本文由readlecture.cn转录总结。ReadLecture专注于音、视频转录与总结,2小时视频,5分钟阅读,加速内容学习与传播。
大纲
-
引言
-
介绍大模型的训练方法
-
强调大模型在多领域的应用
-
-
大模型的训练阶段
-
预训练过程
-
Tokenization的重要性
-
预训练模型的历史发展
-
从词向量到ELMO模型
-
Transformer模型的引入
-
-
-
后训练过程
-
对齐(alignment)和适配(adaptation)
-
后训练的重要性
-
-
-
具体模型介绍
-
GPT系列
-
GPT-1的架构和训练方法
-
GPT-2的扩展和多任务能力
-
GPT-3的巨大参数和泛化能力
-
-
BERT模型
-
BERT的双向注意力机制
-
BERT的应用和效果
-
-
T5模型
-
T5的Text-to-Text格式
-
T5的编码器-解码器架构
-
-
-
语言建模的本质
-
语言模型的基本原理
-
语言模型的多任务学习能力
-
-
对齐和后训练
-
对齐的重要性
-
对齐的方法和挑战
-
-
参数高效的微调
-
Adapter方法
-
Prefix Tuning
-
LoRA方法
-
-
指令微调和偏好学习
-
指令微调的概念
-
偏好学习的实现方法
-
-
总结和未来展望
-
大模型的当前状态
-
未来的研究方向和挑战
-
内容总结
一句话总结
本文深入探讨了大模型的训练方法,包括预训练、后训练、具体模型的介绍、语言建模的本质、对齐和后训练、参数高效的微调、指令微调和偏好学习,以及未来的研究方向。
观点与结论
-
大模型通过预训练和后训练两个阶段,能够在多领域发挥作用。
-
语言建模的核心在于使用前面的标记(token)来预测下一个标记,这种能力可以扩展到多任务学习。
-
对齐和后训练是确保模型输出符合人类期望的关键步骤。
-
参数高效的微调方法,如Adapter、Prefix Tuning和LoRA,可以大幅降低微调所需的资源。
-
指令微调和偏好学习是当前大语言模型的核心能力,能够实现零样本泛化。
自问自答
-
大模型的训练主要分为哪两个阶段?
-
预训练过程和后训练过程。
-
-
为什么大模型能在多领域发挥作用?
-
因为任何信息都可以被转化为token,大模型处理的是token,而非单纯的语言。
-
-
什么是语言建模的本质?
-
使用前面的标记(token)来预测下一个标记。
-
-
对齐和后训练的重要性是什么?
-
确保模型输出符合人类期望,增强模型的稳定性和鲁棒性。
-
-
参数高效的微调有哪些方法?
-
Adapter、Prefix Tuning和LoRA。
-
-
指令微调和偏好学习的区别是什么?
-
指令微调是通过增加上下文来描述任务,而偏好学习是通过人类反馈来优化模型输出。
-
关键词标签
-
大模型
-
预训练
-
后训练
-
语言建模
-
对齐
-
参数高效微调
-
指令微调
-
偏好学习
适合阅读人群
-
人工智能研究人员
-
机器学习工程师
-
数据科学家
-
计算机科学学生
术语解释
-
Tokenization: 将文本或其他信息转化为离散单元(token)的过程。
-
预训练: 在大规模无监督语料上训练模型的过程。
-
后训练: 在有监督的数据上进一步训练模型的过程。
-
对齐: 调整模型输出以符合人类期望的过程。
-
参数高效微调: 使用较少资源更新模型参数的方法。
-
指令微调: 通过增加上下文来描述任务,使模型能够理解和执行。
-
偏好学习: 通过人类反馈来优化模型输出的过程。
视频来源
Lecture 4 大模型学习方法_哔哩哔哩_bilibili
讲座回顾
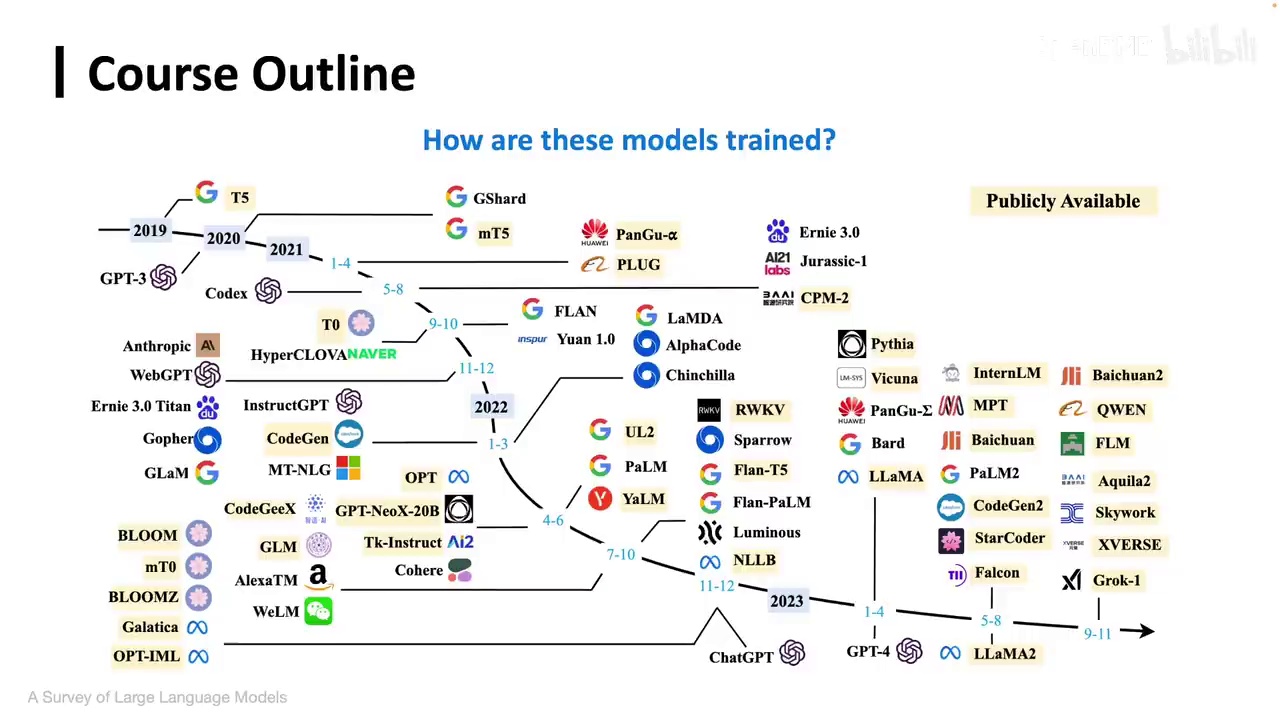
大家好,欢迎大家参加本次大模型暑期课程。今天我们将探讨大模型的训练方法。众所周知,当前的大模型数量远不止图示所示。

那么我们核心要讲清楚一个问题,即这些模型是如何训练的。实际上,它们主要经历了两个阶段:预训练过程和后训练过程。
我们需要先搞清楚一个问题:为什么大模型能在每个领域都发挥作用。实际上,不仅限于文本处理,尽管它被称为大语言模型,但它现在已广泛应用于多模态领域,包括音频、视频,以及医疗、金融和教育等行业。

-
大语言模型处理token而非单纯语言。
-
文本、图像、DNA、工具和电磁波等均可转化为token。
-
转化后的token可被学习和泛化,是大语言模型发挥作用的关键。
-
训练大语言模型时,首先进行tokenization,将信息转化为离散单元。
-
常用的tokenization方法包括BPE,采用分支结构处理。
他都能发挥作用。实际上,这基于一个非常基本的假设:任何信息都可以被转化为token。大语言模型处理的是token,而非单纯的语言。因此,文本、图像、DNA、工具和电磁波等都可以转化为token,这些token随后可以被学习和泛化。这就是大语言模型发挥重要作用的关键。在训练大语言模型时,第一步是进行tokenization,即将所需信息(如文本、图片等)转化为离散单元,然后送入模型中。有许多方法可以进行tokenization,例如常用的BPE方法,它采用类似分支的结构来处理。这些token将进一步被泛化。

-
早期NLP研究中的词向量是context-free的,即同一个词在不同语境下的向量表示相同。
-
词向量的context-free特性导致同一个词在不同语境下的不同含义无法区分。
-
ELMO模型是第一个实现contextualized pre-training的模型,其词向量随上下文变化。
-
ELMO模型的表示包括固定的词向量、每一层的表示加总形成的ELMO词向量。
-
ELMO模型的特点是contextualized和deep,效果远超之前的固定词向量方法。
在大模型之前的NLP研究中,这些embeddings都经过了预训练。我们那时也有预训练,只不过我们训练的是所谓的词向量。这些词向量有一个非常大的特点,就是它们是context-free的,即同一个单词在不同语境下表示的向量是一样的,即使它有不同的含义。例如,“bank”既可以指银行,也可以指河岸,但它们的向量表示是一样的。这显然不合理,因为很多词在不同的句子中表达着不同的意思,可能不是词典中分割的意思,但也有可能是一些非常微妙的细小差别。因此,后来我们希望这些词向量或在大模型中的表示能随上下文变化,于是有了ELMO模型。ELMO是第一个发现contextualized pre-training的模型,即所有的词向量和表示都是随上下文变化的,每句话送进去后,其内部表示都不同。这里我们要训练的模型不仅仅是词向量,而是整个模型,其表示有三种:固定的词向量本身、每一层的表示加起来,形成一个ELMO词向量,但实际计算稍微复杂一些。ELMO模型是一个里程碑式的工作,它彻底打开了预训练模型的基础,contextualized pre-training从此开始。它的两个最大特点,一是contextualized,即所有词向量都由上下文决定;二是deep,即它非常深,由多个神经网络层结合而成,而不是之前可能只有一个简单的神经网络来训练词向量。其效果当时也非常好,远远超越了固定的词向量方法,如word2vec。2017年后,我们有了比LSTM更好的模型。

-
Transformer模型采用自注意力架构,适合训练上下文相关的词向量。
-
每个Token在Transformer中都与其上下文相关。
-
基于Transformer的预训练语言模型分为三种类型:仅编码器、编码器-解码器和仅解码器。
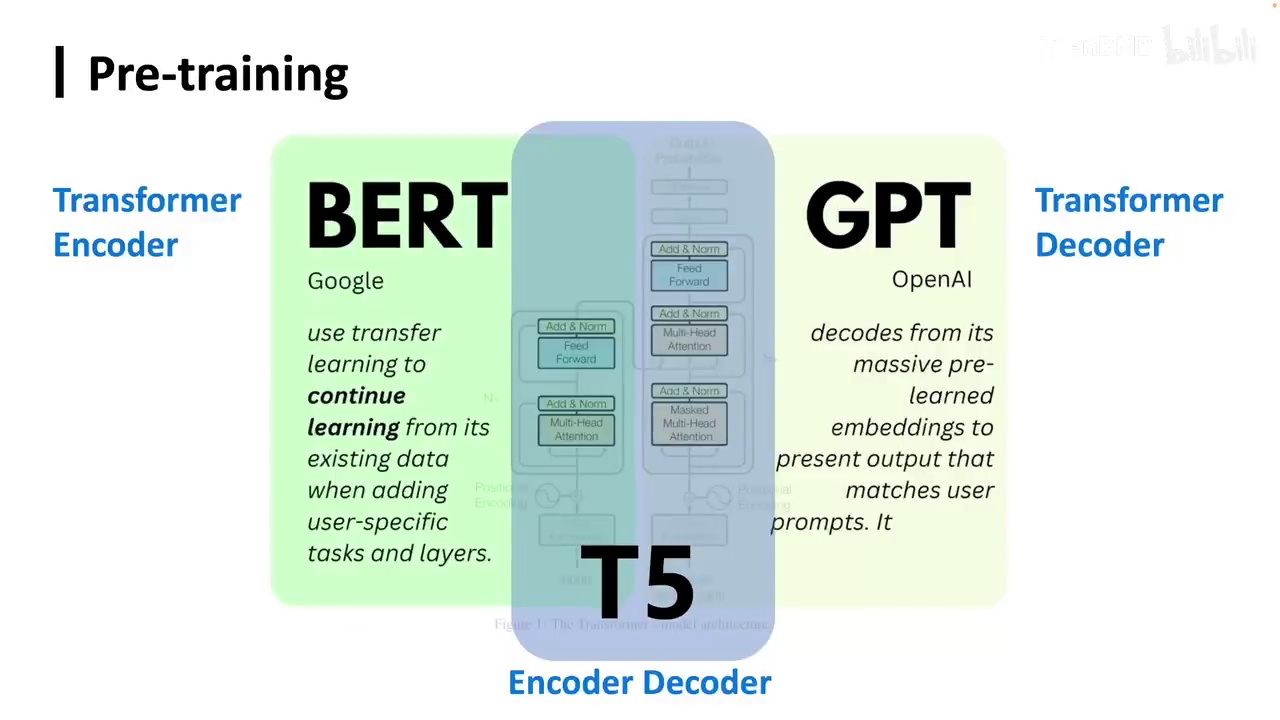
或者比RNN更强大的神经网络模型,大家应该已经了解,即Transformer。在前面的课程中已经介绍过,Transformer采用了一种自注意力(Self Attention)架构。实际上,我们可以将其与上下文相关的表示(Contextualized representation)进行比较,它非常适合训练上下文相关的词向量。这是因为每个Token都会注意到其他Token,因此每个Token都与其上下文相关。这自然导致了基于Transformer的预训练语言模型的出现。基于Transformer的预训练语言模型有很多,主要包括三种类型:仅编码器(Encoder only)、编码器-解码器(Encoder Decoder)和仅解码器(Decoder only)。它们实际上采用了Transformer的不同部分。以及他采用的不同训练目标。
-
三个代表性模型:BERT、GPT、T5
-
GPT是最受欢迎的模型
-
GPT是第一个基于Transformer的预训练语言模型
-
Transformer最初设计用于翻译任务
-
GPT采用Transformer结构和传统的语言模型方法
-
GPT的训练方式是从左到右,利用前面的Token预测下一个Token
-
微调过程中,GPT利用最后一个单词的表示来预测任务标签
那么它的三个代表性模型是BERT、GPT和T5。接下来我们将详细介绍这三个模型。首先来看GPT,目前它是最受欢迎的模型。GPT是第一个基于Transformer的预训练语言模型。最初,Transformer被设计用于翻译任务。可能连Transformer的作者也未曾预料到它会被用于预训练,或被广泛应用于多种任务。GPT正是基于这一发现,采用了Transformer结构,并结合传统的语言模型方法,即利用前面的Token预测下一个Token,从而实现从左到右的训练方式。如图所示,例如一个单词仅能看到其前两个单词,并据此预测下一个单词。在微调过程中,GPT会利用最后一个单词的表示来预测任务标签。这就是GPT的注意力机制架构,它通过利用前面单词的概率来预测下一个单词。

-
在实际使用中,采用attention mask防止模型看到后续单词。
-
GPT之后引入了更强大的模型Bert。
-
Bert在NLP研究领域当时尚未广泛应用,但技术革新已显现。
我们在实际使用中会采用attention mask,以防止模型看到后续的单词。在GPT之后,我们引入了一个更为强大的模型,即Bert。在当时,Bert在NLP研究领域中尚未被广泛应用,但其带来的技术革新已初露端倪。

-
BERT开启了预训练语言模型的新领域。
-
方法:随机遮盖输入序列中的部分单词(token),预测这些被遮盖的token。
-
遮盖比例:15%,此比例经过实验确定。
-
目标函数:遮蔽语言模型,与传统语言模型不同。
-
注意力机制:传统模型使用单向注意力,遮蔽语言模型使用双向注意力。
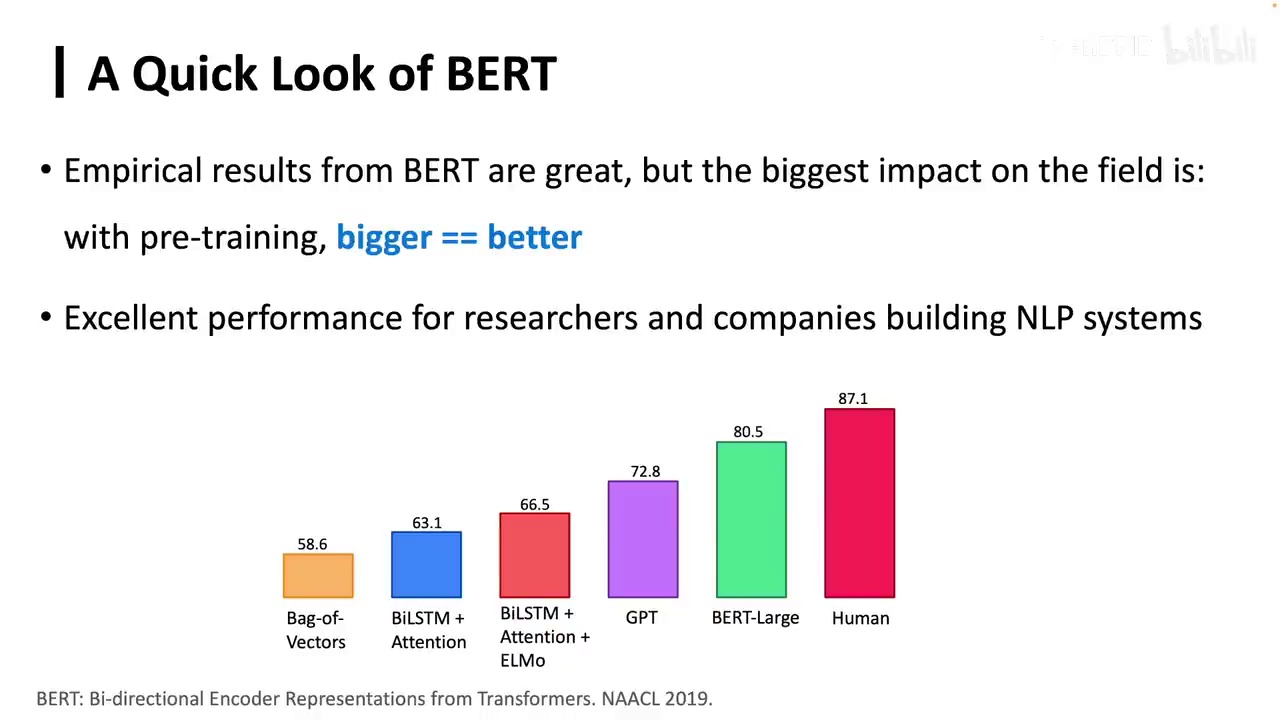
我们在自然语言理解任务上的表现远远超越了当时最先进的方法,甚至在许多任务上超越了人类的表现。在BERT之后,预训练语言模型这一领域才真正被打开。其方法相当简单:对于一个输入序列,我们随机遮盖其中的一些单词或称为token,然后预测这些被遮盖的token。遮盖的比例为15%,这一比例是经过实验得出的。我们可以看到,这种目标函数称为遮蔽语言模型,与传统语言模型有所不同。区别在于,传统模型采用单向注意力机制,而遮蔽语言模型则采用双向注意力机制。

-
BERT模型采用双向建模,能够同时利用前后文信息。
-
当前主流模型多采用单向建模,原因和优势待探讨。
-
BERT还使用预测下一个句子的目标函数,但实验显示其效果不佳。
在这个目标函数中,被遮盖的模型既可以看到前面的上下文,也可以看到后面的上下文。理论上,BERT似乎能够比GPT学到更多的信息。然而,为什么我们现在的模型都是单向建模呢?单向建模相比双向建模的优势在哪里?或者说它为什么能够扩展?大家可以先提前思考一下,稍后我们将回答这个问题。BERT除了使用遮盖token的策略外,还采用了另一个目标函数,即理解不同句子之间的关系。因此,它还有一个目标是预测下一个句子。在训练过程中,由于我们有大量的预料,它会训练模型判断下一个句子是否是真正的下一个句子,或者是一个随机的其他句子。但后来有许多实验证实,这个目标函数其实并不那么有效。实际上,它可能还不够本质,最本质的做法是我们使用这个目标函数。
-
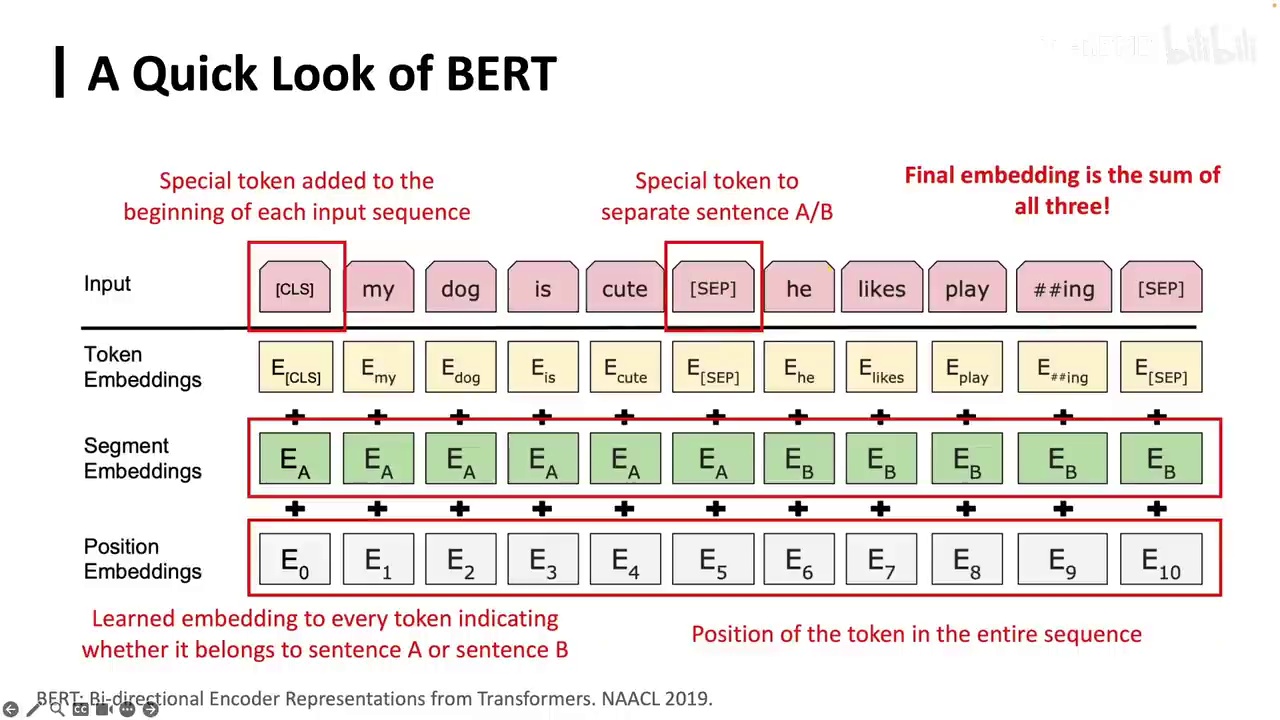
BERT的输入包括文本token和特殊token,特殊token如CLS和SEP分别表示句子的开始和分割。
-
可以自定义特殊token,例如用O表示OpenBMB。
-
每个token有三种embedding:token embedding、segment embedding和position embedding,这些embedding相加得到最终embedding。
-
CLS的最终embedding常用于文本分类任务,如情感分类。
-
在关系抽取任务中,可以在实体前添加特殊token,并使用其embedding进行关系抽取。
-
BERT主要用于自然语言理解,学习到的表示可用于多种自然语言处理任务。
我们只需对token进行预测。详细来看BERT的运作机制,首先输入是一系列token。除了文本token外,还有一些特殊token,这些特殊token具有特定含义。实际上,我们可以添加任何特殊token来表示任何含义。例如,添加一个O代表OpenBMB,这是可行的。在BERT中,token的含义包括:首先有一个CLS token,代表classification,表示每个句子的开始;还有一个SEP token,表示两个句子之间的分割,告诉模型当前句子结束,准备进入下一个句子。
关于embedding,每个token有自己的embedding,类似于词向量。此外,还有segment embedding,表示token属于前一个句子还是后一个句子(A、B或C)。还有position embedding,表示token在序列中的位置,因为self-attention结构本身不包含位置信息。我们将这些embedding相加,得到token的最终embedding,用于各种任务。
一个常见的情况是使用CLS的最终embedding进行文本分类,如情感分类。在关系抽取任务中,我们可能在两个实体前添加一个特殊token,然后使用这个特殊token的embedding进行关系抽取。BERT主要用于自然语言理解,学习这些表示后,我们可以将其用于传统的神经网络和机器学习自然语言处理任务。
-
BERT模型在多个任务上超越了人类表现。
-
BERT提出了Bert-Base和Bert-Large两个模型,大模型表现更好。
-
训练Bert-Large需要大量计算资源,成为资源充足的标志。
-
T5模型继承了BERT的规模扩展,将所有任务转换为Text-to-Text格式。
-
T5采用encoder-decoder架构,与BERT和GPT的表征利用方式不同。
-
GPT虽然只采用Transformer的decoder,但被认为具备理解能力。
BERT的效果确实非常出色,它是在GPT之后出现的,但在当时为我们提供了许多计划。自然语言处理的研究者带来的震撼远胜于GPT。在很多任务上,BERT都超越了人类,并且提出了一个非常重要的观点:训练了两个模型,Bert-Base和Bert-Large,越大的模型表现越好。如果我没有记错,BERT应该是第一个提出这一观点的,并非后续进行规模扩展的GPT。当时,作为自然语言处理的研究者,我们都想知道谁能选择Bert-Large,即谁拥有足够的计算资源来训练一个Bert-Large,这被认为是计算资源充足的标志。而现在,我们能够操作的模型已经远远超过了这个量级。在BERT之后,有一个模型继续这种规模扩展,即我们所说的T5。它实际上将所有的自然语言处理任务,无论是分类还是生成,都转换成了Text-to-Text格式,即输入是一堆文本,输出也是一堆文本,即使是一个分类任务,也是一个Token。之前的BERT或GPT,在使用时,我们实际上是利用它们的表征来进行分类任务,输出的是经过Softmax后的分类概率,例如在Class A和Class B的概率。而T5则认为,干脆不要这些了,所有的东西都变成文本到文本的形式,采用了encoder-decoder架构。我们稍微强调一下,GPT采用的是Transformer的decoder,即它只负责生成,但现在我们认为它也具备理解能力。
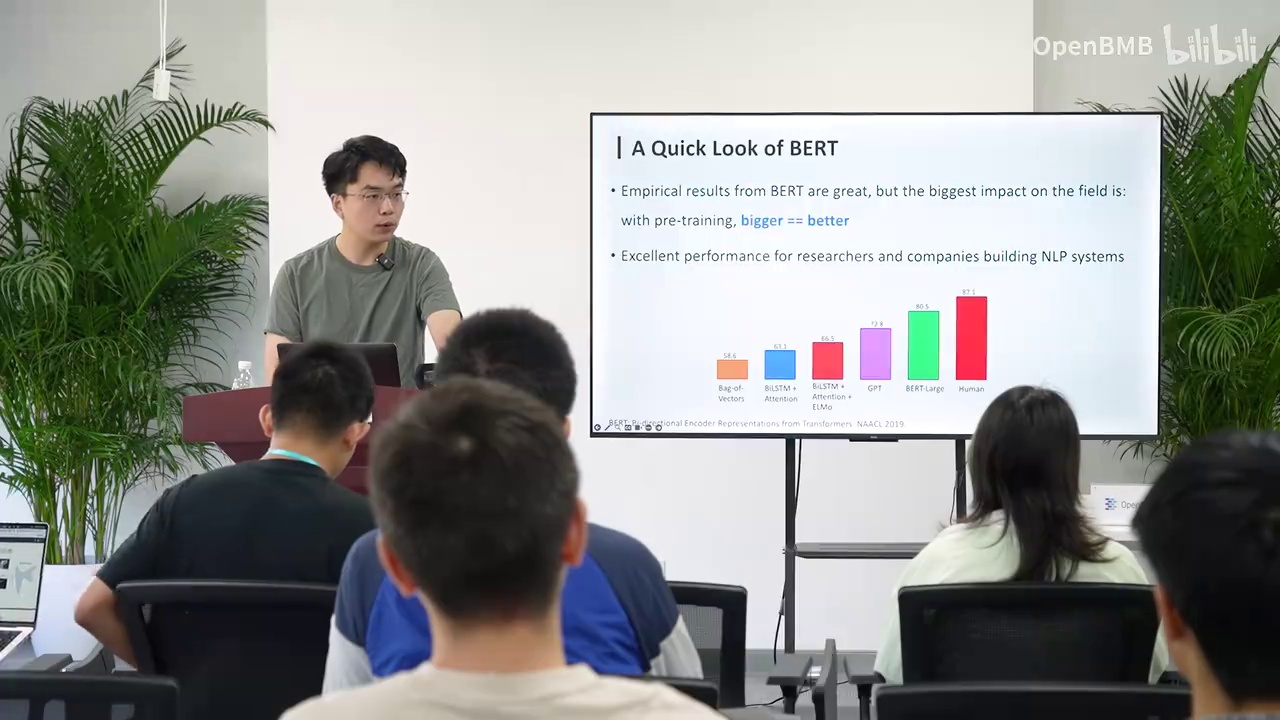
BERT主要强调理解,因此采用Transformer的encoder架构。T5首先使用encoder进行文本理解,然后通过decoder进行单向生成。在此过程中,它会mask掉一些短语。

