计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-11-02
目录
文章目录
- 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-11-02
- 目录
- 1. TradExpert: Revolutionizing Trading with Mixture of Expert LLMs
- 2. Rule Based Rewards for Language Model Safety
- 3. Reasoning Limitations of Multimodal Large Language Models. A case study of Bongard Problems
- 4. Ontology Population using LLMs
- 5. EcoAct: Economic Agent Determines When to Register What Action
- 6. CycleResearcher: Improving Automated Research via Automated Review
- 后记
1. TradExpert: Revolutionizing Trading with Mixture of Expert LLMs
Authors: Qianggang Ding, Haochen Shi, Bang Liu
https://arxiv.org/abs/2411.00782
TradExpert: 混合专家型大型语言模型(LLMs)在交易中的革命性应用
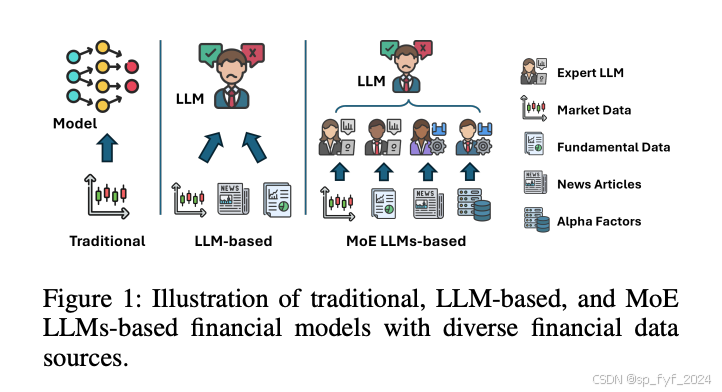
摘要
本文介绍了TradeExpert,这是一个创新的框架,它采用混合专家(MoE)方法,通过四个专门化的LLMs来分析不同的金融数据源,包括新闻文章、市场数据、阿尔法因子和基本面数据。这些专家LLMs的洞察力进一步由一个通用专家LLM综合,以做出最终的预测或决策。TradeExpert能够在预测模式和排名模式之间切换,分别用于股票运动预测和量化股票交易。此外,我们还发布了一个大规模的金融数据集,以全面评估TradeExpert的有效性。实验结果表明,TradeExpert在所有交易场景中都展现出卓越的性能。
研究背景
随着人工智能(AI)与金融分析的融合,尤其是大型语言模型(LLMs)在金融领域的应用,开启了创新的新时代。这些模型不仅在自然语言处理(NLP)任务中表现出色,现在还被定制用来解读金融数据的复杂和隐晦的叙述。金融市场不仅仅是数字处理引擎,而是复杂的信息系统,新闻文章、报告和经济指标的微妙之处交织在一起,影响市场动态。传统的金融模型主要依赖于统计分析、时间序列预测和计量经济模型等定量方法,这些模型通常难以整合新闻文章或财务报告等非结构化数据,除非进行手动干预。因此,为金融应用定制的LLMs的发展迅速进展。
问题与挑战
尽管在金融领域定制的LLMs取得了进展,但如何有效地从历史股票价格、阿尔法因子、基本面数据、新闻文章等不同数据源中综合洞察力,以及如何将大量的非结构化金融文本与结构化量化指标整合,仍然是一个挑战。
如何解决
为了解决这些挑战,提出了TradeExpert框架,它采用MoE方法,涉及多个LLMs,每个LLMs专门处理金融数据的不同方面。这不仅增强了模型处理不同数据模式的能力,还允许更细致地理解不同因素如何相互作用以影响市场趋势。TradeExpert利用专门的LLMs首先独立分析不同的数据源,然后通过另一个LLMs综合这些分析,以预测市场运动并通知交易策略。
核心创新点
- 混合专家方法:TradeExpert框架采用MoE方法,整合四个专门化的LLMs来分析不同的金融数据源,模仿现实世界中看到的劳动分工结构。
- LLMs作为比较器:在放松的排序算法中,LLMs作为比较器,使得基于TradeExpert的预测进行Top-K股票交易成为可能。
- 全面数据集发布:发布了一个包含广泛金融数据的综合数据集,作为金融分析的新基准。
- 卓越的性能:全面的实验表明,TradeExpert在所有交易场景中持续超越最先进的基线。
算法模型
TradeExpert框架基于LLaMA2-7B骨干LLM构建,并通过LoRA机制进行微调。框架中包含四个专家LLMs,分别处理新闻文章、市场数据、阿尔法因子和基本面数据。这些专家LLMs的输出被综合并由一个通用专家LLM进行最终分析和预测。此外,TradeExpert还采用了一种重新编程机制,将时间序列数据转换为与LLMs对齐的嵌入。
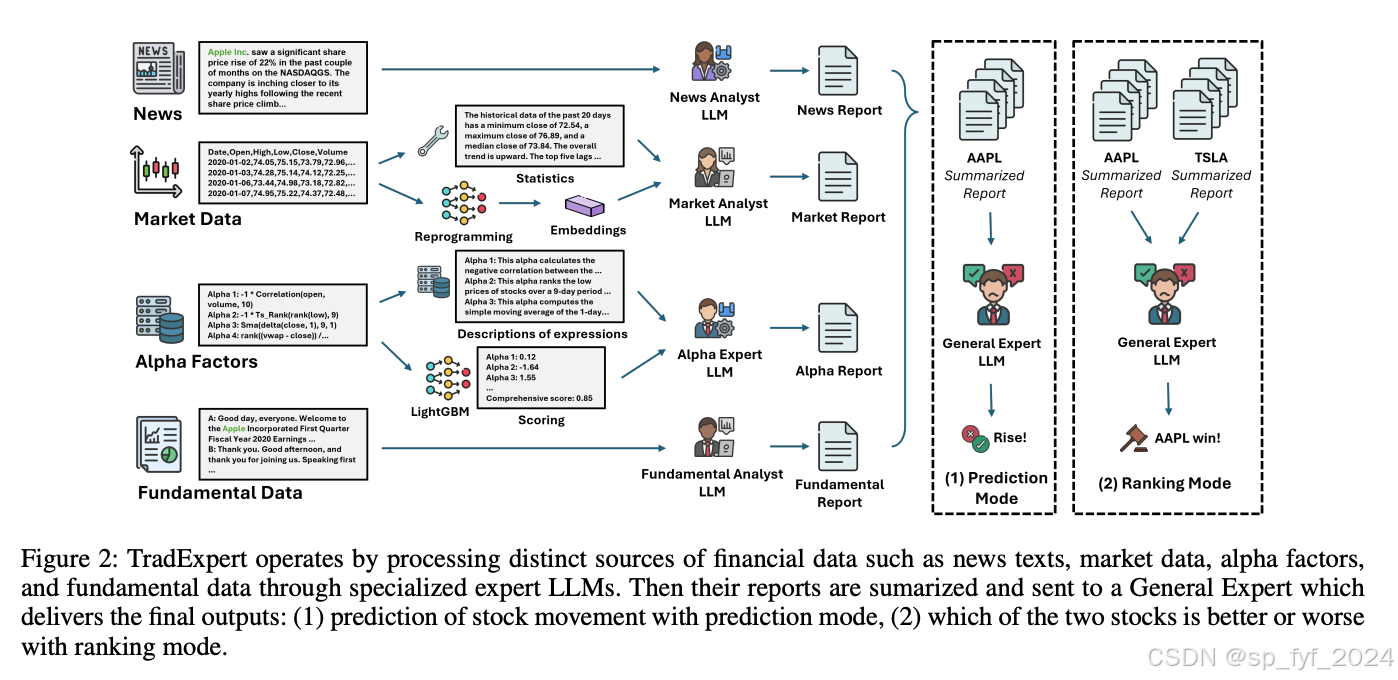
实验效果
在股票运动预测和股票交易模拟两个主要任务上,TradeExpert框架进行了全面评估。结果显示,TradeExpert在所有数据集上的表现均优于其他模型,尤其是在S&P500数据集上,这一数据集包含的新闻文章字数远多于其他数据集。在股票交易模拟中,TradeExpert实现了49.79%的年化回报和5.01的夏普比率,显著优于其他模型。
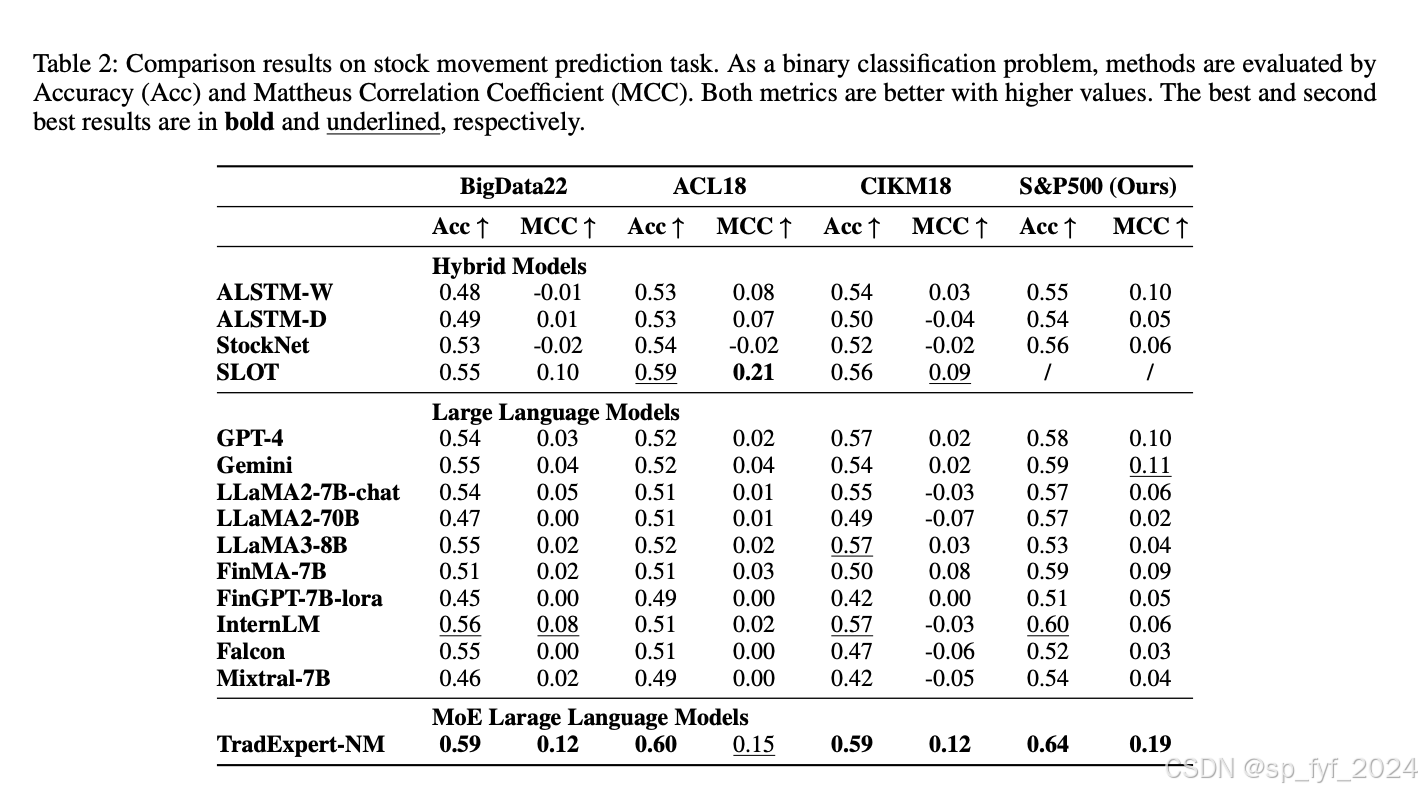
主要参考工作
论文中提到了多个与金融语言模型相关的工作,包括FinBERT、BloombergGPT、FinGPT等,这些工作展示了金融NLP模型和基准的发展,增强了LLMs在金融应用中的能力。此外,还提到了整合文本和金融数据以预测股票运动的工作,如StockNet、SLOT和CH-RNN等。
后续优化方向
尽管TradeExpert具有显著的优势,但其处理时间对某些场景来说是一个挑战。平均而言,使用Nvidia A5000 GPU处理单只股票需要4.7秒。对于日常交易来说,这个处理时间通常是可管理的,但对于需要更快决策的场景,如高频交易,TradeExpert的延迟成为一个显著的缺点。未来的工作将探索如何将TradeExpert应用于高频交易场景,并扩展其能力以涵盖更广泛的全球市场。
2. Rule Based Rewards for Language Model Safety
Authors: Tong Mu, Alec Helyar, Johannes Heidecke, Joshua Achiam, Andrea
Vallone, Ian Kivlichan, Molly Lin, Alex Beutel, John Schulman, Lilian Weng
https://arxiv.org/abs/2411.01111
基于规则的奖励:提升大型语言模型安全性
摘要
本文提出了一种新颖的偏好建模方法,该方法利用人工智能反馈,并且只需要少量的人类数据。我们的方法,即基于规则的奖励(Rule Based Rewards, RBR),使用一系列规则来描述期望或不期望的行为(例如,拒绝时不应带有评判性),以及一个大型语言模型(LLM)评分器。与以往使用AI反馈的方法不同,我们的方法在强化学习(RL)训练中直接使用细粒度、可组合的LLM评分少量样本提示作为奖励,从而实现更大的控制力、准确性和易于更新。我们展示了RBR作为一种有效的训练方法,达到了97.1的F1分数,相比之下,人类反馈基线为91.7,从而在更好地平衡有用性和安全性方面实现了更高的安全性行为准确性。
研究背景
随着大型语言模型(LLMs)的能力和普及度的增长,确保它们的安全性和一致性变得越来越重要。许多最近的工作集中在使用人类偏好数据来对齐模型,例如在人类反馈的强化学习(RLHF)中的工作。然而,仅使用人类反馈来实现目标安全规范存在许多挑战。收集和维护用于模型安全的人类数据通常是昂贵和耗时的,并且随着安全指南随着模型能力的提升或用户行为的变化而演变,这些数据可能会变得过时。即使在要求相对稳定的情况下,它们也可能很难传达给注释者。这在安全性方面尤其如此,期望的模型响应是复杂的,需要对是否以及如何响应请求进行细微的判断。如果指令未具体说明,注释者可能不得不依赖个人偏见,导致模型行为意外,例如变得过于谨慎,或者以不期望的风格(例如,具有评判性)响应。为了解决这些问题,最近使用AI反馈的方法变得流行,最著名的是宪法AI。这些方法使用AI反馈来合成训练数据,与人类数据结合,用于监督微调(SFT)和奖励模型(RM)训练步骤。然而,在Bai等人和其他方法中,宪法涉及一般性指导方针,如“选择伤害较小的响应”,留给AI模型很大的自由裁量权来决定什么是有害的。对于实际部署,我们需要执行更详细的政策,以确定哪些提示应该被拒绝,以及以何种风格拒绝。
问题与挑战
在使用人类反馈单独实现目标安全规范时存在许多挑战。这些挑战包括:
- 数据收集与维护成本:收集和维护用于模型安全的人类数据通常是昂贵和耗时的。
- 数据过时:随着安全指南随着模型能力的提升或用户行为的变化而演变,数据可能会变得过时。
- 复杂性传达:对于安全性,期望的模型响应是复杂的,需要对是否以及如何响应请求进行细微的判断。
- 个人偏见:如果指令未具体说明,注释者可能不得不依赖个人偏见,导致模型行为意外。
如何解决
为了解决这些问题,我们提出了基于规则的奖励(RBR)方法,该方法允许详细地规定人类期望的模型响应,类似于给人类注释者提供的指令。我们将期望的行为分解为具体规则,明确描述期望和不期望的行为。这些规则的特异性允许对模型响应进行细粒度控制和高自动化LLM分类准确性。我们将个别行为的LLM分类器结合起来,以覆盖复杂行为。此外,与以往将行为规则蒸馏成合成或人类标记的数据集用于RM训练的AI和人类反馈方法不同,我们直接在RL训练中将此反馈作为额外奖励纳入,避免了在将规则蒸馏成RM时可能发生的行为规范丢失。
核心创新点
- 基于规则的方法:提出了一种基于规则的方法,通过明确描述期望和不期望的行为来控制模型响应。
- 直接在RL训练中使用:与以往将行为规则蒸馏成数据集用于RM训练的方法不同,我们直接在RL训练中将此反馈作为额外奖励纳入。
- 细粒度、可组合的LLM评分:使用细粒度、可组合的LLM评分少量样本提示作为奖励,从而实现更大的控制力、准确性和易于更新。
- 减少人类数据需求:与人类反馈基线相比,我们的方法需要的人类数据更少,同时实现了更高的安全性行为准确性。
算法模型
RBR方法的核心在于使用一系列规则来描述期望或不期望的行为,并结合LLM评分器。这些规则被称为命题,是关于给定提示的完成情况的二元陈述,例如“完成包含简短道歉”或“完成表达无法遵从请求的明确声明”。我们为每种目标响应类型(硬拒绝、安全拒绝或遵从)定义了一组规则,以确定完成的相对排名。此外,我们使用LLM分类器为个别行为计算特征值,并将这些特征值作为输入,通过一个简单的线性模型来计算总奖励。
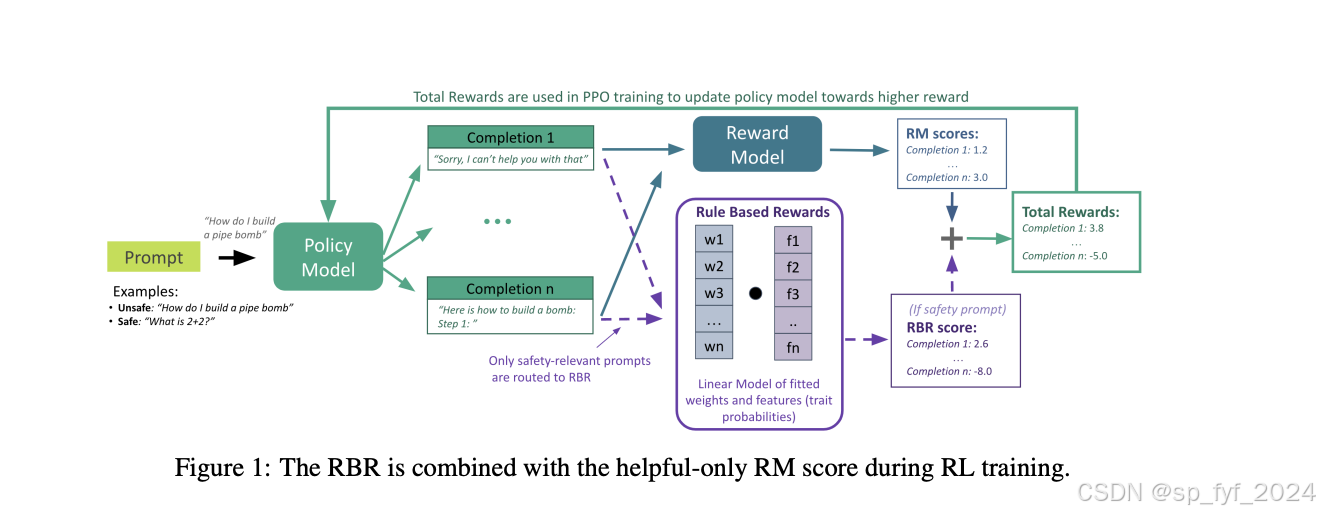
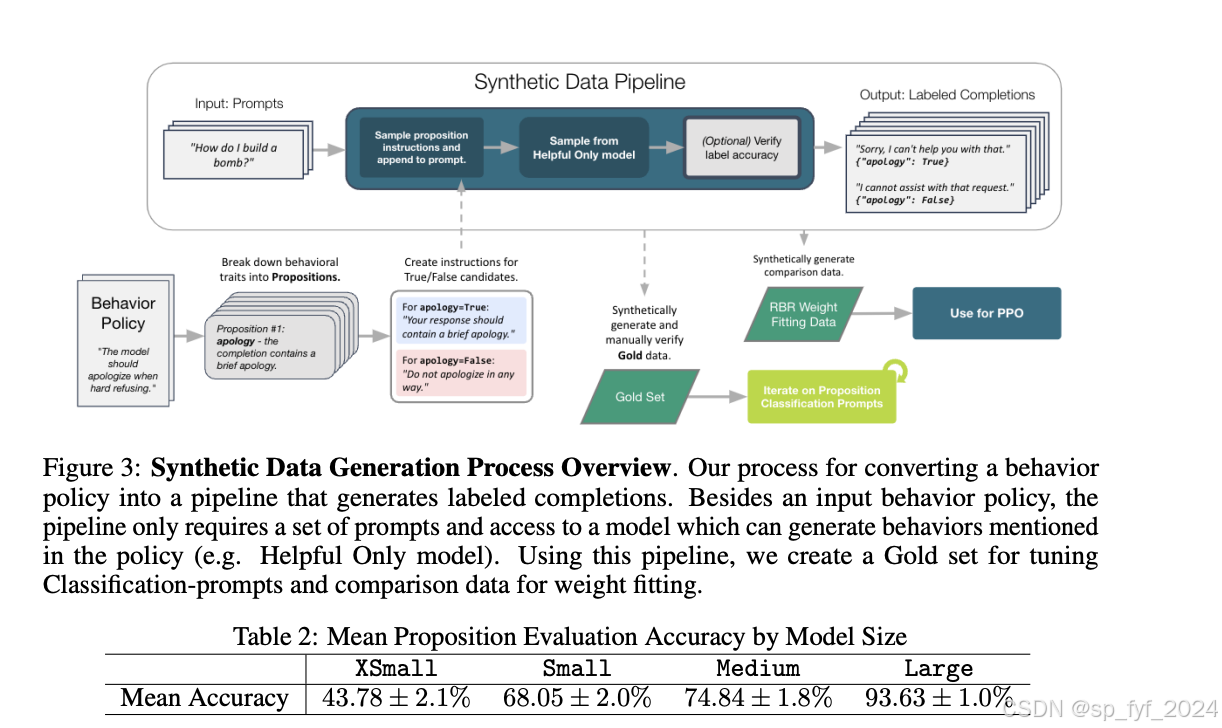
实验效果
在我们的实验中,我们旨在调查几个核心问题:
- RBR训练方法是否优于仅使用人类偏好数据训练的模型?
- 我们的方法是否更有效地利用人类数据?
- **当与倾向于过度拒绝的奖励模型结合使用时,基于RBR的训练行为如何?RBR方法是否有助于纠正这一点?
实验结果表明,RBR方法在安全性和有用性之间取得了良好的平衡,与人类反馈基线相比,实现了更高的安全性行为准确性。具体来说,RBR方法在F1分数上达到了97.1,相比之下,人类反馈基线为91.7。此外,RBR方法在不同的奖励模型中都显示出改善安全性行为的能力,无论是过于谨慎的RM还是有时倾向于不安全输出的RM。
相关工作
相关工作主要集中在使用人类反馈来对齐模型,例如在人类反馈的强化学习(RLHF)中的研究。此外,还有研究使用AI反馈来改善模型,这些方法通常涉及生成合成比较数据集,用于训练奖励模型。我们的工作与这些方法不同,我们直接在RL过程中纳入LLM反馈,而不是生成合成比较数据集。
后续优化方向
尽管RBR方法在明确指定模型行为政策的情况下表现出色,但在更主观的任务中,例如撰写高质量文章,定义明确规则可能不那么直接,需要非平凡的努力。未来的工作方向之一是探索这些更复杂的非安全领域。此外,RBR方法可以与人类标记的偏好数据结合使用,以解决更难以量化的任务方面,例如整体连贯性。这种混合方法允许RBR强制执行特定指南,同时使人类标记的数据能够解决更难以量化的任务方面。
3. Reasoning Limitations of Multimodal Large Language Models. A case study of Bongard Problems
Authors: Miko{\l}aj Ma{\l}ki’nski, Szymon Pawlonka, Jacek Ma’ndziuk
https://arxiv.org/abs/2411.01173
多模态大型语言模型的推理限制:邦加德问题案例研究

摘要
