一、GET请求
1.HTTP GET 请求:
1.GET 请求是 HTTP 协议中的一种方法,用于从服务器请求数据。
通过 GET 请求,可以向服务器发送参数,通常附加在 URL 中的查询字符串中。
2.GET 请求通常用于获取(而不是修改)资源,比如获取网页内容、图片、API 数据等。
使用爬虫进行GET请求的流程。
2.选择合适的爬虫工具或库:
Python 中常用的爬虫库包括 requests、urllib 等。
这些库可以帮助构造和发送 HTTP 请求,并处理响应。
3.构造URL:
1.确定要访问的目标网页的 URL。到你需要的网页点击发发f12即可进入开发者模式,进入网络页面点击禁用,刷新页面,找到网络的第一个,点击找到url就是我们需要的url
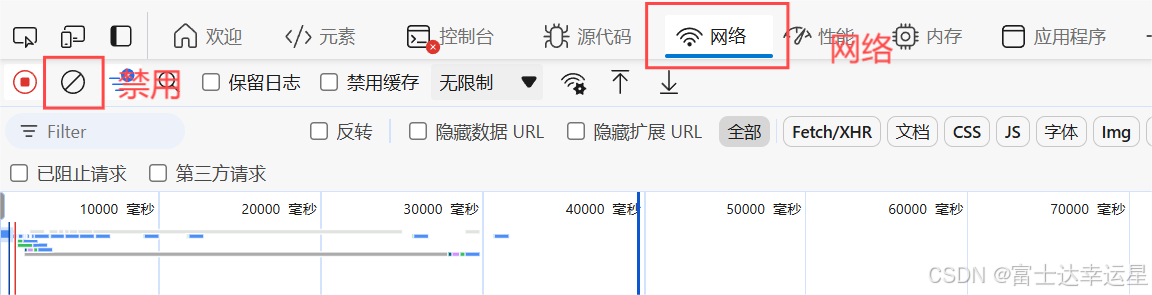
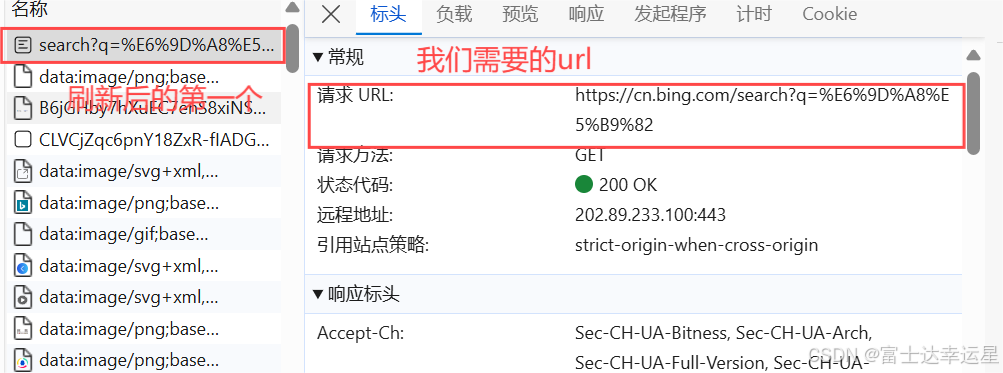
通常我们不能直接去访问页面,所以我们需要一个伪装,也就是UA伪装(url页面向下找即可找到)

如果需要,可以向 URL 添加查询参数,这些参数通常用来指定请求的具体内容或过滤条件。
发送GET请求:
2.使用选定的爬虫库发送 GET 请求到目标 URL。
如果有参数,将参数包含在请求中。
4.处理响应:
获取服务器返回的响应,通常是 HTML 页面或者其他格式的数据。
根据需要,可以从响应中提取出所需的信息,比如解析 HTML、提取特定标签内容或者处理 JSON 数据。
5.处理可能的异常情况:
考虑到网络延迟、服务器错误或其他异常情况,适当处理可能出现的异常。
实例:
import requests
head={
"User-Agent":"exampleuseragent"
}
# 定义目标URL和可能的查询参数
url = 'http://example.com/data'
# 发送GET请求
response = requests.get(url, headers=head)
data = response.json() # 假设响应是JSON格式
#检查是否爬取成功
print(data)注意事项
- 法律和伦理问题:在进行网络爬虫时,要遵守网站的使用条款和法律法规,以避免侵犯隐私或者版权问题。
- 频率控制:爬取数据时要注意不要对目标网站造成过大的负载,可以控制爬虫的访问频率,避免被封IP或其他限制措施。
总之,爬虫和 GET 请求是网页数据获取的基础工具,在合适的情况下使用它们可以帮助自动化数据收集和分析任务。