Redis的Bin目录文件
| 可执行文件 | 作用 |
|---|---|
| redis-server | 启动Redis |
| redis-cli | redis命令行客户端 |
| redis-benchmark | 基准测试工具 |
| redis-check-aof | AOF持久化文件检测和修复工具 |
| redis-check-rdb | RDB持久化文件检测和修复工具 |
| redis-sentinel | 启动哨兵 |
全局命令
> redis-cli
> ping
> dbsize # 显示redis中key的数量
> info stats
redis的key命名格式:业务名:对象名:id:[属性]
Redis常用数据类型:String、Hash、list、set、zset、HyperLogLog、GEO
Redis键/Key
> del key # 删除key
> dump key # 序列化指定key,并返回被序列化的值
# 示例:
> set k1 hello
OK
> dump k1
"\x00\x05hello\x0b\x00\n\xadb\x05\x98\xab\xc9\x83"
> exists key # 检查指定key是否存在
> expire key seconds # 给指定key设置过期时间,单位:秒
> expireat key timestamp # 以UNIX时间戳格式(秒)设置key的过期时间
> pexpire key milliseconds # 给指定key设置过期时间,单位:毫秒
> pexpireat key milliseconds-timestamp # 以UNIX时间戳格式(毫秒)设置key的过期时间
> keys pattern # 查找所有符合给定正则的key
# 示例:
> key * # 查看所有key
> key a* # 查看a开头的所有key
> move key db # 将当前数据库的key移动到指定数据库db中
> persist key # 移除key的过期时间
> pttl key # 查看key的剩余过期时间,单位:毫秒
> ttl key # 查看key的剩余过期时间(TTL, time to live),单位:秒
> randomkey # 随机返回一个key
> rename key newkey # 修改key的名称为newkey
> renamenx key newkey # 修改key的名称为newkey,仅当newkey不存在时
> scan cursor [match pattern] [count count] # 迭代数据库中的键
# 示例:
> scan 0
> type key # 返回key储存的值类型
Redis字符串(String)
> set key value # 设置指定key的值为value
> get key # 获取指定key的值
> getset key value # 将给定key的值设置为value,并返回旧值
> getbit key offset # 获取指定偏移量上的位
> setbit key offset value # 设置或清除指定偏移量上的位
> setrange key offset value # 用value更新key储存的字符串值,从偏移量offset开始
> getrange key start end # 获取key中字符串值的子字符串
> mset key value [key value ...] # 同时设置一个或多个key-value对
> mget key1 [key2 ...] # 获取所有给定key(一个或多个)的值。
> msetnx key value [key value ...] # 同时设置一个或多个key-value对,当且仅当所有给定key都不存在时。
> psetex key milliseconds value # 设置key的值为value,并将过期时间设置为milliseconds,单位:毫秒
> setex key seconds value # 设置key的值为value,并将过期时间设置为seconds,单位:秒
> setnx key value # 在key不存在时设置key的值为value
> strlen key # 返回key储存的字符串长度
> append key value # 如果key存在且它是一个字符串,将指定的 value 追加到该 key 原来值的末尾
> incr key # 将 key 中储存的数字值增一;如果key不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作
> decr key # 将key中储存的数字值减一
> incrby key increment # 将key中储存的数字值增加指定增量increment
> decrby key decrement # 将key中储存的数字值减少指定减量decrement
> incrbyfloat key increment # 将key中储存的数字值增加指定浮点增量increment
Redis 哈希(Hash)
Redis hash 是一个 string 类型的 field和 value的映射表,hash 特别适合用于存储对象。
每个 hash 可以存储
2
32
−
1
2^{32} - 1
232−1 键值对(40多亿)。
> hmset key field value [field value ...] # 设置哈希表中一个或多个field-value
> hmget key field [field ...] # 获取所有字段的值
