1. 人工智能起源
(1)图灵测试:多次测试(一般为5min之内),如果有超过30%的测试者不能确定被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。
(2)达特茅斯会议
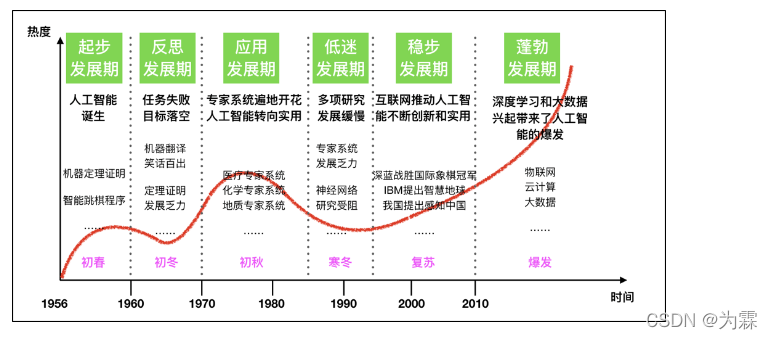
(3)发展阶段:起步发展(1956-20世纪60年代),反思发展期(20世纪60-70年代),应用发展期(20世纪70-80年代),低迷发展期(20世纪80-90年代),稳步发展(20世纪90-2010),蓬勃发展:2011年至今
2. 人工智能发展的必备三要素
(1)数据
(2)算法
(3)计算力:CPU,GPU,TPU;
CPU主要适合I\O密集型的任务
GPU主要适合计算密集型任务
什么类型的程序适合在GPU上运行?
(1)计算密集型的程序
所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
(2)易于并行的程序
GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。
3. 人工智能、机器学习和深度学习
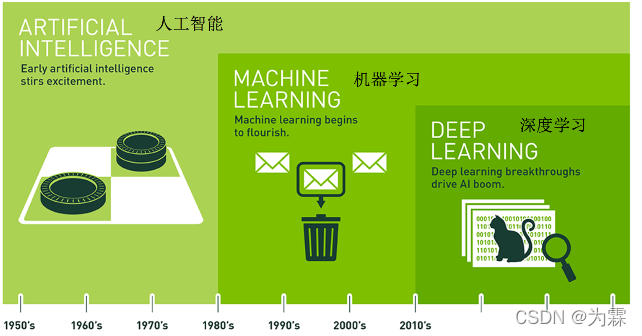
- 机器学习是人工智能的一个实现途径
- 深度学习是机器学习的一个方法发展而来
4. 人工智能的主要分支
(1)计算机视觉
计算机视觉(CV)是指机器感知环境的能力。这一技术类别中的经典任务有图像形成、图像处理、图像提取和图像的三维推理。物体检测和人脸识别是其比较成功的研究领域。
(2)语音识别
语音识别是指识别语音(说出的语言)并将其转换成对应文本的技术。相反的任务(文本转语音/TTS)也是这一领域内一个类似的研究主题。
语音识别已经处于应用阶段很长时间了。最近几年,随着大数据和深度学习技术的发展,语音识别进展颇丰,现在已经非常接近社会影响阶段了。
语音识别领域仍然面临着声纹识别和「鸡尾酒会效应」等一些特殊情况的难题。
现代语音识别系统严重依赖于云,在离线时可能就无法取得理想的工作效果。
(3)文本挖掘/分类
这里的文本挖掘主要是指文本分类,该技术可用于理解、组织和分类结构化或非结构化文本文档。其涵盖的主要任务有句法分析、情绪分析和垃圾信息检测。
当前阶段:
我们将这项技术归类到应用阶段,因为现在有很多应用都已经集成了基于文本挖掘的情绪分析或垃圾信息检测技术。文本挖掘技术也在智能投顾的开发中有所应用,并且提升了用户体验。
(4)机器翻译
机器翻译(MT)是利用机器的力量自动将一种自然语言(源语言)的文本翻译成另一种语言(目标语言)。
当前阶段:
