Python爬虫案例与实战:爬取豆瓣电影简介
本章案例将介绍如何爬取豆瓣电影简介,以此帮助读者学习如何通过编写爬虫程序来批量地从互联网中获取信息。本案例中将借助两个第三方库----Requests库和 BeautifulSoup库。通过Requests库获取相关的网页信息,通过 BeautifulSoup库解析大体框架信息的内容,并且将局部信息中最关键的内容提取出来。通过使用第三方库,读者可以实现定向网络爬取和网页解析的基本目标。
3.1确定信息源
首先,需要明确要爬取哪些内容,并精确到需要爬取的网页。在本章中需要爬取电影的简介,因此选择信息较为全面的豆瓣电影。
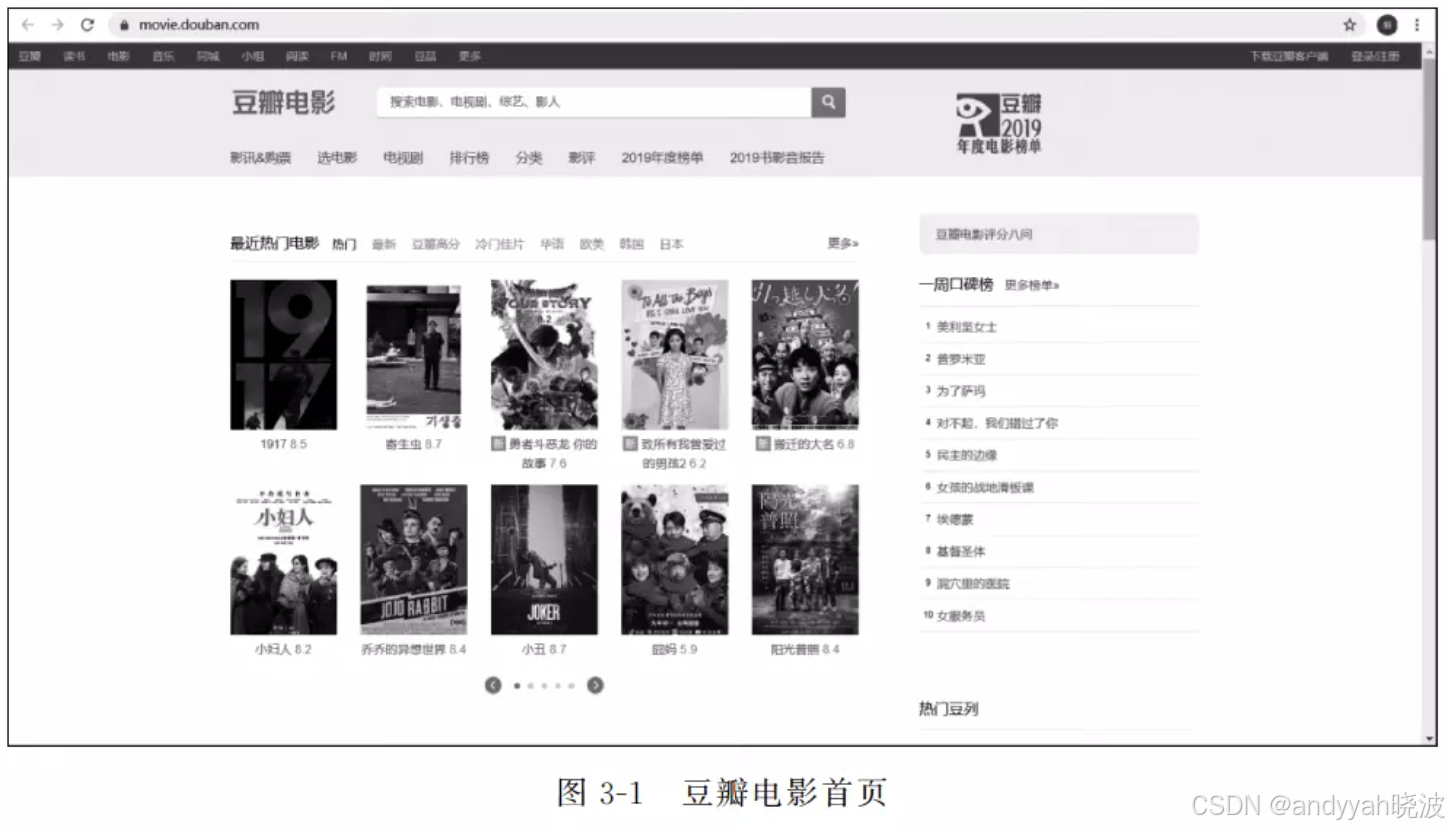
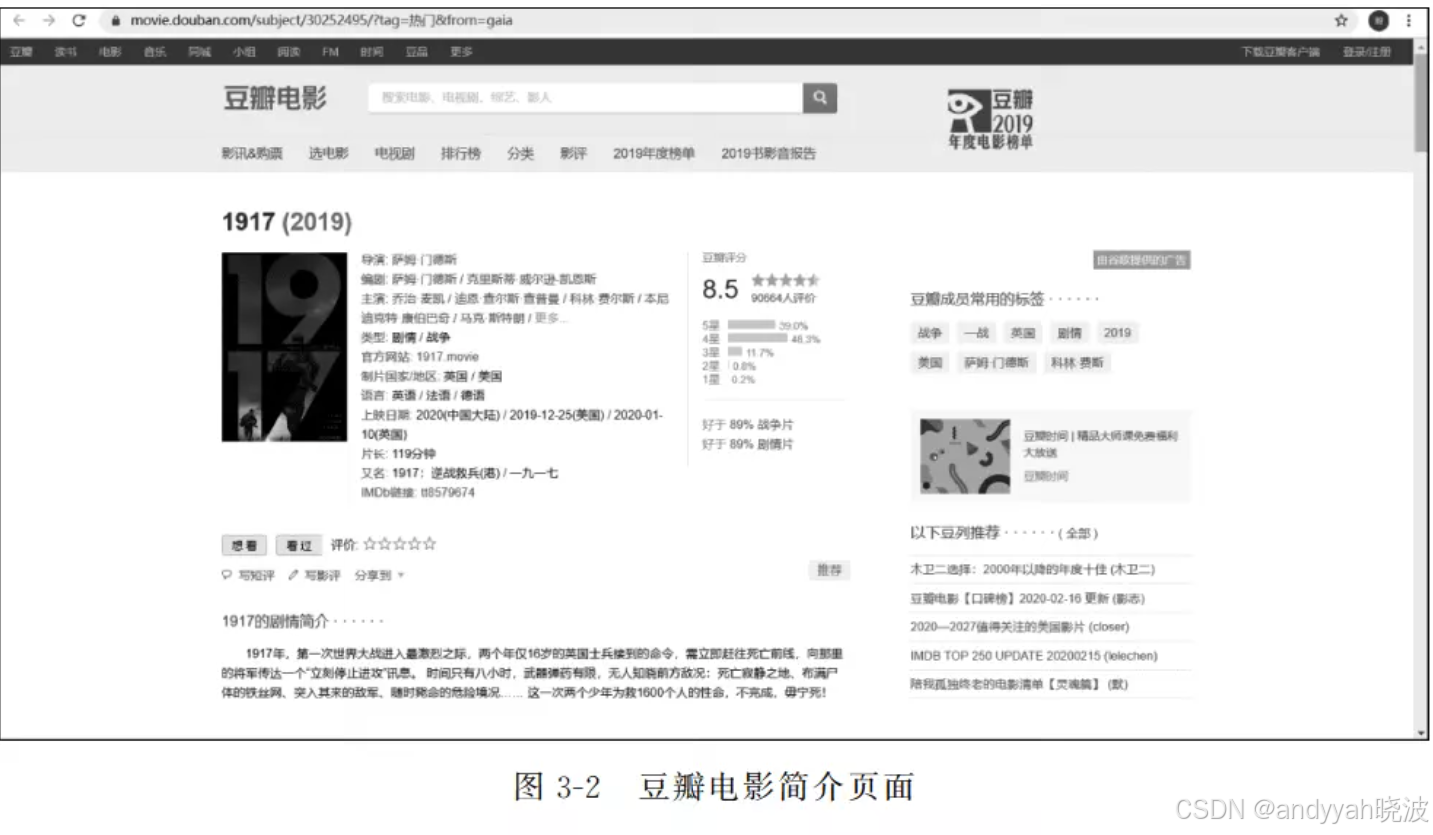
进入“豆瓣电影”首页,如图3-1所示,可以看到各种推荐的电影。选择其中任意一部电影,进入电影简介页面,如图3-2所示。可以发现每部电影的简介页面都具有相似的结构,这为编写爬虫程序提供了极大的方便。这意味着只需要以某部电影的电影简介页面为模板编写爬虫程序,此后便可以运用到豆瓣网站中其他所有电影简介的页面。
3.2获取网页信息
确定了需要爬取的网页后,需要如何获取这些信息呢?要知道网页是一个包含HTML标签的纯文本文件。可以通过使用 Requests库的request()方法向指定网址发送请求获得的文本文件。注意,在使用 Python第三方库前需要在本机上安装第三方库,可以使用pip方式或者其他方式安装。
1.Requests库的两个主要方法
下面先来简单介绍本实验需要用到的 Requests库的两个主要方法。
(1)requests.request()方法。该方法的作用是构造一个请求,是支持其他方法的基础方法。