> hset key field value # 将哈希表key中的字段field值设为value
> hsetnx key field value # 在字段field不存在时,将哈希表key中的字段field值设为value
> hkeys key # 获取哈希表中所有字段
> hvals key # 获取哈希表中所有值
> hlen key # 获取哈希表中字段的数量
> hexists key field # 查看哈希表中指定的字段是否存在
> hdel key field1 [field2 ...] # 删除哈希表的一个或多个字段
> hget key field # 获取哈希表中指定字段的值
> hgetall key # 获取哈希表中指定key的所有字段和值
> hincrby key field increment # 把哈希表key中指定字段的数值加上整数增量increment
> hincrbyfloat key field increment # 把哈希表key中指定字段的数值加上浮点增量increment
> hscan key cursor [match pattern] [count count] # 迭代哈希表中的键值对
Redis 列表(List)
Redis列表是简单的字符串列表,按照插入顺序排序。可以添加元素到列表的头部或尾部。一个列表最多可以包含 2 3 2 − 1 2^32 - 1 232−1个元素(4294967295)。
> lpush key value [value ...] # 将一个或多个值插入到列表头部
> lpushx key value # 将一个值插入到已存在的列表头部
> lpop key # 移出并获取列表的第一个元素
> rpush key value [value ...] # 将一个或多个值插入到列表尾部
> rpushx key value # 将一个值插入到已存在的列表尾部
> rpop key # 移除并获取列表的最后一个元素
> blpop key [key ...] timeout # 移出并获取列表的第一个元素,如果列表没元素会阻塞列表直到等待超时或发现可弹出元素为止。
> brpop key [key ...] timeout # 移出并获取列表的最后一个元素,如果列表没元素会阻塞列表直到等待超时或发现可弹出元素为止。
> brpoplpush source destination timeout # 从列表移出最后一个元素,并将它插入到另外一个列表中;如果列表没元素会阻塞列表直到等待超时或发现可弹出元素为止。
> rpoplpush source destination # 移除列表最后一个元素,并将该元素添加到另一个列表并返回
> lindex key index # 通过索引获取列表中的元素
> linsert key before | after pivot value # 在列表的元素前或后插入元素
> llen key # 获取列表长度
> lrange key start stop # 获取列表指定范围内的元素
# 示例:
> lrange key1 0 -1 # -1表示所有
> lrem key count value # 移除列表元素
> lset key index value # 通过索引设置列表元素的值
> ltrim key start stop # 对列表进行修剪,只保留指定区间内的元素,删除其他元素
Redis 集合(Set)
Redis的Set是String类型的无序集合。Set集合是通过哈希表实现的,添加、删除、查找的复杂度都是O(1),最大成员数是 2 32 − 1 2^{32} - 1 232−1。
> sadd key member [member ...] # 向集合中添加一个或多个成员
> scard key # 获取集合的成员数
> sdiff key [key ...] # 返回第一个集合与其他集合之间的差异
> sdiffstore destination key [key ...] # 返回给定集合的差集并存储在目的集合中
> sinter key [key ...] # 返回给定集合的交集
> sinterstore destination key [key ...] # 返回给定集合的交集并存储在目的集合中
> sismember key member # 判断member元素是否是集合key的成员
> smembers key # 获取集合中的所有成员
> smove source destination member # 将member元素从源集合移动到目的集合
> spop key # 移除并返回集合中的一个随机元素
> srandmember key [count] # 返回集合中一个或多个随机元素
> srem key member [member ...] # 移除集合中的一个或多个元素
> sunion key [key ...] # 获取给定集合的并集
> sunionstore destination key [key ...] # 获取给定集合的并集并存储在destination集合中
> sscan key cursor [match pattern] [count count] # 迭代集合中的元素
Redis 有序集合(sorted set)
Redis有序集合和集合一样也是String类型元素的集合,且不允许重复的成员。
区别是每个元素都会关联一个double类型的分数,而且通过分数来为成员进行从小到大的排序。集合的成员是唯一的,但分数是可以重复的。
> zadd key score member [score member ...] # 向有序集合添加一个或多个成员,或更新已存在成员的分数