机器翻译是一个见证了大量发展历程的应用领域。该领域最近由于神经机器翻译而取得了非常显著的进展,但仍然没有全面达到专业译者的水平;但是,我们相信在大数据、云计算和深度学习技术的帮助下,机器翻译很快就将进入社会影响阶段。
在某些情况下,俚语和行话等内容的翻译会比较困难(受限词表问题)。
专业领域的机器翻译(比如医疗领域)表现通常不好。
(5)机器人
机器人学(Robotics)研究的是机器人的设计、制造、运作和应用,以及控制它们的计算机系统、传感反馈和信息处理。
机器人可以分成两大类:固定机器人和移动机器人。固定机器人通常被用于工业生产(比如用于装配线)。常见的移动机器人应用有货运机器人、空中机器人和自动载具。机器人需要不同部件和系统的协作才能实现最优的作业。其中在硬件上包含传感器、反应器和控制器;另外还有能够实现感知能力的软件,比如定位、地图测绘和目标识别。
5. 机器学习工作流程
(1)什么是机器学习:
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
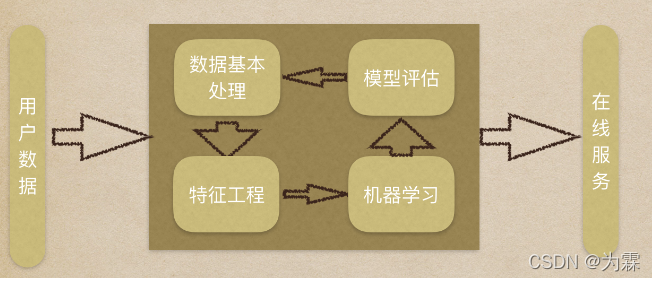
(2)机器学习工作流程:
用户数据→数据基本处理→特征工程→机器学习→模型评估→在线服务
(3)获取到的数据集介绍
在数据集中一般:
-
一行数据我们称为一个样本
- 一列数据我们成为一个特征
- 有些数据有目标值(标签值),有些数据没有目标值(如上表中,电影类型就是这个数据集的目标值)
数据类型的构成:
- 数据类型一:特征值+目标值(目标值是连续的和离散的)
- 数据类型二:只有特征值,没有目标值
数据分割:
- 机器学习一般的数据集会划分为两个部分:
- 测试数据:在模型检验时使用,用于评估模型是否有效
- 训练数据:用于训练,构建模型
- 划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
(4)数据基本处理:即对数据进行缺失值、去除异常值等处理
(5)特征工程:
- 什么是特征工程:使用专业背景知识和技术处理数据,使得特征能在机器学习算法过程中发挥更好的作用的过程——会直接影响机器学习的效果
- 为什么需要特征工程:吴恩达说 特征和数据决定了机器学习的上限,模型和算法只是接近了这个上限
(6)特征工程包含的内容:特征提取;特征预处理;特征降维
- 特征提取:将任意数据(如文本或图像)转换为可用于机器学习的数字特征
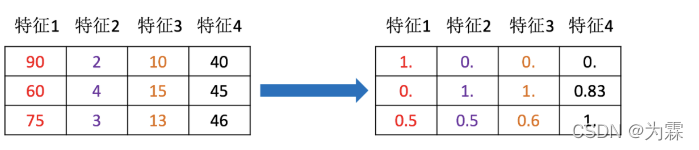
- 特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
- 特征降维: 指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
(7)机器学习 选择合适算法对模型进行训练
(8)对训练好的模型进行评估
6. 算法
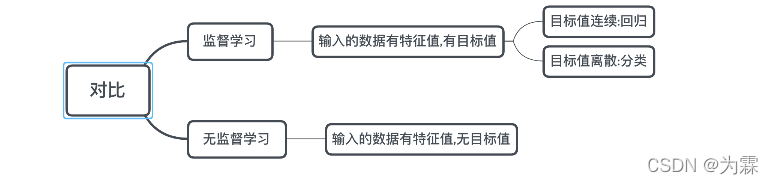
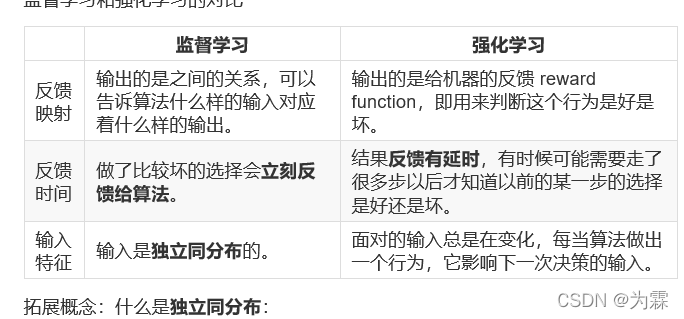
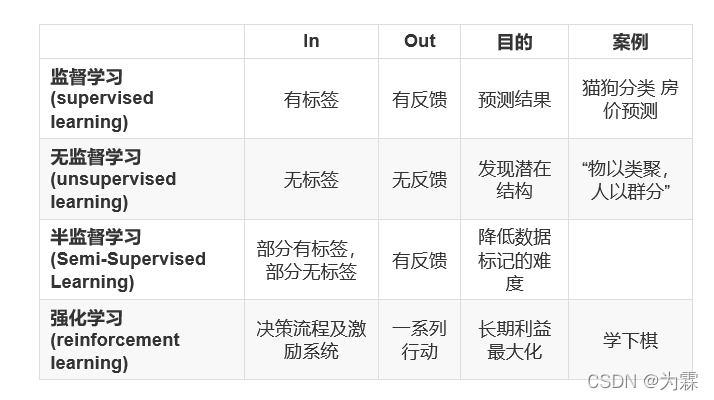
(1)监督学习:
- 输入数据是由输入特征值和目标值所组成。
- 输出可以是一个连续的值(回归),或是输出是有限个离散值(称作分类)。
(2)无监督学习:
-
输入数据是由输入特征值组成,没有目标值
- 需要根据样本间的相似性对样本集进行类别划分。
- 输入数据没有被标记,也没有确定的结果。样本数据类别未知;
(3)半监督学习
-
训练集同时包含标记样本数据和未标记样本数据
-
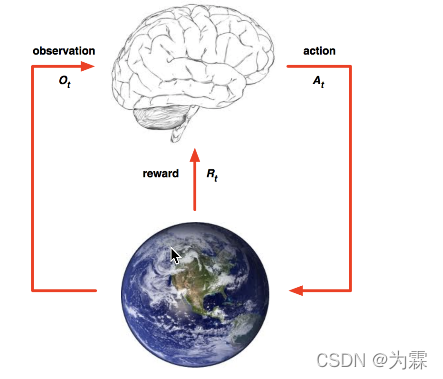
(4)强化学习
-
定义:
- 实质是make decisions 问题,即自动进行决策,并且可以做连续决策。
-
举例:
小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡,接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
小孩就是 agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能走路时,就不会给巧克力。
-
主要包含五个元素:agent, action, reward, environment, observation;
-
-
强化学习的目标就是获得最多的累计奖励。
总结:
-
6. 模型评估
(1)分类模型评估
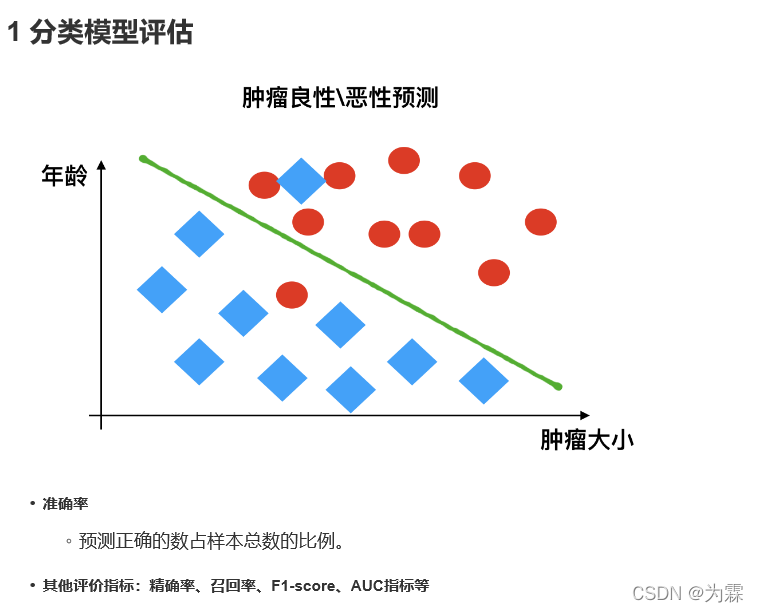
包括:准确率、精确率、召回率、F1-score、AUC
(2)回归模型评估
RMSE仅能比较误差是相同单位的模型。

其他评价指标:相对平方误差(Relative Squared Error,RSE)、平均绝对误差(Mean Absolute Error,MAE)、相对绝对误差(Relative Absolute Error,RAE)
(3)拟合
- 欠拟合:模型学习的太过粗糙,连训练集中的样本数据特征关系都没有学出来。
- 过拟合:所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集中表现不佳。