说明
本项目包含:
1.LSTM简介,主体翻译自这个英文文章,稍微加了一些个人理解
LSTM介绍
长期短期记忆网络 - 通常简称为“LSTM” 是一种特殊的RNN,能够学习长期依赖关系。它们由Hochreiter&Schmidhuber(1997)引入,并在随后的工作中被许多人完善和推广.它们在各种各样的问题上工作的非常好,现在被广泛使用。
LSTM 被明确设计为避免长期依赖问题。长时间记住信息实际上是他们的默认行为,而不是他们努力学习的东西!
所有RNN都具有神经网络的链式重复模块。在标准RNN中,这个重复模块将具有非常简单的结构,例如单个tanh层。
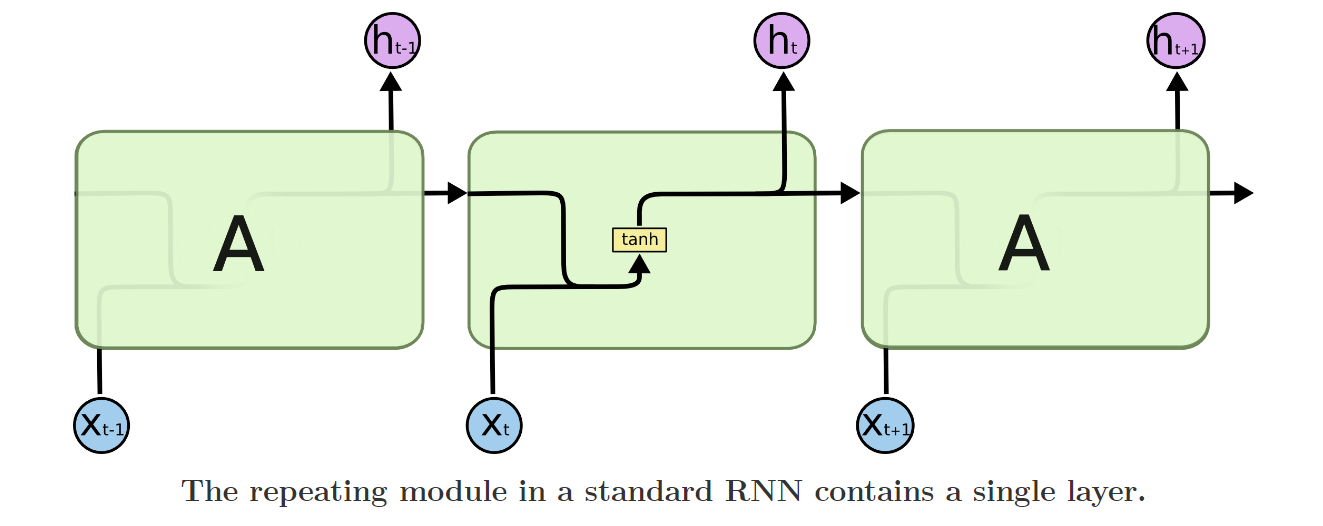
LSTM也有类似的链式模块,但是这些模块有不同的结构,且并非是单个的神经网络层,而是四个以特殊方式相互作用的网络层。
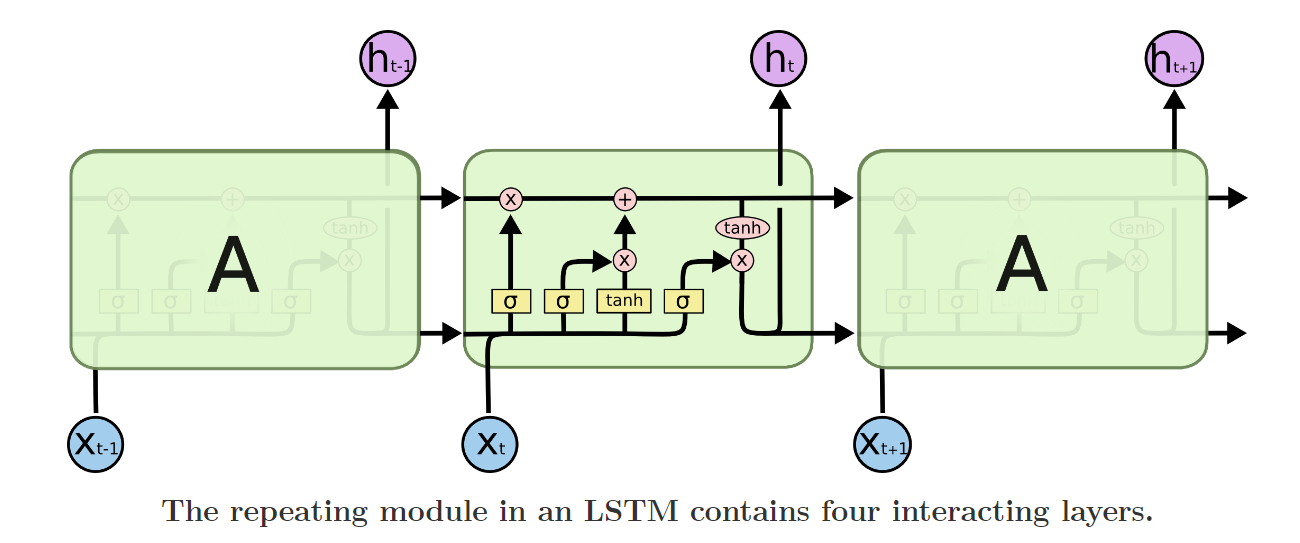
下面是符号介绍

上图中,每条线代表一个完整的向量,从一个节点的输出到其他节点的输入
粉色的圆圈代表逐点运算,比如向量加法
黄色框代表被学习的神经网络层
