最近看到Java相关的面试时,看到一篇关于HashMap的相关面试知识点,感觉蛮好的!现在的面试点不会围绕某个知识让面试者去详细阐述,而会通过一些系列的相关问题去让你阐述,进而形成从点到线,再由线到面来考察面试者的基本功和发散性思维。无穷无尽地深入,知道你回答不出来或者面试官问到底!
面试官:1、你了解/使用过HashMap吗?为什么是使用HashMap?
这个问题相信你一定可以或多或少的回答出来一些相关知识,比如一些特性(优点)!这仅仅是一个考察你对HashMap的前奏!
比如:
- HashMap是一个散列桶(直观的说出来HashMap的数据结构特性:数组和链表),存储的是key-value(键值对)映射
- HashMap采用了数组和链表节后的数据结构,能在查询和修改便于继承了数组的线性查找和链表的寻址修改提高效率
- HashMap是非安全的(非synchronized),所以不保证安全的情况下,速度很快
- HashMap可以是key和value都是null,而Hashtable则不能(原因是Hashtable使用equal方法会产生空指针异常,而HashMap经过API处理过的,不会出现在这种情况)
- 等等
回答到这儿,相信面试官已经知道你了解和使用过HashMap,但面试官会急转之下,深入问道一些刁钻或你对此比较模糊认识的问题,比如一些具体详细的问题
面试官:2、你知道HashMap的工作原理吗?你知道HashMap的put、get方法工作原理吗?
!!??我去!一脸懵!或许你使用HashMap非常的666,但工作原理?艾玛!真的没有深入研究吧!如果你真的不知道的话,也就意味着这个话题终结,但你说一些错误的问题,那就很危险了!面试就是,知道的说,不知道的就直接说不知道,态度很重要!!
来吧,看看这个问题考察的东西吧!
就第一个问题来说:
HashMap是基于hashing的原理!使用HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。
到此,你已经回答出来的HashMap的工作原理,但是(关键指出,HashMap是在backet中存储键和值对象,作为Map的节点Map.Entry),这个有利于你对应get方法获取对象的工作原理,如果你没有意识到这一点的话,或许不仅仅认为只在backet中存储值的话,你就无法回答是如何获取对象的。
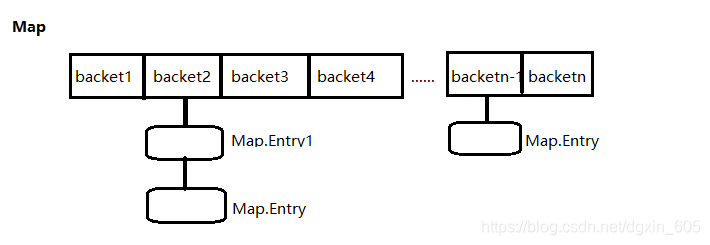
简化模拟一下数据结构
Node[] table = new Node[16]; //散列桶初始化,table
// 节点数据结构
class Node{
int hash; // hash值
key; // 键
value; // 值
Node next; // 用于指向链表的下一层(产生冲突,使用拉链法)
}就第二个问题来说:
put源码
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}put过程大致可以分为一下阶段(针对常用的jdk1.8)
- 对key值进行Hash值计算(hash方法),然后再在计算下标
- 如果key对象没有在backet中存在,则直接放在桶中存储(也称之为碰撞)
- 如果key对象存在,则会以链表的方式存储链接在后面
- 如果链表的长度超过了阈值(TREEIFY THRESHOLD==8),就会把链表转换为红黑树,链表长度低于6,就把红黑树转换为链表
- 如果节点存在,就会替换旧值
- 如果桶满(容量16*加载因子0.75),就会resize(扩容2倍重排)
get源码
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}get获取对象的工作原理
上面已经对于put方法,那对于get方法就简单了很多
当我们调用get方法时,HashMap会使用键对象的hashcode找到bucket的位置,找到bucket位置后,会调用keys.equal()方法去找到链表中正确节点,最终找到值对象
或许以上仅仅是HashMap故事的开始,面试官会在日常开发中遇到的问题来深入询问你的掌握程度。
面试官:3、当两个对象的hashcode相同会发生什么?
看到这个问题的第一反应该是:我去,又是一脸懵!!
从这里开始,真正的困惑开始了,一些面试者会回答因为hashcode相同,所以两个对象是相等的,HashMap将会抛出异常,或者不会存储它们等等,各种答案,五花八门!然后面试官可能会提醒你hashcode和equal两个方法,也有可能有些面试者会直接放弃面试,当然这样关于HashMap的问题就此结束的。
当然会有一些优秀的面试者会继续前进:如果hashcode相等,则可以判断他们的bucket位置相同,会产生“碰撞”,因为HashMap使用链表存储对象,这个Entry(包含键值对的Map.Entry对象)会存储链表。这个答案是在点的,也非常合理。虽然有很多处理碰撞的方法,但这种方法是最简单的,也真是处理HashMap的方法。
但是,故事好没有结束,问题还会继续。哥们儿!挺住....、
面试官:4、如果两个键的hashcode相同,你会如何获取值对象?
当然,获取Map的值对象肯定是通过get方法,那就围绕着get方法工作原理就坡下驴吧!但是,着是不够的呦!这也不是面试官想要的答案,要不然这个问题也不会出现的(上面已经问过你了!!)。
面试者:当我们调用get方法时,HashMap会使用键对象的hashcode值找到bucket位置,然后获取值对象。
面试官:如果有两个或者多个bucket在同一个位置呢?
面试者:HashMap会遍历链表,直到找到对应的值对象。
面试官:你并没有值对象去比较,你是如何确定确定找到值对象的?(除非面试者直到HashMap在链表中存储的是键值对,否则他们不可能回答出这一题。)
还记得HashMap是在backet中存储键和值对象,作为Map的节点Map.Entry吗?那问题就简单化了
面试者:找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。(完美的答案!)
许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如果你认为到这里已经完结了,那么听到下面这个问题的时候,你会崩溃或者开始紧张了。
面试官:5、如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
除非你真的了解HashMap的工作原理,否则你是回答不出来的......
同时,问到这个问题之后,要及时的意识到面试官要把你往线程安全的方向引入了,做好准备。
你可以这样回答:
当数据过大时候,Map则会进行一次rehashing。
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时,和其他集合类(如Array等)一样,将会创建原来HashMap大小2倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程及时rehashing,毕竟在这个过程中调用hash方法找到了新的bucket位置
回答道现在,面试官还不会放过i的,接着会问你。
面试官:6、你了解重新调整HashMap大小存在什么问题吗?
这个问题往往是在多线程的情况下,当然你需要了解条件竞争,要不然,你还是无法找到切入点。
当调整map大小,会产生条件竞争,因为在多线程条件下,两个线程都发现HashMap需要调整大小,那么就会同时尝试调整,在调整的过程中,存储在LinkedList中的元素次序会进行倒叙排列(因为移动到新的bucket位置时候,HashMap会将元素放在LinkedList的头部,而不是尾部,为了尾部遍历)。一旦条件竞争发生了,就会出现死循环。
问题一步步的引导,你回答的越多,则代表掌握的东西越多,这是必然!
那问题由来了,面试官还会继续问你的!
面试官:7、为什么多线程会导致死循环,它是怎么发生的?
怎么样!?面试官会根据你的回答,一步步引导下去,如果你真的知道上一个问题的答案,那吗对于下一个问题也就不用太担心;相反,当你是蒙的,那就会被面试官一步步的识破,最后的结果会很尴尬的!所以,还是那个原则,不懂的话,直接跳过,不要瞎说哦!
对于这个问题的突破口就是出现死循环的根源是什么?很大程度死循环的产生是数据结构的设置,以及对跟数据的操作不当引起的。那么,HashMap的数据结构你应该很了解了吧!没错,就是数组+链表(JDK8后是数组+链表+红黑树了)!数组?线性结构,无论如何是不会产生死循环的!那就剩下链表了(链表很容易产生回路的)!对!就是他!链表也正是HashMap处理碰撞的方式。
HashMap的容量是有限的。当经过多次元素插入时,使得HashMap达到一定的饱和度(接近加载因子0.75),Key映射位置发生冲突的几率会逐渐提高。这时候,HashMap需要扩展他的长度,也就是进行resize(扩容)。
(当然,这时候你可以范文面试官:很奇怪了,为什么在多线程下使用HashMap呢?嘿嘿嘿,面是过程中不仅仅是面试官问你,同样在不合理情况下,你也可以反问面试官,这样会让面试官感到你独特的一面,所谓艺高人胆大嘛!)
面试官:8、如果我想使用HashMap实现多线程,可以做到吗?
哈哈哈!这个时候估计是面试官对你的质问的一个变相的回应!这个会考察多线程下的HashMap,方法很多比如,加锁(极度不推荐使用,但是可以回答)、使用Collections中的方法封装,也可以使用其他拥有相同效果的类代替等等。
当然可以的。可以使用java.util.Collections.synchronizedMap(Map)的方式进行处理。(这是最简单,最有效的的回答,面试官找不到破绽,即便你知道ConcurrentHashMap等方式)简单回答就行了,至于其他问题,再作回答就好了,要懂得适时的收敛,你懂的!!
哈哈哈!经过一系列的问题,你是不是可以理解面试的方式,其实是一种综合问题的分析,不仅仅是深度,还有广度!所以,小伙伴们,功夫应用在平时,到时候不至于手忙脚乱!
---------------------
作者:编码世界
来源:CSDN
原文:https://blog.csdn.net/dgxin_605/article/details/86249771
版权声明:本文为博主原创文章,转载请附上博文链接!!