目录
0 开发环境
作者:嘟粥yyds
时间:2023年7月25日
集成开发工具:PyCharm Professional 2021.1和Google Colab
集成开发环境:Python 3.10.6
第三方库:tensorflow-gpu 2.10.0、tf2-bert、pandas、numpy、matplotlib、random、os
1 多任务文本分类简介
1.1 单任务 vs. 多任务学习
在传统的文本分类任务中,通常会针对单个任务进行建模和训练。每个任务都有自己独立的模型和参数。然而,随着多任务学习的兴起,研究人员开始探索如何将多个相关的文本分类任务结合在一起,共享模型参数和学习过程。
单任务学习适用于解决单一的文本分类问题,但在面对多个相关任务时,单独训练多个独立的模型可能会导致数据冗余和计算资源浪费。相比之下,多任务学习可以通过共享底层网络层来学习共享的特征表示,从而提高模型的泛化能力和效率。
1.2 文本分类任务概述
文本分类是指将文本分配到预定义的类别或标签中的任务。在自然语言处理领域,文本分类被广泛应用于情感分析、垃圾邮件过滤、新闻分类等任务。每个文本分类任务都有自己的特定类别集合和训练数据。
文本分类任务的关键是将文本转化为机器可理解的表示形式。传统的方法通常使用手工设计的特征,如词袋模型、TF-IDF等。然而,这些方法往往无法捕捉到文本的语义和上下文信息。深度学习模型,如CNN、LSTM和BERT等,可以自动学习文本的特征表示,从而提高分类性能。
多任务文本分类将多个相关的文本分类任务结合在一起,共享模型参数和学习过程。这种方法可以通过任务之间的相互关联性提供额外的信息,从而改善分类性能。同时,多任务学习还可以减少模型的过拟合风险,提高模型的泛化能力。
在接下来的部分,我们将介绍使用共享底层网络层的CNN模型、双向LSTM模型和采用了自注意力机制的BERT模型,这些模型在多任务文本分类中的应用和性能表现。
2 共享底层网络层的CNN模型
2.1 CNN模型简介
卷积神经网络(Convolutional Neural Network, CNN)是一种常用于图像处理和文本处理的深度学习模型。CNN模型通过卷积层、池化层和全连接层等组件来提取输入数据的特征表示。
在文本分类任务中,CNN模型可以将文本表示为一个二维矩阵,其中每行表示一个词或字符的特征向量。通过应用一系列的卷积核(filters)对输入矩阵进行卷积操作,CNN模型可以捕捉到不同尺度的局部特征。
2.2 多任务学习框架
在多任务文本分类领域,共享底层网络层的卷积神经网络(CNN)模型被广泛应用,其机制在于通过共享卷积层和池化层来学习通用的特征表示。每个任务都有独立的任务特定输出层,用于学习任务特定的分类决策。
这种CNN模型的优势在于可以通过反向传播算法进行端到端的训练,从而同时优化多个任务的损失函数,以达到整体性能的最大化。此外,共享底层网络层的CNN模型还能够有效减少模型的参数数量和计算复杂度,提高模型的训练效率,尤其适用于处理大规模的多任务文本分类问题。通常情况下,相比单任务模型,共享底层网络层的CNN模型能够取得更优秀的分类性能。
在实际应用中,这种共享底层网络层的CNN模型在多任务文本分类中表现出良好的性能。通过共享底层网络层,模型能够学习到更加通用的特征表示,进而提高了其泛化能力。
综上所述,共享底层网络层的CNN模型是一种适用于多任务文本分类的深度学习模型。其共享特征表示的学习能力不仅提高了模型的泛化性能,还增加了训练效率。实验结果表明,这种模型通常在多任务场景下展现出比单任务模型更为优越的分类性能。
2.3 代码实现
2.3.1 导入所需库并定义超参数
import jieba
import pandas as pd
import numpy as np
from tensorflow.keras.layers import Dense, Input, Dropout, LSTM, Bidirectional
from tensorflow.keras.layers import Conv2D, GlobalMaxPool2D, Embedding, concatenate
from tensorflow.keras.preprocessing.text import Tokenizer, tokenizer_from_json
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Model,load_model
from tensorflow.keras.backend import expand_dims
from tensorflow.keras.layers import Lambda
import tensorflow.keras.backend as K
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import plot_model
import json
# 批次大小
batch_size = 128
# 训练周期
epochs = 1
# 词向量长度
embedding_dims = 128
# 滤波器数量
filters = 32
# 这个数据前半部分都是正样本,后半部分都是负样本
data = pd.read_csv('weibo_senti_100k.csv')
# 查看数据前 5 行
data.head()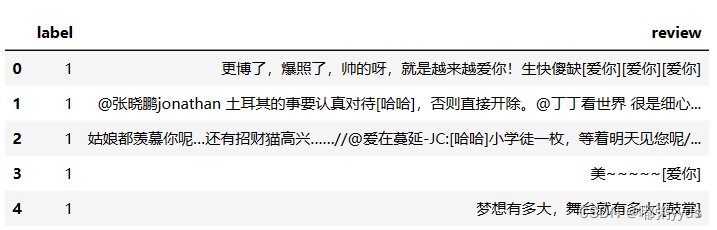
2.3.2 数据处理
# 计算正样本数量
poslen = sum(data['label']==1)
# 计算负样本数量
neglen = sum(data['label']==0)
print('正样本数量:', poslen)
print('负样本数量:', neglen)正样本数量: 59993
负样本数量: 59995# 测试一下结巴分词的使用
print(list(jieba.cut('谎言重复一千遍就成了真理。 --纳粹德国宣传部长')))Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\31600\AppData\Local\Temp\jieba.cache
Loading model cost 0.629 seconds.
Prefix dict has been built successfully.