两个向量聚合并表示拼接,而行分叉表示其内容被复制并且副本将转到不同的位置。
LSTM背后的核心思想
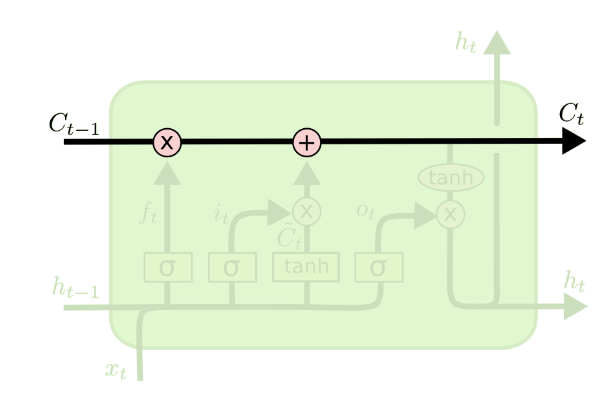
LSTM 的关键是单元状态,即贯穿图表顶部的水平线。
细胞状态有点像传送带。它直接沿着整个链条向下运行,只有一些轻微的线性相互作用。信息很容易原封不动地沿着它流动。
意思是信息经过一些简单的线性变换就可以输出。
如下图黑色线条所示:
LSTM能够通过“门”结构去删除或添加信息到细胞状态。
门是一种选择性地让信息通过的方式。它们由 sigmoid 神经网络层和逐点乘法运算组成。
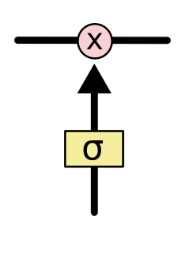
sigmoid 层输出介于 0 和 1 之间的数字,描述每个组件应通过多少信息。值为0表示“不让任何信息通过”,而值为1表示“让所有信息都通过“
LSTM 具有三个这样的门结构,用于保护和控制单元状态。
分步骤拆解LSTM
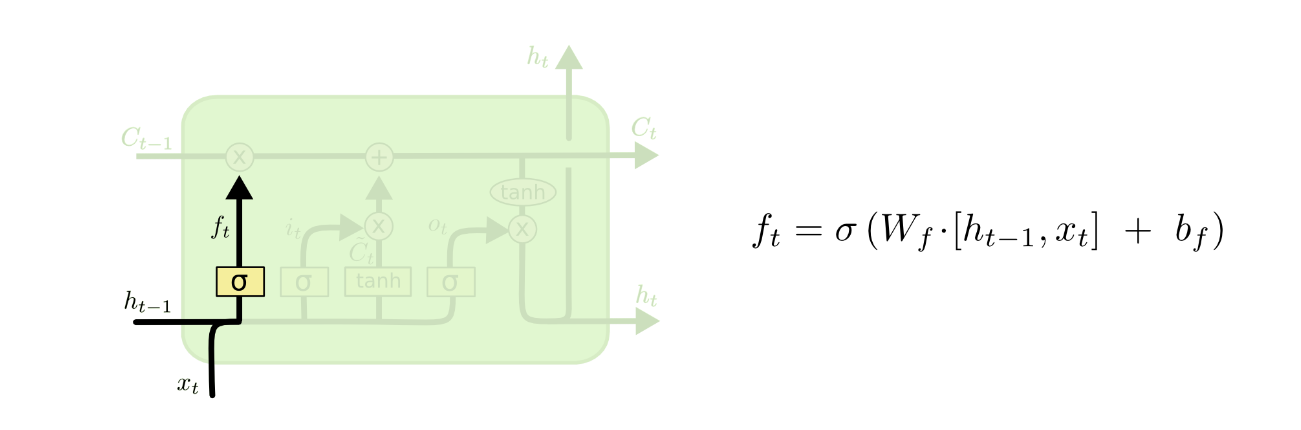
第一步
LSTM 的第一步是决定我们要从细胞状态中丢弃哪些信息。
这个决定是由一个称为“遗忘门层”的sigmoid层做出的。它查看前一个输出
