【Redis源码】 RedisObject结构体
概要
博主这里从redis object由来,和从底层内存分配角度进行讲解哦,小伙伴们自行选择读取
1. redis object 由来
这里涉及到代码的设计思想:高内聚,低耦合,先通过一些例子加深理解,在讲解RedisObject是什么和其作用
🚀通过C语言来讲解下这个设计思想
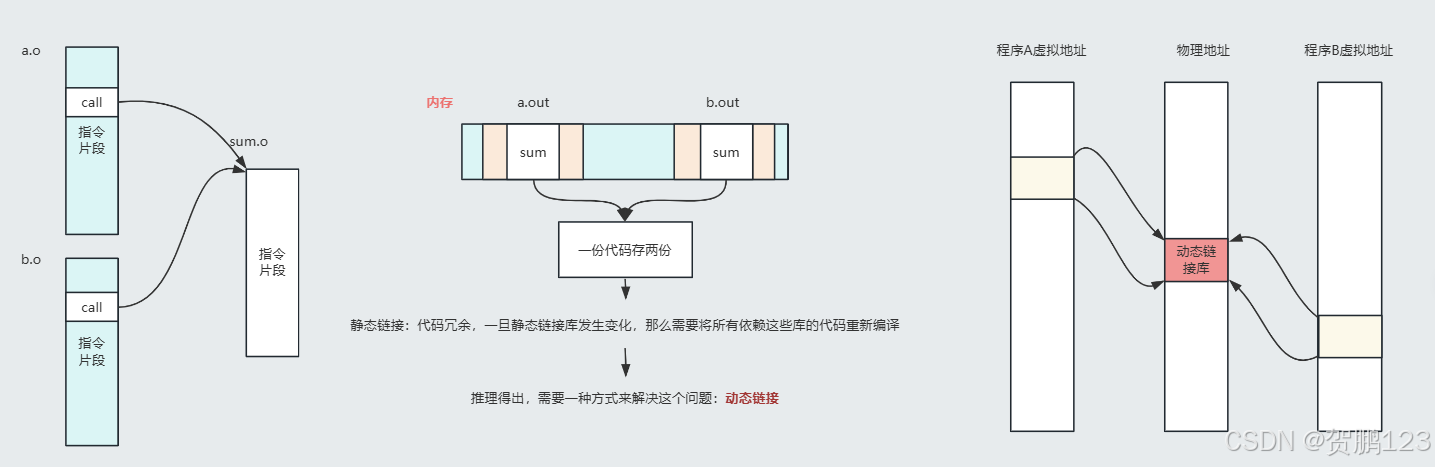
C语言中,分有静态链接,动态链接。他俩之间的区别在于代码的冗余,复用。
如果使用的是静态链接,demo1.c需要sum.o,demo2.c也需要sum.o,那么编译器会将sum.o代码放入demo1.c,demo2.c对应编译后的目标文件。这样就会产生一个sum.o代码在2个文件都有(若读者想自己尝试,可以通过objdump / readelf等命令查看生成的elf文件,如a.out里的代码信息),如果修改了sum.o里的代码,这对应的文件都需要重新编译,则就产生的高耦合。即使它代码运行速度快
如果使用的是动态链接,就可以通过动态链接器生成sum.so文件,当demo1.c代码或者demo2.c调用sum.c里的代码时,通过动态链接器,plt和got进行连接sum,这样就会实现一份代码,在多个文件复用
这张图可看到a.o和b.o要调用sum.o,对于静态链接需要一份代码存2份,而动态链接进行代码的动态链接
🚀Redis Object
Redis的基本数据结构,分有String,HashMap,Set,Sorted Set,List,Redis是用ANSI C标准来实现的,那既然牵涉C语言,C语言的数据类型的操作,底层就是通过malloc分配内存空间而已,分配多少定义成一个类型,如int是4byte,那就分配4byte空间,long是8byte,分配8byte空间
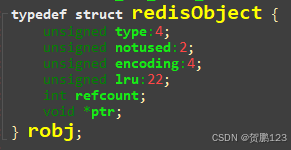
既然上面提到了代码的设计思想,现在又提到了数据类型定义,那有没有一种方式将这些Redis类型进行抽象高内聚化,形成一个结构体进行定义呢?redisObject结构体,那我们来看下redisObject结构体源码。
RedisObject源码图
虽然笔者是Java Coder,但看这些取名也不难看出
-
type:数据类型 -
notused:未使用标识 -
encoding:编码 -
lru:lru time -
refcount:被使用次数 -
*ptr:数据的指针🌟指针意义:
- 保存一个地址值指向数据内存的起始地址
- 指针的类型用于告诉编译器如何解释指向数据地址种的数据,如函数指针,告诉编译器是指向代码段的地址,执行里面的代码
