目录
2. Motivation:简单的增加网络宽度和深度和两个弊端:
11. ILSVRC Detection Challenge
1. 目标检测算法R-CNN分为两步:
-
首先利用低水平的线索(颜色、超像素一致性)以一种类别不确定的方式提取出可能的目标,
-
然后用CNN确定这些区域的物体类别
2. Motivation:简单的增加网络宽度和深度和两个弊端:
- 在训练数据集有限的情况下,会有过拟合风险
- 急剧增加计算资源
3.思路:
解决这些问题的方法当然就是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。
那么,有没有一种方法既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,就如人类的大脑是可以看做是神经元的重复堆积,因此,GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
-
4.Inception module:
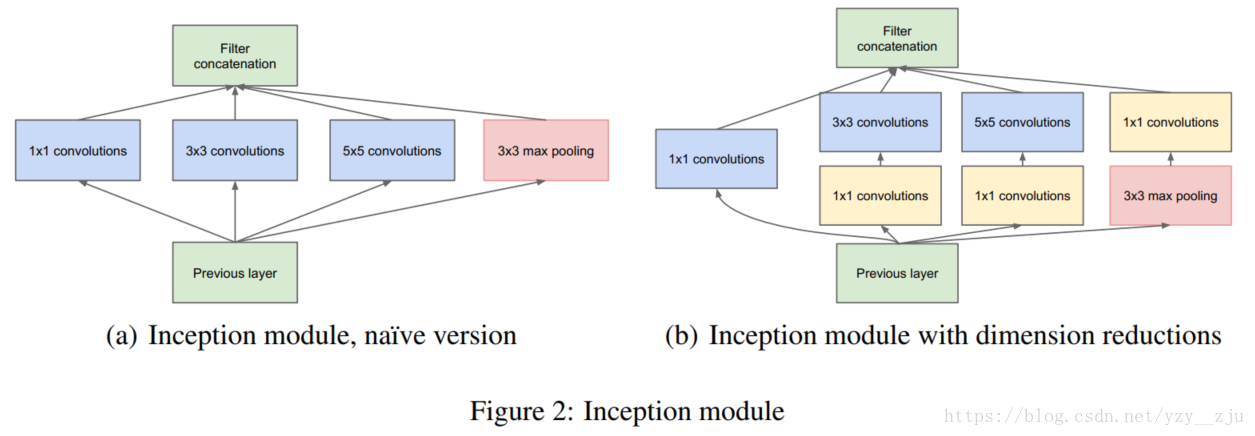
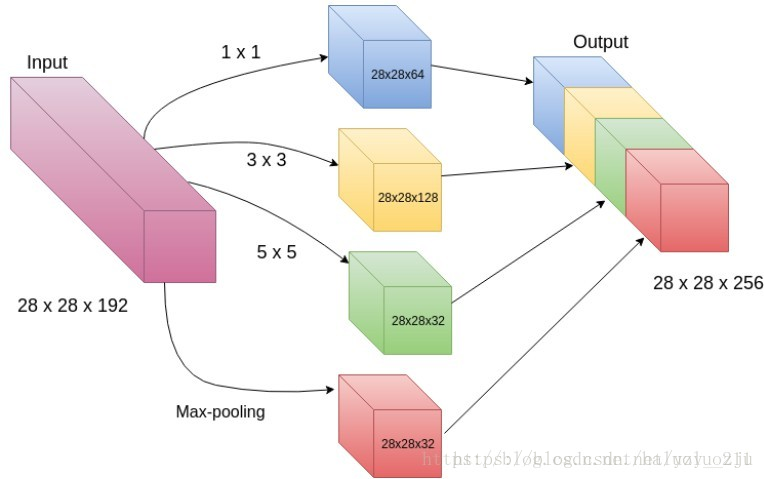
5.这种结构的两大好处:
- 在计算复杂度不发生blow up情况下,可在任何处增加inception unit的数量
- 视觉信息处理是在不同的特征尺度上的,使用不同大小的卷积核使得后层可从不同scale提取特征
6.结构参数表
- 在不会使就算复杂度发生blow up情况下,允许在每一阶段增加这种units的数量
- 视觉信息的处理应该在不同的尺度然后叠加起来,这样后一层可从不同的尺度提取特征
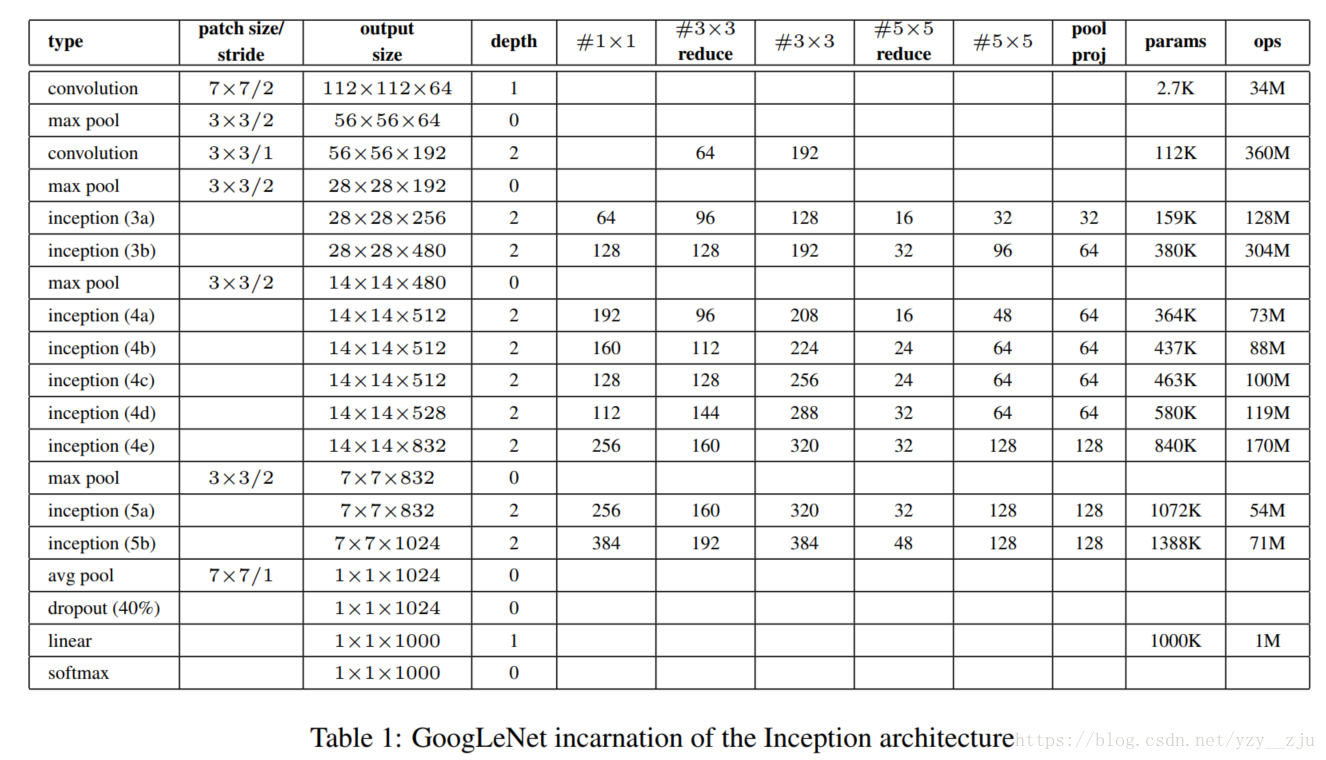
表中#3*3 reduce 和#5*5 reduce分别代表inception单元内3*3卷积核5*5卷积之前降维用的1*1卷积核的数量, pool proj代表max pooling之后1*1卷积核数量
7、1*1卷积作用
- 降维
- 加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;
8、GoogLeNet结构
由9组inception modul堆叠而成,共22层(算上池化共27层)
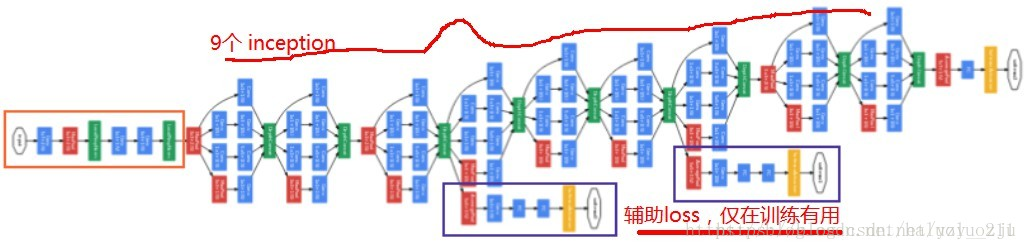
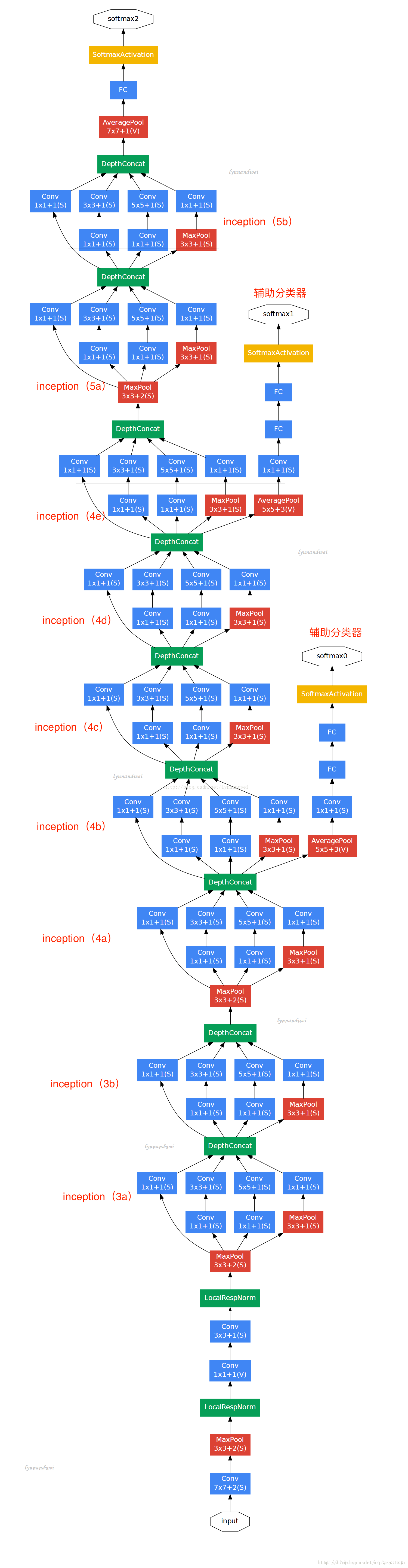
9. 两个辅助分类器
两个辅助分类器位于4a和4d模块的输出处,作用是在训练过程中提供反向传播的梯度。在训练阶段,两个辅助分类器的loss乘以打折的权重0.3加入到最终的loss值中;但在inference阶段,两个辅助分类器将被忽略。
10. 模型和训练、测试方法等更多细节
11. ILSVRC Detection Challenge
ILSVRC 目标检测共包含200个类别。若检测到的物体分类正确并且边界框和物体的重叠率不低于50%,则认为检测正确;若检测不相关则认为是假正例(false positive)并将被惩罚。不同于分类问题,目标检测任务每张图片可能包含很多物体,也可能没包含一个物体,而且物体的尺寸也是从小到大不等。检测衡量结果常用mAP(mean average precision)
- 采用集成学习。训练了7个版本的GoogLeNet模型(包括一个更宽的版本),它们除了样本采样方法不一样外,其余都相同(如参数初始化、学习率策略)。
- 训练方法和参数等不好确定
- 在测试阶段,对图片采用cropping approach裁剪方法,最终每一张原始图片都有144个crops(可理解为144个数据增强版) (4*3*6*2=144)
- 模型输出的softmax概率是经过平均的概率,即7个个体分类器在144个crops输出概率的平均值