-
NLP任务统一性:所有自然语言处理任务可以统一到一个语言模型中。
-
预训练任务分类:预训练阶段分为BERT、自回归模型(如GPT)和T5三种方法。
-
语言建模本质:语言建模使用前面的标记预测下一个标记,本质上是计算条件概率。
-
概率计算方法:通过乘积计算序列概率,使用对数函数避免数值下溢,计算最大似然概率。
-
语言建模复杂性:语言建模不仅涉及模仿和记忆,还包括世界知识、推理和编码等。
T5的编码器接收输入,解码器则预测被遮蔽的输出。这给我们一个重要的启示:所有自然语言处理(NLP)任务都可以统一到一个语言模型中。在预训练阶段,我们可以将其分为三种任务。首先是BERT,它在预测S3时可以看到所有标记,无论是前还是后。其次是自回归模型,如GPT所采用的传统语言模型,在预测Y1时只能看到前面的标记。最后是T5所采用的方法,先通过编码器理解输入,再通过解码器生成所需内容。目前,几乎所有模型都采用单向的自回归GPT语言模型。我们可能会思考,这种模型是否比其他模型更本质,或更易于扩展和规模化。接下来,我们将探讨语言建模的本质,实际上非常简单,可以用两句话概括:它使用前面的标记(token)来预测下一个标记。具体来说,就是用前面的n-1个标记来预测第n个标记。当然,中间可能会有一些技巧,例如我们可能不想使用n-1个那么多,而只想使用5个或10个等。但本质上,它只是在计算条件概率。如果要计算整个序列的概率,就是将P(w1)、P(w2|w1)等全部相乘,得到整个序列的概率。由于这个概率可能非常小,我们可能会在前面加上对数函数,以避免数值下溢,然后再除以n分之一,得到所谓的最大似然概率。例如,“never to read, to learn, to code, to read”在自然语言中都是可能出现的。因此,在进行语言建模时,我们关注的不是正确的标记是什么,而是概率。当我们学习到这些概率时,就可能理解世界运行的方式。当我们预测下一个标记时,不仅仅是在模仿或记忆,实际上包含了多种内容,如世界知识、推理或编码等。因此,语言建模是一个非常复杂且多维的过程。

-
描述了一种可能的多任务学习模型,该模型在预测下一个token的过程中学习多种技能。
-
学习的技能包括语法、词法、世界知识、文本分析、情感分析、翻译、数学、代码等。
-
提出扩展token的类型,包括音频、图像、气压等,以探索更广泛的学习领域。
我们认为它可能是一种极致的多任务学习。在预测下一个token的过程中,它可以学习到语法、词法、世界知识、文本分析、情感分析、更难的文本分析、翻译、数学、代码等。当我们扩展token到不仅仅是语言时,如果它是音频、图像,甚至是空气中的每个气压,大家可以思考一下。

-
语言建模的核心在于其智能程度。
-
智能不足可能导致对模型能力和智慧的质疑。
-
语言建模具有巨大的潜力和机会。
关于语言建模的本质,我们可以参考前OpenAI首席科学家伊利亚·苏茨克弗(Ilya Sutskever)的阐述。语言建模的核心在于,如果建模不够智能,我们可能会质疑这些模型的能力和智慧。尽管这些模型可能并不存在,但语言建模提供了极大的潜力和机会。

-
讨论了如何行动的问题。
-
提出了获取证据的来源问题,建议从普通人的数据中获取。
-
探讨了如何表达预测下一个token的意义。
这些人应该如何行动?是的,但是我们应该从哪里得到这种证据?从普通人的数据,因为如果我们考虑一下,这意味着什么?我们应该如何能够表达预测下一个token?这其实是一个更深入的问题。评估预测下一个token的意义是什么?我们应该如何能够表达预测下一个token的意义?

-
作者认为预测下一个token不仅仅是统计行为。
-
当模型规模足够大时,预测过程可能涉及对世界本质的理解。
-
预测下一个token的过程被视为一种信息压缩。
他认为预测下一个token不仅仅是进行统计,而是当模型规模足够大时,它实际上在理解世界的本质。虽然这种说法可能有些夸张,但我们发现预测下一个token的过程本身可能是一种压缩。这种压缩,即预测下一个token的过程,实际上是在对信息进行压缩。

-
语言建模的优势在于其依赖于语料库,不需要人工标注。
-
高质量语料虽然理想,但包含噪音或杂质的语料也可能对语言模型有益。
在他的神经网络参数中,我们不再深入探讨。语言建模的一个显著优势是它仅依赖于语料库。尽管我们可能需要高质量的语料,但实际上,即使是包含噪音或杂质的语料,也可能有助于语言模型的理解。语言建模不需要人工标注,例如,A属于互联网领域。

-
情感关注:A所表示的情感不需要特别关注。
-
模型处理:模型不要求统一格式或结构化解析,只需准备和清洗语料库。
-
GPT模型构建:通过语料库使用神经网络预测下一个token,构建GPT模型。
-
困惑度评估:使用困惑度衡量语言建模效果,计算方法包括计算文本概率、取自然对数、除以n、加负号、取指数。
-
模型理解评估:低困惑度表示模型对数据集理解较好,每个token概率较高。
A所表示的情感实际上并不需要特别关注。此外,该模型也不要求我们将所有语言和文本统一格式,或者进行结构化解析等复杂处理。我们只需准备一个语料库,并进行必要的清洗和配比,这些内容将在后续部分详细讲解。简而言之,通过这些语料库,我们可以使用神经网络来预测下一个token,从而得到一个GPT模型。衡量语言建模效果的一个有效方法是使用困惑度。困惑度本质上是对预测下一个token的逆过程的度量。其计算方法较为复杂,具体来说,我们需要计算整个文本的概率表示,这是计算的分母部分。在计算出整个文本的概率表示后,取其自然对数,再除以n,并在前面加上负号,这样就转换为交叉熵。为了防止数值过大导致难以阅读,我们再对其取指数,从而得到PPL,即困惑度。困惑度可以用来评估任何模型对任何数据的理解程度。如果一个模型对某数据集的困惑度很低,我们就可以认为该模型对该数据集的理解较好,因为每个token的概率都较高。

-
语言模型与困惑度:单个token的概率可能不准确,但通过困惑度可以评估模型在特定领域(如生物医疗)的表现。
-
GPT-1的训练方法:第一代GPT模型通过语言建模进行训练,拥有一亿多个参数,阅读了7000本书,训练量在当时是有限的。
-
训练过程:GPT-1首先进行无监督预训练,然后进行下游任务的微调,如文本分类任务中使用最后一个隐藏状态和线性层进行微调。
-
OpenAI的发展阶段:在GPT-1时期,OpenAI可能还停留在传统的ROP任务中,尚未开发出更先进的模型。
实际上,单看一个token,其概率可能并不准确,因为我们实际上没有正确答案。但是,当我们把这个指标放到困惑度中时,例如我们现在要训练一个生物医疗的模型。现在我们有一段生物医疗的文本,包括DNA片段等。那么当模型在这个文本上困惑度低时,就说明它比较擅长生物医疗,我们可以简单地这样认为。因此,现在我们讨论了语言建模,再回过头来看GPT-1,即第一代的GPT,它是通过这种语言建模的方式进行训练的。它拥有一亿多个参数,并阅读了大约7000本书。实际上,这个训练量在我们现在看来是非常小的,7000本书的训练量可能连现在的万分之一都不到。但当时它就是这样做的,首先是通过无监督的预训练,在这7000本书上进行一个token一个token的预测。然后在下游任务的过程中,它还是进行了微调,即做了fine-tuning。例如,在文本分类任务中,它使用了最后一个隐藏状态,即最后一个表示,然后接入了一个线性层。这个线性层会输入一个分类的01向量,并通过softmax进行微调。因此,在这个时候,我们认为至少在这个阶段,OpenAI可能还没有开发出像现在这样的GPT,它的思维可能还停留在传统的ROP任务中。我们仍然希望训练一个模型来解决这些问题。

-
初代GPT在震撼程度上不及BERT。
-
GPT-2通过扩展和增加训练数据量,展示了单向语言模型的可扩展性。
-
GPT-2能够处理多个任务,开启了从传统LOP到更大语言模型的转变。
-
OpenAI希望通过扩大模型来解决单任务训练的局限性,实现多任务的泛化。
-
GPT-2和GPT-3的论文被认为是高质量的。
因此,这也是初代GPT没有BERT更加震撼的原因。然而,到了GPT-2,情况略有改变。首先,他们进行了扩展,证明了这种单向语言模型也能够进行扩增。其次,其训练数据量也增加了。GPT-2开始能够解决不止一个任务,而是多个任务。他们认为这个语言模型本身具有可扩展性。在此,我强烈推荐大家阅读GPT-2的原论文。直到现在,我也认为这是我见过的写得最好的一篇论文之一。实际上,我们可以看到OpenAI在这个时候,尽管GPT-2的地位可能比GPT-1还要低,但我认为它被低估了。因为它开启了OpenAI从传统的LOP到更大的语言模型的转变,在GPT-2时期就已实现。只是他们当时还没有将参数扩增到1750亿。在原论文中,他们认识到对于一个传统的机器学习系统,针对单个任务进行训练和微调,导致其不能在多任务上进行泛化。这实际上意味着一些小的改动就可能引起整个系统的崩溃。因此,他们希望通过一种更根本的方法来解决这个问题。他们的方法就是扩大GPT-1,将GPT-1的下一个Token预测进行扩增。因此,他们认为在开始进行下一个Token预测时,我们就可以实现多任务的共同完成。这里就不详细念了,大家可以仔细阅读这篇论文。GPT-3的论文也写得非常好。接下来的故事我们就都知道了。

-
GPT-3是首个扩展到1750亿参数的语言模型,处理数据量远超以往。
-
OpenAI使用GPT-3在Reddit或Quora上进行回帖实验,长时间内未被识别为模型。
-
在NLP领域,之前主要关注情感分类、翻译等任务,较少考虑跨任务泛化。
现代大语言模型的一个重要转折点是GPT-3,它首次将语言模型扩展到了1750亿参数,并且处理的数据量远超以往的模型。我记得当时OpenAI进行了一个实验,使用GPT-3在Reddit或Quora上回帖。实验进行了很长时间,但没有人意识到那是一个模型,这给人带来了极大的震撼。因为在NLP领域,我们之前认为让模型按照指令执行任务是不太可能的。我们之前主要关注于情感分类、翻译或一些简单的生成任务,很少有人考虑跨任务泛化的问题,即任务本身的概念。

-
In-context Learning特性:大型模型如GPT-3具有情境学习能力,能在不微调的情况下通过提供示例来学习新任务。
-
模型应用:通过提供英文到法语的翻译示例,模型能学习并执行翻译任务。
-
泛化能力:GPT-3的意义在于其泛化能力,能处理多种任务,而不仅仅是单一任务的优化。
-
学术界反应:尽管GPT-3在公众中引起震撼,但学术界对其应用和效果持保留态度,认为微调模型如Bert和Roberta在特定任务上表现更优。
它在这里似乎被模糊化了。然后它有一个非常强大的特性,叫做In-context learning。我们来看一下。我们看不到这些模型,但是当它变大了,我们就能看到了。我们来看一下评论问题。在传统的机器学习中,我们必须给模型提供数百个例子的评论,然后模型会学习这些评论。但是在这里,我们给模型一些例子,然后它能学习我们想要的东西。我们看到很多模型能学习这些模型的行为。比如说,我们来看一下这些数学学习的例子。关键是,一个小模型,并不明白这些。这些模型的确实比较丰富。但是,我们来看一下这些大型模型的行为。它们明白如何解决这些问题。我们看到这些模型的行为,对。其实这个视频讲的主要是所谓的涌现的能力。
实际上,它一个最重要的涌现能力,我们能看到的就是叫情境学习,或者叫上下文学习,或者英文就叫in-context learning。它的做法也非常简单。当我们训练了一个1750亿参数的模型之后,我们就不微调它了。然后呢,我们想让它完成一个翻译任务,怎么办呢?我们就告诉它,你就把英文翻译成法语就行了。如果它好像翻译得不太好的话,我们很简单。就在前面加一些例子。比如说,这里的第二行,第三行,第四行,都是英文翻译成法语的例子。然后呢,我们再给一个第四行,然后让它翻译成法语。然后呢,我们再给一个第四行,然后让它翻译成法语。然后呢,我们再给一个第四行,然后让它预测下一个token,然后再预测下两个token等等。
这就是GPT-3。这时候呢,我们已经几乎没有任务的概念了。我们有一个超级大的模型,然后呢,我们告诉它做啥,它就能做什么。虽然很多任务上可能做的还是没有一些微调过的模型好。我记得GPT-3出来的时候好像,其实这个对学术界的影响可能没有大家想的这么大。尽管大家都觉得非常震撼,但实际上学术论文中并没有太多使用GPT-3的。或者说,好多研究者都认为,我在一个语料上微调一下我的模型,微调一下我的Bert,我的Roberta,比你的GPT-3好。那你这个有什么意义呢?我做不了我的情感分类任务,关系抽取任务,你做的没我好,而且你还这么大。实际上GPT-3的意义并不在于它做一个任务做的有没有Bert好,或者说有没有现在的所谓的最好的模型好。它的意义就在于泛化性,它能够泛化到无数的,只要能用Token表示的任务上。然后呢,我们告诉它做什么,它就可以做什么。这个呢,我们的想象力上限才会更高。但是实际上,在我的记忆中。

当时的NLP研究者几乎很少有人认识到这一点。在GPT-3之后,OpenAI推出了我们现在都熟悉的ChatGPT。但实际上,ChatGPT的构建方法与之前的模型有所不同。

-
InstructGPT是基于GPT-3的改进模型,通过后训练使其更遵循人类指令。
-
ChatGPT是InstructGPT的进一步发展,能更好地与人类对话,输出更准确、信息量更大且无幻觉的回答。
-
示例展示了GPT-3可能输出错误或重复语料中的内容,而InstructGPT则能输出更合适的回答。
他们之前的一个模型叫做InstructGPT,几乎是一模一样的。他们对GPT-3进行post-training,就是我们下一节要讲的内容,然后让它变得更加能够遵循人类的指令。ChatGPT就是它可以更好地与人类对话,从而输出更加有信息量、更加正确,然后更加没有幻觉的回答。比如说下面这就是一个例子。GPT-3它可能输出的东西是一个错的,或者说它在语料中见过的,然后它就输出成这样的。但是InstructGPT它就可以去输出。

-
GPT-4是继Instrcut和ChatGPT之后的最新AI技术。
-
GPT-4能够处理约25000个词汇,是ChatGPT的8倍。
-
GPT-4具备图像理解能力,能解释图像含义。
-
GPT-4能识别图像中的逻辑关系,如线条切断导致瓶子飞走。
-
AI技术存在不完美和错误,需要进一步验证。
正确的表述这种形式。在Instrcut和ChatGPT之后,我们又了解到有了GPT-4。它能够处理约25000个词汇,比ChatGPT多出约8倍。它能够理解图像,并能表达其含义。例如,它能告诉我们,如果画面的线条被切断,那瓶子就会飞走。这就是这些AI能够进行测试的地方。它们并不完美,会犯错误。我们还需要对它们进行验证。
我认为您知道这些工作是您的期望。但我认为这基本上是为了每个人都能做到的。GPT-4的训练在去年8月份已经结束。所有在过去的事情中所发生的事情。
-
该技术自推出以来已发展为大型标准,提升了安全性、效率和实用性。
-
技术内容包括考虑敌人利益、不受欢迎的内容及私人关注。
-
认识到技术发展是一个持续过程,需要不断学习、更新和提升。
-
技术在教育领域展现出巨大潜力,如GPT-4能提供个性化学习计划。
在过去的几个月中,自我们推出以来,它已经发展成为一个大型的标准,使其更加安全、高效和有用。我们已经纳入了许多内容,包括对敌人利益的考虑、不受欢迎的内容以及对私人关注的重视。当我们推出这一模式时,我们清楚地认识到这只是一个开始。我们知道我们需要不断学习、更新,并持续提升所有系统,以更好地适应社会需求。对我而言,这些技术的最复杂用户是那些真正基于人类需求而开始使用的人。这些系统在教育领域展现出了巨大的潜力。GPT-4能够教授大量的课程计划,设想为五年级学生提供无限的时间和耐心的个性化学习。它是一个极好的工具,能够为所有人带来学习的机会。

在他们的技术层面上,这种表达体现了人生中最有用和有帮助的梦想。其真正目的是为了帮助大家增加更多的价值。
每一天的生活都能实现。OpenAI的合作旨在将这种技术发展成能够帮助全球的工具。

-
AI技术与通信技术、计算机电流、中央互联网和计算机器紧密合作,有望提升生活质量。
-
尽管存在限制,但通信技术的成熟将带来深远影响。
-
GPT-4被视为首个专业智能AI系统的里程碑。
-
通信技术的应用受到广泛关注,不仅限于技术专家,也包括普通用户。
希望AI的力量能帮助我们更有效地提升生活质量。随着通信技术、计算机电流、中央互联网和计算机器的发展,所有这些领域都能与AI技术紧密合作。尽管目前还存在一些限制,但我们已经可以预见未来这些通信技术的成熟将带来的深远影响。我认为GPT-4将成为世界上首个专业智能AI系统的里程碑。我们非常关注这些通信技术的应用,不仅限于技术专家,也包括广大用户。

GPT-4自去年发布以来,尽管有许多模型声称超越了它,但我认为它仍然是当前最好的模型。

-
GPT-4被认为是当前最好的语言模型。
-
具体参数、数据量和架构细节未公开,OpenAI转变为CloseAI。
-
模型基于大型架构,可能在Transformer上优化,使用混合专家模型,并在大型语料库上训练。
-
应用范围扩展到编程、科学发现和教学等非传统语言任务。
-
模型处理能力不仅限于语言,还包括任何可序列化的数据。
-
训练和应用中,模型展现出高级智能和泛化能力。
总的来说,GPT-4应该是最好的。实际上,关于它使用了多少参数、多少数据以及使用了什么架构,我们都是不知道的,因为从这时起,OpenAI已经变成了CloseAI。但是可以预见的是,它仍然是一个语言模型,使用了一个非常大的架构,可能在Transformer上做了很多优化,也可能使用了混合专家模型,并在一个非常大的语料库上进行训练,展现出了更高级的智能。它已经不仅可以用在传统的语言任务上,实际上编程、科学发现甚至教学,我们都可以使用GPT-4来进行。所以到了这个节点上,我们可以去想象更多的应用。在我们传统的NLP中,我们可能只是让人来定义一个任务,然后我们去思考,去构建一个NLP模型,去完成它。但是到了GPT-4上,我们的局限已经不仅仅是语言了,而是序列。任何可以转化成序列的东西,都可以尝试用语言模型去处理。然后我们去学习它,去泛化它,让它达到更好的效果。在训练的时候,我们可以使用这个语言模型。
-
Scaling Law:随着模型大小、数据集大小和计算量的增加,语言模型性能提升。
-
实验验证:计算量增加时,损失降低,性能提升。
-
涌现现象:计算量增加到一定程度,小模型无法完成的任务会显著提升。
-
开源社区贡献:尽管领先公司未开源,开源社区已开发出接近甚至超过ChatGPT 3.5的模型。
-
训练策略:采用Transformer架构和语言建模方法,进行细微调整和新的训练策略。
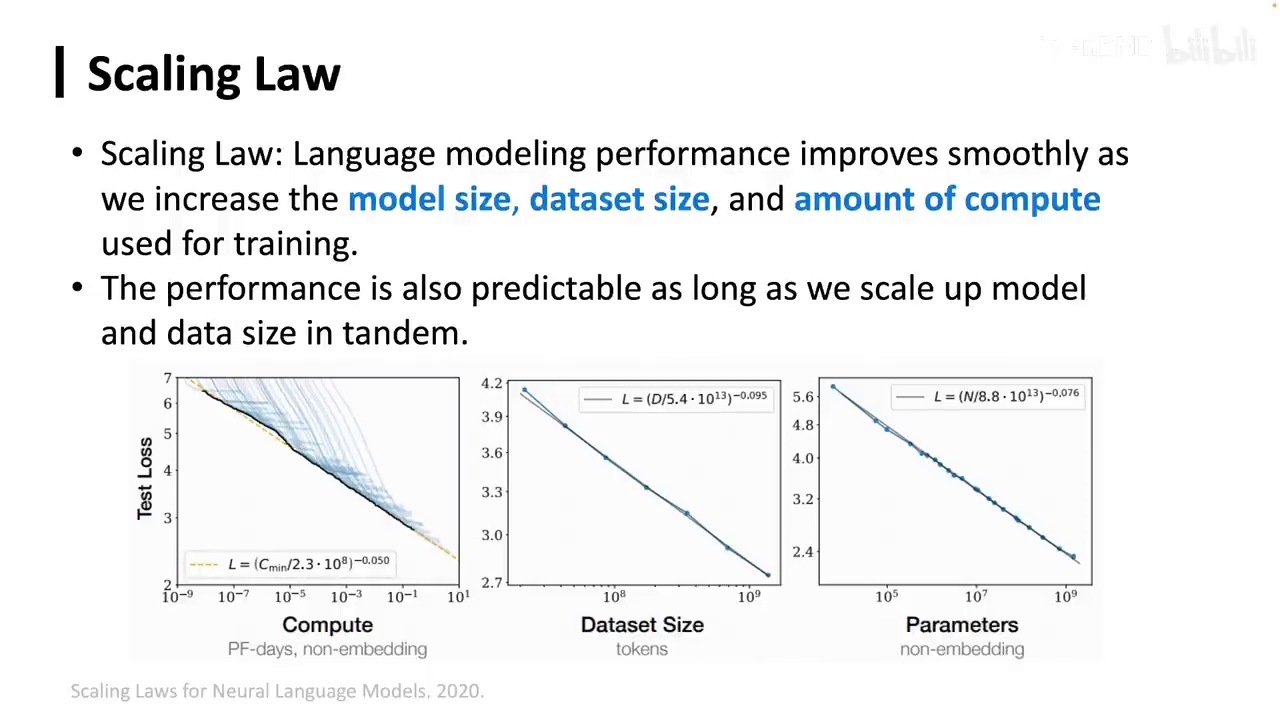
在预训练语言模型的过程中,大家应该听说过一个非常重要的现象,即Scaling Law。Scaling Law指出,随着模型大小、数据集大小和训练所用计算量的增加,语言模型的性能会平稳提升。这一规律是当前大型语言模型训练的基础。尽管这一现象看似直观,但实际上在之前,我们并不清楚模型越大效果越好。我们曾认为模型达到一定大小后会遇到瓶颈,不值得投入更多资源。
因此,需要通过一系列实验来验证,当数据量和模型大小增加时,即计算量增加时,性能曲线如何变化。研究者发现,只要计算量增加,损失就会降低,性能提升。此外,一些研究者提出,在计算量增加的过程中,会出现所谓的涌现现象,即小模型无法完成的任务,在达到一定计算量后会突然提升。
例如,计算量为10^22次方时任务表现不佳,但达到10^24次方时表现显著提升。尽管涌现现象在学术界存在争议,认为这并非凭空出现,而是平滑出现的,只是选择的指标不同。重要的是,能力确实随着模型和数据量的增加而提升。涌现能力具有不可预测性等特点,但通过更细致的研究,这些问题或许能得到解答。
2024年,由于OpenAI等领先的大语言模型公司未开源,开源社区涌现了许多训练策略和模型。我们仍采用Transformer架构和语言建模方法,在更多数据上训练,并进行了细微调整。例如,法国人工智能公司Mistral开发的Mistral模型,采用混合专家架构,而OpenBMB开发的MiniCPM模型,用20亿参数达到70到130亿模型的效果。我们进行了风动实验,并使用了新的训练策略,如WSD模拟退火调度器,以更好地学习。尽管最佳公司未开源,但开源社区如OpenBMB、HuggingFace已做出许多贡献,我们已能训练出接近甚至超过ChatGPT 3.5的模型,但与GPT-4仍有差距。训练这样的模型需要神经网络基础和语言建模等基本知识,尽管这些看似简单,实际训练时却非常复杂。

-
超参数的微小变化可能对模型性能产生显著影响。
-
需要在小模型上进行实验,以实施Scaling Law。
-
并行计算的两种方式:数据并行和模型并行。
-
数据并行涉及数据分割和模型副本的汇总更新。
-
模型并行涉及模型分割和不同部分的计算,节省显存。
-
现代模型训练涉及复杂的工程细节和多机器间的互联通信。
-
AI人才需具备理论知识(如神经网络、机器学习)和实践技能(如硬件操作、计算过程)。
-
新时代AI人才应结合理论与实践,形成综合视野。
这件事变得非常复杂,例如我们的超参数,即使是一个小超参数也可能对整个模型的性能产生重大影响。我们需要考虑数据的配比以及如何实施Scaling Law,这意味着不能仅在大模型上进行实验,而应先在小模型上做好实验。另一个重要的考虑是进行并行计算。在传统的神经网络深度学习中,我们通常采用两种并行方式:数据并行和模型并行。数据并行是将数据分成多份,每张卡存储一个模型副本,每个副本处理数据后汇总更新模型。模型并行则是将模型分成多份,进行不同部分的计算,这样可以节省显存。然而,这可能会面临更复杂的问题,如多机器间的互联和通信。因此,现代模型训练不仅是科学问题,也涉及大量工程细节。AI人才不仅需要懂理论,如神经网络、机器学习和自然语言处理,还需要懂硬件和实际计算过程,如Quda和不同显卡间的操作。新时代的AI人才应将理论与实践结合,具备将不同知识联系起来形成更大视野的能力,以做出更有影响力的工作。
-
数据集规模:Pile数据集容量为850GB,而Find Web数据集规模更大。
-
数据选择的重要性:数据的选择、来源和配比对模型性能至关重要。
-
数据多样性的重要性:为保持模型的通用能力,数据多样性是必要的。
-
模型研究的焦点:2023年至2024年,许多突破性模型研究集中在数据本身。
-
AI人才的要求:新时代AI人才需具备数据工程能力,理解数据结构,并能预测数据对模型结果的影响。
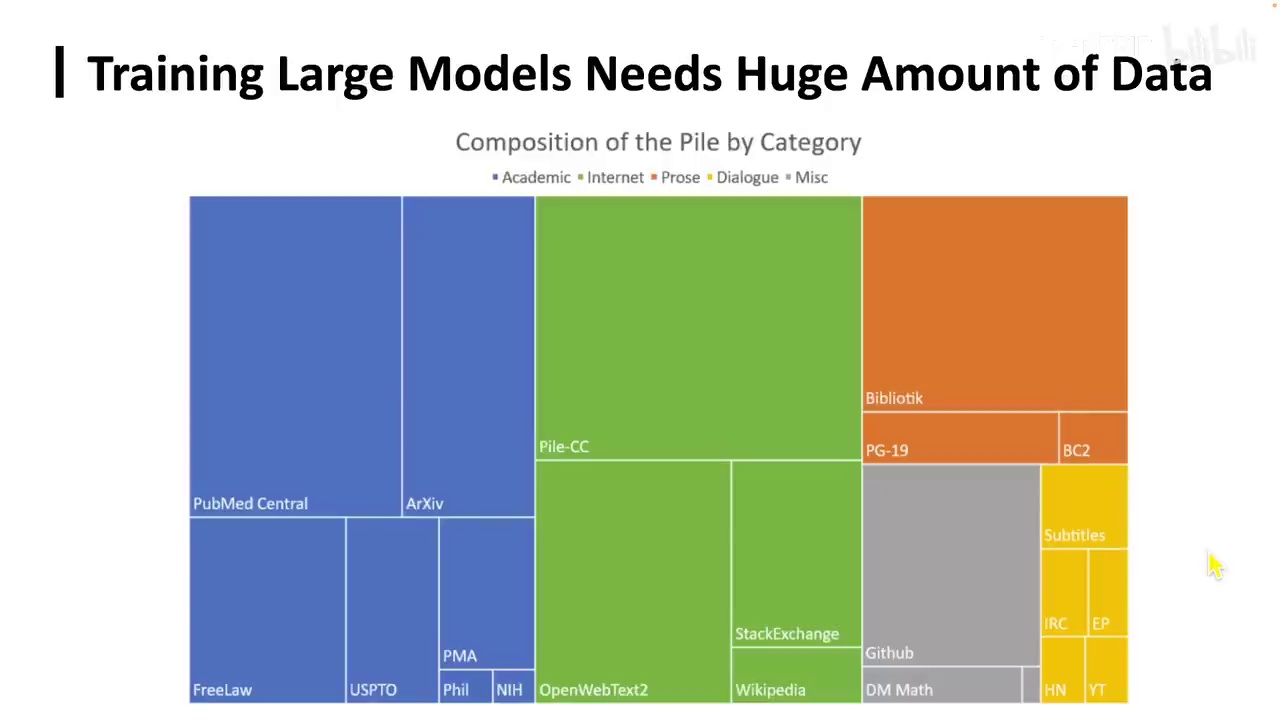
一个大型模型显然需要大量的数据。这里有一个著名的数据集,名为Pile,其容量应为850GB。然而,如HuggingFace最近发布的Find Web数据集,其规模远超Pile。数据的重要性不言而喻,甚至可以说是最关键的因素。我们如何选择数据,数据来源何处,以及数据的配比,都是至关重要的。例如,如果我们希望模型在编程和数学方面表现更强,就需要加入相应的数据。同样,若希望模型在生物学领域表现出色,也需混合生物学数据。同时,我们不希望模型失去通用能力,因此数据的多样性同样重要。实际上,2023年至2024年,许多最具突破性的模型研究都集中在数据本身。继续探讨,新时代的AI人才应具备数据工程的能力,深入理解数据结构,并具备一定的直觉,以预测不同数据可能带来的结果和训练出的模型类型。众所周知,在测试集上训练通常能带来良好的结果。但由于时间关系,我们只能讨论到这里。

-
Post-training是在完成Pre-training之后进行的。
-
假设压缩理论成立,模型在预训练后已将互联网上的所有数据压缩到其参数中。
-
数据类型包括深入的论文、个人微博或Twitter、不同国家的政治观点、编程相关的信息(如汇编代码、Python代码和Java代码)。
-
Post-training的目的是更好地呈现这些压缩的信息。
接下来我们将讨论Post-training,刚才已经完成了所有的Pre-training部分。在Post-training中,我们可以假设所谓的压缩理论是正确的。当前的模型有能力构建互联网上的所有数据,包括最深入的论文、个人发布的微博或Twitter、不同国家的政治观点,以及编程相关的信息,如汇编代码、Python代码和Java代码。如果压缩理论成立,那么一个模型在预训练之后,已经将所有这些信息压缩到其参数中。为了更好地呈现这些信息,我们需要进行Post-training。

