开篇:
在《UI2CODE--整体设计》篇中,我们提到UI2CODE工程的第一步是版面分析,如果是白色的简单背景,我们可以像切西瓜一样,将图片信息切割为GUI元素。但是在实际生产过程中,UI的复杂度会高很多。本篇我们将围绕版面分析这块内容分享我们的探索过程。
架构设计:
版面分析主要处理UI图像的前景提取和背景分析:
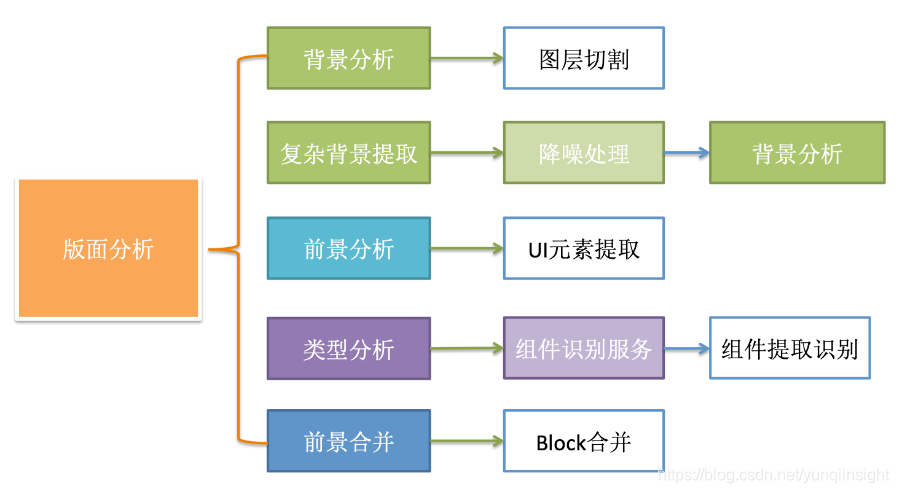
通过前后景分离算法,将UI视觉稿剪裁为GUI元素:
背景分析:通过机器视觉算法,分析背景颜色,背景渐变方向,以及背景的连通区域。
前景分析:通过深度学习算法,对GUI碎片进行整理,合并,识别。背景分析:
背景分析的关键在于找到背景的连通区域和闭合区间;
我们从一个实际的应用场景来分析整个背景提取的过程:
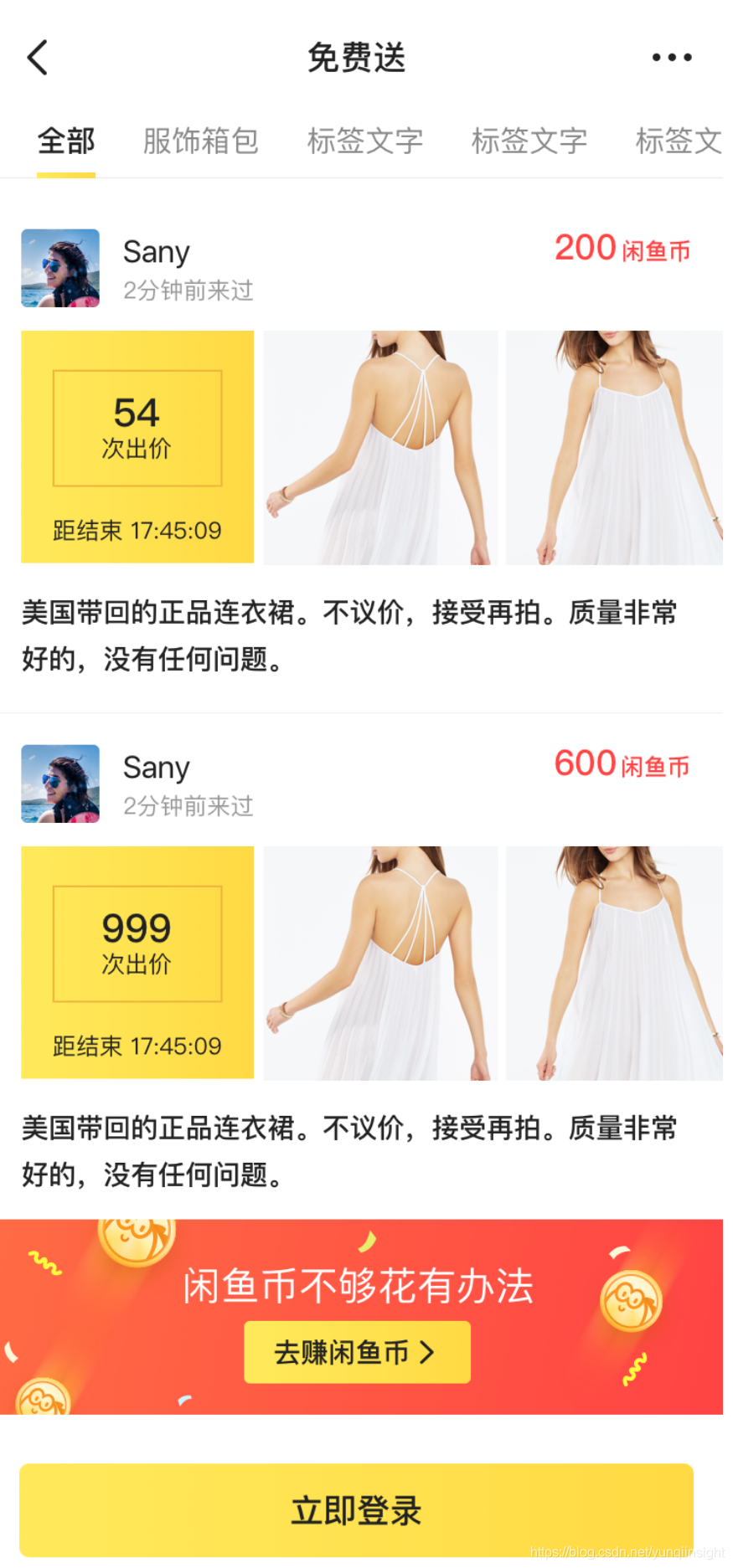
我们期望将上一张图片,通过UI2CODE,来提取GUI元素。
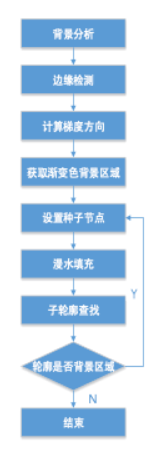
第一步:判断背景区块,通过sobel,Lapacian,canny等边缘检测的方法计算出梯度变化方向,从而得到纯色背景和渐变色背景区域。
基于拉普拉斯算子的背景区域提取
离散拉普拉斯算子的模板:

扩展模板:
当该区域点与模板点乘,得到的数值越小越是平坦的区域,即接近背景区域。如果是渐变色区域,则统计它的运动趋势。(左->右,右->左,上->下, 下->上)
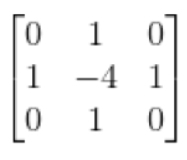
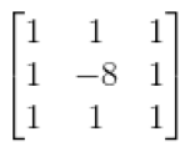
提取效果如下:

我们发现上图虽然能大致提取背景轮廓,但是对于有渐变色的背景还是比较粗糙。
因此我们通过统计背景运动趋势的方式来判定它是否存在渐变色背景。如果存在,我们将通过第二步进行精细化处理。
第二步:基于漫水填充算法,选取漫水的种子节点,滤除渐变色背景区域噪声。
def fill_color_diffuse_water_from_img(task_out_dir, image, x, y, thres_up = (10, 10, 10), thres_down = (10, 10, 10), fill_color = (255,255,255)):
