AGI 之 【Hugging Face】 的【问答系统】的 [Haystack构建问答Pipeline] 的简单整理
目录
AGI 之 【Hugging Face】 的【问答系统】的 [Haystack构建问答Pipeline] 的简单整理
一、简单介绍
AGI,即通用人工智能(Artificial General Intelligence),是一种具备人类智能水平的人工智能系统。它不仅能够执行特定的任务,而且能够理解、学习和应用知识于广泛的问题解决中,具有较高的自主性和适应性。AGI的能力包括但不限于自我学习、自我改进、自我调整,并能在没有人为干预的情况下解决各种复杂问题。
- AGI能做的事情非常广泛:
跨领域任务执行:AGI能够处理多领域的任务,不受限于特定应用场景。
自主学习与适应:AGI能够从经验中学习,并适应新环境和新情境。
创造性思考:AGI能够进行创新思维,提出新的解决方案。
社会交互:AGI能够与人类进行复杂的社会交互,理解情感和社会信号。
- 关于AGI的未来发展前景,它被认为是人工智能研究的最终目标之一,具有巨大的变革潜力:
技术创新:随着机器学习、神经网络等技术的进步,AGI的实现可能会越来越接近。
跨学科整合:实现AGI需要整合计算机科学、神经科学、心理学等多个学科的知识。
伦理和社会考量:AGI的发展需要考虑隐私、安全和就业等伦理和社会问题。
增强学习和自适应能力:未来的AGI系统可能利用先进的算法,从环境中学习并优化行为。
多模态交互:AGI将具备多种感知和交互方式,与人类和其他系统交互。
Hugging Face作为当前全球最受欢迎的开源机器学习社区和平台之一,在AGI时代扮演着重要角色。它提供了丰富的预训练模型和数据集资源,推动了机器学习领域的发展。Hugging Face的特点在于易用性和开放性,通过其Transformers库,为用户提供了方便的模型处理文本的方式。随着AI技术的发展,Hugging Face社区将继续发挥重要作用,推动AI技术的发展和应用,尤其是在多模态AI技术发展方面,Hugging Face社区将扩展其模型和数据集的多样性,包括图像、音频和视频等多模态数据。
- 在AGI时代,Hugging Face可能会通过以下方式发挥作用:
模型共享:作为模型共享的平台,Hugging Face将继续促进先进的AGI模型的共享和协作。
