22年4月来自著名的纽约法美公司Hugging Face、谷歌、法国LightOn、西雅图的Allen Institute for AI (AI2)和巴黎LPENS, École Normale Supérieure的文章“What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?“。
经过预训练的大型Transformer语言模型已被证明表现出零样本泛化,即它们可以执行各种各样的任务,而这些任务并没有经过明确训练。然而,现有模型中使用的架构和预训练目标存在显著差异,这些因素的系统比较有限。这项工作对建模选择及其对零样本泛化的影响进行了大规模评估。特别是,专注于文本-到-文本模型,并对三种模型架构,因果(causal)/非因果(non-causal)解码器以及编码器-解码器,进行实验,用两种不同的预训练目标(自回归和掩码语言模型)进行训练,并在有和无多任务提示微调的情况下进行评估。为超过1700亿个tokens超过50亿个参数的模型进行训练,从而增加了结论转移到更大范围的似然值。实验表明,在完全无监督的预训练后,在自动语言建模目标上训练的仅因果(casual)解码器模型表现出最强的零样本泛化。实验概述如图所示:
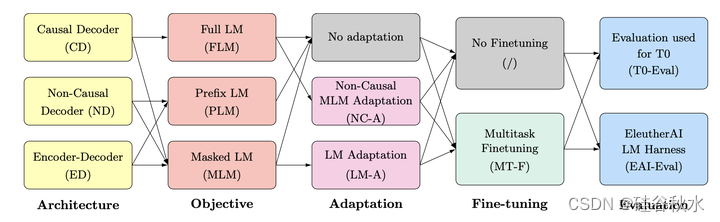
然而,用掩码语言建模目标和多任务微调训练的、输入具有非因果(non-casual)可见性的模型,在实验中表现最好。因此,作者考虑跨体系结构和目标的预训练模型的适应性。用自回归语言建模作为下游任务,预训练的非因果(non-casual)解码器模型可以适应于生成式因果(casual)解码器模型。此外,预训练的因果解码器模型可以有效地适应于非因果解码器模型,最终在多任务微调后性能具备竞争力。
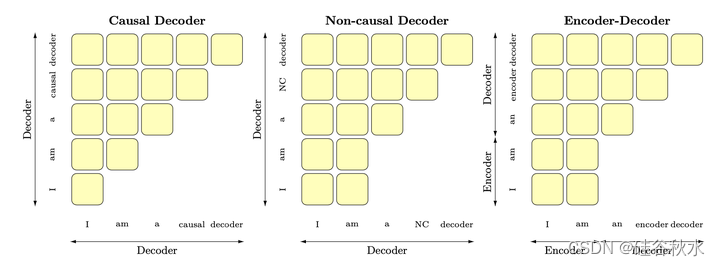
关于模型架构,如图是三种因果解码器、非因果解码器和编码器-解码器架构的注意模式。在因果解码器中,每个token只关注先前的 token。在非因果解码器和编码器-解码器中,注意机制对任何条件信息是双向的。对于编码器-解码器,该条件被馈送到模型的编码器部分。
构建LLM的一个重要步骤是预训练,即通过自监督在大型未标记数据集上训练模型。预训练目标的选择会对LLM的下游可用性产生重大影响,因此在实证研究中将目标选择作为一个因素。如图是完整(full)、前缀(prefix)和掩码(masked)语言建模训练目标(objective)中的输入和目标(target)token。对于全语言建模,在训练过程中使用序列中的所有tokens。对于前缀语言建模,随机选择前缀大小,因此平均只有一半的token用于导出损失。在推断时,前缀将位于输入/条件信息之上。最后,对于掩码语言建模,屏蔽了15%的tokens,平均跨度为3个tokens。用哨兵(sentinel)tokens来替换跨度(spans,注:此处未表示),模型随后输出每个哨兵(sentinel),然后输出其对被哨兵屏蔽的内容预测。

