由于学校的python是笔试,所以找了份感觉比较好的题库刷了下其中前八章的填空和判断,附上选解。各章链接如下
python程序设计题库完整版
https://blog.csdn.net/lijia111111/article/details/80763095
python程序设计第一章基础知识 题库及选解
https://blog.csdn.net/zimuzi2019/article/details/106963005
python程序设计第二章序列类型 题库及选解https://blog.csdn.net/zimuzi2019/article/details/106962735
python程序设计第三章选择与循环 题库及选解https://blog.csdn.net/zimuzi2019/article/details/106968152
python程序设计第四章字符串 题库及选解https://blog.csdn.net/zimuzi2019/article/details/106967507
python程序设计第五章函数设计与应用 题库及选解https://blog.csdn.net/zimuzi2019/article/details/106968597
python程序设计第六章面向对象程序设计 题库https://blog.csdn.net/zimuzi2019/article/details/106974412
python程序设计第七章文件操作 题库https://blog.csdn.net/zimuzi2019/article/details/106974419
python程序设计第八章异常 题库
https://blog.csdn.net/zimuzi2019/article/details/106974425
填空
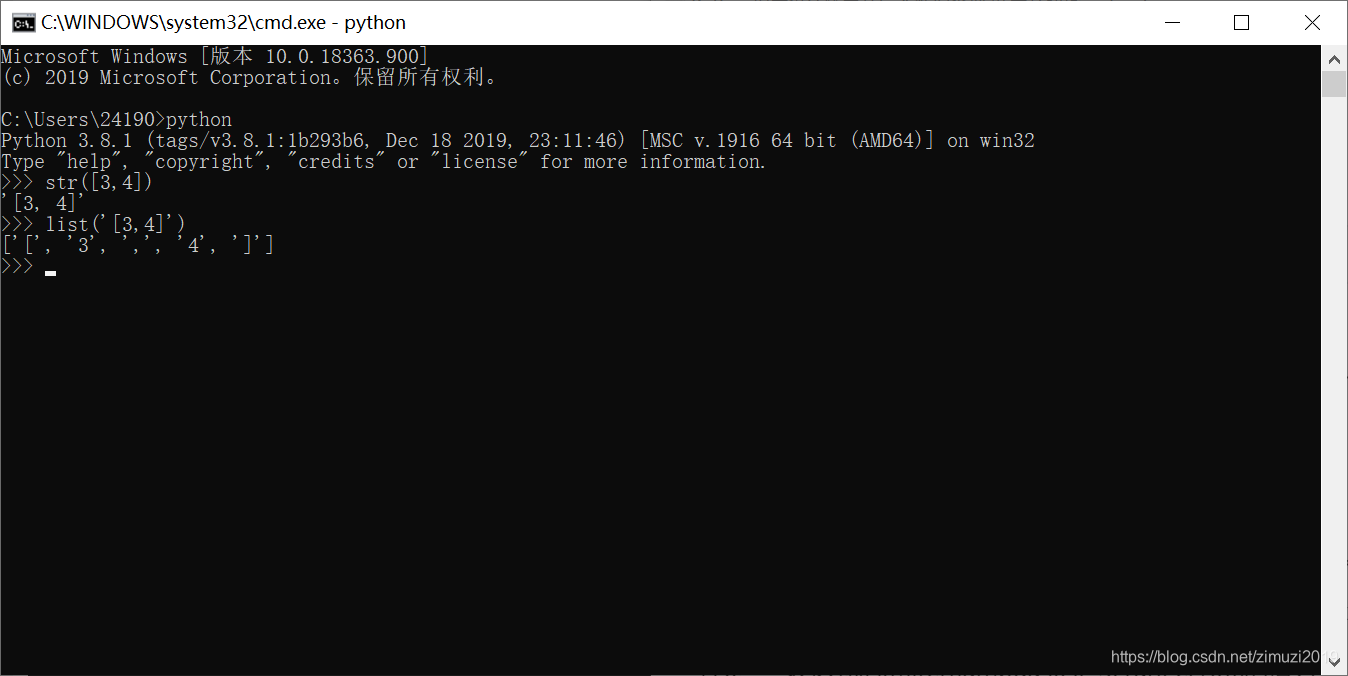
1、 表达式[1, 2, 3]*3的执行结果为() ([1,2,3,1,2,3,1,2,3])
2、 list(map(str, [1, 2, 3]))的执行结果为
['1','2','3']
- Python序列类型包括列表,元组,字典
- map()函数传入一个或多个序列,返回迭代器
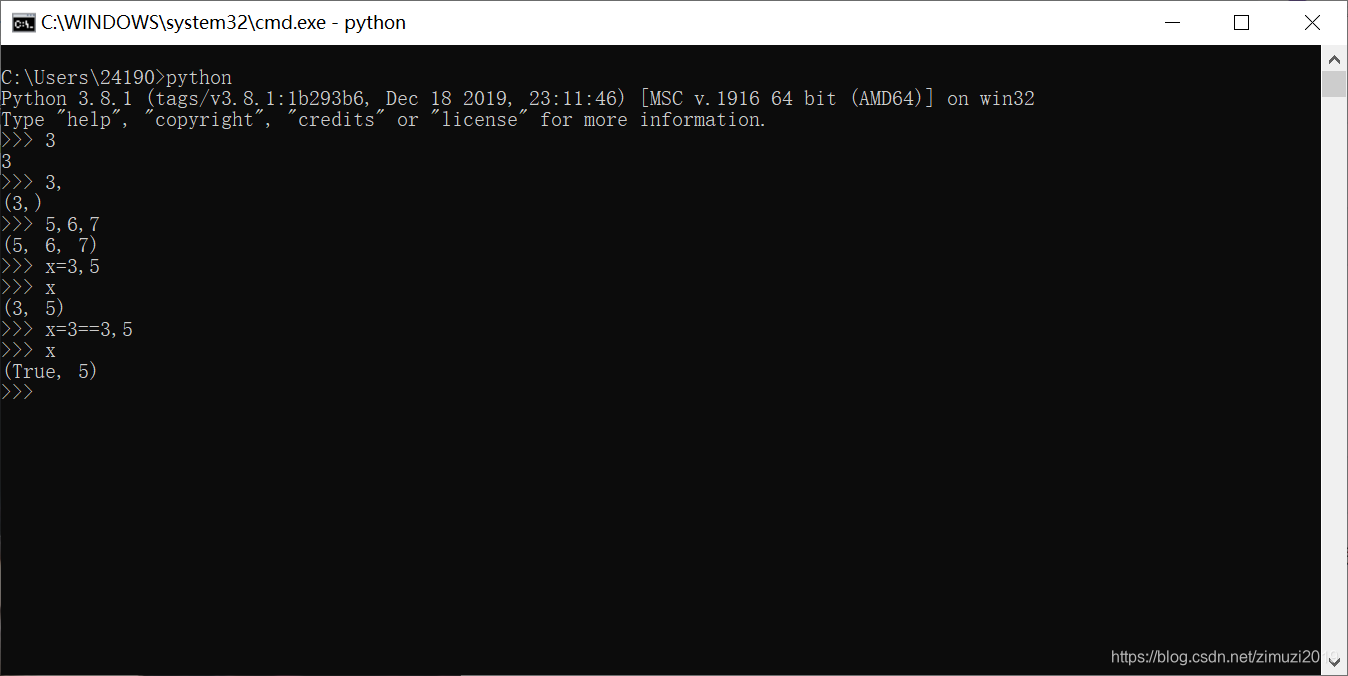
3、 语句x = 3==3, 5执行结束后,变量x的值为
(True, 5)
4、 已知 x = 3,并且id(x)的返回值为 496103280,那么执行语句 x += 6 之后,表达式 id(x) == 496103280 的值为() (False)
5、 已知 x = 3,那么执行语句 x *= 6 之后,x的值为() (18)
6、 表达式[3] in [1, 2, 3, 4]的值为
False
7、 列表对象的sort()方法用来对列表元素进行原地排序,该函数返回值为
None
8、 假设列表对象aList的值为[3, 4, 5, 6, 7, 9, 11, 13, 15, 17],那么切片aList[3:7]得到的值是() ([6, 7, 9, 11])
9、 使用列表推导式生成包含10个数字5的列表,语句可以写为
[5 for i in range(10)]
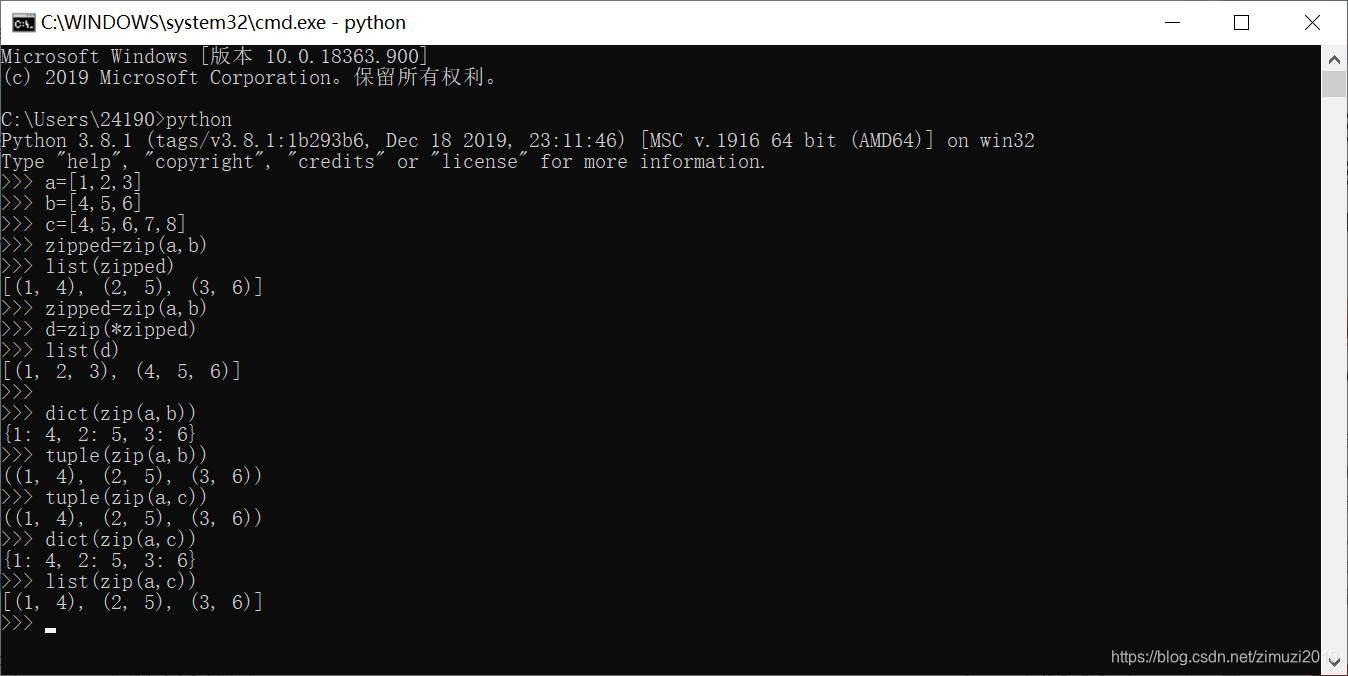
10、假设有列表a = [‘name’, ‘age’, ‘sex’]和b = [‘Dong’, 38, ‘Male’],请使用一个语句将这两个列表的内容转换为字典,并且以列表a中的元素为“键”,以列表b中的元素为“值”,这个语句可以写为
c = dict(zip(a, b))
- zip()函数传入一个或多个可迭代对象,返回迭代器
11、 任意长度的Python列表、元组和字符串中最后一个元素的下标为() (-1)
12、 Python语句list(range(1,10,3))执行结果为
[1, 4, 7]
13、 表达式 list(range(5)) 的值为() ([0, 1, 2, 3, 4])
14、 已知a = [1, 2, 3]和b = [1, 2, 4],那么id(a[1])==id(b[1])的执行结果为() (True)
15、 切片操作list(range(6))[::2]执行结果为
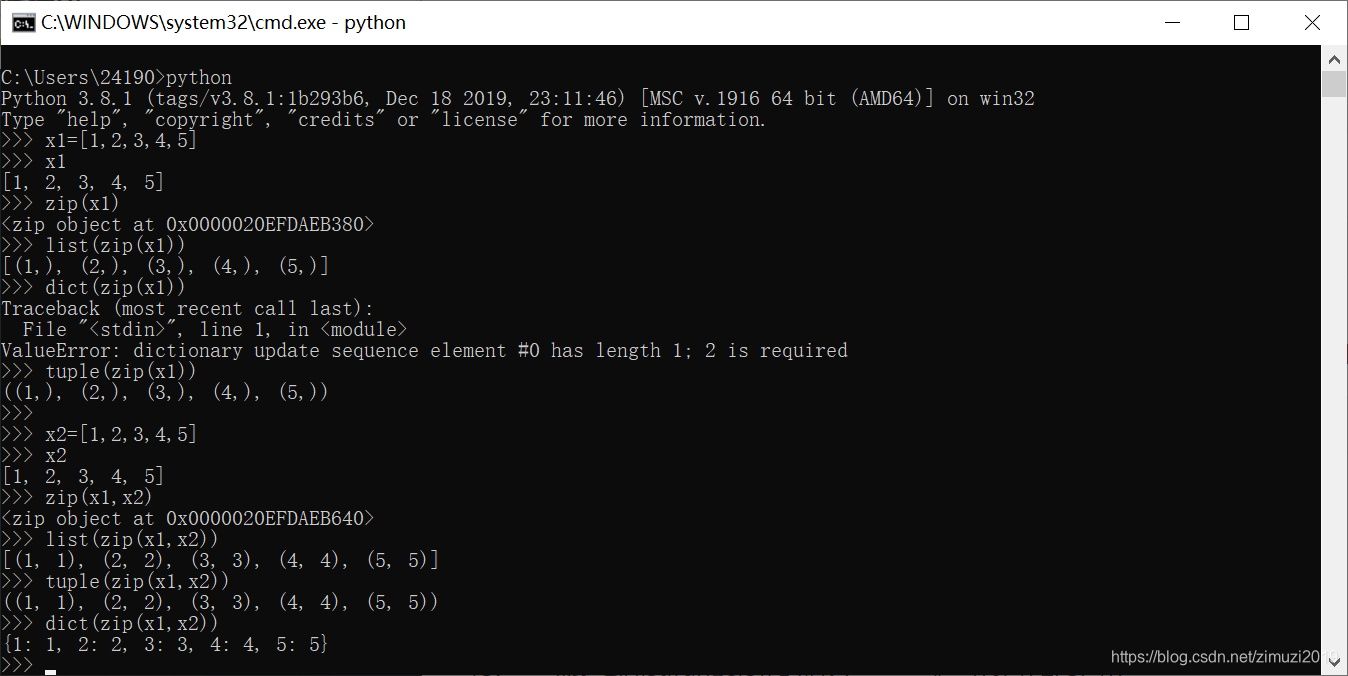
[0, 2, 4]
16、使用切片操作在列表对象x的开始处增加一个元素3的代码为
x[0:0] = [3]
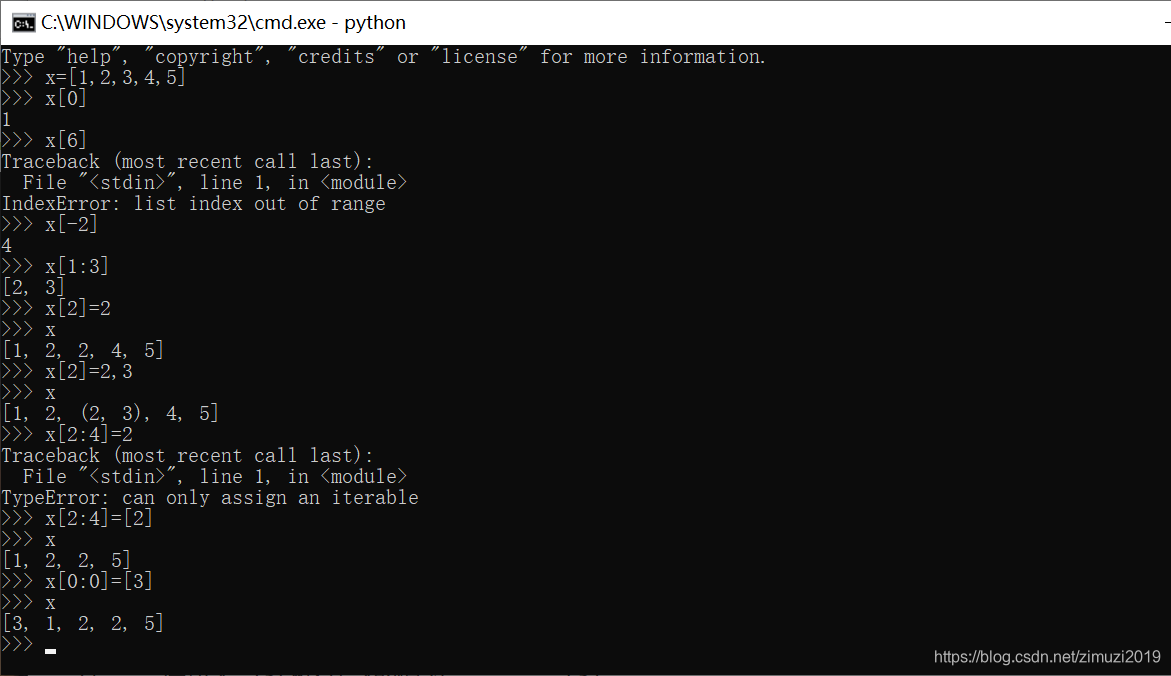
17、 语句sorted([1, 2, 3], reverse=True) == reversed([1, 2, 3])执行结果为
False
- sorted()返回一个新的列表,reversed()返回一个迭代器
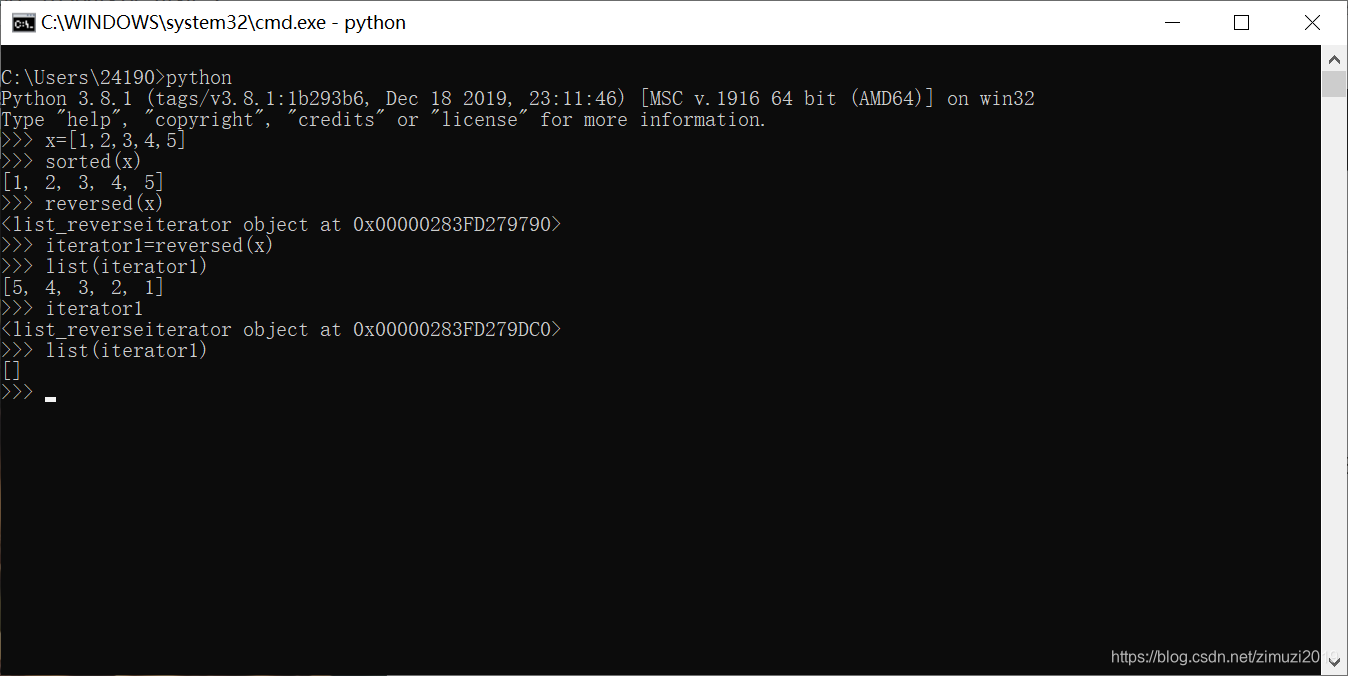
18、 表达式 sorted([111, 2, 33], key=lambda x: len(str(x)))的值为
[2, 33, 111]
19、 表达式 sorted([111, 2, 33], key=lambda x: -len(str(x))) 的值为
[111, 33, 2]
20、 语句 x = (3,) 执行后x的值为() ((3,))
21、 语句 x = (3) 执行后x的值为() (3)
22、 已知x=3和y=5,执行语句 x, y = y, x 后x的值是
