注意:
当前本文有一个重要的待论证问题,本文中Dijkstra堆优化的代码的正确性有待考证,请不要直接复制其代码,否则版主概不负责。如果有人能严谨地证明这种方法的正确性或错误性,请在下方评论,不胜感激。【2017.8.31】
我的图论学得一直不怎么样,所以今天决定写一发关于最短路的几种算法。
几种常用的最短路算法
首先,先说一个最好理解的,但也是时间效率最低的。
1.Floyed-Warshall(弗洛伊德)
弗洛伊德算法做的工作就是枚举“中间点”。如果我们用dis[i][j]来表示结点i到结点j之间的最小距离,那么就有这个式子:
dis[i][j]=min(dis[i][k]+dis[k][j]) (i、j之间无边相连)
dis[i][j]=min(w[i][j],dis[i][k]+dis[k][j]) (i、j之间有一条边权为w[i][j]的边相连)
所以,我们可以先把dis数组初始化成INF,然后如果ij之间有边那就让dis[i][j]=min(dis[i][j],w[i][j])。然后再用三层循环,分别枚举中间点、起点和终点,就可以实现了。
Floyed算法可以求出任意两点之间的最短路,时间复杂度O(n^3)。
#include<cstdio>
const int MAXN=467,INF=0x7fffffff;
int dis[MAXN][MAXN];
int min(int a,int b){return a<b?a:b;}
int main()
{
int n,m;scanf("%d%d",&n,&m);
//n->nodeCnt m->edgeCnt
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
if(i==j)dis[i][j]=0;
else dis[i][j]=INF/3;
for(int i=1;i<=m;i++)//input edge
{
int from,to,cost;
scanf("%d%d%d",&from,&to,&cost);
dis[from][to]=min(dis[from][to],cost);
dis[to][from]=dis[from][to];
}
for(int k=1;k<=n;k++)//Floyed
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
dis[i][j]=min(dis[i][j],dis[i][k]+dis[k][j]);
for(int i=1;i<=n;i++)//output
{
for(int j=1;j<=n;j++)
printf("dis[%d][%d]=%d ",i,j,dis[i][j]);
printf("\n");
}
return 0;
}注:上文中之所以要用INF/3而不是INF,是因为计算dis[i][k]+dis[k][j]时可能会出现“溢出”的情况导致它们的加和甚至变成了一个很小的负数。因为INF/3仍是一个很大的数,而且能保证比任何一条边的权值要大得多,所以在一些问题中也是可以接受的。
需要注意的一点是:外层循环必须枚举中转点k,而不能枚举起始点或终止点。就比如,如果最内层枚举中转点,对于一个确定的i和j,我们每一次用所有的k去更新它们的dis值,但是我们不能保证dis[i][k]和dis[k][j]在此之前已经被更新成了正确的值。
另外Floyed算法还可以用来判断任意两点的连通性:如果我们用dis[i][j]=0表示i和j不连通,dis[i][j]=1表示这两点连通那么就有:
dis[i][j]=dis[i][j] || (dis[i][k] && dis[k][j])
代码编写方式同上文。
【2017.8.31 关于弗洛伊德求最小环】
这种方法可能和在其他地方看到的不太一样,正确性有待验证。
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<algorithm>
#include<vector>
#include<queue>
using namespace std;
const int maxn=500+1,INF=0x3f3f3f3f;
struct Floyed{
int dist[maxn][maxn],n;
void init(int n){
this->n=n;
for(int i=1;i<=n;i++)//clear edge
for(int j=1;j<=n;j++)
dist[i][j]=INF;
}
void addedge(int f,int t,int c){
dist[f][t]=min(dist[f][t],c);
}
int mincircle(){
for(int k=1;k<=n;k++)
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
dist[i][j]=min(dist[i][j],dist[i][k]+dist[k][j]);
int ans=INF;
for(int i=1;i<=n;i++)
ans=min(ans,dist[i][i]);
return ans==INF?-1:ans;
}
}floyed;
int main(){
int n,m;scanf("%d%d",&n,&m);//nodeCnt edgeCnt
floyed.init(n);//init
for(int i=1;i<=m;i++){//input edge
int f,t,c;scanf("%d%d%d",&f,&t,&c);
floyed.addedge(f,t,c);
}
int mc=floyed.mincircle();
printf("%d\n",mc);
return 0;
}
原理就是令dist[i][i]=INF,这样的话在被更新之后dist[i][i]的值就会被更新为从i出发并回到i所需走过的最小代价,上文代码针对有向图(无向图只需要插入两条边就好了)。
2.Dijkstra(迪杰斯特拉)
迪杰斯特拉算法是一种O(n^2)求解单源最短路的算法,要说它的原理,那就得从BFS说起。
如果图中所有的边权都为1,那么要求单源最短路,就只需要BFS一次就好了,这个BFS的“搜索树”便是一棵“最短路树”。因为所有的边权都为1,所以相邻的点一定是最近的,与相邻的点相邻的点就是“次近”的,所以一个点在BFS中第一次出现时的层次就是它到起点的最短路长度。
迪杰斯特拉就是把BFS拓展到了边权不为1的情况,令dis[u]表示当前求出的u到起点的最短路长度,vis[u]表示u的最短路是否已经被确定。这样我们可以每次找到vis[u]=0的点中dis[u]最小的,把它的vis设成1,并且用它去更新与它相邻的所有点的dis值。因此每次循环可以确定出一个点最短距离,只需要n次循环就可以完成求解。
而为什么dis[u]最小那么它地最短路就是确定的呢?因为根据上文弗洛伊德中的论述,有这样的一个式子:
dis[u]=min(dis[u],dis[v]+w[u][v]) (u、v之间有一条边)
当边权w[u][v]>0时,如果dis[u]是最小的,则有dis[u]<=dis[v]。又因为w[u][v]>0,所以dis[u] < dis[v]+w[u][v]。也就是说这时dis[u]不可能被再次更新,即这个点的最短路已经被确定。
而这个性质成立的条件就是w[u][v]>=0,当图中的所有边权都非负的时候Dijkstra算法才是可行的。
同时,我们还可以定义一个pre数组,pre[u]表示在“最短路树”中,u结点的前驱结点,只需要在每次更新dis[u]的时候顺便更新一下pre[u]就可以了。下文代码中对图的储存采用了“前向星”的方法,这使得这个算法的时间复杂度严格小于O(n^2),只有最坏情况——任意两点之间都有边相连才能达到O(n^2)。
#include<cstdio>
const int MAXN=10001,nil=0,INF=0x7fffffff;
#define prompt if(0)
int from[MAXN*MAXN+MAXN],to[MAXN*MAXN+MAXN],edgeCnt=0;
int fstEdge[MAXN],nxt[MAXN*MAXN+MAXN],cost[MAXN*MAXN+MAXN];
int dis[MAXN],pre[MAXN],vis[MAXN];
void AddEdge(int From,int To,int Cost)
{
int edgeNum=++edgeCnt;
cost[edgeNum]=Cost;
from[edgeNum]=From;to[edgeNum]=To;
nxt[edgeNum]=fstEdge[From];
fstEdge[From]=edgeNum;
}
void print(int nodeNum)
{
printf("%d:",nodeNum);
if(dis[nodeNum]==INF)
{
printf("no solution!\n");
return;
}
printf("[%d]\t",dis[nodeNum]);
for(int i=nodeNum;i!=nil;i=pre[i])
if(i!=1)printf("%d -> ",i);
else printf("%d",i);
printf("\n");
}
int main()
{
freopen("dijkstra.in","r",stdin);
freopen("dijkstra.out","w",stdout);
int n,m;//n:nodeCnt,m:edgeCnt
prompt printf("input nodeCnt,edgeCnt:");
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)//input edges
{
int f,t,c;//from,to,cost
prompt printf("input edge[%d] from,to,cost:",i);
scanf("%d%d%d",&f,&t,&c);
AddEdge(f,t,c);AddEdge(t,f,c);
}
for(int i=2;i<=n;i++)//clr dis
dis[i]=INF;
for(int q=1;q<=n;q++)
{
int minNode,minDis=INF;
for(int i=1;i<=n;i++)
if(!vis[i] && dis[i]<minDis)