语言建模。自GPT-2[Radford2019]出现以来,通常用自回归语言建模目标对仅解码器的大型模型进行预训练[Brown2020,Wu2021,Rae2021]。给定以前的tokens,模型的任务是预测下面的tokens,称之为全语言建模(FLM)。这个目标在预训练过程中特别有效:序列中的所有tokens都可以并行生成一个损失信号。在推理时,迭代地要求模型预测下一个token。
前缀语言建模。对于编码器-解码器和非因果解码器模型执行语言建模,可以定义一个前缀,其中注意掩码被允许是非因果的。与标准语言建模类似,该模型的任务是在给定所有先前tokens的情况下预测前缀之外的每个token,此目标称为前缀语言建模(PLM)。前缀的损失被忽略,因为前缀中的token可以关注它们的目标。对于推断,前缀自然是输入文本;在预训练过程中,通常对每个样本进行随机选择。
掩码语言建模。编码器模型,如BERT[Devlin 2018],通常使用掩码语言建模目标进行预训练。输入文本中的token或 token跨度(span)被替换为特殊的掩码token,并且模型被训练以预测丢失的token。Raffel[2020]介绍了该目标的一个版本,适用于跨度破坏(span corruption)形式的文本-到-文本模型:哨兵token用于标记短随机长度的屏蔽跨度,在处理屏蔽输入后,模型输出哨兵,然后输出其各自的预测内容,其方法称为掩码语言建模(MLM)。
适应扩展了具有不同目标和/或架构的预训练。与微调相反,适应不使用新的下游数据,只使用额外的预训练数据。语言建模自适应(LM-A)采用MLM预训练的模型,并用PLM或FLM扩展其训练。它已被用于将MLM预训练的编码器-解码器模型(如T5)转换为更好的生成模型。值得注意的是,它被用作提示调整前的第一步[Lester 2021],也被用作T0中多任务微调前的模型准备[Sanh 2021]。当对非因果解码器专用模型执行语言建模自适应时,只需切换注意掩码即可将其转换为因果解码器。此外,建议研究反向的自适应:从FLM预训练的因果解码器开始,将模型转换为非因果解码器(再次切换注意掩码),并扩展MLM预训练。称这种方法为非因果MLM适应(NC-A)。
现代预训练语料库,通常是大规模的预处理全能网络爬虫[Oltiz Suárez 2019,Raffel 2020],在没有明确考虑下游任务的情况下,所收集的高质量跨域数据,是实现更好零样本泛化的途径[Gao 2020,Scao 2022]。最近,(Sanh2021)方法,用MLM训练的编码器-解码器模型,和(Wei2021),用FLM训练的因果解码器模型,探讨了显式微调模型,解决多个任务,支持零样本泛化的潜力。这是在提示任务的数据集上微调模型完成的(即,以自然语言格式,利用在许多数据集上应用的提示模板),这最终提高了零样本性能,而不是纯粹的无监督预训练。称之为多任务微调(MT-F),并采用为T0开发的公开可用数据集和提示。
(Radford2019)首次证明了LLM显示出零样本能力:在足够的规模下,语言模型能够执行许多任务,而无需明确访问任何监督样本。语言模型的零样本使用依赖于一种称为提示的技术,其中任务是以自然语言格式制定的(根据预训练目标)。应用于每个示例并将其转换为此格式的模板,称为提示。不幸的是,模型可能对提示的措辞表现出显著的敏感性[Sanh2021],并且很难诊断性能差是提示问题还是模型相关问题。
社区对零样本能力的兴趣越来越大,大多数破纪录的LLM证明了这一点,仅报告零/少样本结果[Brown 2020,Smith 2022,Rae 2021,Chowdhery 2022]。零样本的使用之所以如此受欢迎,有很多原因:它不需要任何标记的示例,它消除了模型微调和部署的复杂性,还测试了对未见任务的泛化能力。
本文依赖于两个评估基准聚合NLP任务中的提示,共有30个任务:EleutherAI LM评估(EAI-Eval)[Gao 2021],它重新实现了(Brown2020)的提示,旨在评估FLM训练的因果解码器模型,以及T0(T0-Evall)的评估集[Sanh 2021]。注意,EAI Eval每个任务只包括一个提示,而T0 Eval的性能是多个提示的平均值。
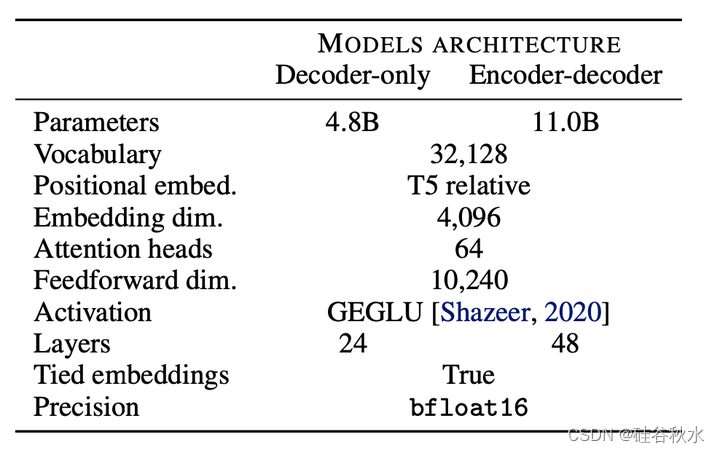
如表是用于所有训练模型的共享体系结构。编码器-解码器架构的大小加倍,获得类似于解码器架构的预训练计算预算。
下表针对所有训练模型进行预训练和多任务微调配置。预训练持续输入1680亿个token,而多任务微调则完成130亿个token的工作。

实验研究得出结论,零样本性能的最佳架构和目标选择取决于模型最终是否会进行多任务微调:而用全语言建模训练的解码器模型在仅进行无监督预训练后实现了最佳零样本性能,一旦应用了多任务微调,具有掩码语言建模的编码器-解码器是最好的。不过,多任务微调编码器-解码器模型可能不适用于解码器模型擅长的许多开放式生成任务,而解码器模型在许多零样本任务中将不是最好的。
下面研究适应的实践工作:用不同的架构和/或目标扩展预训练。最终目标是有效地获得两个不同的模型:一个利用多任务微调来最大限度地提高零样本性能,另一个可以用作高质量的语言模型。
语言建模自适应(LM-A)。首先,建议预训练具有MLM目标的非因果解码器模型,然后将该模型进一步训练为具有FLM目标的因果解码器(语言建模自适应)。这种转换很简单,因为参数和整体架构可以保持不变,只需要切换注意掩码。也尝试从编码器-解码器模型的解码器部分进行这种自适应,但它的性能明显比从头开始训练差。
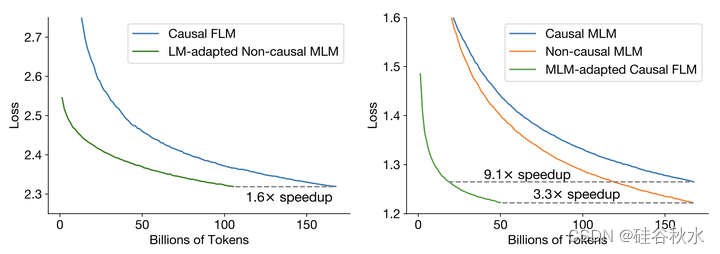
验证损失如下图左侧所示。与从头开始用FLM目标训练因果解码器模型做相比,从MLM预训练的非因果解码器模型开始明显加快了收敛。为了实现与FLM预训练168B个token后的损失相当,语言建模自适应只需要105B个额外token(1.6倍的加速)。这可以获得高质量的零样本模型和良好的生成模型,只需训练单模型成本的1.6倍。
非因果掩码语言建模自适应(NC-A)。为了研究自适应的替代途径,引入非因果掩码语言建模自适应:从预训练FLM作为目标的因果解码器模型开始,然后用MLM目标继续将模型训练为非因果解码器。这本质上与语言建模自适应设置相反,并且通过切换注意掩码可以很容易地进行转换。
验证损失如上图右所示。MLM预训练目标的收敛速度显著加快:与从头开始训练非因果解码器相比,收敛速度提高了3.3倍,与从头开始训练因果解码器相比(均具有掩掩码语言建模目标),收敛速度高达9.1倍。这甚至比之前考虑的语言建模自适应都有了改进,仅需1.3倍的训练单模型成本就可以获得零样本模型和优秀的生成模型。