前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
背景
2016 年,优步开发了 Apache Hudi(一开始叫 Hoodie),这是一个增量处理框架,以低延迟和高效率为业务关键数据管道提供动力。
一年后,优步选择开源该解决方案,允许其他依赖数据的组织利用其优势,然后在 2019年,又进一步推进了这一承诺,将其捐赠给 Apache 软件基金会。
然后,经过一年半后,Apache Hudi 以顶级项目毕业于 Apache 软件基金会。
WHAT

Apache Hudi 是下一代的实时计算数据湖平台,它在自助的数据存储层上通过增量的数据管道来构建实时计算数据湖,同时也优化了数据湖引擎和离线计算。
Apache Hudi 不仅非常适合实时计算工作负载,还允许创建高效的增量离线计算数据管道。
Apache Hudi 使用插入(upsert)和增量拉取等原语,将流式处理带到了类批处理的大数据中。
这些功能有助于为我们的服务显示更快、更新鲜的数据,统一的服务层具有大约几分钟的数据延迟,避免维护多个系统的任何额外开销。
除了灵活性外,Apache Hudi 可以在 Hadoop 分布式文件系统(HDFS)或云存储上运行。
Hudi 在数据湖上实现了原子性、一致性、隔离性和持久性(ACID)语义。
Hudi 使用最广泛的两个功能是插入(upsert)和增量拉取,这使用户能够吸收更改数据捕获,并将其大规模应用于数据湖。
Hudi 还提供了广泛的可插拔索引功能,为了实现这一目标,自己实现了数据索引。
Hudi 控制和管理数据湖中文件布局的能力,不仅对克服 HDFS 命名节点和其他云存储限制至关重要,而且对于通过提高可靠性和查询性能来维护健康的数据生态系统也非常重要。
为此,Hudi 支持多个查询引擎集成,如 Presto、Apache Hive、Apache Spark 和 Apache Impala。
特性
- 通过快速、可插拔的索引实现 upsert/delete
- 增量查询,记录级别的变更流。
- 交易、回滚、并发控制。
- 来自 Spark、Presto、Trino、Hive 等的 SQL 读写
- 文件大小自动化、数据集群化、文件合并与清理。
- 流数据的摄取,内置 CDC 数据源和工具。
- 内置元数据的跟踪,用于可扩展的存储访问。
- 向后兼容的模式(Schema)升级和实施。
内部细节
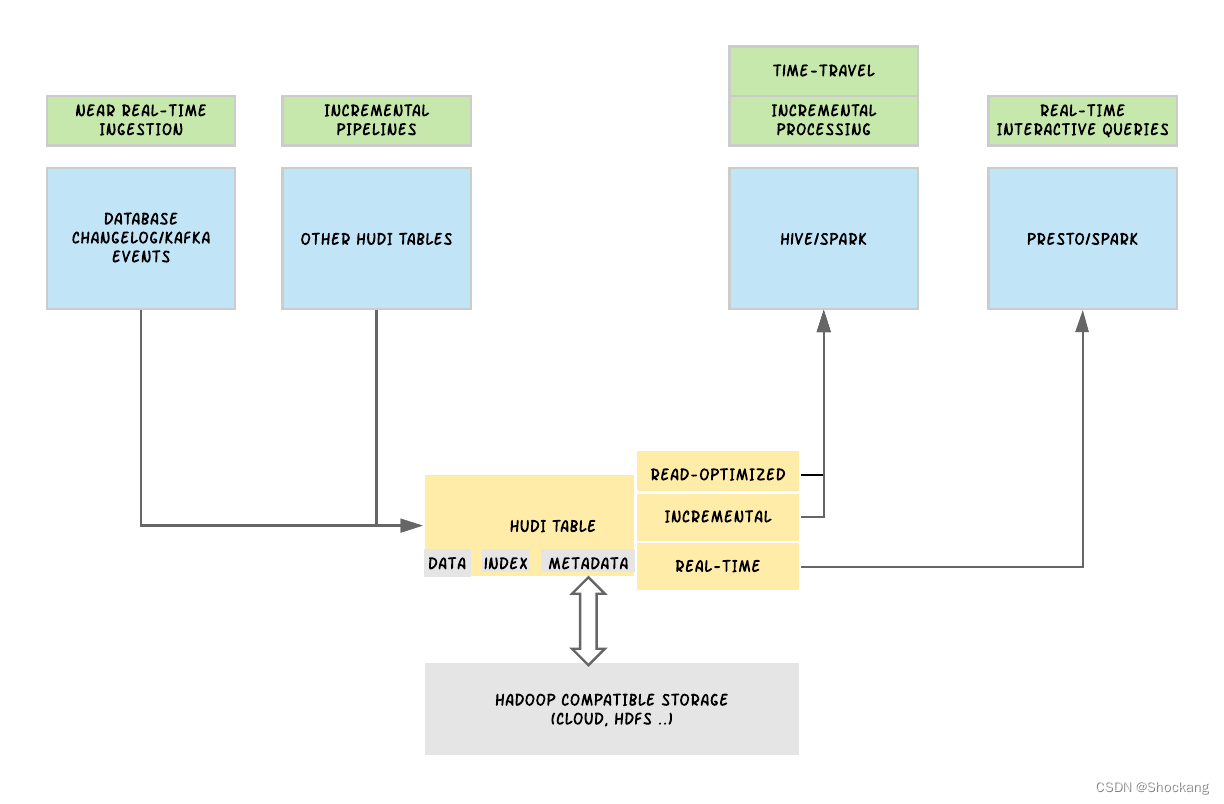
在顶层设计上,Hudi 在概念上分为三个主要组成部分:需要存储的原始数据、用于提供插入(upsert)能力的数据索引以及用于管理数据集的元数据。
在其核心,Hudi 维护着在不同时间点在数据表上执行的所有操作的时间表,称为 instants in Hudi。这提供了数据表的即时视图,同时也有效地支持按到达顺序来检索数据。
Hudi 保证在时间线上执行的操作是原子的,并且基于即时时间,即数据库中变更发生的时间,是一致的。
有了这些信息,Hudi 提供了同一 Hudi 表的不同视图,包括用于快速列存性能的读取优化视图,用于快速数据摄取的实时视图,以及上图所示的将 Hudi 表作为变更日志流读取的增量视图。
Hudi 在分布式文件系统的基本路径下将数据表组织成目录结构。
表被分解为分区,在每个分区中,文件被组织成文件组,由文件 ID 唯一标识。
每个文件组包含几个文件片,其中每个切片包含一个在特定提交/压缩即时时间生成的基础文件(* .parquet),以及一组日志文件( * .log. * ),其中包含自生成基础文件生成以来对基本文件的插入/更新。
Hudi 采用多版本并发控制(MVCC),其中压缩操作合并日志和基础文件以生成新的文件切片,清理操作将删除未使用/旧的文件片以回收文件系统上的空间。
Hudi 支持两种表类型:写时复制(copy-on-write)和读取时合并(merge-on-read)。
写时复制表类型仅使用列式文件格式(例如 Apache Parquet)存储数据。
通过写时复制,通过在写入过程中执行同步合并来简单更新版本并重写文件。
读取合并表类型使用列存(例如 Apache parquet)和基于行存(例如Apache Avro)文件格式的组合存储数据。
更新被记录到增量文件,然后压缩,以同步或异步生成新版本的列存文件。
Hudi 还支持两种查询类型:快照和增量查询。
快照查询是从给定的提交或压缩操作中获取表的“快照”的请求。
当利用快照查询时,写入时复制表类型仅公开最新文件切片中的基本/列存文件,并保证与非 Hudi 表具有相同的列存查询性能。
写时复制为现有的 Parquet 表提供了下拉式替换,同时提供插入/删除和其他功能。
在读取合并表的情况下,快照查询通过实时合并最新文件切片的基文件和增量文件来公开近实时数据(分钟顺序)。
对于写入时复制表,增量查询提供自给定提交或压缩以来写入表的新数据,提供变更流以启用增量数据管道。