
print(learning_rate)
>>>
0.9090909090909091
我们还可以在一个循环中进行模拟,这与我们应用学习率衰减的方式更为相似:
starting_learning_rate = 1.
learning_rate_decay = 0.1
for step in range(20):
learning_rate = starting_learning_rate * (1. / (1 + learning_rate_decay * step))
print(learning_rate)
>>>
1.0
0.9090909090909091
0.8333333333333334
0.7692307692307692
0.7142857142857143
0.6666666666666666
0.625
0.588235294117647
0.5555555555555556
0.5263157894736842
0.5
0.47619047619047616
0.45454545454545453
0.4347826086956522
0.41666666666666663
0.4
0.3846153846153846
0.37037037037037035
0.35714285714285715
0.3448275862068965
这种学习率衰减方案通过上述公式在每个步骤中降低学习率。最初,学习率下降很快,但每个步骤中学习率的变化都在减小,让模型尽可能接近最小值。模型在训练结束时需要小的更新,以便尽可能接近这一点。我们现在可以更新我们的SGD优化器类,以允许学习率衰减:
# SGD optimizer
class Optimizer_SGD:
# Initialize optimizer - set settings,
# learning rate of 1. is default for this optimizer
def __init__(self, learning_rate=1.0, decay=0.):
self.learning_rate = learning_rate
self.current_learning_rate = learning_rate
self.decay = decay
self.iterations = 0
# Call once before any parameter updates
def pre_update_params(self):
if self.decay:
self.current_learning_rate = self.learning_rate * (1. / (1. + self.decay * self.iterations))
# Update parameters
def update_params(self, layer):
layer.weights += -self.learning_rate * layer.dweights
layer.biases += -self.learning_rate * layer.dbiases
# Call once after any parameter updates
def post_update_params(self):
self.iterations += 1
我们在SGD类中更新了一些内容。首先,在__init__方法中,我们添加了对当前学习率的处理,self.learning_rate现在是初始学习率。我们还添加了跟踪衰减率和优化器已经经过的迭代次数的属性。接下来,我们添加了一个名为pre_update_params的新方法。如果我们有一个不为0的衰减率,这个方法将使用前面的公式更新我们的self.current_learning_rate。update_params方法保持不变,但我们有一个新的post_update_params方法,将增加我们的self.iterations跟踪。使用我们更新的SGD优化器类,我们添加了打印当前学习率的功能,并添加了优化器方法的前置和后置调用。让我们使用1e-2(0.01)的衰减率再次训练我们的模型:
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create Dense layer with 2 input features and 64 output values
dense1 = Layer_Dense(2, 64)
# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()
# Create second Dense layer with 64 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()
# Create optimizer
# learning_rate=0.85
decay = 1e-2
optimizer = Optimizer_SGD(decay=decay)
# Train in loop
for epoch in range(10001):
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through activation function
# takes the output of first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second Dense layer
# takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y)
# Calculate accuracy from output of activation2 and targets
# calculate values along first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions==y)
if not epoch % 100:
print(f'epoch: {epoch}, ' +
f'acc: {accuracy:.3f}, ' +
f'loss: {loss:.3f}, ' +
f'lr: {optimizer.current_learning_rate}')
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dinputs)
activation1.backward(dense2.dinputs)
dense1.backward(activation1.dinputs)
# Update weights and biases
optimizer.pre_update_params()
optimizer.update_params(dense1)
optimizer.update_params(dense2)
optimizer.post_update_params()
>>>
epoch: 0, acc: 0.360, loss: 1.099, lr: 1.0
epoch: 100, acc: 0.400, loss: 1.087, lr: 0.5025125628140703
epoch: 200, acc: 0.417, loss: 1.077, lr: 0.33444816053511706
epoch: 300, acc: 0.420, loss: 1.076, lr: 0.2506265664160401
epoch: 400, acc: 0.400, loss: 1.074, lr: 0.2004008016032064
epoch: 500, acc: 0.400, loss: 1.071, lr: 0.1669449081803005
epoch: 600, acc: 0.417, loss: 1.067, lr: 0.14306151645207438
epoch: 700, acc: 0.437, loss: 1.062, lr: 0.1251564455569462
epoch: 800, acc: 0.430, loss: 1.055, lr: 0.11123470522803114
epoch: 900, acc: 0.390, loss: 1.064, lr: 0.10010010010010009
epoch: 1000, acc: 0.400, loss: 1.062, lr: 0.09099181073703366
...
epoch: 2000, acc: 0.403, loss: 1.037, lr: 0.047641734159123386
...
epoch: 3000, acc: 0.543, loss: 0.985, lr: 0.03226847370119393
...
epoch: 4000, acc: 0.520, loss: 0.971, lr: 0.02439619419370578
...
epoch: 5000, acc: 0.510, loss: 0.973, lr: 0.019611688566385566
...
epoch: 7000, acc: 0.593, loss: 0.905, lr: 0.014086491055078181
...
epoch: 10000, acc: 0.647, loss: 0.874, lr: 0.009901970492127933
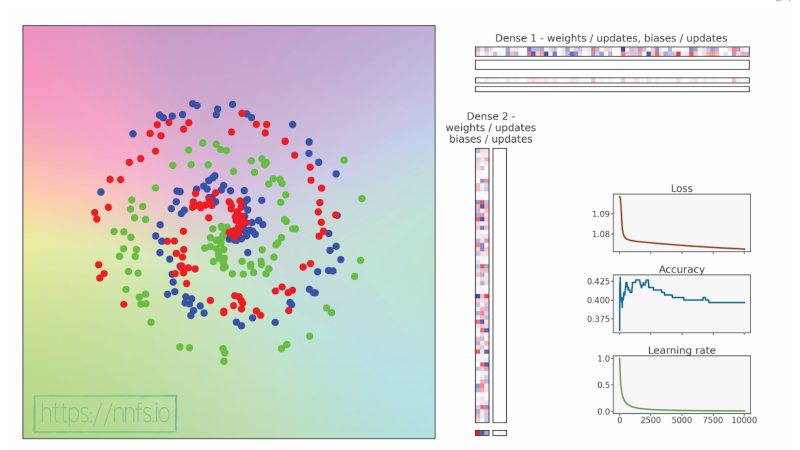
代码可视化:https://nnfs.io/zuk
这个模型肯定卡住了,原因几乎可以肯定是因为学习率衰减得太快,变得太小,使得模型陷入了某个局部最小值。这很可能是为什么我们的准确率和损失不再有任何变化,而不是摆动的原因。
我们可以尝试通过将衰减率设为一个更小的数字来稍微慢一些地进行衰减。例如,我们可以尝试1e-3(0.001):
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create Dense layer with 2 input features and 64 output values
dense1 = Layer_Dense(2, 64)
# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()
# Create second Dense layer with 64 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(64, 3)
# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()
# Create optimizer
# learning_rate=0.85
decay = 1e-3
optimizer = Optimizer_SGD(decay=decay)
# Train in loop
for epoch in range(10001):
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Perform a forward pass through activation function
# takes the output of first dense layer here
activation1.forward(dense1.output)
# Perform a forward pass through second Dense layer
# takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)
# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y)
# Calculate accuracy from output of activation2 and targets
# calculate values along first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y.shape) == 2:
y = np.argmax(y, axis=1)
accuracy = np.mean(predictions==y)
if not epoch % 100:
print(f'epoch: {epoch}, ' +
f'acc: {accuracy:.3f}, ' +
f'loss: {loss:.3f}, ' +
f'lr: {optimizer.current_learning_rate}')
# Backward pass
loss_activation.backward(loss_activation.output, y)
dense2.backward(loss_activation.dinputs)
activation1.backward(dense2.dinputs)
dense1.backward(activation1.dinputs)
# Update weights and biases
optimizer.pre_update_params()
optimizer.update_params(dense1)
optimizer.update_params(dense2)
optimizer.post_update_params()
>>>
epoch: 0, acc: 0.360, loss: 1.099, lr: 1.0
epoch: 100, acc: 0.400, loss: 1.087, lr: 0.9099181073703367
epoch: 200, acc: 0.417, loss: 1.077, lr: 0.8340283569641367
...
epoch: 1700, acc: 0.397, loss: 1.043, lr: 0.3705075954057058
epoch: 1800, acc: 0.450, loss: 1.038, lr: 0.35727045373347627
epoch: 1900, acc: 0.483, loss: 1.025, lr: 0.3449465332873405
epoch: 2000, acc: 0.403, loss: 1.037, lr: 0.33344448149383127
epoch: 2100, acc: 0.457, loss: 1.022, lr: 0.32268473701193934
...
epoch: 3200, acc: 0.487, loss: 0.976, lr: 0.23815194093831865
...
epoch: 5000, acc: 0.510, loss: 0.973, lr: 0.16669444907484582
...
epoch: 6000, acc: 0.490, loss: 0.940, lr: 0.1428775539362766
...
epoch: 8000, acc: 0.617, loss: 0.874, lr: 0.11112345816201799
...
epoch: 9800, acc: 0.600, loss: 0.926, lr: 0.09260116677470137
epoch: 9900, acc: 0.610, loss: 0.915, lr: 0.09175153683824203
epoch: 10000, acc: 0.647, loss: 0.874, lr: 0.09091735612328393
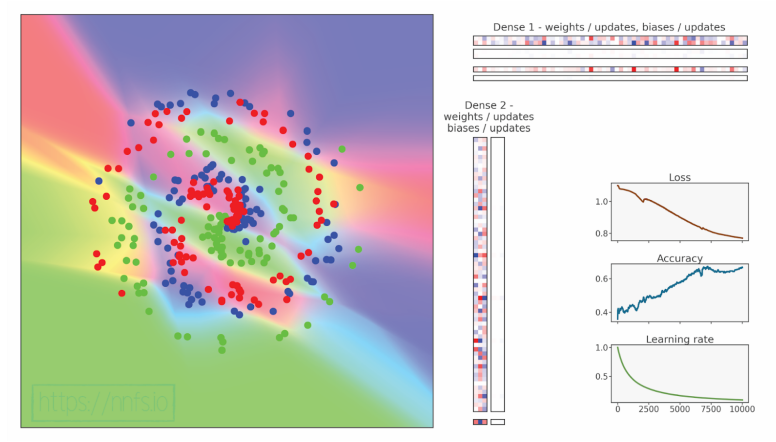
代码可视化:https://nnfs.io/muk
我们还应该有可能找到能带来更好结果的参数。例如,你可能会怀疑初始学习率太高。尝试找到更好的设置可以成为一个很好的练习。随意尝试!
带学习率衰减的随机梯度下降可以做得相当好,但仍然是一种基本的优化方法,它只遵循梯度,没有任何可能帮助模型找到损失函数全局最小值的额外逻辑。改善SGD优化器的一个选项是引入动量。
4. 带动量的随机梯度下降法(Stochastic Gradient Descent with Momentum)
本章的章节代码、更多资源和勘误表:https://nnfs.io/ch10