5
- 这是交换x,y的值。等号左侧多个变量一起赋值是Python特殊的赋值方式。会自动分析右侧的可迭代对象然后一次性赋值,如x,y,z=[1,2,3]
23、 可以使用内置函数()查看包含当前作用域内所有全局变量和值的字典。
globals()
24、 可以使用内置函数()查看包含当前作用域内所有局部变量和值的字典。
locals()
25、 字典中多个元素之间使用()分隔开,每个元素的“键”与“值”之间使用()分隔开。 (逗号、冒号)
26、 字典对象的()方法可以获取指定“键”对应的“值”,并且可以在指定“键”不存在的时候返回指定值,如果不指定则返回None。
get()
- get()函数的语法为dict.get(key,default=None)
27、 字典对象的()方法返回字典中的“键-值对”列表。
items()
- items方法返回字典中的"键-值对"组成的元组的列表
28、 字典对象的()方法返回字典的“键”列表。
keys()
29、 字典对象的()方法返回字典的“值”列表。
values()
30、 已知 x = {1:2},那么执行语句 x[2] = 3之后,x的值为
{1: 2, 2: 3}
31、 表达式 {1, 2, 3, 4} - {3, 4, 5, 6}的值为
{1, 2}
- set1-set2返回set1有但是set2没有的元素
32、 表达式set([1, 1, 2, 3])的值() ({1, 2, 3})
33、 使用列表推导式得到100以内所有能被13整除的数的代码可以写作
[i for i in range(100) if i%13==0]
34、 已知 x = [3, 5, 7],那么表达式 x[10:]的值为
[]
- 切片操作超出下标并不会报错而是返回空列表
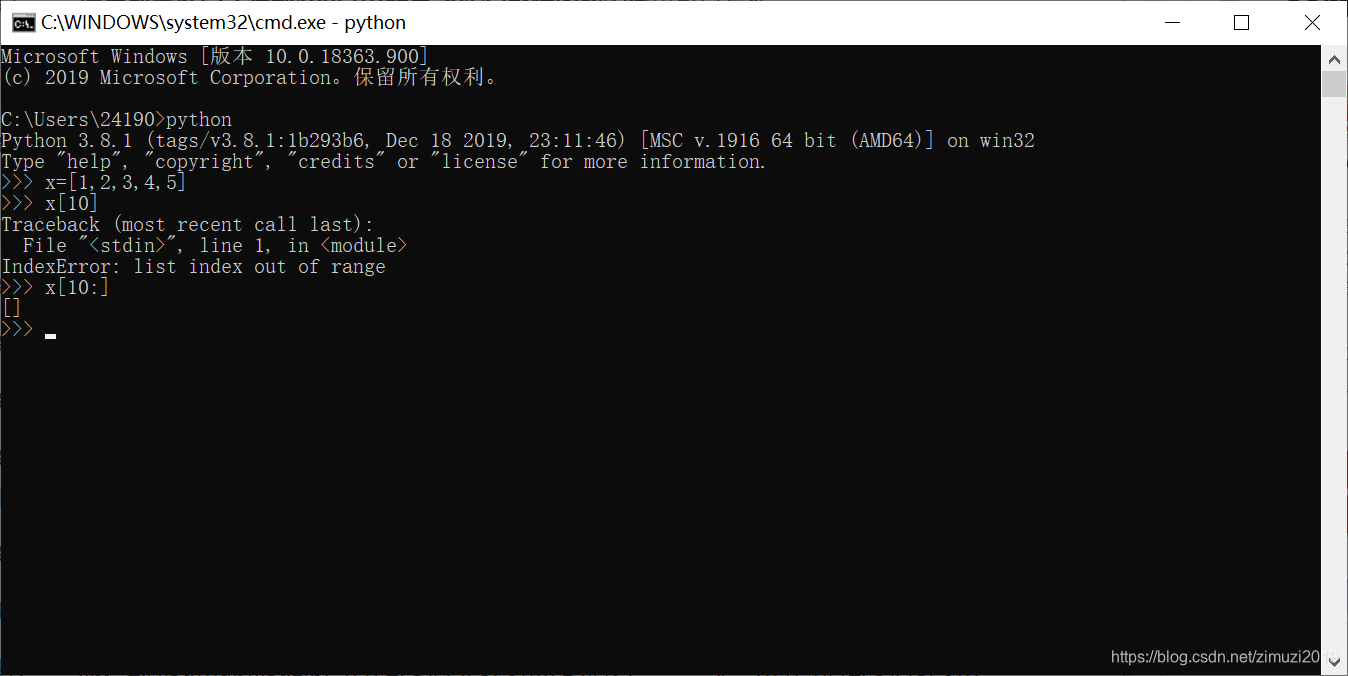
35、 已知 x = [3, 5, 7],那么执行语句 x[len(x):] = [1, 2]之后,x的值为
[3, 5, 7, 1, 2]
36、 已知 x = [3, 7, 5],那么执行语句 x.sort(reverse=True)之后,x的值为
[7, 5, 3]
-
sorted()和list.sort()不同,区别在于
1.前者不是原地排序,原列表不变。后者是原地排序,原列表改变
2.前者返回值是一个排序后的新列表。后者没有返回值
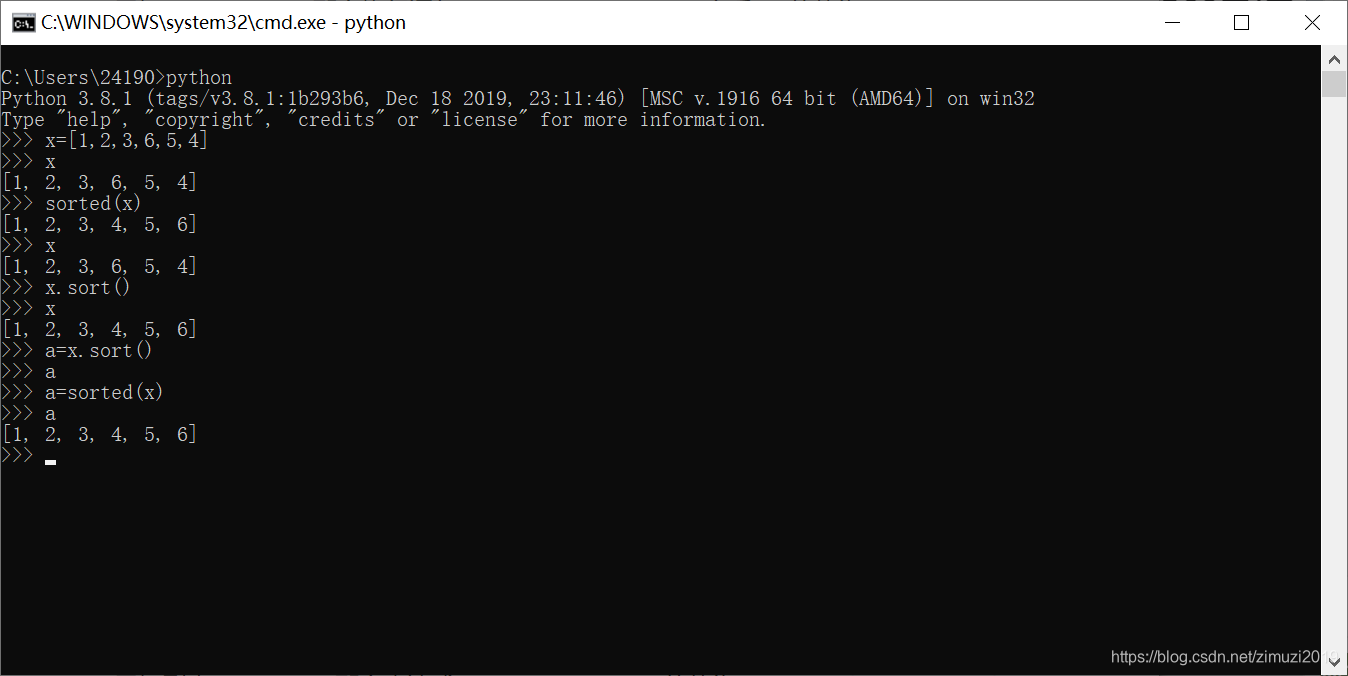
37、 已知 x = [3, 7, 5],那么执行语句 x = x.sort(reverse=True)之后,x的值为
None
38、 已知 x = [1, 11, 111],那么执行语句 x.sort(key=lambda x: len(str(x)), reverse=True) 之后,x的值为
[111, 11, 1]
39、 表达式 list(zip([1,2], [3,4]))的值为
[(1, 3), (2, 4)]
40、 已知 x = [1, 2, 3, 2, 3],执行语句 x.pop() 之后,x的值为
[1, 2, 3, 2]
- 列表的pop方法的参数要移除的元素的索引值,如果不填默认为最后一个元素。返回值为移除元素
41、 表达式 list(map(list,zip(*[[1, 2, 3], [4, 5, 6]])))的值为
[[1, 4], [2, 5], [3, 6]]
- '*'操作符可以理解为解包的意思
42、 表达式 [x for x in [1,2,3,4,5] if x<3] 的值为
[1, 2]
43、 表达式 [index for index, value in enumerate([3,5,7,3,7]) if value == max([3,5,7,3,7])]的值为
[2, 4]
- enumerate()函数的用法见https://www.runoob.com/python/python-func-enumerate.html

44、 已知 x = [3,5,3,7],那么表达式 [x.index(i) for i in x if i==3] 的值为
[0,0]
- 列表的index方法只会返回第一个匹配项的索引位置
45、 已知列表 x = [1, 2],那么表达式 list(enumerate(x)) 的值为
[(0, 1), (1, 2)]
46、 已知 vec = [[1,2], [3,4]],则表达式 [col for row in vec for col in row] 的值为
[1, 2, 3, 4]
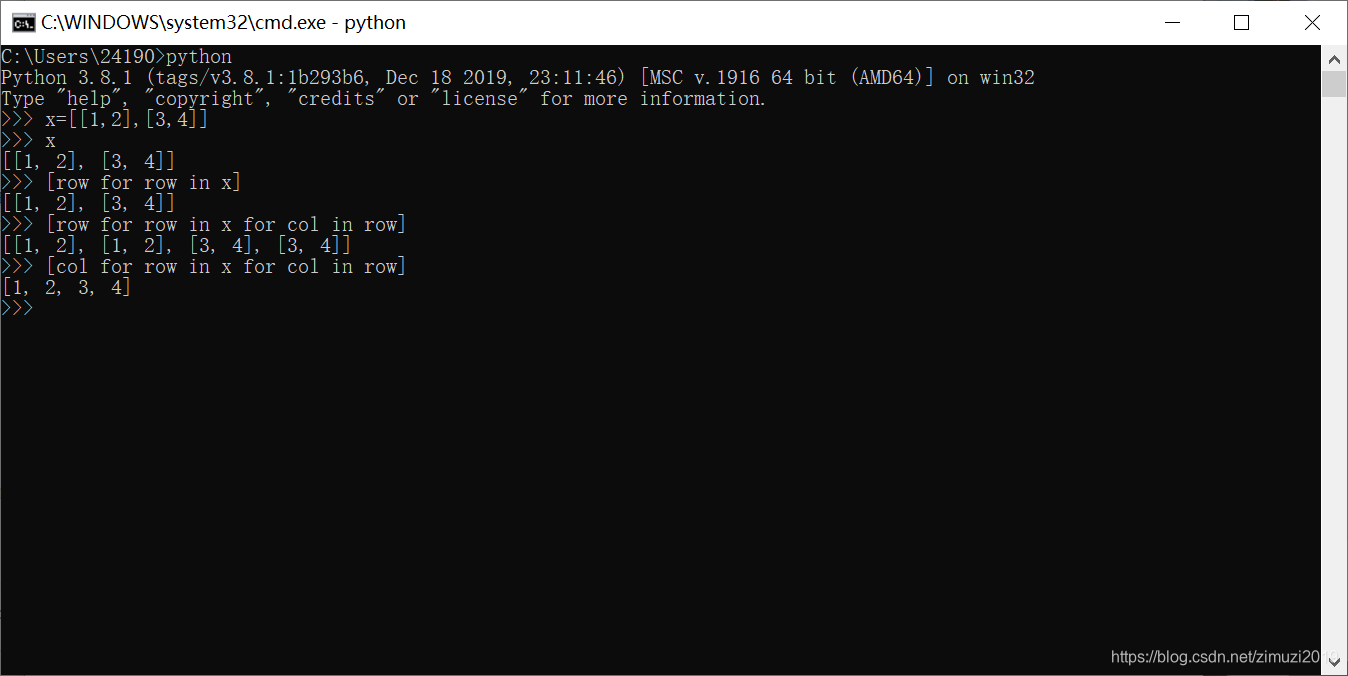
47、 已知 vec = [[1,2], [3,4]],则表达式 [[row[i] for row in vec] for i in range(len(vec[0]))] 的值为
[[1, 3], [2, 4]]
48、 已知 x = list(range(10)),则表达式 x[-4:] 的值为() ([6, 7, 8, 9])
49、 已知 x = [3, 5, 7],那么执行语句 x[1:] = [2]之后,x的值为() ([3, 2])
50、 已知 x = [3, 5, 7],那么执行语句 x[:3] = [2]之后,x的值为
[2]
51、 已知x为非空列表,那么执行语句y = x[:]之后,id(x[0]) == id(y[0])的值为() (True)
52、 已知 x = [1, 2, 3, 2, 3],执行语句 x.remove(2) 之后,x的值为
[1, 3, 2, 3]
- remove()方法只会移除第一个匹配项
53、 表达式 len([i for i in range(10)]) 的值为() (10)
54、 表达式 len(range(1,10)) 的值为
9
55、 表达式 range(10)[-1] 的值为() (9)
56、 表达式 range(10,20)[4] 的值为()
14
57、 表达式 round(3.4) 的值为
3
- round()返回浮点数的四舍五入值
58、 表达式 round(3.7) 的值为
4
59、 已知 x = (3), 那么表达式 x * 3 的值为() (9)
60、 已知 x = (3,),那么表达式 x * 3 的值为()
(3, 3, 3)
61、 假设列表对象x = [1, 1, 1],那么表达式id(x[0]) == id(x[2])的值为() (True)
62、 已知列表 x = list(range(10)),那么执行语句 del x[::2]之后,x的值为
[1, 3, 5, 7, 9]
63、 已知列表 x = [1, 2, 3, 4],那么执行语句 del x[1] 之后x的值为() ([1, 3, 4])
64、 表达式 [1] * 2 的值为() ([1, 1])
65、 表达式 [1, 2] * 2 的值为() ([1, 2, 1, 2])
66、 已知列表 x = [1, 2, 3],那么执行语句 x.insert(1, 4) 后x的值为
[1, 4, 2, 3]
67、 已知列表 x = [1, 2, 3],那么执行语句 x.insert(0, 4) 后x的值为
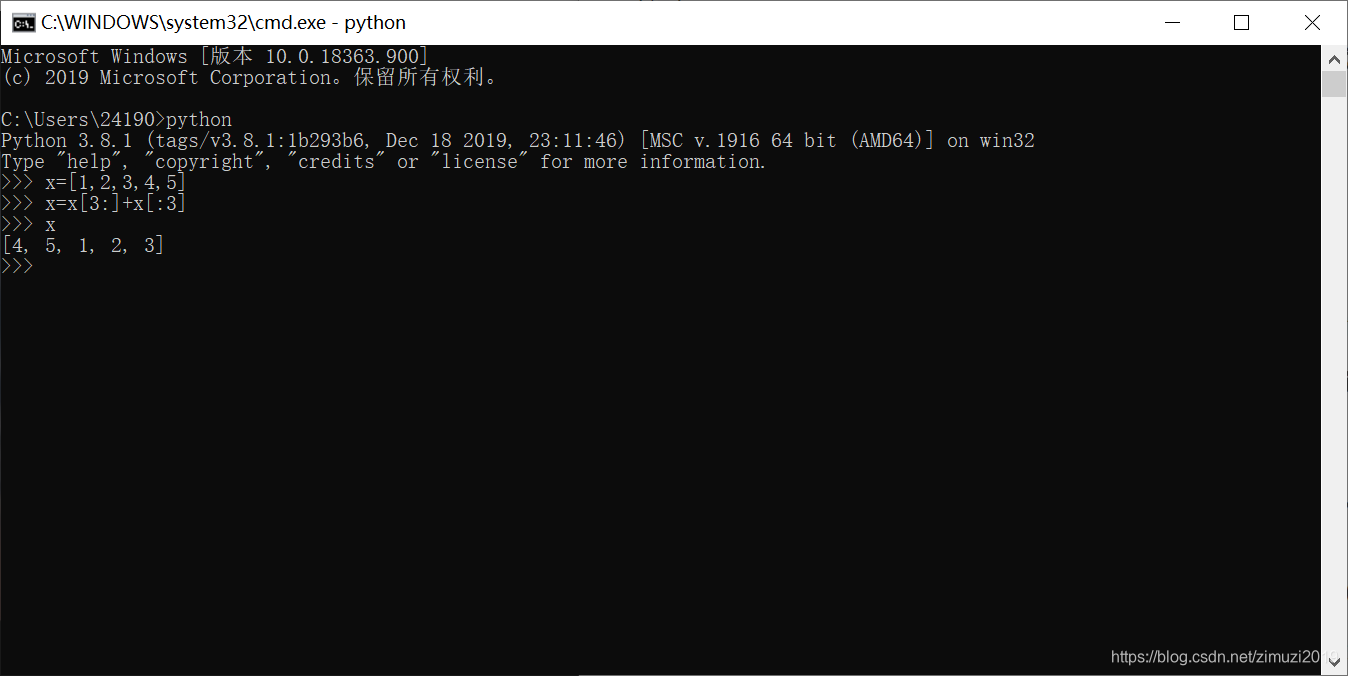
[4, 1, 2, 3]
68、 已知列表 x = [1, 2, 3],那么执行语句 x.pop(0) 之后,x的值为
[2, 3]
69、 已知 x = [[1]] * 3,那么执行语句 x[0] [0]= 5之后,变量x的值为
[[5], [5], [5]]
70、 表达式 list(map(lambda x: x+5, [1, 2, 3, 4, 5])) 的值为
[6, 7, 8, 9, 10]
71、 表达式 {1, 2, 3, 4, 5} ^ {4, 5, 6, 7} 的值为
{1, 2, 3, 6, 7}
- set1^set2返回二者的对称差集,该集中元素是set1或者set2的元素但不是set1和set2都有的元素
72、 已知 x = [1, 2, 3],那么执行语句 x[len(x)-1:] = [4, 5, 6]之后,变量x的值为() ([1, 2, 4, 5, 6])
73、 表达式 len(range(1, 10)) 的值为() (9)
74、 已知x是一个列表对象,那么执行语句 y = x[:] 之后表达式 id(x) == id(y) 的值为() (False)
75、 表达式 sorted([13, 1, 237, 89, 100], key=lambda x: len(str(x))) 的值为
[1, 13, 89, 237, 100]
76、 已知 x = {1:2, 2:3},那么表达式 x.get(3, 4) 的值为
4
77、 已知 x = {1:2, 2:3},那么表达式 x.get(2, 4) 的值为() (3)
78、 表达式 {1, 2, 3} | {3, 4, 5} 的值为
{1, 2, 3, 4, 5}
- set1|set2为求二者的并集,把两个集合合并
79、 表达式 {1, 2, 3} | {2, 3, 4} 的值为
{1, 2, 3, 4}
80、 表达式 {1, 2, 3} & {3, 4, 5} 的值为() ({3})
81、 表达式 {1, 2, 3} & {2, 3, 4} 的值为
{2, 3}
- set1&set2为求二者的交集,即两个集合共有的元素
82、 表达式 {1, 2, 3} - {3, 4, 5} 的值为() ({1, 2})
83、 表达式 {1, 2, 3} < {3, 4, 5} 的值为
False
- set1<set2判断set1是否为set2的子集
84、 表达式 {1, 2, 3} < {1, 2, 4} 的值为() (False)
85、 表达式 [1,2,3].count(4) 的值为
0
86、 Python标准库random中的()方法作用是从序列中随机选择1个元素。
choice()
87、 Python标准库random中的sample(seq, k)方法作用是从序列seq中选择()(重复/不重复)的k个元素。 (不重复)
88、 random模块中()方法的作用是将列表中的元素随机乱序。
shuffle()
89、 执行代码 x, y, z = sorted([1, 3, 2]) 之后,变量y的值为
2
90、 表达式 (1, 2, 3)+(4, 5) 的值为
(1, 2, 3, 4, 5)
91、 表达式 dict(zip([1, 2], [3, 4])) 的值为
{1: 3, 2: 4}
92、 语句 x, y, z = [1, 2, 3] 执行后,变量y的值为() (2)
93、 已知 x = [[1,3,3], [2,3,1]],那么表达式 sorted(x, key=lambda item:item[0]+item[2]) 的值为
[[2, 3, 1], [1, 3, 3]]
94、 已知 x = [[1,3,3], [2,3,1]],那么表达式 sorted(x, key=lambda item:(item[1],item[2])) 的值为
[[2, 3, 1], [1, 3, 3]]
95、 已知 x = [[1,3,3], [2,3,1]],那么表达式 sorted(x, key=lambda item:(item[1], -item[2])) 的值为() ([[1, 3, 3], [2, 3, 1]])
96、 已知 x = {1, 2, 3},那么执行语句 x.add(3) 之后,x的值为
{1, 2, 3}
97、 已知 x = {1:1},那么执行语句 x[2] = 2之后,len(x)的值为
2
98、 已知 x = {1:1, 2:2},那么执行语句 x[2] = 4之后,len(x)的值为
2
99、 假设已从标准库functools导入reduce()函数,那么表达式 reduce(lambda x, y: x-y, [1, 2, 3]) 的值为
-4
100、 假设已从标准库functools导入reduce()函数,那么表达式 reduce(lambda x, y: x+y, [1, 2, 3]) 的值为() (6)
101、 假设已从标准库functools导入reduce()函数,那么表达式reduce(lambda x,y:max(x,y), [1,2,3,4,4,5])的值为
5
102、 已知有函数定义 def demo(*p):return sum§,那么表达式 demo(1, 2, 3) 的值为()、表达式 demo(1, 2, 3, 4) 的值为()
6、10
103、 已知列表 x = [1, 2],那么连续执行命令 y = x和 y.append(3) 之后,x的值为() ([1, 2, 3])
104、 已知列表 x = [1, 2],那么连续执行命令 y = x[:] 和 y.append(3) 之后,x的值为() ([1, 2])
105、 已知列表 x = [1, 2],执行语句 y = x[:] 后,表达式 id(x) == id(y) 的值为() (False)
106、 已知列表 x = [1, 2],执行语句 y = x 后,表达式 id(x) == id(y) 的值为() (True)
107、 已知列表 x = [1, 2],执行语句 y = x 后,表达式 x is y 的值为() (True)
108、 已知列表 x = [1, 2],执行语句 y = x[:] 后,表达式 x is not y 的值为() (True)
109、 表达式 sorted(random.sample(range(5), 5)) 的值为
[0, 1, 2, 3, 4]
110、 表达式 [i for i in range(10) if i>8] 的值为() ([9])
111、 已知有列表 x = [[1, 2, 3], [4, 5, 6]],那么表达式 [[row[i] for row in x] for i in range(len(x[0]))] 的值为
[[1, 4], [2, 5], [3, 6]]
112、 执行语句 x,y,z = map(str, range(3)) 之后,变量y的值为
'1'
113、 已知列表 x = [1, 2],那么执行语句 x.extend([3]) 之后, x的值为
[1, 2, 3]
- extend()的参数为一个可迭代对象
114、 已知列表 x = [1, 2],那么执行语句 x.append([3]) 之后,x的值为
[1, 2, [3]]
115、 表达式 print(0b10101) 的值为
21
116、 已知 x = [1, 2, 3, 4, 5],那么执行语句 del x[:3] 之后,x的值为() ([4, 5])
117、 已知 x = range(1,4) 和 y = range(4,7),那么表达式 sum([i*j for i,j in zip(x,y)]) 的值为
32
118、 表达式 [5 for i in range(3)] 的值为() ([5, 5, 5])
119、 表达式 {1, 2, 3} == {1, 3, 2} 的值为() (True)
120、 表达式 [1, 2, 3] == [1, 3, 2] 的值为() (False)
121、 已知 x = [1, 2, 1],那么表达式 id(x[0]) == id(x[2]) 的值为() (True)
122、 表达式 3 not in [1, 2, 3]的值为() (False)
123、 已知 x = [1, 2],那么执行语句 x[0:0] = [3, 3]之后,x的值为
[3, 3, 1, 2]
124、 已知 x = [1, 2],那么执行语句 x[0:1] = [3, 3]之后,x的值为() ([3, 3, 2])
125、 已知 x = [1, 2, 3, 4, 5],那么执行语句 del x[1:3] 之后,x的值为
[1, 4, 5]
126、 已知 x = [[1, 2, 3,], [4, 5, 6]],那么表达式 sum([i * j for i,j in zip(*x)]) 的值为
32
127、 已知列表 x = [1, 2, 3] 和 y = [4, 5, 6],那么表达式 [(i,j) for i, j in zip(x,y) if i==3] 的值为[(3, 6)]
[(3, 6)]
128、 已知列表 x = [1.0, 2.0, 3.0],那么表达式 sum(x)/len(x) 的值为
