第二十周周报
摘要
本文主要介绍了深度学习的基础知识和操作,包括数据操作、数据运算、数据预处理。最后复习了循环神经网络(RNN)和长短期记忆网络(LSTM)。在数据操作部分,详细讲解了张量的基本操作,如创建、形状调整、元素总数计算、初始化和元素赋值。数据运算部分则包括了张量的算术运算、连结、逻辑运算和求和。文章还介绍了广播机制和索引切片的使用方法。数据预处理部分,通过使用pandas库对CSV文件中的数据进行读取、处理缺失值、转换为张量格式。最后,文章复习了RNN和LSTM的基本概念和工作原理,包括槽填充、词汇向量编码、RNN的变形和LSTM的结构和运算过程。
Abstract
This article primarily introduces the fundamental knowledge and operations of deep learning, encompassing data manipulation, data operations, and data preprocessing. It concludes with a review of Recurrent Neural Networks and Long Short-Term Memory networks . The section on data manipulation detailedly explains the basic operations of tensors, such as creation, shape adjustment, element count calculation, initialization, and element assignment. The data operations section includes arithmetic operations, concatenation, logical operations, and summation of tensors. The article also introduces the broadcasting mechanism and the usage of indexing and slicing. In the data preprocessing part, the article demonstrates how to read data from a CSV file, handle missing values, and convert data into tensor format using the pandas library. Finally, the article reviews the basic concepts and working principles of RNNs and LSTMs, including slot filling, word vector encoding, RNN variations, and the structure and operation process of LSTMs.
一、动手深度学习
接下来的学习回围绕深度学习的代码部分和之前几周学习过的理论知识进行复习和巩固学习,提高代码实战能力,手撕一下学习过的模型很原来,这一周从基础部分开始学习。
1. 数据操作
1.1 数据基本操作
张量表示是由单一数值构成的多维数组。这种数组可以具有不同的维度。
具体来说,一个轴的张量在数学上对应于向量(vector);
两个轴的张量对应于矩阵(matrix);
而超过两个轴的张量则没有特定的数学术语来描述。
- ⾸先,我们可以使⽤
arange创建⼀个⾏向量 x。这个⾏向量包含以0开始的前12个整数,它们默认创建为整数。也可指定创建类型为浮点数。
张量中的每个值都称为张量的元素(element)。
例如,张量 x 中有 12 个元素。除⾮额外指定,新的张量将存储在内存中,并采⽤基于CPU的计算。
import torch
x = torch.arange(12)
print(x)

- 可以通过张量的
shape属性来访问张量(沿每个轴的⻓度)的形状
# 可以通过张量的shape属性来访问张量(沿每个轴的⻓度)的形状
print(x.shape)

- 如果只想知道张量中元素的总数,即形状的所有元素乘积,可以检查它的⼤⼩(size)。
因为这⾥在处理的是⼀个向量,所以它的shape与它的size相同。
# 如果只想知道张量中元素的总数,即形状的所有元素乘积,可以检查它的⼤⼩(size)。
print(x.numel())

- 若要调整张量的形状而不改变其元素数量和值,可以使用
reshape函数
例如,可以将形状为(12,)的行向量张量x重塑为(3,4)的矩阵形状。重塑后的张量包含与重塑前完全相同的元素值,但被视为一个3行4列的矩阵。重要的是要强调,尽管张量的形状发生了变化,但其元素的值保持不变。
请注意,改变张量的形状并不会影响张量的总大小。
X = x.reshape(3, 4)
print(X)
我们不需要通过⼿动指定每个维度来改变形状。也就是说,如果我们的⽬标形状是(⾼度,宽度),那么在知道宽度后,⾼度会被⾃动计算得出,不必我们⾃⼰做除法。
在上⾯的例⼦中,为了获得⼀个3⾏的矩阵,我们⼿动指定了它有3⾏和4列。
我们可以通过-1来调⽤此⾃动计算出维度的功能。即我们可以⽤x.reshape(-1,4)或x.reshape(3,-1)来取代x.reshape(3,4)。

- 有时,我们希望使⽤全0、全1、其他常量,或者从特定分布中随机采样的数字来初始化矩阵。
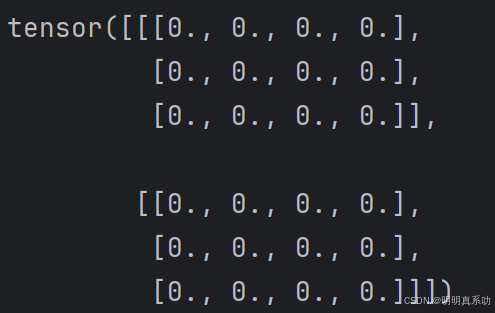
我们可以创建⼀个形状为(2,3,4)的张量,其中所有元素都设置为0。
torch.zeros((2, 3, 4))
print(x)
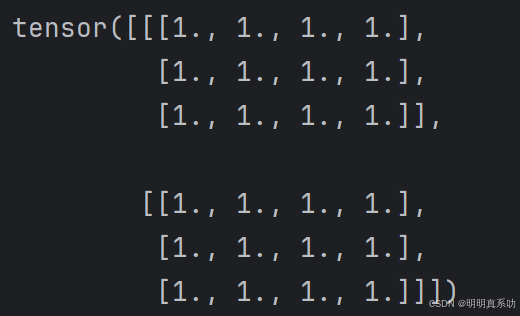
或者可以创建⼀个形状为(2,3,4)的张量,其中所有元素都设置为1。
x = torch.ones((2, 3, 4))
print(x)
- 在某些情况下,我们希望张量中的每个元素值是通过从特定的随机概率分布中抽取样本得到的。
例如,在构建神经网络参数的数组时,我们通常会采用随机初始化的方法来设定这些参数的初始值。
以下代码展示了如何创建一个形状为(3,4)的张量,其每个元素都是从均值为0、标准差为1的标准高斯分布(也称为正态分布)中随机抽取的样本。
x = torch.randn(3, 4)
print(x)

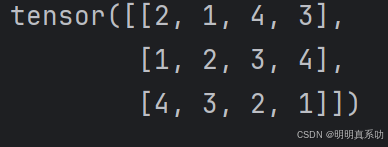
- 我们还可以通过提供包含数值的Python列表(或嵌套列表),来为所需张量中的每个元素赋予确定值
如下最外层的列表对应于轴0,内层的列表对应于轴1。
x = torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(x)
1.2 数据运算
- 对于任意具有相同形状的张量,常⻅的标准算术运算符(+、-、*、/和 求幂运算)都可以被升级为按元素运算。我们可以在同⼀形状的任意两个张量上调⽤按元素操作
在下⾯的例⼦中,我们使⽤逗号来表⽰⼀个具有5个元素的元组,其中每个元素都是按元素操作的结果。
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算


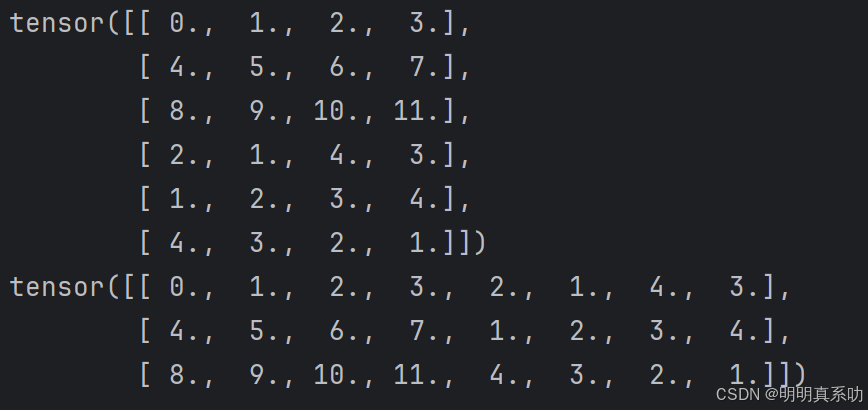
- 我们也可以把多个张量连结(concatenate)在⼀起,把它们端对端地叠起来形成⼀个更⼤的张量。
我们只需要提供张量列表,并给出沿哪个轴连结。
下⾯的例⼦分别演⽰了当我们
沿⾏(轴-0,形状的第⼀个元素)
按列(轴-1,形状的第⼆个元素)
连结两个矩阵时,会发⽣什么情况。
我们可以看到
第⼀个输出张量的轴-0⻓度(6)是两个输⼊张量轴-0⻓度的总和(3 + 3);
第⼆个输出张量的轴-1⻓度(8)是两个输⼊张量轴-1⻓度的总和(4 + 4)
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(torch.cat((X, Y), dim=0))
print(torch.cat((X, Y), dim=1))
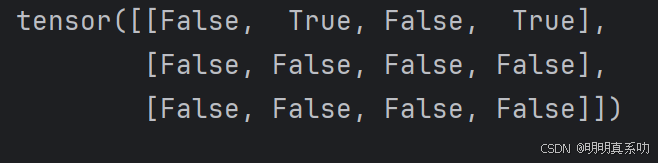
3.通过逻辑运算符构建⼆元张量。
以X == Y为例:对于每个位置,如果X和Y在该位置相等,则
新张量中相应项的值为1。
这意味着逻辑语句X == Y在该位置处为真,否则该位置为0。
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(X == Y)
- 对张量中的所有元素进⾏求和,会产⽣⼀个单元素张量。
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
print(X.sum())

1.2.1 广播机制
在前文中,我们探讨了如何在形状相同的两个张量上进行逐元素操作。
在某些情况下,即使两个张量的形状不同,我们也可以利用广播机制(broadcasting mechanism)来执行逐元素操作。
广播机制的工作原理如下:
首先,通过适当地复制元素来扩展一个或两个数组,使得在转换之后,两个张量具有相同的形状。
然后,对这些扩展后的数组进行逐元素操作。
在大多数情况下,我们会沿着数组中长度为1的维度进行广播,正如以下示例所示:
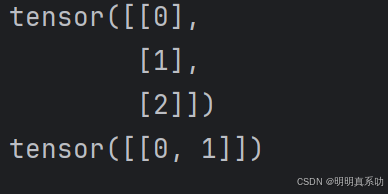
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
print(a,b)
由于a和b分别是3 × 1和1 × 2矩阵,如果让它们相加,它们的形状不匹配。
我们将两个矩阵⼴播为⼀个更⼤的3 × 2矩阵
如下所⽰:矩阵a将复制列,矩阵b将复制⾏,然后再按元素相加。
print(a + b)

1.3 索引和切片
就像在任何其他Python数组中⼀样,张量中的元素可以通过索引访问。
与任何Python数组⼀样:第⼀个元素的索引是0,最后⼀个元素索引是-1;
可以指定范围以包含第⼀个元素和最后⼀个之前的元素。
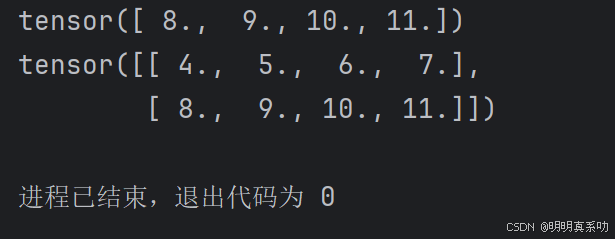
- 如下所示,我们可以⽤[-1]选择最后⼀个元素,可以⽤[1:3]选择第⼆个和第三个元素:
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
print(X[-1])
print(X[1:3])
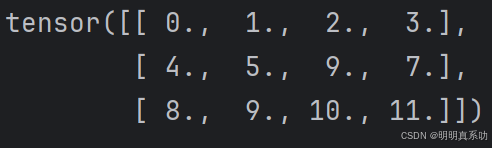
- 除读取外,我们还可以通过指定索引来将元素写⼊矩阵。
X[1, 2] = 9
print(X)
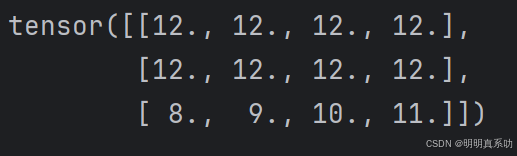
- 如果我们想为多个元素赋值相同的值,我们只需要索引所有元素,然后为它们赋值。
例如,[0:2, :]访问第1⾏和第2⾏(左闭右开),其中“:”代表沿轴1(列)的所有元素。虽然我们讨论的是矩阵的索引,但这也适⽤于向量和超过2个维度的张量。
X[0:2, :] = 12
print(X)
2. 数据预处理
为了应用深度学习技术解决现实世界的问题,我们通常从原始数据的预处理工作入手,而不是直接从已经准备好的张量格式数据开始。
在Python的数据分析工具库中,pandas软件包是我们常用的工具之一。与Python生态系统中的许多其他扩展库一样,pandas能够与张量格式兼容。
我们将简要介绍 如何使用pandas对原始数据进行预处理,以及如何将这些数据转换成张量格式。
- 读取数据集
⾸先创建⼀个⼈⼯数据集,并存储在CSV(逗号分隔值)⽂件 ./data/house_tiny.csv中。
以其他格式存储的数据也可以通过类似的⽅式进⾏处理。下⾯我们将数据集按⾏写⼊CSV⽂件中。
import os
# makedirs:创建新文件夹;
# os.path.join:连接路径;
# exist_ok:是否在目录存在时触发异常。如果为False(默认值),则在目标目录已存在的情况下触发FileExistsError异常;如果为True,则在目标目录已存在的情况下不会触发异常。
os.makedirs(os.path.join('.', 'data'), exist_ok=True)
data_file = os.path.join('.', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f: # w:打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每⾏表⽰⼀个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')

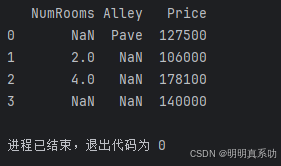
- 要从创建的CSV⽂件中加载原始数据集,我们导⼊pandas包并调⽤read_csv函数。
该数据集有四⾏三列。
其中每⾏描述了房间数量(“NumRooms”)、巷⼦类型(“Alley”)和房屋价格(“Price”)。
import pandas as pd
import torch
# 要从创建的CSV⽂件中加载原始数据集,我们导⼊pandas包并调⽤read_csv函数。该数据集有四⾏三列。
# 其中每⾏描述了房间数量(“NumRooms”)、巷⼦类型(“Alley”)和房屋价格(“Price”)。
data = pd.read_csv('./data/house_tiny.csv')
print(data)
3. 处理缺失值
注意,“NaN”项代表缺失值。
为了处理缺失的数据,典型的⽅法包括插值法和删除法,其中插值法⽤⼀个替代值弥补缺失值,⽽删除法则直接忽略缺失值。在这⾥,我们将考虑插值法。
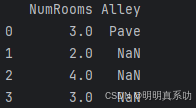
通过位置索引iloc,我们将data分成inputs和outputs,其中前者为data的前两列,⽽后者为data的最后⼀列。
对于inputs中缺少的数值,我们⽤同⼀列的均值替换“NaN”项。
# 分割数据集为输入和输出
inputs = data.iloc[:, 0:2] # :表示全部行 0:2表示0-1行即[0,2)左闭右开
outputs = data.iloc[:, 2] # :表示全部行 2表示3行
inputs = inputs.fillna(inputs.mean(numeric_only=True)) # numeric_only=True只计算数字的列 即 NumRooms
print(inputs)
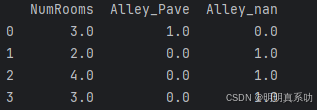
对于inputs中的类别值或离散值,我们将“NaN”视为⼀个类别。
由于“巷⼦类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”,pandas可以⾃动将此列转换为两列“Alley_Pave”和“Alley_nan”。巷⼦类型为“Pave”的⾏会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。
缺少巷⼦类型的⾏会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
# 处理类别值或离散值
# 类似于one-hot
inputs = pd.get_dummies(inputs, dummy_na=True)
# 将布尔类型转化为float
inputs = inputs.astype(float)
print(inputs)
- 转换为张量格式
现在inputs和outputs中的所有条⽬都是数值类型,它们可以转换为张量格式。
当数据采⽤张量格式后,可以通过在引⼊的张量函数来进⼀步操作。
# 转换为张量格式
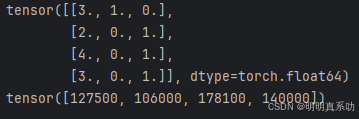
X = torch.tensor(inputs.values)
y = torch.tensor(outputs.values)
print(X)
print(y)
总体代码如下:
import pandas as pd
import torch
# 从创建的CSV文件中加载原始数据集
data = pd.read_csv('./data/house_tiny.csv')
print(data)
# 分割数据集为输入和输出
inputs = data.iloc[:, 0:2]
outputs = data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
# 处理类别值或离散值
# 类似于one-hot
inputs = pd.get_dummies(inputs, dummy_na=True)
inputs = inputs.astype(float)
print(inputs)
# 转换为张量格式
X = torch.tensor(inputs.values)
y = torch.tensor(outputs.values)
print(X)
print(y)
二、复习RNN与LSTM
1. Recurrent Neural Network(RNN,循环神经网络)
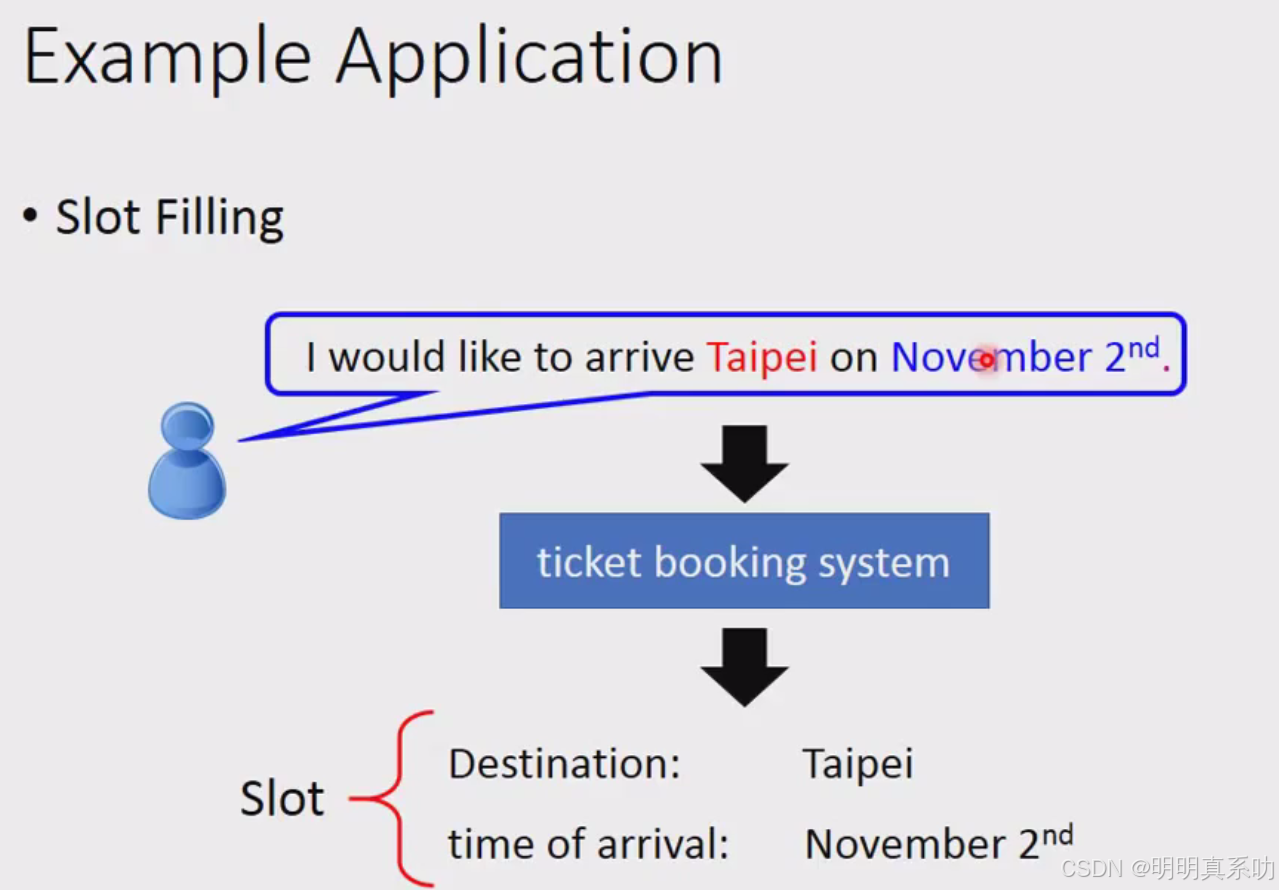
槽填充(Slot Filling)
什么是slot filling?
