论文来源:WWW 2022
论文地址:https://arxiv.org/pdf/2201.11332.pdf
论文代码:暂未公开
笔记仅供参考,撰写不易,请勿恶意转载抄袭!
Abstract
小样本学习旨在基于有限数量的样本就行预测。结构化数据(如知识图谱、本体库)已被用于少样本设置的各种任务。但是现有方法采用的先验存在知识缺失、知识噪声和知识异质性等问题,影响了小样本学习的性能。在本研究中,我们探索了基于预训练语言模型的小样本学习知识注入,并提出本体增强的提示优化。具体而言,本文开发了基于外部知识图谱的本体转换来解决知识缺失问题,实现了结构化知识向文本的转换。本文进一步通过可见矩阵引入跨度敏感知识注入,以选择信息性知识来处理知识噪声问题。为了弥补知识和文本之间的差距,本文提出了一种集体训练算法来联合优化表示。
Introduction
在过去几年中,FSL已被引入到广泛的机器学习任务中,如关系抽取、事件抽取和知识图谱补全等。(Over the past few years, FSL has been introduced in a wide range of machine learning tasks, such as relation extraction, event extraction and knowledge graph completion.)但是,FSL存在以下问题:
- 知识缺失 由于外部知识库的不完整性,知识注入可能无法检索与任务相关的事实,从而为下游任务提供无用或者不相关的信息。如何丰富与任务相关的知识是一个重要问题。
- 知识噪声 先前的研究表明,并不是所有的知识都对下游任务有益,不加区分的知识注入可能会导致负面信息注入,影响下游任务执行。因此上下文敏感和任务的知识选择对于知识增强学习至关重要。
- 知识异质性 下游任务的语料库与注入的知识截然不同,导致两个单独的向量表示。如何设计一个特殊融合知识信息的联合训练目标是另一个挑战。
针对上述问题所提出的策略:
- 提出了本体转换来丰富和转换结构化知识到文本形式。(简单来说,就是将实体等信息作为提示,加入到输入文本中,弥补知识缺失问题)
具体而言,本文使用预定义的模板将知识转换为文本作为提示。提示调优可以减少预训练模型任务和下游任务之间的差距。例如,“Turing entered King’s College, Cambridge in 1931, and then went to Princeton University to study for a doctorate(图灵1931年进入剑桥国王学院,然后去普林斯顿大学攻读博士学位)”,可以根据本体将他们包装成“s. Turing [MASK] King's College”,PLMs应该预测掩码位置的标签来确定输入的标签。