2.0
129、 已知 x = {1:2, 2:3, 3:4},那么表达式 sum(x) 的值为
6
- sum对字典使用是字典key值相加
130、 已知 x = {1:2, 2:3, 3:4},那么表达式 sum(x.values()) 的值为
9
131、 已知 x = [3, 2, 3, 3, 4],那么表达式 [index for index, value in enumerate(x) if value==3] 的值为
[0, 2, 3]
132、 表达式 1234%1000//100 的值为() (2)
133、 表达式 3 // 5 的值为() (0)
134、 表达式 [1, 2] + [3] 的值为
[1, 2, 3]
135、 表达式 (1,) + (2,) 的值为
(1, 2)
136、 表达式 (1) + (2) 的值为() (3)
137、 已知 x, y = map(int, [‘1’, ‘2’]),那么表达式 x + y 的值为()
3
138、 已知列表 x = list(range(5)),那么执行语句 x.remove(3) 之后,表达式 x.index(4) 的值为
3
139、 已知列表 x = [1, 3, 2],那么执行语句 x.reverse() 之后,x的值为
[2, 3, 1]
140、 已知列表 x = [1, 3, 2],那么执行语句 x = x.reverse() 之后,x的值为
None
141、 已知x为非空列表,那么表达式 x.reverse() == list(reversed(x)) 的值为
False
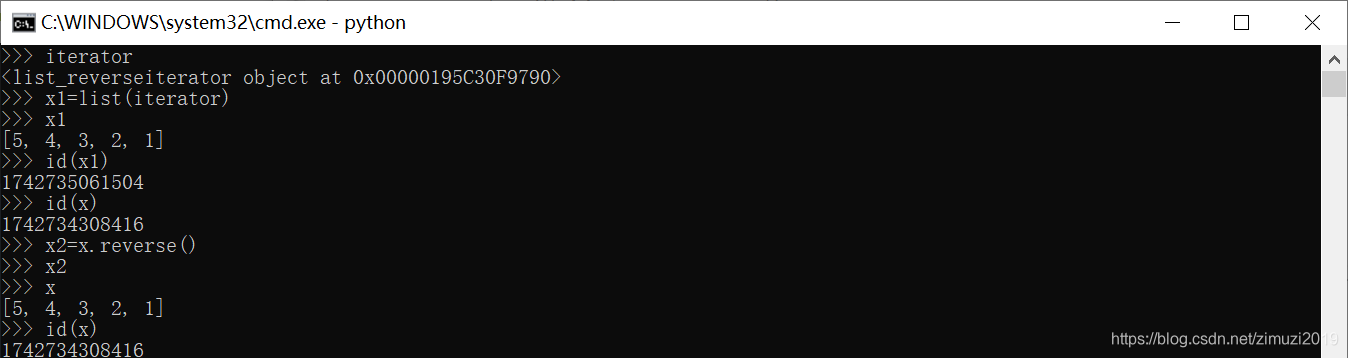
142、 已知x为非空列表,那么表达式 x.sort() == sorted(x) 的值为
False
143、 已知列表 x = [1, 3, 2],那么执行语句 y = list(reversed(x)) 之后,x的值为
[1, 3, 2]
144、 已知列表 x = [1, 3, 2],那么执行语句 y = list(reversed(x)) 之后,y的值为() ([2, 3, 1])
145、 已知列表x中包含超过5个以上的元素,那么表达式 x == x[:5]+x[5:] 的值为
True
146、 已知字典 x = {i:str(i+3) for i in range(3)},那么表达式 sum(x) 的值为
3
147、 已知字典 x = {i:str(i+3) for i in range(3)},那么表达式 sum(item[0] for item in x.items()) 的值为
3
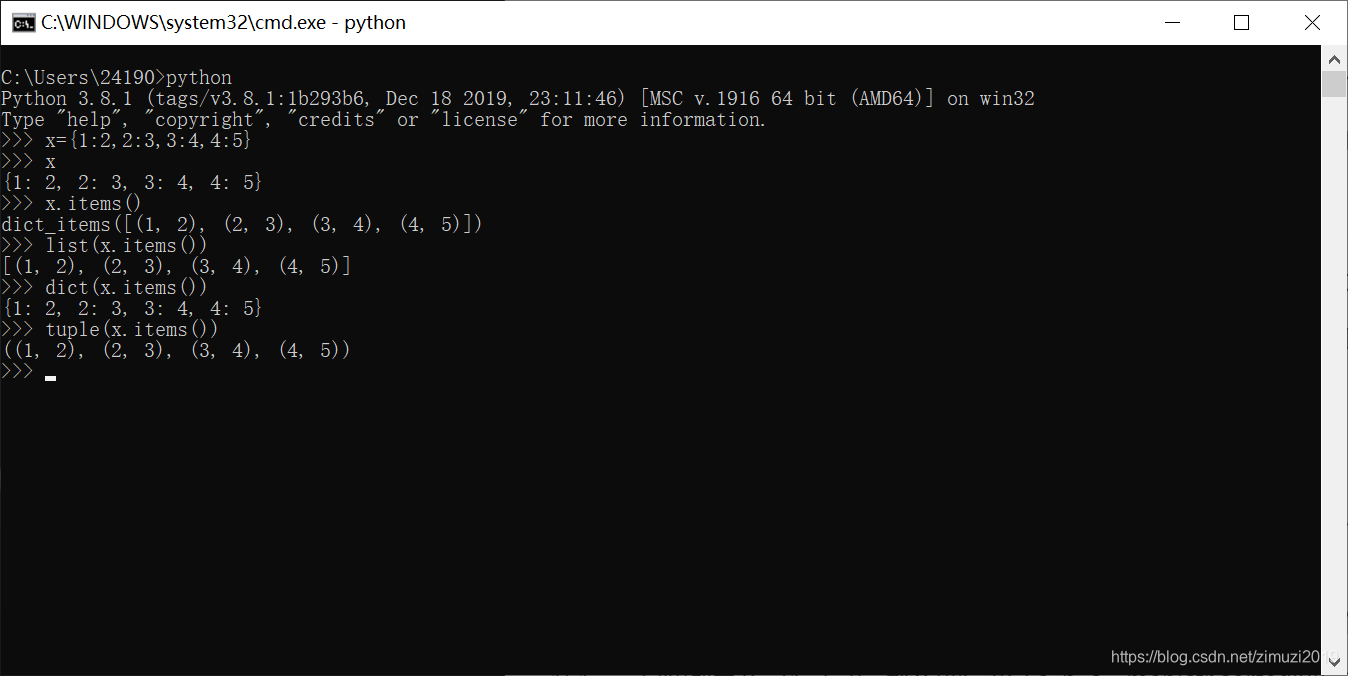
148、 已知字典 x = {i:str(i+3) for i in range(3)},那么表达式 ‘’.join([item[1] for item in x.items()]) 的值为
'345'
149、 已知列表 x = [1, 3, 2],那么表达式 [value for index, value in enumerate(x) if index==2] 的值为
[2]
150、 已知列表 x = [1, 3, 2],那么执行语句 a, b, c = sorted(x) 之后,b的值为() (2)
151、 已知列表 x = [1, 3, 2],那么执行语句 a, b, c = map(str,sorted(x)) 之后,c的值为() (‘3’)
152、 表达式 set([1,2,3]) == {1, 2, 3} 的值为() (True)
153、 表达式 set([1,2, 2,3]) == {1, 2, 3} 的值为() (True)
154、 表达式 ‘%c’%65 == str(65) 的值为
False
155、 表达式 ‘%s’%65 == str(65) 的值为
True
156、 表达式 chr(ord(‘b’)^32) 的值为
'B'
- ^为按位异或运算符,只要对应的二进制有一个为1时,结果位就为1
157、 表达式 ‘abc’ in ‘abdcefg’ 的值为() (False)
158、 已知x为整数变量,那么表达式 int(hex(x), 16) == x 的值为
True
- hex()函数参数为一个十进制数,返回十六进制数,以字符串形式表示。
- int()函数的用法见https://www.runoob.com/python/python-func-int.html
159、 已知 x, y = 3, 5,那么执行x, y = y, x 之后,x的值为() (5)
160、 已知 x = ‘abcd’ 和 y = ‘abcde’,那么表达式 [i==j for i,j in zip(x,y)] 的值为
[True, True, True, True]
161、 已知x = list(range(20)),那么表达式x[-1]的值为() (19)
162、 已知x = 3+4j和y = 5+6j,那么表达式x+y的值为() (8+10j)
163、 已知x = [3],那么执行x += [5]之后x的值为
[3, 5]
164、 已知x = [3, 3, 4],那么表达式id(x[0])==id(x[1])的值为() (True)
165、 表达式int(‘11’, 2)的值为
3
166、 表达式int(‘11’, 8)的值为() 9
167、 表达式int(bin(54321), 2)的值为
54321
- bin传入一个整数int或者长整数long int,以二进制表示后用字符串返回
168、 表达式chr(ord(‘A’)+1)的值为() (‘B’)
169、 表达式int(str(34)) == 34的值为() (True)
170、 表达式list(str([3, 4])) == [3, 4]的值为
False
171、 表达式{1, 2, 3, 4, 5, 6} ^ {5, 6, 7, 8}的值为()
{1, 2, 3, 4, 7, 8}
172、 表达式15 // 4的值为() (3)
173、 表达式sorted({‘a’:3, ‘b’:9, ‘c’:78})的值为
['a', 'b', 'c']
- sorted对字典进行排序时默认根据字典的键值与ASCII码顺序升序排列
174、 表达式sorted({‘a’:3, ‘b’:9, ‘c’:78}.values())的值为
[3, 9, 78]
175、 已知x = [3, 2, 4, 1],那么执行语句x = x.sort()之后,x的值为() (None)
176、 表达式list(filter(lambda x: x>5, range(10)))的值为
[6, 7, 8, 9]
177、 已知x = list(range(20)),那么语句print(x[100:200])的输出结果为
[]
178、 已知x = list(range(20)),那么执行语句x[:18] = []后列表x的值为() ([18, 19])
179、 已知x = [1, 2, 3],那么连续执行y = x[:]和y.append(4)这两条语句之后,x的值为() ([1, 2, 3])
180、 已知x = [1, 2, 3],那么连续执行y = x和y.append(4)这两条语句之后,x的值为() ([1, 2, 3, 4])
181、 已知x = [1, 2, 3],那么连续执行y = [1, 2, 3]和y.append(4)这两条语句之后,x的值为() ([1, 2, 3])
182、 已知x = [[]] * 3,那么执行语句x[0].append(1)之后,x的值为()
[[1], [1], [1]]
183、 已知x = [[] for i in range(3)],那么执行语句x[0].append(1)之后,x的值为
[[1], [], []]
184、 已知x = ([1], [2]),那么执行语句x[0].append(3)后x的值为() (([1, 3], [2]))
185、 已知x = {1:1, 2:2},那么执行语句x.update({2:3, 3:3})之后,表达式sorted(x.items())的值为
[(1, 1), (2, 3), (3, 3)]
186、 已知x = {1:1, 2:2},那么执行语句x[3] = 3之后,表达式sorted(x.items())的值为
[(1, 1), (2, 2), (3, 3)]
187、 已知x = [1, 2, 3],那么表达式not (set(x*100)-set(x))的值为
True
188、 已知x = [1, 2, 3],那么表达式not (set(x*100)&set(x))的值为
False
189、 表达式{‘x’: 1,** {‘y’: 2}}的值为
{'x': 1, 'y': 2}
190、 表达式{*range(4), 4, *(5, 6, 7)}的值为
{0, 1, 2, 3, 4, 5, 6, 7}
191、 已知 x = [1,2,3,4,5],那么执行语句 x[::2] = range(3) 之后,x的值为
[0, 2, 1, 4, 2]
192、 已知 x = [1,2,3,4,5],那么执行语句 x[::2] = map(lambda y:y!=5,range(3)) 之后,x的值为
[True, 2, True, 4, True]
193、 已知 x = [1,2,3,4,5],那么执行语句 x[1::2] = sorted(x[1::2], reverse=True) 之后,x的值为
[1, 4, 3, 2, 5]
194、 表达式 True*3 的值为
3
195、 表达式 False+1 的值为
1
判断
1、 Python支持使用字典的“键”作为下标来访问字典中的值。(对)
2、 列表可以作为字典的“键”。(错)
3、 元组可以作为字典的“键”。(对)
4、 字典的“键”必须是不可变的。(对)
- 不可变序列包括字符串,元组,数字。可变序列包括列表,字典,集合
5、 已知x为非空列表,那么表达式 sorted(x, reverse=True) == list(reversed(x)) 的值一定是True。(错)
6、 已知x为非空列表,那么x.sort(reverse=True)和x.reverse()的作用是等价的。(错)
7、 生成器推导式比列表推导式具有更高的效率,推荐使用。(对)
8、 Python集合中的元素不允许重复。(对)
9、 Python集合可以包含相同的元素。(错)
10、 Python字典中的“键”不允许重复。(对)
11、 Python字典中的“值”不允许重复。(错)
12、 Python集合中的元素可以是元组。(对)
13、 Python集合中的元素可以是列表。(错)
14、 Python字典中的“键”可以是列表。(错)
15、 Python字典中的“键”可以是元组。(对)
16、 Python列表中所有元素必须为相同类型的数据。(错)