['谎言', '重复', '一千遍', '就', '成', '了', '真理', '。', ' ', '--', '纳粹德国', '宣传部长']#定义匿名分词函数,对传入的 x 进行分词,返回一个包含了分词后结果的生成器对象
cw = lambda x: list(jieba.cut(x)) # 返回一个列表
# pandas的apply函数接受一个传入的函数,即把 cw 函数应用到 data['review']这一列的每一行
data['words'] = data['review'].apply(cw)
# 再查看数据前 5 行
data.head()
# 计算一条数据最多有多少个词汇
max_length = max([len(x) for x in data['words']])
# 把 data['words']中所有的 list 都变成字符串格式
texts = [' '.join(x) for x in data['words']]
# 查看一条评论,现在数据变成了字符串格式,并且词与词之间用空格隔开
# 这是为了满足下面数据处理对格式的要求,下面要使用 Tokenizer 对数据进行处理
print(texts[4])梦想 有 多 大 , 舞台 就 有 多 大 ! [ 鼓掌 ]2.3.3 模型构建
# 定义模型输入,shape-(batch, 202)
sequence_input = Input(shape=(max_length,))
# Embedding 层,30000 表示 30000 个词,每个词对应的向量为 embedding_dim 维
embedding_layer = Embedding(input_dim=30000, output_dim=embedding_dims)
# embedded_sequences 的 shape-(batch, 202, 128)
embedded_sequences = embedding_layer(sequence_input)
# embedded_sequences 的 shape 变成了(batch, 202, 128, 1)
embedded_sequences = K.expand_dims(embedded_sequences, axis=-1)
# 卷积核大小为 3,列数必须等于词向量长度
cnn1 = Conv2D(filters=filters, kernel_size=(3,embedding_dims), activation='relu')(embedded_sequences)
cnn1 = GlobalMaxPool2D()(cnn1)
# 卷积核大小为 4,列数必须等于词向量长度
cnn2 = Conv2D(filters=filters, kernel_size=(4,embedding_dims), activation='relu')(embedded_sequences)
cnn2 = GlobalMaxPool2D()(cnn2)
# 卷积核大小为 5,列数必须等于词向量长度
cnn3 = Conv2D(filters=filters, kernel_size=(5,embedding_dims), activation='relu')(embedded_sequences)
cnn3 = GlobalMaxPool2D()(cnn3)
# 合并
merge = concatenate([cnn1, cnn2, cnn3], axis=-1)
# 全连接层
x = Dense(128, activation='relu')(merge)
# Dropout层
x = Dropout(0.5)(x)
# 输出层
preds = Dense(2, activation='softmax')(x)
# 定义模型
model = Model(sequence_input, preds)
plot_model(model, show_shapes=True, dpi=180)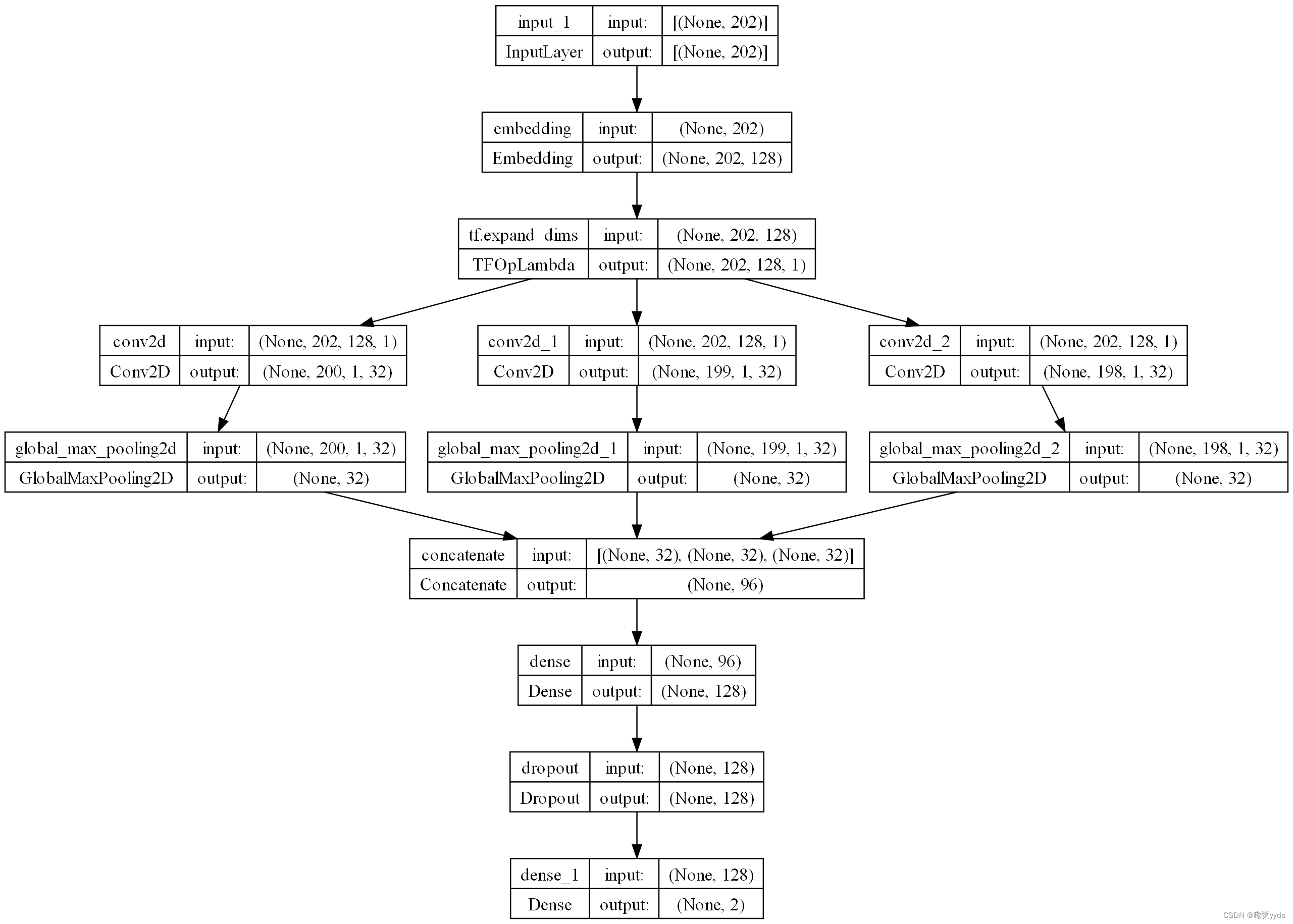
2.3.4 训练和测试
# 定义代价函数,优化器
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 训练模型
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test))
# 保存模型
model.save('cnn_model.h5')750/750 [==============================] - 1112s 1s/step - loss: 0.0504 - acc: 0.9800 - val_loss: 0.0415 - val_acc: 0.9825因为原始数据中有大量表情符号,如[爱你],[哈哈],[鼓掌],[可爱]等,这些表情符号中对应的文字从较大程度上代表了这一句话的情感。所以我们做的这个项目之所以得到这么高的准确率,跟这里的表情符号是有很大关系。大家如果使用其他数据集来做情感分类,应该也会得到不错的结果,但是应该很难得到 98%这么高的准确率。
# 载入 tokenizer
json_file = open('token_config.json','r',encoding='utf-8')
token_config = json.load(json_file)
tokenizer = tokenizer_from_json(token_config)
# 载入模型
model = load_model('cnn_model.h5')
# 情感预测
def predict(text):
# 对句子进行分词
cw = list(jieba.cut(text))
# 将列表转为字符串
texts = ' '.join(cw)
# 将词转为编号
sequences = tokenizer.texts_to_sequences([texts])
sequences = pad_sequences(sequences, maxlen=model.input_shape[1], padding='pre')
# 模型预测
res = np.argmax(model.predict(sequences))
if res == 1:
print("正面情绪")
else:
print("负面情绪")
predict("小明今天的考试不及格[失落]")
predict("小明今天的考试不及格[崩溃]")1/1 [==============================] - 0s 19ms/step
正面情绪
1/1 [==============================] - 0s 18ms/step
负面情绪从上面这个例子更能直观的看出训练得到的模型在这个数据集上能得到这么高的准确率跟表情符号有很大关系。
3 双向LSTM模型
3.1 LSTM模型简介
长短期记忆网络(Long Short-Term Memory, LSTM)是一种常用于序列数据处理的循环神经网络(Recurrent Neural Network, RNN)变体。相比于传统的RNN模型,LSTM模型能够更好地捕捉长期依赖关系,适用于处理文本等序列数据。
LSTM模型通过引入门控机制来控制信息的流动,包括输入门、遗忘门和输出门。这些门控机制使得LSTM模型能够选择性地记住或遗忘过去的信息,并将重要的信息传递到后续时间步。
3.2 多任务学习框架
在多任务文本分类领域,双向长短期记忆网络(BiLSTM)模型被广泛运用,其通过共享双向LSTM层来学习共享的特征表示。该模型在每个时间步都同时考虑过去和未来的上下文信息,从而更为有效地捕捉文本的语义和上下文关系。
类似于共享底层网络层的卷积神经网络(CNN)模型,双向LSTM模型也可以针对每个任务单独设计任务特定的输出层,以学习任务特定的分类决策。
实践证明,双向LSTM模型在多任务文本分类方面取得了良好的性能。通过共享双向LSTM层,该模型能够学习到更为丰富的上下文信息,从而提高分类性能。
尤其在处理长文本和序列数据时,双向LSTM模型显示出明显优势,能够更准确地捕捉文本中的语义和上下文关系。因此,在一些需要考虑全局信息的任务上,该模型表现出色。通常情况下,双向LSTM模型在多个任务上都能取得比单任务模型更优的分类性能。
综上所述,双向LSTM模型作为一种适用于多任务文本分类的循环神经网络,通过共享双向LSTM层实现共享特征表示,进而提高模型的分类性能。尤其在处理长文本和序列数据时,双向LSTM模型表现出优越性,能够更准确地捕捉文本的语义和上下文关系。
3.2.1 代码实现
由于该模型的数据处理方面与共享底层网络的CNN模型没有区别,故这里不再重复展示相同代码,只展示模型构建及其之后的代码。
# 所需库和很多其他超参数与原CNN模型相同,故这里不再定义,直接沿用
epochs = 3
# cell 数量
lstm_cell = 64
# 数据预处理也直接沿用CNN模型的做法,这里也不给出实现,直接定义模型
# 定义模型输入,shape-(batch, 202)
sequence_input = Input(shape=(max_length,))
# Embedding 层,30000 表示 30000 个词,每个词对应的向量为 128 维
embedding_layer = Embedding(input_dim=30000, output_dim=embedding_dims)
# embedded_sequences 的 shape-(batch, 202, 128)
embedded_sequences = embedding_layer(sequence_input)
# 双向 LSTM
x = Bidirectional(LSTM(lstm_cell))(embedded_sequences)
# 全连接层
x = Dense(128, activation='relu')(x)
# Dropout 层
x = Dropout(0.5)(x)
# 输出层
preds = Dense(2, activation='softmax')(x)
# 定义模型
model = Model(sequence_input, preds)
# 画图
plot_model(model, show_shapes=True)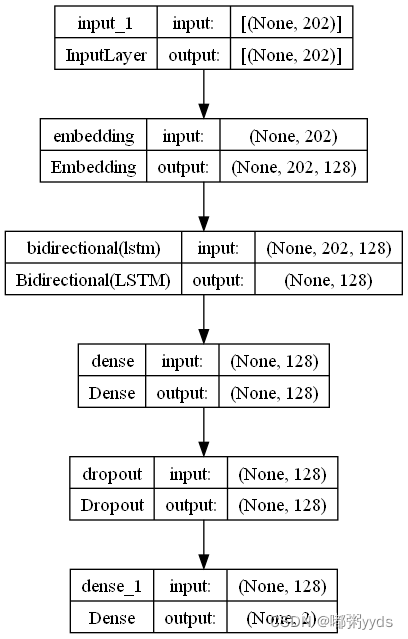
3.2.2 训练和测试
# 定义代价函数,优化器
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
# 训练模型
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test))
# 保存模型
model.save('lstm_model.h5')Epoch 1/3
750/750 [==============================] - 31s 38ms/step - loss: 0.1160 - acc: 0.9647 - val_loss: 0.0640 - val_acc: 0.9824
Epoch 2/3
750/750 [==============================] - 36s 48ms/step - loss: 0.0506 - acc: 0.9815 - val_loss: 0.0456 - val_acc: 0.9822
Epoch 3/3
750/750 [==============================] - 34s 45ms/step - loss: 0.0438 - acc: 0.9814 - val_loss: 0.0541 - val_acc: 0.9815单从准确率看,该模型并未取得比原始CNN模型更好的表现,不过训练代价相比却大大降低。在相同GPU资源的情况下,训练一个epoch的时间少了32倍。
# 载入 tokenizer
json_file = open('token_config.json','r',encoding='utf-8')
token_config = json.load(json_file)
tokenizer = tokenizer_from_json(token_config)
# 载入模型
model = load_model('lstm_model.h5')
predict("小明今天的数学考了90分[失落]")
predict("小明今天的数学考了90分[伤心]")1/1 [==============================] - 0s 25ms/step
正面情绪
1/1 [==============================] - 0s 24ms/step
负面情绪4 采用自注意力机制的BERT模型
4.1 BERT模型简介
BERT(Bidirectional Encoder Representations from Transformers)是一种基于自注意力机制的预训练语言模型,被广泛应用于自然语言处理任务。BERT模型通过在大规模文本语料上进行预训练,学习到丰富的语言表示。
BERT模型采用了Transformer架构,其中的自注意力机制使得模型能够同时考虑输入序列中的所有位置信息,从而更好地捕捉上下文关系。BERT模型的特点是双向性,即它可以同时利用前向和后向的上下文信息。
4.2 多任务学习框架
在多任务文本分类领域,采用自注意力机制的 BERT 模型通过共享编码层来学习共享的语言表示。每个任务都拥有独立的任务特定输出层,用于学习任务特定的分类决策。
BERT 模型的预训练过程使其具备学习丰富语言表示的能力,这些表示可以在多个任务上进行微调,以适应不同的文本分类任务。
在多任务文本分类中,采用自注意力机制的 BERT 模型表现出显著的性能提升。通过共享BERT 的编码层,模型能够学习到更加丰富的语言表示,从而提高分类性能。
BERT 模型在处理语义和上下文关系方面具有优势,能够更好地捕捉文本的语义信息。这使得在某些需要深入理解文本语义的任务上,BERT 表现出色。通常情况下,采用 BERT 模型的多任务学习能够在多个任务上获得比单任务模型更好的分类性能。
综上所述,采用自注意力机制的 BERT 模型是一种用于多任务文本分类的预训练语言模型。通过共享 BERT 的编码层,模型能够学习到共享的语言表示,提高模型的分类性能。在处理语义和上下文关系时,BERT 模型具有优势,能够更好地捕捉文本的语义信息。
4.3 代码实现
4.3.1 预准备
BERT 模型的完整实现即便是做了很多的精简,整个程序也还是有 1000 多行的代码。所以在这里就不讲解 BERT 模型实现的细节了。下面主要讲一下如何使用 BERT 来完成 NLP 相关的一些任务。
首先我们需要先安装 tf2_bert 模块,安装方式为打开命令提示符运行命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tf2-bert模块安装好以后我们还需要下载预训练模型,可以通过网址https://github.com/google-research/bert 下载谷歌官方的预训练模型,但谷歌提供的预训练模型大部分都是使用英文语料训练出来的。如果要使用中文语料训练的 BERT 模型,推荐大家使用哈工大提供的预训练模型,网址为: https://github.com/ymcui/Chinese-BERT-wwm。 本文使用的是哈工大提供的预训练模型中的一个简称为“RoBERTa-wwm-ext, Chinese”的 模型,下载好以后得到一个名为“chinese_roberta_wwm_ext_L-12_H-768_A-12”的文件夹,文件夹中的文件如下:
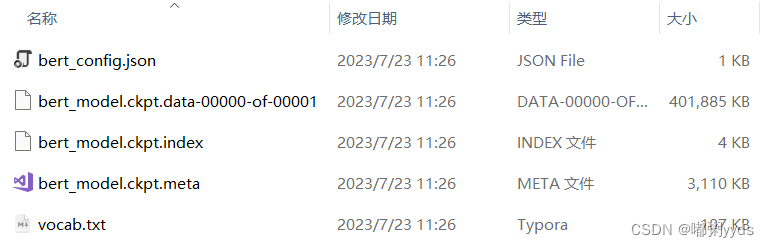
其中“bert_config.json”是 BERT 模型相关的一些配置文件,“vocab.txt”为 BERT 模型训练时用到的词表,剩下的 3 个为 Tensorflow 的模型文件。“ckpt”为“checkpoint” 的缩写,“ckpt”这种模型保存格式在 Tensorflow1.0 中用得比较多,也可以沿用至 Tensorflow2。