需要注意的是,本体作为提示将实体/跨度的知识加入到输入文本中,这是与模型无关的,即可以插入任何类型的PLMs中。 - 提出跨度敏感知识注入,以选择信息化知识并减轻噪声注入。(也就是要避免不相关和噪声知识对模型产生影响)
利用一个基于跨度及相应的外部知识的可视矩阵来指导知识注入,这样,并非输入句子中所有token 都会受到外部知识的影响。 - 提出一种联合优化表示的集体训练算法。
注意,注入的外部知识应与上下文相关联;我们通过随机初始化添加了一些可学习的token,并对这些token和注入的token进行优化。由于,在低数据状态下提示调优是不稳定的,可能会获得较差的性能,我们进一步优化所有参数以集体训练本体文本和输入文本表示。
Methodology
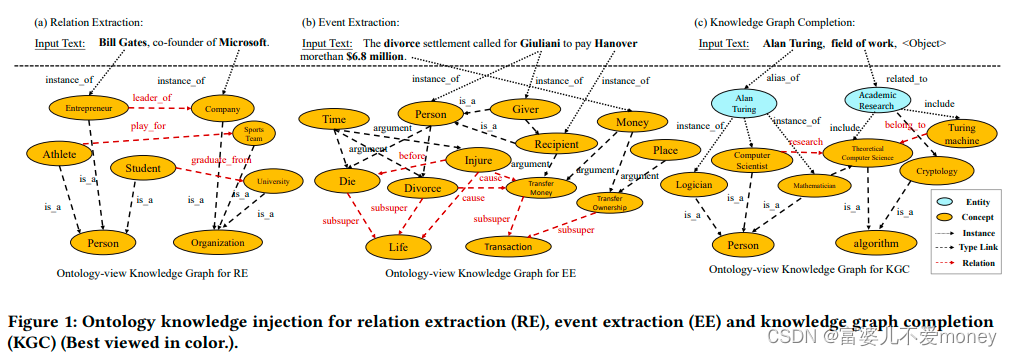
OntoPrompt是一个通用框架,可以应用于多种任务,如Figure 2所示。本文在关系抽取、事件抽取和知识图谱补全任务上评估我们的模型。
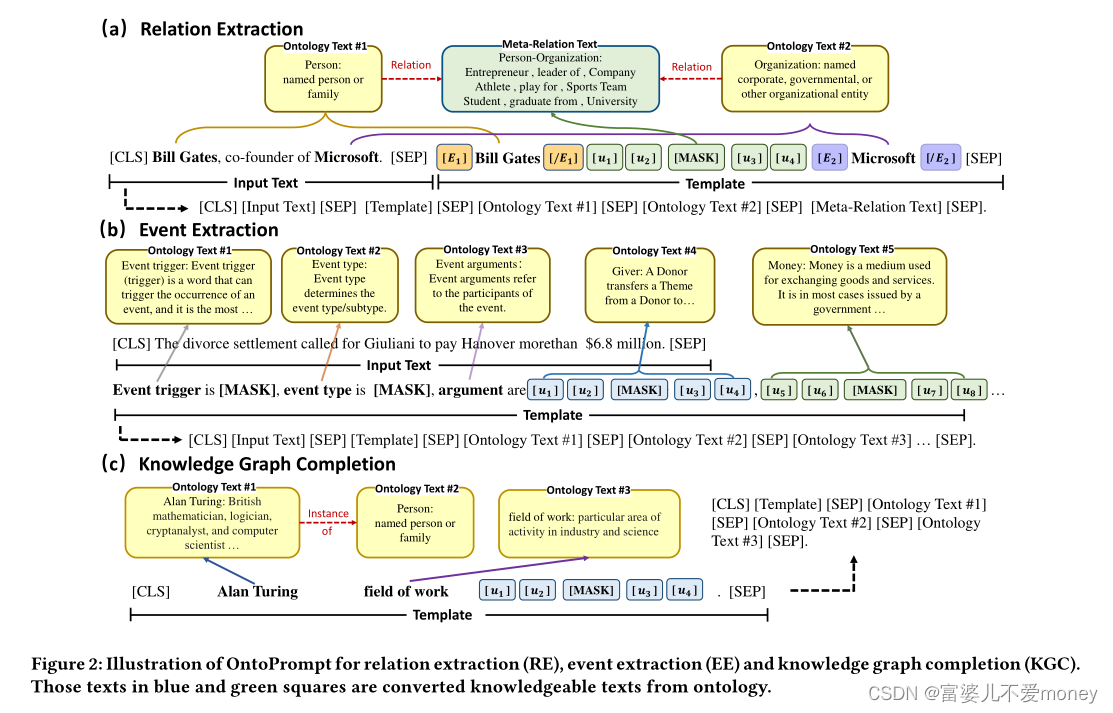
General Framework with Prompt-Tuning
输入为句子与模板的拼接:![X_{prompt}=[CLS]X_{in}[SEP]T[SEP]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9YXyU3QnByb21wdCU3RCUzRCU1QkNMUyU1RFhfJTdCaW4lN0QlNUJTRVAlNURUJTVCU0VQJTVE)
![p(y|X_{prompt})=\sum_{w\in v_y}^{}p([MASK]=w|X_{prompt})](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9wJTI4eSU3Q1hfJTdCcHJvbXB0JTdEJTI5JTNEJTVDc3VtXyU3QnclNUNpbiUyMHZfeSU3RCU1RSU3QiU3RHAlMjglNUJNQVNLJTVEJTNEdyU3Q1hfJTdCcHJvbXB0JTdEJTI5)
Ontology Transformation
在本文中,将本体表示为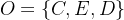
- 应用于关系抽取
利用MUC来定义命名实体的概念。注意,命名实体可以提供重要的类型信息,这有利于RE。然后将这些定义用作本体模式中的文本描述,即将“[CLS] <InputText> [SEP] <Template> [SEP] <OntologyText> [SEP]”作为最终的输入序列。本文为<OntologyText>中的实体构造占位符,并用外部文本描述来替换这些占位符,并利用来自本体的实体对之间的路径作为元关系文本来增强<OntologyText>。
并将可学习的tokens,[u1]-[u4],作为虚拟tokens添加到[MASK]的两边,使模型自动学习最合适的单词作为提示。 - 应用于事件抽取
构建了一个更大的事件本体,同样将“[CLS] <InputText> [SEP] <Template> [SEP] <OntologyText> [SEP]”作为最终的输入序列,为触发词构造占位符并在<OntologyText>中输入。 - 应用于知识图谱补全
外部Wikidata作为本体源,并提取文本描述。将知识图谱补全视为三元组分类任务,并链接实体和关系作为输入序列。与上述任务相同,将“[CLS] <InputText> [SEP] <Template> [SEP] <OntologyText> [SEP]”作为默认输入序列。
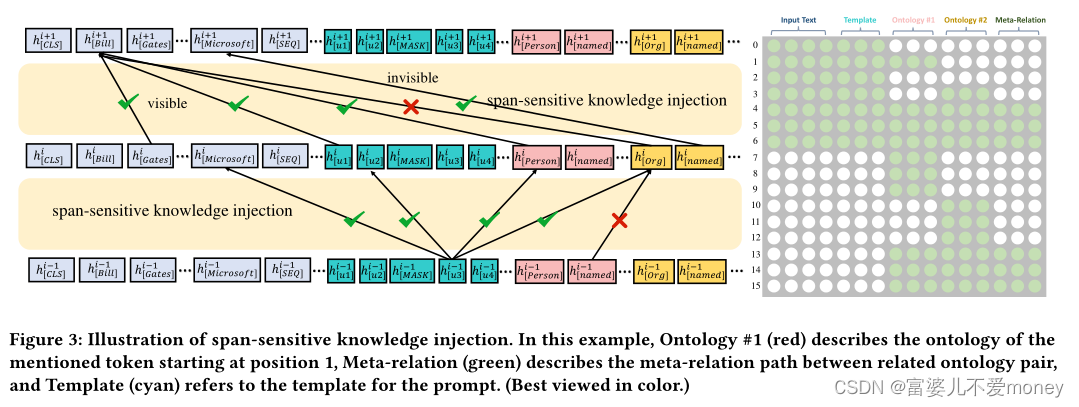
Span-sensitive Knowledge Injection
跨度敏感知识注入如Figure 3所示。使用一个可见矩阵来限制知识输入付输入文本的影响。在语言模型架构中,在softmax之前添加了一个具有自注意力权重的注意力掩码矩阵。注意力掩码矩阵如下:
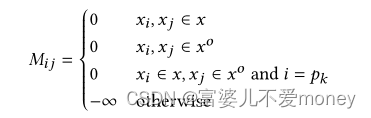
以下情况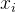
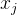
Collective Training
首先,使用使用实词嵌入来初始化本体token,并使用固定的语言模型进行优化,然后优化了模型的所有参数,包括语言模型和本体token。
Experiments
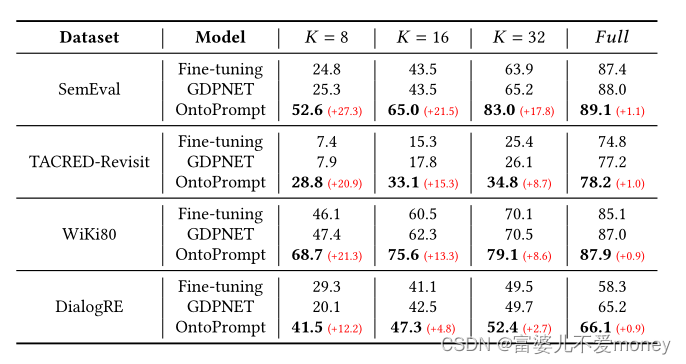
RE:
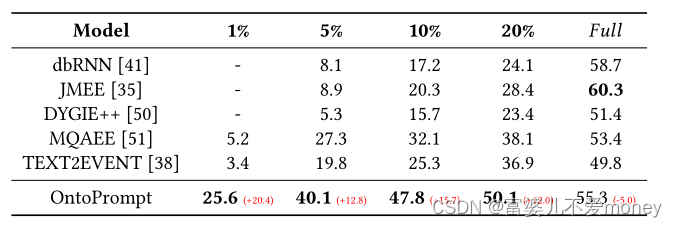
EE:
KGC: