Flink CDC系列之:学习理解核心概念——Transform
Transform
Transform模块帮助用户根据表中的数据列进行数据列的删除和扩展。
此外,它还可以帮助用户在同步过程中过滤一些不必要的数据。
参数
为了描述转换规则,可以使用以下参数:
| 参数 | 含义 | 可选/必需 |
|---|---|---|
| source-table | 源表id,支持正则表达式 | 必需 |
| projection | 投影规则,支持类似SQL中select子句的语法 | 可选 |
| filter | 过滤规则,支持类似SQL中where子句的语法 | 可选 |
| primary-keys | Sink 表主键,以逗号分隔 | 可选 |
| partition-keys | 接收表分区键,以逗号分隔 | 可选 |
| table-options | 用于自动创建表时配置表创建语句 | 可选 |
| description | 变换规则说明 | 可选 |
可以在一个管道 YAML 文件中声明多个规则。
元数据字段
字段定义
有一些隐藏列用于访问元数据信息。它们仅在转换规则中明确引用时才会生效。
| 字段 | 数据类型 | 描述 |
|---|---|---|
| namespace_name | String | 包含该行的命名空间的名称。 |
| schema_name | String | 包含该行的架构的名称。 |
| table_name | String | 包含该行的表的名称。 |
| data_event_type | String | 数据改变事件的操作类型。 |
元数据关系
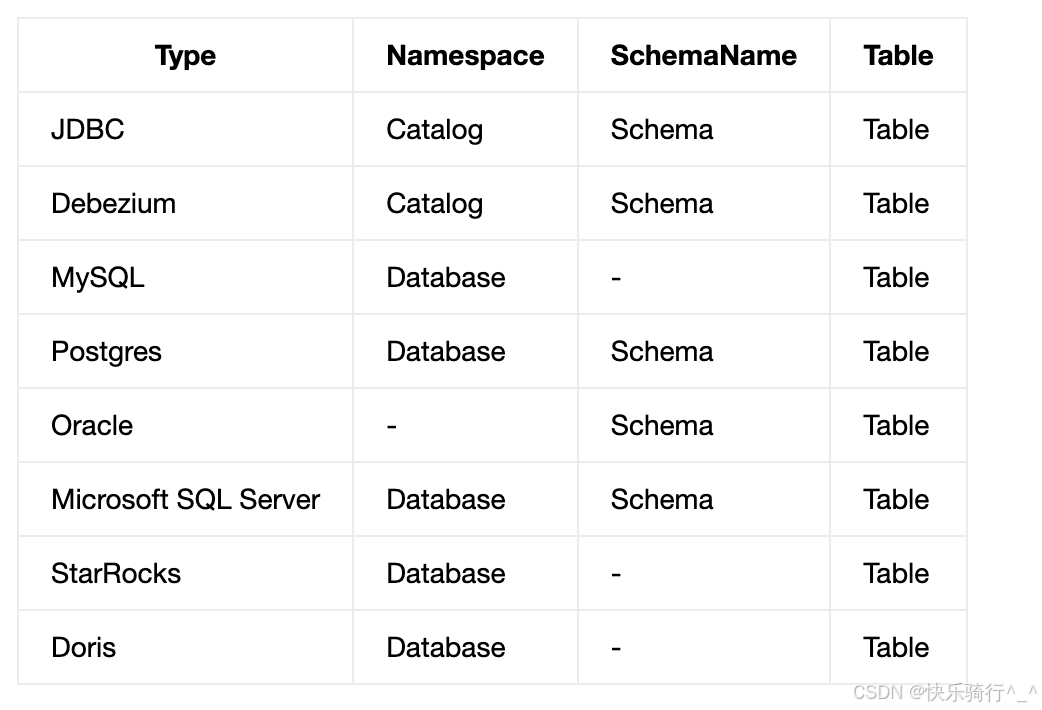
函数
Flink CDC 使用 Calcite 解析表达式,并使用 Janino 脚本通过函数调用来评估表达式。
比较函数
| Function | Janino Code | 描述 |
|---|---|---|
| value1 = value2 | valueEquals(value1, value2) | 如果 value1 等于 value2,则返回 TRUE;如果 value1 或 value2 为 NULL,则返回 FALSE。 |
| value1 <> value2 | !valueEquals(value1, value2) | 如果 value1 不等于 value2,则返回 TRUE;如果 value1 或 value2 为 NULL,则返回 FALSE。 |
| value1 > value2 | value1 > value2 | 如果 value1 大于 value2,则返回 TRUE;如果 value1 或 value2 为 NULL,则返回 FALSE。 |
| value1 >= value2 | value1 >= value2 | 如果 value1 大于或等于 value2,则返回 TRUE;如果 value1 或 value2 为 NULL,则返回 FALSE。 |
| value1 < value2 | value1 < value2 | 如果 value1 小于 value2,则返回 TRUE;如果 value1 或 value2 为 NULL,则返回 FALSE。 |
| value1 <= value2 | value1 <= value2 | 如果 value1 小于或等于 value2,则返回 TRUE;如果 value1 或 value2 为 NULL,则返回 FALSE。 |
| value IS NULL | null == value | 如果值为 NULL,则返回 TRUE。 |
| value IS NOT NULL | null != value | 如果值不为 NULL,则返回 TRUE。 |
| value1 BETWEEN value2 AND value3 | betweenAsymmetric(value1, value2, value3) | 如果 value1 大于或等于 value2 且小于或等于 value3,则返回 TRUE。 |
| value1 NOT BETWEEN value2 AND value3 | notBetweenAsymmetric(value1, value2, value3) | 如果 value1 小于 value2 或大于 value3,则返回 TRUE。 |
| string1 LIKE string2 | like(string1, string2) | 如果 string1 与模式 string2 匹配,则返回 TRUE。 |
| string1 NOT LIKE string2 | notLike(string1, string2) | 如果 string1 与模式 string2 不匹配,则返回 TRUE。 |
| value1 IN (value2 [, value3]* ) | in(value1, value2 [, value3]*) | 如果 value1 存在于给定列表 (value2, value3, …) 中,则返回 TRUE。 |
| value1 NOT IN (value2 [, value3]* ) | notIn(value1, value2 [, value3]*) | 如果 value1 不存在于给定列表 (value2, value3, …) 中,则返回 TRUE。 |
逻辑函数
| Function | Janino Code | 描述 |
|---|---|---|
| boolean1 OR boolean2 | boolean1 | |
| boolean1 AND boolean2 | boolean1 && boolean2 | 如果 BOOLEAN1 和 BOOLEAN2 都为 TRUE,则返回 TRUE。 |
| NOT boolean | !boolean | 如果布尔值为 FALSE,则返回 TRUE;如果布尔值为 TRUE,则返回 FALSE。 |
| boolean IS FALSE | false == boolean | 如果布尔值为 FALSE,则返回 TRUE;如果布尔值为 TRUE,则返回 FALSE。 |
| boolean IS NOT FALSE | true == boolean | 如果 BOOLEAN 为 TRUE,则返回 TRUE;如果 BOOLEAN 为 FALSE,则返回 FALSE。 |
| boolean IS TRUE | true == boolean | 如果 BOOLEAN 为 TRUE,则返回 TRUE;如果 BOOLEAN 为 FALSE,则返回 FALSE。 |
| boolean IS NOT TRUE | false == boolean | 如果布尔值为 FALSE,则返回 TRUE;如果布尔值为 TRUE,则返回 FALSE。 |
字符串函数
| Function | Janino Code | 描述 |
|---|---|---|
| string1 | string2 | |
| CHAR_LENGTH(string) | charLength(string) | 返回 STRING 中的字符数。 |
| UPPER(string) | upper(string) | 返回大写的字符串。 |
| LOWER(string) | lower(string) | 返回小写的字符串。 |
| TRIM(string1) | trim(‘BOTH’,string1) | 返回删除两侧空格的字符串。 |
| REGEXP_REPLACE(string1, string2, string3) | regexpReplace(string1, string2, string3) | 返回 STRING1 中的字符串,其中所有与正则表达式 STRING2 匹配的子字符串均被 STRING3 连续替换。例如,‘foobar’.regexpReplace(‘oo |
| SUBSTRING(string FROM integer1 [ FOR integer2 ]) | substring(string,integer1,integer2) | 返回从位置 INT1 开始、长度为 INT2(默认到末尾)的 STRING 子字符串。 |
| CONCAT(string1, string2,…) | concat(string1, string2,…) | 返回连接 string1、string2、… 的字符串。例如,CONCAT(‘AA’, ‘BB’, ‘CC’) 返回 ‘AABBCC’。 |
时间函数
| Function | Janino Code | 描述 |
|---|---|---|
| LOCALTIME | localtime() | 返回本地时区的当前SQL时间,返回类型为TIME(0)。 |
| LOCALTIMESTAMP | localtimestamp() | 返回当前SQL本地时区的时间戳,返回类型为TIMESTAMP(3)。 |
| CURRENT_TIME | currentTime() | 返回本地时区的当前 SQL 时间,这是 LOCAL_TIME 的同义词。 |
| CURRENT_DATE | currentDate() | 返回本地时区的当前 SQL 日期。 |
| CURRENT_TIMESTAMP | currentTimestamp() | 返回当前SQL本地时区的时间戳,返回类型为TIMESTAMP_LTZ(3)。 |
| NOW() | now() | 返回本地时区的当前 SQL 时间戳,这是 CURRENT_TIMESTAMP 的同义词。 |
| DATE_FORMAT(timestamp, string) | dateFormat(timestamp, string) | 将时间戳转换为日期格式字符串指定格式的字符串值。格式字符串与 Java 的 SimpleDateFormat 兼容。 |
| TIMESTAMPDIFF(timepointunit, timepoint1, timepoint2) | timestampDiff(timepointunit, timepoint1, timepoint2) | 返回时间点 1 和时间点 2 之间的时间点单位的(有符号)数。间隔的单位由第一个参数指定,该参数应为以下值之一:SECOND、MINUTE、HOUR、DAY、MONTH 或 YEAR。 |
| TO_DATE(string1[, string2]) | toDate(string1[, string2]) | 将格式为 string2 的日期字符串 string1(默认为“yyyy-MM-dd”)转换为日期。 |
| TO_TIMESTAMP(string1[, string2]) | toTimestamp(string1[, string2]) | 将格式为 string2 的日期时间字符串 string1(默认情况下为:“yyyy-MM-dd HH:mm:ss”)转换为不带时区的时间戳。 |
条件函数
| Function | Janino Code | 描述 |
|---|---|---|
| CASE value WHEN value1_1 [, value1_2]* THEN RESULT1 (WHEN value2_1 [, value2_2 ]* THEN result_2)* (ELSE result_z) END | 嵌套三元表达式 | 当值第一次包含在(值 X_1、值 X_2、…)中时,返回 resultX。当没有值匹配时,如果提供了 result_z,则返回 result_z,否则返回 NULL。 |
| CASE WHEN condition1 THEN result1 (WHEN condition2 THEN result2)* (ELSE result_z) END | 嵌套三元表达式 | 第一个条件满足时返回resultX,不满足条件时,若有条件则返回结果,否则返回NULL。 |
| COALESCE(value1 [, value2]*) | coalesce(Object… objects) | 返回第一个不为 NULL 的参数。如果所有参数均为 NULL,则也返回 NULL。返回类型是其所有参数中限制最少的通用类型。如果所有参数也均为可空,则返回类型为可空。 |
| IF(condition, true_value, false_value) | condition ? true_value : false_value | 如果条件满足,则返回 true_value,否则返回 false_value。例如,IF(5 > 3, 5, 3) 返回 5。 |
示例
添加计算列
求值表达式可用于生成新列。例如,如果我们想基于数据库 mydb 中的表 web_order 附加两个计算列,我们可以定义一个转换规则,如下所示:
transform:
- source-table: mydb.web_order
projection: id, order_id, UPPER(product_name) as product_name, localtimestamp as new_timestamp
description: append calculated columns based on source table
参考元数据列
我们可以在投影表达式中引用元数据列。例如,给定数据库 mydb 中的表 web_order,我们可以定义转换规则如下:
transform:
- source-table: mydb.web_order
projection: id, order_id, __namespace_name__ || '.' || __schema_name__ || '.' || __table_name__ identifier_name
description: access metadata columns from source table
使用通配符投影所有字段
通配符 (*) 可用于引用表中的所有字段。例如,给定数据库 mydb 中的两个表 web_order 和 app_order,我们可以定义转换规则如下:
transform:
- source-table: mydb.web_order
projection: \*, UPPER(product_name) as product_name
description: project fields with wildcard character from source table
- source-table: mydb.app_order
projection: UPPER(product_name) as product_name, *
description: project fields with wildcard character from source table
注意:当表达式开头出现 * 字符时,需要使用转义反斜杠。
添加过滤规则
使用引用列在数据库mydb中的表web_order中添加过滤规则时,我们可以定义一个转换规则如下:
transform:
- source-table: mydb.web_order
filter: id > 10 AND order_id > 100
description: filtering rows from source table
计算列也可以用于过滤条件。例如,给定数据库 mydb 中的表 web_order,我们可以定义转换规则如下:
transform:
- source-table: mydb.web_order
projection: id, order_id, UPPER(province) as new_province
filter: new_province = 'SHANGHAI'
description: filtering rows based on computed columns
重新分配主键
我们可以在转换规则中重新分配主键。例如,给定数据库 mydb 中的表 web_order,我们可以定义转换规则如下:
transform:
- source-table: mydb.web_order
projection: id, order_id
primary-keys: order_id
description: reassign primary key example
还支持复合主键:
transform:
- source-table: mydb.web_order
projection: id, order_id, UPPER(product_name) as product_name
primary-keys: order_id, product_name
description: reassign composite primary keys example
重新分配分区键
我们可以在转换规则中重新分配分区键。例如,给定数据库 mydb 中的表 web_order,我们可以定义转换规则如下:
transform:
- source-table: mydb.web_order
projection: id, order_id, UPPER(product_name) as product_name
partition-keys: product_name
description: reassign partition key example
指定表创建配置
可以在转换规则中定义额外选项,这些选项将在创建下游表时应用。给定数据库 mydb 中的表 web_order,我们可以定义转换规则如下:
transform:
- source-table: mydb.web_order
projection: id, order_id, UPPER(product_name) as product_name
table-options: comment=web order
description: auto creating table options example
提示:table-options的格式为key1=value1,key2=value2。
分类映射
可以定义多个转换规则来对输入数据行进行分类并应用不同的处理。只有第一个匹配的转换规则才会应用。例如,我们可以定义如下转换规则:
transform:
- source-table: mydb.web_order
projection: id, order_id
filter: UPPER(province) = 'SHANGHAI'
description: classification mapping example
- source-table: mydb.web_order
projection: order_id as id, id as order_id
filter: UPPER(province) = 'BEIJING'
description: classification mapping example
用户定义函数
用户定义函数 (UDF) 可用于转换规则。
如果满足以下条件,类可用作 UDF:
- 实现 org.apache.flink.cdc.common.udf.UserDefinedFunction 接口
- 具有无参数的公共构造函数
- 至少有一个名为 eval 的公共方法
它还可以:
- 覆盖 getReturnType 方法以指示其返回 CDC 类型
- 覆盖 open 和 close 方法以执行一些初始化和清理工作
例如,这是一个有效的 UDF 类:
public class AddOneFunctionClass implements UserDefinedFunction {
public Object eval(Integer num) {
return num + 1;
}
@Override
public DataType getReturnType() {
return DataTypes.INT();
}
@Override
public void open() throws Exception {
// ...
}
@Override
public void close() throws Exception {
// ...
}
}
为了简化从 Flink SQL 到 Flink CDC 的迁移,Flink ScalarFunction 也可以用作转换 UDF,但有一些限制:
- 不支持具有带参数的构造函数的 ScalarFunction。
- ScalarFunction 中的 Flink 样式类型提示将被忽略。
- 不会调用打开/关闭生命周期钩子。
可以通过添加用户定义函数块来注册 UDF 类:
pipeline:
user-defined-function:
- name: addone
classpath: org.apache.flink.cdc.udf.examples.java.AddOneFunctionClass
- name: format
classpath: org.apache.flink.cdc.udf.examples.java.FormatFunctionClass
请注意,给定的类路径必须是完全限定的,并且相应的 jar 文件必须包含在 Flink /lib 文件夹中,或者使用 flink-cdc.sh --jar 选项传递。
正确注册后,UDF 可以在投影和过滤表达式中使用,就像内置函数一样:
transform:
- source-table: db.\.*
projection: "*, inc(inc(inc(id))) as inc_id, format(id, 'id -> %d') as formatted_id"
filter: inc(id) < 100
已知限制
- 目前,转换不适用于路由规则。它将在未来版本中得到支持。
- 计算列不能引用最终投影结果中不存在的修剪列。这将在未来版本中修复。
- 不支持具有不同架构的表的常规匹配。如有必要,需要编写多个规则。