{
minDis=dis[i];minNode=i;
}
vis[minNode]=1;//visited
for(int i=fstEdge[minNode];i!=nil;i=nxt[i])
{
if(dis[to[i]]>dis[minNode]+cost[i])
{
pre[to[i]]=minNode;
dis[to[i]]=dis[minNode]+cost[i];
}
}//updata dis[1..MAXN]
}
prompt printf("Search Start at node[1]:\n");
for(int i=2;i<=n;i++)
print(i);
return 0;
}“前向星”就是利用类似链表的方法记录每一个结点的每一条出边,这样在修改这个结点的所有后继结点时就不用一直循环到n,判断这两点是否相连。这种储存方式相比于邻接表来说更节省空间,而且在时间上也毫不逊色。(邻接矩阵这种“垃圾”储存方式,除了数据范围特别小的时候用着很爽,写着很方便以外。其他情况下尽量不要用。)
我们可以定义一个fst数组,fst[i]表示i的“第一条”出边的编号。再定义一个nxt数组,nxt[e]表示边e的“下一条边”的编号,其中边nxt[e]和边e一定有着相同的from结点。
void AddEdge(int From,int To,int Cost)
{
int edgeNum=++edgeCnt;
cost[edgeNum]=Cost;
from[edgeNum]=From;to[edgeNum]=To;
nxt[edgeNum]=fstEdge[From];
fstEdge[From]=edgeNum;
}以上代码是在“前向星”图中加一条有向边的操作,我们让当前边的nxt为原来的from结点的fst,再让from结点的fst=当前边就可以了。“前向星”就是给每一条边一个“指针”,让它指向在插入它之前最后一个被插入到from上的出边。这样当我要访问某一个结点的所有出边时,只需要用一个for循环就可以了:
for(int i=fstEdge[minNode];i!=nil;i=nxt[i])
{
if(dis[to[i]]>dis[minNode]+cost[i])
{
pre[to[i]]=minNode;
dis[to[i]]=dis[minNode]+cost[i];
}
}//updata dis[1..MAXN]因为最开始的时候fst数组被初始化成了0,所以当我沿着nxt指针走,一直走到了0的时候,说明所有的出边都已经被访问过了。(我的代码中的nil是一个整数常数=0,定义见前文。)
3.SPFA
比起dijkstra,SPFA更像是一个BFS。SPFA的算法思想就是利用一个队列储存待处理的点,每一次弹出队首,用这个元素去更新它的所有后继结点的pre和dis。如果这个后继结点被更新,而且它还不在这个队列中,就把它加入到这个队列中。当这个队列被弹空,即没有结点可以被继续更新,也就是所有的最短路已经被求出了,这时就可以退出循环。
#include<cstdio>
#include<queue>
using namespace std;
#define prompt if(0)
const int MAXN=10001,MAXM=MAXN*MAXN+MAXN,NIL=0,INF=0x7fffffff;
int from[MAXM],to[MAXM],cost[MAXM],nxt[MAXM],ecnt=0;
int dis[MAXN],pre[MAXN],fste[MAXN];
bool exist[MAXN];
void addedge(int f,int t,int c)
{
int ne=++ecnt;
from[ne]=f;to[ne]=t;cost[ne]=c;
nxt[ne]=fste[from[ne]];
fste[from[ne]]=ne;
}
void print(int n)
{
printf("[%d]->",n);
n=pre[n];
while(n!=1 && n!=0)
{
printf("%d->",n);
n=pre[n];
}
if(n) printf("%d\n",n);
else printf("no answer!\n",n);
}
queue<int>que;
int main()
{
freopen("SPFA.in","r",stdin);
freopen("SPFA.out","w",stdout);
prompt printf("input nodeCnt & edgeCnt:");
int n,m;scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
prompt printf("input edge [%d] form to cost:",i);
int f,t,c;scanf("%d%d%d",&f,&t,&c);
addedge(f,t,c);addedge(t,f,c);
}
for(int i=2;i<=n;i++)dis[i]=INF;
exist[1]=1;que.push(1);
while(!que.empty())
{
int nw=que.front();que.pop();