> zcard key # 获取有序集合的成员数
> zcount key min max # 计算有序集合中指定区间分数的成员数
> zincrby key increment member # 有序集合中对指定成员的分数增加增量increment
> zinterstore destination numkeys key [key ...] # 计算给定的一个或多个有序集合的交集,并将结果存储在新的有序集合中
> zlexcount key min max # 计算有序集合中指定字典区间内成员数量
> zrange key start stop [withscores] # 通过索引区间返回有序集合指定区间内的成员
# 示例:
> zrangebyscore z1 2 6 withscores
> zrangebyscore z1 -inf +inf withscores
> zrangebylex key min max [limit offset count] # 通过字典区间返回有序集合的成员
> zrangebyscore key min max [withscores] [limit] # 通过分数返回有序集合指定区间内的成员
> zrank key member # 返回有序集合中指定成员的索引
> zrem key member [member ...] # 移除有序集合中的一个或多个成员
> zremrangebylex key min max # 移除有序集合中给定的字典区间的所有成员
> zremrangebyrank key start stop # 移除有序集合中给定的排名区间的所有成员
> zremrangebyscore key min max # 移除有序集合中给定的分数区间的所有成员
> zrevrange key start stop [withscores] # 返回有序集合中指定区间内的成员,通过索引,分数从高到低
> zrevrangebyscore key max min [withscores] # 返回有序集合中指定分数区间内的成员,分数从高到低排序
> zrevrank key member # 查询有序集合中指定成员的排名,有序集合成员按分数值递减排序
> zscore key member # 查询有序集合中指定成员的分数值
> zunionstore destination numkeys key [key ...] # 计算给定的一个或多个有序集合的并集,并存储在新的key中
> zscan key cursor [match pattern] [count count] # 迭代有序集合中的元素
Redis的位图(Bitmap)
Bitmap是一种特殊的字符串数据类型,它利用字符串类型键来存储一系列连续的二进制位(bits),每个位可以独立地表示一个布尔值(0或1)。非常适合用于存储和操作大量二值状态的数据,尤其在需要高效空间利用率和特定位操作场景中表现出色。
> setbit key offset value # 设置或清除指定偏移量上的位值
> getbit key offset # 返回指定偏移量上的位值
> bitcount key [start end] # 计算键指定范围内为1的位的数量
> bitop operation destkey key [key ...] # 对一个或多个键执行位操作,并将结果保存到destkey。支持的操作包括AND/OR/XOR/NOT
> bitpos key bit [start] [end] # 查找指定键内第一个值为bit的位的偏移量
Redis HyperLogLog
Redis HyperLogLog是用来做基数统计的算法,它的优点是在输入元素的数量或体积非常大时,计算基数所需要的空间总是固定的、并且是很小的。
HyperLogLog提供不精确的去重计数方案,虽然不精确但也不是非常不精确,其标准误差是0.81%。常用于统计大型网站每个网页每天的UV数据(独立访客,Unique Visitor)。
什么是基数:比如数据集{1, 3, 5, 5, 7, 7, 8}的基数集为{1, 3, 5, 7, 8},基数(不重复元素个数)为5。基数估计就是在误差可接受的范围内,快速计算基数。
> pfadd key element [element ...] # 添加指定元素到HyperLogLog中
> pfcount key [key ...] # 返回给定HyperLogLog的基数估算值
> pfmerge destkey sourcekey [sourcekey ...] # 将多个HyperLogLog合并为一个
HyperLogLog基于概率论中伯努利试验并结合了极大似然估算方法,并做了分桶优化。
Redis GEO
Redis GEO主要用于存储地理位置信息,并对存储的信息进行操作。
> help @geo # 查看GEO相关的命令
> geoadd key longitude latitude member [longitude latitude member ...] # 添加地址位置到GEO中
# 示例:
> geoadd city 116.28 39.54 beijing 117.10 39.10 tianjin 114.26 38.03 sjz 118.09 39.37 tangshan
> geopos key member [member ...] # 获取地理位置的坐标
# 示例:
> geopos city beijing tianjin
> geodist key member1 member2 [M|KM] # 计算两个位置之间的距离
# 示例:
> geodist city beijing tianjin KM