h
t
−
1
h_{t−1}
ht−1 和当前输出
x
t
x_{t}
xt,并为细胞状态
C
t
−
1
C_{t−1}
Ct−1中的每个数字输出一个介于 0 和 1 之间的数字。1 表示“完全保留”,而 0 表示“完全丢弃”。
即,分量输入被sigmoid压缩,如果该分量压缩后输出为0,就完全抛弃,为1就全部接收。这样就可以达到”遗忘“不重要信息,记住重要信息的效果
第二步
第二步决定我们将在单元格状态中存储哪些新信息。
首先,称为“输入门层”的 sigmoid 层决定我们将更新哪些值。
接下来,tanh 层创建一个新的候选值
C
t
~
\widetilde{C_{t}}
Ct
的向量,可以将其添加到状态中。
在下一步中,我们将结合这两者来创建状态更新。
简单来说,这一步
用tanh函数层将现在的向量中的有效信息提取出来,然后使用sigmoid函数层来控制这些记忆要放“多少”进入单元状态
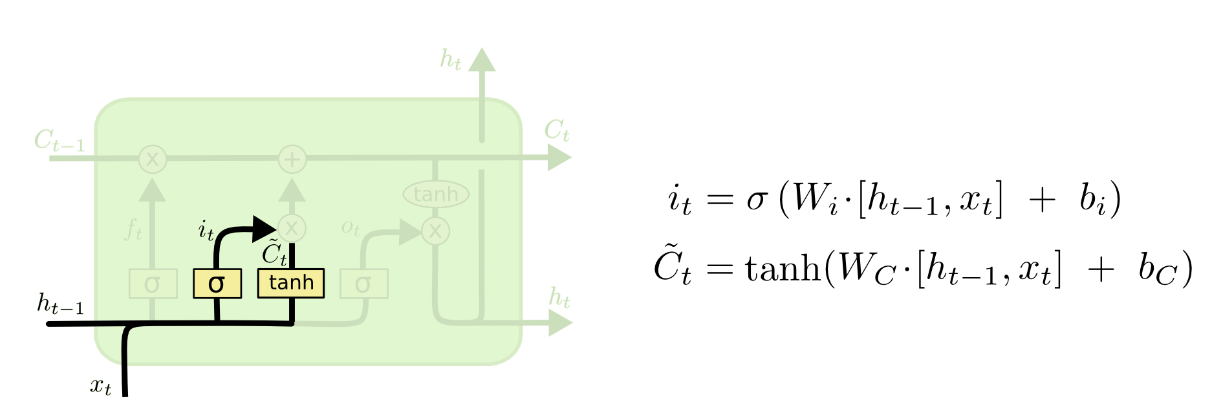
第三步
第三步是将旧的细胞状态
C
t
−
1
C_{t−1}
Ct−1更新为新的细胞状态
C
t
C_{t}
Ct。
我们将旧状态乘以
f
t
f_t
ft,忘记了我们之前决定忘记的信息。然后我们添加
i
t
∗
C
t
~
i_{t}∗\widetilde{C_{t}}
it∗Ct
。这是新的候选值,按我们决定更新每个状态值的程度进行缩放。
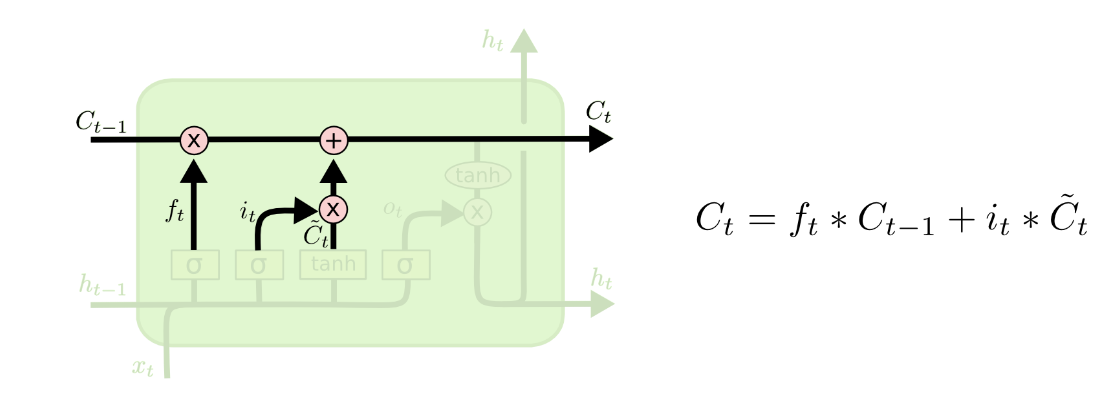
其实这一步就是将上述的一二步作用结合起来
第四步
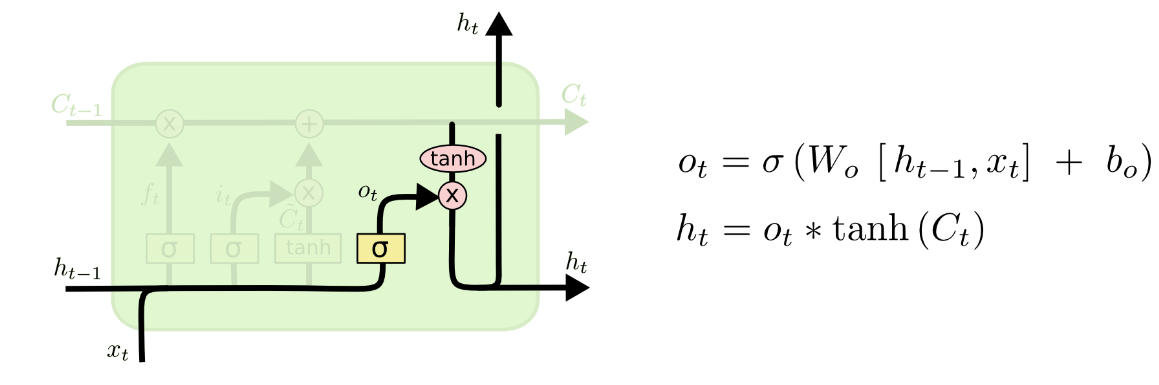
第四步,我们需要决定要输出什么。
首先,我们运行一个 sigmoid 层,它决定我们要输出细胞状态的哪些部分。
(输出层会先将当前输入值与上一时刻输出值整合后的向量用sigmoid函数提取其中的信息,即图中的
o
t
o_{t}
ot)
然后,我们将单元格状态通过tanh(将值推到−1和1之间)并将其乘以sigmoid门的输出,这样我们只输出我们决定的部分。
(将当前的单元状态通过tanh函数压缩,输出为
h
t
h_t
ht)
往期文章可以关注我的CSDN
也可以关注我的和鲸社区专栏
下巴同学的数据加油小站
会不定期分享数据挖掘、机器学习、风控模型、深度学习、NLP等方向的学习项目