"""
漫水填充:会改变图像
"""
# 获取图片的高和宽
h, w = image.shape[:2]
# 创建一个h+2,w+2的遮罩层,
# 这里需要注意,OpenCV的默认规定,
# 遮罩层的shape必须是h+2,w+2并且必须是单通道8位,具体原因我也不是很清楚。
mask = np.zeros([h + 2, w + 2], np.uint8)
# 这里执行漫水填充,参数代表:
# copyImg:要填充的图片
# mask:遮罩层
# (x, y):开始填充的位置(开始的种子点)
# (255, 255, 255):填充的值,这里填充成白色
# (100,100,100):开始的种子点与整个图像的像素值的最大的负差值
# (50,50,50):开始的种子点与整个图像的像素值的最大的正差值
# cv.FLOODFILL_FIXED_RANGE:处理图像的方法,一般处理彩色图象用这个方法
cv2.floodFill(image, mask, (x, y), fill_color, thres_down, thres_up, cv2.FLOODFILL_FIXED_RANGE)
cv2.imwrite(task_out_dir + "/ui/tmp2.png", image)
# mask是非常重要的一个区域,这块区域内会显示哪些区域被填充了颜色
# 对于UI自动化,mask可以设置成shape,大小以1最大的宽和高为准
return image, mask
处理过后的效果如下:

第三步:通过版面切割,提取GUI元素,切割方法之前有提到过。

这个时候我们已经成功提取了80%的GUI元素,但是叠加图层部分元素还无法解析。
第四步:通过霍夫直线、霍夫圆和轮廓查找的方式找到对称的轮廓区域。对提取的轮廓区域做第二步到第四步的递归处理。
复杂背景的提取是后续前景分析的基础。当提炼出背景区域后,我们就可以通过连通域分析前景区域,并利用组件识别的方式分析前景类别,再通过语义分析等方式对前景做拆分和合并。
背景分析小结:
对比较简单的渐变色背景,通过上述四步基本都能够解决。基于霍夫直线和霍夫圆的思想,去查找特定的轮廓区域,并分析这些轮廓区域做细化分析。再通过漫水填充的方式消除渐变色背景。
对于复杂背景的处理,可以基于目标检测的方法,找到一些特定含义的内容。再利用马尔科夫随机场(mrf)细化边缘特征。
前景分析
前景分析的关键在于组件完整性切割与识别;
我们通过连通域分析,防止组件碎片化,再通过机器学习识别组件类型,再通过组件类型进行碎片化合并,反复执行上述动作,直到无特征属性碎片。
但是有些情况会比较复杂,我们通过瀑布流中提取一个完整item为例:
概述
闲鱼页面中瀑布流卡片识别是实现布局分析的一个重要步骤,需求是当卡片完整出现在截屏图像中时(允许图标遮挡)需要识别出来,卡片被背景部分遮挡时不应该识别出来。下图所示的瀑布流卡片样式,由于其布局紧凑且样式繁多,导致容易产生漏检或误检。
瀑布流卡片样式 a)红框显示卡片部分被图标遮挡 b)红框显示卡片内图片颜色和卡片外背景颜色接近

基于边缘梯度或连通域的传统图像处理方法能根据图像本身的灰度或者形状特征提取出瀑布流卡片的轮廓,优点是定位精度高、运算速度快。缺点是容易受到干扰,召回率不高。
基于目标检测或者特征点检测的深度学习方法采用有监督的方式学习卡片的样式特征,优点是不易受到干扰,召回率很高。缺点是因为涉及回归过程,定位精度比传统图像处理方法要低,并且需要大量的人工标注,运算速度也比传统图像处理方法要慢。
受集成学习的启发,通过融合传统图像处理方法和深度学习方法,结合两者各自的优点,最终能得到具有较高精确率、召回率和定位精度的识别结果。
传统图像处理
1.算法流程
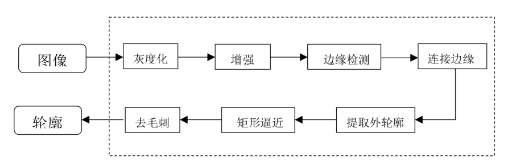
整个算法流程如下图所示:
1》. 输入的瀑布流卡片图像转换成灰度图后使用对比度受限的自适应直方图均衡化(CLAHE)进行增强
2》. 使用Canny算子进行边缘检测得到二值化图像
3》. 对二值化图像进行形态学膨胀处理,连接断开的边缘
4》. 提取连续边缘的外层轮廓,并基于轮廓包含区域的面积大小丢弃面积较小的轮廓,输出候选轮廓
5》. 使用Douglas-Peucker算法进行矩形逼近,保留最像矩形的外轮廓,输出新的候选轮廓
6》. 最后对第4步的候选轮廓进行水平和垂直方向投影得到平滑的轮廓作为输出
卡片轮廓提取流程
2.边缘检测
算法流程中1》-3》可以归为边缘检测部分。
受各种因素影响,图像会出现降质,需要对其进行增强来提高边缘检测的效果。使用全图单一的直方图进行均衡化显然不是最好的选择,因为截取的瀑布流图像不同区域对比度可能差别很大,增强后的图像可能会产生伪影。在单一直方图均衡化的基础上,学者基于分块处理的思想提出了自适应的直方图均衡化算法(AHE),但是AHE在增强边缘的同时有时候也会将噪声放大。后来学者在AHE的基础上提出了CLAHE,利用一个对比度阈值来去除噪声的干扰,如下图所示直方图,CLAHE不是将直方图中超过阈值的部分丢弃,而是将其均匀分布于其他bin中。
CLAHE对比度限制示意图

Canny算子是一种经典的边缘检测算子,它能得到精确的边缘位置。Canny检测的一般步骤为:1)用高斯滤波进行降噪 2)用一阶偏导的有限差分计算梯度的幅值和方向 3)对梯度幅值进行非极大值抑制 4)用双阈值检测和连接边缘。实验过程中,需要多次尝试选择较好的双阈值参数。
检测出来的边缘在某些局部地方会断开,可以采用特定形状和尺寸的结构元素对二值化图像进行形态学膨胀处理来连接断开的边缘。边缘检测的结果如下图所示,其中c)中CLAHE设定对比度阈值为10.0,区域大小为(10,10),d)中Canny检测设置双阈值为(20,80),e)中形态学膨胀结构元素使用大小为(3,3)的十字线。
边缘检测结果 a)原始图像 b)灰度化图像 c)CLAHE增强图像 d)Canny检测图像 e)形态学膨胀图像

3.轮廓提取
算法流程中4》-6》可以归为轮廓提取部分。
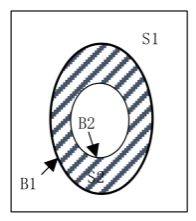
二值图像形态学膨胀处理后,首先提取连续边缘的外层轮廓。如下图所示,对于只有0和1的二值图像,假设S1为像素值为0的一堆背景点,S2为像素值为1的一堆前景点,外层轮廓B1为一堆前景点最外围的点,内层轮廓B2为一堆前景点最内部的点。通过对二值图像进行行扫描给不同轮廓边界赋予不同的整数值,从而确定轮廓的类型以及之间的层次关系。提取出外层轮廓后通过计算轮廓包含的面积大小丢弃面积较小的外层轮廓,输出第一步候选轮廓。
内外轮廓示意图
闲鱼页面瀑布流卡片轮廓近似于矩形,在四个角由弧形曲线连接。对于提取的候选轮廓使用Douglas-Peucker算法进行矩形逼近,保留形状接近矩形的外轮廓。Douglas-Peucker算法通过将一组点表示的曲线或多边形拟合成另一组更少的点,使得两组点之间的距离满足特定的精度。之后输出第二步候选轮廓。