(2)requests.get()方法。该方法是本案例需要用到的一个获取网页的方法,会构造一个向服务器请求资源的 Request对象,然后返回一个包含服务器资源的 Response对象。其作用是获取 HTML网页,对应于HTTP 的 GET。调用该方法需要一些参数。
- requests.get(url,params= None,**kwargs)。
- url:需要获取页面的URL链接。
- params:可选参数,URL 中的额外参数,字典或字节流格式。
- **kwargs:12个控制访问的参数。
2.Response对象机器属性
Response对象包含服务器放回的所有信息,也包含请求的 Request信息。该对象具如下属性。
- status_code:HTTP请求的返回状态,200表示链接成功。只有链接成功的对象内容才是正确有效的,而对于链接失败的行为则产生异常的结果。这里可以使用raise_for_status()方法。该方法会判断 status_code是否等于200,如果不等于则产生异常requests.HTTPError。
- text:HTTP 相应内容的字符串形式,也即 URL对应的页面内容。这部分也是爬虫需要获得的最重要部分。
- encoding:从HTTP header 中猜测的响应内容的编码方式。选择正确的编码方式才能得到可读的正确信息内容。
- apparent_encoding:从内容中分析出响应内容的编码方式。
学习完上面的基础知识,就可以利用Requests库编写程序来获取“豆瓣电影”首页的信息。获取“豆瓣电影”首页信息的程序如图3-3所示。
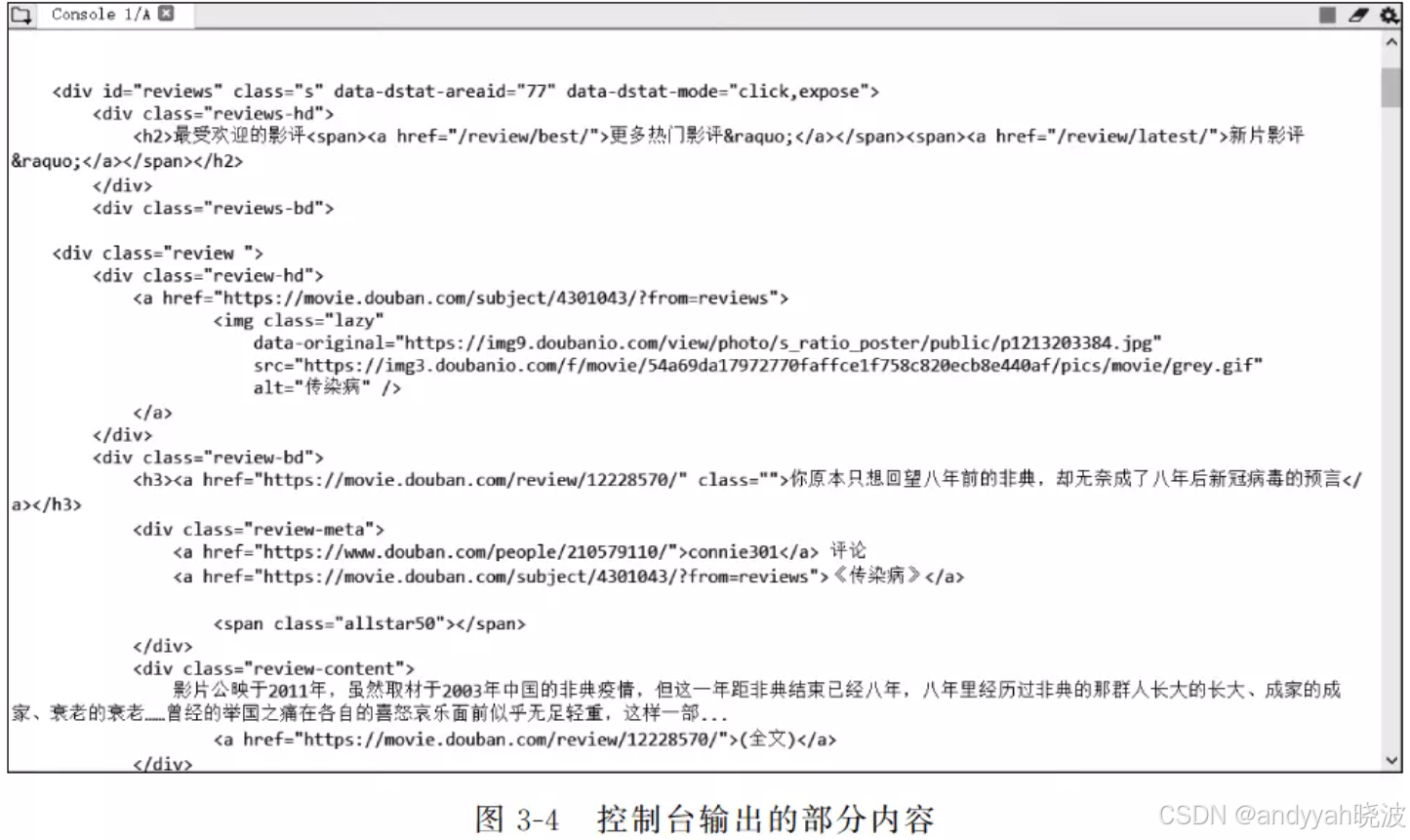
在控制台里就能够看见“豆瓣电影”首页HTTP相应内容的字符串形式,如图3-4所示。
[试一试]改变上述代码中的URL链接,尝试爬取你喜欢网站中的信息,看看返回的内容有什么区别。

3.3解析信息内容
浏览器通过解析HTML 文件,展示丰富的网页内容。HTML是一种标识性的语言。HTML 文件是由一组尖括号形成的标签组织起来的,每对括号形成一对标签,标签之间存在一定的关系,形成标签树。可以利用 BeautifulSoup库解析、遍历、维护这样的“标签树”。
[注意]对于没有HTML基础的读者,简单学习HTML后将有助于对本书后续内容的理解。
1.BeautifulSoup库中的一些基本元素
Tag:标签,最基本的信息组织单元,用<>标明开头,</>标明结尾。任何标签都可以用soup.访问获得,如果HTML 文档中存在多个相同< tag>对应内容时,soup.返回第一个该类型标签的内容。
- Name:标签的名字,即尖括号中的字符串。如
…
的name是’p’。每个都有自己的名字,可通过.name获取。 - Attributes:标签的属性,字典形式组织。一个可以有零个或多个属性。可以通过.attrs获取。
- NavigableString:标签内非属性字符串,即<>和</>之间的字符串。可以通过< tag >.string调用。
- Comment:标签内字符串的注释部分,一种特殊的 Comment类型。
2.BeautifulSoup库的三种遍历方式
由于HTML格式是一个树状结构,BeautifulSoup库提供了三种遍历方式,分别为下行遍历、上行遍历和平行遍历。
利用下列属性可以轻松地对其进行遍历操作。
(1)下行遍历。
.contents:子节点的列表,将所有的儿子节点存人列表。
.children:子节点的迭代类型,与.contents相似。
.descendants:子孙节点的迭代类型,包含所有子孙节点。
(2)上行遍历。
.parent:节点的父亲标签。
.parents:节点先辈标签的迭代类型。
(3)平行遍历。
.next_sibling:返回按照HTML 文本顺序的下一个平行节点标签。
.previous_sibling:返回按照HTML 文本顺序的上一个平行节点标签。
.next_siblings:迭代类型,返回按照HTML 文本顺序的所有平行节点标签。
.previous_siblings:迭代类型,返回按照HTML 文本顺序的前续所有平行节点标签。
3.查找内容
该如何对所需要的内容进行查找呢?这就需要用到一个方法<>.find_all(name,attrs,recursive,string,**kwargs)。其中,name:对标签名称的检索字符串,attrs:对标签属性值的检索字符串,recursive:是否对子孙全部检索,默认为True,string:<>…</>中字符串区域的检索字符串。因此,可以利用该方法对所需要的成员进行特征检索。该方法还有许多拓展方法,在此就不一一介绍了,感兴趣的读者可以自行阅读相关文件。
4.定位文本内容
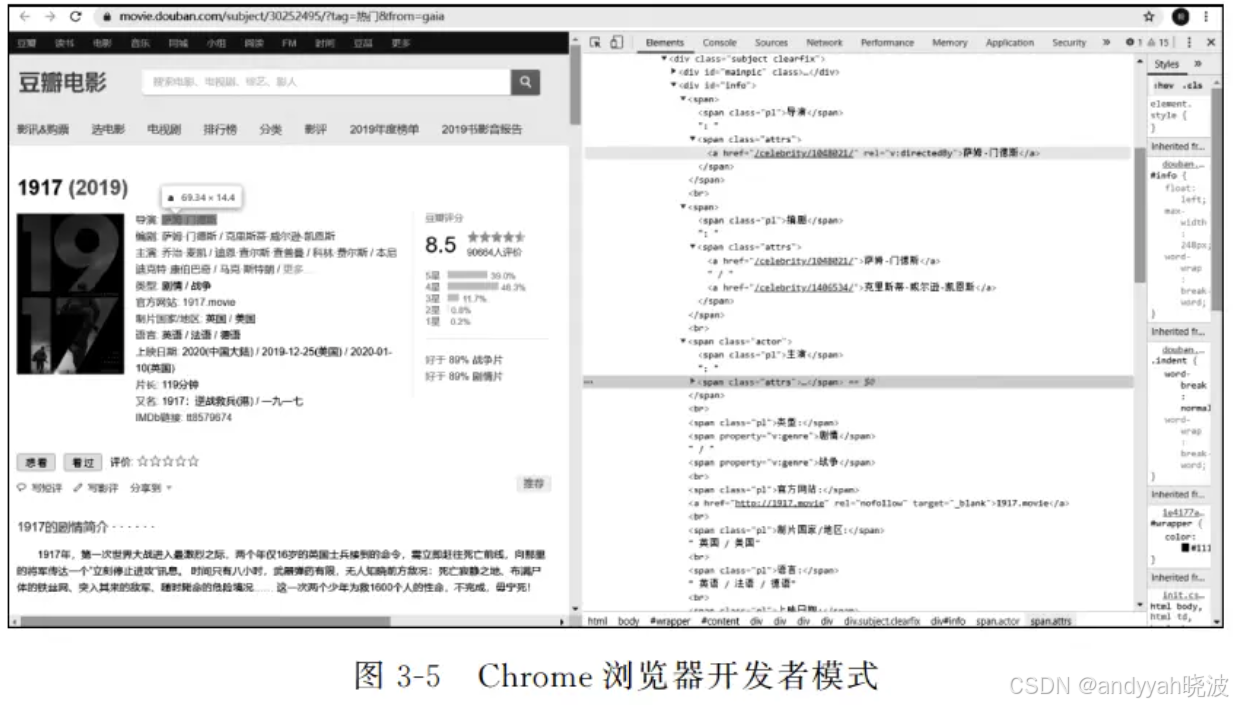
如果想定位所需要的文本内容,则要在需要爬取的页面按F12键,便调出开发者界面,即可直接查看该网页的HTML 文本。Chrome浏览器开发者模式如图3-5所示。
可以单击图3-6 中的圆按钮,此后只需将光标悬停在需要查找的网页内容上,便可自动定位其在HTML 文本中的标签位置。
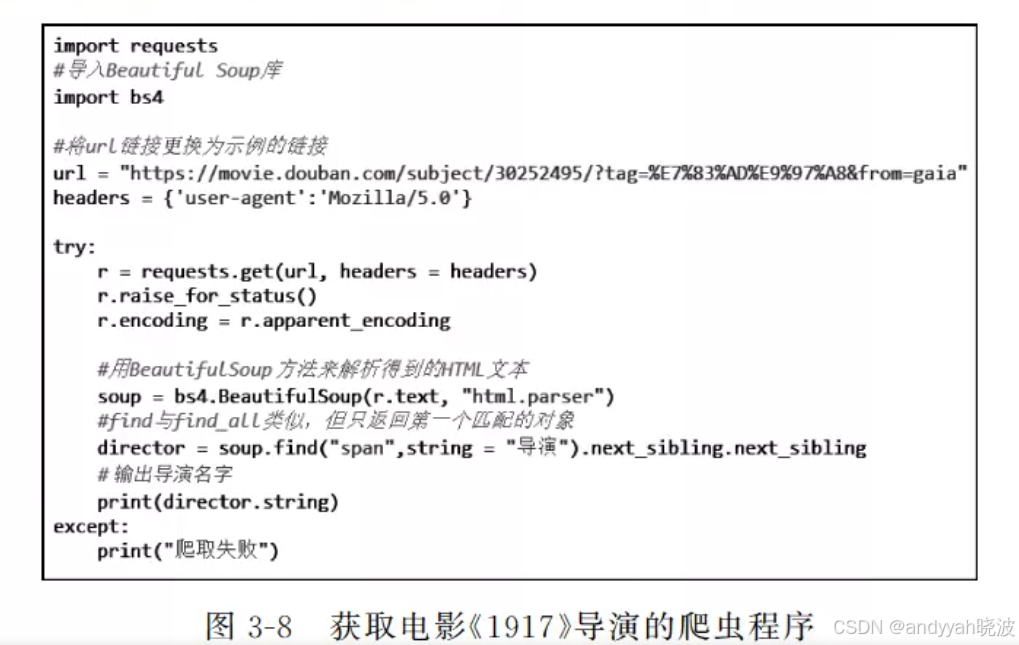
例如,可以在图3-5所示的页面中快速定位该影片导演的信息所在的位置,如图3-7所示。通过观察可以发现,“导演”标签的平行标签中NavigableString便是需要的导演名字。以此方法,可以快速定位电影编剧、主演、类型等信息。通过比较多个网页发现标签中的共同元素,便可以通过编写程序快速解析出需要的信息,并运用于所有的豆瓣电影简介页面。
下面编写程序来实验一下,如图3-8所示。
在控制台就可以看到输出的导演名字“萨姆・门德斯”。类似地,根据其他标签的特征,也可以爬取其他信息。
[试一试]模仿上述代码,爬取一个你喜欢网页的信息。
3.4批量爬取网页信息
学会了如何爬取一个网页,但是如何做到批量爬取呢?这里提供两个可行的方法作为参考。
(1)通过豆瓣的排行榜获取不同电影简介页面的网址,将其存人本地列表中,不断爬取。
(2)从每个豆瓣电影简介页面的“喜欢这部电影的人也喜欢”内容块中,获取相关电影简介页面的网址。
每爬取一个电影就能得到10个相关电影简介页面的网址,理论上的程序可以不断地获取新的电影简介页面的网址,并将其存人队列。只需要借助一个while循环便可以轻松地完成操作。
下面来编写一个完整的爬取豆瓣电影简介的程序,由于目标网站反爬措施升级,以下列出的部分程序可能会运行失效。列出如下代码的目的是交流学习,读者可以在掌握相关库的基本用法及思路的基础上,灵活做出调整。
# -*- coding: utf-8 -*-
"""
Created on Fri Feb 21 12:37:05 2020
@author: 1
"""
import requests
#导入Beautiful Soup库
import bs4
import queue
#获取指定网页的HTML链接
def get_HTMLtext(url, headers):
try:
r = requests.get(url, headers = headers)
r.raise_for_status()
return r.text
except:
return None
#获取解析后的BeautifulSoup对象
def get_soup(text):
return bs4.BeautifulSoup(text, "html.parser")
#获取电影名
def get_name(soup):
return soup.find("span",{"property":"v:itemreviewed"}).string
#获取导演姓名
def get_director(soup):
director = soup.find("span",string = "导演").next_sibling.next_sibling
return director.string
#获取演员列表
def get_actors(soup):
actors = ""
act = soup.find("span",{"class":"actor"}).find("span",{"class":"attrs"})
for actor in act:
actors += actor.string
return actors
#获取电影类型
def get_types(soup):
types = ""
for t in soup.find_all("span",{"property":"v:genre"}):
types += t.string
types += " "
return types
#获取更多url链接
def get_more_url(soup, q):
for t in soup.find_all("dd"):
q.put(t.a.get("href"))
return
#爬虫起始网页链接
url = "https://movie.douban.com/subject/30252495/?tag=%E7%83%AD%E9%97%A8&from=gaia"
headers = {'user-agent':'Mozilla/5.0'}
#待爬取的url链接队列
q = queue.Queue()
#将起始网页存入队列
q.put(url)
#用于存储信息的列表,可根据需要换成其他数据结构储存
moive_list = []
#已爬取网页数
num = 0
#爬取程序,可指定爬取网页数
while(num < 10):
#创建字典储存信息
moive = {}
#从队列中取出一个url链接
url = q.get()
#获取HTML文本
text = get_HTMLtext(url, headers)
#判断是否失败
if (text == None):
continue
#利用BeautifulSoup库解析
soup = get_soup(text)
#在字典中存入电影名
moive["电影名"] = get_name(soup)
#在字典中存入导演
moive["导演"] = get_director(soup)
#在字典中存入主演
moive["主演"] = get_actors(soup)
#在字典中存入电影类型
moive["类型"] = get_types(soup)
#将更多网页加入队列
get_more_url(soup, q)
#将本电影信息加入列表中
moive_list.append(moive)
#已爬取页面数数加一
num += 1
print(movie_list)
3.5本章小结
本章通过介绍爬取豆瓣电影简介的案例详细分析了一个简单的爬虫程序。将爬虫分为四个步骤,便于读者理解。同时介绍了两个第三方库一–Requests库和 BeautifulSoup库的使用方法,以及一些关于HTML的小知识。这能帮助读者更好地理解爬虫。