4.3.2 BERT的简单使用
from tf2_bert.models import build_transformer_model
from tf2_bert.tokenizers import Tokenizer
import numpy as np
# 定义预训练模型路径
model_dir = './chinese_roberta_wwm_ext_L-12_H-768_A-12'
# BERT 参数
config_path = model_dir+'/bert_config.json'
# 保存模型权值参数的文件
checkpoint_path = model_dir+'/bert_model.ckpt'
# 词表
dict_path = model_dir+'/vocab.txt'
# 建立分词器
tokenizer = Tokenizer(dict_path)
# 文本特征提取
# 建立模型,加载权重
model = build_transformer_model(config_path, checkpoint_path)
# 句子 0
sentence0 = '机器学习'
# 句子 1
sentence1 = '深度学习'
# 用分词器对句子分词
tokens = tokenizer.tokenize(sentence0)
# 分词后自动在句子前加上[CLS],在句子后加上[SEP]
print(tokens)
['[CLS]', '机', '器', '学', '习', '[SEP]']
# 编码测试1
token_ids1, segment_ids1 = tokenizer.encode(sentence0)
# [CLS]的编号为 101,机为 3322,器为 1690,学为 2110,习为 739,[SEP]为 102
print('token_ids1:',token_ids1)
# 因为只有一个句子所以 segment_ids1 都是 0
print('segment_ids1:',segment_ids1)
# 编码测试2
token_ids2, segment_ids2 = tokenizer.encode(sentence0,sentence1)
# 可以看到两个句子分词后的结果为:
# ['[CLS]', '机', '器', '学', '习', '[SEP]', '深', '度', '学', '习', [SEP]]
print('token_ids2:',token_ids2)
# 0 表示第一个句子的 token,1 表示第二个句子的 token
print('segment_ids2:',segment_ids2)token_ids1: [101, 3322, 1690, 2110, 739, 102]
segment_ids1: [0, 0, 0, 0, 0, 0]
token_ids2: [101, 3322, 1690, 2110, 739, 102, 3918, 2428, 2110, 739, 102]
segment_ids2: [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]# 增加一个维度表示批次大小为 1
token_ids = np.expand_dims(token_ids,axis=0)
# 增加一个维度表示批次大小为 1
segment_ids = np.expand_dims(segment_ids,axis=0)
# 传入模型进行预测
pre = model.predict([token_ids, segment_ids])
# 得到的结果中 1 表示批次大小,11 表示 11 个 token,768 表示特征向量长度
# 这里就是把句子的 token 转化为了特征向量
print(pre.shape)1/1 [==============================] - 4s 4s/step
(1, 11, 768)# 完形填空
# 建立模型,加载权重
# with_mlm=True 表示使用 mlm 的功能,模型结构及最后的输出会发生一些变化,可以用来预测被 mask 的 token
model = build_transformer_model(config_path, checkpoint_path, with_mlm=True)
# 分词并转化为编码
token_ids, segment_ids = tokenizer.encode('机器学习是一门交叉学科')
# 把“学”字和“习”字变成“[MASK]”符号
token_ids[3] = token_ids[4] = tokenizer._token_dict['[MASK]']
# 增加一个维度表示批次大小为 1
token_ids = np.expand_dims(token_ids,axis=0)
# 增加一个维度表示批次大小为 1
segment_ids = np.expand_dims(segment_ids,axis=0)
# 传入模型进行预测
pre = model.predict([token_ids, segment_ids])[0]
# 我们可以看到第 3,4 个位置经过模型预测,[MASK]变成了“学习”
print(tokenizer.decode(pre[3:5].argmax(axis=1)))
# 分词并转化为编码
token_ids, segment_ids = tokenizer.encode('机器学习是一门交叉学科')
# 把“交”字和“叉”字变成“[MASK]”符号
token_ids[8] = token_ids[9] = tokenizer._token_dict['[MASK]']
# 增加一个维度表示批次大小为 1
token_ids = np.expand_dims(token_ids,axis=0)
# 增加一个维度表示批次大小为 1
segment_ids = np.expand_dims(segment_ids,axis=0)
# 传入模型进行预测
pre = model.predict([token_ids, segment_ids])[0]
# 我们可以看到第 8,9 个位置经过模型预测,[MASK]变成了“什么”,句子变成了一个疑问句
# 虽然模型没有预测出原始句子的词汇,不过作为完形填空,填入一个“什么”句子也是正确
print(tokenizer.decode(pre[8:10].argmax(axis=1)))1/1 [==============================] - 2s 2s/step
学习
1/1 [==============================] - 0s 143ms/step
什么4.3.3 电商用户多情绪判定项目
上面两个模型使用的情感分类数据都是网上可以找到的开源数据,并且相对简单。这一小节 来点更硬核的内容,给大家介绍一个我之前给某化妆品公司做的电商用户多种情绪判断的项目,项目用到的部分标注好的数据会随本文项目资源一起给出。
项目背景大概就是化妆品公司希望可以通过分析自己用户的评论数据,挖掘影响产品购买的因素,提供产品建议或策略指导,进而提升效率。了解对方需求后,我对用户评论的分析并不只是针对好评还是差评这一个维度来判断,只判断好评差评维度太单一,无法挖掘出更深层次的内容。因此我把用户评论的分析分为了 7 个不同维度,分别是总体评论、是否为老用户、是否是参与活动购买、产品质量评价、性价比评价、客户物流包装等服务评价和是否考虑在再次购买。每个维度都有 3 个分类,在数据的标注中使用 1,0,-1 来标注。
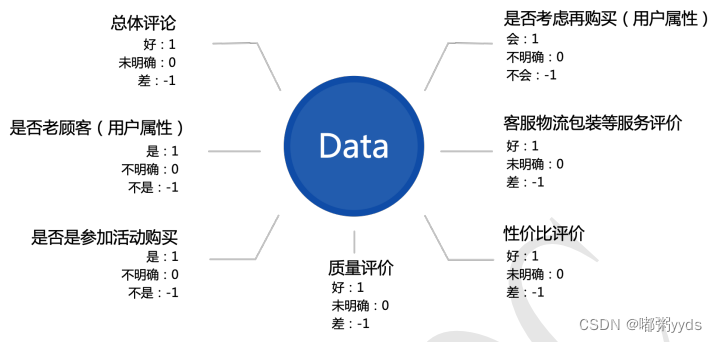
4.3.3.1 导入所需库并定义超参数
由于 BERT 模型较大,本文选用的预训练 BERT模型所需GPU资源相比较小。batch_size=32时所需GPU资源大概15G左右,读者可根据自身情况调整batch_size参数的值。
from tf2_bert.models import build_transformer_model
from tf2_bert.tokenizers import Tokenizer
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras.layers import Lambda, Dense, Input, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint
import numpy as np
import pandas as pd
# 周期数
epochs = 5
# 批次大小
batch_size = 32
# 验证集占比
validation_split = 0.2
# 句子长度
seq_len = 256
# 载入数据
data = pd.read_excel('reviews.xlsx')
# 查看数据前 5 行
data.head()
# 定义预训练模型路径
model_dir = './chinese_roberta_wwm_ext_L-12_H-768_A-12'
# BERT 参数
config_path = model_dir + '/bert_config.json'
# 保存模型权值参数的文件
checkpoint_path = model_dir + '/bert_model.ckpt'
# 词表
dict_path = model_dir + '/vocab.txt'
# 建立分词器
tokenizer = Tokenizer(dict_path)
# 建立模型,加载权重
bert_model = build_transformer_model(config_path, checkpoint_path)
4.3.3.2 数据处理
token_ids = [] # 存储每个句子分词后的编号序列
segment_ids = [] # 存储每个句子的分段编号序列
# 循环每个句子
for s in data['评论'].astype(str):
# 分词并把 token 变成编号
token_id, segment_id = tokenizer.encode(s, first_length=seq_len)
token_ids.append(token_id)
segment_ids.append(segment_id)
token_ids = np.array(token_ids)
segment_ids = np.array(segment_ids)
# 定义标签
def LabelEncoder(y):
# 增加一个维度
y = y[:, np.newaxis]
# 原始标签把-1,0,1 变成 0,1,2 保证标签从 0 开始计数,便于后续进行独热编码
y = y + 1
y = y.astype('uint8') # 转换为 'uint8',以减少内存占用
# 转成独热编码
y = to_categorical(y, num_classes=3)
return y
# 获取 7 个维度的标签,并把每个维度的标签从-1,0,1 变成 0,1,2
label = [(LabelEncoder(np.array(data[columns]))) for columns in data.columns[1:]]
label = np.array(label)
# token 输入
token_in = Input(shape=(None,))
# segment 输入
segment_in = Input(shape=(None,))
# 使用 BERT 进行特征提取
x = bert_model([token_in, segment_in])
# 每个序列的第一个字符是句子的分类[CLS],该字符对应的 embedding 可以用作分类任务中该序列的总表示
# 说白了就是用句子第一个字符的 embedding 来表示整个句子
# 取出每个句子的第一个字符对应的 embedding
x = Lambda(lambda x: x[:, 0])(x)4.3.3.3 多任务模型构建
# 多任务学习
# 性价比输出层
x0 = Dropout(0.5)(x)
preds0 = Dense(3, activation='softmax', name='out0')(x0)
# 产品质量输出层
x1 = Dropout(0.5)(x)
preds1 = Dense(3, activation='softmax', name='out1')(x1)
# 参加活动输出层
x2 = Dropout(0.5)(x)
preds2 = Dense(3, activation='softmax', name='out2')(x2)
# 客服物流包装输出层
x3 = Dropout(0.5)(x)
preds3 = Dense(3, activation='softmax', name='out3')(x3)
# 是否为老顾客输出层
x4 = Dropout(0.5)(x)
preds4 = Dense(3, activation='softmax', name='out4')(x4)
# 是否会再买输出层
x5 = Dropout(0.5)(x)
preds5 = Dense(3, activation='softmax', name='out5')(x5)
# 总体评论输出层
x6 = Dropout(0.5)(x)
preds6 = Dense(3, activation='softmax', name='out6')(x6)
# 定义模型
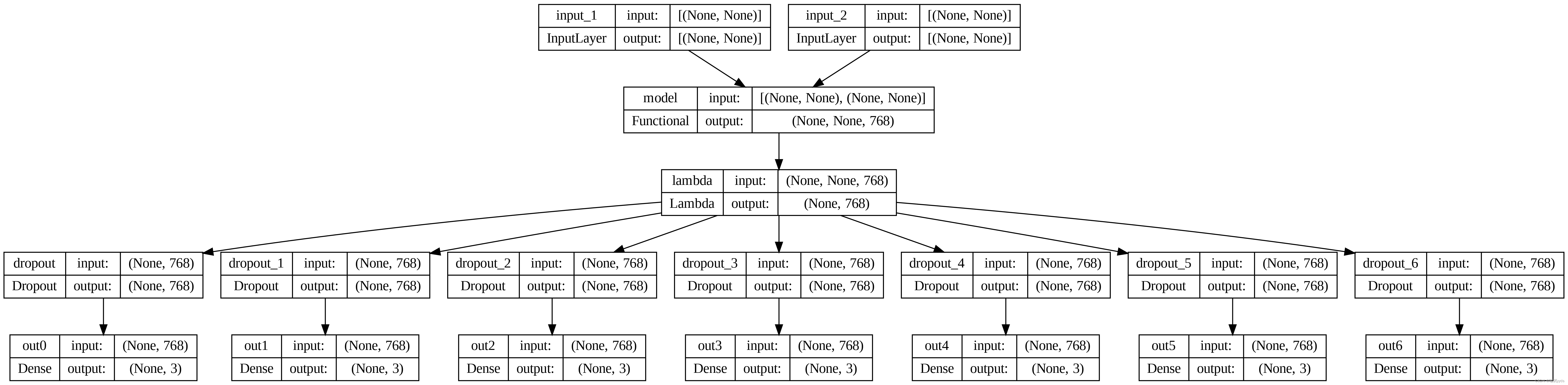
model = Model([token_in, segment_in], [preds0, preds1, preds2, preds3, preds4, preds5, preds6])
# 画出模型结构
plot_model(model, show_shapes=True, dpi=300)
model.summary()Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None)] 0 []
input_2 (InputLayer) [(None, None)] 0 []
model (Functional) (None, None, 768) 101677056 ['input_1[0][0]',
'input_2[0][0]']
lambda (Lambda) (None, 768) 0 ['model[0][0]']
dropout (Dropout) (None, 768) 0 ['lambda[0][0]']
dropout_1 (Dropout) (None, 768) 0 ['lambda[0][0]']
dropout_2 (Dropout) (None, 768) 0 ['lambda[0][0]']
dropout_3 (Dropout) (None, 768) 0 ['lambda[0][0]']
dropout_4 (Dropout) (None, 768) 0 ['lambda[0][0]']
dropout_5 (Dropout) (None, 768) 0 ['lambda[0][0]']
dropout_6 (Dropout) (None, 768) 0 ['lambda[0][0]']
out0 (Dense) (None, 3) 2307 ['dropout[0][0]']
out1 (Dense) (None, 3) 2307 ['dropout_1[0][0]']
out2 (Dense) (None, 3) 2307 ['dropout_2[0][0]']
out3 (Dense) (None, 3) 2307 ['dropout_3[0][0]']
out4 (Dense) (None, 3) 2307 ['dropout_4[0][0]']
out5 (Dense) (None, 3) 2307 ['dropout_5[0][0]']
out6 (Dense) (None, 3) 2307 ['dropout_6[0][0]']
==================================================================================================
Total params: 101,693,205
Trainable params: 101,693,205
Non-trainable params: 0
__________________________________________________________________________________________________
# 定义模型训练的 loss,loss_weights,optimizer
# loss_weights 表示每个任务的权重,可以看情况设置
model.compile(loss={
'out0': 'categorical_crossentropy',
'out1': 'categorical_crossentropy',
'out2': 'categorical_crossentropy',
'out3': 'categorical_crossentropy',
'out4': 'categorical_crossentropy',
'out5': 'categorical_crossentropy',
'out6': 'categorical_crossentropy'},
loss_weights={
'out0': 1.,
'out1': 1.,
'out2': 1.,
'out3': 1.,
'out4': 1.,
'out5': 1,
'out6': 2.},
optimizer=Adam(1e-5),
metrics=['accuracy'])
# 保存 val_loss 最低的模型
callbacks = [ModelCheckpoint(filepath='bert_model.h5',
monitor='val_loss',
verbose=1,
save_best_only=True)]4.3.3.4 模型训练与测试
# 训练模型
model.fit([token_ids, segment_ids], [label[0], label[1], label[2], label[3], label[4], label[5], label[6]],
batch_size=batch_size,
epochs=epochs,
validation_split=validation_split,
callbacks=callbacks)Epoch 1/5
250/250 [==============================] - ETA: 0s - loss: 4.4207 - out0_loss: 0.3608 - out1_loss: 0.8598 - out2_loss: 0.2808 - out3_loss: 0.6312 - out4_loss: 0.6134 - out5_loss: 0.3301 - out6_loss: 0.6723 - out0_accuracy: 0.9000 - out1_accuracy: 0.6279 - out2_accuracy: 0.9246 - out3_accuracy: 0.7703 - out4_accuracy: 0.7991 - out5_accuracy: 0.9064 - out6_accuracy: 0.7650
Epoch 1: val_loss improved from inf to 3.25829, saving model to bert_model.h5
250/250 [==============================] - 528s 2s/step - loss: 4.4207 - out0_loss: 0.3608 - out1_loss: 0.8598 - out2_loss: 0.2808 - out3_loss: 0.6312 - out4_loss: 0.6134 - out5_loss: 0.3301 - out6_loss: 0.6723 - out0_accuracy: 0.9000 - out1_accuracy: 0.6279 - out2_accuracy: 0.9246 - out3_accuracy: 0.7703 - out4_accuracy: 0.7991 - out5_accuracy: 0.9064 - out6_accuracy: 0.7650 - val_loss: 3.2583 - val_out0_loss: 0.3208 - val_out1_loss: 0.5651 - val_out2_loss: 0.2841 - val_out3_loss: 0.2007 - val_out4_loss: 0.4896 - val_out5_loss: 0.2769 - val_out6_loss: 0.5605 - val_out0_accuracy: 0.9215 - val_out1_accuracy: 0.7620 - val_out2_accuracy: 0.8975 - val_out3_accuracy: 0.9260 - val_out4_accuracy: 0.8095 - val_out5_accuracy: 0.8995 - val_out6_accuracy: 0.7870
Epoch 2/5
250/250 [==============================] - ETA: 0s - loss: 2.0810 - out0_loss: 0.1507 - out1_loss: 0.4365 - out2_loss: 0.1167 - out3_loss: 0.2002 - out4_loss: 0.2979 - out5_loss: 0.1842 - out6_loss: 0.3474 - out0_accuracy: 0.9561 - out1_accuracy: 0.8214 - out2_accuracy: 0.9604 - out3_accuracy: 0.9361 - out4_accuracy: 0.8971 - out5_accuracy: 0.9312 - out6_accuracy: 0.8720
Epoch 2: val_loss improved from 3.25829 to 3.01527, saving model to bert_model.h5
250/250 [==============================] - 465s 2s/step - loss: 2.0810 - out0_loss: 0.1507 - out1_loss: 0.4365 - out2_loss: 0.1167 - out3_loss: 0.2002 - out4_loss: 0.2979 - out5_loss: 0.1842 - out6_loss: 0.3474 - out0_accuracy: 0.9561 - out1_accuracy: 0.8214 - out2_accuracy: 0.9604 - out3_accuracy: 0.9361 - out4_accuracy: 0.8971 - out5_accuracy: 0.9312 - out6_accuracy: 0.8720 - val_loss: 3.0153 - val_out0_loss: 0.2306 - val_out1_loss: 0.6138 - val_out2_loss: 0.2658 - val_out3_loss: 0.1862 - val_out4_loss: 0.3345 - val_out5_loss: 0.1956 - val_out6_loss: 0.5944 - val_out0_accuracy: 0.9370 - val_out1_accuracy: 0.7680 - val_out2_accuracy: 0.9245 - val_out3_accuracy: 0.9420 - val_out4_accuracy: 0.8875 - val_out5_accuracy: 0.9300 - val_out6_accuracy: 0.8115
Epoch 3/5
250/250 [==============================] - ETA: 0s - loss: 1.5960 - out0_loss: 0.1176 - out1_loss: 0.3653 - out2_loss: 0.0858 - out3_loss: 0.1490 - out4_loss: 0.2015 - out5_loss: 0.1161 - out6_loss: 0.2803 - out0_accuracy: 0.9663 - out1_accuracy: 0.8608 - out2_accuracy: 0.9732 - out3_accuracy: 0.9536 - out4_accuracy: 0.9310 - out5_accuracy: 0.9592 - out6_accuracy: 0.8974
Epoch 3: val_loss improved from 3.01527 to 2.99901, saving model to bert_model.h5
250/250 [==============================] - 466s 2s/step - loss: 1.5960 - out0_loss: 0.1176 - out1_loss: 0.3653 - out2_loss: 0.0858 - out3_loss: 0.1490 - out4_loss: 0.2015 - out5_loss: 0.1161 - out6_loss: 0.2803 - out0_accuracy: 0.9663 - out1_accuracy: 0.8608 - out2_accuracy: 0.9732 - out3_accuracy: 0.9536 - out4_accuracy: 0.9310 - out5_accuracy: 0.9592 - out6_accuracy: 0.8974 - val_loss: 2.9990 - val_out0_loss: 0.2126 - val_out1_loss: 0.5682 - val_out2_loss: 0.2477 - val_out3_loss: 0.1711 - val_out4_loss: 0.3055 - val_out5_loss: 0.2174 - val_out6_loss: 0.6383 - val_out0_accuracy: 0.9350 - val_out1_accuracy: 0.8000 - val_out2_accuracy: 0.9275 - val_out3_accuracy: 0.9485 - val_out4_accuracy: 0.8970 - val_out5_accuracy: 0.9230 - val_out6_accuracy: 0.8160
Epoch 4/5
250/250 [==============================] - ETA: 0s - loss: 1.3170 - out0_loss: 0.0955 - out1_loss: 0.3149 - out2_loss: 0.0664 - out3_loss: 0.1186 - out4_loss: 0.1641 - out5_loss: 0.0937 - out6_loss: 0.2319 - out0_accuracy: 0.9720 - out1_accuracy: 0.8742 - out2_accuracy: 0.9811 - out3_accuracy: 0.9616 - out4_accuracy: 0.9438 - out5_accuracy: 0.9675 - out6_accuracy: 0.9165
Epoch 4: val_loss improved from 2.99901 to 2.78956, saving model to bert_model.h5
250/250 [==============================] - 464s 2s/step - loss: 1.3170 - out0_loss: 0.0955 - out1_loss: 0.3149 - out2_loss: 0.0664 - out3_loss: 0.1186 - out4_loss: 0.1641 - out5_loss: 0.0937 - out6_loss: 0.2319 - out0_accuracy: 0.9720 - out1_accuracy: 0.8742 - out2_accuracy: 0.9811 - out3_accuracy: 0.9616 - out4_accuracy: 0.9438 - out5_accuracy: 0.9675 - out6_accuracy: 0.9165 - val_loss: 2.7896 - val_out0_loss: 0.1771 - val_out1_loss: 0.5672 - val_out2_loss: 0.2306 - val_out3_loss: 0.1802 - val_out4_loss: 0.3047 - val_out5_loss: 0.2488 - val_out6_loss: 0.5404 - val_out0_accuracy: 0.9400 - val_out1_accuracy: 0.7990 - val_out2_accuracy: 0.9320 - val_out3_accuracy: 0.9465 - val_out4_accuracy: 0.9015 - val_out5_accuracy: 0.9225 - val_out6_accuracy: 0.8345
Epoch 5/5
231/250 [==========================>...] - ETA: 30s - loss: 1.1235 - out0_loss: 0.0811 - out1_loss: 0.2844 - out2_loss: 0.0580 - out3_loss: 0.0994 - out4_loss: 0.1419 - out5_loss: 0.0756 - out6_loss: 0.1916 - out0_accuracy: 0.9758 - out1_accuracy: 0.8937 - out2_accuracy: 0.9834 - out3_accuracy: 0.9702 - out4_accuracy: 0.9521 - out5_accuracy: 0.9774 - out6_accuracy: 0.9309import matplotlib.pyplot as plt
# 获取训练过程中的准确率和损失值
accuracy_out0 = history.history['out0_accuracy']
accuracy_out1 = history.history['out1_accuracy']
accuracy_out2 = history.history['out2_accuracy']
accuracy_out3 = history.history['out3_accuracy']
accuracy_out4 = history.history['out4_accuracy']
accuracy_out5 = history.history['out5_accuracy']
accuracy_out6 = history.history['out6_accuracy']
loss_out0 = history.history['out0_loss']
loss_out1 = history.history['out1_loss']
loss_out2 = history.history['out2_loss']
loss_out3 = history.history['out3_loss']
loss_out4 = history.history['out4_loss']
loss_out5 = history.history['out5_loss']
loss_out6 = history.history['out6_loss']
# 创建 epochs 列表,用于横坐标
epochs = range(1, len(accuracy_out0) + 1)
# 绘制七个任务的准确率曲线
plt.plot(epochs, accuracy_out0, label='Accuracy out0')
plt.plot(epochs, accuracy_out1, label='Accuracy out1')
plt.plot(epochs, accuracy_out2, label='Accuracy out2')
plt.plot(epochs, accuracy_out3, label='Accuracy out3')
plt.plot(epochs, accuracy_out4, label='Accuracy out4')
plt.plot(epochs, accuracy_out5, label='Accuracy out5')
plt.plot(epochs, accuracy_out6, label='Accuracy out6')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy for Each Task')
plt.show()
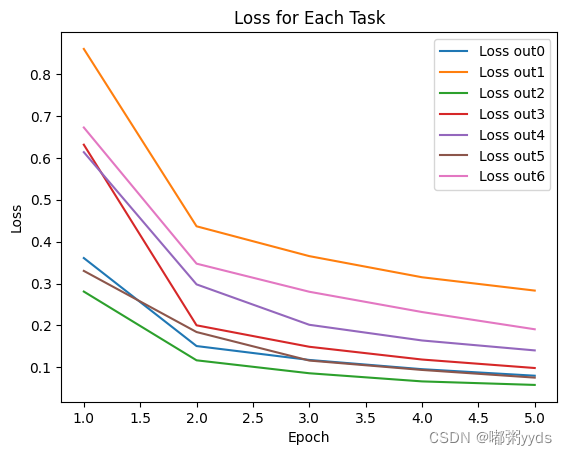
# 绘制七个任务的损失值曲线
plt.plot(epochs, loss_out0, label='Loss out0')
plt.plot(epochs, loss_out1, label='Loss out1')
plt.plot(epochs, loss_out2, label='Loss out2')
plt.plot(epochs, loss_out3, label='Loss out3')
plt.plot(epochs, loss_out4, label='Loss out4')
plt.plot(epochs, loss_out5, label='Loss out5')
plt.plot(epochs, loss_out6, label='Loss out6')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss for Each Task')
plt.show()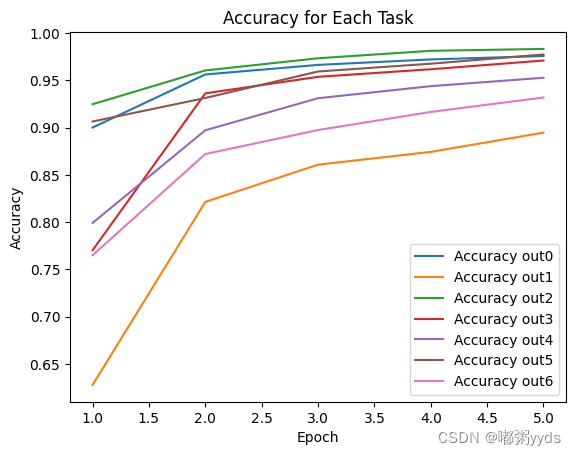
# 载入模型
model = load_model('bert_model.h5')
# 词表路径
dict_path = './chinese_roberta_wwm_ext_L-12_H-768_A-12'+'/vocab.txt'
# 建立分词器
tokenizer = Tokenizer(dict_path)
# 预测函数
def predict(text):
# 分词并把 token 变成编号,句子长度需要与模型训练时一致
token_ids, segment_ids = tokenizer.encode(text, first_length=256)
# 增加一个维度表示批次大小为 1
token_ids = np.expand_dims(token_ids,axis=0)
# 增加一个维度表示批次大小为 1
segment_ids = np.expand_dims(segment_ids,axis=0)
# 模型预测
pre = model.predict([token_ids, segment_ids])
# 去掉一个没用的维度
pre = np.array(pre).reshape((7,3))
# 获得可能性最大的预测结果
pre = np.argmax(pre,axis=1)
comment = ''
if(pre[0]==0):
comment += '性价比差,'
elif(pre[0]==1):
comment += '-,'
elif(pre[0]==2):
comment += '性价比好,'
if(pre[1]==0):
comment += '质量差,'
elif(pre[1]==1):
comment += '-,'
elif(pre[1]==2):
comment += '质量好,'
if(pre[2]==0):
comment += '希望有活动,'
elif(pre[2]==1):
comment += '-,'
elif(pre[2]==2):
comment += '参加了活动,'
if(pre[3]==0):
comment += '客服物流包装差,'
elif(pre[3]==1):
comment += '-,'
elif(pre[3]==2):
comment += '客服物流包装好,'
if(pre[4]==0):
comment += '新用户,'
elif(pre[4]==1):
comment += '-,'
elif(pre[4]==2):
comment += '老用户,'
if(pre[5]==0):
comment += '不会再买,'
elif(pre[5]==1):
comment += '-,'
elif(pre[5]==2):
comment += '会继续购买,'
if(pre[6]==0):
comment += '差评'
elif(pre[6]==1):
comment += '中评'
elif(pre[6]==2):
comment += '好评'
return pre,comment
pre,comment = predict("还没用,不知道怎么样")
print('pre:',pre)
print('comment:',comment)
pre,comment = predict("质量不错,还会再来,价格优惠")
print('pre:',pre)
print('comment:',comment)
pre,comment = predict("好用不贵物美价廉,用后皮肤水水的非常不错")
print('pre:',pre)
print('comment:',comment)1/1 [==============================] - 7s 7s/step
pre: [1 1 1 1 1 1 1]
comment: -,-,-,-,-,-,中评
1/1 [==============================] - 0s 100ms/step
pre: [2 2 1 1 1 2 2]
comment: 性价比好,质量好,-,-,-,会继续购买,好评
1/1 [==============================] - 0s 71ms/step
pre: [2 2 1 1 1 1 2]
comment: 性价比好,质量好,-,-,-,-,好评通过对基于深度学习的多任务文本分类任务的介绍,我们了解到多任务文本分类是一种通过共享模型参数和学习过程来同时处理多个文本分类任务的方法。它可以提高分类性能和模型的泛化能力,同时还可以通过任务之间的相互关联性提供额外的信息。
在具体的模型选择上,我们介绍了共享底层网络层的CNN模型、双向LSTM模型和采用自注意力机制的BERT模型。这些模型在不同的文本长度和任务关联性下都有各自的优势和限制。
最终的选择应该根据具体的任务需求、数据特点和计算资源来进行权衡。同时,还可以根据实际情况进行模型的调优和改进,以提高多任务文本分类的性能和效果。
总的来说,基于深度学习的多任务文本分类是一个具有广泛应用前景的研究领域,通过不断的探索和创新,我们可以进一步提升文本分类的性能和效果。
5 项目资源地址
项目资源地址如下:0911duzhou/NLP- (github.com)
若无法访问Github,也可在博主主页的资源里下载。