
找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程程(ಥ_ಥ)-CSDN博客
所属专栏:JavaEE
前面我们学习多线程的经典案例之一:饿汉模式与懒汉模式。两者的区别是创建类的实例的时机不同,前者是迫不及待的去创建类的实例,而后者是迫不得已去创建类的实例。这样就导致了前者在 get 方法中只有"读"操作,不会造成线程安全问题,而后者会出现线程安全问题。最后经过我们的不断深入探索并解决了其中的问题。首先是进行加锁操作,避免了修改操作原子性,其次是加了 if 判断语句,避免了不必要的加锁,从而导致的性能下降,最后,针对指令重排序的问题,在引用变量中加上了 volatile 关键字。如果想更加深入了解,可以点击下面的链接:饿汉模式、懒汉模式、指令重排序等
阻塞队列
现在我们来学习另外一个经典的案例:阻塞队列。
阻塞队列是属于队列的一种,但是和普通的队列相比,它具有以下的特性:
1、它具备线程安全的特点,即使在多线程的环境下,也是可以正常使用的。
2、阻塞特性:1)当队列为空时,如果再去队列中取元素的话,会发生阻塞,直至队列不为
空;2)当队列满了时,如果再去队列中插入元素的话,也会发生阻塞,直至队列不为满。
生产者—消费者模型
阻塞队列的主要应用场景是:“生产者—消费者模型”。那什么是生产者,什么又是消费者呢?简单理解就是,生产者与消费者之间是通过某种资源进行来进行交互的。生产者,就是生产这个资源的,而消费者,就是消耗这个资源的。
例如,在我们日常中,最常见的就是包饺子,包饺子需要擀面皮的人、包饺子的人、放面皮的布。(肉已经被绞肉机给搞好了) 这里就是一个经典的"生产者一消费者模型"。
生产者:擀面皮的人、消费者:包饺子的人、阻塞队列:放面皮的布。这里生产者与消费者进行交互的就是"面皮"这种资源。
我们在日常生活中,有两种包饺子的方式:
1、家里面几个人全部一起参与包饺子的全过程。即每个人都需要 擀面皮、包饺子。而擀面杖只有一个,那么当一个人在进行擀面皮时,另外几个人都得阻塞等待,当这个人把面皮给擀完之后,才会释放,这样下一个人才有机会去使用。这个擀面杖就是我们前面学习的锁。
上面的方式,我们会发现一个很大的缺陷:当其中一个人在生产面皮时,其余的人得阻塞等待,也就是有空闲时间。这对于计算机来说,简直就是浪费,因此下面这种方式更为合理。
2、一个人专门擀面皮,另外的人负责包饺子,这样就不会导致生产者或者消费者会出现空闲的情况(生产速度与消费速度是一致的)。
生产者—消费者模型的优势:
1、解耦合:
生产者与消费者避免了直接交互,而是通过阻塞队列来进行交互,这样有利于代码的解耦合,使得后期的维护成本变低。
2、削峰填谷:
当 生产者—消费者模型 应用于两个服务器时,就可以达到削峰填谷的效果。
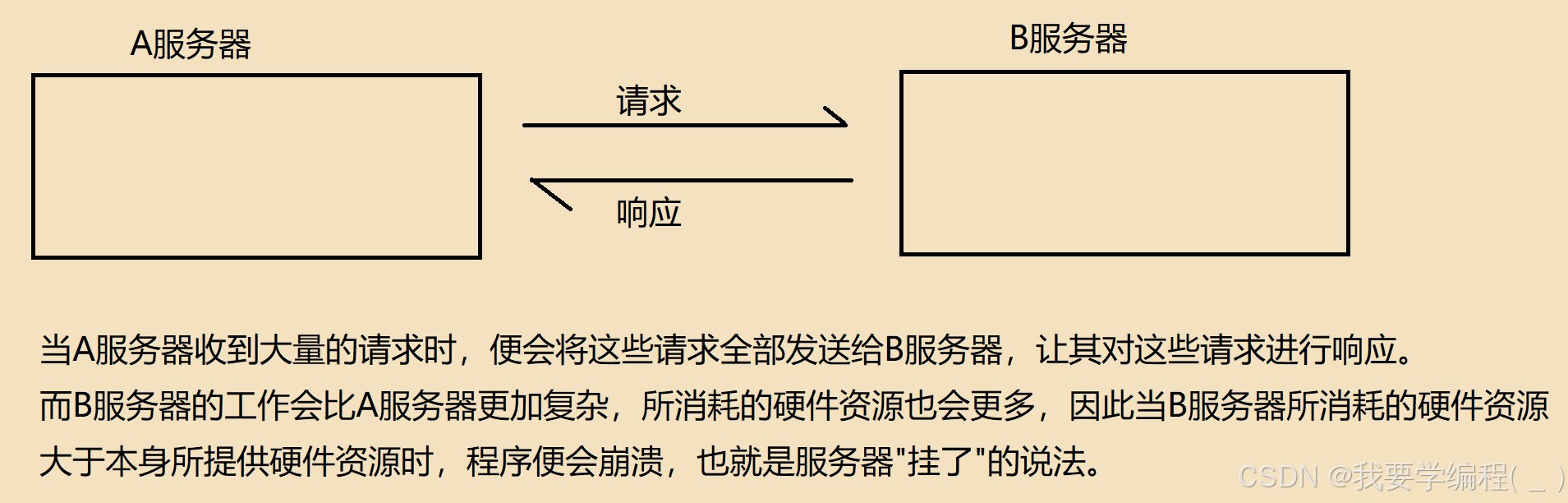
因此为了避免上述的情况,我们需要对用一个阻塞队列来处理这种"突然的大量请求的情况"。例如,学校选课的时候,通常就会出现这样的情况。
解决方法:使用一个阻塞队列来充当缓冲的作用。当A服务器突然接收到有大量的请求时,这个阻塞队列便会接收这些请求,但是还是以平常的速度给到B服务器,这样B服务器还是会正常运行,这就是 “削峰”。当这个峰值过去之后,就是平常少量的请求,而阻塞队列这时候就会来处理在高峰期接收的请求,这样B服务器还是以平常的速度在处理请求,这就是"填谷"。阻塞队列通过降低高峰期的发送请求,而是在低谷期来处理,这样B服务器就是以一个平均的速度在处理请求。
注意:
1、阻塞队列通常可以接收并存放很多的请求。
2、高峰期比较短,所以阻塞队列一般不会出现满的情况。
生产者—消费者模型的劣势:
1、引入阻塞队列之后,整体的结构相交以前更为复杂了,同时也需要更多的机器进行部署,使生产环境的结构更复杂,同时管理起来也更为麻烦了。
2、效率也有一定的影响。之前是A服务器和B服务器直接进行交互,现在多了个阻塞队列,消息的传递所消耗的时间也变多了。
Java标准库中的阻塞队列:
Java的标准库中提供的阻塞队列是:BlockingQueue。
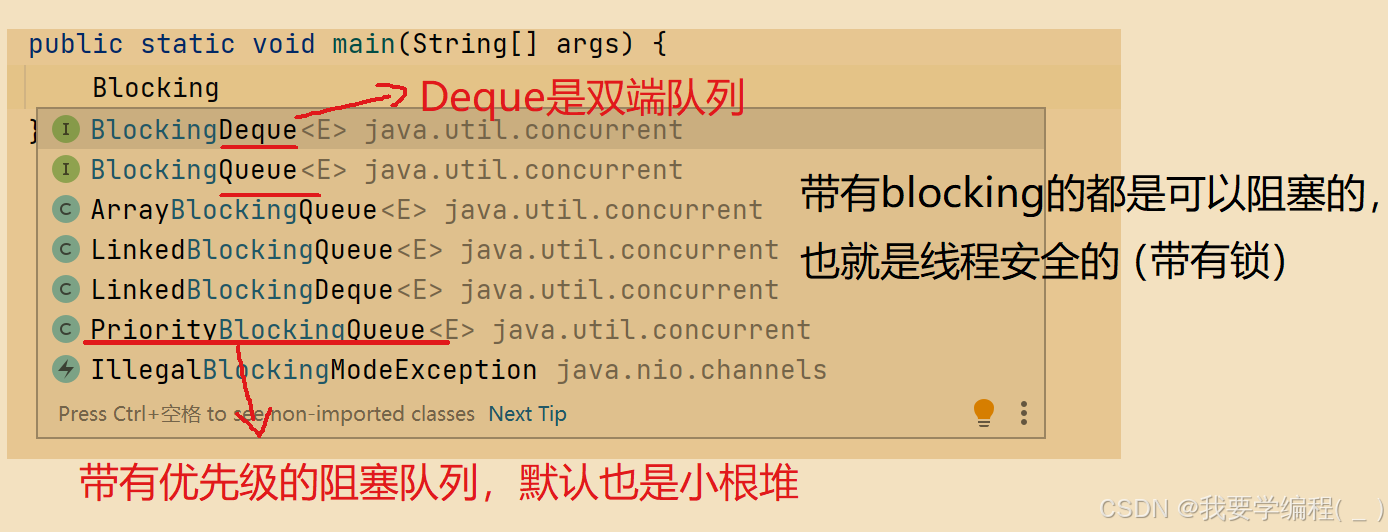
我们在日常的开发中,主要就是使用:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue。下面是使用的示例:

public class Test {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(100);
// 在多线程中,队列的插入方法要用put。因为其带有阻塞功能,且线程安全
queue.put(1);
queue.put(2);
queue.put(3);
queue.put(4);
// 同样多线程中的删除也要用take
int n = queue.size();
for (int i = 0; i < n; i++) {
System.out.print(queue.take()+" "); // 1 2 3 4
}
}
}
我们现在可以去看一下阻塞功能。
public class Test {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(1);
// 在队列为空的情况下,尝试去取元素
System.out.println(queue.take()); // 由于是单线程,因此会一直阻塞,即死等。
queue.put(1);
// 在队列为满足,尝试去插入新元素
queue.put(2);
}
}
同样下面去尝试插入新元素时,也是会发生阻塞等待的,也是死等的情况。
public class Test {
public static void main(String[] args) {
int n = 1;
System.out.println("队列的总容量:"+n);
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(n);
System.out.println("队列此时的容量:"+queue.size());
Thread t1 = new Thread(()-> {
try {
System.out.println("阻塞队列为空,尝试取出元素,等待其他的线程插入元素");
queue.take();
System.out.println("成功取出元素~");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Thread t2 = new Thread(()->{
try {
for (int i = 0; i < 3; i++) {
Thread.sleep(1000); // 确保t1线程先执行到take方法,并放慢让我们观察
System.out.println("正在尝试插入第" + (i + 1) + "个元素");
queue.put(i);
System.out.println("插入成功~");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
t1.start();
t2.start();
}
}
运行结果:

模拟实现阻塞队列:
要求:我们主要是实现队列的 put方法、take方法、size方法即可。
思路:put、take方法都需要保证线程安全和阻塞的特性。
线程安全,我们直接对代码进行加锁操作即可;
阻塞特性:当队列为满时,要阻塞到其他线程使用掉其中的对头元素,即得等待其他线程调用take方法来唤醒当前因队列满而造成的阻塞,这也就需要用到我们前面学习的wait 和 notify 方法。
阻塞队列代码:
public class MyBlockingQueue {
// 基于数组去模拟实现
private static int[] array = null;
private static int usedSize = 0; // 元素个数
private int head = 0; // 头指针
private int tail = 0; // 尾指针
public MyBlockingQueue() {
array = new int[10];
}
public MyBlockingQueue(int capacity) {
if (capacity < 0) {
throw new RuntimeException();
} else if (capacity >= Integer.MAX_VALUE) {