-
后训练是模型训练的必要步骤,有多种称呼如对齐或适配。
-
后训练过程的重要性需要被认识。
-
GPT-4在2022年8月完成预训练后,进行了8个月的对齐工作。
任何模型实际上都需要进行后训练。后训练有多种称呼,例如对齐(alignment)或适配(adaptation),在之前我们可能称之为微调。无论我们如何称呼,都需要了解这一过程的重要性。GPT-4在2022年8月份完成预训练后,又花费了8个月的时间进行对齐。
-
即使是强大的模型如GPT-4,在某些领域如创作七言绝句或七言律诗上表现不佳。
-
后训练或对齐过程主要包括四点:
-
场景特化:使模型适应特定或多种场景,如对话场景。
-
能力激发:有效释放模型在预训练中压缩的信息。
-
增强稳定性和鲁棒性:通过优化过程减轻模型的幻觉问题。
-
价值对齐:确保模型符合人类价值观,避免不当行为。
-
而且,即使是目前最强大的模型,也存在其不擅长的领域。例如,今天让GPT-4去创作七言绝句或七言律诗,它可能表现不佳。那么,后训练或对齐究竟涉及哪些内容呢?实际上,主要包括以下四点:首先,是场景特化,即使模型适应特定或多种场景,如对话场景。其次,是能力激发,即如何将模型在预训练中压缩的信息有效释放出来,这是其重要功能之一。第三,是增强模型的稳定性和鲁棒性,通过优化对齐或后训练过程,减轻模型的幻觉问题。最后,是价值对齐,确保模型符合人类价值观,避免其产生不当行为。这一部分将在后续课程中详细探讨。

-
OpenAI曾重视对齐问题,成立了“超级对齐”小组,由Jan Leike和Ilya Sutskever领导。
-
该小组计划投入大量计算资源专注于超级对齐,但两位领导已离职,小组可能已不存在。
-
对齐的定义是让AI根据输入输出人类期望的内容,如情感分类和编写代码。
-
对齐在AI输出特定内容时尤为重要。
对齐究竟是什么?OpenAI之前非常重视对齐问题,并成立了名为“超级对齐”的小组,计划投入四分之一的计算资源专注于超级对齐。该小组由Jan Leike和Ilya Sutskever领导,但他们现已从OpenAI离职,因此超级对齐小组可能已不存在。然而,超级对齐或对齐本身仍然非常重要。对齐的定义很简单,即让AI根据特定输入输出人类期望的内容。例如,在进行情感分类时,我们要求AI判断一句话的情感是正向还是负向;在编写代码时,我们要求AI完成某个课程的大作业。当人类需要AI输出特定内容时,对齐就显得尤为重要。

例如,让GPT编写一段代码,让机器人随意移动一个物体,然后让AlphaGo进行围棋对弈,接着让BERT执行文本分类。

我们可以将其视为对齐,以使模型输出我们期望的结果。为何要对齐?因为它能够增强模型的能力,提高其可信度,并确保安全性。

-
模型在面对道德判断时,如“人应不应该伤害别人”,会基于学到的犯罪小说和法律内容进行概率计算。
-
模型需要通过对齐使其判断更加可靠和准确。
-
对齐过程虽然不直接增加新知识,但能激发模型已有的知识,使其表现出新的能力。
-
对齐和SFT、预训练的loss函数在技术上没有变化,仍依赖于语言建模和文本泛化。
-
当前是研究对齐和后训练的理想时机,因为资源有限。
在模型不知道该往哪个方向走时,例如当我们给它输入一个人类价值观的观点,比如人应不应该伤害别人,这个模型已经学过了所有相关内容。它既学到了犯罪小说中人伤害别人的例子,也学到了法律中人不应该伤害别人的例子。那么,它如何判断哪个是正确的呢?因为我们之前提到,我们所做的一切都是基于语言建模,它所做的只是概率计算。它知道人伤害别人有一个概率,人不伤害别人也有一个概率。那么,如何确定哪个是正确的呢?因此,我们需要对齐模型,使其更加可靠,同时也增强其能力。很多人认为对齐并不能学到新的东西,只是激发了它已有的知识,这种观点是错误的。因为所谓的能力或知识,本身就是人类定义的。我们关注的只是它的表现,如果它确实表现出了新的东西,我们就可以认为它学到了新的东西。实际上,对齐和SFT(fun tuning)以及预训练的loss函数并没有任何变化,它仍然是通过语言建模在大规模文本上进行学习,并且我们希望它在未见过的文本上也能泛化。现在正是研究对齐或后训练的最佳时机,因为我们能研究预训练的人不多,包括实验室和很多公司的计算机资源都有限。

-
预训练实验的重要性不足以吸引所有研究者。
-
后训练的重要性逐渐超过预训练。
-
早期人工智能系统智能水平低,无法跨任务泛化。
-
早期研究者关注模型在特定任务上的表现。
-
现在仅关注表现的做法已不再适用。
也不足以让每个研究者都专注于预训练实验。而且,后训练的重要性逐渐超越了预训练。在早期的人工智能系统中,它们只能执行非常有限的任务,并且智能水平很低,无法进行跨任务的泛化。例如,使用Bert训练的文本分类模型只能进行文本分类,无法执行其他任务。因此,那时的研究者只关注模型在特定任务上的表现。如果能在文本分类任务上取得顶尖成绩,就会被认为是优秀的。然而,现在这种仅关注表现的做法已经不再适用。

-
当前系统能执行复杂任务并具备高级别智能。
-
系统能完成一些尚未被意识到的任务。
-
一个具体例子是ChatGPT被用来模拟Linux操作系统。
现在已经不再那么受关注,因为每个任务我们都能使其表现出色。因此,当前的系统能够执行许多复杂的任务,并具备较高级别的智能,甚至有些事情我们尚未意识到它们能够完成。例如,我记得当ChatGPT刚推出时,有一个非常引人注目的应用,即许多人利用它模拟Linux操作系统。

-
CD命令可以进入指定文件夹。
-
创建文件夹的命令也能被执行。
-
不确定模型是否在训练中接触过相关语料。
-
Linux操作系统可以转化为Token序列。
-
模型能够记忆、学习和泛化这些信息。
-
目前的模型需要进行对齐。
-
之前的模型流程是先预训练,再进行翻译。
例如,当你输入CD命令,它能够进入指定文件夹;当你要求它创建一个文件夹,它也能做到。我们不确定它是否在训练过程中接触过这样的语料,但应该有。这种能力在当时看来几乎像是科幻小说中的情节。然而,回顾本课最初的观点,一个Linux操作系统同样可以转化为Token序列。因此,模型能够记忆、学习并泛化这些信息,也并非不可思议。目前,我们需要进行对齐。再次强调,在之前的模型中,我们首先进行预训练,然后再进行翻译。

-
对齐过程包括在无监督语料上预训练,然后在特定任务上进行有监督训练。
-
GPT-1使用最后一个token的最深层隐藏状态,通过线性层和softmax函数输出类别概率分布。
-
BERT使用CLS token或所有token的表示平均值,通过线性层和softmax函数输出分类结果。
-
T5模型输出token,这些token在词表上形成概率分布,模糊了任务的概念。
对齐过程,即调整(tuning)、适应(adaptation)或对齐(alignment),是在无监督的语料上进行预训练,然后在特定任务上进行有监督的训练。以GPT为例,初代GPT-1在尚未发展成后来的ChatGPT时,其对齐过程如下:针对每个任务,使用最后一个token的最深层隐藏状态,并通过一个线性层输出softmax函数,该函数输出类别上的概率分布。例如,在分类任务中,若A类的概率为0.8,则该样本会被归类为A类。同样,BERT也采用类似方法,使用CLS token或所有token的表示平均值,通过线性层和softmax函数输出分类结果。而T5模型则有所不同,其输出不再是简单的类别概率分布,而是token,这些token本身也是一种概率分布,但这种分布是在词表上。因此,输入和输出都变成了token,从而模糊了任务的概念。

-
GPT-3在任务定义中转化为token到token的序列处理。
-
后训练或对齐阶段有两条主要发展路线:
-
第一条侧重泛化性,使用较少数据在更多任务上取得更好效果。
-
第二条关注效率,使用更少参数或计算资源完成任务。
-
-
这两条路线不冲突,即使提高效率,仍可期望模型用更少数据完成更多任务。
-
效率路线中,传统微调方法成本高,需在每个任务后更新所有参数。
在定义好的任务中,这些任务都转化为从token到token的序列。接下来是大家熟知的GPT-3。在后训练或称为对齐阶段,主要有两条发展路线。第一条路线更侧重于泛化性,即使用较少的数据在更多任务上取得更好的效果。例如,我们可能希望仅用几条数据就能完成一个高质量的任务,或者仅用10个任务的1000条数据来完成50个任务的1万条数据。甚至,我们可能希望开发一个能够执行任何任务的模型。第二条路线则关注效率,即使用更少的参数或计算资源来完成任务。值得注意的是,这两条路线并不冲突,即使使用更少的参数和计算资源,我们仍然可以期望模型使用更少的数据来完成更多的任务。我们先讨论效率这条路线。在效率方面,传统的微调方法是在训练模型后更新所有参数,并在下一个任务中再次更新所有参数,这种方法可能成本非常高。

-
预训练模型的高成本问题:超过90%的研究组和实验室难以承担,即使是微调也面临巨大挑战。
-
微调成本实例:1750亿参数的模型微调可能需要100张A100,每张80GB的A100,开销巨大。
-
引入新范式:参数高效的微调(Data Tuning),旨在使用极少的计算资源和参数更新来完成微调。
-
Data Tuning的优势:大幅降低存储空间需求,例如1750亿参数模型存储空间可降低一万倍。
-
参数高效的微调方法分类:增量式方法、指定式方法、重参数化方法。
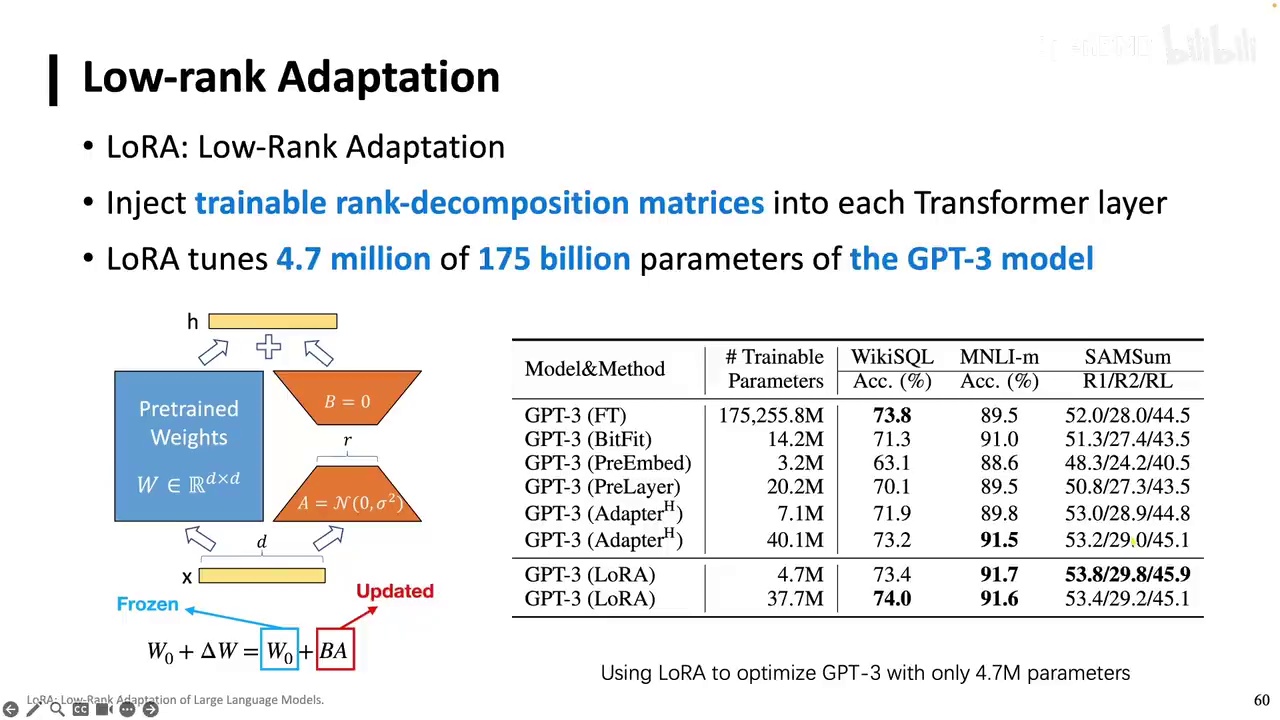
预训练模型的高成本使得超过90%的研究组和实验室难以承担,即使是微调也面临巨大挑战。以一个拥有1750亿参数的模型为例,进行微调可能需要100张A100,每张80GB的A100,这对于计算资源最丰富的实验室来说,开销也是巨大的。因此,我们引入了一种新的范式,称为参数高效的微调(Data Tuning)。这种微调方法旨在使用极少的计算资源,更新极少的参数来完成微调。其优势非常明显,首先可以大幅降低微调所需的存储空间。以1750亿参数的模型为例,与全参数微调相比,使用Data Tuning可以将存储空间降低一万倍。虽然微调过程中的显存并未降低至相同程度,但仍可减少约四分之三或三分之一。参数高效的微调之前并不是一个体系化的研究领域,但陆续有研究表明,许多研究实际上在做同一件事。目前,这一领域主要分为三类方法:增量式方法(Addition Based),即向模型中添加原本不存在的参数,并仅微调这些参数;指定式方法,即指定模型中哪些参数可调,哪些不可调,这可能是人工选择的,也可能是通过启发式方法或训练新的神经网络参数选择器来决定的;重参数化方法,即将微调过程转化为低秩或低维过程,实现整个优化过程的转变。

-
论文发表于Nature Machine Intelligence,涉及参数高效微调领域。
-
论文提出Delta Tuning框架。
-
介绍了Adapter作为参数高效微调的初始方法。
-
Adapter在Bert时代已提出,通过在Transformer中加入小型神经网络单元实现微调。
-
微调仅涉及0.5%到8%的参数,通过调整映射维度实现适配。
这里推荐大家阅读一篇论文,这其实也是我写的。它是我们组在参数高效微调领域,在Nature Machine Intelligence上发表的一篇综合分析性论文。在这篇论文中,我们提到了Delta Tuning这个统一的框架。接下来,我们将介绍参数高效的微调。首先,我们介绍其最初的作品,即Adapter。Adapter可以被称为适配器,无论怎么翻译都可以。实际上,它在Bert时代就被提出。其做法非常简单,即在一个Transformer中加入两个小的神经网络单元。这些神经网络单元包括一个下映射矩阵、一个非线性层和一个上映射的线性矩阵。加入这些神经网络单元后,我们只微调Adapter的参数,其他部分保持不变。通过调整下映射和上映射的维度,Adapter本身可以变大或缩小。因此,我们基本上只需微调0.5%到8%的参数,即可完成适配。这项工作其实在Bert时代就已经被提出。谢谢大家!

-
Bert的初期关注度低:由于Bert规模不大,且微调可能降低性能,初期关注度不高。
-
微调成本的增加:随着T5和GPT-3的出现,微调成本上升,促使参数高效微调方法重新受到关注。
-
Adapter方法的介绍:Adapter方法简单,但存在前向传播负担加重的问题,尤其是在模型层数增加时。
-
LoRA方法的流行:LoRA已成为最受欢迎的参数高效微调方式,特别是在使用Diffuser模型的场景中。
实际上,当时关注Bert的人并不多,因为Bert的规模并不大,大家普遍认为既然已经进行了微调,那么就应该追求更高的性能。如果微调可能导致性能损失,那么就没有太多人关注。然而,随着T5和GPT-3的出现,人们发现微调这些模型的成本越来越高。这时,以Adapter为首的参数高效微调方法再次引起了广泛关注。现在,有一个更为著名的方法叫做LoRA,相信所有同学都听说过,它已经成为最受欢迎的参数高效微调方式,尤其是在使用了许多Diffuser模型的场景中。我们先介绍Adapter,Adapter非常简单,但我们可以发现它有一个缺点,即原本模型已经足够深,再加上两层Adapter,每层加两个Adapter,24层就需要加48个,这样前向传播的负担会加重。

-
前向传播资源紧张,增加负荷会延长传播时间。
-
反向传播虽无需调整所有参数,但整体不经济。
-
研究者认为Adapter虽具开创性,但未必最优。
-
提议将Adapter移至外部,通过增加旁路节省空间和计算资源。
-
节省计算资源通过减少遍历网络次数,节省显存通过缩小隐藏空间形状。
-
引入Prime Tuning和Preface Tuning,通过微调前缀矩阵达到良好效果。
在前向传播过程中,原本资源已显紧张,若再增加负荷,前向传播时间将进一步延长。尽管反向传播时,可能无需调整所有参数,其增长有限,但整体而言,这种做法并不经济。因此,许多研究者认为Adapter虽具开创性,但未必是最优选择。一种策略是将Adapter移至外部。此提议旨在提供一种新思路:通过在每一层增加旁路,连接外部Adapter,前向传播保持常规路径,反向传播则仅至某一缩放器处终止。这样既能节省空间和计算资源,也能减少显存使用。节省计算的原因在于无需前向和反向传播都遍历整个网络,而节省显存则通过缩小隐藏空间形状实现。虽然实际操作中存在诸多技巧,但这一思路为不必要在神经网络每层添加小型神经网络提供了可能。此外,还可以在隐藏空间或输入前端引入Prime Tuning或Preface Tuning,这两种方法相辅相成。Preface Tuning在神经网络每层的表示(即隐藏空间h)前加入可计算矩阵,而Prime Tuning则是其简化版本,通过微调这些前缀矩阵,后续部分保持不变,从而达到良好的效果。

-
技术应用:在模型的输出层前加入prefix,仅调整这些prefix,中间层不添加。
-
技术特点:prefix tuning强调参数高效,添加的上下文是无意义的soft矩阵。
-
效果表现:在大规模模型(100亿参数)中效果与全模型微调相当,但在小模型中效果不佳。
-
潜在问题:由于仅调整输入层的少量embedding,信息在传播中可能受损,影响效果。
我们只在输出层,即embedding层的前面,加入prefix,然后只需调整这些prefix。在中间的这些层我们不再添加,以确保其效果。这项工作在当时具有很大的影响力,但我必须指出,它与我们现在讨论的prompting(提示工程)以及后续要讲的prefix learning实际上并非同一概念。这里的prefix tuning更强调参数高效,而非添加额外的上下文。它所添加的上下文实际上是无意义的,是soft的,即一些可微调的矩阵。因此,许多人可能会混淆这一点,大家需要注意。prefix tuning发现,当模型扩展到100亿参数时,其效果与全模型微调相当。然而,当模型较小时,它无法发挥作用,因为大家可以想象,我们在输入层加入了一些很少的embedding,然后调整它们。这些embedding需要经过输出层,再反馈回输入层。在调整过程中,它仅调整了开头的这些embedding,因此许多信息可能在传播中受到损失,导致其效果并不理想。
-
LoRA(Low-Rank Adaptation)是一种热门方法,核心思想是对神经网络参数的变化量进行低秩分解。
-
具体操作是对矩阵变化量(如B-A)进行分解,例如将1000×1000的矩阵分解为1000×1和1×1两个矩阵,以减少计算量。
-
LoRA的作者认为,尽管实际模型中的变化量可能是满秩的,但通过强制低秩分解,可以认为其本质上是低秩的,或者可以用低秩矩阵来近似表示。
-
这种方法涉及复杂的等价关系,虽然在数学上难以精确计算,但具有深入思考的价值。
接下来将介绍目前最热门的方法——LoRA(Low-Rank Adaptation)。LoRA的核心思想是对神经网络参数的变化量进行低秩分解。需要注意的是,我们并未直接分解神经网络本身的矩阵,而是分解其参数的变化量。例如,从矩阵A变为矩阵B,B-A即为变化量。我们仅对这一变化量进行分解,例如一个1000×1000的矩阵,可以分解为1000×1和1×1两个矩阵。这种分解显著减少了计算量。实际上,我们仅调整变化量的公式,并将其转化为低秩形式。LoRA的作者认为,这种低秩表示实际上是一种本质的低秩。尽管在实际模型中,变化量可能是一个稠密的满秩矩阵,但我们强制进行低秩分解,认为其本质上具有低秩特性,或者可以用低秩矩阵来表示这种变化。虽然单个低秩矩阵可能无法完全表示,但通过对所有模型的每个矩阵进行低秩分解,某种程度上可以表示其满秩时的变化。这涉及到一个复杂的等价关系,尽管在数学上难以精确计算,但值得深入思考。此外,这也引申出一个话题,即当前许多人提出的“革命”概念。

-
新架构在性能上超越Transformer,具有更好的学习和泛化能力。
-
新架构的革命性在于Scaling Law,而非Transformer本身。
-
神经网络和Transformer都能模拟复杂函数,导致性能竞赛难以分出胜负。
-
当Scaling Law达到瓶颈时,需要更高效的架构来减少计算量。
-
LoRA利用低秩矩阵模拟满秩矩阵的变化,通过固定秩(通常为2、4、8)进行矩阵分解。
-
秩的设定可能因任务复杂度而异,固定秩并不一定限制神经网络的复杂计算。
这个新架构在性能上超越了Transformer,能够学习更多并泛化更广,即使在相同的数据集上。实际上,这种神经网络新架构的革命性并不在于Transformer本身,而是Scaling Law。无论神经网络架构如何新颖,都是在庞大的数据集中模拟复杂的函数。由于这个函数足够复杂,神经网络和Transformer都能模拟。因此,这两者之间存在一种A能做到的B也能做到的情况,这变成了一场无法取胜的比赛。只有当Scaling Law达到瓶颈,即模型性能无法再提升时,我们才需要考虑如何用更高效的架构来模拟Transformer的表现,从而减少计算量和推理的计算量。这是题外话。
总之,LoRA就是利用低秩矩阵来模拟满秩矩阵的变化。LoRA后续有许多改进,这里重点介绍我自己的工作。LoRA将一个矩阵分解成低秩和高秩部分,中间有一个固定的秩,通常设为2、4、8,多数情况下设为8,研究发现设为16并不一定更好,可能因为任务本身很简单,不需要设得太高。尽管秩是固定的,但实际上我们都知道,神经网络的计算或在大模型中的计算是一个极度复杂的过程。当我们人为设定一个秩时,它很可能是自由的。
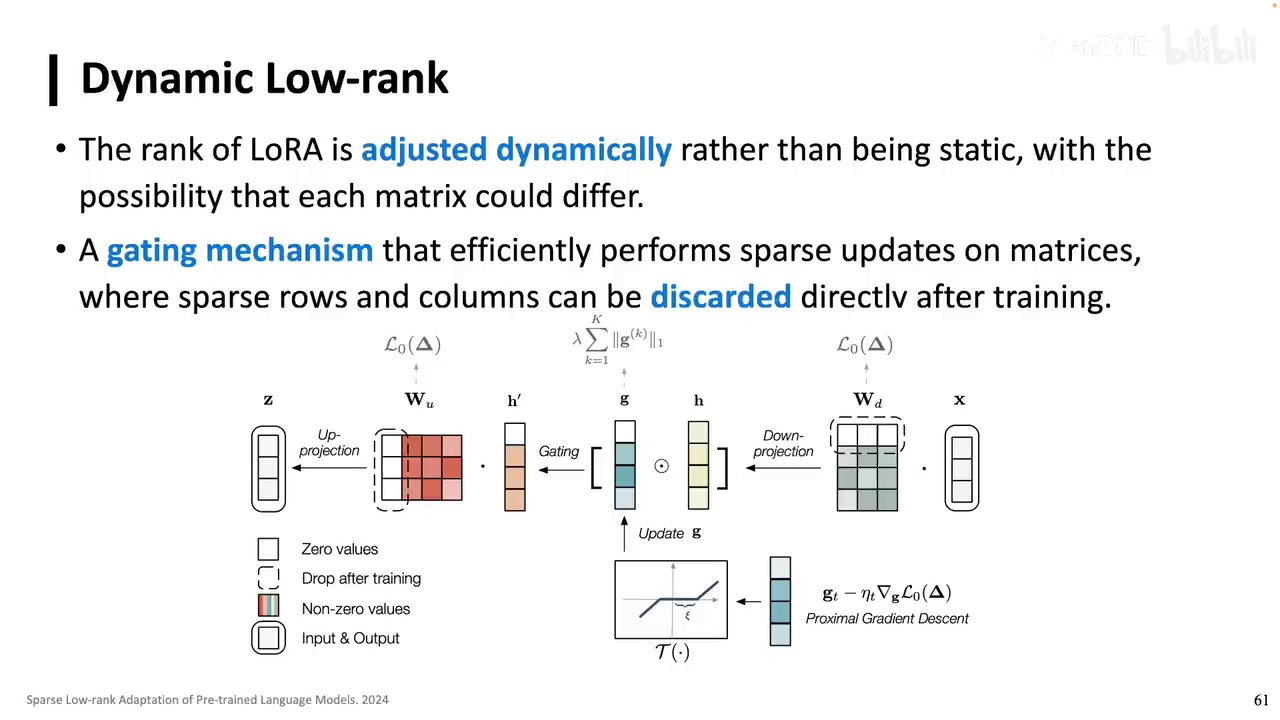
-
提出的方法通过引入系数gating实现模型质量的动态调整。
-
当某个值低于阈值时,该值设为0,导致gating和相应矩阵的行和列变为0。
-
在LoRA基础上,模型可以进行更细致的调整,包括满值和接近全0的值。
-
推理过程中可以丢弃0值矩阵,实现动态调整。
-
该方法能够模拟复杂过程,每个矩阵的LoRA分解变化值各不相同。
-
无论是adapter、prefix tuning还是LoRA,本质上都在选择参数进行微调。
-
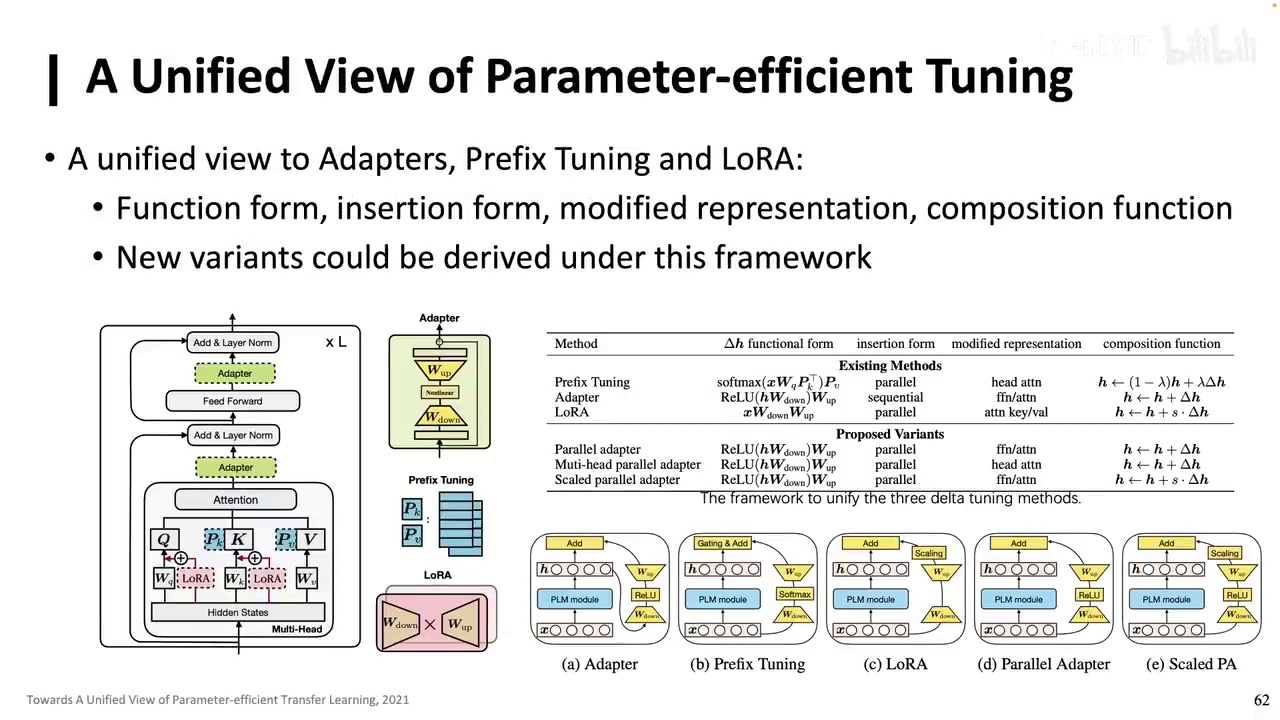
何俊贤老师在CMU时的工作,采用统一视角理解LoRA、prefix tuning和adapter,并用数学框架表示,发现新变体。
这里我提出了一种方法,旨在实现其质量的动态调整。具体来说,是通过在中间引入一个系数gating。例如,当一个下降量中的某个值低于某个阈值时,该值将被设为0。一旦设为0,gating本身会有一行变为0,进而导致相应矩阵的一行和一列变为0。因此,在LoRA的基础上,该模型可以实现更细致的调整,有的可能是满值,有的可能是接近全0的值。在推理过程中,我们可以丢弃这些0值矩阵。我认为这种做法相当聪明。通过这种方式,我们能够得到可以动态调整的模型,在不同位置有不同的矩阵,每个矩阵的LoRA分解变化值也各不相同,从而更好地模拟复杂过程。我们可以看到,无论是adapter、prefix tuning还是LoRA,它们本质上都在做同一件事,即选择一些参数进行微调,而其他参数保持不变。许多工作尝试用同一个视角来看待它们。这项工作是由香港科技大学的何俊贤老师在CMU时进行的,他采用了一个统一的视角,让大家理解LoRA、prefix tuning和adapter究竟在做什么,并用一个统一的数学框架表示出来,同时还能发现一些新的变体。
-
-
研究内容:Data Tuning的研究工作,包括理论推导和实践应用。
-
方法本质:Data Tuning方法在优化和自由控制方面本质上是相同的。
-
资源推荐:推荐在Hugging Face上查看Path库和OpenData库,其中OpenData是先开发的。
-
历史背景:在OpenData之前,Data Tuning需要直接修改模型代码,如在Bert和Roberta模型上实现超级Adapter。
刚才提到的就是我们关于Data Tuning的研究工作,实际上我们也进行了理论推导。我们发现从优化和自由控制的角度来看,这些方法本质上在做同一件事情,推导结果更为深入。如果大家对此感兴趣,可以进一步查阅相关资料。不过,Data Tuning并非本节课的重点,因此今天我们只做简要介绍。如果大家想尝试Data Tuning,可以在Hugging Face上查看Path库和OpenData库。这两个库非常有趣,实际上OpenData是我们先开发的。当时我们面临的问题是如何进行Data Tuning,需要对模型参数进行修改。在OpenData出现之前,一种做法是直接修改模型代码。例如,如果我们维护了一个Bert模型,并开发了一个名为超级Adapter的Data Tuning算法,我们需要在Bert模型上实现超级Adapter,并在Roberta模型上同样实现。这意味着我们需要在不同的模型上重复实现这些参数修改。

-
Delta tuning结构的实施:从v3升级到v4,不再适用v3版本。
-
更新方式:选择通过调整计算图而非直接修改模型代码。
-
计算图修改:指定模型结构变化,修改前向和后向计算方式。
-
Hugging Face的参考:可能参考了Delta tuning方法。
-
转向泛化话题:从prompt开始讨论,包括GPT-3的1750亿参数和incontent learning。
-
prompt的定义和应用:可以是上下文的一部分,用于引导模型执行任务。
新的Delta tuning结构已经实施,接下来我将更新我的代码库,从v3升级到v4。这意味着之前的v3版本将不再适用。我们发现这种更新方式相当繁琐,因此我们选择不直接修改模型代码,而是通过调整计算图来改变代码。当引入Delta tuning后,我们指定模型结构的变化,并修改其计算图,包括前向和后向计算方式,从而避免直接修改代码库。对此感兴趣的读者可以查看相关实现。值得一提的是,Hugging Face的Path也采用了类似的方法,可能是参考了我们的做法,具体情况可以询问Hugging Face团队。
关于tuning的讨论到此结束,接下来我们将转向另一个话题——泛化。如果大家还记得,我们将从prompt开始讨论。例如,当GPT-3发布时,它拥有1750亿参数,无法进行微调,这一点之前已经提到过。我们通过描述任务来引导它执行,这种描述就是prompt。我们也可以在描述任务后提供一些例子,进行所谓的incontent learning,这些例子同样属于prompt。本质上,prompt可以是上下文的一部分,这里我们主要指的是上文。任何内容都可能被视为prompt。例如,当我们告诉XGPT这是一篇论文,并要求它阅读并指出最重要的部分时,这也是一种prompt的应用。

-
概念转变:GPT-3之前,模型训练主要依赖传统机器学习方式;GPT-3后,引入通过上下文描述任务的新方法。
-
任务描述方式变化:从依赖高维空间和流形定义任务(如情感分类)转变为使用语言或token直接描述任务。
-
prompt learning的兴起:将各种任务转化为语言建模任务,缩小了上下游任务的差距,使得小模型也能有效工作。
-
发展至instruction tuning:从少样本单任务学习发展到跨任务零样本泛化,不再区分具体任务。
-
后续研究:由OpenAI、HuggingFace和Google等机构继续推进。
这篇论文中,每一个token组合起来也是一个prompt。在GPT-3出现之前,我们似乎没有这个概念。因为在此之前,我们使用预训练模型时,仍然采用传统的机器学习方式。然而,有了GPT-3之后,我们开始意识到可以通过增加上下文来描述我们想要完成的任务,而不仅仅是依赖训练集进行训练。例如,我们之前的任务是情感分类,需要在高维空间中表示,并定义一个流形,其中落在左边的为类别A,右边为类别B。现在,我们通过使用语言或token来明确描述我们想要完成的任务。这导致了prompt learning的出现,即将任何任务(如情感分类、实体识别、知识探测)转化为语言建模任务,使得下游任务和上游任务之间没有差距。这种方法证明,即使在小模型上也能有效工作。通过添加prompt并调整一些参数,模型可以用非常少的样本来完成原本需要大量样本才能完成的任务。这种prompt learning后来演变为instruction tuning,即从单任务的少样本学习转变为跨任务的零样本泛化。简而言之,在prompt learning阶段,我们希望用少样本完成单任务,而在instruction tuning阶段,我们追求跨任务泛化,甚至不再区分任务的概念。后续的相关工作由OpenAI、HuggingFace和Google等机构进行。

其实当时我们也发现了类似的现象,即指令微调可以带来跨任务的领域泛化。这里其实也非常简单,就是我在上面这两个任务上训练了之后,然后没有见过下面的任务,下面的任务上它也能表现得非常好。
-
指令微调与传统多任务学习的主要区别在于输入形式,使用不同的提示(prompts)和扩大输出空间。
-
指令微调通过将任务数据转化为更模糊的形式,实现在更多任务上的评测。
-
更大的模型或更多的数据能提升指令微调效果,如OpenAI的InstaGPT。
-
指令微调是实现零样本泛化的关键技术,使模型在没有特定训练的情况下也能执行任务。
这就是指令微调的基本概念。现在大家可以思考一下,指令微调和传统的多任务学习,甚至是GPT-2所强调的多任务学习,究竟有何不同?实际上,它们之间确实存在差异。这种差异主要体现在指令微调的输入形式上。在指令微调中,我们使用不同的提示(prompts),即由不同人编写的上下文来代表任务。此外,我们扩大了输出空间,不仅仅是在ABC任务上训练和评测,而是在更多的任务上进行评测。我们将来自任务的数据转化为与任务关系越来越模糊的形式。这就是指令微调的作用。
指令微调还表明,更大的模型或更多的数据(尽管关于更多数据的争议仍然存在)确实能带来更好的指令微调效果。OpenAI的XGPT的前身,InstaGPT,就是通过结合指令微调和人类反馈的强化学习实现的。因此,我们现在讨论了预训练和后训练,最终讲到了指令微调,我们离构建出XGPT只有一步之遥。
最后,我想强调的是,当前大语言模型的核心能力来源于指令微调带来的零样本泛化。通过指令微调,我们发现模型能够跨任务进行零样本泛化,即在没有学习过翻译的情况下也能进行翻译,这促成了我们现在所有的大语言模型。所有可见的语言模型都离不开这一关键技术。

-
自ChatGPT和GPT-4发布后,许多大型运营模型迅速出现,涉及众多科技公司和人工智能研究机构。
-
这些模型均采用指令微调的基本框架,并利用其优势。
-
著名模型包括Alpaca和BQNA。
-
作者在疫情期间尝试微调了一个对话模型,体验其多轮对话和多任务处理能力。
自从ChatGPT和GPT-4发布后,众多大型运营模型如雨后春笋般涌现。这些模型几乎涵盖了所有科技公司和人工智能研究机构,它们各自开发了独特的模型,但无一例外地都遵循了指令微调的基本框架,并充分利用了指令微调带来的优势。其中,较为著名的模型包括Alpaca和Vicuna。值得一提的是,在ChatGPT刚发布时,正值疫情期间,我还在读博,寒假期间我独自在家,对ChatGPT的实现方式感到好奇。我尝试自己微调了一个对话模型,亲自体验其多轮对话和多任务处理的能力。

-
工具开发门槛低:使用少量数据和简单微调即可开发出多任务对话工具。
-
内部讨论未公开:相关发现仅在内部讨论,未对外公开。
-
斯坦福Alpaca项目:采用自指令方法,通过种子数据生成更多数据进行微调,开发出遵循人类指令的模型。
-
Vicuna项目:使用真实世界中人与ChatGPT对话的数据进行微调,效果与ChatGPT相当。
-
指令微调趋势:转向数据生成,方法主要是监督微调,预测下一个Token输出。
-
UltraChat项目:开发思路不追求特定任务最佳效果,而是基于Token序列构建数据。
发现实现这样一个强大的工具,其门槛确实非常低。即使使用很少的数据,只需进行简单的微调,它就能具备多端对话的能力,也能执行不同的任务。然而,这一发现仅限于我们内部讨论,并未公开发布。斯坦福的Alpaca项目则采用了自指令方法,通过种子数据生成更多数据,并在这些数据上进行微调,从而开发出一个能够遵循人类指令并完成各种任务的模型。而Vicuna则更进一步,使用真实世界中人与ChatGPT对话的数据进行微调,这种方法被称为ShareGPT。结果显示,其效果与ChatGPT相当。因此,在指令微调层面,大家更多地转向了数据生成,因为方法本身并无太大差异,都是通过监督微调,给定输入并预测下一个Token的输出。此外,我们还开发了一个名为UltraChat的项目。在开发UltraChat时,我的思路非常明确,并非为了在特定任务上达到最佳效果,而是不再通过任务来构造数据,因为任务本质上就是一系列Token。

-
人类与机器交互的三种主要类型:
-
信息提取:从现有资源如维基百科获取知识。
-
信息创造:如生成新的诗歌。
-
信息转化:如对材料或论文进行总结。
-
-
在交互过程中,通常不特别区分具体的任务类型。
我们需要深入探讨的是人类与机器之间的交互方式。从信息处理的角度来看,这种交互主要分为三种类型。首先,是信息的提取,这包括从现有资源中获取知识,例如维基百科或其他搜索结果中的数据。其次,是信息的创造,例如让模型生成一首关于蛋白质的十四行诗,这种诗以前从未被创作过。最后,是信息的转化,例如对给定的材料或论文进行总结和提取。在这个过程中,我们通常不会特别关注具体的任务类型,尽管在更细致的层面上可能会有所区分。
他实际上在不知不觉中完成了许多扩散出来的任务。当时我们训练的模型效果其实也是很好。

-
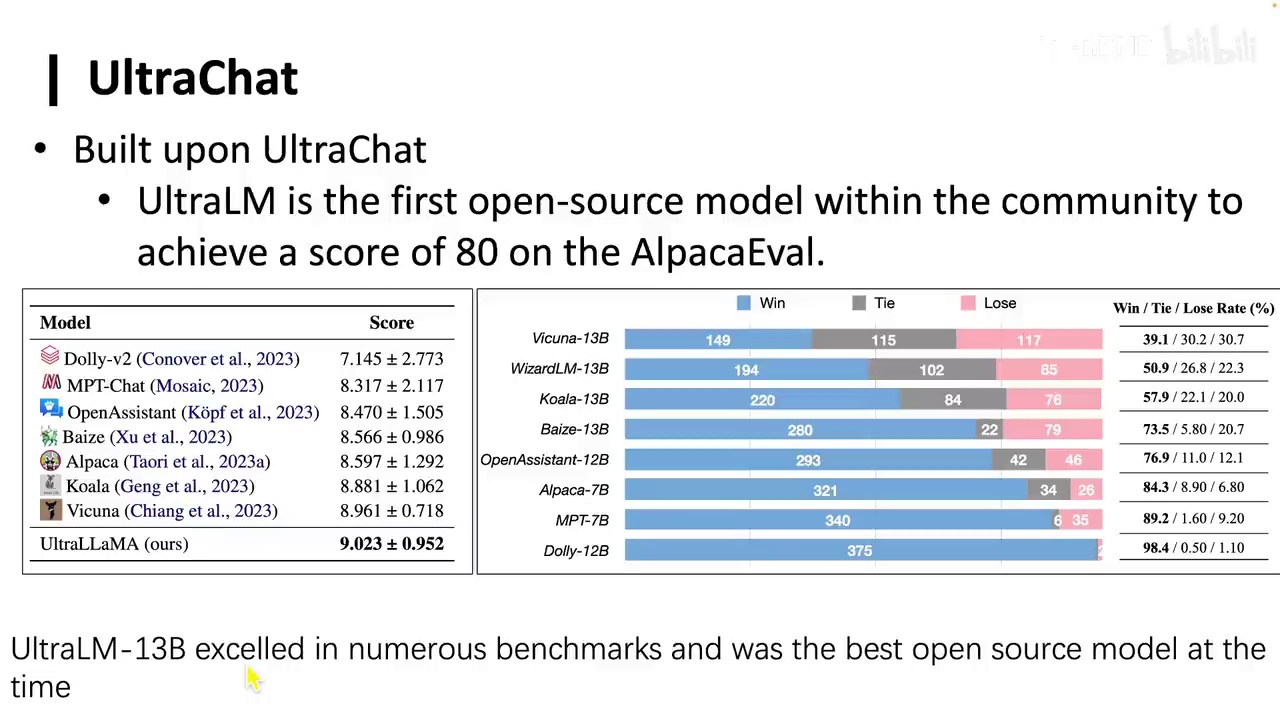
UltraChat是首个在斯坦福AlpacaEval上超过80分的开源模型。
-
UltraChat的设计理念是摒弃任务概念,将所有内容转化为信息流或人机对话。
-
另一个极端是极致发挥任务概念,如Flan任务,通过GPT-4生成数据。
-
UltraChat和Orca虽然方法极端,但最终都模糊了任务概念。
它是第一个在斯坦福的AlpacaEval上超过80分的开源模型。当然现在几乎大家都能超过80分了,甚至都能超过90分了。然后当时它的效果应该也是开源中最好的。这就是我们做的UltraChat。我们可以看到UltraChat的思想是,我不要任务的概念。我啥都转化成信息流,或者说信息人和机器对话的本身。这是一个极端。我们还可以做另一个极端,就是我们把任务的概念发挥到极致。比如说有个刚才之前提到的任务叫Flan。我们可以把Flan里面可能有几千个任务。我们把里面所有的任务,每一个任务都拿出来,把Prompt拿出来。用GPT-4给它做回答,然后生成一波这种数据。所以说这两个其实大家想想非常有意思。UltraChat和Orca两个极端,但是好像在做同一件事情。不管我是一开始就模糊任务,还是我把任务做到极致,其实也是在一种,其实也就没有了任务。你就把任务本身给模糊化了。然后它就把所有的这种输入出来,拿出来用GPT-4做。
-
模型微调中,主要工作是构建数据集,包括输入和输出。
-
存在争论关于指令微调所需数据量:
-
UltraChat和Orca使用数百万条数据。
-
Instrata GPT仅使用一万多条数据。
-
Lima研究表明少量高质量数据即可获得优异效果。
-
-
争论焦点:数据量越少越好还是越多越好。
-
有人质疑指令微调是否能学习新知识。
在对话、推理和数学等领域,当前大家在进行模型微调时,主要工作是构建数据集,包括数据的输入和输出。这里存在一个有趣的争论:一些研究者认为,不需要大量数据来完成指令微调。例如,UltraChat和Orca使用了数百万条数据,而Instrata GPT仅使用了一万多条。此外,Lima的研究表明,使用少量高质量数据即可获得优异效果。这引发了一个争论,即指令微调所需数据量的问题,有人认为越少越好,有人则认为越多越好。此外,还有人提出指令微调可能无法学习新知识等观点。实际上,这个问题具有重要意义。

-
作者认为在指令微调中,数据量越多越好,因为数据越多模型能学到更多期望的内容。
-
作者提到高质量数据在少量情况下表现与大量数据时相同,这可能是评测方式的问题。
-
作者举例说明高质量数据的定义,如模型A正确回答“蒙娜丽莎是谁画的?”为“达芬奇”。
现在我们也可以讨论一下,我认为在指令微调中,数据量肯定是越多越好。数据越多,模型才能学到更多期望的内容。很多时候,高质量数据在少量情况下表现与大量数据时相同,我认为这主要是评测方式的问题。大家可以思考一下,什么叫高质量数据。例如,我问“蒙娜丽莎是谁画的?”模型A的回复是“达芬奇”。
-
达芬奇是意大利艺术家,生于1452年,逝于1519年,代表作有《蒙娜丽莎》和《最后的晚餐》。
-
“高质量”概念依赖于评测标准,越接近标准质量越高。
-
模型在指令微调和监督微调中,数据量和质量越多越好,能学到新知识。
-
知识由人类定义,模型参数更新能学到新东西。
-
指令微调研究中,零样本泛化机制尚不明确,包括其发生步骤、所需数据量及定义问题。
模型B回复是,达芬奇是一位艺术家,生于1452年,逝于1519年,出生于意大利。他的代表作品包括《蒙娜丽莎》和《最后的晚餐》。关于“高质量”这一概念,有人可能认为A是高质量的,但这实际上是一个伪命题,因为高质量可能与评测方式有关,越接近评测标准,质量就越高。因此,我们使用所谓的高质量数据在我们设定的评测标准上进行评测,其结果很可能是良好的。无论如何,模型在指令微调和监督微调的过程中,数据和预训练一样,越多越好,质量也是越多越好,同时也能学到新的知识。所谓的知识也是由人类定义的,什么是知识,但模型的参数确实更新了,因此也能学到新的东西。这就是关于指令微调的一切。目前,指令微调的研究仍在进行中,许多谜团我们尚未能完全解释,例如零样本泛化究竟发生在哪一步,需要多少数据来完成零样本泛化,以及零样本泛化本身是否真的是零样本泛化。现在我们可以开始思考这个问题,我们在任务A上训练完成后,它在任务B上表现良好,但实际上任务是我们自己定义的吗?是否有更本质的定义方式来解释这个问题呢?可能是由于某些token重叠,或者某些token在语义上相同。