exist[nw]=0;
for(int i=fste[nw];i!=NIL;i=nxt[i])
if(dis[to[i]]>dis[nw]+cost[i])
{
dis[to[i]]=dis[nw]+cost[i];
pre[to[i]]=nw;
if(!exist[to[i]])
{
que.push(to[i]);
exist[to[i]]=1;
}
}
}
for(int i=2;i<=n;i++)
print(i);
return 0;
}
4.Dijkstra的堆优化(HeapDijkstra)
注意:
本文中的迪杰斯特拉堆优化算法可能存在一定问题,请不要直接复制,谢谢合作。
迪杰斯特拉算法中有一个重要的过程,那就是找到当前没被访问过的点中dis最小的一个。这个过程如果用以个循环来做可能是有点浪费时间的。我们可以尝试着用一个堆去维护dis值和点的编号,每次堆中弹出dis值最小的一个,可以省时间。
(但是我觉得时间复杂度并不是O(nlogn),而只能是O(nlogn)到O(n^2)之间的一个值,但还是相对接近于O(nlogn)的,可能是我对这个算法的理解有一些问题。)
【2017.8.29注】
2017.8.29 NEYC 联训时,请教了主讲FZW大神。
Dijkstra对于稀疏图的优化效果显著。我的理解是:假设一个结点的出边不超过logN级,那么这个算法使用“前向星”,或vector邻接表之类的,时间复杂度可以得到保证。
【2017.8.29 对算法重点的重新声明】
堆优化的时候,我们只需要把每次被更新的点插入到堆中,并维护堆的性质。每次只弹出dis值最小元素,不仅不对堆中的其他元素进行修改,而且会直接忽略那些没被使用的结点。这个算法的正确性是很显然的:因为每次弹出的最小元素一定是在上一次循环中被修改的某一个点,而不可能是更之前的循环修改的。而我每次弹出的只是最小的,与次小无关。(这里写得可能不是很好,等待以后有机会具体解释。)
我们最开始先把起点以及他的dis=0入队,然后每次从堆中弹出一个dis值最小的,去更新它所有后继结点的dis和pre。如果一个结点的dis被更新,那么就把这个点也加到堆中。然后循环n次就能得到单源最短路的解。这里的堆可以用STL的优先队列实现,只需要自己定义一个比较函数就好了(下文中重载了小于号);
#include<cstdio>
#include<queue>
using namespace std;
struct node{int dis,to;};
bool operator<(node A,node B)//重载小于号
{
return A.dis>B.dis;//小根堆
}
priority_queue<node>Q;
const int maxn=10001,maxm=10000001;
int from[maxm],to[maxm],cost[maxm],next[maxm];
int dis[maxn],pre[maxn],fst[maxn],mcnt=0;
void addEdge(int f,int t,int c)//还是前向星风格
{
int newEdge=++mcnt;
from[newEdge]=f;
to[newEdge]=t;
cost[newEdge]=c;
next[newEdge]=fst[f];
fst[f]=newEdge;
}
void print(int x)//打印路径
{
while(x>1)
{
printf("%d->",x);
x=pre[x];
}
if(x==0) printf("no answer!\n");
else printf("%d\n",x);
}
int main()
{
int n,m;scanf("%d%d",&n,&m);//n:点数,m:边数
for(int i=1;i<=m;i++)//读入所有的边
{
int f,t,c;scanf("%d%d%d",&f,&t,&c);
addEdge(f,t,c);addEdge(t,f,c);
}
for(int i=1;i<=n;i++)//dis的初始值为INF
dis[i]=0x7fffffff;
dis[1]=0;node h={0,1};Q.push(h);//起点进堆
for(int i=1;i<=n;i++) //这里可能存在一定的问题【2017.9.2补充】
{
node hn=Q.top();Q.pop();//弹出队首
for(int i=fst[hn.to];i!=0;i=next[i])//前向星修改后继结点
if(dis[hn.to]+cost[i]<dis[to[i]])
{
dis[to[i]]=dis[hn.to]+cost[i];
pre[to[i]]=hn.to;
node nw={dis[to[i]],to[i]};
Q.push(nw);
}
}
for(int i=2;i<=n;i++)
print(i);
return 0;
}但是在这种写法中其实一个点是可以入队多次的,其中又一次是正确的,那就是dis值最小的那一次。而这是一个小根堆,dis值较小的一定会先于不正确的dis值出队。所以它的后继结点会得到正确的结果。(这个HeapDij的代码不是很可靠,待作者实验验证之后再说明!)
【2017.8.31 附上比较靠谱的while循环版的代码】
#include<cstdio>
#include<cstring>
#include<queue>
#include<vector>
#include<algorithm>
using namespace std;
const int maxn=2002,maxm=maxn*maxn;
struct HeapDij{
struct Qnode{
int dist,pos;
};
struct cmp{
bool operator()(Qnode A,Qnode B){
return A.dist>B.dist;
}
};
int n,m;
int from[maxm],to[maxm],cost[maxm],nxt[maxm];
int fst[maxn],pre[maxn],dis[maxn],vis[maxn];
void init(int n){
this->n=n;m=0;
memset(fst,0,sizeof(int)*(n+1));
}
void addedge(int f,int t,int c){
int ne=++m;
from[ne]=f;to[ne]=t;cost[ne]=c;
nxt[ne]=fst[f];fst[f]=ne;
}
void Dijkstra(int s){
priority_queue<Qnode,vector<Qnode>,cmp>heap;
memset(dis,0x7f,sizeof(int)*(n+1));
memset(vis,0x00,sizeof(int)*(n+1));
dis[s]=0;heap.push((Qnode){0,s});
while(!heap.empty()){
int x=heap.top().pos;heap.pop();
if(vis[x])continue;vis[x]=1;
for(int i=fst[x];i;i=nxt[i]){
int tn=to[i];
if(dis[tn]>dis[x]+cost[i]){
dis[tn]=dis[x]+cost[i];
heap.push((Qnode){dis[tn],tn});
}
}
}
}
}dij;slf版
#include<cstdio>
#include<cstdlib>
#include<algorithm>
#include<queue>
#include<cstring>
using namespace std;
const int maxn=10001,maxm=100001;
struct feq
{
int store[maxn+3];
int st,ed;
feq(){st=0;ed=0;}
inline bool empty(){return st>=ed;}
inline int nxt_pos(int i){return (i+1)%maxn;}
inline int lst_pos(int i)
{
int pos=(i-1)%maxn;
while(pos<0)pos+=maxn;
return pos;
}
inline int top(){return store[st];}
inline void pop(){st=nxt_pos(st);}
void push_front(int x){st=lst_pos(st);store[st]=x;}
void push_back(int x){store[ed]=x;ed=nxt_pos(ed);}
};
struct SPFA
{
int n,mcnt,s;
int from[maxm],to[maxm],cost[maxm],nxt[maxm]; //edges
int pre[maxn],dis[maxn],vis[maxn],fst[maxn]; //nodes
void init(int N)
{
n=N;mcnt=0;
memset(fst,0x00,sizeof(int)*(N+1));
//memset(pre,0x00,sizeof(int)*(n+1));
}
void addedge(int f,int t,int c)
{
int ne=++mcnt;
from[ne]=f;to[ne]=t;cost[ne]=c;
nxt[ne]=fst[f];fst[f]=ne;
}
void normal(int S)
{
printf("/spfa.normal\n");
memset(dis,0x7f,sizeof(int)*(n+1)); //min
memset(vis,0x00,sizeof(int)*(n+1));
queue<int>Q;
s=S;pre[S]=0;vis[S]=1;Q.push(S);/*dis[S]!!!*/dis[S]=0;
while(!Q.empty())
{
int x=Q.front();Q.pop();vis[x]=0;
printf("/ .while x=%3d\n",x);
for(int i=fst[x];i;i=nxt[i])
{
printf("/ . .for i=%d f=%d t=%d c=%d\n",
i,from[i],to[i],cost[i]);
int t=to[i];
if(dis[t]>dis[x]+cost[i])
{
printf("/ . . .if re new t=%d\n",t);
dis[t]=dis[x]+cost[i];pre[t]=x;
if(!vis[t])vis[t]=1,Q.push(t);
}
}
}
}
void slf(int S)
{
printf("/spfa.slf\n");
memset(dis,0x7f,sizeof(int)*(n+1)); //min
memset(vis,0x00,sizeof(int)*(n+1));
feq Q;
s=S;pre[S]=0;vis[S]=1;Q.push_back(S);/*dis[S]!!!*/dis[S]=0;
while(!Q.empty())
{
int x=Q.top();Q.pop();vis[x]=0;
printf("/ .while x=%3d\n",x);
for(int i=fst[x];i;i=nxt[i])
{
printf("/ . .for i=%d f=%d t=%d c=%d\n",
i,from[i],to[i],cost[i]);
int t=to[i];
if(dis[t]>dis[x]+cost[i])
{
printf("/ . . .if re new t=%d\n",t);
dis[t]=dis[x]+cost[i];pre[t]=x;
if(!vis[t])
{
vis[t]=1;
if(dis[t]<dis[Q.top()])
Q.push_front(t);
else Q.push_back(t);
}
}
}
}
}
void path(int x)
{
int dist=dis[x];
if(pre[x]==0)printf("No Path!\n");
else{while(x!=s)printf("%d -> ",x),x=pre[x];
printf("%d [%d]\n",s,dist);}
}
void outnxt()
{
printf("/spfa.fst\n");
for(int i=1;i<=mcnt;i++)printf("%3d",i);
printf("\n");
for(int i=1;i<=mcnt;i++)printf("%3d",nxt[i]);
printf("\n");
}
}spfa;
int main()
{
int n,m;scanf("%d%d",&n,&m);
spfa.init(n);
for(int i=1;i<=m;i++)
{
int f,t,c;scanf("%d%d%d",&f,&t,&c);
spfa.addedge(f,t,c);spfa.addedge(t,f,c);
/*two edges!!!*/
}
spfa.slf(1);
for(int i=1;i<=n;i++)printf("%d :",i),spfa.path(i);
spfa.outnxt();
return 0;
}【2017.9.3】暂时还没找到这种“假HeapDij”不适用的情况(也就是说,我竟然拿这种“假算法”A了好几道题..,这一定是数据太水的缘故)。
后记
本文中介绍了三种常用的最短路求法,图论中的一些最短路的问题一般只需要在这些算法上稍加改动就可以实现。
赶稿匆忙,如有谬误,请谅解。
彩蛋——一组很水的测试数据
一组简单而水的测试数据,可用于测试纯粹的最短路算法(仅供参考),计算所有点到点1的最短路径,以及最短距离。
输入格式
第一行,两个数:点数n,边数m
接下来的m行:三个整数f,t,c
(表示有一条连接点f和点t的边,边权为c。)
样例输入
6 9
2 3 1
2 4 2
1 2 17
2 5 8
2 6 21
4 5 14
4 6 3
1 5 5
5 6 4
样例说明
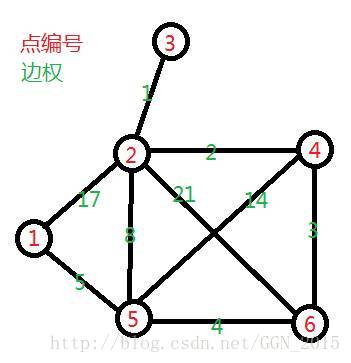
无输出格式
样例答案
2:[13] 2 -> 5 -> 1
3:[14] 3 -> 2 -> 5 -> 1
4:[12] 4 -> 6 -> 5 -> 1
5:[5] 5 -> 1
6:[9] 6 -> 5 -> 1
注:“起点:[距离] 起点 ->… 路径 …->1(终点)”
一道很水的例题
【2017.8.29 补充例题】
NEYC 2017.8 联训中的一道水题
(from virtual judge ,不要尝试点这个链接,除非你参加了NEYC2017.8联训)
题目描述
在每年的校赛里,所有进入决赛的同学都会获得一件很漂亮的t-shirt。但是每当我们的工作人员把上百件的衣服从商店运回到赛场的时候,却是非常累的!所以现在他们想要寻找最短的从商店到赛场的路线,你可以帮助他们吗?
输入描述
输入包括多组数据。每组数据第一行是两个整数N、M(N<=100,M<=10000),N表示成都的大街上有几个路口,标号为1的路口是商店所在地,标号为N的路口是赛场所在地,M则表示在成都有几条路。N=M=0表示输入结束。接下来M行,每行包括3个整数A,B,C(1<=A,B<=N,1<=C<=1000),表示在路口A与路口B之间有一条路,我们的工作人员需要C分钟的时间走过这条路。
输入保证至少存在1条商店到赛场的路线。
输出描述
对于每组输入,输出一行,表示工作人员从商店走到赛场的最短时间
样例输入
2 1
1 2 3
3 3
1 2 5
2 3 5
3 1 2
0 0
样例输出
3
2
在这里我给出我的HeapDij的代码(结构体版)。
#include<cstdio>
#include<queue>
#include<vector>
#include<cstring>
#include<algorithm>
using namespace std;
const int maxn=100+5,maxm=maxn*maxn;
struct HeapDijkstra{
struct Qnode{//node for heap
int dis,index;
};
struct cmp{//cmp for priority_queue
bool operator()(Qnode A,Qnode B){
return A.dis>B.dis;
}
};
int n,m;//nodeCnt edgeCnt
int from[maxm],to[maxm],cost[maxm],nxt[maxm];//edges
int fst[maxn],dis[maxn];//nodes
void init(int n){//init dij
memset(fst,0,sizeof(int)*(n+1));//clear fst
this->n=n;m=0;
}
void addedge(int f,int t,int c){//add an edge
int ne=++m;
from[ne]=f;to[ne]=t;cost[ne]=c;
nxt[ne]=fst[f];fst[f]=ne;
}
void Dijkstra(int s){
memset(dis,0x7f,sizeof(int)*(n+1));//set INF
dis[s]=0;
priority_queue<Qnode,vector<Qnode>,cmp>heap;
heap.push((Qnode){dis[s],s});//start push
for(int i=1;i<=n;i++){//heap Dij
int x=heap.top().index;heap.pop();
for(int j=fst[x];j;j=nxt[j]){//out edge
int tn=to[j];
if(dis[tn]>dis[x]+cost[j]){//refresh
dis[tn]=dis[x]+cost[j];
heap.push((Qnode){dis[tn],tn});
}
}
}
}
}dij;
int main(){//for question
int N,M;
while(scanf("%d%d",&N,&M) &&N &&M){//for all query
dij.init(N);//init dij
for(int i=1;i<=M;i++){//input edges
int A,B,C;scanf("%d%d%d",&A,&B,&C);
dij.addedge(A,B,C);dij.addedge(B,A,C);
}
dij.Dijkstra(1);//solve shortest path
printf("%d\n",dij.dis[N]);//output ans
}
return 0;
}(这个代码是基本上是可靠的,反正我过了vjudge评测。)
在上文写法中出现了一些生僻的写法:
这是一个“比较结构体”的定义:
struct cmp{//cmp for priority_queue
bool operator()(Qnode A,Qnode B){
return A.dis>B.dis;
}
};实现方法就是在结构体里重载一个小括号。“>”表示小根堆,“<”表示大根堆。比较直观的理解是这样的:如果返回值为1,表示这两个数会被交换;返回值为0,表示这两个数不会被交换。在调用时,A的位置在B的前面(即在堆中靠上的位置),如果A>B那么交换,体现出来的效果就是根节点一定是最小的元素。
这是一个带比较函数的优先队列的定义:
priority_queue<Qnode,vector<Qnode>,cmp>heap;格式:priority_queue<结点类型,容器,比较结构体>变量名;
其中,“容器”一般为该类型结点的vector。
感兴趣的同学可以尝试一下这种写法,很不错呦!