文章目录
- XGBoost简介
- 安装XGBoost
- 代码
- 原始
- 查看训练过程
- 查看特征重要性
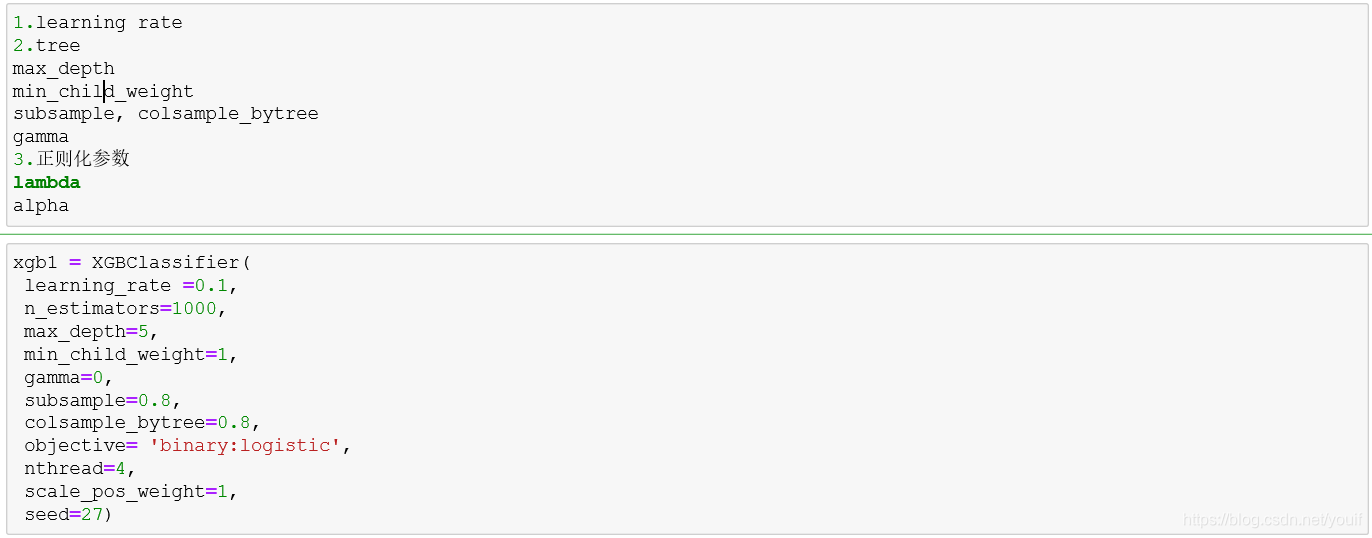
- 调参 查找最好的学习率
- 提升参数
- 1. eta [default=0.3, alias: learning_rate]
- 2. min_child_weight [default=1]
- 3. max_depth [default=6]
- 4. gamma [default=0, alias: min_split_loss]
- 5. subsample [default=1]
- 6. colsample_bytree [default=1]
- 7. colsample_bylevel [default=1]
- 8. lambda [default=1, alias: reg_lambda]
- 9. alpha [default=0, alias: reg_alpha]
- 10. scale_pos_weight, [default=1]
XGBoost简介
XGBoost号称“比赛夺冠的必备大杀器”,横扫机器学习竞赛罕逢敌手,堪称机器学习算法中的新女王!
在涉及非结构化数据(图像、文本等)的预测问题中,人工神经网络显著优于所有其他算法或框架。但当涉及到中小型结构/表格数据时,基于决策树的算法现在被认为是最佳方法。而基于决策树算法中最惊艳的,非XGBoost莫属了。
打过Kaggle、天池、DataCastle、Kesci等国内外数据竞赛平台之后,一定对XGBoost的威力印象深刻。XGBoost号称“比赛夺冠的必备大杀器”,横扫机器学习竞赛罕逢敌手。最近甚至有一位大数据/机器学习主管被XGBoost在项目中的表现惊艳到,盛赞其为“机器学习算法中的新女王”!
XGBoost最初由陈天奇开发。陈天奇是华盛顿大学计算机系博士生,研究方向为大规模机器学习。他曾获得KDD CUP 2012 Track 1第一名,并开发了SVDFeature,XGBoost,cxxnet等著名机器学习工具,是Distributed (Deep) Machine Learning Common的发起人之一。
XGBoost实现了高效、跨平台、分布式gradient boosting (GBDT, GBRT or GBM) 算法的一个库,可以下载安装并应用于C++,Python,R,Julia,Java,Scala,Hadoop等。目前Github上超过15700星、6500个fork。
安装XGBoost
pip install xgboost - i https://pypi.douban.com/simple
使用豆瓣云 速度超快的
代码
原始
导入xgboost
import xgboost
导入相关库及数据,数据后面附地址
# First XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
dataset
分割数据集,安装属性和标签分别分割
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
Y
训练,预测,评估

# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))

查看训练过程
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# fit model no training data
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
# make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))

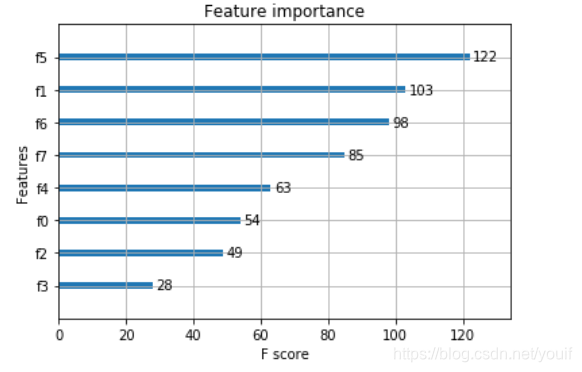
查看特征重要性
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
y = dataset[:,8]
# fit model no training data
model = XGBClassifier()
model.fit(X, y)
# plot feature importance
plot_importance(model)
pyplot.show()
调参 查找最好的学习率
# Tune learning_rate
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
# load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
# grid search
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
params = grid_result.cv_results_['params']
for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))

对XGBoost主要参数进行解释,方括号内是对应scikit-learn中XGBoost算法模块的叫法。
提升参数
虽然有两种类型的booster,但是我们这里只介绍tree。因为tree的性能比线性回归好得多,因此我们很少用线性回归。
1. eta [default=0.3, alias: learning_rate]
学习率,可以缩减每一步的权重值,使得模型更加健壮: 典型值一般设置为:0.01-0.2
2. min_child_weight [default=1]
一个子集的所有观察值的最小权重和。如果新分裂的节点的样本权重和小于min_child_weight则停止分裂 。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合。
3. max_depth [default=6]
树的最大深度,值越大,树越大,模型越复杂 可以用来防止过拟合,典型值是3-10。
4. gamma [default=0, alias: min_split_loss]
分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。
5. subsample [default=1]
构建每棵树对样本的采样率,如果设置成0.5,XGBoost会随机选择一半的样本作为训练集。
6. colsample_bytree [default=1]
列采样率,也就是特征采样率。
7. colsample_bylevel [default=1]
构建每一层时,列采样率。
8. lambda [default=1, alias: reg_lambda]
L2正则化,这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。
9. alpha [default=0, alias: reg_alpha]
L1正则化,增加该值会让模型更加收敛
10. scale_pos_weight, [default=1]
在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛。
学习目标参数:
这个参数用来控制理想的优化目标和每一步结果的度量方法。
1、objective[默认reg:linear]
这个参数定义需要被最小化的损失函数。常用的值有:
· reg:linear:线性回归
· reg:logistic:逻辑回归
· binary:logistic 二分类的逻辑回归,返回预测的概率
· binary:logitraw:二分类逻辑回归,输出是逻辑为0/1的前一步的分数
· multi:softmax:用于Xgboost 做多分类问题,需要设置num_class(分类的个数)
· multi:softprob:和softmax一样,但是返回的是每个数据属于各个类别的概率。
· rank:pairwise:让Xgboost 做排名任务,通过最小化(Learn to rank的一种方法)
2、eval_metric( 默认值取决于objective参数的取值)
· 对于有效数据的度量方法。
· 对于回归问题,默认值是rmse,对于分类问题,默认值是error。
· 典型值有:
rmse 均方根误差
mae 平均绝对误差
logloss 负对数似然函数值
error 二分类错误率(阈值为0.5)
merror 多分类错误率
mlogloss 多分类logloss损失函数
auc 曲线下面积
参数调优的一般步骤
1. 确定学习速率和提升参数调优的初始值
2. max_depth 和 min_child_weight 参数调优
3. gamma参数调优
4. subsample 和 colsample_bytree 参数优
5. 正则化参数alpha调优
6. 降低学习速率和使用更多的决策树
个人微信公众号,专注于学习资源、笔记分享,欢迎关注。我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活,,如果觉得有点用的话,请不要吝啬你手中点赞的权力,谢谢我亲爱的读者朋友。


Doing what you love is the cornerstone of having abundance in your life.— Wayne Dyer
「做你爱做的事是拥有富足人生的基石。」– 韦恩 戴尔
参考:https://www.cnblogs.com/LHWorldBlog/p/9195623.html
代码数据链接:https://pan.baidu.com/s/1otk7l8Z90TfNIj6EYnDiAA
提取码:40zb
XiangLin
2020年3月14日于重庆城口
好好学习,天天向上,终有所获