17、 Python列表、元组、字符串都属于有序序列。(对)
18、 已知A和B是两个集合,并且表达式A<B的值为False,那么表达式A>B的值一定为True。(错)
19、 列表对象的append()方法属于原地操作,用于在列表尾部追加一个元素。(对)
20、 对于列表而言,在尾部追加元素比在中间位置插入元素速度更快一些,尤其是对于包含大量元素的列表。(对)
21、 假设有非空列表x,那么x.append(3)、x = x+[3]与x.insert(0,3)在执行时间上基本没有太大区别。(错)
22、 使用Python列表的方法insert()为列表插入元素时会改变列表中插入位置之后元素的索引。(对)
23、 假设x为列表对象,那么x.pop()和x.pop(-1)的作用是一样的。(对)
24、 使用del命令或者列表对象的remove()方法删除列表中元素时会影响列表中部分元素的索引。(对)
25、 已知列表 x = [1, 2, 3],那么执行语句 x = 3 之后,变量x的地址不变。(错)
26、 使用列表对象的remove()方法可以删除列表中首次出现的指定元素,如果列表中不存在要删除的指定元素则抛出异常。(对)
27、 元组是不可变的,不支持列表对象的inset()、remove()等方法,也不支持del命令删除其中的元素,但可以使用del命令删除整个元组对象。(对)
28、 Python字典和集合属于无序序列。(对)
29、 无法删除集合中指定位置的元素,只能删除特定值的元素。(对)
30、 元组的访问速度比列表要快一些,如果定义了一系列常量值,并且主要用途仅仅是对其进行遍历二不需要进行任何修改,建议使用元组而不使用列表。(对)
31、 当以指定“键”为下标给字典对象赋值时,若该“键”存在则表示修改该“键”对应的“值”,若不存在则表示为字典对象添加一个新的“键-值对”。(对)
32、 假设x是含有5个元素的列表,那么切片操作x[10:]是无法执行的,会抛出异常。(错)
- 返回空列表而不是抛出异常
33、 只能对列表进行切片操作,不能对元组和字符串进行切片操作。(错)
34、 只能通过切片访问列表中的元素,不能使用切片修改列表中的元素。(错)
35、 只能通过切片访问元组中的元素,不能使用切片修改元组中的元素。(对)
36、 字符串属于Python有序序列,和列表、元组一样都支持双向索引。(对)
37、 Python字典和集合支持双向索引。(错)
38、 Python集合不支持使用下标访问其中的元素。(对)
39、 相同内容的字符串使用不同的编码格式进行编码得到的结果并不完全相同。(对)
40、 删除列表中重复元素最简单的方法是将其转换为集合后再重新转换为列表。(对)
41、 已知列表x中包含超过5个以上的元素,那么语句 x = x[:5]+x[5:] 的作用是将列表x中的元素循环左移5位。(错)
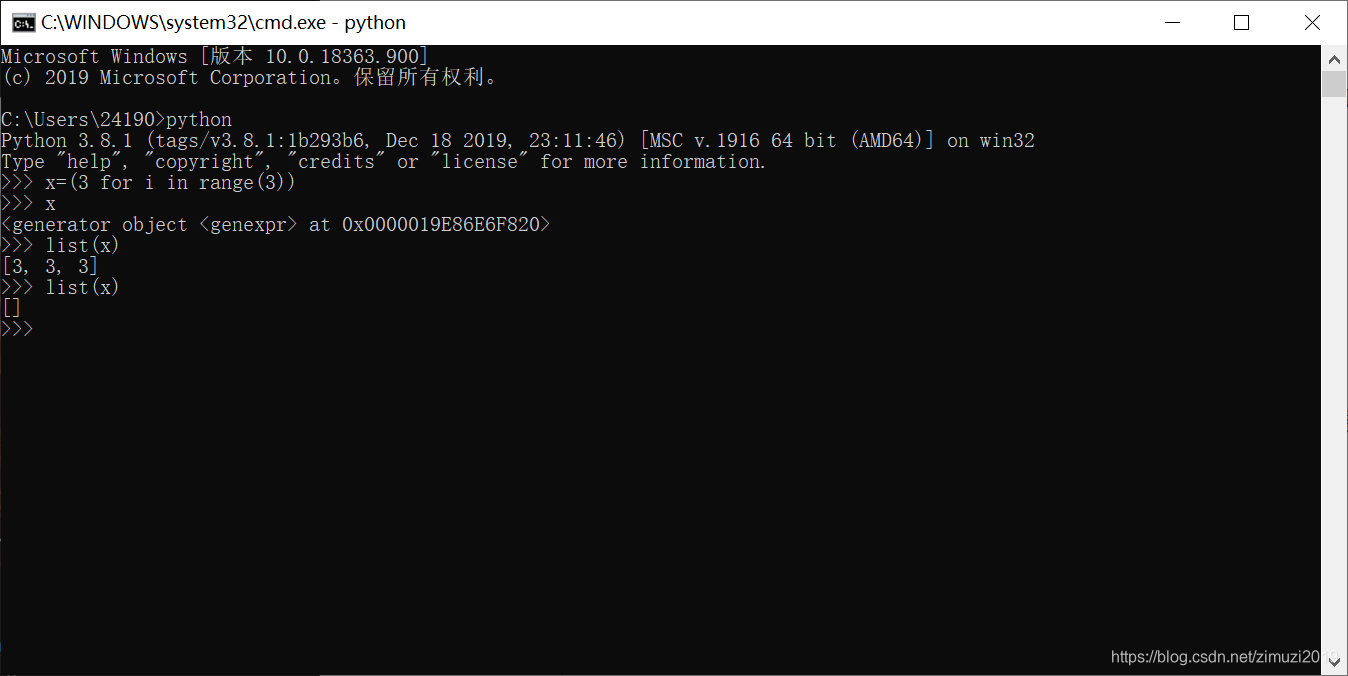
42、 对于生成器对象x = (3 for i in range(5)),连续两次执行list(x)的结果是一样的。(错)
43、 对于大量列表的连接,extend()方法比运算符+具有更高的效率。(对)
44、 表达式 {1, 3, 2} > {1, 2, 3} 的值为True。(错)
45、 列表对象的extend()方法属于原地操作,调用前后列表对象的地址不变。(对)
46、 对于数字n,如果表达式 0 not in [n%d for d in range(2, n)] 的值为True则说明n是素数。(对)
47、 表达式 ‘a’+1的值为’b’。(错)
48、 创建只包含一个元素的元组时,必须在元素后面加一个逗号,例如(3,)。(对)
49、 表达式 list(‘[1, 2, 3]’) 的值是[1, 2, 3]。(错)
50、 同一个列表对象中的元素类型可以各不相同。(对)
51、 同一个列表对象中所有元素必须为相同类型。(错)
52、 已知x为非空列表,那么执行语句x[0] = 3之后,列表对象x的内存地址不变。(对)
53、 列表可以作为集合的元素。(错)
54、 集合可以作为列表的元素。(对)
55、 元组可以作为集合的元素。(对)
56、 集合可以作为元组的元素。(对)
57、 字典可以作为集合的元素。(错)
58、 集合可以作为字典的键。(错)
59、 集合可以作为字典的值。(对)
60、 可以使用del删除集合中的部分元素。(错)
61、 列表对象的pop()方法默认删除并返回最后一个元素,如果列表已空则抛出异常。(对)
62、 表达式 {1, 2} * 2 的值为 {1, 2, 1, 2}。(错)
63、 Python字典支持双向索引。(错)
64、 Python集合支持双向索引。(错)
65、 Python元组支持双向索引。(对)
66、 假设re模块已成功导入,并且有 pattern = re.compile(‘^’+‘.’.join([r’\d{1,3}’ for i in range(4)])+‘$’),那么表达式 pattern.match(‘192.168.1.103’) 的值为None。(错)
67、 假设random模块已导入,那么表达式 random.sample(range(10), 20) 的作用是生成20个不重复的整数。(错)
- 这样会抛出异常
68、 假设random模块已导入,那么表达式 random.sample(range(10), 7) 的作用是生成7个不重复的整数。(对)
69、 使用random模块的函数randint(1, 100)获取随机数时,有可能会得到100。(对)
70、 已知x = (1, 2, 3, 4),那么执行x[0] = 5之后,x的值为(5, 2, 3, 4)。(错)
71、 已知x = 3,那么执行x += 6语句前后x的内存地址是不变的。(错)
72、 成员测试运算符in作用于集合时比作用于列表快得多。(对)
73、 内置函数len()返回指定序列的元素个数,适用于列表、元组、字符串、字典、集合以及range、zip等迭代对象。(对)
74、 已知x和y是两个等长的整数列表,那么表达式sum((i*j for i, j in zip(x, y)))的作用是计算这两个列表所表示的向量的内积。(对)
75、 已知x和y是两个等长的整数列表,那么表达式[i+j for i,j in zip(x,y)]的作用时计算这两个列表所表示的向量的和。(对)
76、 表达式int(‘1’*64, 2)与sum(2 * * i for i in range(64))的计算结果是一样的,但是前者更快一些。(对)
77、 已知x = list(range(20)),那么语句del x[::2]可以正常执行。(对)
78、 已知x = list(range(20)),那么语句x[::2] = []可以正常执行。(错)
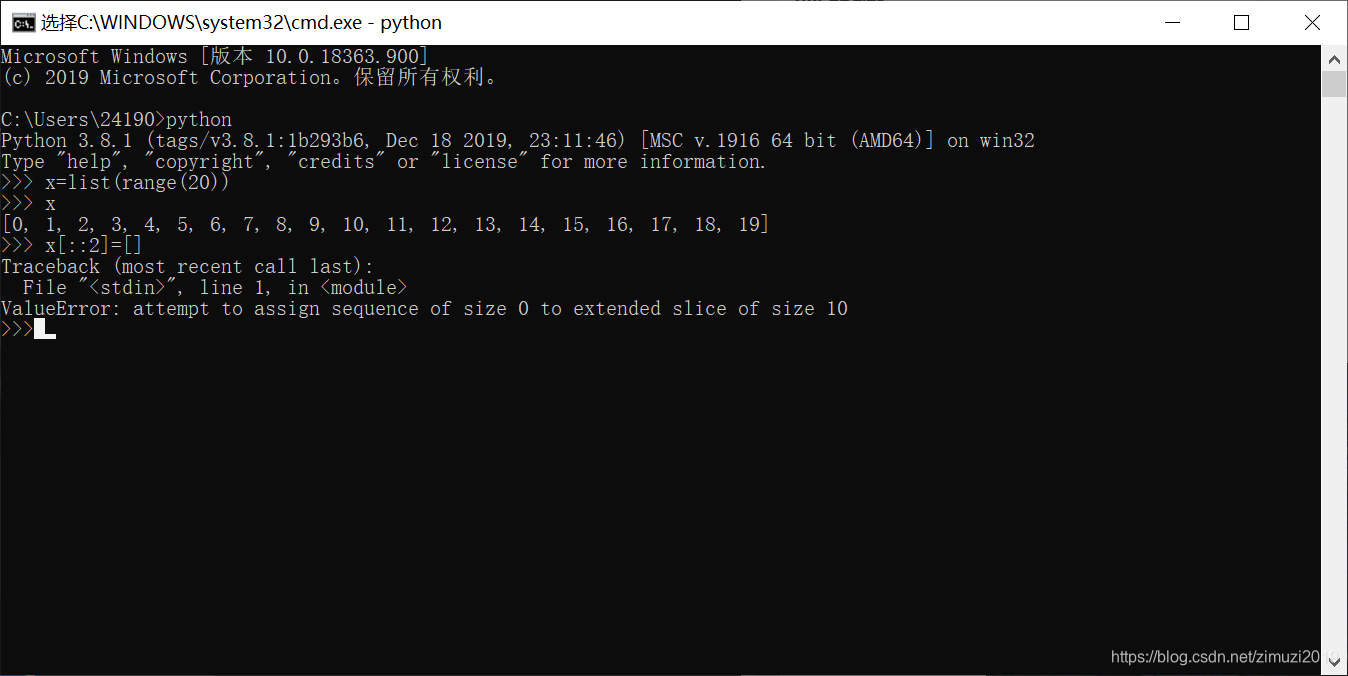
79、 已知x = list(range(20)),那么语句print(x[100:200])无法正常执行。(错)
80、 已知x是个列表对象,那么执行语句y = x之后,对y所做的任何操作都会同样作用到x上。(对)
81、 已知x是个列表对象,那么执行语句y = x[:]之后,对y所做的任何操作都会同样作用到x上。(错)
82、 在Python中,变量不直接存储值,而是存储值的引用,也就是值在内存中的地址。(对)
83、 表达式(i * *2 for i in range(100))的结果是个元组。(错)
- 是一个生成器对象
84、 在Python中元组的值是不可变的,因此,已知x = ([1], [2]),那么语句x[0].append(3)是无法正常执行的。(错)
85、 Python内置的字典dict中元素是按添加的顺序依次进行存储的。(错)
86、 Python内置的集合set中元素顺序是按元素的哈希值进行存储的,并不是按先后顺序。(对)
87、 已知x = {1:1, 2:2},那么语句x[3] =3无法正常执行。(错)
88、 Python内置字典是无序的,如果需要一个可以记住元素插入顺序的字典,可以使用collections.OrderedDict。(对)
89、 已知列表x = [1, 2, 3, 4],那么表达式x.find(5)的值应为-1。(错)
- 列表没有find方法,这是字符串用来寻找子串的方法。list只有index方法。
90、 列表对象的排序方法sort()只能按元素从小到大排列,不支持别的排序方式。(错)
91、 已知x是一个列表,那么x = x[3:] + x[:3]可以实现把列表x中的所有元素循环左移3位。(对)
75、 已知x和y是两个等长的整数列表,那么表达式[i+j for i,j in zip(x,y)]的作用时计算这两个列表所表示的向量的和。(对)
76、 表达式int('1’64, 2)与sum(2 *i for i in range(64))的计算结果是一样的,但是前者更快一些。(对)
77、 已知x = list(range(20)),那么语句del x[::2]可以正常执行。(对)
78、 已知x = list(range(20)),那么语句x[::2] = []可以正常执行。(错)
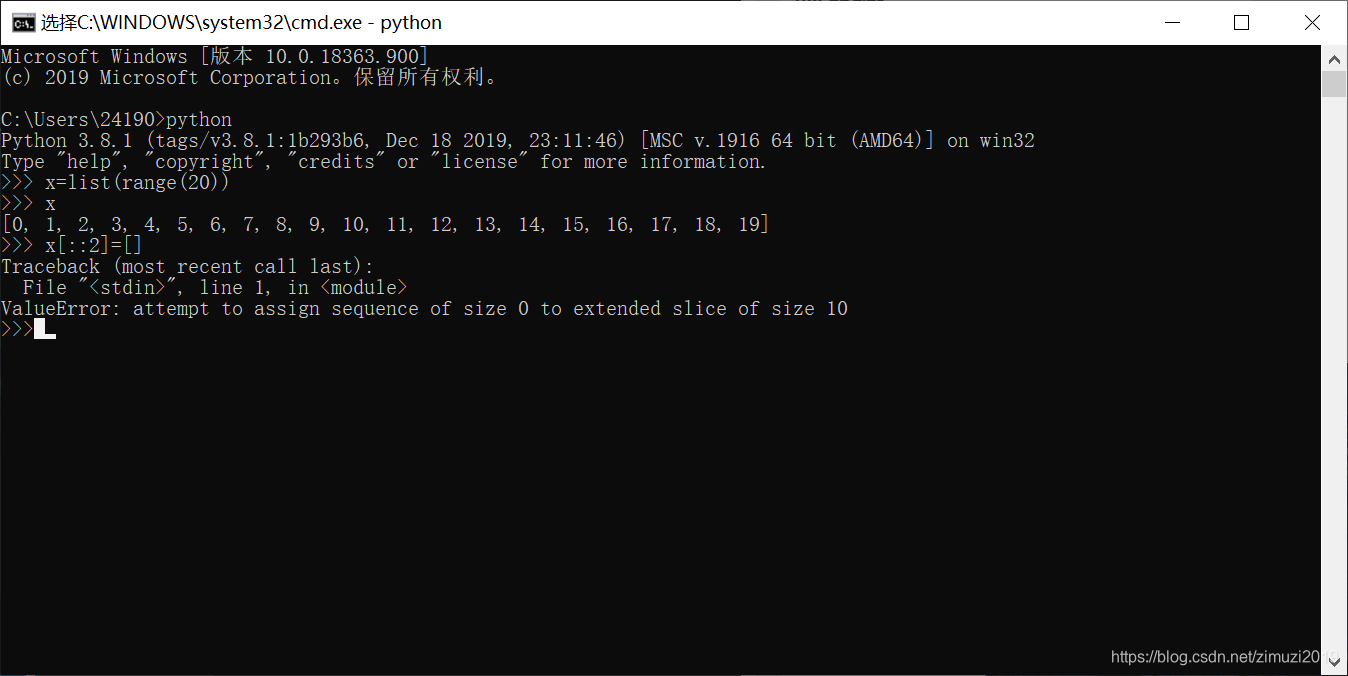
79、 已知x = list(range(20)),那么语句print(x[100:200])无法正常执行。(错)
80、 已知x是个列表对象,那么执行语句y = x之后,对y所做的任何操作都会同样作用到x上。(对)
81、 已知x是个列表对象,那么执行语句y = x[:]之后,对y所做的任何操作都会同样作用到x上。(错)
82、 在Python中,变量不直接存储值,而是存储值的引用,也就是值在内存中的地址。(对)
83、 表达式(i * *2 for i in range(100))的结果是个元组。(错)
- 是一个生成器对象
84、 在Python中元组的值是不可变的,因此,已知x = ([1], [2]),那么语句x[0].append(3)是无法正常执行的。(错)
85、 Python内置的字典dict中元素是按添加的顺序依次进行存储的。(错)
86、 Python内置的集合set中元素顺序是按元素的哈希值进行存储的,并不是按先后顺序。(对)
87、 已知x = {1:1, 2:2},那么语句x[3] =3无法正常执行。(错)
88、 Python内置字典是无序的,如果需要一个可以记住元素插入顺序的字典,可以使用collections.OrderedDict。(对)
89、 已知列表x = [1, 2, 3, 4],那么表达式x.find(5)的值应为-1。(错)
- 列表没有find方法,这是字符串用来寻找子串的方法。list只有index方法。
90、 列表对象的排序方法sort()只能按元素从小到大排列,不支持别的排序方式。(错)
91、 已知x是一个列表,那么x = x[3:] + x[:3]可以实现把列表x中的所有元素循环左移3位。(对)