我们经常使用错误率(即分类错误的样本占总体样本的比例)来分析一个机器学习算法的性能,但是有时候不能满足任务的需求。
例如,我们想要利用机器学习算法来预测肿瘤是不是恶性的。在训练集中,只有0.5%的样本是恶性肿瘤。假设我编写一个非机器学习的算法,无论输入是什么,我都预测肿瘤是良性的,那么最终错误率也就只有0.5%。而如果我通过一个机器学习算法得到了1%的错误率,我是不是可以说这个机器学习的算法反而不如不学习?显然,这是有问题的。所以这时候,错误率就不能用来作为评判算法性能的依据了。此时就需要用到查准率和查全率了。
假设我们用y=1表示肿瘤是恶性,y=0表示肿瘤是良性。则:
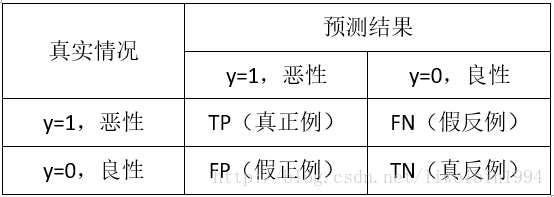
如上图,TP表示预测为真的是恶性,而实际也是恶性的样例数;
FN表示预测是良性,而实际是恶性的样例数;
TP+FN表示实际是恶性的样例总数;
FP表示预测为恶性,而实际是良性的样例数;
TN表示预测为良性,而实际是良性的样例数;
TP+FP表示预测为恶性的样例数。
所以,查准率(Precision)P的定义为:
P=TPTP+FP P = T P T P + F P
它表示在所有预测为恶性的样例中,实际真的是恶性的比例。比例越高,说明FP越小,查得越准。
查全率(Recall)R的定义为:
R=TPTP+FN R = T P T P + F N