> georadius # 根据给定的坐标获取指定范围内的位置集合
# 示例:
> georadius city 110 40 500 KM
> georadiusbymember key member radius unit # 根据存储在位置集合中的某个位置获取指定范围内的位置集合
# 示例:
> georadiusbymember city beijing 100 KM WITHDIST
> geohash key member # 返回一个或多个位置对象的geohash
GeoHash编码方式
经度范围是东经180度到西经180度,纬度范围是南纬90度到北纬90度。假设西经为负,东经为正,南纬为负,北纬为正,即[-180, 180],[-90, 90]。
如果以本初子午线、赤道为界,地球可以分成四个部分。
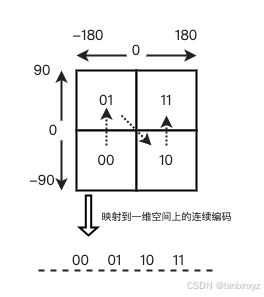
上述操作其实是把经度、纬度做一次二分操作,如果做两次二分操作,结果如下:
实际应用中,可以继续做二分操作,通常二分操作的次数记为N,它是可以自定义的。
这相当于把整个地理空间划分成了一个个方格,每个方格对应了 GeoHash 中的一个分区。每个方格覆盖了一定范围内的经纬度值,分区越多,每个方格能覆盖到的地理空间就越小,也就越精准。这个方法的基本原理就是“二分区间,区间编码”。
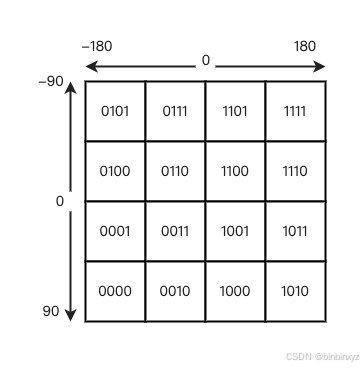
下面,以北京坐标(116.28, 39.54)进行五次分区来阐述算法具体的实现:
经度116.28分区过程:
| 分区次数 | 左分区 | 右分区 | 经度116.28所在的分区 | 编码 |
|---|---|---|---|---|
| 1 | [-180,0) | [0,180] | [0,180] | 1 |
| 2 | [0,90) | [90,180] | [90,180] | 1 |
| 3 | [90,135) | [135,180] | [90,135) | 0 |
| 4 | [90,112.5) | [112.5,135) | [112.5,135) | 1 |
| 5 | [112.5,123.75) | [123.75,135) | [112.5,123.75) | 0 |
经度116.28编码为:11010
纬度39.54分区过程:
| 分区次数 | 左分区 | 右分区 | 纬度39.54所在的分区 | 编码 |
|---|---|---|---|---|
| 1 | [-90,0) | [0,90] | [0,90] | 1 |
| 2 | [0,45) | [45,90] | [0,45) | 0 |
| 3 | [0,22.5) | [22.5,45) | [22.5,45) | 1 |
| 4 | [22.5,33.75) | [33.75,45) | [33.75,45) | 1 |
| 5 | [33.75,39.375) | [39.375,45) | [39.375,45) | 1 |
纬度39.54编码为:10111
合并编码是把上述经度编码、纬度编码依次合并而来,如下:
| 序号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 经度编码 | 1 | 1 | 0 | 1 | 0 | |||||
| 纬度编码 | 1 | 0 | 1 | 1 | 1 | |||||
| 合并编码 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
经过上述过程,我们算出了GeoHash合并经度、纬度的编码值1110011101,然后使用Base32算法进行编码即可。编码过程是将每5位一组,进行转化。5位二进制刚好就是0-31。
由1110011101进行base32编码即可得到结果wx,这就是geohash值。
Base32编码
标准Base32编码
标准Base32编码起源于1987年,它采用5位二进制数表示一个字符,共有32个字符,包括26个字母A-Z和6个数字2-7。
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符 | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P |
| 索引 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 字符 | Q | R | S | T | U | V | W | X | Y | Z | 2 | 3 | 4 | 5 | 6 | 7 |
GeoHash的Base32编码
GEO功能中使用的Base32编码与标准Base32编码有所不同。它使用了一个自定义的Base32编码,包括10个数字和22个字母(a-z,去掉a/i/l/o)。它在标准Base32编码的基础上做了一些修改,主要是为了避免混淆,提高编码值的可读性。
- 数字 0 和字母 O:数字 0 和字母 O 容易混淆。
- 数字 1 和字母 i、字母L:数字 1 和字母 i 、字母L容易混淆。
- 数字 8 和字母 B:数字 8 和字母 B 容易混淆。
- 数字 9 和字母 S:数字 9 和字母 S 也容易混淆。
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| 索引 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 字符 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |