一、EM算法的提出
当你有一组数据像如下这样:
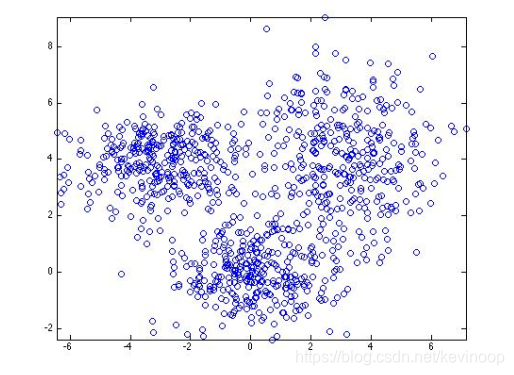
显然用单个高斯分布模型去拟合它们效果不好,这是一个典型的高斯混合模型的例子:
p
(
X
)
=
∑
l
=
1
k
α
l
N
(
X
∣
μ
l
,
Σ
l
)
∑
l
=
1
k
α
l
=
1
p(X)=\sum_{l=1}^k \alpha_lN (X|\mu_l,\Sigma_l) \quad\sum_{l=1}^{k} \alpha_l=1
p(X)=l=1∑kαlN(X∣μl,Σl)l=1∑kαl=1
(
其
中
α
l
可
以
理
解
为
每
一
个
高
斯
分
布
的
权
重
)
(其中 \alpha_l 可以理解为每一个高斯分布的权重)
(其中αl可以理解为每一个高斯分布的权重)
令
Θ
=
{
α
1
,
…
,
α
k
,
μ
1
,
…
,
μ
k
,
Σ
1
,
…
,
Σ
k
}
\Theta=\{\alpha_1,\ldots,\alpha_k,\mu_1,\ldots,\mu_k,\Sigma_1,\ldots,\Sigma_k\}
Θ={α1,…,αk,μ1,…,μk,Σ1,…,Σk},则有:
Θ M L E = arg max Θ L ( Θ ∣ X ) = arg max Θ ( ∑ i = 1 n l o g ∑ l = 1 k α l N ( X ∣ μ l , Σ l ) ) \Theta_{MLE}=\mathop{\arg\max}_{\Theta}L(\Theta|X)\\ =\mathop{\arg\max}_{\Theta} \left ( \sum_{i=1}^{n}log \sum_{l=1}^{k} \alpha_lN(X|\mu_l,\Sigma_l) \right ) ΘMLE=argmaxΘL(Θ∣X)=argmaxΘ(i=1∑nlogl=1∑kαlN(X∣μl,Σl))
该式子包含和(或积分)的对数,不能像单个高斯模型那样直接求导,再令导数为0来求解。这时我们需要利用 EM 算法通过迭代逐步近似极大化 L ( Θ ∣ X ) L(\Theta|X) L(Θ∣X) 来求解。
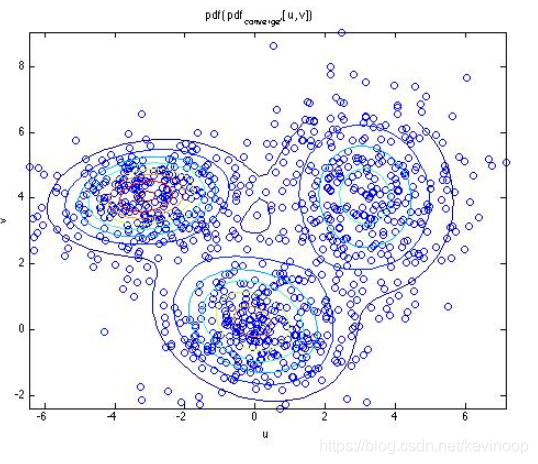
二、EM算法的导出
先提出 Jensen 不等式:
对于凸函数(convex),有:
f
(
t
⋅
x
1
+
(
1
−
t
)
⋅
x
2
)
≤
t
⋅
f
(
x
1
)
+
(
1
−
t
)
⋅
f
(
x
2
)
f(t \cdot x_1+(1-t)\cdot x_2) \leq t\cdot f(x_1)+(1-t)\cdot f(x_2)
f(t⋅x1+(1−t)⋅x2)≤t⋅f(x1)+(1−t)⋅f(x2)扩展到高维,令
∑
i
=
1
k
p
i
=
1
p
i
≥
0
\sum_{i=1}^{k} p_i=1 \quad p_i \geq0
∑i=1kpi=1pi≥0:
f
(
p
1
⋅
x
1
+
…
+
p
k
⋅
x
k
)
≤
p
1
⋅
f
(
x
1
)
+
…
+
p
k
⋅
f
(
x
k
)
f(p_1 \cdot x_1+\ldots +p_k\cdot x_k) \leq p_1\cdot f(x_1)+\ldots +p_k\cdot f(x_k)
f(p1⋅x1+…+pk⋅xk)≤p1⋅f(x1)+…+pk⋅f(xk)
f
(
∑
i
=
1
k
p
i
⋅
x
i
)
≤
∑
i
=
1
k
p
i
⋅
f
(
x
i
)
f(\sum_{i=1}^{k} p_i\cdot x_i)\leq \sum_{i=1}^{k} p_i\cdot f(x_i)
f(i=1∑kpi⋅xi)≤i=1∑kpi⋅f(xi)用
ϕ
\phi
ϕ 代替
f
f
f ,
f
(
x
)
f(x)
f(x) 代替
x
x
x, 我们有
ϕ
(
∑
i
=
1
k
p
i
⋅
f
(
x
i
)
)
≤
∑
i
=
1
k
p
i
⋅
ϕ
(
f
(
x
i
)
)
\phi(\sum_{i=1}^{k} p_i\cdot f(x_i))\leq \sum_{i=1}^{k} p_i\cdot \phi (f(x_i))
ϕ(i=1∑kpi⋅f(xi))≤i=1∑kpi⋅ϕ(f(xi))
故对于凸函数(convex),有下面这条结论:
ϕ ( E [ f ( x ) ] ) ≤ E [ ϕ ( f ( x ) ) ] \phi(E[f(x)])\leq E[\phi(f(x))] ϕ(E[f(x)])≤E[ϕ(f(x))] 同理,对于凹函数(concave),有相反的结论:
ϕ ( E [ f ( x ) ] ) ≥ E [ ϕ ( f ( x ) ) ] \phi(E[f(x)])\geq E[\phi(f(x))] ϕ(E[f(x)])≥E[ϕ(f(x))]
我们通过引入隐变量 Z 来极大化观测数据 X 关于参数
θ
\theta
θ 的对数似然函数:
L
(
θ
)
=
l
n
P
(
X
∣
θ
)
=
l
n
(
P
(
X
,
Z
∣
θ
)
P
(
Z
∣
X
,
θ
)
)
=
l
n
(
P
(
X
,
Z
∣
θ
)
Q
(
Z
)
⋅
Q
(
Z
)
P
(
Z
∣
X
,
θ
)
)
=
l
n
(
P
(
X
,
Z
∣
θ
)
Q
(
Z
)
)
+
l
n
(
Q
(
Z
)
P
(
Z
∣
X
,
θ
)
)
L(\theta)=ln\ P(X|\theta)=ln\left ( \frac{P(X,Z|\theta )}{P(Z|X,\theta )}\right )\\ =ln\left ( \frac{P(X,Z|\theta )}{Q(Z)} \cdot \frac{Q(Z)}{P(Z|X,\theta )}\right )\\ =ln\left ( \frac{P(X,Z|\theta )}{Q(Z)} \right ) +ln\left ( \frac{Q(Z)}{P(Z|X,\theta )} \right )
L(θ)=ln P(X∣θ)=ln(P(Z∣X,θ)P(X,Z∣θ))=ln(Q(Z)P(X,Z∣θ)⋅P(Z∣X,θ)Q(Z))=ln(Q(Z)P(X,Z∣θ))+ln(P(Z∣X,θ)Q(Z))
故:
l
n
P
(
X
∣
θ
)
=
∫
Z
l
n
(
P
(
X
,
Z
∣
θ
)
Q
(
Z
)
)
Q
(
Z
)
+
∫
Z
l
n
(
Q
(
Z
)
P
(
Z
∣
X
,
θ
)
)
Q
(
Z
)
=
r
(
X
∣
θ
)
+
K
L
(
Q
(
Z
)
∣
∣
P
(
Z
∣
X
,
θ
)
)
ln\ P(X|\theta) =\int_{Z}ln\left ( \frac{P(X,Z|\theta )}{Q(Z)} \right )Q(Z) + \int_{Z} ln\left ( \frac{Q(Z)}{P(Z|X,\theta )} \right )Q(Z)\\ =r(X|\theta)+KL(Q(Z)||P(Z|X,\theta ))
ln P(X∣θ)=∫Zln(Q(Z)P(X,Z∣θ))Q(Z)+∫Zln(P(Z∣X,θ)Q(Z))Q(Z)=r(X∣θ)+KL(Q(Z)∣∣P(Z∣X,θ))
其中,
K
L
(
⋅
)
≥
0
KL(\cdot)\geq 0
KL(⋅)≥0,则
l
n
P
(
X
∣
θ
)
≥
r
(
X
∣
θ
)
ln\ P(X|\theta)\geq r(X|\theta)
ln P(X∣θ)≥r(X∣θ),也可利用上面的 Jensen 不等式证明:
l
n
P
(
X
∣
θ
)
=
l
n
∫
Z
P
(
X
,
Z
∣
θ
)
=
l
n
∫
Z
P
(
X
,
Z
∣
θ
)
Q
(
Z
)
⋅
Q
(
Z
)
=
l
n
E
Q
(
Z
)
[
f
(
Z
)
]
≥
E
Q
(
Z
)
l
n
[
f
(
Z
)
]
=
∫
Z
l
n
(
P
(
X
,
Z
∣
θ
)
Q
(
Z
)
)
⋅
Q
(
Z
)
ln\ P(X|\theta)=ln \int_ZP(X,Z|\theta)\\ =ln \int_Z \frac{P(X,Z|\theta)}{Q(Z)}\cdot Q(Z)=lnE_{Q(Z)}[f(Z)]\\ \geq E_{Q(Z)}ln[f(Z)]= \int_Z ln \left(\frac{P(X,Z|\theta)}{Q(Z)} \right)\cdot Q(Z)
ln P(X∣θ)=ln∫ZP(X,Z∣θ)=ln∫ZQ(Z)P(X,Z∣θ)⋅Q(Z)=lnEQ(Z)[f(Z)]≥EQ(Z)ln[f(Z)]=∫Zln(Q(Z)P(X,Z∣θ))⋅Q(Z)
又当
Q
(
Z
)
=
P
(
Z
∣
X
,
Θ
(
g
)
)
Q(Z)=P(Z|X,\Theta^{(g)} )
Q(Z)=P(Z∣X,Θ(g)) 时 ,有
K
L
(
⋅
)
=
0
KL(\cdot)=0
KL(⋅)=0,此时有:
l
n
P
(
X
∣
Θ
(
g
)
)
=
r
(
X
∣
Θ
(
g
)
)
ln\ P(X|\Theta^{(g)}) = r(X|\Theta^{(g)})
ln P(X∣Θ(g))=r(X∣Θ(g))
由上
r
(
X
∣
Θ
)
r(X|\Theta)
r(X∣Θ) 是
L
(
Θ
)
L(\Theta)
L(Θ) 的一个下界函数,我们通过不断求解下界函数的极大化来逼近求解对数似然函数的极大化:
Θ ( g + 1 ) = arg max Θ ∫ Z l n ( P ( X , Z ∣ Θ ) P ( Z ∣ X , Θ ( g ) ) ) P ( Z ∣ X , Θ ( g ) ) = arg max Θ ∫ Z l n ( P ( X , Z ∣ Θ ) ) P ( Z ∣ X , Θ ( g ) ) d z \Theta^{(g+1)}=\mathop{\arg\max}_{\Theta} \int_{Z}ln\left ( \frac{P(X,Z|\Theta )}{P(Z|X,\Theta^{(g)})} \right )P(Z|X,\Theta^{(g)})\\ =\mathop{\arg\max}_{\Theta} \int_{Z}ln\left ( P(X,Z|\Theta ) \right )P(Z|X,\Theta^{(g)})\ dz Θ(g+1)=argmaxΘ∫Zln(P(Z∣X,Θ(g))P(X,Z∣Θ))P(Z∣X,Θ(g))=argmaxΘ∫Zln(P(X,Z∣Θ))P(Z∣X,Θ(g)) dz
EM算法每次迭代包含两步:E步,求期望;M步,求极大化。令 :
Q
(
Θ
,
Θ
(
g
)
)
=
∫
Z
l
n
(
P
(
X
,
Z
∣
Θ
)
)
P
(
Z
∣
X
,
Θ
(
g
)
)
d
z
Q(\Theta,\Theta^{(g)})= \int_{Z}ln\left ( P(X,Z|\Theta ) \right )P(Z|X,\Theta^{(g)})\ dz
Q(Θ,Θ(g))=∫Zln(P(X,Z∣Θ))P(Z∣X,Θ(g)) dz
EM算法如下:
EM算法:
输入:观测变量数据X,隐变量数据Z,联合分布 P ( X , Z ∣ Θ ) P(X,Z|\Theta) P(X,Z∣Θ) ,条件分布 P ( Z ∣ X , Θ ) P(Z|X,\Theta) P(Z∣X,Θ)
输出:模型参数 Θ \Theta Θ
(1) 选择初始参数 Θ ( 0 ) \Theta^{(0)} Θ(0);
(2) E步,记 Θ ( i ) \Theta^{(i)} Θ(i) 为第 i 次迭代参数 Θ \Theta Θ 的估计值,在第 i+1 次迭代的E步, 计算 Q ( Θ , Θ ( g ) ) Q(\Theta,\Theta^{(g)}) Q(Θ,Θ(g));
(3) M步,确定第 i+1 次迭代的参数的估计值 Θ ( i + 1 ) \Theta^{(i+1)} Θ(i+1),即:
Θ ( i + 1 ) = arg max Θ Q ( Θ , Θ ( g ) ) \Theta^{(i+1)}=\mathop{\arg\max}_{\Theta}\ Q(\Theta,\Theta^{(g)}) Θ(i+1)=argmaxΘ Q(Θ,Θ(g))
(4) 重复(2)步和(3)步,直到收敛。
下图给出 EM 算法的直观解释:

由图,两个函数在 θ = θ ( g ) \theta=\theta^{(g)} θ=θ(g) 处相等,由EM算法 (3) 步,我们得到下一个点 θ ( g + 1 ) \theta^{(g+1)} θ(g+1) 使下界函数极大化。下界函数的增加保证对数似然函数在每次迭代中也是增加的。EM算法在点 θ ( g + 1 ) \theta^{(g+1)} θ(g+1) 处重新计算 Q ( Θ , Θ ( g + 1 ) ) Q(\Theta,\Theta^{(g+1)}) Q(Θ,Θ(g+1)), 进行下一次迭代。迭代过程中,对数似然函数不断增大,但从图可以看出EM算法不能保证找到全局最优值。
三、EM算法的收敛性
由
P
(
X
∣
θ
)
=
P
(
X
,
Z
∣
θ
)
P
(
Z
∣
X
,
θ
)
P(X|\theta)=\frac{P(X,Z|\theta)}{P(Z|X,\theta)}
P(X∣θ)=P(Z∣X,θ)P(X,Z∣θ)取对数有:
l
o
g
P
(
X
∣
θ
)
=
l
o
g
P
(
X
,
Z
∣
θ
)
−
l
o