如下图所示
比如有一个智慧订票系统,顾客输入他的行程需求
智慧系统就要提取关键词,填入到slot(目的地、到达时间)
那这个问题要怎么实现呢?
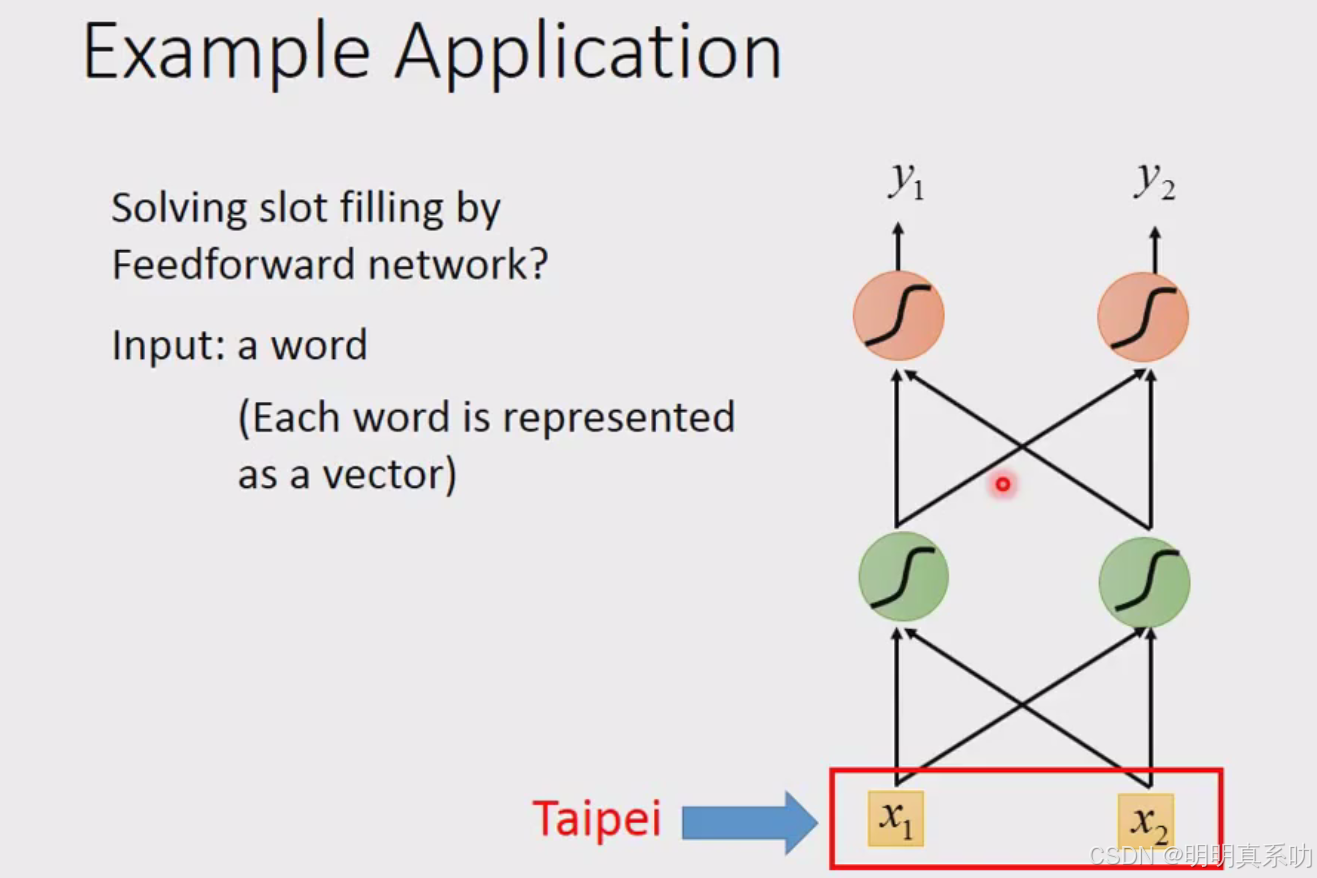
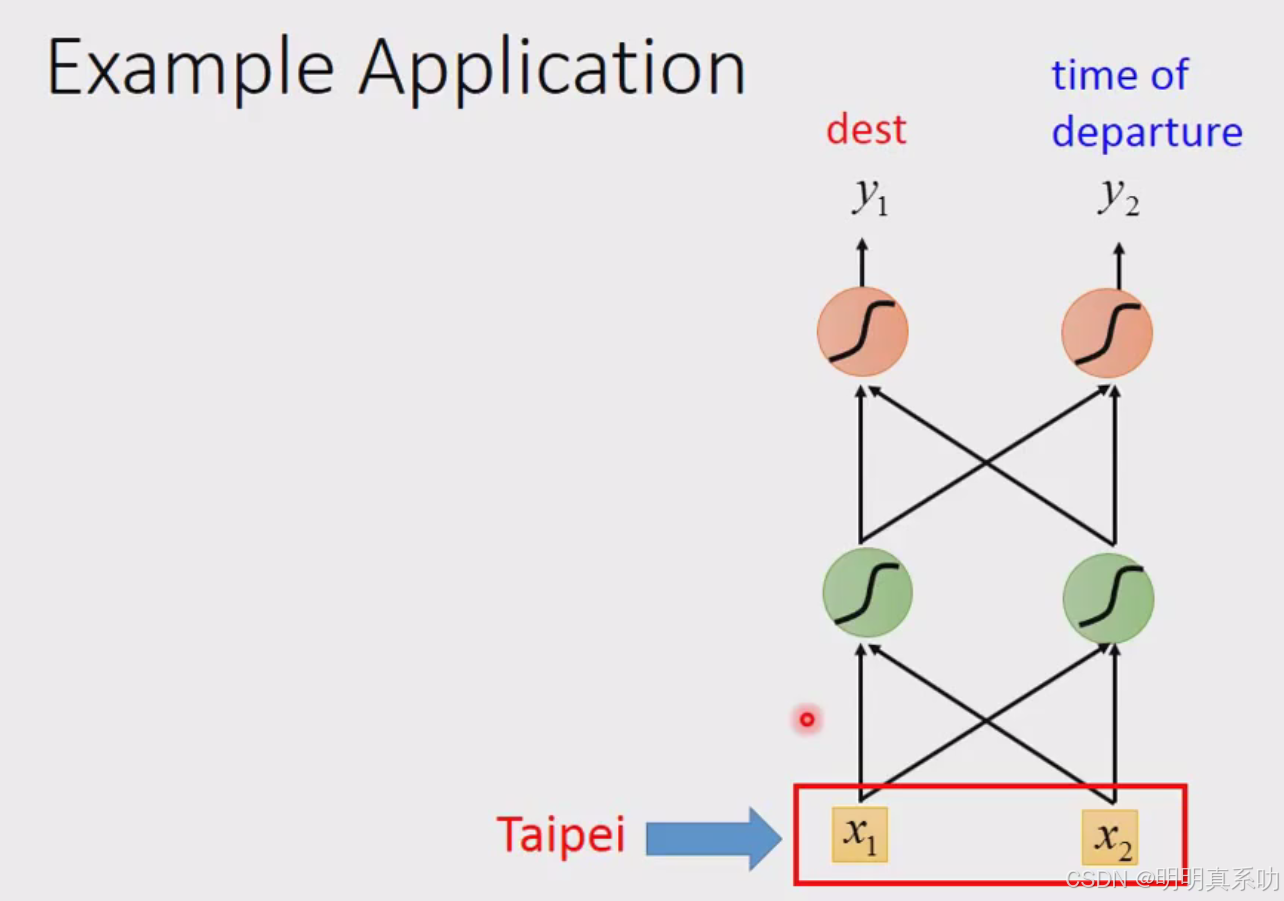
我们可以用一个feedforward neural network(前馈神经网络)来完成。
input就是一个词汇
1.1 词汇vector的编码方式
1-of-N encoding
词汇肯定要变成vector来表示,那么我们有最经典的表达方式 1-of-N encoding
(即有多少个词汇就有多少个向量;向量的维度等同于词汇的数量)
每个词汇表达的方式,如下图所示:
又或者我们对1-of-N encoding的编码方式做出一些改进
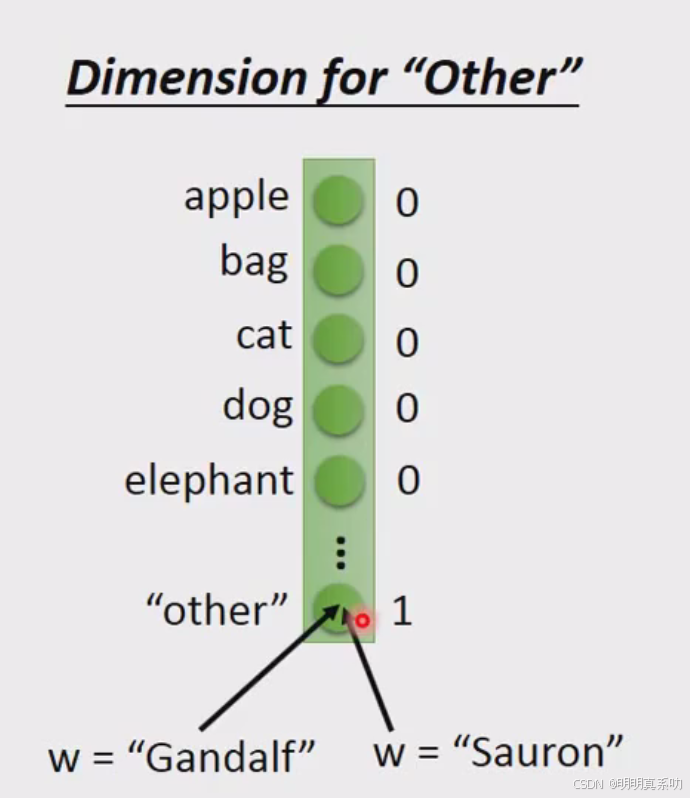
改进方式1:Dimension for “other”
因为我们的词汇实在是太多了,更何况还有一些人名之类的。把所有词汇按照上述方式编排,vector的维度和数量是不敢想象的。
因此我们可以设置一个other来表示其他没有见过的词汇(通过拓展一个dimension来表示other)
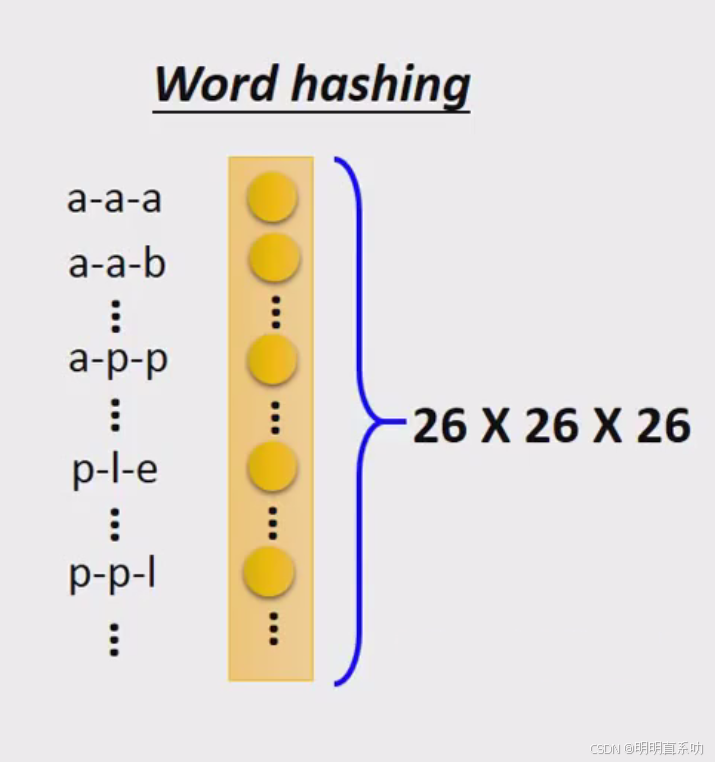
改进方式2:word hashing(字串比对)
可以用某一个词汇的字母来表示它的vector
如果你用某一个词汇的字母的来表示那个vector的话呢,你就不会有某一个词汇不在词典中的问题。

word hashing(字串比对)
仅用于英文中。
具体以bool这个单词为例,分为三个步骤:
1.在bool两端添加临界符#bool#
2.采用n-gram的方式分成多个部分,如果是trigrams那么结果是[#bo, boo, ool, ol#]
3.最终bool将会用[#bo, boo, ool, ol#]的向量来表示
不难发现,hashing后的结果[#bo, boo, ool, ol#] 每个letter长度都是3个字母,因此成为tri-letter。
单词词表很大,很容易出现OOV,OOV(Out-Of-Vocabulary)是指在自然语言处理中遇到的未知单词。
但是word hashing后,词表不再是单词,而是每个letter,也就是词根,这样词表规模就会小很多。
无论我们用以上哪一种方式,我们都可以将词汇转化为vector作为feedforward neural network的input。
然后output是一个probability distribution(概率分布)
这个probability distribution代表是我们现在input的这个词汇属于每一个slot的几率。
这样就完成了slot filling的任务。
比如TaiBei属于destination的几率 或 属于time of departure的几率
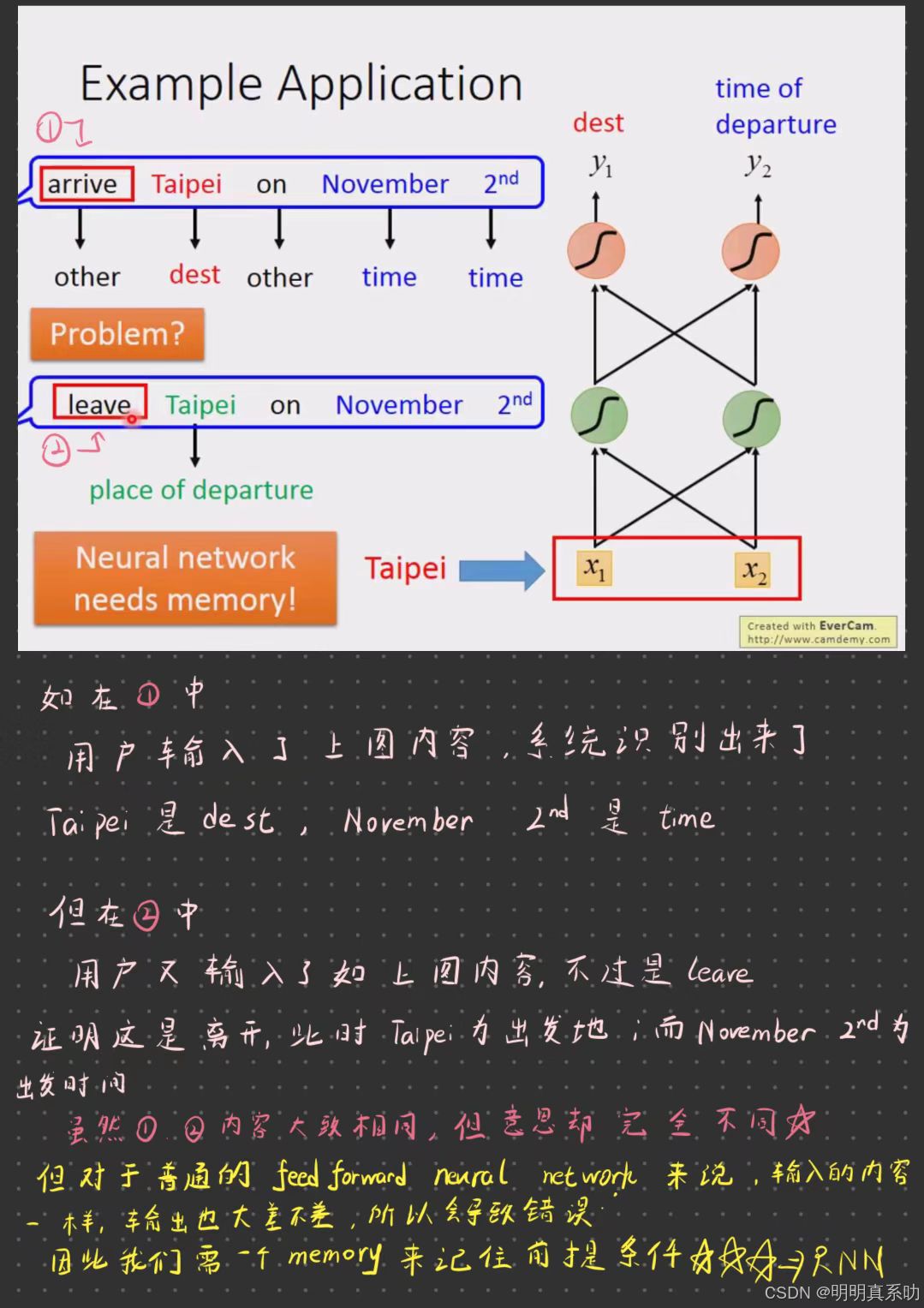
但是如果单纯的使用feedforward neural network会出现一些问题,如下图所示:
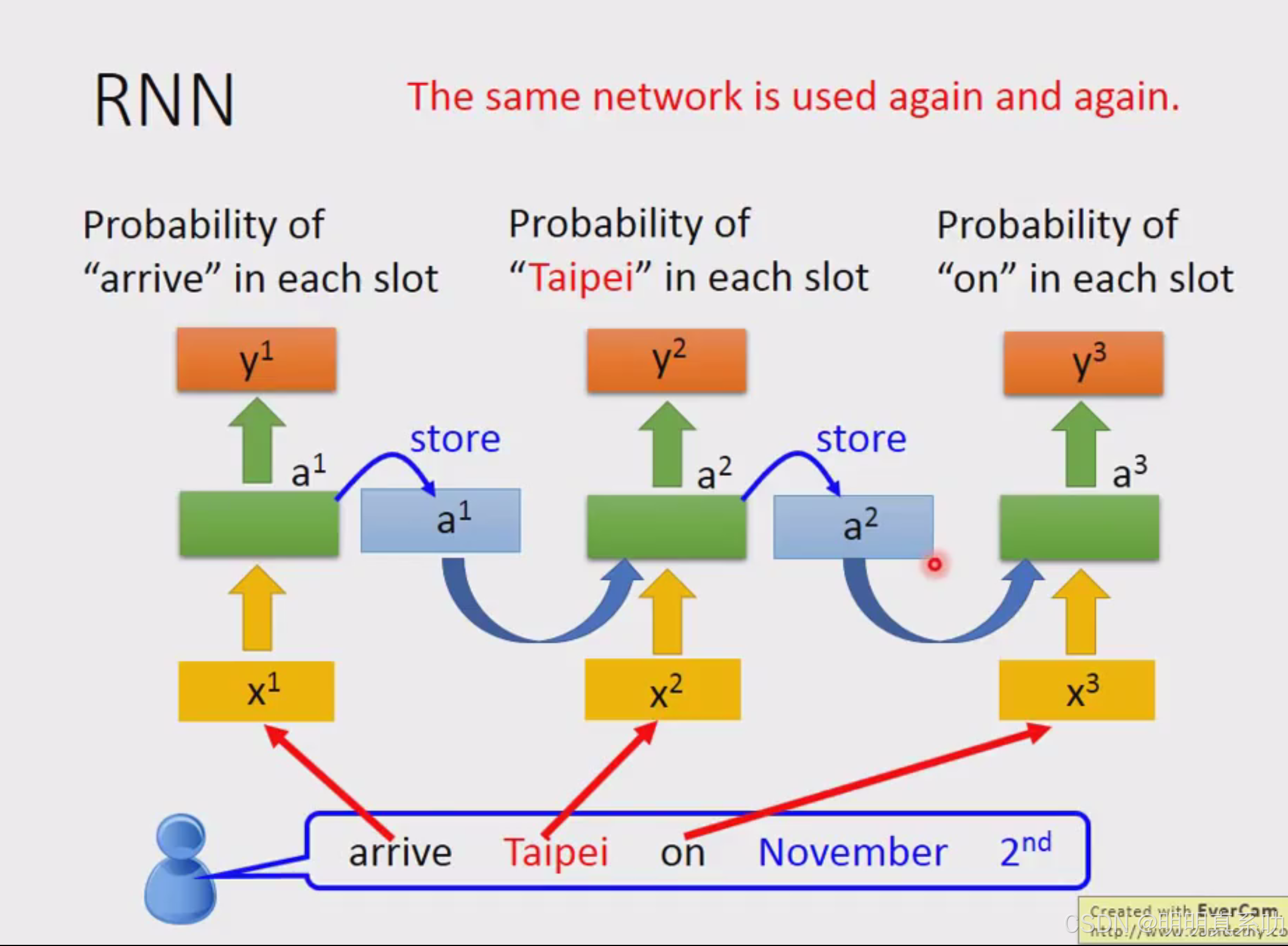
这种有记忆的network叫做RNN(Recurrent Neural Network,循环神经网络)
在RNN中,hidden layer的输出不会被遗忘,而是会被记住。在下一次输出的时候,会连同input与这些hidden layer 的 output一同考虑,最后再输出。
所以即使是相同的内容,在RNN里面受memory里面一些hidden layer output的影响,也会有不同的输出
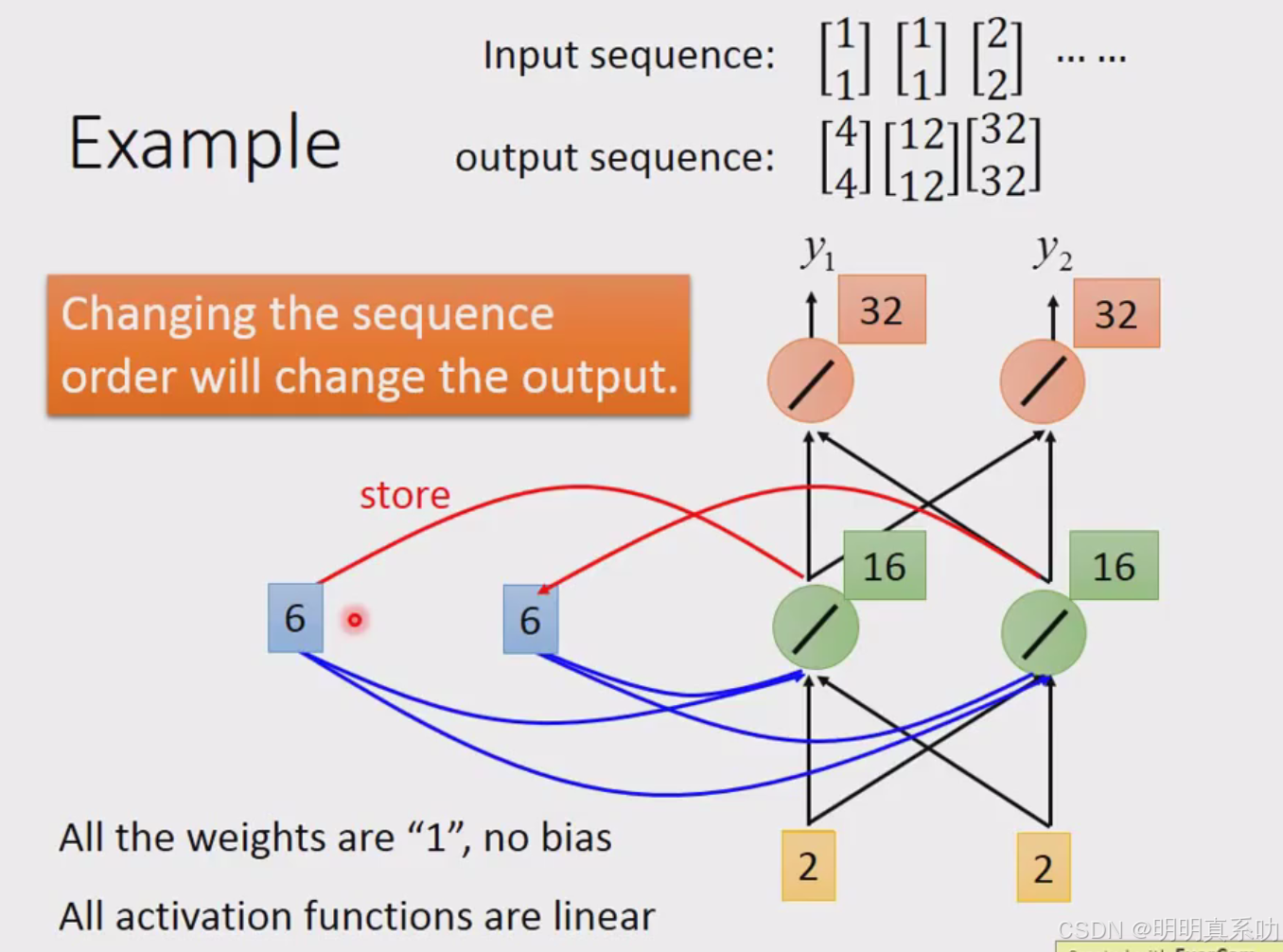
假设现在这个下图中的这个network它所有的weight呢都是1,然后所有的neuron都没有任何的bias,所有的activation function都是linear。
那现在假设我们的input是一个sequence
i
n
p
u
t
s
e
q
u
e
n
c
e
=
[
1
1
]
[
1
1
]
[
2
2
]
…
…
{\color{Red} input\space sequence= \begin{bmatrix}1 \\1\end{bmatrix}\begin{bmatrix}1 \\1\end{bmatrix}\begin{bmatrix}2 \\2\end{bmatrix}\dots\dots}
input sequence=[11][11][22]……
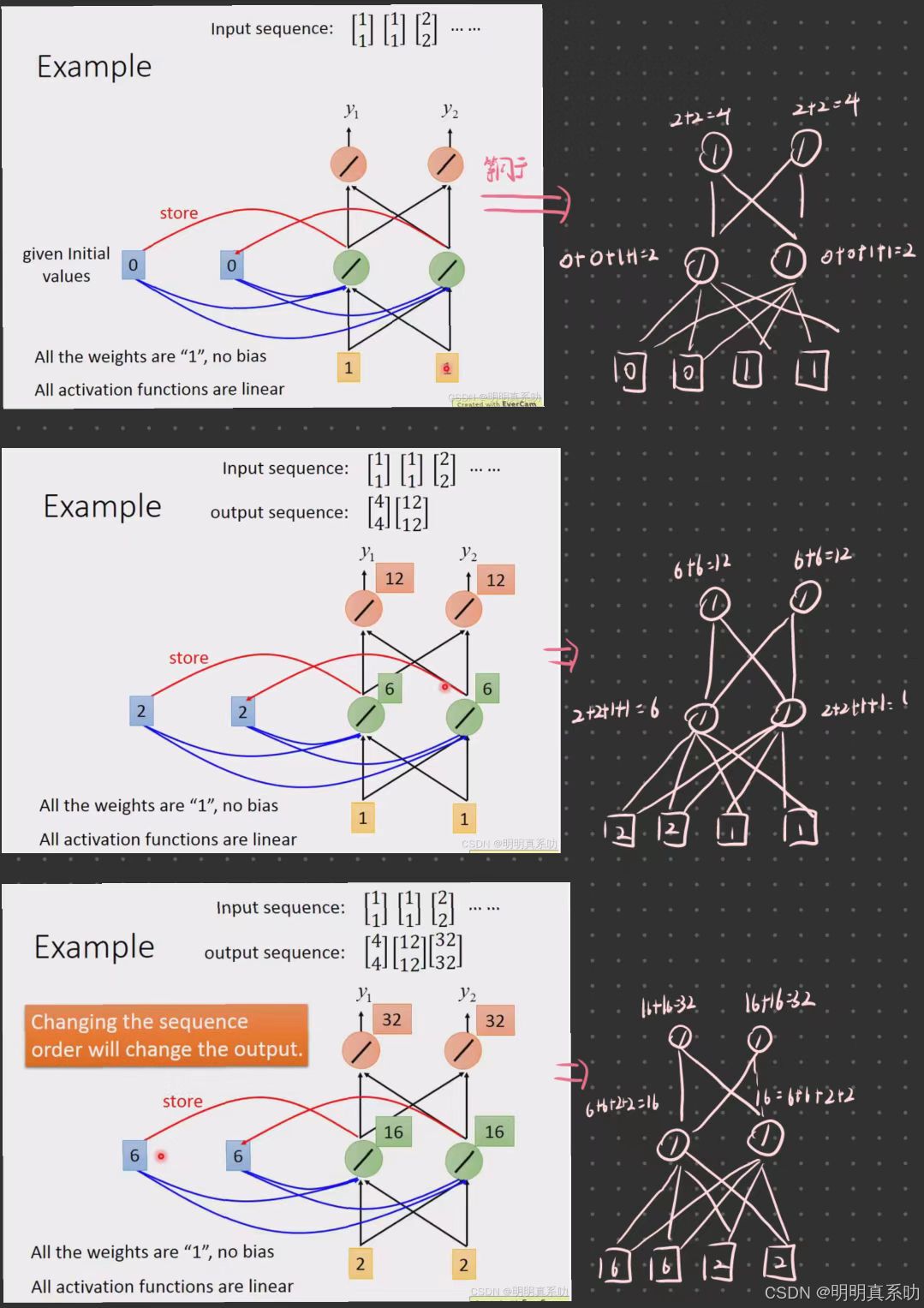
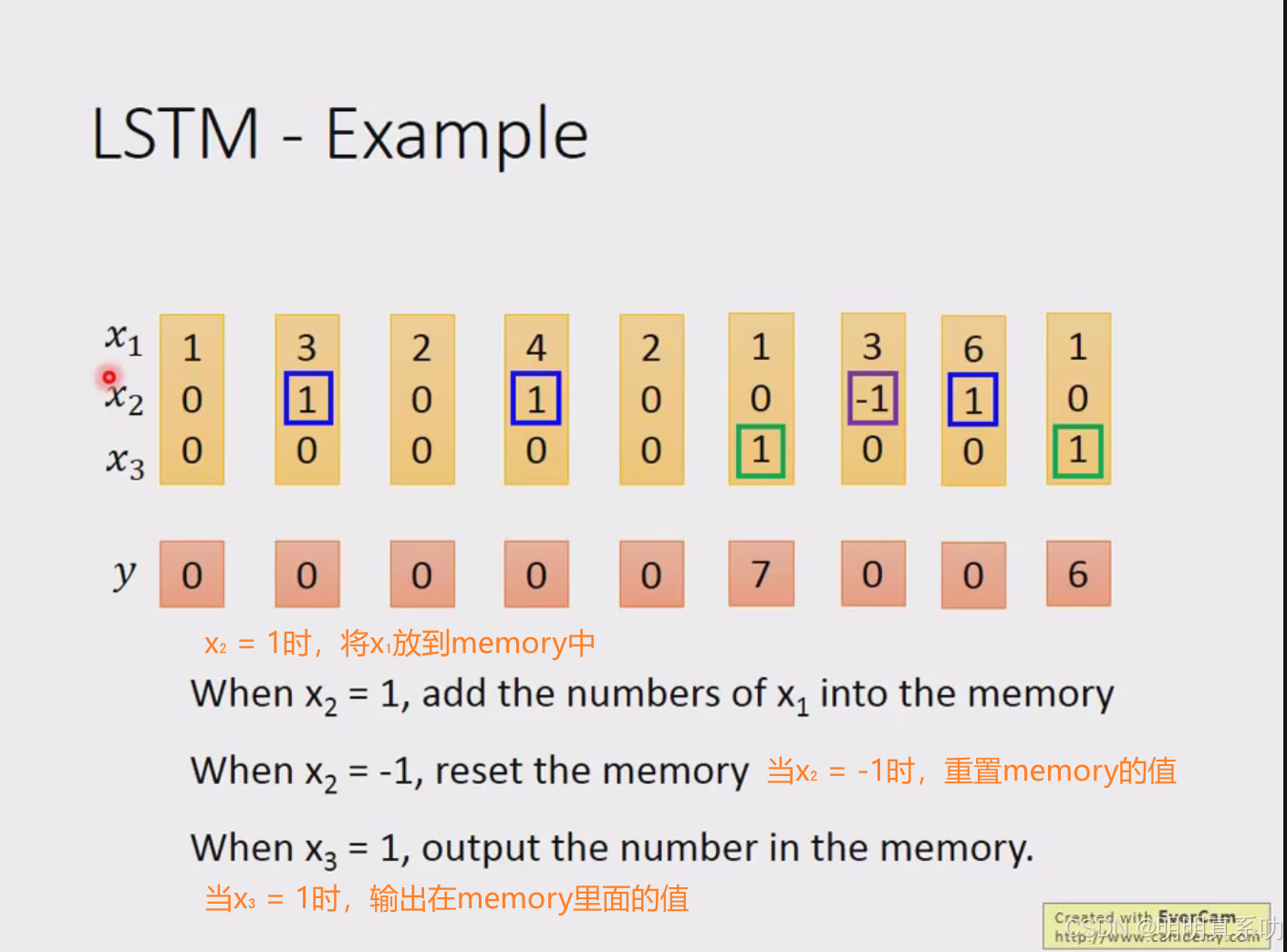
例子如下:
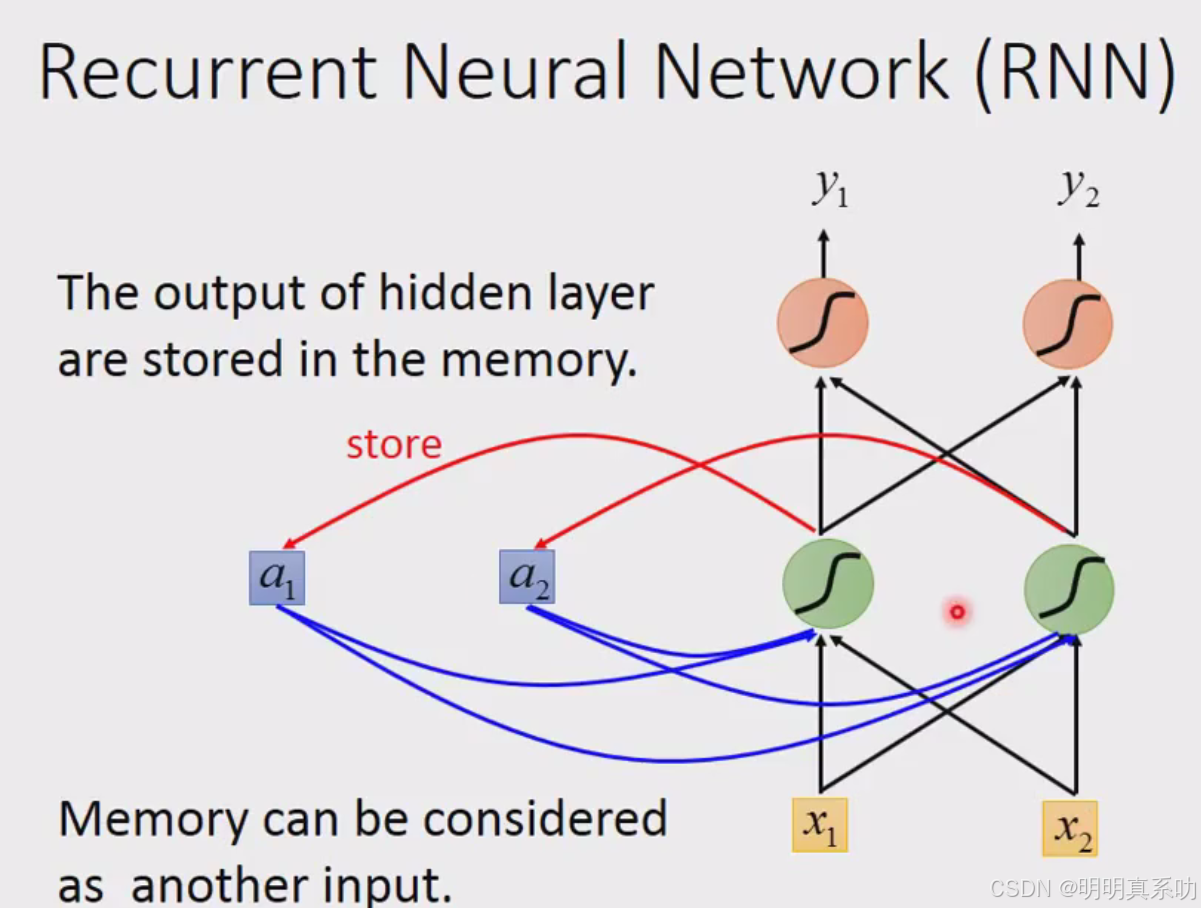
一开始的memory是没东西的,算作是0 0
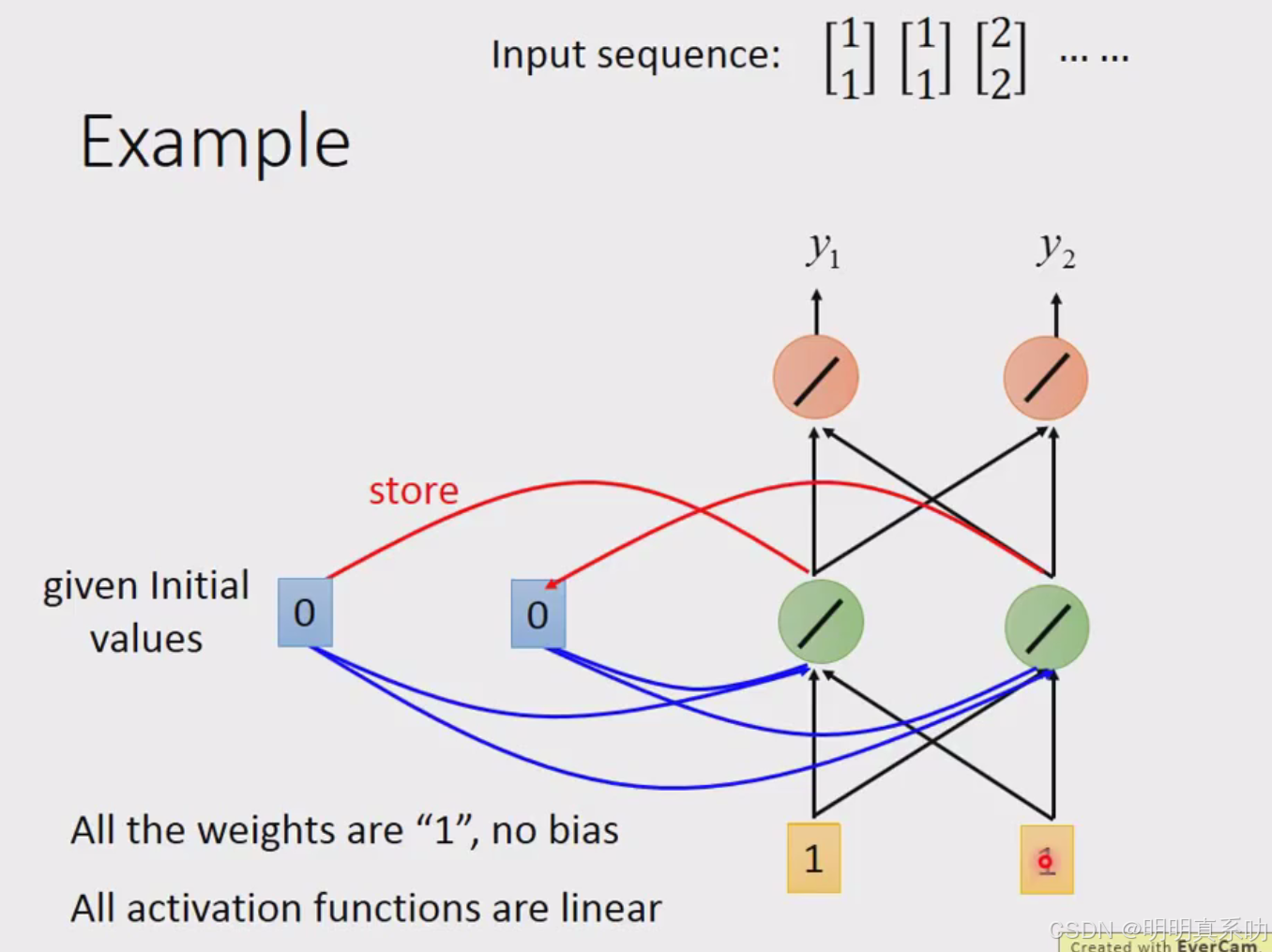
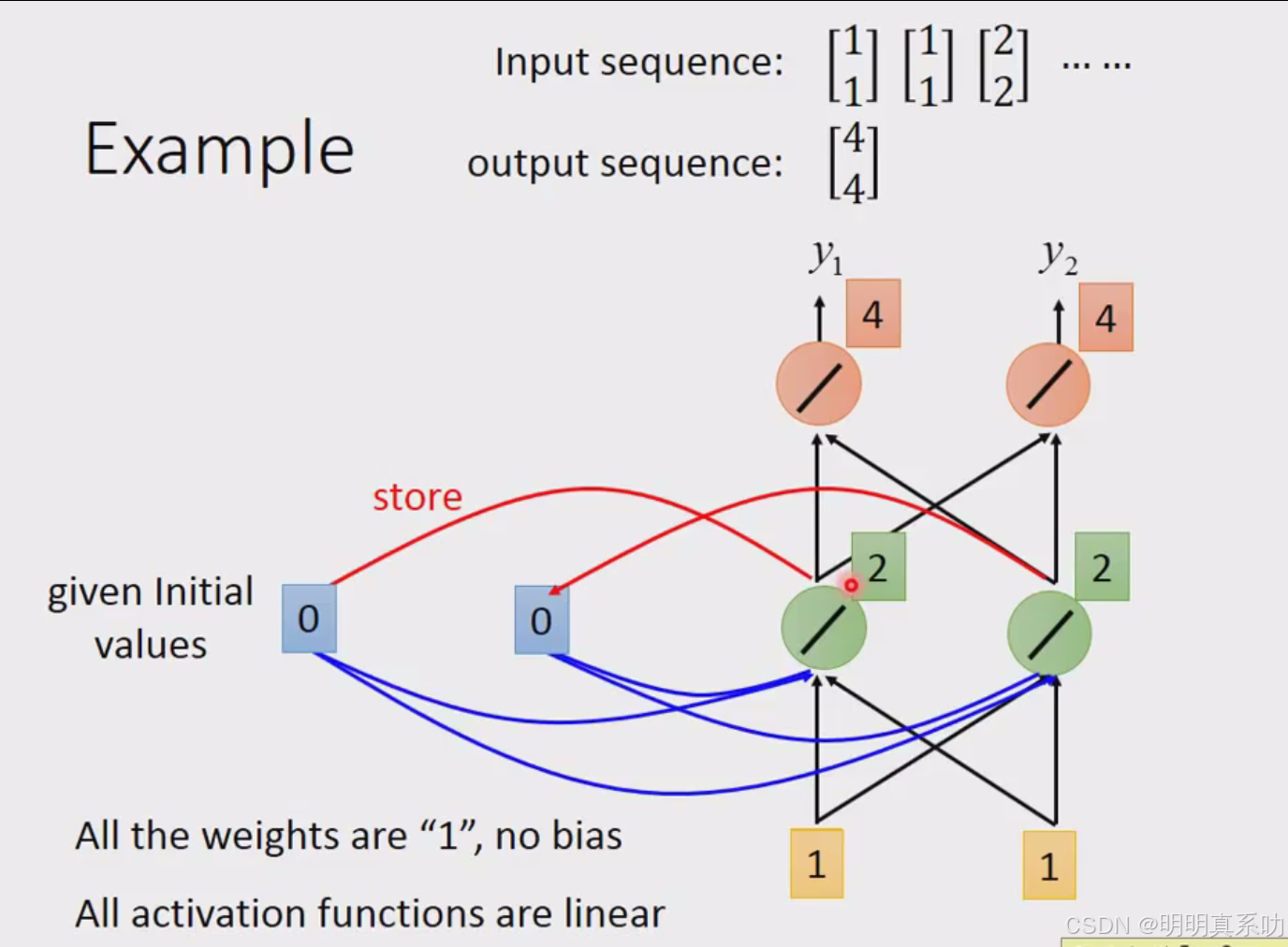
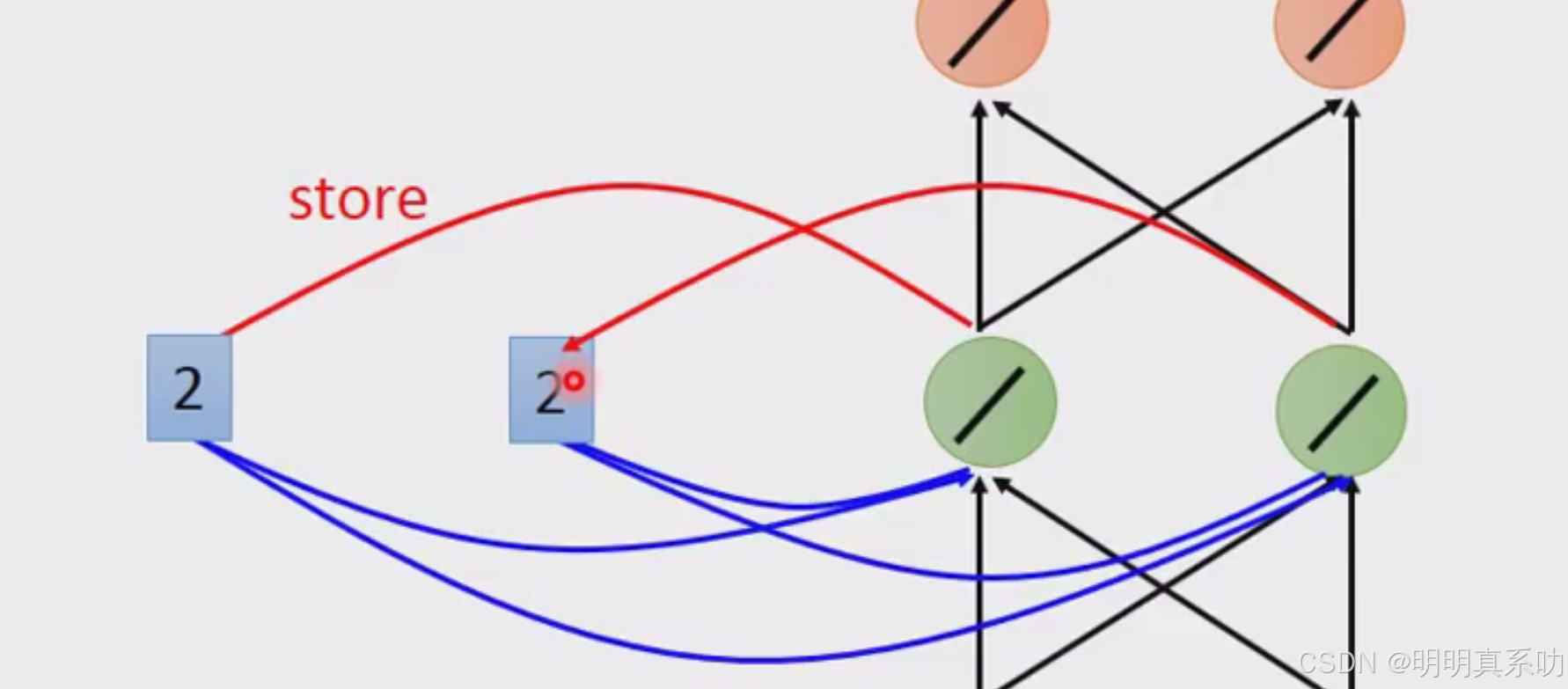
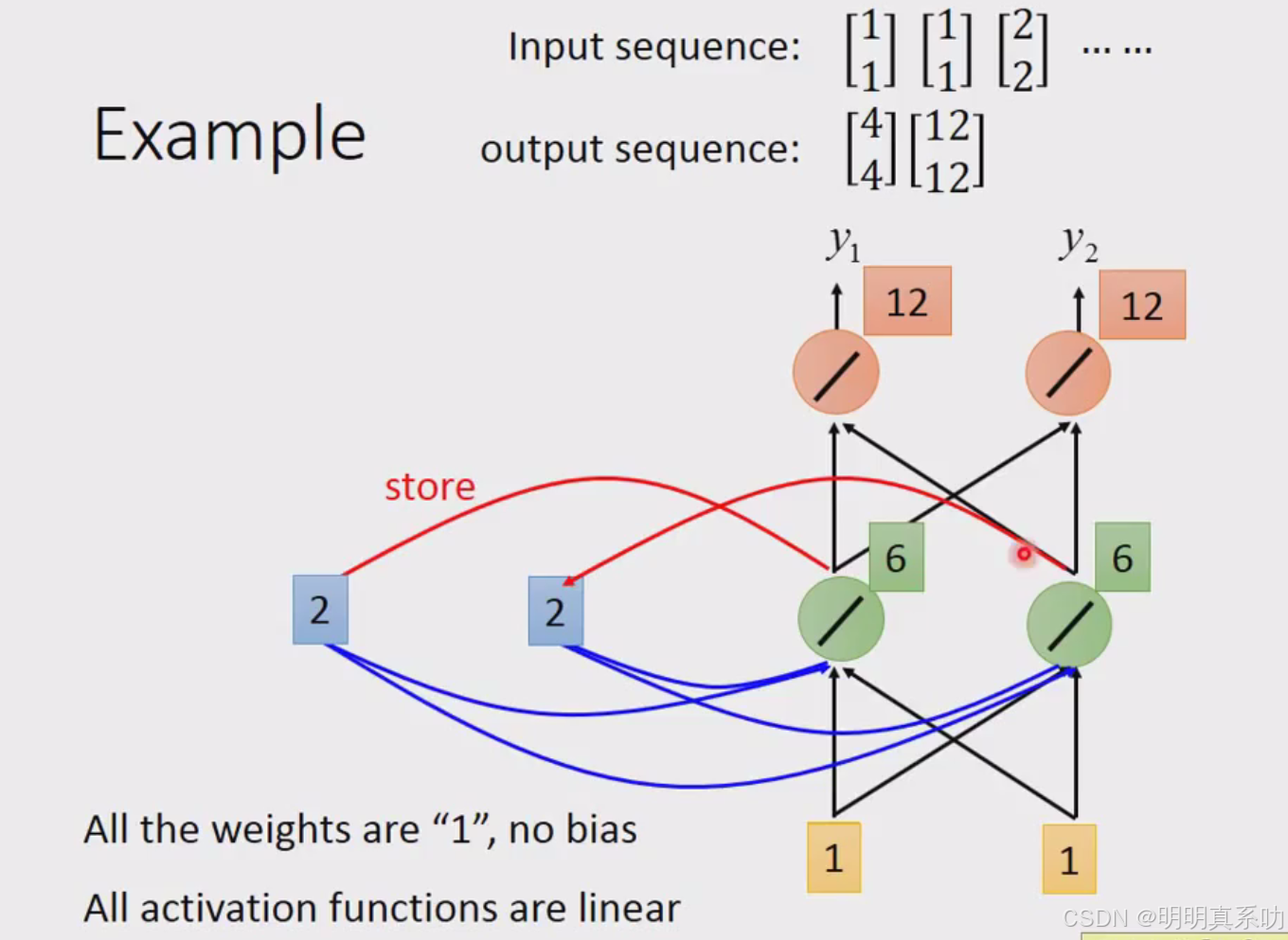
RNN的特别之处就来了,刚刚得出的绿色部分的2会被写入memory中。
然后会被当做input的一部分
然后[6,6]放入memory
以上个结果的计算过程如下:
具体将其运用到我们刚刚的智慧订票系统,如下:
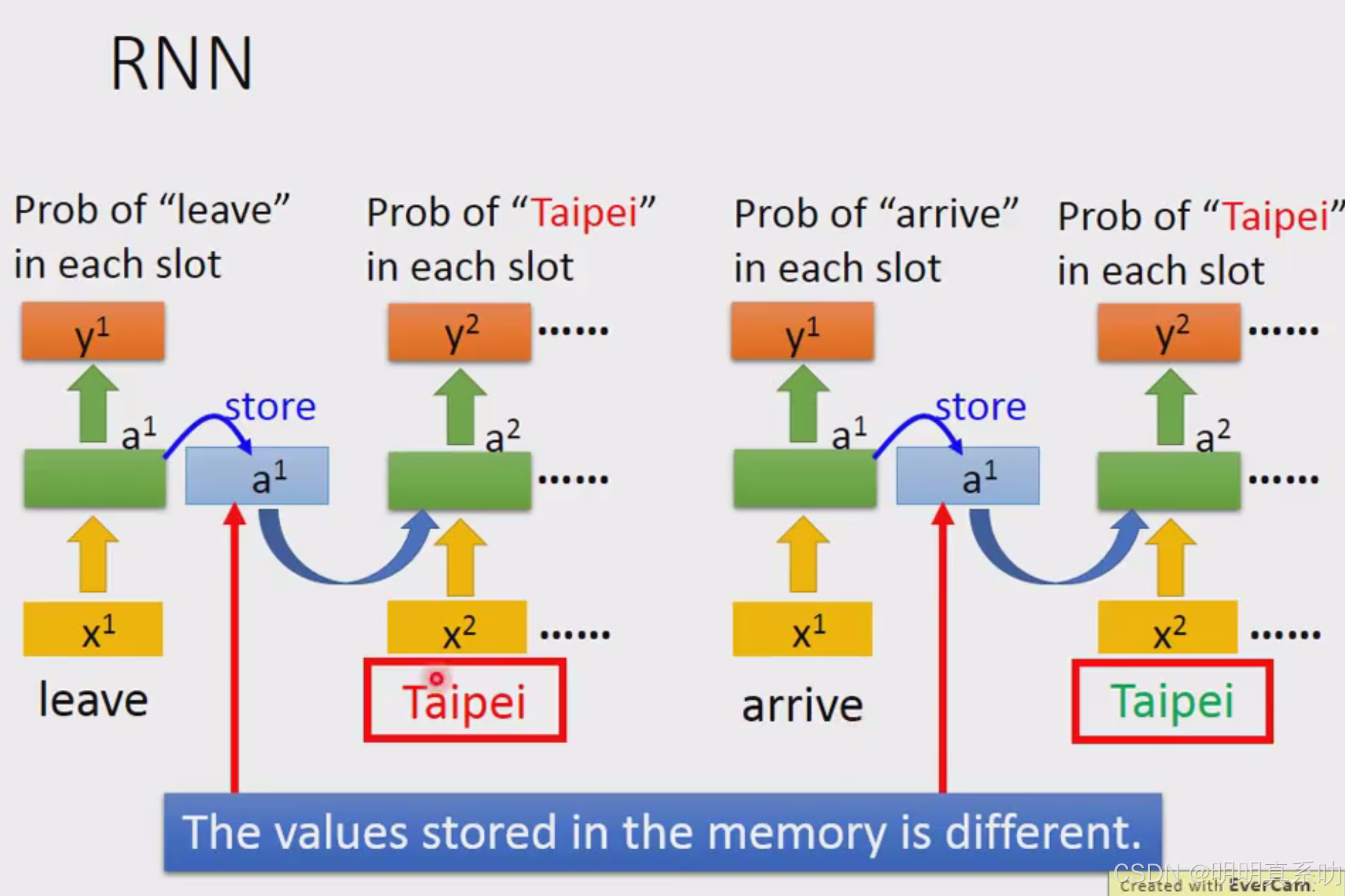
注:这里不是3个network,而是同1个network在3个不同的时间点被使用了3次
所以即使是同一个Taipei的输入,但是由于memory的内容不同,所以其output的结果也不同。
9
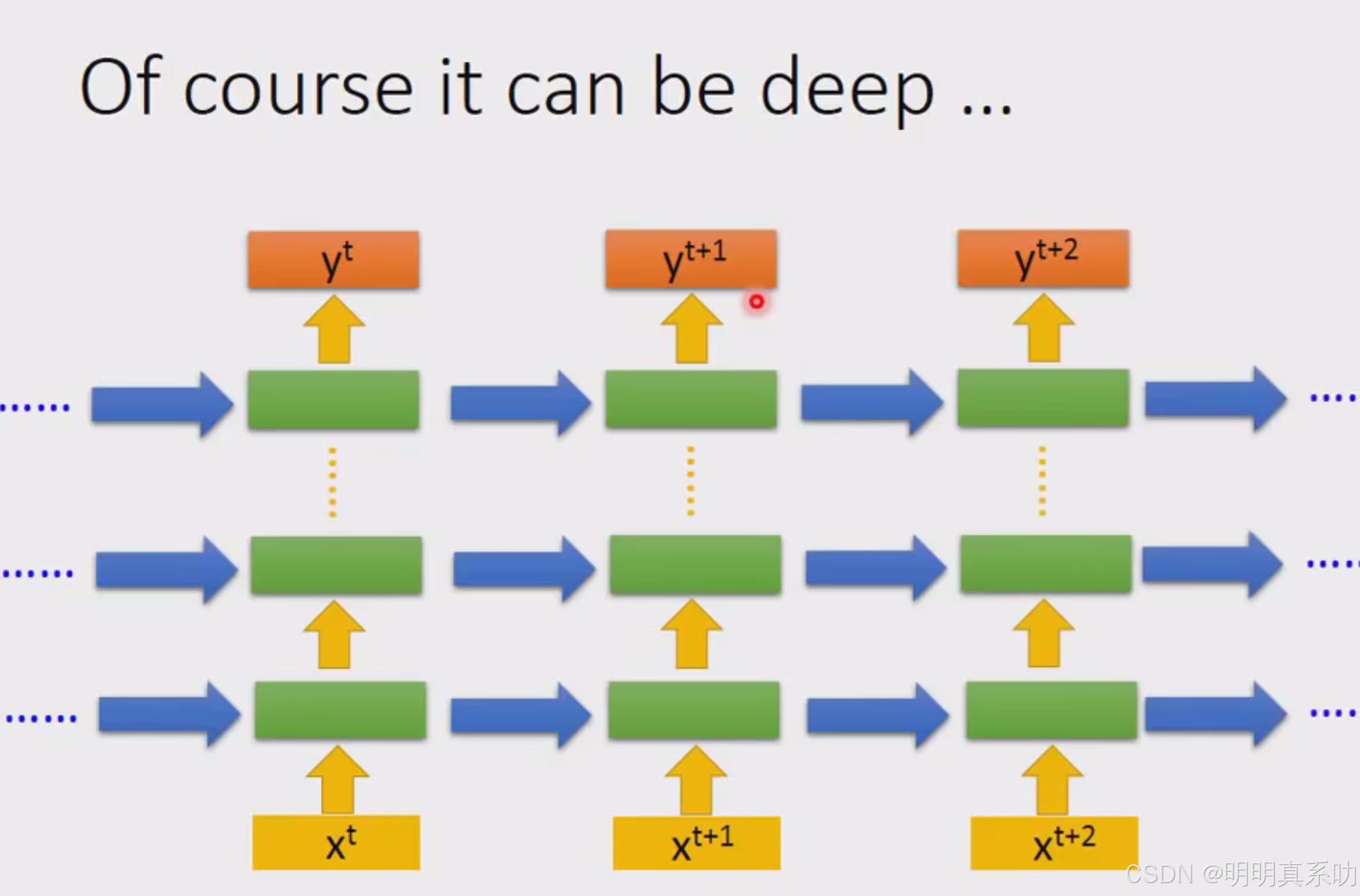
RNN也是可以deep
我们只需把每层的hidden layer的记录在memory,然后再与对应层的input相关联即可
不过input也可能是某一个hidden layer的output罢了。
注:这里不是3个network,而是同一个network在3个不同的时间点被使用了3次
1.2 RNN的变形
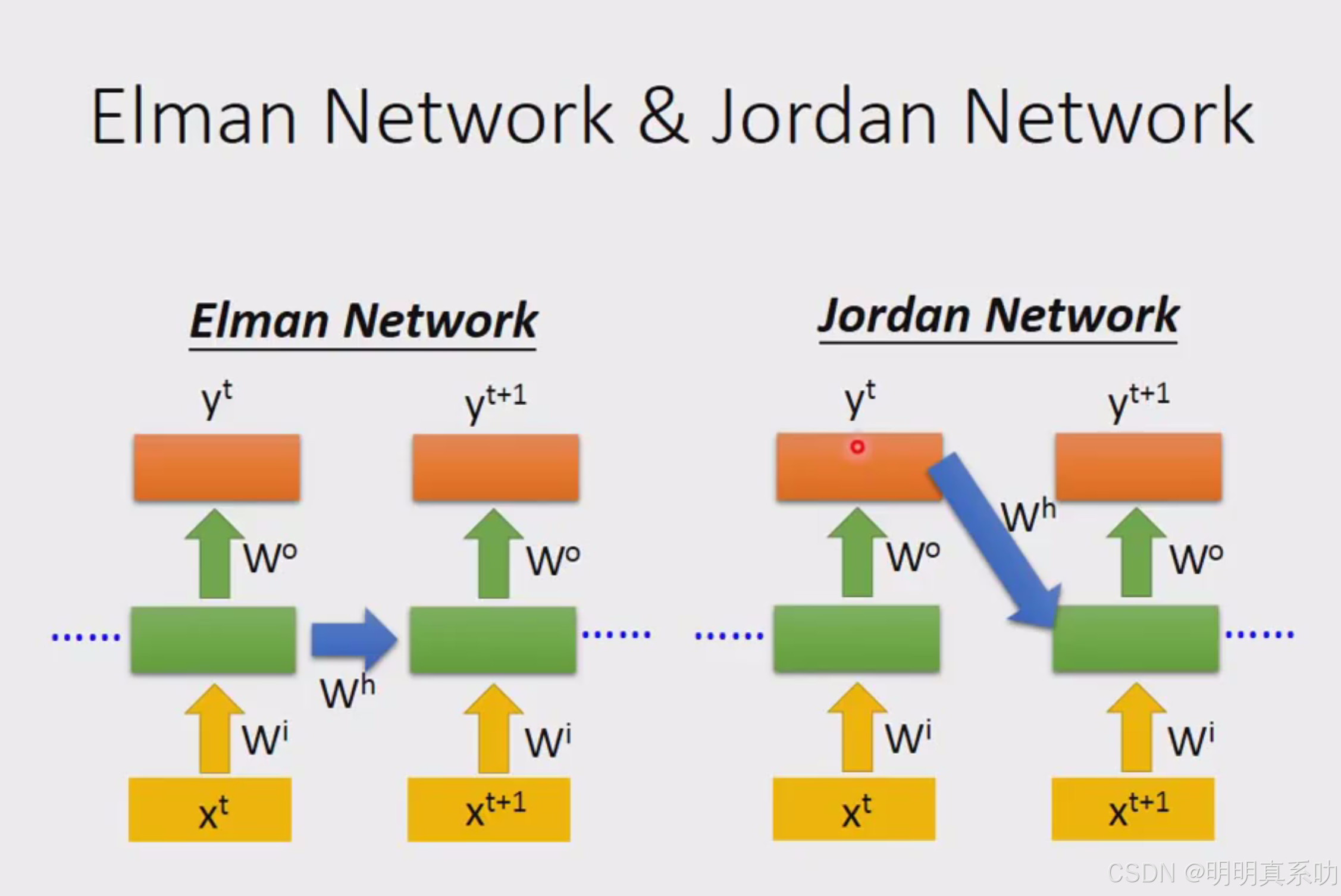
1.Jordan Network
recurrent neural network有不同的变形
我们刚刚学习的是Elman Network(就是记忆hidden layer的值)
而Jordan Network就是把最后output的值记忆下来,然后再倒过去影响input的值。
相比于Elman Network 在Jordan Network里面这个y它是有target的,所以可以比较清楚我们放在memory里面的是什么样的东西。
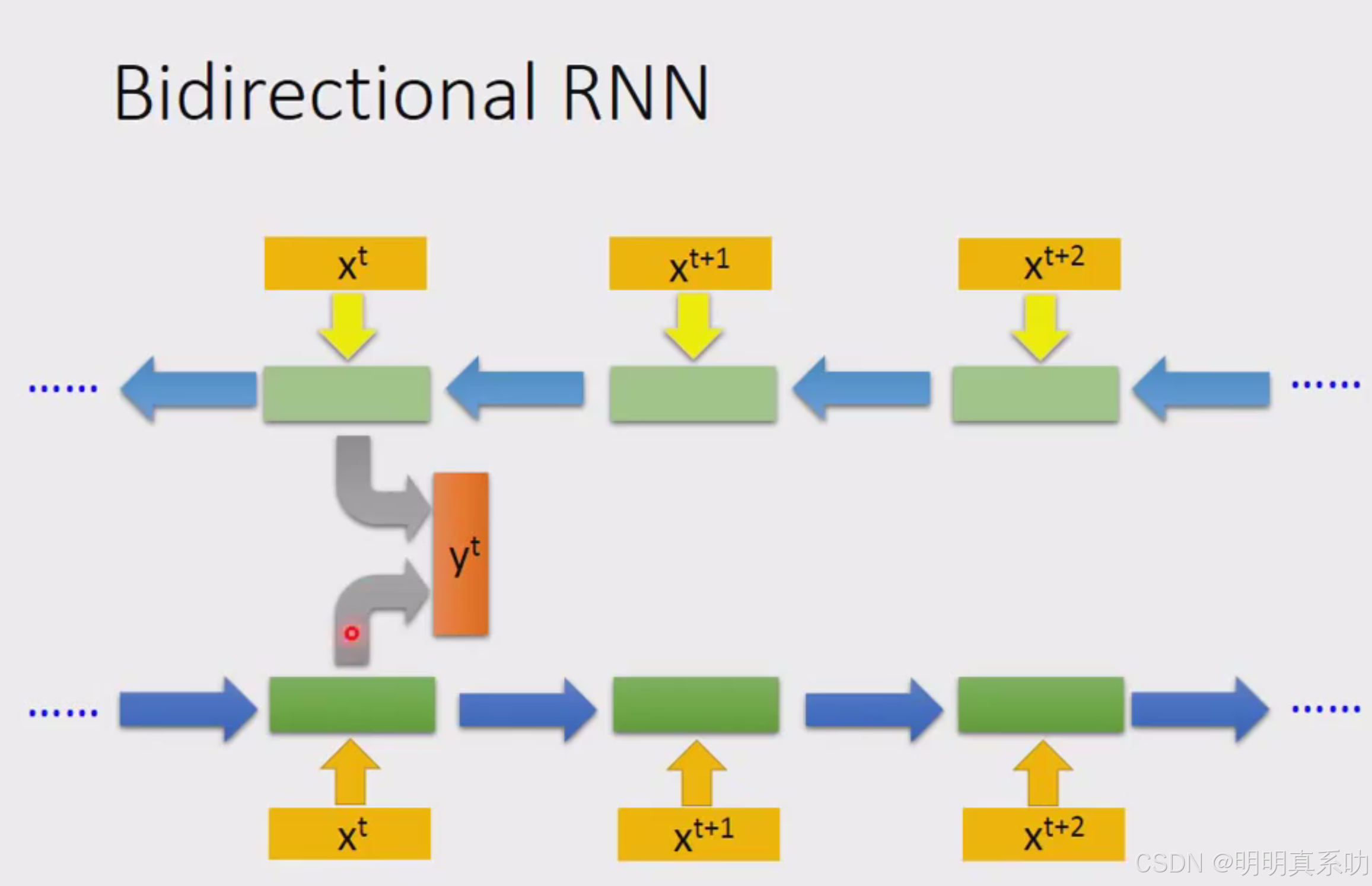
2.Bidirectional RNN(双向性RNN)
你input一个句子的话,它就是从句首一直读到句尾
但是它的读取方向也可以是反过来的
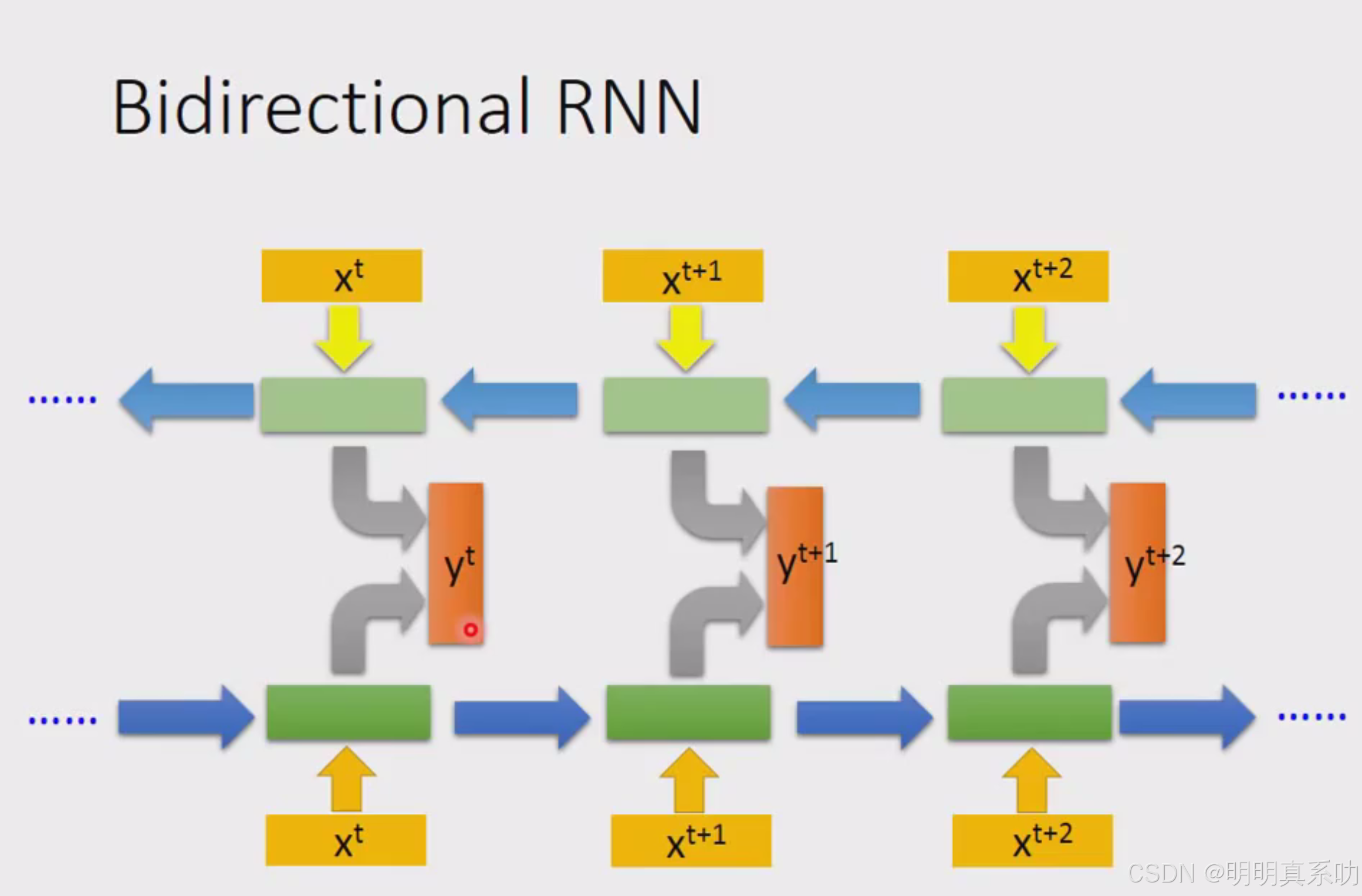
可以同时train一个正向的recurrent neural network,又同时train一个逆向的recurrent network
把这两个recurrent neural network的hidden layer拿出来都接给一个output layer,得到最后的y
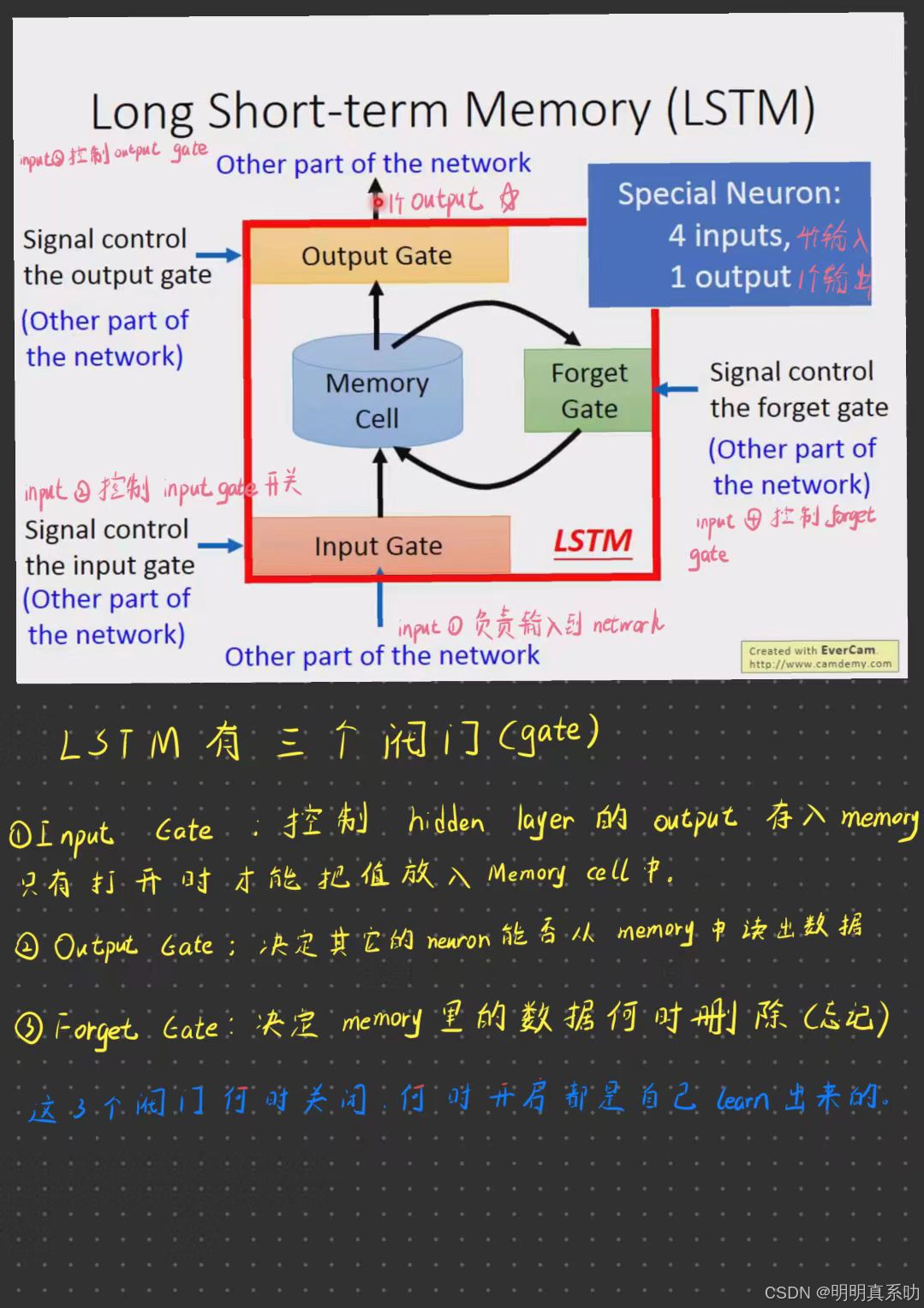
2. Long Short Term Memory(LSTM,长短期记忆网络)
刚才的memory是最简单的
即我们随时都可以把值呢存到memory里面去,也可以随时把值呢从memory里面读出来
但现在比较常用的memory呢,称之为long short term memory(长短期记忆网络)
LSTM通过引入记忆单元(memory cell)和门控机制(gate mechanism),有效地捕捉序列数据中的长期依赖关系。
具体如下:
更详细的结构如下图所示:
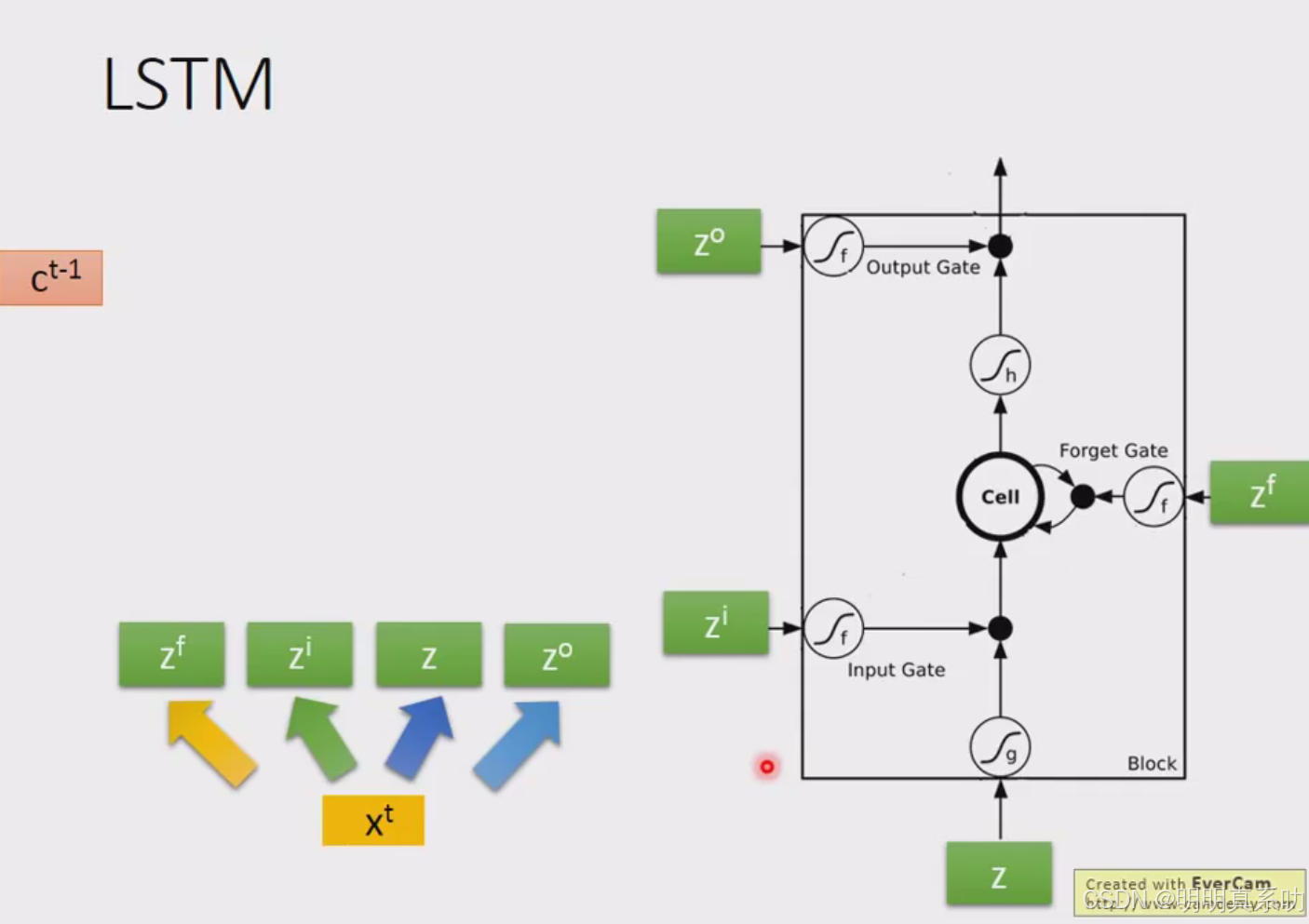
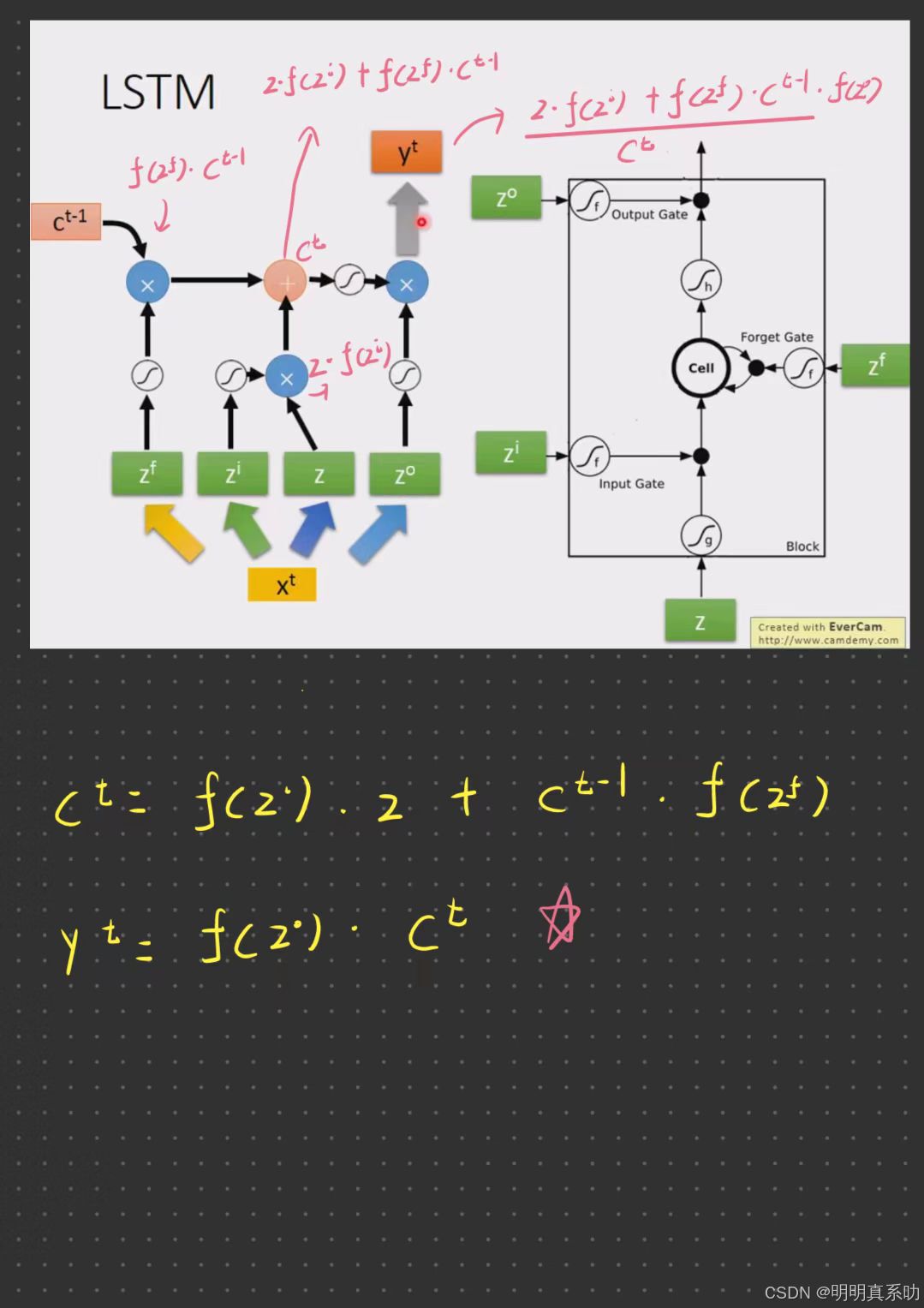
在要被存到cell里面的input叫做z
操控input gate signal叫做zi。
操控Forget Gate 叫做zf
注意:Forget Gate有点反直觉,因为我们说等于1的时候一般是开启,等于0的时候一般是关闭。
这里的zf = 1时,表示任然记住原来的值(保留);zf = 0的时候,则忘记原来的值;。
操作Output Gate 叫做zo。
假设我们现在cell里面在有这个四个输入之前,它里面已经存了值c
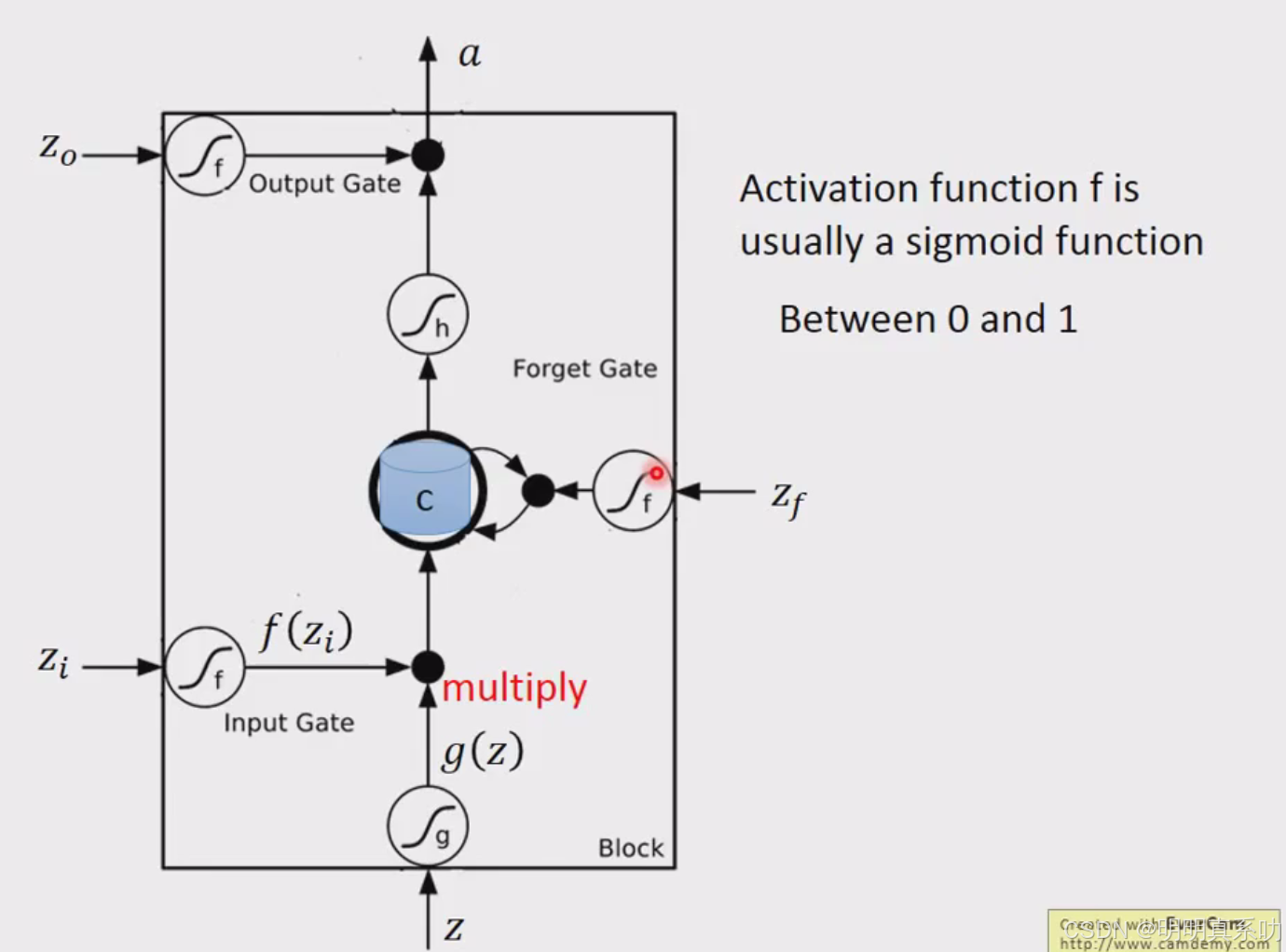
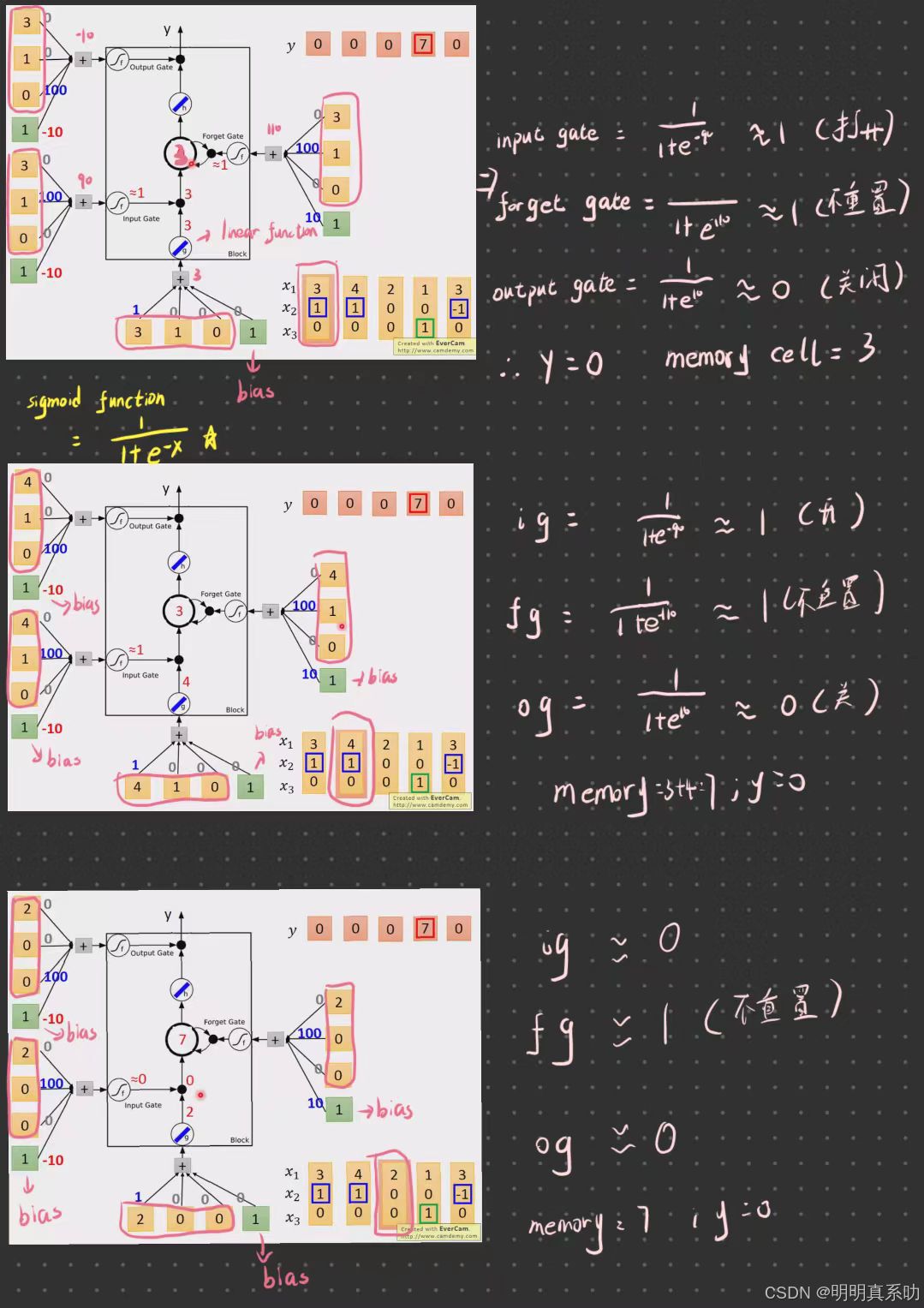
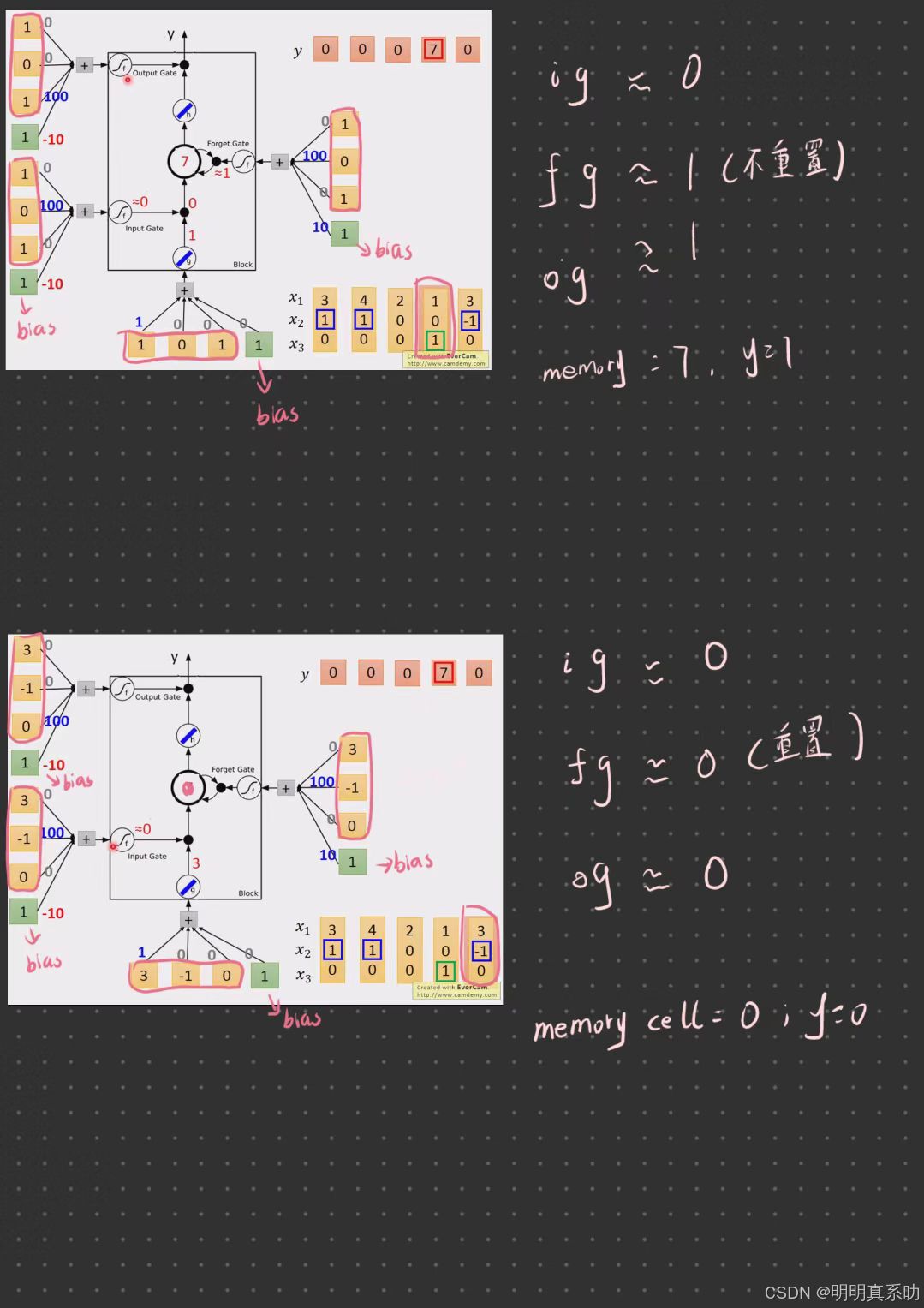
zi、zf跟zo(即控制阀门的input),通过的activation function通常我们会选择sigmoid function。
选择sigmoid方程的意义就是sigmoid方程只是记在0到1之间,而这个0到1之间的值代表了这个gate被打开的程度。
如果activation function的output是1,代表gate是处于被打开的状态;反之,代表这个gate是被关起来的。
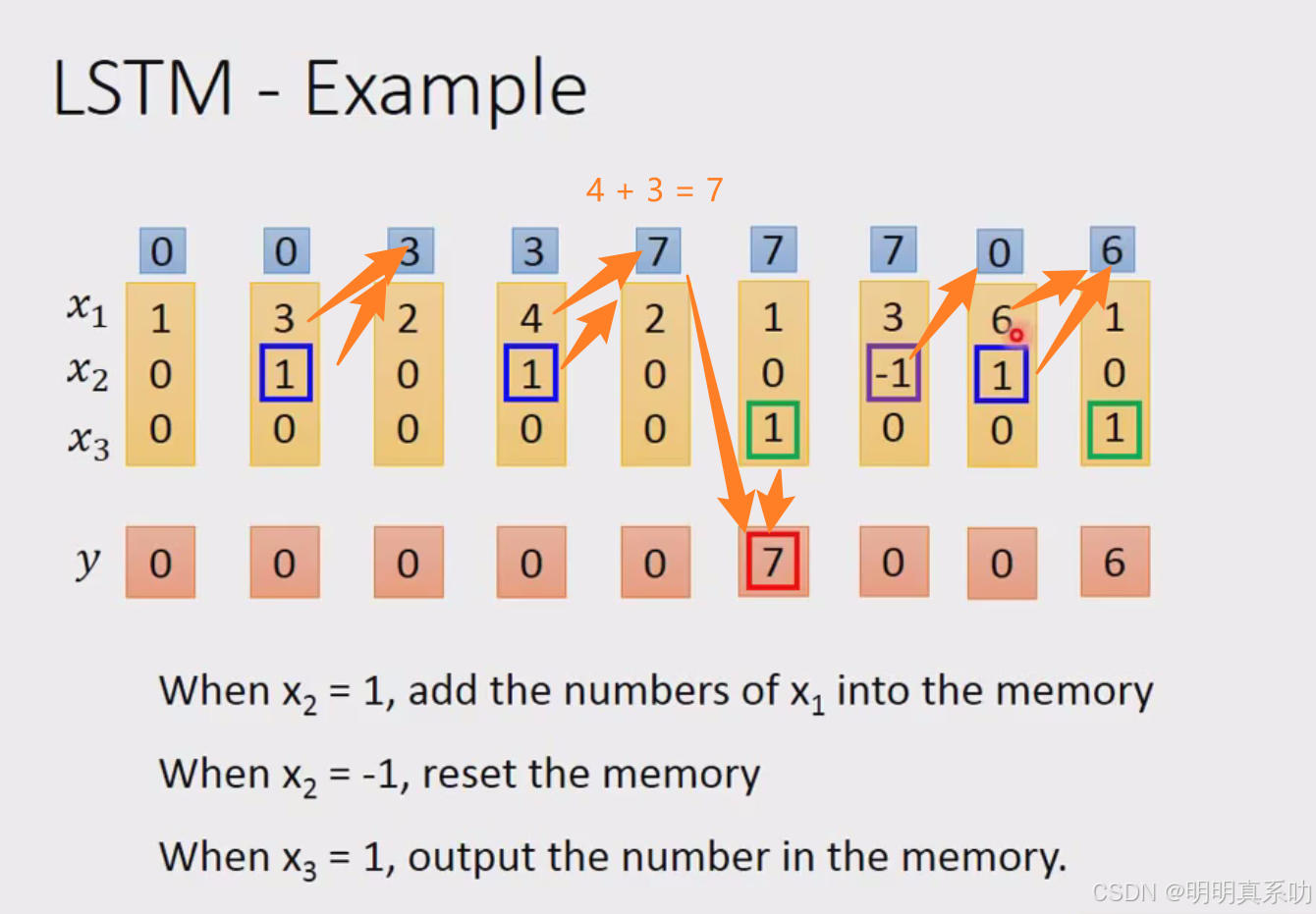
举个例子说明:
network 只有一个LSTM cell
input都是三维的vector
output都是一维的vector
如下如所示
我们带入到刚刚的memory cell模型中,实际做一下运算
3个input值再乘上3个weight的再加上bias,得到activation function 的 input
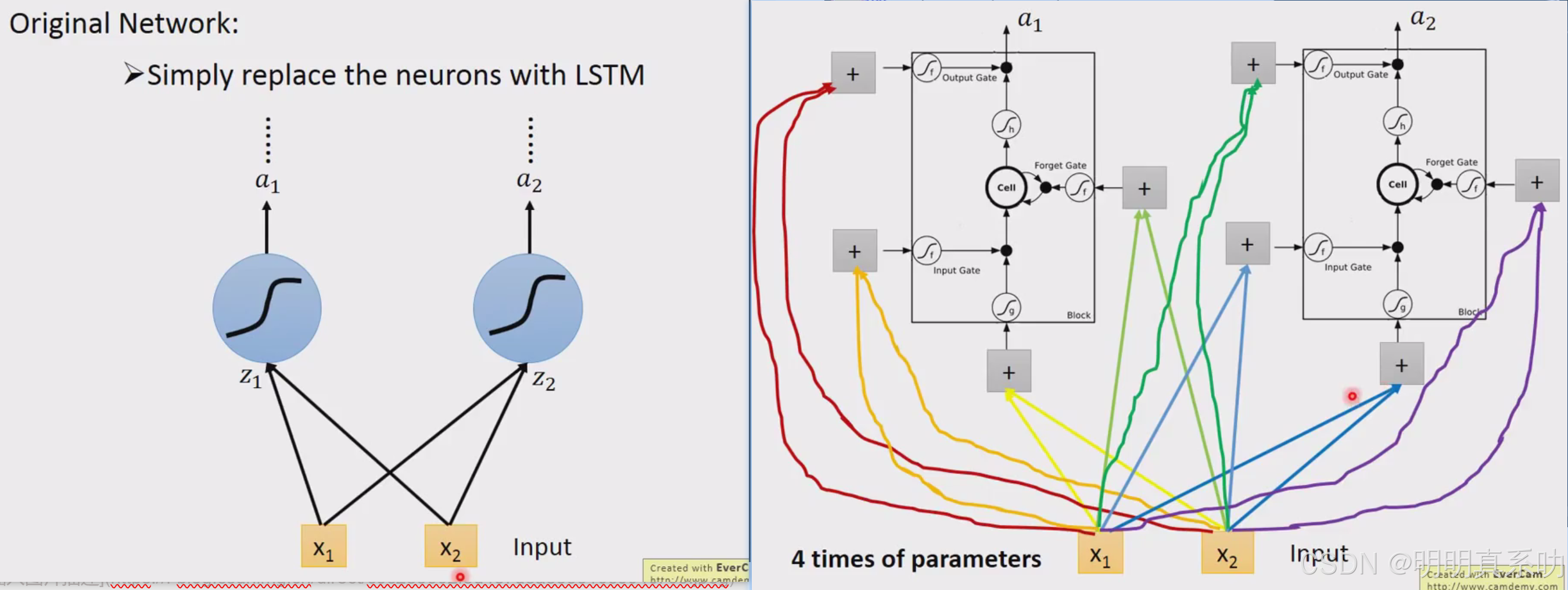
其实我们在学习LSTM的使用,无非就是把neuron换成LSTM就可以了
但是又有所差别
对于LSTM来说,这四个input都不一样**(因为weight和bias不同)**。
一般的neural network只需要部分的参数,但LSTM还要操控另外三个gate,所以它需要四倍的参数。
但是我们还是无法深刻的体会到Recurrent Neural network的模型。
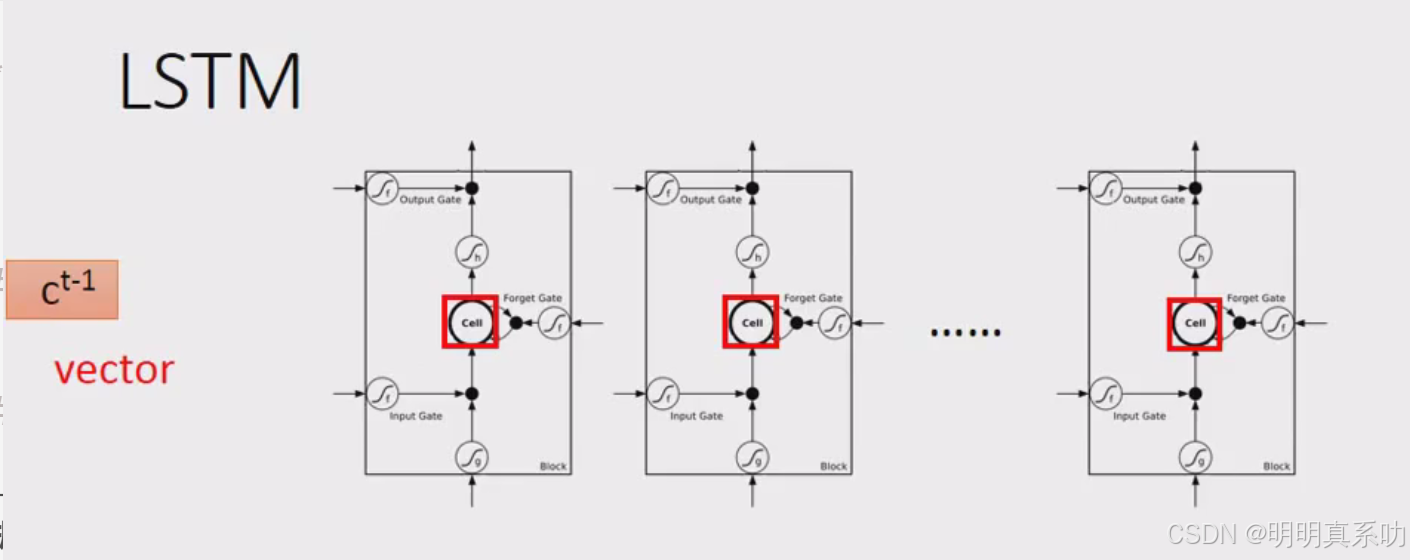
假设一整排的LSTM里面每一个memory里面都存了一个scalar(值),把所有的scalar接起来就变成了一个vector,写为ct-1
每一个memory里面存的scalar就代表这个vector里面的一个dimension
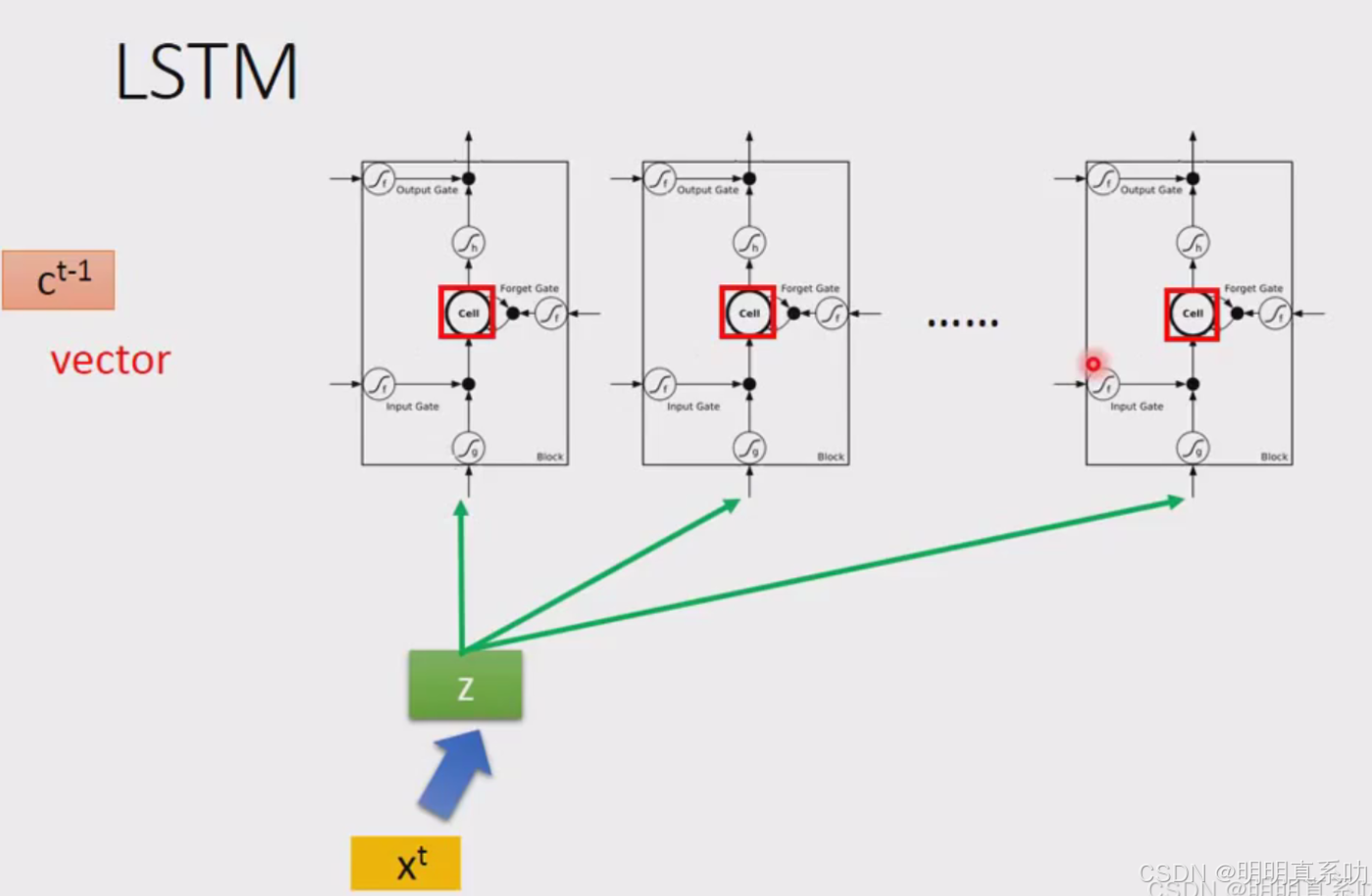
在时间点t时input一个vector xt,把xt乘上一个matrix变成z
z个vector的每一个dimension就代表了操控每一个LSTM的input(就正好是LSTM的memory cell的数量)
第一维就丢给第一个cell,第二维就丢给第二个cell,以此类推。
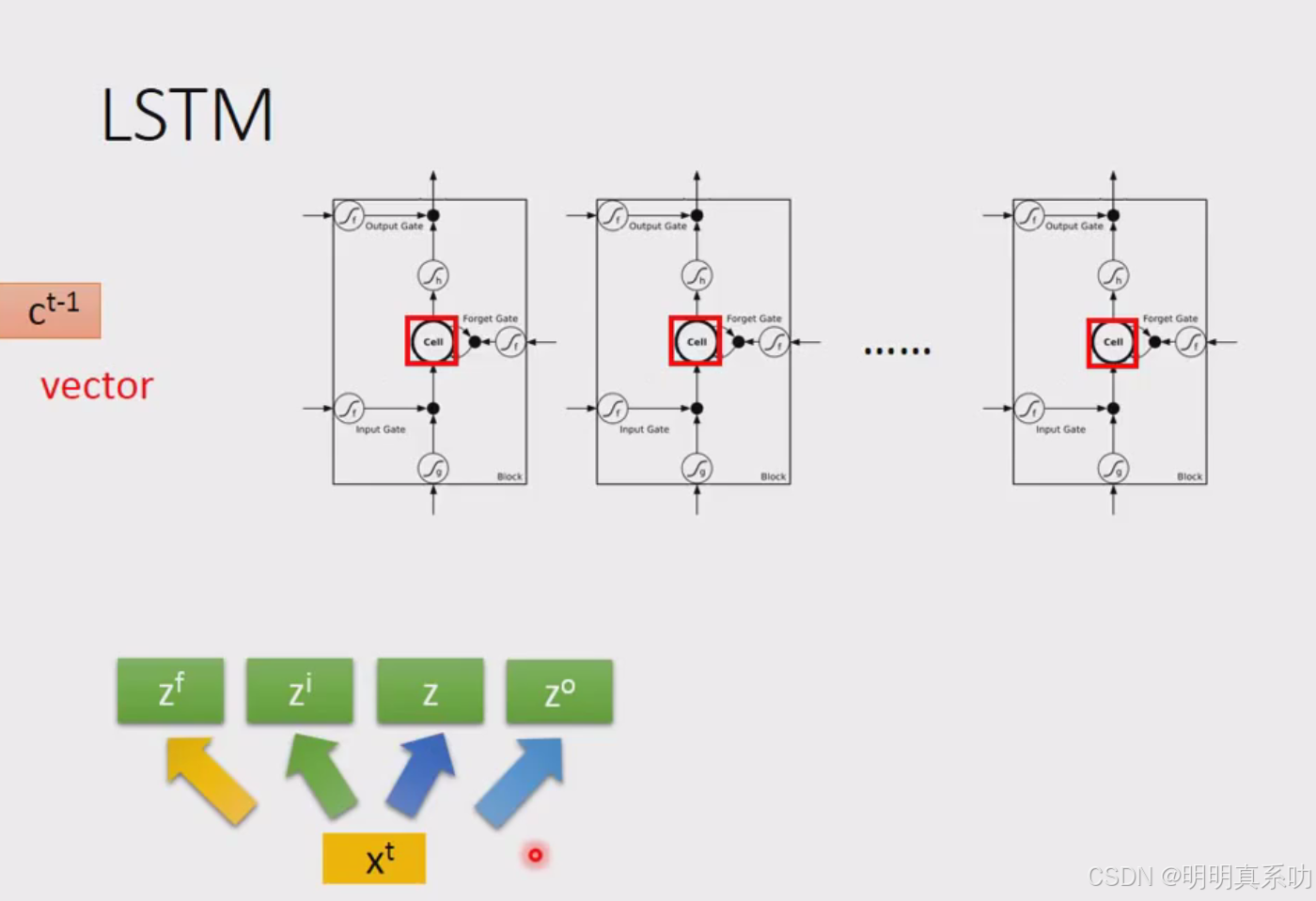
xt 也会乘上一个transform 得到zi
同z一样,zi的每一个dimension都会去操控一个memory,不过是操控其input gate
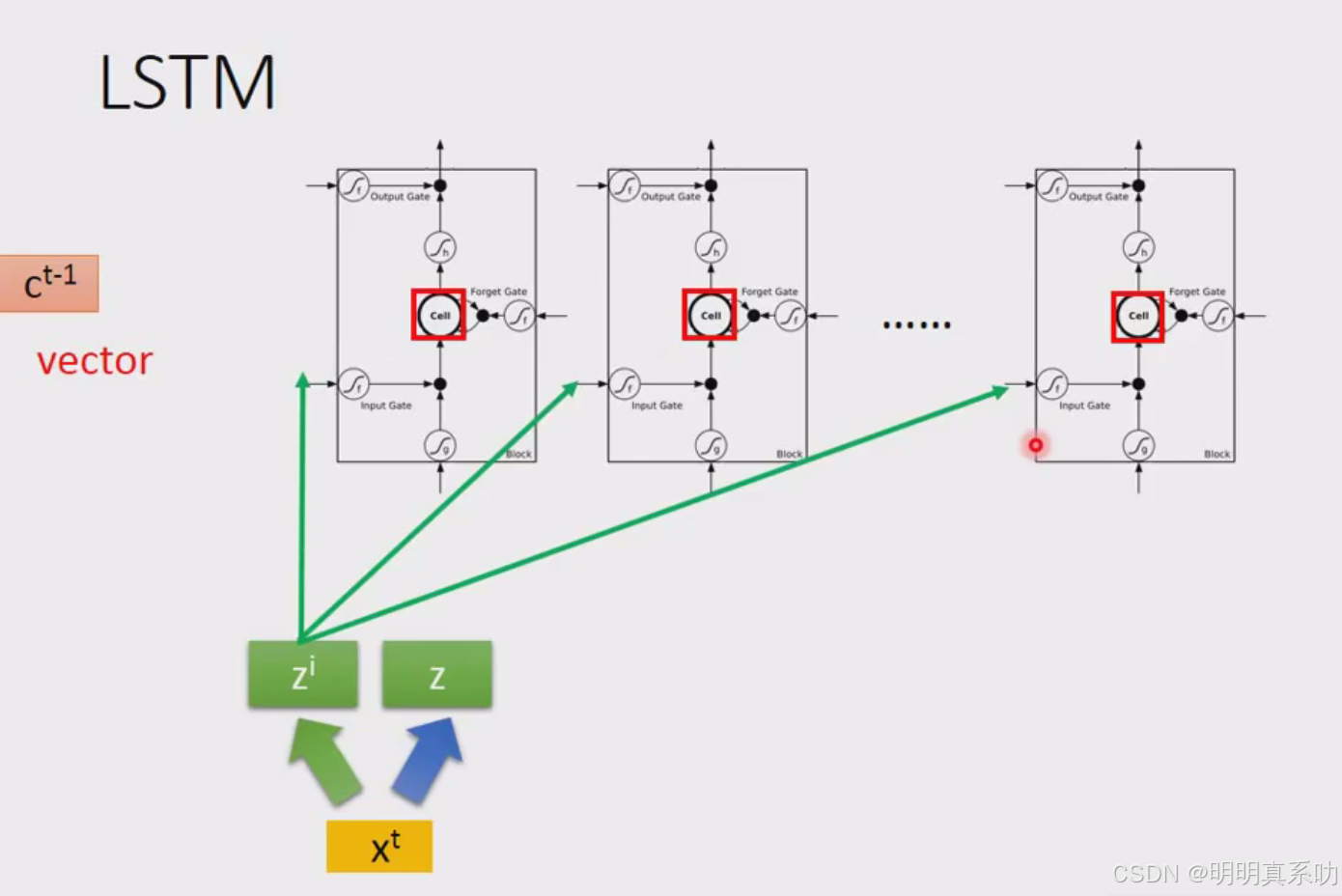
这四个vector合起来就会去操控这些memory cell的运作
注意:这四个z其实都是vector丢到memory里面的值其实只是每一个vector的一个dimension
因为每一个input的dimension都是不一样的,所以每一个cell input值都会是不一样,但是所有的值是可以共同一起被运算
计算过程如下:
这个process就反复的继续下去,在下一个时间点input xt+1 重复上述操作即可。


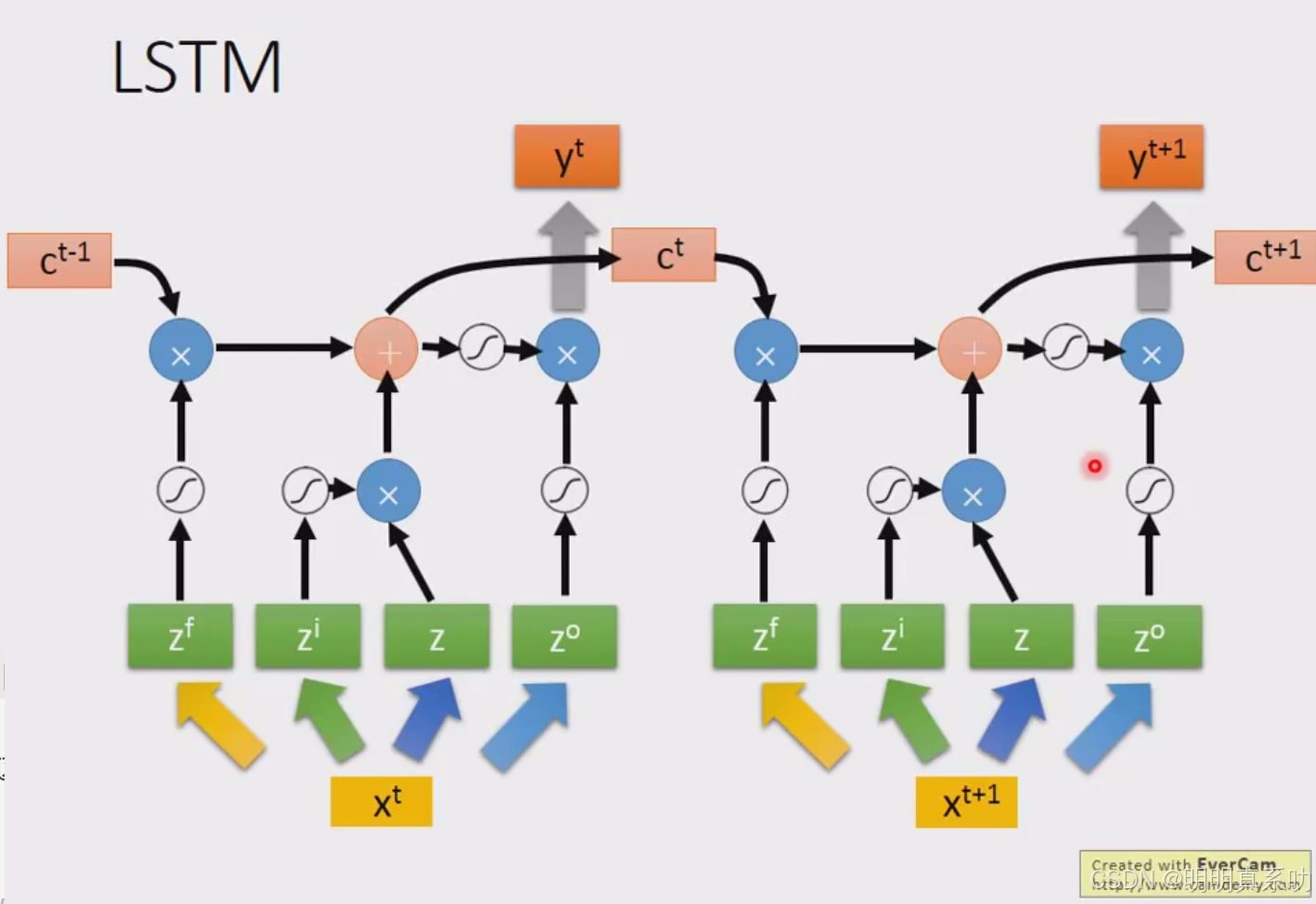
2.1 LSTM最终形态
但是这个不是LSTM的最终形态,这个只是一个si3plified version(简化版本)
真正的LSTM会把hidden layer的输出呢接进来,当做下一个时间点的input。
也就是说下一个时间点操控这些gate的值不是只看那个时间点的input xt+1,还看前一个时间点的output ht。
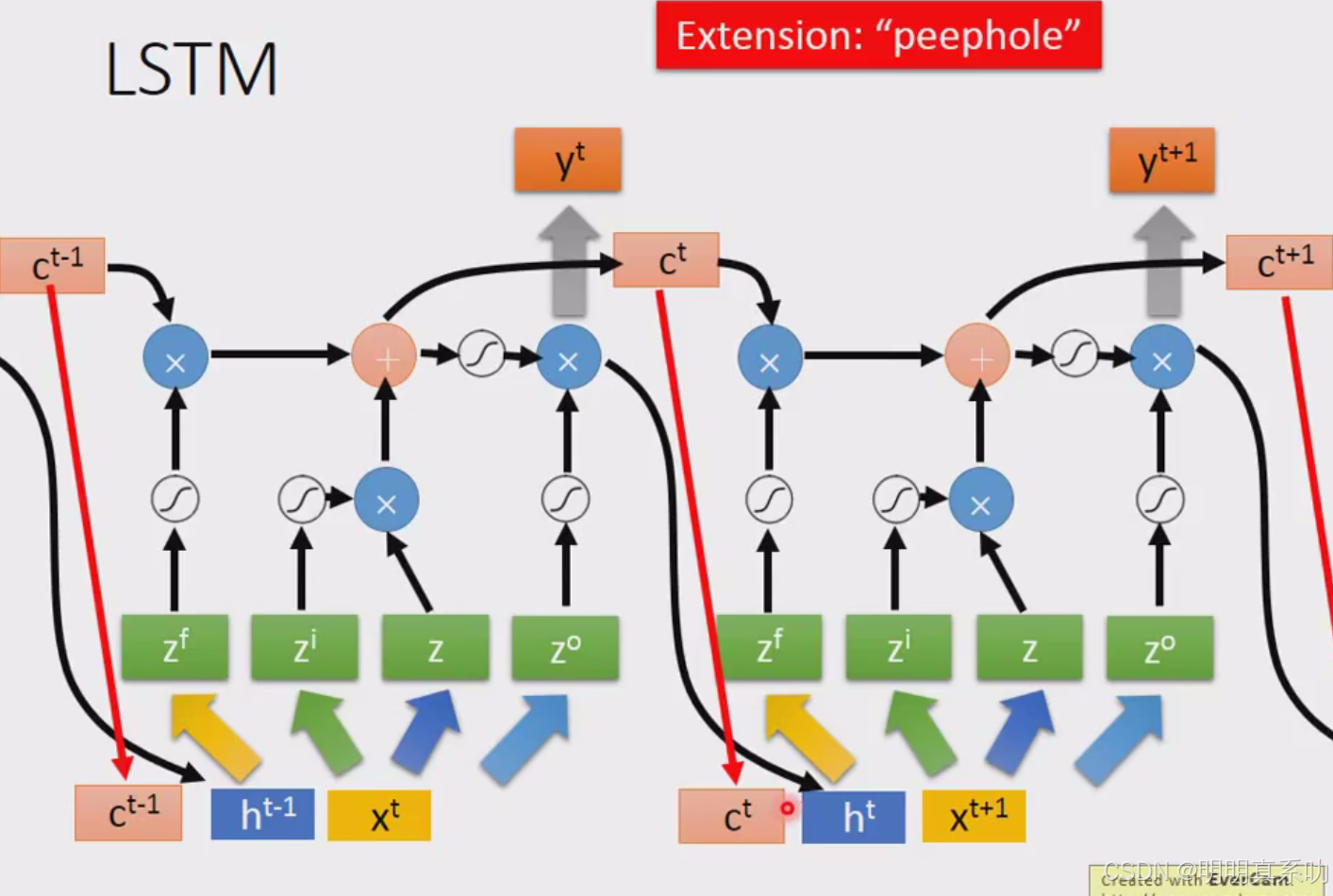
其实还不止这样
还会加一个东西叫做peephole(窥视孔)
peephole(窥视孔)就是把存在memory cell里面的值也拉过来作为input