通过对第二步候选轮廓所处位置对应的第一步候选轮廓进行水平和垂直方向投影,去除毛刺影响,输出矩形轮廓。轮廓提取的结果如下图所示,其中c)中轮廓包含面积设置的阈值为10000,d)中Douglas-Peucker算法设置的精度为0.01*轮廓长度。本文所有提取的轮廓均包含输入框。
轮廓提取结果 a)原始图像 b)形态学膨胀图像 c)红色线段为第一步候选轮廓 d)红色线段为第二步候选轮廓 e)红色线段为最终输出矩形轮廓

我们再介绍下机器学习如何处理:
深度学习算法
1.目标检测算法
传统算法中提出采用传统图像处理方法提取轮廓特征,这样会带来一个问题:当图像不清晰或者有遮挡的情况下无法提取出轮廓,即召回率不是很高。
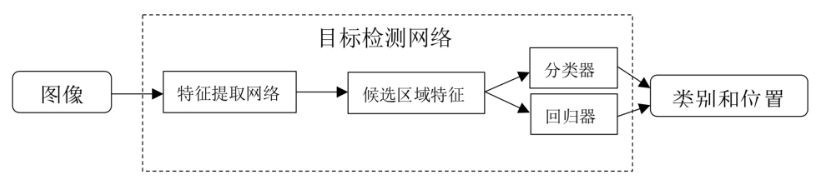
基于卷积神经网络的目标检测算法能通过输入大量样本数据,学习到更具有代表性和区别性的特征。目前目标检测算法主要分成两个派系:以R-CNN家族为代表的两阶段流和以YOLO、SSD为代表的一阶段流。一阶段流直接对预测的目标进行分类和回归,优点是速度快,缺点是mAP整体上没有两阶段流高。两阶段流在对预测的目标进行分类和回归前需要先生成候选的目标区域,这样训练时更容易收敛,因此优点是mAP高,缺点是速度上不如一阶段流。不管是一阶段流还是两阶段流,通用的目标检测推理过程如图所示。输入一张图像到特征提取网络(可选择VGG、Inception、Resnet等成熟的CNN网络)得到图像特征,然后将特定区域特征分别送入分类器和回归器进行类别分类和位置回归,最后将框的类别和位置进行输出。
目标检测推理过程
2.Faster R-CNN
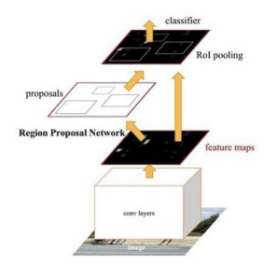
Faster R-CNN对R-CNN家族最大的贡献是将生成候选目标区域的过程整合到整个网络中,使得综合性能有了较大提高,尤其是在检测速度上。Faster R-CNN的基本结构如图所示。主要分为4个部分:1)conv layers。作为一种特征提取网络,使用一组基础的conv+relu+pooling层提取图像的特征,该特征被共享用于后续RPN网络和全连接层。2)Region Proposal Network。该网络用于生成候选目标框,通过softmax判断候选框是属于前景还是背景,并且通过候选框回归修正候选框位置。3)RoI pooling。收集输入的特征图和候选区域,将这些候选区域映射到固定大小并送入后续全连接层。4)classifer。计算候选框的具体类别,并且再次回归修正候选框的位置。
Faster R-CNN基本结构
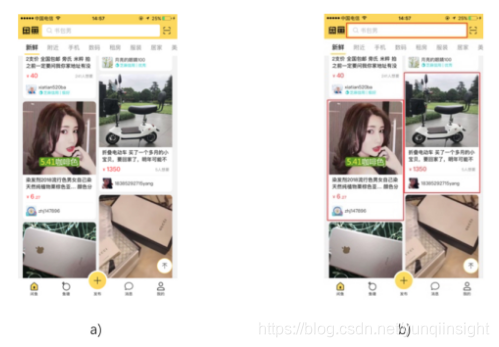
使用Faster R-CNN进行瀑布流卡片的识别,得到下图的结果。
Faster R-CNN识别结果 a)原始图像 b)红框显示识别的卡片
传统算法与机器学习的融合
1.融合流程
描述的传统图像方法能够获得高定位精度的卡片位置,但受卡片本身模式的影响,召回率不高)中右边卡片没有检测到。上文描述的基于目标检测的深度学习方法具有较高的泛化能力,能获得较高的召回率,但是回归过程无法得到高定位精度的卡片位置)中卡片都能检测出来,但有两个卡片的边缘几乎粘连在了一起。
将两种方法得到的结果融合在一起,能同时获得高精确率、高召回率、高定位精度的检测结果。融合过程如下:
- 输入一张图像,并行运行传统图像处理方法和深度学习方法,分别得到提取的卡片框trbox和dlbox。定位精度以trbox为标杆,精确率和召回率以dlbox为标杆
- 筛选trbox。规则为当trbox与dlbox的IOU大于某个阈值时(比如0.8)保留此trbox,否则丢弃,得到trbox1
- 筛选dlbox。规则为当dlbox与trbox1的IOU大于某个阈值时(比如0.8)丢弃此dlbox,否则保留,得到dlbox1
- 修正dlbox1位置。规则为dlbox1的每条边移动到距离其最近的一条直线上,约束条件为移动的距离不能超过给定的阈值(比如20个像素),并且移动的边不能跨越trbox1的边,得到修正的dlbox2
- 输出trbox1+dlbox2为最终融合的卡片框
2.结果
先介绍几个基本指标:
True Positive(TP):被模型预测为正的正例数
True Negative(TN):被模型预测为负的负例数
False Positive(FP):被模型预测为正的负例数
False Negative(FN):被模型预测为负的正例数
精确率(Precision) = TP/(TP+FP):反映了被模型预测的正例中真正的正样本所占比重
召回率(Recall) = TP/(TP+FN):反映了被模型正确预测的正例占总的正样本比重
定位精度(IOU) = 两个框的交集大小/两个框的并集大小
融合结果 a)原始图像 b)红框显示传统图像处理识别的卡片 c)红框显示深度学习识别的卡片 d)红框显示融合b)和c)后的卡片

上图分别显示了不同方法识别的卡片,d)相对于b)的优势是提高了召回率,d)相对于c)的优势是提高了定位精度。
图一图二图三显示了一些其他实例图像的识别,每行图像是一类实例图,第一列是原始图像,第二列是传统图像处理识别的卡片,第三列是深度学习识别的卡片,第四列是融合的卡片。
图一图二能够准确识别卡片轮廓:
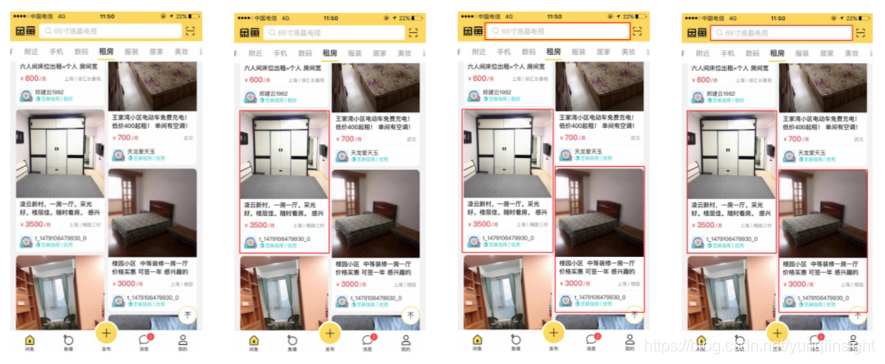
图一
图二
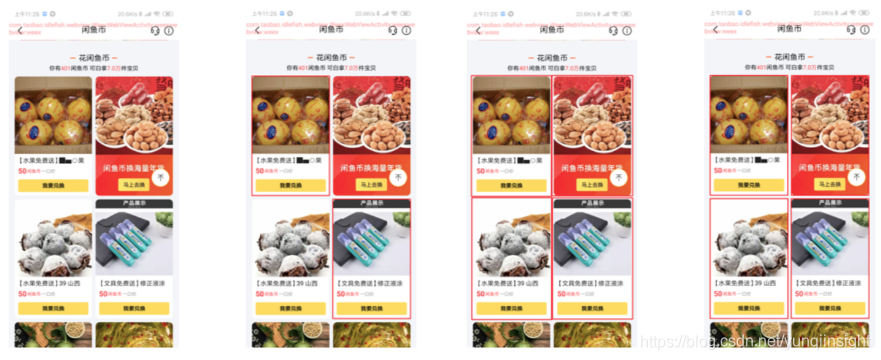
图三融合卡片的下边缘并没有完全贴合,这是因为融合步骤中修正dlbox1位置时,采用传统图像处理方法寻找临域范围内最近的直线,受到图像样式的影响,找到的直线并不是期望的卡片下边缘。
图三
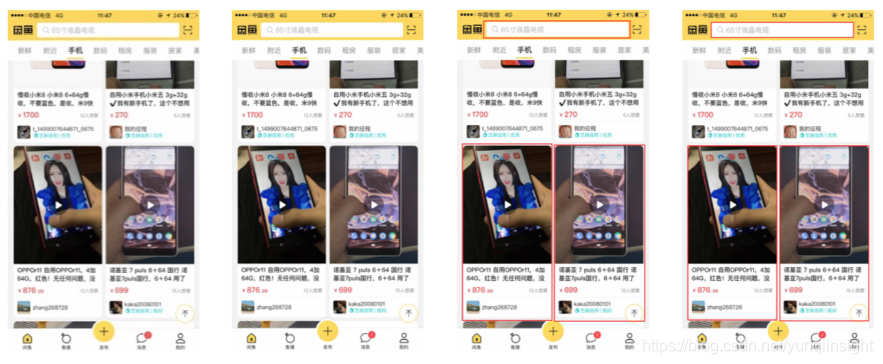
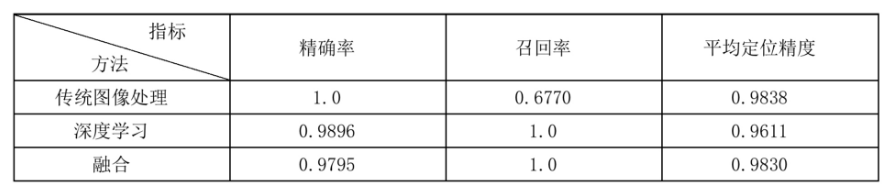
实验过程中随机截取了50张闲鱼瀑布流卡片图像,共有卡片96个(不包含输入框),对每张图像分别采用传统图像处理方法、深度学习方法、融合方法得到卡片的识别结果,其中传统图像处理方法共识别出65个卡片,深度学习方法共识别出97个,融合后共识别出98个。精确率、召回率、定位精度如下表所示。融合后识别结果结合了传统图像处理方法定位精度高、深度学习方法召回率高的优点。
不同方法结果
前景算法小结
通过对闲鱼页面瀑布流卡片识别过程中的描述,我们简单介绍了前景处理的探索,通过机器视觉算法和机器学习算法协同完成前景元素的提取和识别。
结束语
本篇我们通过对前景提取和背景分析的介绍,提出了一种通过传统图像处理和深度学习相融合的方法,来得到高精确率、高召回率和高定位精度的识别结果。但方法本身还存在一些瑕疵,比如融合过程对组件元素进行修正时也会受到图像样式的干扰,后续这部分可以进一步进行优化。
#阿里云开年Hi购季#幸运抽好礼!
点此抽奖:https://www.aliyun.com/acts/product-section-2019/yq-lottery?utm_content=g_1000042901
原文链接
本文为云栖社区原创内容,未经允许不得转载。