g
P
(
Z
∣
X
,
θ
)
logP(X|\theta)=logP(X,Z|\theta)-logP(Z|X,\theta)
logP(X∣θ)=logP(X,Z∣θ)−logP(Z∣X,θ)
记,
Q
(
θ
,
θ
(
g
)
)
=
∫
Z
l
o
g
(
P
(
X
,
Z
∣
θ
)
)
P
(
Z
∣
X
,
θ
(
g
)
)
d
z
Q(\theta,\theta^{(g)})=\int_{Z}log \left ( P(X,Z|\theta ) \right )P(Z|X,\theta^{(g)})\ dz
Q(θ,θ(g))=∫Zlog(P(X,Z∣θ))P(Z∣X,θ(g)) dz
H
(
θ
,
θ
(
g
)
)
=
∫
Z
l
o
g
(
P
(
Z
∣
X
,
θ
)
)
P
(
Z
∣
X
,
θ
(
g
)
)
d
z
H(\theta,\theta^{(g)})=\int_{Z}log \left ( P(Z|X,\theta ) \right )P(Z|X,\theta^{(g)})\ dz
H(θ,θ(g))=∫Zlog(P(Z∣X,θ))P(Z∣X,θ(g)) dz
于是对数似然函数可以写成:
l
o
g
P
(
X
∣
θ
)
=
Q
(
θ
,
θ
(
g
)
)
−
H
(
θ
,
θ
(
g
)
)
logP(X|\theta)=Q(\theta,\theta^{(g)})-H(\theta,\theta^{(g)})
logP(X∣θ)=Q(θ,θ(g))−H(θ,θ(g))
故有如下等式:
l
o
g
P
(
X
∣
θ
(
g
+
1
)
)
−
l
o
g
P
(
X
∣
θ
(
g
)
)
=
[
Q
(
θ
(
g
+
1
)
,
θ
(
g
)
)
−
Q
(
θ
(
g
)
,
θ
(
g
)
)
]
−
[
H
(
θ
(
g
+
1
)
,
θ
(
g
)
)
−
H
(
θ
(
g
)
,
θ
(
g
)
)
]
logP(X|\theta^{(g+1)})-logP(X|\theta^{(g)})=[Q(\theta^{(g+1)},\theta^{(g)})-Q(\theta^{(g)},\theta^{(g)})]-[H(\theta^{(g+1)},\theta^{(g)})-H(\theta^{(g)},\theta^{(g)})]
logP(X∣θ(g+1))−logP(X∣θ(g))=[Q(θ(g+1),θ(g))−Q(θ(g),θ(g))]−[H(θ(g+1),θ(g))−H(θ(g),θ(g))]
显然,右端第一项,由于
θ
(
g
+
1
)
\theta^{(g+1)}
θ(g+1) 使
Q
(
θ
,
θ
(
g
)
)
Q(\theta,\theta^{(g)})
Q(θ,θ(g))达到极大,所以有:
Q
(
θ
(
g
+
1
)
,
θ
(
g
)
)
−
Q
(
θ
(
g
)
,
θ
(
g
)
)
≥
0
Q(\theta^{(g+1)},\theta^{(g)})-Q(\theta^{(g)},\theta^{(g)})\geq0
Q(θ(g+1),θ(g))−Q(θ(g),θ(g))≥0其第二项,有:
H
(
θ
(
g
+
1
)
,
θ
(
g
)
)
−
H
(
θ
(
g
)
,
θ
(
g
)
)
=
∫
Z
l
n
(
P
(
Z
∣
X
,
θ
(
g
+
1
)
)
P
(
Z
∣
X
,
θ
(
g
)
)
)
P
(
Z
∣
X
,
θ
(
g
)
)
≤
l
n
∫
Z
(
P
(
Z
∣
X
,
θ
(
g
+
1
)
)
P
(
Z
∣
X
,
θ
(
g
)
)
P
(
Z
∣
X
,
θ
(
g
)
)
)
=
l
n
(
∫
Z
P
(
Z
∣
X
,
θ
(
g
+
1
)
)
)
=
0
H(\theta^{(g+1)},\theta^{(g)})-H(\theta^{(g)},\theta^{(g)})\\ =\int_{Z}ln\left ( \frac{P(Z|X,\theta^{(g+1)} )}{P(Z|X,\theta^{(g)})} \right )P(Z|X,\theta^{(g)})\\ \leq ln\int_{Z}\left ( \frac{P(Z|X,\theta^{(g+1)} )}{P(Z|X,\theta^{(g)})} P(Z|X,\theta^{(g)})\right )\\ =ln(\int_Z P(Z|X,\theta^{(g+1)}))=0
H(θ(g+1),θ(g))−H(θ(g),θ(g))=∫Zln(P(Z∣X,θ(g))P(Z∣X,θ(g+1)))P(Z∣X,θ(g))≤ln∫Z(P(Z∣X,θ(g))P(Z∣X,θ(g+1))P(Z∣X,θ(g)))=ln(∫ZP(Z∣X,θ(g+1)))=0综上,有:
l
o
g
P
(
X
∣
θ
(
g
+
1
)
)
≥
l
o
g
P
(
X
∣
θ
(
g
)
)
logP(X|\theta^{(g+1)})\geq logP(X|\theta^{(g)})
logP(X∣θ(g+1))≥logP(X∣θ(g))
四、EM算法在GMM中的应用
在本文的第一部分已经提出高斯混合模型:
p
(
X
)
=
∑
l
=
1
k
α
l
N
(
X
∣
μ
l
,
Σ
l
)
∑
l
=
1
k
α
l
=
1
p(X)=\sum_{l=1}^k \alpha_lN (X|\mu_l,\Sigma_l) \quad\sum_{l=1}^{k} \alpha_l=1
p(X)=l=1∑kαlN(X∣μl,Σl)l=1∑kαl=1令
Θ
=
{
α
1
,
…
,
α
k
,
μ
1
,
…
,
μ
k
,
Σ
1
,
…
,
Σ
k
}
\Theta=\{\alpha_1,\ldots,\alpha_k,\mu_1,\ldots,\mu_k,\Sigma_1,\ldots,\Sigma_k\}
Θ={α1,…,αk,μ1,…,μk,Σ1,…,Σk}
在本文的第三部分我们已经推导出EM算法:
Θ
(
g
+
1
)
=
arg
max
Θ
∫
Z
l
n
(
P
(
X
,
Z
∣
Θ
)
)
P
(
Z
∣
X
,
Θ
(
g
)
)
d
z
\Theta^{(g+1)}=\mathop{\arg\max}_{\Theta} \int_{Z}ln\left ( P(X,Z|\Theta ) \right )P(Z|X,\Theta^{(g)})\ dz
Θ(g+1)=argmaxΘ∫Zln(P(X,Z∣Θ))P(Z∣X,Θ(g)) dz
E step:
我们需要定义这两项
l
n
P
(
X
,
Z
∣
Θ
)
lnP(X,Z|\Theta )
lnP(X,Z∣Θ) 和 $ P(Z|X,\Theta)$;
P
(
X
∣
Θ
)
=
∑
l
=
1
k
α
l
N
(
X
∣
μ
l
,
Σ
l
)
=
∏
i
=
1
n
∑
l
=
1
k
α
l
N
(
x
i
∣
μ
l
,
Σ
l
)
P(X|\Theta )=\sum_{l=1}^k \alpha_lN (X|\mu_l,\Sigma_l) =\prod_{i=1}^n \sum_{l=1}^k \alpha_l N (x_i|\mu_l,\Sigma_l)
P(X∣Θ)=l=1∑kαlN(X∣μl,Σl)=i=1∏nl=1∑kαlN(xi∣μl,Σl)
由上式,我们可以定义:
P
(
X
,
Z
∣
Θ
)
=
∏
i
=
1
n
p
(
x
i
,
z
i
∣
Θ
)
=
∏
i
=
1
n
p
(
x
i
∣
z
i
,
Θ
)
p
(
z
i
∣
Θ
)
=
∏
i
=
1
n
α
z
i
N
(
μ
z
i
,
Σ
z
i
)
P(X,Z|\Theta )=\prod_{i=1}^n p(x_i,z_i|\Theta)\\ =\prod_{i=1}^n p(x_i|z_i,\Theta) p(z_i|\Theta)=\prod_{i=1}^n \alpha_{z_i}N (\mu_{z_i},\Sigma_{z_i})
P(X,Z∣Θ)=i=1∏np(xi,zi∣Θ)=i=1∏np(xi∣zi,Θ)p(zi∣Θ)=i=1∏nαziN(μzi,Σzi)
由贝叶斯公式,我们有:
P
(
Z
∣
X
,
Θ
)
=
∏
i
=
1
n
p
(
z
i
∣
x
i
,
Θ
)
=
∏
i
=
1
n
α
z
i
N
(
μ
z
i
,
Σ
z
i
)
∑
l
=
1
k
α
l
N
(
μ
l
,
Σ
l
)
P(Z|X,\Theta)=\prod_{i=1}^np(z_i|x_i,\Theta)= \prod_{i=1}^n \frac{\alpha_{z_i}N (\mu_{z_i},\Sigma_{z_i})}{ \sum_{l=1}^k \alpha_{l}N (\mu_{l},\Sigma_{l})}
P(Z∣X,Θ)=i=1∏np(zi∣xi,Θ)=i=1∏n∑l=1kαlN(μl,Σl)αziN(μzi,Σzi)
结合两式,得到:
Q
(
Θ
,
Θ
(
g
)
)
=
∫
Z
l
n
(
P
(
X
,
Z
∣
Θ
)
)
P
(
Z
∣
X
,
Θ
(
g
)
)
d
z
=
∫
z
1
…
∫
z
k
(
∑
i
=
1
n
[
l
n
α
z
i
+
l
n
N
(
μ
z
i
,
Σ
z
i
)
]
)
⋅
∏
i
=
1
n
p
(
z
i
∣
x
i
,
Θ
(
g
)
)
d
z
1
…
d
z
k
Q(\Theta,\Theta^{(g)})=\int_{Z}ln\left ( P(X,Z|\Theta ) \right )P(Z|X,\Theta^{(g)})\ dz\\ =\int_{z_1}\ldots \int_{z_k}\left ( \sum_{i=1}^{n}[ln\alpha _{z_i}+lnN (\mu_{z_i},\Sigma_{z_i})] \right )\cdot \prod_{i=1}^{n}p(z_i|x_i,\Theta^{(g)})\ d{z_1}\ldots d{z_k}
Q(Θ,Θ(g))=∫Zln(P(X,Z∣Θ))P(Z∣X,Θ(g)) dz=∫z1…∫zk(i=1∑n[lnαzi+lnN(μzi,Σzi)])⋅i=1∏np(zi∣xi,Θ(g)) dz1…dzk
令:
f
(
z
i
)
=
l
n
α
z
i
+
l
n
N
(
μ
z
i
,
Σ
z
i
)
f(z_i)=ln\alpha _{z_i}+lnN (\mu_{z_i},\Sigma_{z_i})
f(zi)=lnαzi+lnN(μzi,Σzi)
p
(
z
1
,
…
,
z
k
)
=
∏
i
=
1
n
p
(
z
i
∣
x
i
,
Θ
(
g
)
)
p(z_1,\ldots,z_k)=\prod_{i=1}^{n}p(z_i|x_i,\Theta^{(g)})
p(z1,…,zk)=i=1∏np(zi∣xi,Θ(g)) 又可以写成如下形式:
Q
(
Θ
,
Θ
(
g
)
)
=
∫
z
1
…
∫
z
k
(
∑
i
=
1
n
f
(
z
i
)
)
⋅
p
(
z
1
,
…
,
z
k
)
d
z
1
…
d
z
k
Q(\Theta,\Theta^{(g)})=\int_{z_1}\ldots \int_{z_k}\left ( \sum_{i=1}^{n}f(z_i) \right )\cdot p(z_1,\ldots,z_k)\ d{z_1}\ldots d{z_k}
Q(Θ,Θ(g))=∫z1…∫zk(i=1∑nf(zi))⋅p(z1,…,zk) dz1…dzk看上式的第一项,可以作如下化简:
∫
z
1
…
∫
z
k
(
f
(
z
1
)
)
⋅
p
(
z
1
,
…
,
z
k
)
d
z
1
…
d
z
k
=
∫
z
1
f
(
z
1
)
∫
z
2
…
∫
z
k
⋅
p
(
z
1
,
…
,
z
k
)
d
z
1
…
d
z
k
=
∫
z
1
f
(
z
1
)
⋅
p
(
z
1
)
d
z
1
\int_{z_1}\ldots \int_{z_k}\left ( f(z_1) \right )\cdot p(z_1,\ldots,z_k)\ d{z_1}\ldots d{z_k}\\ =\int_{z_1} f(z_1) \int_{z_2} \ldots \int_{z_k}\cdot p(z_1,\ldots,z_k)\ d{z_1}\ldots d{z_k}\\ =\int_{z_1} f(z_1)\cdot p(z_1)d{z_1}
∫z1…∫zk(f(z1))⋅p(z1,…,zk) dz1…dzk=∫z1f(z1)∫z2…∫zk⋅p(z1,…,zk) dz1…dzk=∫z1f(z1)⋅p(z1)dz1
每一项都作类似的化简,我们得到:
Q
(
Θ
,
Θ
(
g
)
)
=
∑
i
=
1
n
∫
z
i
f
(
z
i
)
⋅
p
(
z
i
)
d
z
i
=
∑
i
=
1
n
∫
z
i
(
l
n
α
z
i
+
l
n
N
(
x
i
∣
μ
z
i
,
Σ
z
i
)
)
⋅
p
(
z
i
∣
x
i
,
Θ
(
g
)
)
d
z
i
=
∑
z
i
=
1
k
∑
i
=
1
n
(
l
n
α
z
i
+
l
n
N
(
x
i
∣
μ
z
i
,
Σ
z
i
)
⋅
p
(
z
i
∣
x
i
,
Θ
(
g
)
)
=
∑
l
=
1
k
∑
i
=
1
n
(
l
n
α
l
+
l
n
N
(
x
i
∣
μ
l
,
Σ
l
)
⋅
p
(
l
∣
x
i
,
Θ
(
g
)
)
Q(\Theta,\Theta^{(g)})=\sum_{i=1}^{n}\int_{z_i} f(z_i)\cdot p(z_i)d{z_i}\\ =\sum_{i=1}^{n}\int_{z_i} \left( ln\alpha _{z_i}+lnN (x_i|\mu_{z_i},\Sigma_{z_i}) \right ) \cdot p(z_i|x_i,\Theta^{(g)})d{z_i}\\ =\sum_{z_i=1}^{k} \sum_{i=1}^{n} \left( ln\alpha _{z_i}+lnN (x_i|\mu_{z_i},\Sigma_{z_i}\right ) \cdot p(z_i|x_i,\Theta^{(g)})\\ =\sum_{l=1}^{k} \sum_{i=1}^{n} \left( ln\alpha _{l}+lnN (x_i|\mu_{l},\Sigma_{l}\right ) \cdot p(l|x_i,\Theta^{(g)})
Q(Θ,Θ(g))=i=1∑n∫zif(zi)⋅p(zi)dzi=i=1∑n∫zi(lnαzi+lnN(xi∣μzi,Σzi))⋅p(zi∣xi,Θ(g))dzi=zi=1∑ki=1∑n(lnαzi+lnN(xi∣μzi,Σzi)⋅p(zi∣xi,Θ(g))=l=1∑ki=1∑n(lnαl+lnN(xi∣μl,Σl)⋅p(l∣xi,Θ(g))
M step:
Q
(
Θ
,
Θ
(
g
)
)
=
∑
l
=
1
k
∑
i
=
1
n
(
l
n
α
l
+
l
n
N
(
x
i
∣
μ
l
,
Σ
l
)
)
⋅
p
(
l
∣
x
i
,
Θ
(
g
)
)
=
∑
l
=
1
k
∑
i
=
1
n
l
n
α
l
⋅
p
(
l
∣
x
i
,
Θ
(
g
)
)
+
∑
l
=
1
k
∑
i
=
1
n
l
n
[
N
(
x
i
∣
μ
l
,
Σ
l
)
]
⋅
p
(
l
∣
x
i
,
Θ
(
g
)
)
Q(\Theta,\Theta^{(g)})=\sum_{l=1}^{k} \sum_{i=1}^{n} \left( ln\alpha _{l}+lnN (x_i|\mu_{l},\Sigma_{l})\right ) \cdot p(l|x_i,\Theta^{(g)})\\ =\sum_{l=1}^{k} \sum_{i=1}^{n} ln\alpha _{l}\cdot p(l|x_i,\Theta^{(g)})\\ \quad +\sum_{l=1}^{k} \sum_{i=1}^{n}ln[N (x_i|\mu_{l},\Sigma_{l})] \cdot p(l|x_i,\Theta^{(g)})
Q(Θ,Θ(g))=l=1∑ki=1∑n(lnαl+lnN(xi∣μl,Σl))⋅p(l∣xi,Θ(g))=l=1∑ki=1∑nlnαl⋅p(l∣xi,Θ(g))+l=1∑ki=1∑nln[N(xi∣μl,Σl)]⋅p(l∣xi,Θ(g))
容易看出第一项只含参数
α
\alpha
α,第二项只含参数
μ
,
Σ
\mu,\Sigma
μ,Σ,因此我们可以独立地进行最大化两项。
(1)最大化
α
\alpha
α
∂
∑
l
=
1
k
∑
i
=
1
n
l
n
α
l
⋅
p
(
l
∣
x
i
,
Θ
(
g
)
)
∂
α
1
,
…
,
∂
α
k
=
[
0
,
…
,
0
]
\frac{\partial \sum_{l=1}^{k} \sum_{i=1}^{n} ln\alpha _{l}\cdot p(l|x_i,\Theta^{(g)}) }{\partial \alpha_1,\ldots,\partial \alpha_k}=[0,\ldots,0]
∂α1,…,∂αk∂∑l=1k∑i=1nlnαl⋅p(l∣xi,Θ(g))=[0,…,0]
s
t
.
∑
l
=
1
k
α
l
=
1
st.\sum_{l=1}^{k}\alpha _{l}=1
st.l=1∑kαl=1
这是一个有约束的极值问题,我们利用拉格朗日乘子法进行求解:
L
(
α
1
,
…
,
α
k
,
λ
)
=
∑
l
=
1
k
l
n
(
α
l
)
(
∑
i
=
1
n
p
(
l
∣
x
i
,
Θ
(
g
)
)
−
λ
(
∑
l
=
1
k
α
l
−
1
)
L(\alpha_1,\ldots,\alpha_k,\lambda)=\sum_{l=1}^k ln(\alpha_l)\left( \sum_{i=1}^n p(l|x_i,\Theta^{(g)}\right)-\lambda \left( \sum_{l=1}^k \alpha_l-1\right)
L(α1,…,αk,λ)=l=1∑kln(αl)(i=1∑np(l∣xi,Θ(g))−λ(l=1∑kαl−1) 求解如下:
⇒
∂
L
∂
α
l
=
1
α
l
(
∑
i
=
1
n
p
(
l
∣
x
i
,
Θ
(
g
)
)
)
−
λ
=
0
\Rightarrow \frac{\partial L}{\partial \alpha_l}=\frac{1}{\alpha_l}\left ( \sum_{i=1}^{n}p(l|x_i,\Theta^{(g)}) \right )-\lambda =0
⇒∂αl∂L=αl1(i=1∑np(l∣xi,Θ(g)))−λ=0
∂
L
∂
λ
=
(
∑
l
=
1
k
α
l
−
1
)
=
0
\frac{\partial L}{\partial \lambda }=\left( \sum_{l=1}^k \alpha_l-1\right)=0
∂λ∂L=(l=1∑kαl−1)=0
⇒
α
l
=
1
N
∑
i
=
1
n
p
(
l
∣
x
i
,
Θ
(
g
)
)
\Rightarrow \alpha_l=\frac{1}{N} \sum_{i=1}^{n} p(l|x_i,\Theta^{(g)})
⇒αl=N1i=1∑np(l∣xi,Θ(g))
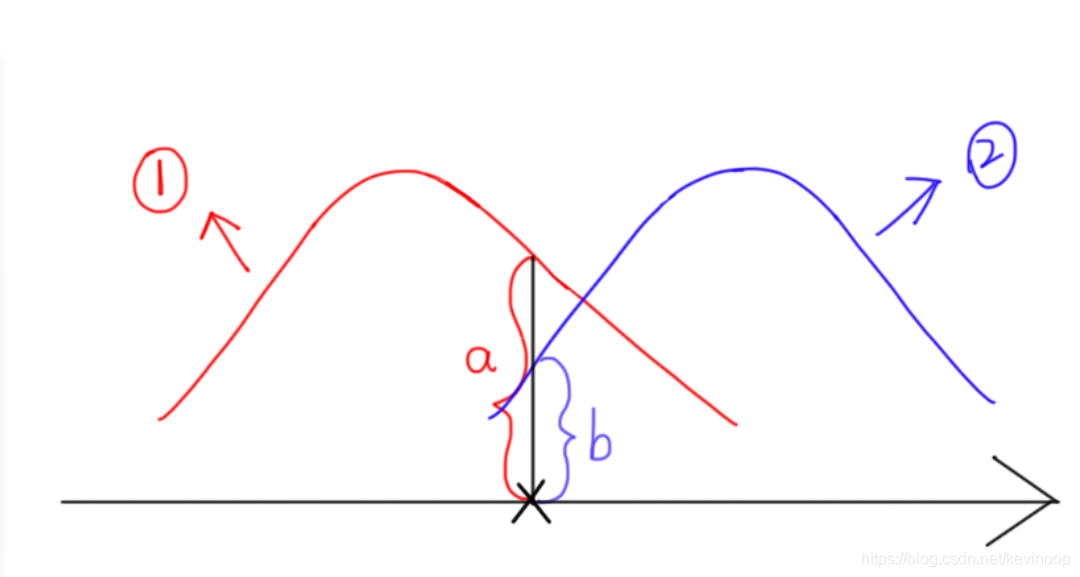
由下图我们可以直观理解:
α
1
\alpha_1
α1 就是把所有样本点的
a
a
+
b
\frac{a}{a+b}
a+ba 加起来再除以样本总数N,即求所有样本点的
a
a
+
b
\frac{a}{a+b}
a+ba 的均值;
α
2
\alpha_2
α2 就是把所有样本点的
b
a
+
b
\frac{b}{a+b}
a+bb 加起来再除以样本总数N,即求所有样本点的
b
a
+
b
\frac{b}{a+b}
a+bb 的均值;
(2)最大化
μ
,
Σ
\mu,\Sigma
μ,Σ
∂
∑
l
=
1
k
∑
i
=
1
n
l
n
[
N
(
x
i
∣
μ
l
,
Σ
l
)
]
⋅
p
(
l
∣
x
i
,
Θ
(
g
)
)
∂
μ
1
,
…
,
∂
μ
k
,
∂
Σ
1
,
…
,
∂
Σ
k
=
[
0
,
…
,
0
]
\frac{\partial \sum_{l=1}^{k} \sum_{i=1}^{n}ln[N (x_i|\mu_{l},\Sigma_{l})] \cdot p(l|x_i,\Theta^{(g)}) }{\partial \mu_1,\ldots,\partial \mu_k,\partial \Sigma_1,\ldots,\partial \Sigma_k}=[0,\ldots,0]
∂μ1,…,∂μk,∂Σ1,…,∂Σk∂∑l=1k∑i=1nln[N(xi∣μl,Σl)]⋅p(l∣xi,Θ(g))=[0,…,0]
经过化简可以得到:
μ
l
=
∑
i
=
1
n
x
i
p
(
l
∣
x
i
,
Θ
)
∑
i
=
1
n
p
(
l
∣
x
i
,
Θ
)
\mu_l=\frac{\sum_{i=1}^n x_ip(l|x_i,\Theta ) }{\sum_{i=1}^n p(l|x_i,\Theta ) }
μl=∑i=1np(l∣xi,Θ)∑i=1nxip(l∣xi,Θ)
Σ
l
=
∑
i
=
1
n
(
x
i
−
μ
l
)
(
x
i
−
μ
l
)
T
p
(
l
∣
x
i
,
Θ
)
∑
i
=
1
n
p
(
l
∣
x
i
,
Θ
)
\Sigma_l=\frac{\sum_{i=1}^{n} (x_i-\mu_l)(x_i-\mu_l)^Tp(l|x_i,\Theta)}{\sum_{i=1}^{n} p(l|x_i,\Theta)}
Σl=∑i=1np(l∣xi,Θ)∑i=1n(xi−μl)(xi−μl)Tp(l∣xi,Θ)
五、PYTHON Demos
Demo1:
Demo2:


六、参考资料
[1] 李航《统计学习方法》
[2] 徐亦达教授的自视频
[3] machine-learning-notes(em.pdf).Professor Richard Xu .