所以在操纵LSTM的四个gate的时候
同时考虑了x、同时考虑了h、同时考虑了c
把这三个vector并在一起乘上4个不同的transform,得到这四个不同的vector再去操控LSTM。
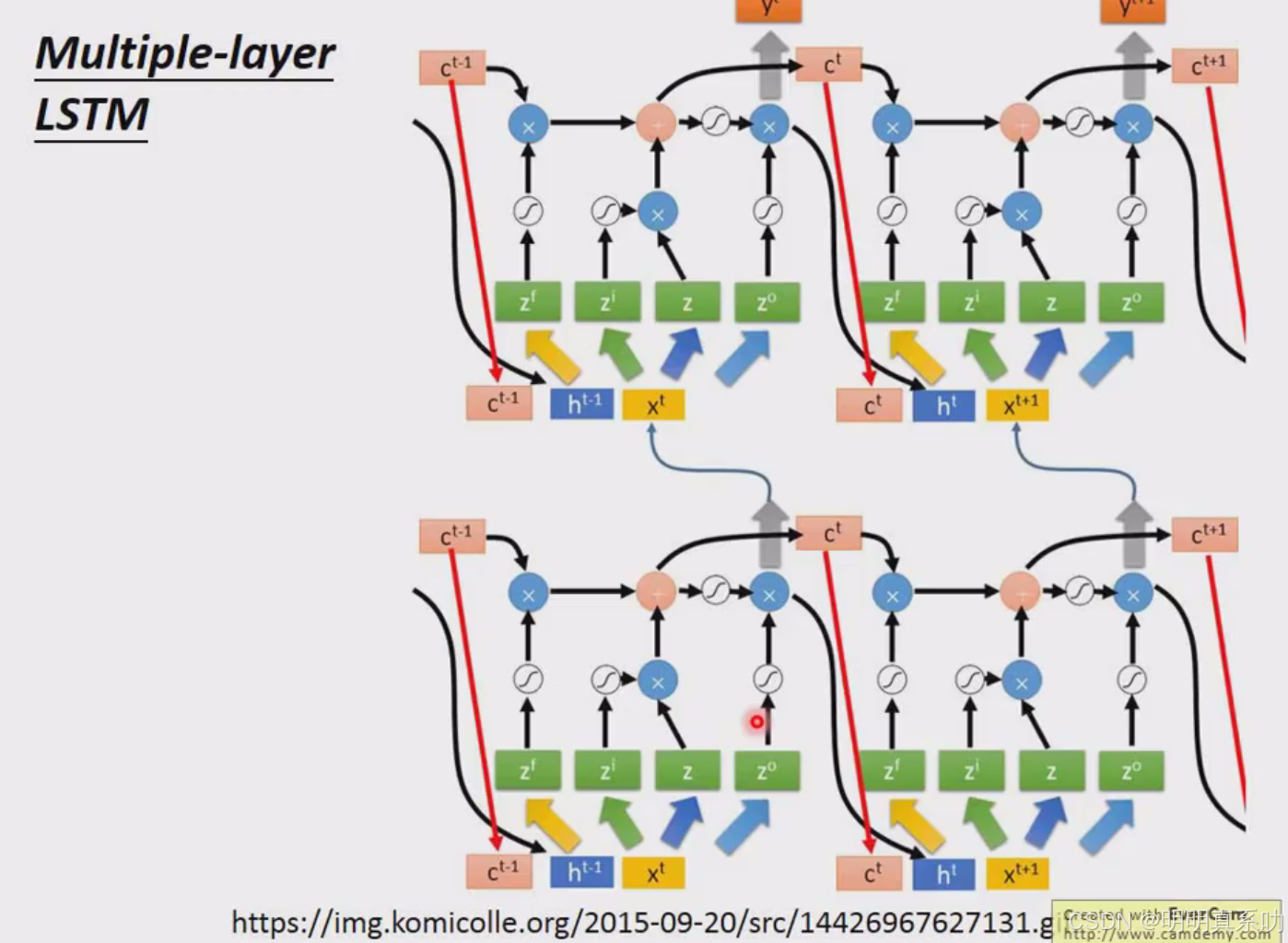
通常不会只有一层,一般要叠个五六层,如下图所示
非常复杂
当用RNN做了什么事情的时候,其实就是用LSTM。

总结
本周因为要准备考试和课程论文,进度缓慢,考试完之后需要加快进度。
本周学习了深度学习的基础知识和操作,内容涵盖了数据操作、数据运算、数据预处理以及循环神经网络(RNN)和长短期记忆网络(LSTM)的复习。在张量的基本操作中,包括张量的创建、形状调整、元素总数计算、初始化和元素赋值。通过使用arange函数,可以创建一个行向量,并讨论了张量元素的默认数据类型及其在内存中的存储方式。我还学习了如何通过shape属性访问张量的形状,以及如何使用numel方法获取张量中元素的总数。此外,还详细介绍了reshape函数的使用,展示了如何调整张量的形状而不改变其元素数量和值。在数据运算部分,学习了张量的算术运算、连结、逻辑运算和求和。通过示例代码,演示了如何对相同形状的张量进行按元素的算术运算。我还学习了如何使用torch.cat函数将多个张量连结在一起,以及如何通过逻辑运算符构建二元张量。此外,我还学习了张量的求和操作,以及广播机制的使用,后者允许在不同形状的张量之间进行逐元素操作。最后,我还学习了如何通过索引和切片访问和修改张量中的元素。包括如何使用负索引选择元素,以及如何为多个元素赋值相同的值。数据预处理部分,学会了使用pandas库对CSV文件中的数据进行读取、处理缺失值、转换为张量格式的步骤,展示了如何将原始数据预处理并转换为适合深度学习模型输入的张量格式。我创建了一个人工数据集,学会了如何使用pandas处理缺失值,包括使用均值填充数值缺失和处理类别值的缺失。最后,在数据预处理部分学会了如何将处理后的数据转换为张量格式,以便于后续的深度学习模型训练。
最后还对RNN和LSTM的基础概念部分进行了复习。
下一周计划动手深度学习内容,学习线性代数和求导的手撕实现。