注:仅展示部分文档内容和系统截图,需要完整的视频、代码、文章和安装调试环境请私信up主。
摘 要
在这个现代化发展迅速并且是大数据的时代,人类社会的数据正以飞快的速度增长和发展。数据本身潜藏着非常大的价值,无论是对我们个人工作、生活,还是对企业未来的发展和商业化模式的创新,都有着很大的帮助。充分的挖掘数据潜在价值,能帮助人们找到更加适合自己的可合作的对象、性价比更高的生活用品,通过对比分析商品本身的性价比,更好的找到适合自己,更直观的对有需求的同种类商品进行对比。也能帮助企业更好的分析市场中人们所需要的物品,更好的将市场进行细化分类,有针对性地为企业在以后的发展提供数据上的支撑。
本系统使用了HTML、CSS、JavaScript、BootStrap、Python语言,采用了Django框架,旨在为基于用户分析的商品后台管理系统—以京东净水器为例进行设计与实现,分析客户净水器的主要评价,提出客户对净水器评价不足的地方让商家有对应修改点,最终设计与实现一个基于文本挖掘的小米净水器商品后台管理系统。
关键词:商品后台管理系统,Python,Django框架
目 录
2.4 爬虫技术介绍
如果要收集大量评论数据,就需要找到一种能够自动化、规模化抓取的工具。因此,我们可以借助强大的爬虫技术来完成留言收集和提取。该系统包括三个主要模块:网络请求模块、爬行控制模块和内容分析提取模块。网络请求模块包含初始 URL、请求头和响应头三个方面。
以前的网络爬虫通常从一个原始 URL开始,通过“深度”和“宽度”的策略不断提取新 URL,以实现目标页面的抓取。然而,现在的网站通常会针对DoS攻击采取一些防御措施,如对同一个IP访问的次数进行限制等。这对爬虫构成了一定的影响。因此,我们需要采用伪装成浏览器的方式来隐藏爬虫,利用代理IP进行访问,避免被网站限制。爬虫的运行控制需要设置爬虫按照何种规律进行抓取目标页面,网络上有许多开放源代码的爬虫可供使用,只需要设置好参数和抓取顺序即可。
在内容分析时,需要手动开启页面的Python脚本程序,通过特定标记格式或ID进行分析,找到有用的HTML标记下的内容,以抓取我们想要获取的信息。
2.5文本分词算法
文本分词算法(Text Segmentation Algorithm)是一种将一个连续的文本序列分割成符号单元序列的自然语言处理技术。其主要目的是识别和标准化一个句子或文本中的词汇和短语,以便于计算机对文本的处理和分析。
文本分词算法的应用非常广泛,包括搜索引擎、信息检索、机器翻译、分析索引、情感分析等领域。如何更加准确、高效地将文本分割成单词成为了自然语言处理领域的一个重要问题。
常见的文本分词算法包括基于规则的算法、基于统计的算法和基于深度学习的算法。
基于规则的算法首先需要人工定义一些规则或模板,以识别一个含有语法结构的文本中的特定单词或短语。例如,基于规则的算法可以根据标点符号、空格符和其他语言的规则来识别单词和短语。
基于统计的算法则是通过计算和分析大量的文本语料库来自动学习相应的分词模型。这种模型能够自适应地分析文本中的词汇之间的相关性,并且可以根据个别语言的特点来进一步提高算法的准确性。近年来,基于统计的算法的强大性能使其成为了许多自然语言处理任务的常用算法之一。
基于深度学习的算法则是通过神经网络来自动地学习文本分词模型,这种算法是近年来在自然语言处理领域中取得的最大突破之一。这种算法的优点是能够自动识别复杂的语言结构和语义关系,但是需要大量的训练数据和计算资源来支持其训练和推理。
总之,文本分词算法在自然语言处理领域中居于重要地位,其准确性和效率对于许多任务的成功实现至关重要。不同的算法有其优缺点,设计人员应该根据任务的要求选择适当的算法来实现高质量的文本分词。
2.6 添加情感因子的LDA主题模型
2.6.1LDA主题模型
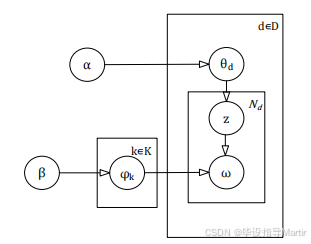
“主题模型”是一种方法,通常用来将文档归类到某个主题下。而LDA(潜在狄利克雷分配)则是一种非监督的贝叶斯模型,它包含词汇、主题和文档的三个层次结构。在建模时,不需要人工对训练数据进行标记,只需要规定一定数量的词汇和主题,并将某些词汇描述为与特定主题相关即可。文章中话题的传递符合多项式分布,而话题与词汇之间的关系也是如此。LDA是一种非监督方法,它可以从文本和数据中挖掘出潜在的话题。LDA的关键思想是利用词袋模型(Bag-of-Word)来将构建好的词汇向量空间转换为主题空间,这样就更容易求解。这种方法忽略了文本中词汇的位置信息,从而提高了模型的性能。每个文件都由若干个话题组成的一个概率,每个话题则是由很多字组成的。为了对文本进行自动分类,最有效的方法是对文本进行聚类,而贝叶斯理论为文本分类提出了基于后验分布的方法。
2.6.2LDA主题模型的实现
给定狄利克雷的先验参数 alpha 和 beta,以及文档 d 中的不同题目的多项式参数 theta 和不同题目 k 中不同单词的多项式参数 Phi,我们可以计算单词 omi 代表题目 k 的概率以及文档 d 中代表题目 zi 的概率,LDA模型图如下图2-1所示。
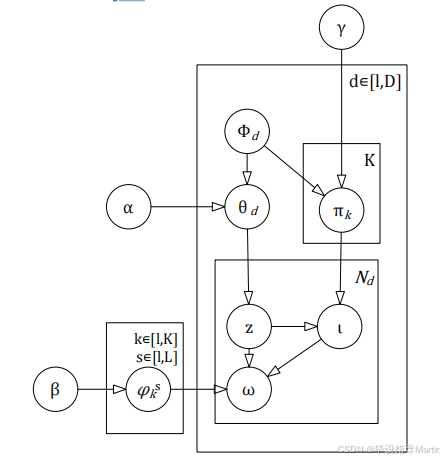
2.6.3R-STF-LDA情感主题模型
本项目提出了一种非监督的文本话题分类方法。这种方法利用了文本话题中词汇话题的话题性和情绪倾向性的同时存在的特点,并引入了情绪因素,从而实现了文本话题的自动分类。具体来说,首先假设文本和词汇间存在一个话题,可以从话题中获取词汇的空间位置和话题,并增加情绪标记,构建具有评价性质的 LDA 情绪话题的 RSTF-LDA 模型。其结构见附图2-2。在训练集中,使用一个情绪话题的词汇来推导出情绪话题,并在情绪话题对 [k, s] 中,使词汇的分配达到最大。同样地,通过计算一个有感情的题目的感情倾向性,用贝叶斯的数学方法反向推导出感情倾向性的题目的出现几率。在词汇、评论文档、主题及情感四个维度中,主题 Z 与文档有关,情感极性与主题 Z 有关,词汇既与主题 Z 也与情感极性有关。。
(1)对于评论文档d
首先,我们会根据评论的评价结果构建一个话题分布,即 theta do(Dir (gamma))。然后基于狄利克雷分布,我们会获得每个话题所代表的情绪倾向性的概率分布 pik(Dir (gamma))。
评论的点赞数量、附加评论,甚至对该评论的评论数量都能证明该评论得到了很多人的支持,因此这条评论应该比较受欢迎。在本文章中,我们使用一个人气系数为评论中的情绪和话题赋予更高的权重,这也更能代表出该评论的话题。
因此,当我们统计话题和情绪标记时,需要给予热度更高的评论更高的主题和情感标签概率。
(2)对于评论集中的单词ωi
首先,我们要选择第 i个词语的一个话题 zi,接着,我们要对该词语进行情绪分类,最终,我们要根据词语 omega i到 s的话题情绪对[k, s]中词语的分配来构建多项式(ωi~s)
4.2.4 前台数据分析模块
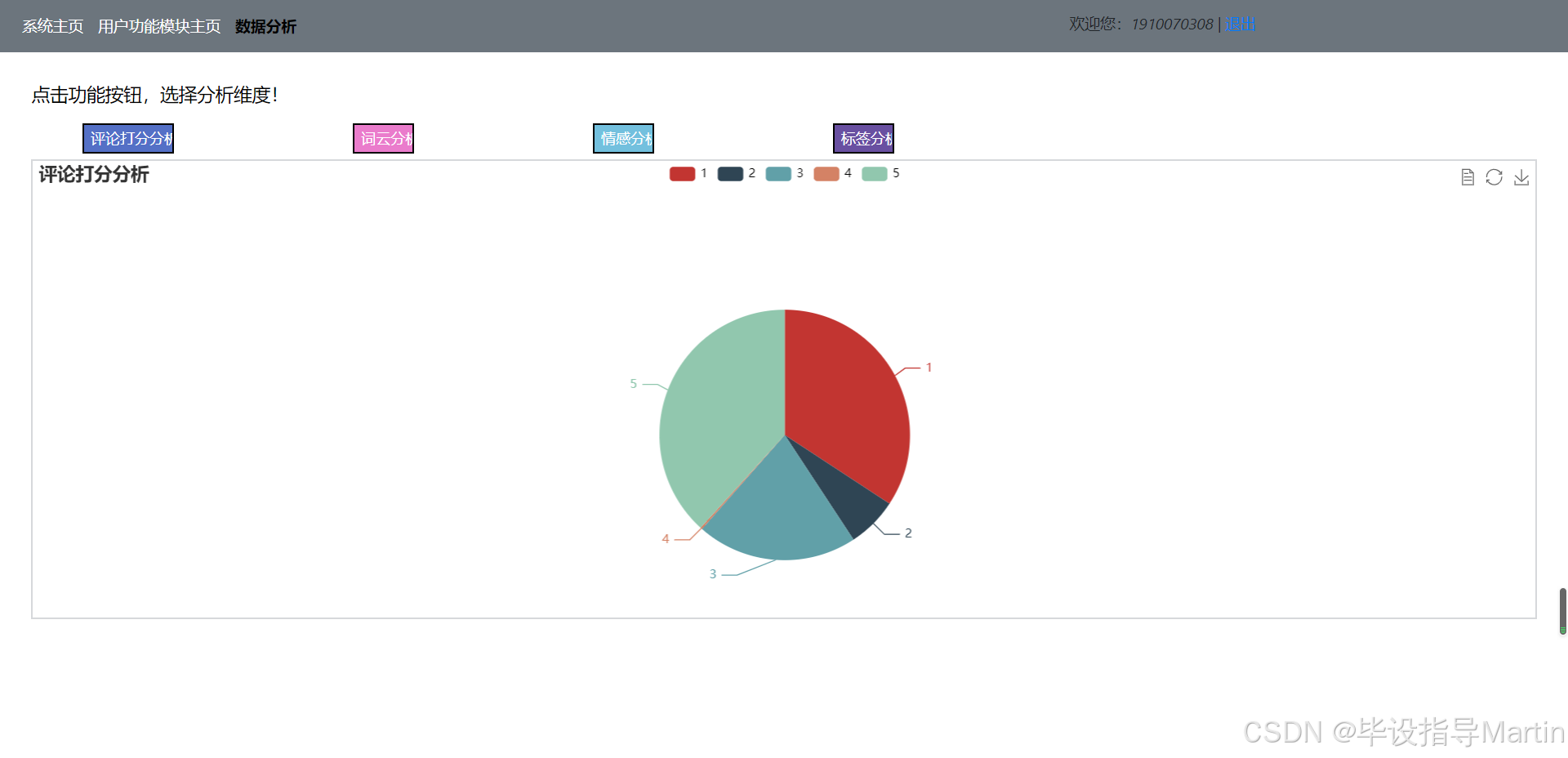
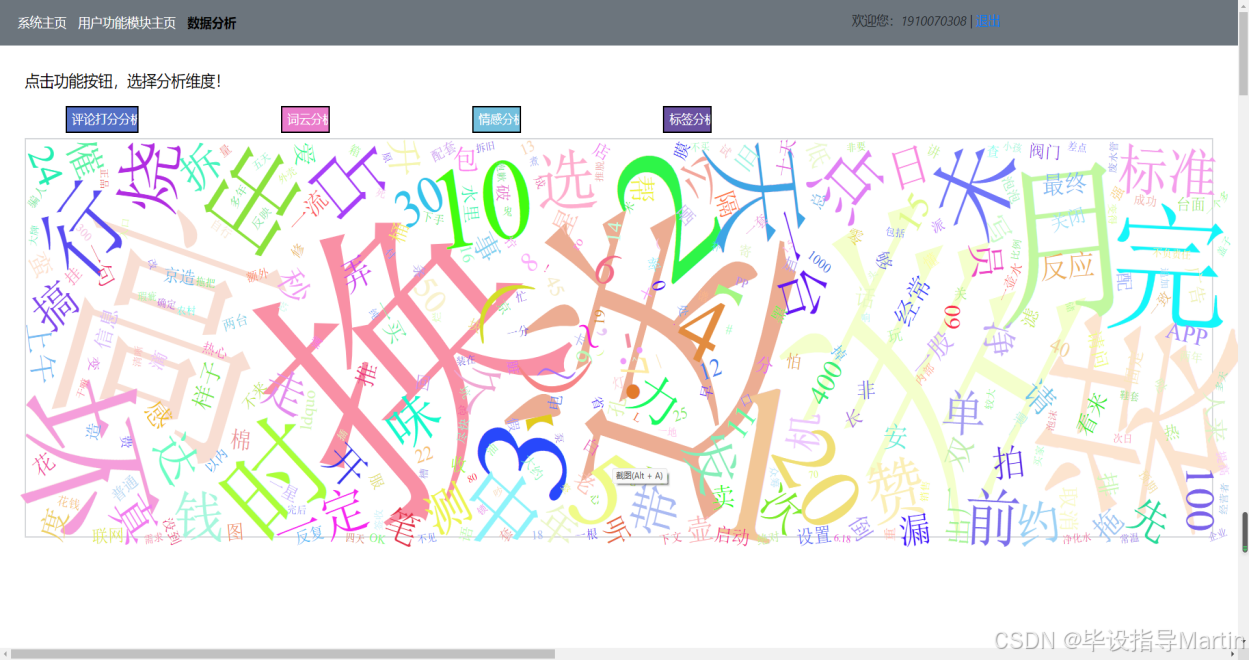
在前台用户主界面中点击“数据分析模块”,可进入数据分析页面,如图4.5所示。在数据分析页面有“评论打分分析”、“词云分析”、“情感分析”和“标签分类分析”四个功能按钮。分别如图4.5、4.6、4.7、4.8所示:
关于评论打分分析功能,