时序动作检测SSAD《Single Shot Temporal Action Detection》_程大海的博客-CSDN博客_时序动作检测
时序动作检测《BSN: Boundary Sensitive Network for Temporal Action Proposal Generation》_程大海的博客-CSDN博客
时序动作检测《BMN: Boundary-Matching Network for Temporal Action Proposal Generation》_程大海的博客-CSDN博客
《Non-local Neural Networks》个人总结理解_程大海的博客-CSDN博客
温馨提示:本文仅供自己参考(勿捧杀),如有理解错误,有时间再改!
时序动作分类:识别一段视频中的动作类别
时序动作检测:识别一段视频中的动作类别以及动作的开始和结束时间
时空动作检测:识别一段视频中的动作类别、动作的开始和结束时间,以及动作发生的空间位置(如投篮人所在的bbox)
时序动作检测可以被看做是时序版本的图像目标检测,因为两者都是需要检测目标的类别,并且都需要确定目标的准确边界位置。
detect by classifying时序动作检测方法:先使用proposal模块生成可能的推荐框(或者推荐动作片段),然后在对proposal进行分类识别。类似于Faster RCNN的先检测生成proposal后分类的时序动作检测方法的缺点:
1、类似于Faster RCNN那样,检测网络和识别网络需要分开训练,理想情况是可以进行联合训练得到最优模型
2、检测网络生成proposal需要额外的计算时间
3、使用滑窗生成的proposal边界通常都不够精确,并且滑窗方法需要事先确定窗口大小,只能处理固定长度的片段,不能灵活应用于变长片段。
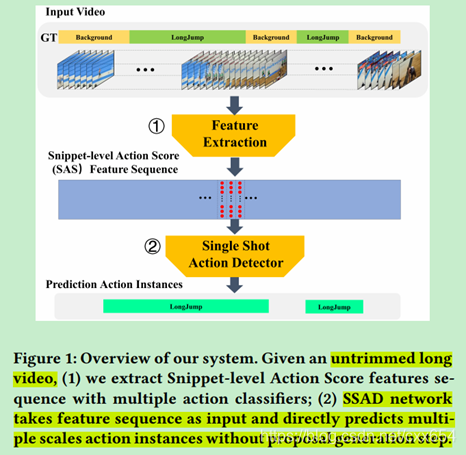
论文中提出的Single Shot Action De[1]tector (SSAD)网络是采用多种时序动作识别模型提取不同时间粒度特征的时序卷积网络,SSAD网络是一段式的网络,不需要先生成预测proposal,直接预测动作的时序边界以及置信度。
问题形式化表示:
视频形式化定义:
其中表示一个未裁剪的视频片段,
表示这个视频片段的总帧数,
表示视频
中的第
帧。
视频动作形式化定义:
其中,表示一个未裁剪视频片段
中包含的所有标注动作片段,
表示视频中动作片段个数,
表示
中被标注的一个动作片段,
分别表示这个被标注的动作片段的开始时间、结束时间,以及动作类别,
表示动作类别的总数。
视频片段形式化定义(视频Xv中的一小段):
其中表示一个视频片段,
表示视频
中的第
帧。
表示以
为中心,前后各取一段组成的片段的光流特征,
。
表示以
为中心,前后各取一段组成的图像片段,
。对于一个视频
,以每一帧
为中心可以得到一个
,可以得到一个多个
组成的序列
,
的长度等于视频总帧数
。对于视频的前端补充第一帧,对于视频的后端补充最后一帧。
所以,对于视频片段:
是单张图片,使用Spatial Network进行片段分类,侧重利用空间特征,输出的概率预测结果记做
,长度为𝑲+𝟏,𝑲是动作总类别数量,+1表示背景类别
是堆叠的光流数据,共10帧,使用Temporal Network进行片段分类,侧重利用时序运动特征
,长度为𝑲+𝟏,𝑲是动作总类别数量,+1表示背景类别
是堆叠的图像数据,共16帧,使用C3D Network进行片段分类,侧重利用时空特征
,长度为𝑲+𝟏,𝑲是动作总类别数量,+1表示背景类别
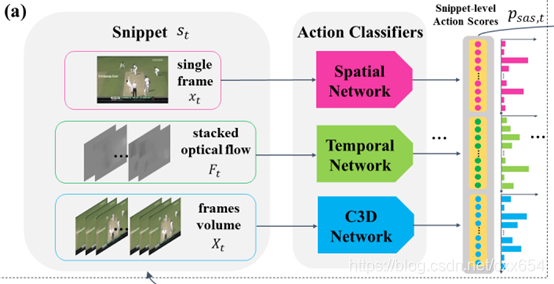
Snippet-level Action Score (SAS) 特征:
输出结果进行concat,
的特征维度为3*(𝑲+𝟏)。
对于一个视频,提取得到小片段
,每个小片段
预测得到
,然后最终得到整个视频
的SAS特征:
的维度是
。

由于视频的帧数很大,所以得到的特征序列也很长,论文中采用了大小的
的观测窗口,对于观测窗口的形式化定义如下:
其中,是观测窗口的开始时间和结束时间,
是观测窗口覆盖的特征序列,
是观测窗口对应的ground truth动作实例。
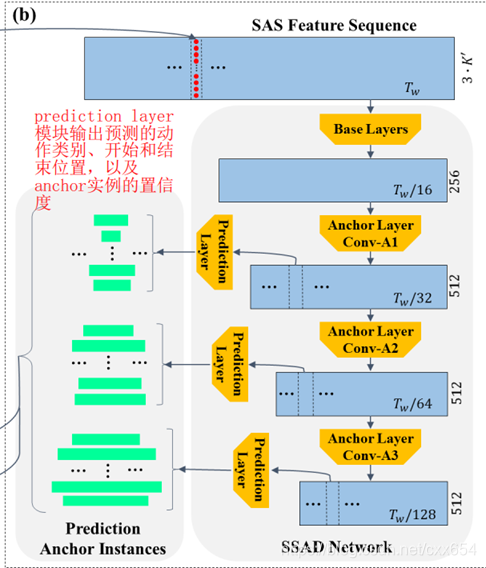
SSAD网络模型有三个子模块:
1、Base Layers:在SAS特征序列上使用1D时序卷积和池化操作降低特征序列的时序长度大小,同时提升时序维度的感受野。
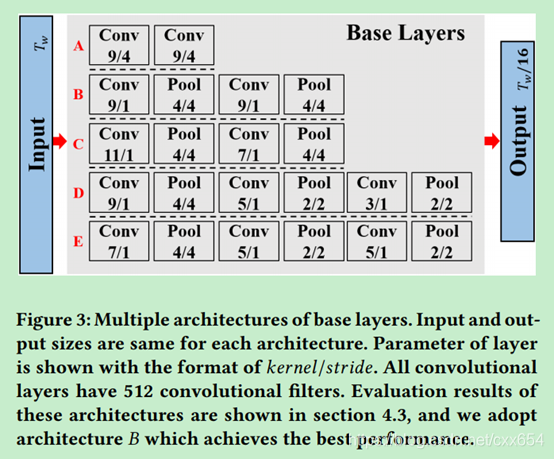
论文中尝试了多种Base Layers网络结构,其中的Conv是temporal上的1D卷积,Pool是temporal上的1D池化。实验表明B网络结构性能最好,经过Base Layer之后,时序特征的时序长度变为原来的1/16。
1D卷积示意图如下(手残党画图):

2、Anchor Layers:使用1D时序卷积进一步缩小特征图,采用卷积核大小为3,步长为2,输出通道数为512的1D卷积操作。经过Conv-A1、Conv-A2、Conv-A3之后,时间维度大小分别减小为原来的1/32、1/64、1/128。这三种尺度的Anchor Layer输出特征使得SSAD网络可以多种尺度的特征图。在每种尺度的特征图的每个位置(cell)使用多种尺度(尺度是对于时间维度来说的)anchor box。Conv-A1层具有更大的特征图和更小的感受野,所以在Conv-A1特征图上的anchor box负责检测short action,Conv-A2检测middle action,Conv-A3检测long action,这点和YoloV2的多个检测头类似。
假设Base Layer输出的特征图为f,特征图的时序长度为M,定义一个anchor的尺寸基数:
然后对于不同的层设置不同的anchor ratio,Conv-A1的anchor ratio设置为{1, 1.5, 2},Conv-A2和Conv-A3的anchor ratio设置为{0.5, 0.75, 1, 1.5, 2},anchor ratio记做。计算anchor的宽度如下:
Anchor的中心计算如下:
表示feature map在时序维度上的第
个cell,
表示feature map的时序长度。
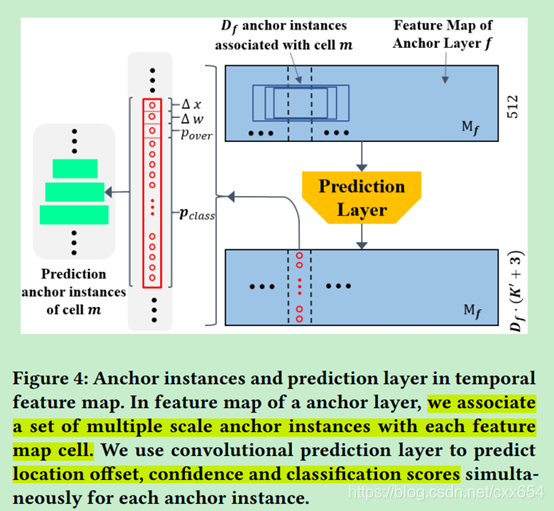
3、Prediction Layers:prediction layer预测输出类别概率、重合置信度、预测位置偏移。定义表示特征图的时序长度,
表示特征图每个时序位置采用的anchor数量,使用输出通道数为
的1D时序卷积,卷积核大小为3,步长为1,卷积的输出结果维度为
,每个anchor位置的预测输出维度是
,预测结果表示为
。其中K'是K类+1类背景,3表示预测的重合度得分(预测结果与GT的重合度[0,1],可以使用sigmoid得到),以及预测结果与对应anchor的偏移量,偏移量包括中心位置偏移和宽度偏移。Prediction layer在Conv-A1、Conv-A2、Conv-A3层都会输出预测结果。
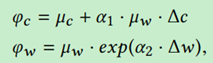
是预测结果与anchor中心坐标以及anchor的宽的偏移量,
是anchor的中心坐标位置,
是anchor的宽度,
是超参数用于控制通过偏移量计算结果的稳定性。
是预测结果的中心位置以及宽度。
的计算中使用了指数计算方式,和Faster RCNN以及Yolov2中的计算类似。由以上预测结果可以得到检测到的动作片段的开始位置和结束位置分别是:
模型训练
训练样本特征构建:
先对于每个视频提取固定大小的时间序列特征,然后在此特征的基础上使用窗口大小为的滑窗,滑窗的重叠度为75%,也就是滑窗的移动步长是
。使用滑窗的目的一是为了解决动作位于窗口边界的问题,二是可以增加训练样本数量,每个滑窗内的特征都是一个输入到网络中的训练样本,作者设置的
。训练过程中只保留至少包含一个动作实例的滑窗内的特征。
训练样本标签生成:
对于prediction layer基于每个anchor box输出的预测结果,计算每个预测结果与所有GT的IoU数值,如果最高的IoU数值大于0.5,则将该预测结果定义为positive正样本,阈值IoU最高的那个GT就是这个正样本的label标签,这点和目标检测的label分配类似。一个GT可以和多个anchor box的预测结果匹配,一个anchor box的预测结果只能和一个GT匹配。Anchor box的预测结果与GT的匹配结果表示如下:
其中,分别表示anchor box预测结果的中心坐标偏移、宽度大小偏移、预测类别概率、预测重合置信度,
表示与anchor box匹配的GT的类别,与anchor box预测结果的IoU重合度,以及GT的中心位置坐标和宽度大小。
通过上述计算方法会得到少量的positive和大量的negative,正负样本数量极度不均衡,论文中使用难样本挖掘来平衡正负样本的数量,这点与Faster RCNN类似。
优化目标(损失函数):
SSAD同时预测目标的开始、结束位置,类别以及重合置信度,是一个多任务优化问题。损失函数如下:
主要包括分类损失,重叠置信度回归损失,边界回归损失以及正则化项。分类损失使用交叉熵损失,重合置信度损失使用回归损失MSE,预测偏移量损失使用SmoothL1。
模型预测及后处理
在测试阶段,序列特征采样的滑窗重合度比率降低到25%来增加预测速度,如果输入视频的长度小于滑窗大小,则对特征序列进行pad补足
长度,那个这个视频就只有一个滑窗结果。对于某个预测结果
,计算这个预测片段内的mean Snippet-level Action Score
。
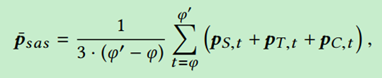
其中,是预测的开始时间
到结束时间
之间每个时间位置的Spatial Network、Temporal Network、C3D Network预测概率结果。然后计算每个anchor instance的最终分类结果。选择
中结果最大的维度对应的类别作为预测类别,最大维度对应的数值作为预测的置信度
。
在获得了一段视频所有的预测action instance后,本文采用NMS(非极大化抑制)对重叠的预测进行去重,NMS阈值设置为0.1。从而获得最终的temporal action detection结果。
数据集:THUMOS14数据集以及MEXaction2
总结:本文的主要贡献我认为包括两点,一是将基于时序卷积的Single Shot结构的模型引入了temporal action detection问题;二是探索了使用时序卷积网络进行temporal action detection的一些网络结构以及训练策略的设置。
参考:"Single Shot Temporal Action Detection" 论文介绍 - 知乎
参考:Video Analysis 相关领域解读之Temporal Action Detection(时序行为检测) - 知乎