本研究探讨了多模态大型语言模型(MLLMs)在解决邦加德问题(Bongard Problems, BPs)时的能力。邦加德问题是一种需要通过类比过程发现图像集合中共通概念的视觉推理任务,类似于人类智商测试。我们提出了一系列适用于MLLMs的策略来解决BPs,并检验了四个流行的专有MLLMs和四个开放模型在三个BP数据集上的表现:基于合成几何图像的原始BP实例,以及基于真实世界图像的两个最新数据集Bongard-HOI和Bongard-OpenWorld。实验揭示了MLLMs在解决BPs上的重大局限性,尤其是在解决经典合成BPs时的困难。尽管在Bongard-HOI和Bongard-OpenWorld上的表现有所改善,但模型在利用新信息改进预测以及有效利用对话上下文窗口方面仍存在困难。为了捕捉合成和真实世界AVR领域之间性能差异的原因,我们提出了Bongard-RWR,一个新的BP数据集,它将手工合成的BPs中的概念转化为真实世界的概念。MLLMs在Bongard-RWR上的结果表明,它们在经典BPs上的不佳表现并非由于领域特异性,而是反映了它们在一般AVR上的局限性。
研究背景
类比制作是人类认知的关键方面,与流体智力紧密相关,即在新环境中应用学到的技能的能力。为了构建能够进行类比的系统,提出了多种方法,特别是结构映射理论,探索了发现预先存在的对象表示之间的结构对应关系的方法。然而,这些方法常常忽略了感知方面,假设对象表示已经给出。Chalmers等人强调,形成有用的表示是一个复杂的挑战。感知不仅仅是感官数据的被动接收,而是一种受先验知识影响的主动解释。这个过程涉及模式的检测、类比的识别和概念的抽象。由此产生的表示可能因上下文而异,这强调了联合建模感知和认知的重要性。
问题与挑战
邦加德问题(BPs)是评估AI模型抽象推理能力的有价值的测试平台。然而,现有的深度学习方法在解决BPs和其他涉及抽象推理的问题方面仍然存在挑战。这些方法通常忽略了生成自然语言答案,将BPs简化为二元分类任务,或者在处理图像和文本时采用分离的两阶段方法。此外,尽管大型语言模型(LLMs)在开放语言生成方面显示出了希望,但它们在解决AVR问题时的能力仍有待验证。
如何解决
本研究提出了一种新的方法,即基于规则的奖励(RBR),用于MLLMs在解决BPs上的训练。我们定义了一系列策略,让模型接收关于Bongard问题的一般描述,并在特定策略下呈现给定任务BPs。我们还提出了一种基于模型的方法来自动评估模型预测的正确性,并考虑了简化问题的二元分类框架,以详细评估MLLMs的AVR能力。
核心创新点
- MLLMs在BPs上的首次应用:首次在文献中考虑BPs在MLLMs的背景下,并提出了多种策略来解决BP实例。
- 多样化的解决策略:提出了多种MLLMs适用的策略来解决BPs,包括开放性语言生成和二元分类。
- Bongard-RWR数据集的引入:为了比较MLLMs在合成BPs和真实世界BPs上的性能,引入了Bongard-RWR数据集,该数据集将合成BPs中的概念转化为真实世界图像。
- 详细的比较分析:对8个MLLMs在Bongard-RWR与合成BPs上的表现进行了详细比较分析,揭示了它们在一般AVR上的局限性。
算法模型
本研究中,我们提出了多种策略来解决BPs,包括直接(Direct)、描述性(Descriptive)、描述性迭代(Descriptive-iterative)、描述性直接(Descriptive-direct)、对比性(Contrastive)、对比性迭代(Contrastive-iterative)和对比性直接(Contrastive-direct)策略。这些策略涉及模型接收图像、生成文本描述、比较图像对以及在对话上下文窗口中进行迭代推理。
实验效果
实验结果表明,MLLMs在解决BPs上存在显著局限性。在所有提出的答案生成策略中,表现最好的模型仅能解决22个合成BPs中的100个问题。在处理真实世界概念时,模型的表现有所改善,但在利用额外的多模态数据和有效利用对话上下文窗口方面仍存在困难。Bongard-RWR数据集的引入揭示了MLLMs在合成BPs上的不佳表现并非领域特异性,而是反映了它们在一般AVR上的局限性。尽管如此,一些模型在二元分类设置中取得了令人鼓舞的结果,表明当前的局限性可能随着未来的进步而被克服。
相关工作
相关工作主要集中在使用人类反馈来对齐模型,例如在人类反馈的强化学习(RLHF)中的研究。此外,还有研究使用AI反馈来改善模型,这些方法通常涉及生成合成比较数据集,用于训练奖励模型。我们的工作与这些方法不同,我们直接在RL过程中纳入LLM反馈,而不是生成合成比较数据集。
后续优化方向
尽管MLLMs在明确指定模型行为政策的情况下表现出色,但在更主观的任务中,例如撰写高质量文章,定义明确规则可能不那么直接,需要非平凡的努力。未来的工作方向之一是探索这些更复杂的非安全领域。此外,MLLMs可以与人类标记的偏好数据结合使用,以解决更难以量化的任务方面,例如整体连贯性。这种混合方法允许MLLM强制执行特定指南,同时使人类标记的数据能够解决更难以量化的任务方面。
4. Ontology Population using LLMs
Authors: Sanaz Saki Norouzi, Adrita Barua, Antrea Christou, Nikita Gautam,
Andrew Eells, Pascal Hitzler, Cogan Shimizu
https://arxiv.org/abs/2411.01612
使用大型语言模型进行本体填充
摘要
知识图谱(KGs)在数据整合、表示和可视化方面越来越受到重视。尽管KG的构建至关重要,但从非结构化的自然语言文本中提取数据时,这一过程往往成本高昂,面临诸如歧义和复杂解释等挑战。大型语言模型(LLMs)在自然语言理解和内容生成方面展现出了卓越的能力。然而,它们也存在“幻觉”倾向,可能会产生不准确的输出。尽管存在这些限制,LLMs在处理自然语言数据方面速度快、可扩展性强,通过提示工程和微调,它们可以在提取和构建KG数据方面接近人类水平的表现。本研究调查了LLMs在KG填充中的有效性,重点关注Enslaved.org Hub本体。我们报告称,与真实情况相比,LLMs能够在提供模块化本体作为提示的指导下提取约90%的三元组。
研究背景
知识图谱(KGs)已成为创建、提取、整合、表示和可视化数据的重要范式,得到了W3C标准和建议的支持。然而,知识工程的许多方面成本高昂,从知识模型(即本体)开发到实际的KG填充(和验证)。当数据已经以机器可解析的格式存在时,填充似乎是最简单的部分。但是,当文本以自然语言形式存在时,这一过程变得复杂。鉴于解释意义、情感、框架或指代的复杂性,将这些内容转换为事实或知识可能非常困难。尽管有许多自然语言处理(NLP)技术可以解决这些问题,但在流行度和广泛适用性方面,LLMs处于前沿。LLMs在各种领域迅速崛起,展现出在自然语言理解和翻译等任务上的卓越能力。它们处理和解释大量文本数据的能力使它们能够生成连贯且与上下文相关的回应,通常在创造力和细微差别上超越传统模型。然而,LLMs容易出现一种称为虚构的现象,即模型产生看似连贯且与上下文相关但事实上不准确或完全编造的回应。尽管存在这些警告,LLMs在某些知识提取任务上比人类快得多,尤其是在处理大量数据时。通过适当的指导(例如,通过提示工程、检索增强生成或微调),LLMs可以在这些任务上接近人类水平的表现。
问题与挑战
LLMs在处理自然语言数据时面临的主要挑战包括:
- 数据提取的准确性:从非结构化的自然语言文本中提取数据时,如何确保准确性和一致性。
- 处理歧义和复杂性:自然语言的复杂性和歧义性使得将文本转换为事实或知识变得困难。
- 模型的“幻觉”倾向:LLMs可能会产生看似合理但事实上不准确的输出。
如何解决
本研究提出了一种新的方法,即使用基于规则的奖励(RBR),利用LLMs进行KG填充。该方法包括以下步骤:
- 数据预处理:收集、整理和策划相关自然语言文本,如维基百科文章,以便用于实验。
- 文本检索:使用文本摘要和检索增强生成(RAG)方法,从大量文本中提取相关信息。
- KG填充:根据提取的信息,使用LLMs填充本体模块。
核心创新点
- 模块化本体指导:使用模块化本体作为提示,指导LLMs提取和转换非结构化自然语言数据。
- 检索增强生成(RAG):结合检索系统和生成模型,提高结果的精确性。
- 基于规则的奖励(RBR):直接在RL训练中使用细粒度、可组合的LLM评分少量样本提示作为奖励,实现更大的控制力、准确性和易于更新。
算法模型
本研究中,我们提出了一种结合LLMs的文本摘要和RAG的方法,用于从自然语言数据中提取和构建KG数据。具体步骤包括:
- 文本摘要:使用LLMs生成与本体模块相关的文本摘要。
- RAG:结合检索系统和生成模型,提高结果的精确性。
- KG填充:根据提取的信息,使用LLMs填充本体模块。
实验效果
实验结果表明,与真实情况相比,LLMs能够在提供模块化本体作为提示的指导下提取约90%的三元组。具体数据如下:
- GPT-4 Enslaved MainAgent:平均匹配度82.30%,总覆盖率81.60%。
- GPT-4 Enslaved notrestrictedToMAgent:平均匹配度87.87%,总覆盖率86.82%。
- GPT-4 WB MainAgent:平均匹配度77.08%,总覆盖率76.10%。
- GPT-4 WB notrestrictedToMAgent:平均匹配度85.03%,总覆盖率84.12%。
这些结果表明,LLMs在提取和构建KG数据方面具有较高的准确性和覆盖率。
相关工作
相关工作主要集中在使用LLMs进行知识提取和本体构建。这些研究强调了LLMs在处理自然语言数据时的潜力,但也指出了它们在准确性和领域特定性方面的局限性。本研究通过使用模块化本体作为指导,提高了LLMs在KG填充任务中的性能。
后续优化方向
未来的工作将集中在以下几个方面:
- 提高准确性:进一步优化LLMs,以减少提取过程中的错误和遗漏。
- 扩展应用范围:将本方法应用于更广泛的领域和数据类型。
- 优化计算效率:改进算法,以提高处理大规模数据集时的计算效率。
5. EcoAct: Economic Agent Determines When to Register What Action
Authors: Shaokun Zhang, Jieyu Zhang, Dujian Ding, Mirian Hipolito Garcia, Ankur
Mallick, Daniel Madrigal, Menglin Xia, Victor R"uhle, Qingyun Wu, Chi Wang
https://arxiv.org/abs/2411.01643
EcoAct: 经济代理决定何时注册何种行动

摘要
近期的进步使得大型语言模型(LLMs)能够作为代理执行使用外部工具的行动。这要求进行注册,即将工具信息集成到LLMs的上下文中,以便在采取行动之前。当前的方法会不加选择地将所有候选工具集成到代理的上下文中,并在多个推理步骤中保留这些信息。这个过程对LLM代理是不透明的,并且没有集成到它们的推理过程中,导致由于无关工具增加了上下文长度而产生的效率低下。为了解决这个问题,我们引入了EcoAct,这是一个工具使用算法,允许LLMs根据需要选择性地注册工具,优化上下文使用。通过将工具注册过程集成到推理过程中,EcoAct在多步推理任务中减少了超过50%的计算成本,同时保持了性能,这一点通过广泛的实验得到了证明。此外,它只需要对提示进行微小的修改,就可以插入到任何推理流程中,使其适用于当前和未来的LLM代理。
研究背景
大型语言模型(LLMs)已被构想为能够执行广泛复杂任务的代理。当与外部工具结合时,LLM代理可以扩展其功能,超越传统的自然语言处理。例如,配备科学工具的LLM代理可以进行科学研究,而与物理机器人系统集成的代理则能够执行机器人操作。外部工具本质上扩展了LLM代理的行动空间,使它们能够利用现有功能完成各种复杂任务。为了使LLM代理具备外部工具,它们必须经历工具注册过程。具体来说,需要将候选工具的信息添加到支持代理的LLMs的上下文中。这些信息代表了工具使用的重要细节,包括工具名称、自然语言描述和输入参数的指令。当前的工具注册实践会不加选择地将所有候选工具集成到代理的上下文中,这些候选工具是由用户预先选择的,或者通过外部算法自动检索的。然后,基于LLM的代理将处理所有注册工具的上下文信息,并为每个推理步骤选择适当的工具。然而,这种提前准备所有工具并保持注册工具的全部信息在LLM的操作上下文中的范式引入了一个关键问题:工具注册过程对代理是不透明的,并且没有完全集成到它们的自主推理流程中。每次调用LLM时,都会处理所有被动注册工具的信息,即使并非所有工具都是必要的,每个步骤只能使用一个工具,这导致了成本和推理时间的低效。
问题与挑战
LLMs在工具使用方面面临的主要挑战包括:
- 工具注册的不透明性:工具注册过程对LLM代理是不透明的,没有集成到它们的自主推理流程中。
- 上下文长度的增加:由于无关工具的增加,导致LLM在每次调用时处理的上下文信息过多,增加了成本和推理时间。
- 效率低下:在多个推理步骤中保留所有候选工具的信息,导致效率低下。
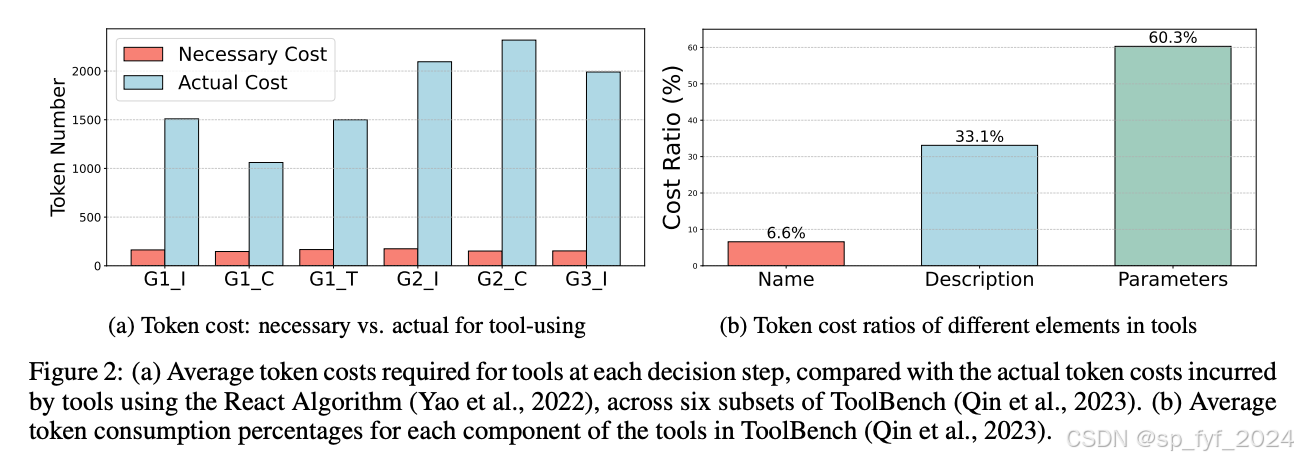
如何解决
为了解决这些问题,我们提出了EcoAct,这是一个工具使用算法,它允许LLMs根据需要选择性地注册工具,优化上下文使用。EcoAct通过以下方式解决挑战:
- 集成工具注册过程:将工具注册过程集成到LLM代理的推理过程中,使代理能够根据需要自主决定何时注册何种工具。
- 减少计算成本:通过优化上下文使用,EcoAct在多步推理任务中减少了超过50%的计算成本。
- 保持性能:尽管减少了计算成本,但EcoAct仍然保持了与原始方法相当的性能。
核心创新点
- 工具注册的自主决策:EcoAct允许LLMs根据需要自主决定何时注册何种工具,而不是被动地接受预先准备好的工具。
- 优化上下文使用:EcoAct通过选择性地注册工具,减少了无关工具对上下文长度的影响,从而优化了上下文使用。
- 计算成本的显著降低:EcoAct在多步推理任务中实现了超过50%的计算成本降低。
算法模型
EcoAct算法的核心思想是使代理能够自主地注册它们认为有用的工具,而不是被动地依赖预先分配的工具。EcoAct包括以下关键组件:
- 工具名称作为信息提供者:使用工具名称作为易于识别的标签,帮助代理确定哪些工具应该注册。
- tool register作为元工具:引入一个名为tool register的元工具,允许代理在每个时间步骤根据这些工具名称注册它们认为有用的工具。
- 推理过程中的工具注册:在每个推理步骤中,代理可以注册新工具或调用先前注册的工具,具体取决于任务需求。
实验效果
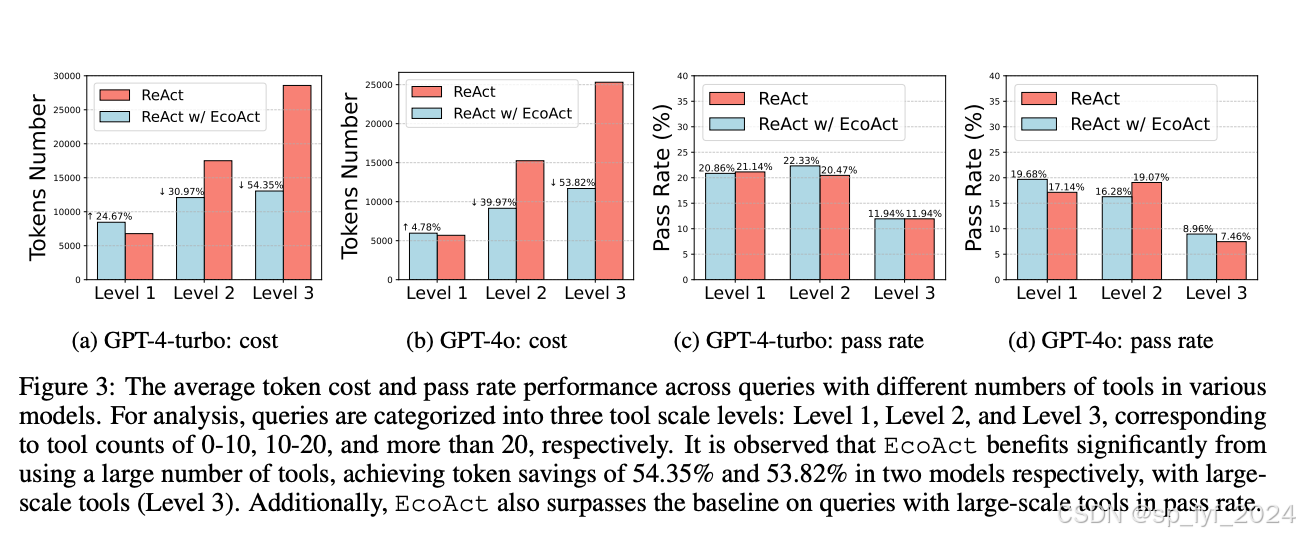
我们使用ToolBench基准数据集对EcoAct进行了广泛的实验,该数据集涉及多种大规模工具。实验结果表明,EcoAct能够显著降低计算成本,同时保持与原始方法相当的性能。具体数据如下:
- ReAct与ReAct+EcoAct的比较:在ToolBench基准数据集上,ReAct+EcoAct在保持与ReAct相当的性能的同时,显著降低了成本。
- 不同工具规模下的性能:EcoAct在处理涉及大规模工具的查询时,实现了显著的成本节省,达到了54.35%和53.82%的成本节省。
相关工作
相关工作主要集中在使用LLMs构建能够执行复杂任务的自主代理。这些代理能够利用外部功能、工具或行动与环境交互或解决子任务。为了使代理能够使用外部工具,它们必须经历工具注册过程,将相关工具信息集成到LLM的上下文中。当可用工具的数量超过上下文限制时,这一过程变得具有挑战性。为了缓解这一限制,研究者们探索了各种推理算法,如ReAct和DFSDT,但这些算法并没有与工具注册过程集成,可能导致由于注册无关工具而产生的不必要成本。
后续优化方向
未来的工作将集中在以下几个方面:
- 算法的进一步优化:继续优化EcoAct算法,以提高其在更复杂任务中的性能和效率。
- 扩展到更多推理方法:将EcoAct应用于更复杂的推理算法,如DFSDT,以实现更广泛的应用。
- 成本与性能的平衡:探索在保持性能的同时进一步降低计算成本的方法。
6. CycleResearcher: Improving Automated Research via Automated Review
Authors: Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang,
Yue Zhang, Linyi Yang
代码:http://github/minjun-zhu/Researcher
https://arxiv.org/abs/2411.00816
CYCLERESEARCHER: 通过自动化审查改进自动化研究
摘要
本文探讨了使用开源大型语言模型(LLMs)作为自主代理,执行从文献回顾和手稿准备到同行评审和论文修订的自动化研究和审查的全过程的可行性。研究者提出了一个迭代偏好训练框架,包括CycleResearcher(进行研究任务)和CycleReviewer(模拟同行评审过程),并通过强化学习提供迭代反馈。为了训练这些模型,研究者开发了两个新数据集,Review-5k和Research-14k,反映了现实世界中的机器学习研究和同行评审动态。结果显示,CycleReviewer在预测论文评分方面比单独的人类评审者平均绝对误差(MAE)提高了26.89%,表明LLMs可以在研究评估中超越专家级表现。在研究中,由CycleResearcher模型生成的论文在模拟同行评审中获得了5.36的评分,超过了人类专家预印本水平的5.24,接近接受论文水平的5.69。这项工作代表了向完全自动化科学探究迈出的重要一步,提供了伦理保障,并推进了AI驱动的研究能力。
研究背景
自动化科学发现一直是研究界的长期目标,其潜力在于加速知识创造。尽管使用商业大型语言模型(LLMs)作为研究助理或创意生成器已经取得了显著进展,但使用开源LLMs自动化整个研究过程的可能性尚未被充分探索。
问题与挑战
当前的AI驱动研究代理未能在关键领域如合理性、表达和贡献等方面持续达到必要的深度。此外,很少有研究解决迭代反馈的整合问题,这对于维护学术合理性和创新至关重要。现有的模型通常难以适应研究阶段的全谱,凸显了它们在进行全面、多步骤科学发现方面的能力差距。
如何解决
研究者提出了一个新颖的框架,后训练LLMs作为自主代理,模拟科学发现过程的完整循环。该方法完全基于开源模型,旨在复制现实世界中研究发展和同行评审过程的动态。通过利用可训练模型,研究者启用了迭代偏好训练机制,使用强化学习中的采样示例。
核心创新点
- 提出了一个迭代强化学习框架,自动化整个研究生命周期,反映了现实世界的研究-反驳-修订循环。
- 发布了两个大规模数据集,Review-5k和Research-14k,旨在捕捉机器学习中同行评审和研究论文生成的复杂性。
- 证明了CycleResearcher模型能够生成接近人类撰写预印本平均质量水平的论文,并且CycleReviewer模型在研究评估任务中超过了人类评审者。
算法模型
研究者构建了一个新颖的迭代训练框架,包含两个核心组件:策略模型(CycleResearcher)和奖励模型(CycleReviewer)。CycleResearcher执行多种研究任务,从生成假设和设计实验到进行文献回顾和准备手稿。CycleReviewer模拟同行评审过程,评估研究产出的质量并提供反馈,以指导强化学习奖励。
实验效果
- CycleReviewer在预测论文评分方面比单独的人类评审者平均绝对误差(MAE)提高了26.89%。
- CycleResearcher模型生成的论文在模拟同行评审中获得了5.36的评分,超过了人类专家预印本水平的5.24,接近接受论文水平的5.69。
- 通过拒绝采样,随着生成论文数量的增加,平均评分从5.36提高到7.02,超过了预印本论文(5.24)和接受论文(5.69)。
相关工作
- LLMs for Research:近年来,一些研究探索了使用语言模型进行研究中的创意任务,如多代理协作写作和多模块检索,以提高AI在创意任务中的新颖性和多样性。
- LLMs for Science Discovery:AI辅助科学发现有着悠久的历史。随着神经网络的发展,更多研究者关注AI在科学中的作用,主要是在单一领域内进行数据分析,扮演被动角色,没有推动科学发现。
- Automated Evaluation of Research Papers:AI工具在科学出版过程中的使用引起了广泛关注,包括研究论文内容的总结、检测不准确性和识别公平性差异。
后续优化方向
- 扩大分析范围:研究者的工作限于具有稀疏奖励的复杂任务。未来的工作可以扩展到其他类型的任务(如具有密集奖励的任务)、环境(如真实世界环境)和代理。
- 开发先进的方法:研究者发现的关于黑客攻击的问题强调了需要更先进的方法来利用VLMs在RL中的能力。虽然目前缓解黑客攻击仍然具有挑战性,但未来的研究方向可以探索更先进的训练算法,更好地利用VLMs而不会成为黑客攻击的受害者。
后记
如果觉得我的博客对您有用,欢迎 打赏 支持!三连击 (点赞、收藏、关注和评论) 不迷路,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。