array = new int[Integer.MAX_VALUE];
} else {
array = new int[capacity];
}
}
// put方法
public void put(int x) throws InterruptedException {
synchronized (this) { // 保证线程安全
while (usedSize >= array.length) { // 满足阻塞队列的特性
// 阻塞等待
this.wait(); // 等待其他线程取出元素,使队列不为满
}
array[tail] = x;
tail = (tail+1) % array.length; // 这里是采用循环队列的方式
usedSize++;
this.notify(); // 唤醒空的阻塞
}
}
public int take() throws InterruptedException {
synchronized (this) { // 保证线程安全
while (usedSize <= 0) { // 满足阻塞队列的特性
// 阻塞等待
this.wait(); // 等待其他线程插入元素,使队列不为空
}
int ans = array[head];
head = (head+1) % array.length;
usedSize--;
this.notify(); // 唤醒满的阻塞
return ans;
}
}
public int size() {
return usedSize;
}
}
测试代码:
public class Test {
public static void main(String[] args) throws InterruptedException {
int n = 1;
MyBlockingQueue queue = new MyBlockingQueue(n);
System.out.println("队列的总容量为:"+n);
System.out.println("队列当前的容量为:"+queue.size());
Thread t1 = new Thread(()->{
try {
Thread.sleep(500);
System.out.println("队列为空,阻塞等待别的线程插入数据");
queue.take();
System.out.println("取出元素~");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 3; i++) {
try {
Thread.sleep(1000);
System.out.println("正在尝试插入第"+(i+1)+"个元素");
queue.put(i);
System.out.println("插入成功~");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
t2.start();
}
}
运行结果:

注意:
1、我们使用加锁操作,是为了避免出现下面这种情况:一个线程在修改,另一个线程在读取,把数据修改之后,可能会造成另一个线程执行有误,因此我们得对代码进行加锁操作,是同一时刻只能有一个线程去进行修改操作(读取操作是不会影响数据的),因此对于修改操作的代码,都得处于 synchronized 代码块中,而上述 put、take 方法的大部分代码都是修改操作,因此我们就将整个代码逻辑都置于 synchronized 代码块中了。
2、put、take 方法中之所以将判断阻塞的条件放到 while 循环中,是因为可能会出现下面这样的情况:有三个线程都是处于put方法的阻塞状态,而这时新来了一个执行take方法的线程,其会随机唤醒三个线程中的一个,当三个线程中,某个线程执行完 notify 方法之后,也会随机唤醒剩下的两个线程,但是此时这个唤醒操作不符合要求,因为我们是希望将处于take方法的阻塞线程所唤醒,因此这个是错误唤醒,所以我们要用 while 循环去再次线程判断到底是不是因为正常唤醒而被唤醒的。
好啦!本期 初始JavaEE篇——多线程(4):生产者-消费者模型、阻塞队列 的学习之旅 就到此结束啦!