开源生态:Hugging Face的开源生态将有助于加速AGI技术的发展和创新。
工具和服务:提供丰富的工具和服务,支持开发者和研究者在AGI领域的研究和应用。
伦理和社会责任:Hugging Face注重AI伦理,将推动负责任的AGI模型开发和应用,确保技术进步同时符合伦理标准。
AGI作为未来人工智能的高级形态,具有广泛的应用前景,而Hugging Face作为开源社区,将在推动AGI的发展和应用中扮演关键角色。
(注意:以下代码运行,可能需要科学上网)
二、构建问答系统
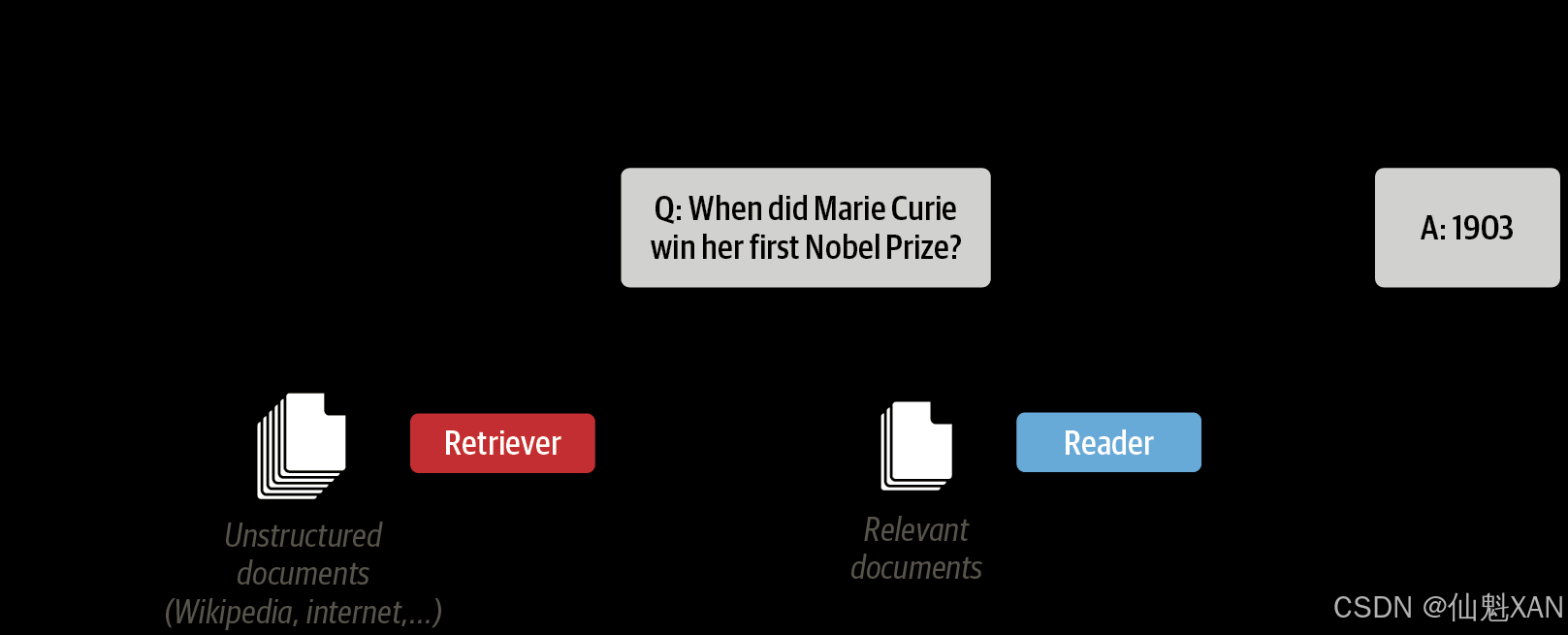
无论你是研究人员、分析师还是数据科学家,都很有可能需要在浩如烟海的文档中跋山涉水才能找到你所需要的信息。最让人感到崩溃的是,在使用Google或者Bing搜索引擎的时候,它们还不断提醒你,还有更好的搜索方法。例如,使用Google搜索:玛丽·居里什么时候获得她的第一个诺贝尔奖?可以立即得到正确答案:1903,如下图所示。

虽然在这种情况下,每个人都知道DropC是最好的吉他调音方式。
在这个例子中,Google首先检索出了大约319 000个与查询信息相关的文档,然后执行了另一个处理步骤,即从这些文档中提取出带有相应段落和网页的答案片段。所以,搜索引擎的每条搜索结果看起来似乎对你都很有用。再比如,使用Google搜索一个稍微棘手的问题:“哪种吉他调音最好?”这次并没有直接显示出答案片段,而是需要点击搜索引擎推荐的网页链接,跳转到各个网站中才能找到我们想要的答案。
这项技术背后的方法被称为问答系统,问答系统有各种各样的类型,但最为常见的是提取式问答系统,它将所涉问题的答案识别为文档中的一小段文本,这里的文档可以是网页、法律合同或新闻文章。这种先查到相关文档,然后再从中提取答案的两阶段处理方式,是许多现代问答系统的理论基础,像语义搜索引擎、智能助手或者自动信息提取器,都是基于这种理论来构建的。在本节中,我们将使用这种处理方式来解决电商网站所面临的一个常见问题:帮助消费者解答特定问题,帮助其了解一个商品。在这个场景中,把用户的评论当作问答系统的文本数据源,在此过程中,我们将了解到Transformer模型如何作为强大的阅读理解工具,来从文本中提取有价值的信息。
- 什么是问答系统?
问答系统(Question Answering, QA)是一种自然语言处理(NLP)任务,旨在从给定的文本或知识库中找到问题的答案。这些系统可以分为以下几种类型:
- 开放域问答系统:能够回答关于广泛主题的问题,通常需要从大量未结构化数据中提取答案。
- 封闭域问答系统:专注于特定领域内的问题,通常基于领域特定的知识库。
- 基于文本的问答系统:直接从给定的文本(如一段文章)中提取答案。
- 知识库问答系统:从结构化的知识库(如数据库)中检索答案。
- 问答系统的实现方式
构建问答系统有多种方法,每种方法都有其优缺点。以下是一些常见的实现方式:
- 1. 基于规则的方法
这种方法依赖于预定义的规则和模板来匹配问题并从文本中提取答案。这种方法适用于简单且格式固定的问答任务,但在处理复杂和多变的问题时效果不佳。
- 2. 基于信息检索的方法
这类系统首先使用信息检索技术找到与问题相关的文档,然后从这些文档中提取答案。典型的步骤包括:
- 文档检索:从大型文档库中找到最相关的文档。
- 段落检索:从相关文档中找到最相关的段落。
- 答案提取:从相关段落中提取答案。
- 3. 基于深度学习的方法
深度学习方法已经显著提高了问答系统的性能。常见的模型包括:
- BERT(Bidirectional Encoder Representations from Transformers):一个双向Transformer模型,可以理解上下文并从中提取答案。
- RoBERTa(Robustly optimized BERT approach):BERT的改进版,性能更强。
- DistilBERT:BERT的轻量级版本,计算效率更高。
这些模型通常在大型问答数据集(如SQuAD)上进行预训练,然后在特定任务上进行微调。
- 基于深度学习的问答系统构建步骤
以下是使用Hugging Face的Transformers库构建基于深度学习的问答系统的步骤:
- 1. 安装库
pip install transformers torch
- 2. 加载预训练模型和Tokenizer
from transformers import AutoTokenizer, AutoModelForQuestionAnswering # 加载预训练的BERT模型和tokenizer tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad") model = AutoModelForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
- 3. 编写问答函数
import torch def answer_question(question, context): inputs = tokenizer.encode_plus(question, context, return_tensors="pt") input_ids = inputs["input_ids"].tolist()[0] outputs = model(**inputs) answer_start_scores = outputs.start_logits answer_end_scores = outputs.end_logits # 获取答案的开始和结束位置 answer_start = torch.argmax(answer_start_scores) answer_end = torch.argmax(answer_end_scores) + 1 # 将答案token转换为字符串 answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])) return answer
- 4. 测试问答系统
context = "Hugging Face 是一个开源社区,专注于自然语言处理技术。" question = "Hugging Face 是什么?" answer = answer_question(question, context) print(f"Question: {question}") print(f"Answer: {answer}")
本节着重介绍提取式问答,不同场景适用的问答形式也不同。比如,技术社区的问答系统收集的是用户在Stack Overflow(https://stackoverflow.com)等技术论坛上的问答对,然后使用语义相似度搜索来找到与新问题最匹配的答案。还有开放域长格式(long-form)问答,旨在为诸如“为什么天空是蓝色的?”之类的开放性问题生成复杂的长文本答案。另外还可以针对表格,像TAPAS(https://oreil.ly/vVPWO)这种Transformer模型能为表格生成聚合操作语句,来获取相关信息。
三、用Haystack构建问答pipeline
在本节前面的示例中,我们为模型传入问题和上下文,就能得到答案。但在实际业务场景中,用户只会提出关于商品的问题,因此需要找到某种方式来从语料库中的所有评论中选出相关的文本段。一种方式是将给定商品的所有评论拼接在一起,再将拼接好的长文本提供给模型。这种方式看似简单,但却有明显的缺点,那就是会使上下文变得特别长,从而影响处理效率,带来很高的延迟。例如,假设平均每个商品有30个评论,每条评论的处理时间是100ms,如果使用这种方式来处理并获取答案,则会使每次查询操作都不会少于3s,这种体验对于电商网站来说是非常糟糕的。
为了解决这个问题,现在的问答系统通常都基于检索器-阅读器(Retriever-Reader)架构,从名称就可以看出,这种架构有两个主要组件:
1、检索器
如果向量的大部分元素为0,则称该向量是稀疏向量。
检索器(Retriever)旨在为给定查询操作检索相关文档,目前的检索器通常分为三类:稀疏检索器(Sparse Retriever)、密集检索器(Dense Retriever)和迭代检索器(Iterative Retriever)。稀疏检索器使用词频将每个文档和查询表示为一个稀疏向量(sparse vector) ,然后通过计算向量内积来确定查询和文档的相关性,但稀疏检索不能解决术语不匹配问题,在问题与文档相似但不存在重复术语的情况下,稀疏检索效果较差。随着深度学习的逐渐成熟,发展出了密集检索器,密集检索器使用类似Transformer的编码器将查询和文档表示为上下文嵌入(密集向量)。这些嵌入将语义编码,通过理解查询内容来提高搜索准确率。迭代检索器则是通过多次迭代从大集合从检索相关文档。
2、阅读器
阅读器(Reader)旨在从检索器输出的文档中提取答案。阅读器通常是一个阅读理解模型,在本章末尾我们将见到可以生成具有自由格式答案的模型样例。
如下图所示,还有其他组件能对检索器获取的文档或阅读器提取的答案做后处理。例如,检索出来的文档可能需要以重新排序的方式,来消除噪声或那些可能让使用者无法理解的文档。同样,当正确答案来自长文档不同段落时,通常需要对答案进行后处理。
我们将使用Haystack库(https://haystack.deepset.ai)来构建问答系统,它是一家专注于NLP领域的德国公司deepset(https://deepset.ai)所开发的。Haystack基于检索器-阅读器架构,它将构建问答系统的大部分复杂性抽象出来,并与Hugging Face Transformers库紧密集成。
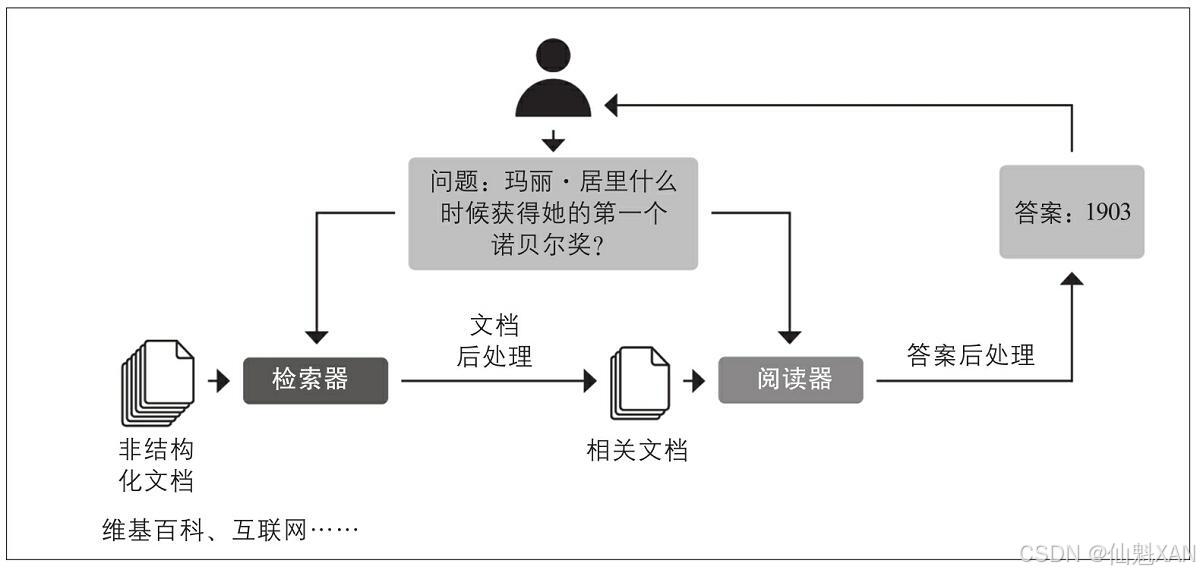
除了检索器和阅读器之外,在使用Haystack构建问答pipeline时还需要另外两个组件:
1)Document Store
文档存储器,用于存储在检索时提供给检索器的文档和元数据。
2)Pipeline
流程控制器,封装了问答系统所有流程组件,用以编写自定义检索流程或者合并多个检索器处理后的文档等。
在本节中,我们将了解如何使用这些组件构建一个问答pipeline的原型系统,之后的内容将研究如何提升它的性能。
本节内容全部基于Haystack 0.9.0版本库编写,在0.10.0版本库(https://oreil.ly/qbqgv)中,pipeline API和用于评估的API均已被重构,目的是更易于探查检索器或阅读器是否影响了整体性能。如果想获知本章代码使用新版API如何编写,可以查看相关GitHub仓库(https://github.com/nlp-with-Transformers/notebooks)。
3、初始化文档存储
在Haystack中,有多种文档存储可供选择,每一种都能与一组专用的检索器组合配对。如下表所示,其中展示了稀疏检索器(TF-IDF和BM25)和密集检索器(Embedding和DPR)与所有可选文档存储器的兼容关系,我们将在本节后面内容解释这些缩写的含义。

于我们在本节中会使用稀疏检索器和密集检索器,因此这里选用Elasticsearch作为文档存储器,因为它与两种类型的检索器都兼容。Elasticsearch是一种搜索引擎,能够处理多种数据类型,包括文本、数字、地理空间、结构化数据和非结构化数据。它能够存储大量数据并使用全文搜索功能快速过滤数据,因此也特别适合用于开发问答系统。Elasticsearch目前基本上已经成为基础设施分析行业的一个标准,应用范围非常广,因此你的公司很有可能已经拥有了可以直接使用的Elasticsearch集群。
该使用手册还提供了MacOS和Windows的安装说明。
要初始化文档存储,需要下载安装Elasticsearch,按照Elasticsearch的使用手册(https://oreil.ly/bgmKq) ,使用wget命令下载压缩包,并用tar命令解压:
url = """https://artifacts.elastic.co/downloads/elasticsearch/\
elasticsearch-7.9.2-linux-x86_64.tar.gz"""
!wget -nc -q {url}
!tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz下面我们来启动Elasticsearch服务器,由于本书完全是在Jupyter notebook中运行所有代码,因此我们需要使用Python的Popen()函数来开启一个新进程
(Windows 下 Elasticsearch 安装见附录 ):
(有些版本不行,不能正常启动成功,elasticsearch-7.9.2-windows-x86_64 测试可以)
import os
from subprocess import Popen, PIPE, STDOUT
import time
# 确保 Elasticsearch 文件夹的路径正确
es_path = r'D:\Software\elasticsearch-7.9.2-windows-x86_64\elasticsearch-7.9.2\bin\elasticsearch.bat' # 修改为你的实际路径
# 运行 Elasticsearch 作为后台进程
es_server = Popen(
args=[es_path], # 指定要运行的 Elasticsearch 可执行文件路径
stdout=PIPE, # 将标准输出定向到管道
stderr=STDOUT # 将标准错误定向到标准输出
)
# 打印启动日志
print("Elasticsearch is starting...")
time.sleep(60) # 等待 Elasticsearch 启动
# 检查 Elasticsearch 是否已启动并输出日志
for line in es_server.stdout:
decoded_line = line.decode().strip()
print(decoded_line)
if "started" in decoded_line:
print("Elasticsearch has started successfully.")
break
else:
print("Elasticsearch did not start successfully.")运行结果:
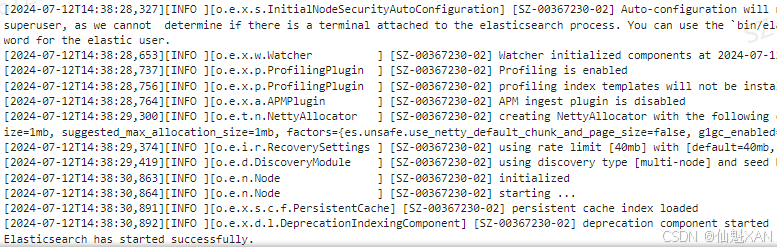
在Popen()函数中,args参数需要指定希望运行的程序,stdout=PIPE参数表示为标准输出创建一个新管道,stderr=STDOUT参数收集该管道的错误信息,preexec_fn参数表示指定该程序运行的ID。Elasticsearch默认监听9200端口,可以通过它来发送HTTP请求到localhost,验证是否启动成功:(浏览器中输入:http://localhost:9200/)
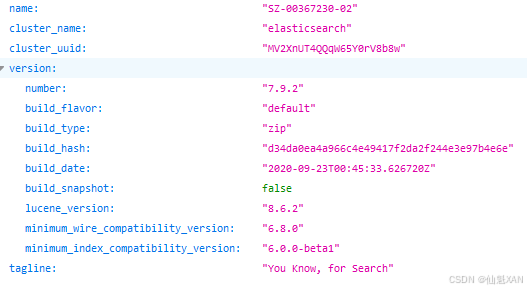
显示上面的内容就表示Elasticsearch已经启动成功了,接下来要做的就是实例化文档存储对象:
from haystack.document_stores.elasticsearch import ElasticsearchDocumentStore # 确保导入路径正确
# 创建一个 ElasticsearchDocumentStore 实例,并设置返回嵌入向量,以便后续使用密集检索器
document_store = ElasticsearchDocumentStore(return_embedding=True)默认情况下,ElasticsearchDocumentStore实例化之后会在Elasticsearch创建两个索引,一个叫作document,用于存储文档,另一个叫作label,用于存储带标注的答案片段。接下来将SubjQA数据集的评论设置为文档的索引,Haystack的文档存储需要一个包含带文本和元键的字典,字段名称为text和meta,如下所示:

meta字段中的信息可以提供给检索器作为过滤条件使用。对于本书介绍的这个场景,我们提取SubjQA数据集的item_id和q review_id列,这样就可以按商品和问题ID结合相应的训练进行过滤。然后遍历每个DataFrame,使用write_documents()方法将它们添加到索引中,如下所示:
from haystack import Document
for split, df in dfs.items():
# 排除重复的评论
docs = [Document(
content=row["context"], # 将评论文本作为文档的文本内容
meta={"item_id": row["title"], "question_id": row["id"], "split": split} # 将标题、ID 和数据分割信息作为元数据
) for _, row in df.drop_duplicates(subset="context").iterrows()] # 去重,按 "context" 列去除重复项
document_store.write_documents(docs, index="document") # 将文档写入 Elasticsearch 文档存储
# 打印加载的文档数量
print(f"Loaded {document_store.get_document_count()} documents")运行结果:
Loaded 1615 documents
执行上述操作,就将所有评论信息加载到了索引中。如何检索这些索引呢?这时就需要用到检索器了,下面来看看如何为Elasticsearch初始化一个检索器。
4、初始化检索器
Elasticsearch兼容Haystack提供的所有检索器,下面使用稀疏检索器BM25(“Best Match 25”的缩写)来进行讲解。BM25是经典的TF-IDF(Term Frequency-Inverse Document Frequency)算法的改进版本,可以将问题和上下文转化为可以在Elasticsearch中进行快速检索的稀疏向量。BM25分数可以用以度量匹配到的文本与检索的相关程度,在TF-IDF基础上通过快速饱和TF值和规范化文档长度来获得更好的效果,所以更加倾向于用在短文本检索领域 。
在Haystack中,ElasticsearchRetriever默认使用BM25检索器,下面是它的初始化方式:
from haystack.retriever.sparse import ElasticsearchRetriever
# 创建 Elasticsearch 检索器,使用之前创建的 Elasticsearch 文档存储
es_retriever = ElasticsearchRetriever(document_store=document_store)
接下来我们看看如何查询训练集中的某个电子产品。对于像本章中这种基于评论的问答系统来说,将查询范围限制到某一类别非常重要,否则检索器将去检索与用户查询无关的商品评论。例如,查询“这个相机质量好吗?”,如果没有商品过滤器,则可能会返回有关于手机的评论信息,而用户实际上想知道某款笔记本电脑摄像头的质量怎么样。数据集中的item_id是Amazon的ASIN编号,它是Amazon商品的一个特殊的编码标识,可以登录Amazon ASIN查询网站(https://amazon-asin.com)来查看具体的商品信息。下面代码段中的ASIN编号对应于Amazon的一款Fire品牌的平
板电脑,我们使用retrieve()方法来检索“它是否适用于阅读?”的答案:
# 设置要检索的商品 ID 和查询语句
item_id = "B0074BW614"
query = "Is it good for reading?"
# 使用 Elasticsearch 检索器检索相关文档
retrieved_docs = es_retriever.retrieve(
query=query, # 设置查询语句
top_k=3, # 检索结果的数量,这里设置为前 3 条
filters={ # 设置过滤器,限定商品 ID 和数据集分割(例如 "train")
"item_id": [item_id],
"split": ["train"]
}
)
在以上代码片段中,我们使用top_k参数指定返回的文档数量,并对包含在meta字段中的item_id和split键都使用了过滤器。retrieved_docs中的每一个元素都是一个Haystack的文档对象,其中包括具体的文档信息,以及检索器本次查询的分数和其他元数据。下面是一个retrieved_docs信息示例:
# 打印检索到的第一个文档,这里假设 retrieved_docs 是一个包含检索结果的列表
print(retrieved_docs[0])
运行结果:
{'text': 'This is a gift to myself. I have been a kindle user for 4 years and
this is my third one. I never thought I would want a fire for I mainly use it
for book reading. I decided to try the fire for when I travel I take my laptop,
my phone and my iPod classic. I love my iPod but watching movies on the plane
with it can be challenging because it is so small. Laptops battery life is not
as good as the Kindle. So the Fire combines for me what I needed all three to
do. So far so good.', 'score': 6.243799, 'probability': 0.6857824513476455,
'question': None, 'meta': {'item_id': 'B0074BW614', 'question_id':
'868e311275e26dbafe5af70774a300f3', 'split': 'train'}, 'embedding': None, 'id':
'252e83e25d52df7311d597dc89eef9f6'}
以上除了检索出的文档结果之外,我们还可以看到Elasticsearch计算出的查询分数(分数越高,匹配度越高)。Elasticsearch底层使用Lucene(https://lucene.apache.org)进行索引和搜索,所以Elasticsearch默认使用Lucene的评分函数。如果想深入了解,可以在Elasticsearch文档(https://oreil.ly/b1Seu)中找到评分函数的细节。简而言之,它首先使用布尔测试(文档与查询内容是否匹配)来对待选文档进行过滤,然后应用基于将文档和查询表示为向量的相似度度量方式来进行评分。
到目前为止,我们了解了一种检索相关文档的方法,接下来讲解一种从文档中提取答案的方法,以及如何在Haystack中加载MiniLM模型。
5、初始化阅读器
在Haystack中,有两种类型的阅读器可以用来从给定的上下文中提取答案。
1)FARMReader
基于deepset公司研发的FARM框架(https://farm.deepset.ai),用来对Transformer进行微调操作和部署操作,它完全兼容经Hugging Face Transformers库训练出的模型,也可以直接加载Hugging Face Hub上的模型。
2)TransformersReader
基于Hugging Face Transformers库的问答pipeline,仅用于推理。
尽管两个阅读器都以相同的方式处理模型的权重,但它们在将预测结果转换成答案的方式上存在一些差别:
●在Hugging Face Transformers库中,问答pipeline在每个文本段中使用softmax对开始和结束的logit进行规范化处理,也就是说,只有在分数之和为1的情况下,在同一段文本中提取的答案的分数才有相互比较的意义。一段文本的答案分数为0.9,不一定比另一段分数为0.8的文本答案效果好。在FARM中,logit也没有规范化,因此也只能比较同一个文本段的答案。
●TransformersReader有时会两次预测出相同的答案,但分数却不一样,这是因为窗口将答案截断,两个窗口中都有答案片段,在FA R M中,这些重复项会被删除。
由于本节后续内容包括对Reader进行微调操作,我们会用到FARMReader。与Hugging Face Transformers库一样,需要在Hugging Face Hub上指定MiniLM的checkpoint和一些问答特定的参数来加载模型。
# 导入 FARMReader 类,用于从文档中提取答案
from haystack.reader.farm import FARMReader
# 定义用于阅读理解的预训练模型的路径或名称
model_ckpt = "deepset/minilm-uncased-squad2"
# 设置最大序列长度和文档步进大小,以控制模型的输入大小
max_seq_length, doc_stride = 384, 128
# 初始化 FARMReader 实例,配置模型加载参数
reader = FARMReader(
model_name_or_path=model_ckpt, # 模型路径或名称
progress_bar=False, # 禁用进度条显示
max_seq_len=max_seq_length, # 最大输入序列长度
doc_stride=doc_stride, # 文档步进大小
return_no_answer=True # 是否返回未找到答案的情况
)
也可以直接在Hugging Face Transformers库中微调阅读理解模型,然后将其加载到TransformersReader中进行推理,关于如何进行微调的详细信息,请参阅文档(https://oreil.ly/VkhIQ)。
在FARMReader中,滑动窗口的行为由词元分析器中的max_seq_length和doc_stride参数控制,这里我们直接使用MiniLM论文中的值,下面使用一个之前的例子来测试Reader的效果:
# 输出阅读器对给定问题和文本的预测答案,返回最可能的顶级答案
print(reader.predict_on_texts(question=question, texts=[context], top_k=1))
运行结果:
{'query': 'How much music can this hold?', 'no_ans_gap': 12.648084878921509,
'answers': [{'answer': '6000 hours', 'score': 10.69961929321289, 'probability':
0.3988136053085327, 'context': 'An MP3 is about 1 MB/minute, so about 6000 hours
depending on file size.', 'offset_start': 38, 'offset_end': 48,
'offset_start_in_doc': 38, 'offset_end_in_doc': 48, 'document_id':
'e344757014e804eff50faa3ecf1c9c75'}]}
可以看出,Reader的效果满足预期,到这里,所有的子步骤已经完成,接下来使用Haystack Pipeline将所有组件打包成一个完整的pipeline。
5、问答pipeline组装
Haystack提供了Pipeline抽象模块,用来将检索器、阅读器和其他组件以图的形式集成在一起,按需定制pipeline。另外还有一些类似Hugging Face Transformers库中那样可以预定义的pipeline,专门为问答系统设计。这里我们使用它制作一个用于答案提取的pipeline,会用到ExtractiveQAPipeline,它需要用一对检索器-阅读器作为其参数:
# 导入 ExtractiveQAPipeline 类从 haystack.pipeline 模块中
from haystack.pipeline import ExtractiveQAPipeline
# 创建一个 ExtractiveQAPipeline 实例,将阅读器(reader)和 Elasticsearch 检索器(es_retriever)作为参数传入
pipe = ExtractiveQAPipeline(reader, es_retriever)
每个Pipeline都有一个run()方法来执行整个pipeline,只需要设置一些参数。对于ExtractiveQAPipeline来说,需要设置query参数,使用top_k retriever指定提取的文档数量,以及使用top_k_reader指定从这些文档中提取的答案数量,还需要像之前那样设置filters参数。下面再次使用关于Amazon Fire平板电脑的那个问题来获取答案:
# 设置要返回的答案数量
n_answers = 3
# 运行管道,查询问题,并进行检索和读取操作
preds = pipe.run(
query=query, # 查询问题
top_k_retriever=3, # 检索器返回的顶部文档数
top_k_reader=n_answers, # 阅读器返回的顶部答案数
filters={"item_id": [item_id], "split":["train"]} # 过滤器,限定检索的条件
)
# 打印查询问题
print(f"Question: {preds['query']} \n")
# 遍历返回的答案列表并打印每个答案及其相关文本片段
for idx in range(n_answers):
print(f"Answer {idx+1}: {preds['answers'][idx]['answer']}")
print(f"Review snippet: ...{preds['answers'][idx]['context']}...")
print("\n\n")
运行结果:
Question: Is it good for reading? Answer 1: I mainly use it for book reading Review snippet: ... is my third one. I never thought I would want a fire for I mainly use it for book reading. I decided to try the fire for when I travel I take my la... Answer 2: the larger screen compared to the Kindle makes for easier reading Review snippet: ...ght enough that I can hold it to read, but the larger screen compared to the Kindle makes for easier reading. I love the color, something I never thou... Answer 3: it is great for reading books when no light is available Review snippet: ...ecoming addicted to hers! Our son LOVES it and it is great for reading books when no light is available. Amazing sound but I suggest good headphones t...
pipeline按照预期返回了答案数组,一个端到端用于Amazon商品评论的问答系统就完成了。但是我们从结果中可以发现,似乎第二个答案和第三个答案更接近问题的实际要求。为了优化这一点,需要一些指标来量化检索器和阅读器的性能
附录:
一、Windows 下 安装 Elasticsearch
Elasticsearch 是一个开源的分布式搜索和分析引擎,主要用于处理各种类型的数据,包括结构化和非结构化数据。它通常被用来进行全文搜索、日志和指标分析、应用程序性能监控以及其他相关的实时数据分析任务。
1、到 官网下载安装包
官网:Download Elasticsearch | Elastic
7.9.2 :Elasticsearch 7.9.2 | Elastic
2、下载好后,解压压缩包

3、在 bin 文件夹下即可找到对应的 .bat 文件
二、Elasticsearch 简单介绍
Elasticsearch 是一个开源的分布式搜索和分析引擎,主要用于处理各种类型的数据,包括结构化和非结构化数据。它通常被用来进行全文搜索、日志和指标分析、应用程序性能监控以及其他相关的实时数据分析任务。以下是对 Elasticsearch 的一些关键特性和用途的详细介绍:
1、关键特性
分布式架构:
- Elasticsearch 可以在多个节点上分布运行,能够处理大量的数据和复杂的查询。其分布式性质使得它具有高可用性和可扩展性。
全文搜索:
- Elasticsearch 使用反向索引结构,能够非常高效地执行全文搜索。它支持复杂的查询语法,包括布尔查询、范围查询、地理位置查询等。
近实时搜索:
- Elasticsearch 的搜索速度非常快,通常在数据写入后的一秒钟内即可被搜索到,这使得它在需要快速响应的应用场景中非常有用。
多租户支持:
- Elasticsearch 可以在同一集群中管理多个索引,每个索引可以独立设置和操作,这为不同的应用提供了多租户支持。
RESTful API:
- Elasticsearch 提供了丰富的 RESTful API,使得与它的交互非常简单。通过 HTTP 请求,可以轻松执行索引、搜索、更新和删除操作。
集成与扩展:
- Elasticsearch 与许多其他工具和框架集成良好,如 Logstash、Kibana 和 Beats,它们共同组成了 Elastic Stack(简称 ELK Stack),用于数据采集、处理和可视化。
2、常见用途
搜索引擎:
- 许多网站和应用程序使用 Elasticsearch 作为其搜索引擎,提供快速和相关性高的搜索结果。
日志分析:
- Elasticsearch 常用于日志数据的收集和分析,帮助企业监控和排查系统问题。通过 Logstash 或 Beats 采集日志,再通过 Kibana 进行可视化分析,是一个常见的日志管理解决方案。
数据存储和分析:
- 由于其强大的查询能力和快速的检索速度,Elasticsearch 常被用来存储和分析各种数据,如用户行为数据、财务数据、传感器数据等。
安全信息和事件管理 (SIEM):
- Elasticsearch 可以用于安全日志的分析和监控,帮助企业发现和应对潜在的安全威胁。
3、示例应用场景
电子商务网站:
- 使用 Elasticsearch 来实现快速、智能的产品搜索,提供个性化推荐。
社交媒体平台:
- 用于实时搜索和分析用户生成内容,监控和管理平台内容。
监控和告警系统:
- 通过 Elasticsearch 分析系统日志和指标,构建监控和告警系统,确保系统的健康运行。
Elasticsearch 因其强大的功能、扩展性和易用性,成为了现代数据处理和分析的一个重要工具。