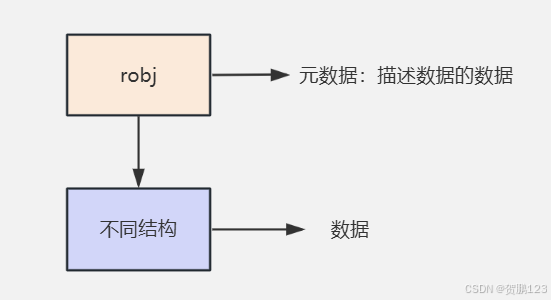
通过这些可以看出来,将多个结构的共同特性进行抽取形成robj,通过很多字段属性来定义这个数据属性,然后最后进行通过ptr来获取这个数据的内存地址,从而进行数据操作,也就是下面这张图
加上Redis为了节约内存的使用率,通过encoding指定编码来进行内存的节约使用,举个例子
这个a占用了3byte,
1和2和\0,加起来是3byte。如果这时使用b,只占用1byte。
这时空间就很好的利用
String a = "12";
byte b = 12;
也可以看robj的属性声明,是通过位域来进行声明,也不难看出,内存使用的节约性
unsigned type:4:定义4bit的type
简单通过这些,就可看出Redis的内存节约使用和代码的高效性。
2. 通过汇编代码分析
前面讲解了robj由来,简单的介绍,那现在我觉得需要进行一些底层代码上的理解,看看从底层是怎么进行内存分配和赋值操作的
这里,我写了一段c的代码,进行robj的代码理解,与底层的汇编是如何实现的
#include <stdio.h>
typedef struct redisObject {
unsigned type:4;
unsigned notused:2; /* Not used */
unsigned encoding:4;
unsigned lru:22; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
int main(){
robj oo = {1,2,3,4,5,NULL};
printf("%d\n", oo.refcount); // 5
// 位域:(4+2+4+22)/8 = 4
// 4 + 4 + 8 = 16
printf("%d\n", sizeof(robj)); // 16
return 1;
}
🐱robj oo = {1,2,3,4,5,NULL}对应的汇编代码
笔者使用的eclipse编译生成的汇编,我这里使用的GNUC套件,所以是AT&T的语法
这里我将汇编的每行解释,都进行了注释,方便理解
20 robj oo = {1,2,3,4,5,NULL};
0000000000400549: movzbl -0x10(%rbp),%eax // movzbl,代表低8位,也就是10,其余高位扩展为0,也就是0x0000_0010(因为是eax,e是32位)
// 它开辟了16位的内存大小,从下面的代码对这个开辟的栈空间可看出,是用于临时变量存储
// 但由于代码每个属性的栈赋值最多只需8位,它却开辟了16位?
// 内存对齐,64位机,要求结构体以16byte对齐
// 它的位数加起来是128位哦(32 + 32 + 64) = 128只是正好,但如果你是一个属性,他也开辟16byte
// type赋值
000000000040054d: and $0xfffffff0,%eax // 截断eax低4位 --》 unsigned type:4; 初始化为0
0000000000400550: or $0x1,%eax // 将1与eax相与 --》 保存type的位域为1
0000000000400553: mov %al,-0x10(%rbp) // 低8位 放入rbp
0000000000400556: movzbl -0x10(%rbp),%eax // rbp低16位(其余是0填充)放入eax
// notused赋值
000000000040055a: and $0xffffffcf,%eax // 截断从左数的5-6位 --》 unsigned notused:2; 初始化为0
000000000040055d: or $0x20,%eax // 将2和eax相与 --》保存notused为2 (使用or,保留之前的type的位域值)
0000000000400560: mov %al,-0x10(%rbp) // 将寄存器的低8位放入rbp
0000000000400563: movzwl -0x10(%rbp),%eax // 将rbp的低8位放入eax
// encoding赋值
0000000000400567: and $0xfc3f,%ax // 截断从左数7-10,放入16位寄存器 --》unsigned encoding:4; 初始化为0
000000000040056b: or $0xc0,%al // 1100_0000,和寄存器的低8位相与操作 --》 保存enconding为3
000000000040056d: mov %ax,-0x10(%rbp) // 将16位的ax放入rbp里
0000000000400571: mov -0x10(%rbp),%eax // 将rbp(不做扩展0操作),放入32位eax
// lru赋值
0000000000400574: and $0x3ff,%eax // 截断从左数11-32,放入32位寄存器 --》unsigned lru:22; 初始化为0
0000000000400579: or $0x10,%ah // 寄存器现在的位域值:0011_10_0001 ->encoding_notused_type
// 0000_0000_1110_0001 高8_低8
// 现在进行ah,也就是16位寄存器的高8位进行与操作,0001_0000 | 0000_0000
// 得到lru的赋值
000000000040057c: mov %eax,-0x10(%rbp) // 放入rbp
// refcount赋值
000000000040057f: movl $0x5,-0xc(%rbp) // 前面的位域在rbp的12-16(因为是与操作,所以是在12-16里操作的),现在-0xc(%rbp)从12赋值
// ptr赋值
0000000000400586: movq $0x0,-0x8(%rbp) // 减8,进行0-8赋值这个地址
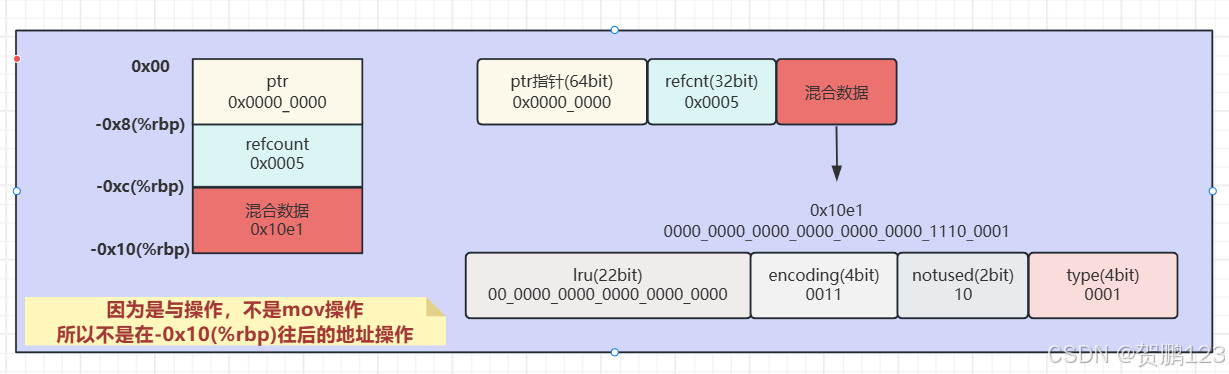
🚪这也是笔者画的图,方便更好的理解
从汇编代码可看出来,就是对一个16byte的操作,进行不同地址段间的赋值,从而进行提高内存的使用率
`robj`总共是32 + 32 + 64 = 128bit,占用了128/8 = 16byte
对于上面的汇编代码,开辟了16byte的内存空间,作为临时变量赋值存储,但我还需要强调一下,64位机,结构体需要内存是16byte,所以即使你是一个属性,也会开辟16byte哦
🐯对于底层来说,利用指针来指向操作的数据内存,在128位里,分段成不同的区间进行不同变量的赋值,这样Redis就很好的利用了内存空间,达到内存的高利用率。
从下面的图我们可以看出
0x00 ~ 0x8存储的是ptr指针0x8 ~ 0xc存储的是refcount0xc ~ 0x10存储的是真正的数据
对于混合数据,又进行分位域属性,达到更好的利用率
3. 总结
⭐️对于RedisObject,分析到这,可以很好的理解它本身出现的意义和作用
在C里通过指针地址来指向操作数据的地址空间,通过类型来定义操作多少byte内存空间大小,redisObject在进行了代码的高内聚抽象,形成了robj。
在通过不同的属性,进行封装,利用位域达到最大化的空间利用率,再通过汇编代码角度,进行了robj层面的理解