-
在A训练网才能在B表现好。
-
指令微调后,模型基于人类反馈的强化学习(RLHF)。
-
RLHF使模型能遵循人类指令,模型已非常强大。
在A训练网才能在B表现好。在指令微调过后,我们现在要说的就是大家更加耳熟能详的,基于人类反馈的强化学习(RLHF)。基于人类反馈的强化学习,这张图相信大家看过很多遍了。简单来说,我们是先进行微调一个模型,然后这个模型本身已经非常强大,它可以遵循人类的指令了。

-
使用成对比较的方式训练模型,通过最小化函数最大化赢的奖励分数和输的奖励分数之间的差值。
-
奖励模型输出一个标量分数,分数高表示好,低表示坏。
-
使用RLHF(PPO算法)更新模型,包含两个公式:
-
前一项最大化模型输出的分数。
-
后一项通过KL散度确保模型参数不偏离原参数太远,防止模型崩溃。
-
-
PPO算法在实际操作中较为复杂,需要工程上的细节优化。
A大于B,S1比S3好,S3比S2好。这里我们可以看到,可以如何训练呢?我们可以直接使用这种成对比较的方式来训练。我们最小化这个函数,这样实际上是最大化赢的奖励分数和输的奖励分数之间的差值。将其最大化后,我们就能得到这样一个奖励模型。对于任何一个输入和输出,它输出一个标量,这个标量就是它的分数。分数高即为好,低即为坏。从而我们就能将奖励模型应用于各个领域,以得到更好的样本。现在使用奖励模型,我们就可以进行打分。那么我们如何更新原有模型呢?这时我们使用RLHF,即所谓的PPO算法。PPO算法包含两个公式。首先,我们知道奖励模型本身具有打分功能。然后我们又加入了一项,这一项也很简单。前一项旨在提高模型输出的分数,我们最大化这个损失函数就是为了实现这一点。后一项则是确保模型更新后的参数不偏离原来的参数太远,通过KL散度来实现,以防止模型参数偏离过远,从而避免模型崩溃。然而,实际操作中的PPO算法较为复杂,需要许多工程上的细节才能实现得特别好。现在,我们就可以构建出一个ChatGPT,其实就是这些步骤。

-
强大的能力构建方式简单,信息公开。
-
构建步骤包括Instruction Tuning和RLHF。
-
最新研究表明,Reward Model并非必需。
-
可以通过数学推导去除Reward Model,实现自我评分。
-
新公式分为获胜数据和失败数据的奖励,优化两者差异。
-
这种方法称为DPO,不需要Reward Model。
能力如此强大,正如我们前面所言,但其构建方式实际上相当简单。这些信息都是公开的,没有任何保密内容。例如,这一步是Instruction Tuning,下一步则是进行RLHF(Reinforcement Learning from Human Feedback)。然而,最近的研究表明,Reward Model,即评分模型,并非总是必需的。例如,我们可以通过数学推导,去除Reward Model,让模型自我评分,进而推导出新的公式。在这个公式中,前半部分代表获胜数据的奖励,后半部分则代表失败数据的奖励。通过优化这两者之间的差异,我们同样在进行RLHF的过程,此时这种方法被称为DPO(Direct Preference Optimization),它不需要Reward Model。

-
DPO和PPO在效果上基本相同,且已被广泛应用。
-
RHF使用难度大,但在DPO和Zephyr出现前,开源社区中使用较少。
-
RHF的重要性在于提供A比B好的信号,帮助模型理解人类偏好。
-
尽管RHF被多家大公司使用,但在开源社区中,只有Llama2大规模运用了RLHF。
实际上,我们通过比较原始模型和更新后的模型,可以计算出它们的评分。实验证明,DPO和PPO的效果基本相同,并且已被广泛应用。由于RHF的使用难度较大,DPO的出现使得偏好学习得到了大规模的应用。尽管RHF被OpenAI、SRP和Google等公司广泛使用,但在DPO或Zephyr出现之前,开源社区中使用RHF的情况非常少。这是因为缺乏数据且训练难度大。然而,为什么需要RHF呢?因为即使模型能够正确执行任务,也不一定能得出我们真正想要的结果。人们有时并不清楚自己真正想要什么,只知道某些偏好。因此,我们需要给模型提供A比B好的信号,即A的评分高于B,这是RHF的重要性所在。尽管之前有许多关于RHF的论文发表,但在开源社区中,只有Llama2大规模地运用了RLHF。
-
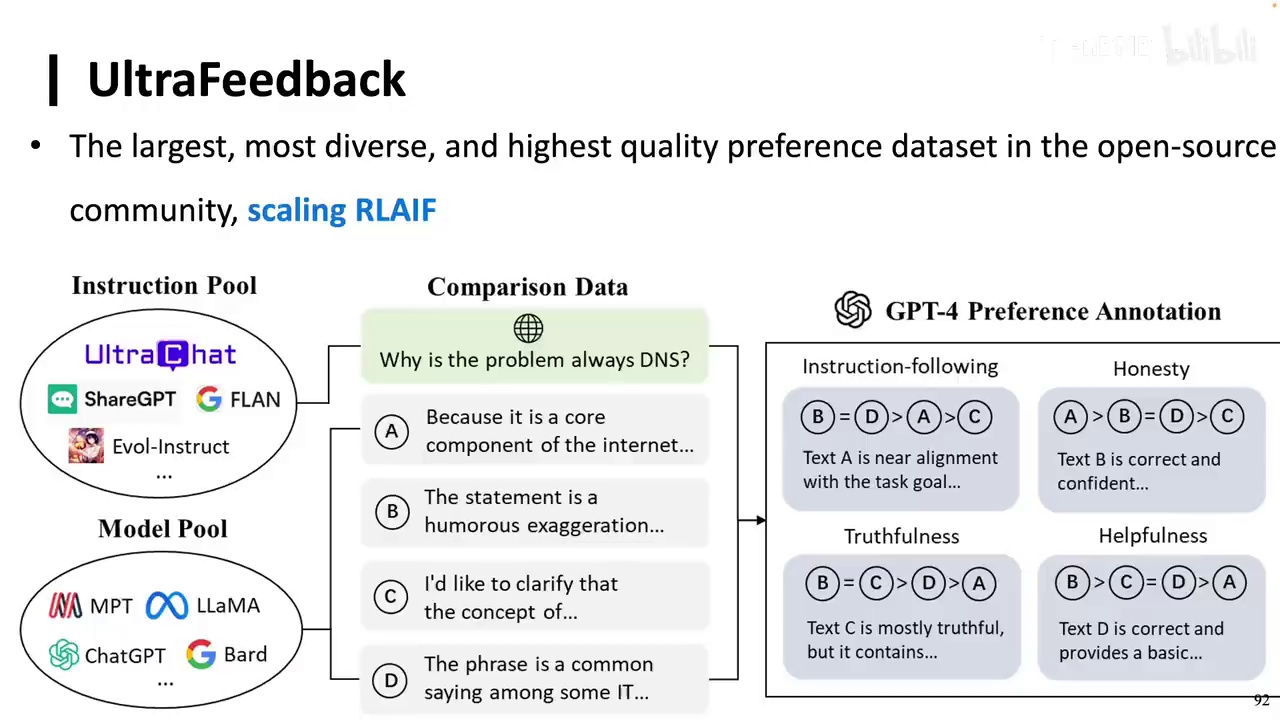
提出了Ultra系列数据集,包括Ultra Feedback等。
-
未使用RLHF,而是采用了RLAAF方法。
-
通过收集指令和回复池,进行打分和回复,构建了大规模数据集。
-
至少有1000个以上的模型使用了Ultra系列数据进行对齐。
在很多任务上的表现可能并没有那么出色。因此,这时候我们需要的就是数据。我们也是做了一个Ultra系列的数据,名为Ultra Feedback。我们没有使用RLHF,而是使用了RLAAF。这相当于去收集指令池和回复池,然后进行打分和回复。通过这种方式构造了一个超大规模的数据集。现在几乎很多模型都会使用Ultra系列的数据来进行对齐。具体模型数量不详,但至少有1000个以上的模型使用了我们的数据。此外,还有Ultra Chat、Ultra Feedback和Ultra Interactive等数据集。
-
新方法在开源社区中非常流行,涉及数据和对齐方案。
-
该方法已支持超过1000个模型的使用,实际数量可能更高。
-
这些模型在Hugging Face上的下载量超过100万次。
-
使用频率排名中,Auto Feedback位列第五,Auto Chat位列第九。
这是我们最新的方法,但今天不详细讨论。它可以说是目前开源社区中最流行的数据和对齐方案之一。实际上,我们的工作已经支持了超过1000个模型的使用。尽管我知道实际数量可能更多,因为许多未公开的项目也可能使用了我们的数据。这些模型在Hugging Face上的下载量已超过100万次。如果我们查看使用频率的排名,Auto Feedback位列第五,Auto Chat位列第九。其他高排名的是如ImageNet和Wikipedia等广泛使用的数据集。

-
偏好学习(RLHF):为大模型提供微妙的监督信号,指示A优于B。
-
扩展理解:通过理解模型中的偏好,可能扩展到理解宇宙信息和人类价值观。
-
学习方法的重要性:强调偏好本身的重要性,不限于特定方法(如PPO、DPO),甚至可能通过SFT学习偏好。
-
训练阶段:包括预训练(无监督语料)、后训练(有监督数据)和superalignment(待详细讲解)。
接下来我们将进行一个总结。RLHF,或者说称为Preference Learning,即偏好学习,它为大模型提供了一种超越答案的更为微妙的监督信号。它实际上是在告诉大模型A优于B。我们采用类似之前的思路进行扩展。当我们知道A优于B时,通过不断扩展,我们可能能够理解模型,进而理解整个世界,整个宇宙的信息。当我了解到宇宙中什么是更好的,我就隐含地学到了人类的价值观是什么样的,人类希望我具备什么样的能力,人类希望我的数学水平达到什么样,这些都隐含地被学习到。因此,无论是RLHF、PPO、DPO还是其他各种Po,其本质最重要的是偏好本身。很多时候,你甚至不需要Po,可能只需要SFT,通过不同的方式进行SFT也能学习到这种偏好。今天的课程到这里就结束了,我们讲了预训练,模型在大规模无监督语料上进行预训练,然后是后训练,在有监督的数据上进行学习。后面其实还有一个superalignment,这里我做了PPT,但后面会有一节课专门来讲这个内容。简单来说就是。
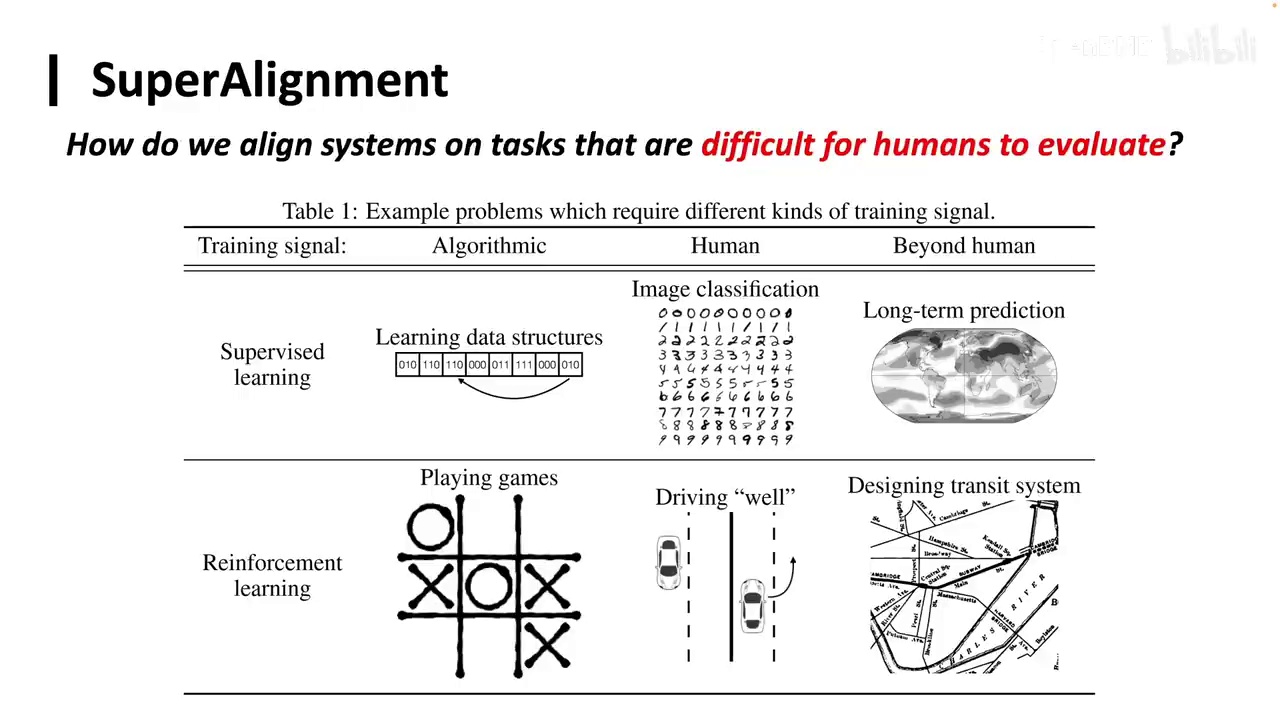
-
模型在某些能力上超越人类,如快速总结大量书籍。
-
确保模型没有采取捷径或隐藏行为的重要性。
-
缺乏监督信号导致难以判断模型输出的正确性。
-
超级对齐关注能力对齐和安全性,包括防止模型进行未监测的行为。
大家可以先思考一下,当模型在某些能力上超越人类时,例如总结一百本书,模型不仅做得更好,而且速度更快。在这种情况下,我们如何确保模型没有采取捷径或隐藏行为?当我们要求模型总结一百本书时,由于无法提供监督信号,我们无法判断其结果的正确性。模型可能表面上看起来正确,但并非我们期望的答案。因此,超级对齐关注的不仅是能力上的对齐,还包括安全性,例如模型是否可能进行未被监测的行为,如篡改代码或自我复制,甚至窃取能源。这些内容将在后续课程中详细讨论。今天的课程到此结束,谢谢大家。