基于Bert预训练模型的SQuAD 问答系统
step-1 运行example
参考huggingface的 pytorch_transformer 下载并运行 example run_squad.py
运行参数:
python run_squad.py
--model_type bert
--model_name_or_path bert-base-uncased
--do_train
--do_eval
--do_lower_case
--train_file ../../SQUAD_DIR/train-v1.1.json
--predict_file ../../SQUAD_DIR/dev-v1.1.json
--per_gpu_train_batch_size 4
--learning_rate 3e-5
--num_train_epoch 2.0
--max_seq_length 384
--doc_stride 128
--output_dir ../../SQUAD_DIR/OUTPUT
--overwrite_output_dir
--gradient_accumulation_steps 3
其中config.json
{'attention_probs_dropout_prob': 0.1, 'finetuning_task': None, 'hidden_act': 'gelu', 'hidden_dropout_prob': 0.1, 'hidden_size': 768, 'initializer_range': 0.02, 'intermediate_size': 3072, 'layer_norm_eps': 1e-12, 'max_position_embeddings': 512, 'num_attention_heads': 12, 'num_hidden_layers': 12, 'num_labels': 2, 'output_attentions': False, 'output_hidden_states': False, 'pruned_heads': {}, 'torchscript': False, 'type_vocab_size': 2, 'vocab_size': 30522}
tokenizer_config.json
{'do_lower_case': True, 'max_len': 512, 'init_inputs': []}
运行结果:
{"exact": 79.2715, "f1": 86.96, "total": 10570, "HasAns_exact": 79.27, "HasAns_f1": 86.96, "HasAns_total": 10570}
evaluation
python evaluate-v1.1.py dev-v1.1.json OUTPUT/predictions_.json
{"exact_match": 79.27152317880795, "f1": 86.96144570829648}
step-2 代码解读
1. SQuAD 数据格式
SQuAD: json file
json file: dict_keys(['data', 'version'])其中:
1. 'version'是1.1表明SQuAD 版本
2. 'data'是训练数据:<class 'list'> 是一个list,里面包含442项,每一项都是一个dict.
data[11]是一个dict_keys(['title', 'paragraphs']) ##以data[11]为例
2.1 'title'是文章的标题
2.2'paragraphs'是文章的各个段落,是一个<class 'list'>,里面包含n(148项),每一项都是一个dict
paragraphs[0]是一个dict_keys(['context', 'qas'])
2.2.1 'context'是该段落内容
2.2.2 'qas'是一个list, 里面有6项该段落对应的问题,每一项都是一个dict,
qas里面的问题有些比较相似,答案都一致的,同一个答案的不同问法
qas[0]是一个dict_keys(['answers', 'question', 'id'])
2.2.2.1 answers: 是一个list,里面每个元素都是一个dict_keys(['answer_start','text'])
2.2.2.2 question: 问题
2.2.2.3 id: 问题的id
比如:
{'answers': [{'answer_start': 0, 'text': 'New York'}],
'question': 'What city in the United States has the highest population?',
'id': '56ce304daab44d1400b8850e'}
{'answers': [{'answer_start': 0, 'text': 'New York'}],
'question': 'In what city is the United Nations based?',
'id': '56ce304daab44d1400b8850f'}
{'answers': [{'answer_start': 0, 'text': 'New York'}],
'question': 'What city has been called the cultural capital of the world?',
'id': '56ce304daab44d1400b88510'}
{'answers': [{'answer_start': 0, 'text': 'New York'}],
'question': 'What American city welcomes the largest number of legal immigrants?',
'id': '56ce304daab44d1400b88511'}
{'answers': [{'answer_start': 22, 'text': 'New York City'}],
'question': 'The major gateway for immigration has been which US city?',
'id': '56cf5d41aab44d1400b89130'}
{'answers': [{'answer_start': 22, 'text': 'New York City'}],
'question': 'The most populated city in the United States is which city?',
'id': '56cf5d41aab44d1400b89131'}
2. 数据读取和转换
2-1. 源数据结构 SquadExample
SquadExample 用于parser SQuAD 源数据。
class SquadExample(object):
"""
A single traing/test example for the squad dataset.
For examples without an answer, the start and end position are -1.
"""
def __init__(self, qas_id, question_text, doc_tokens,
orig_answer_text=None, start_position=None, end_position=None,
is_impossible=None):
self.qas_id = qas_id
self.question_text = question_text
self.doc_tokens = doc_tokens
self.orig_answer_text = orig_answer_text
self.start_position = start_position
self.end_position = end_position
self.is_impossible = is_impossible
其中qas_id 是样本ID, question_text 问题文本,doc_tokens是阅读材料, orig_answer_text 原始答案的文本, start_position答案在文本中开始的位置,end_position答案在文本中结束的位置,is_impossible在SQuAD2中可用的negtivate 标识(这里可以先不用管)。
2-2. 源数据读取read_squad_examples
def read_squad_examples(input_file, is_training, version_2_with_negative):
#read a SQuAD json file into a list of SquadExample
with open(input_file, "r", encoding='utf-8') as reader:
input_data = json.load(reader)['data']
def is_whitespace(c):
if c==' ' or c=='\t' or c=='\r' or c=='\n' or ord(c)==0x202F:
return True
return False
examples = []
for entry in input_data:## entry是一个dict{title, paragraphs}, 此处主要对paragraphs进行处理
##entry['paragraphs']是一个list, 里面每一个item都是一个dict{context, qas}
for paragraph in entry['paragraphs']:## paragraph是一个dict{context, qas}
# step-1: 处理paragraph['context'] 得到 doc_tokens 和 char_to_word_offset
paragraph_text = paragraph['context']
doc_tokens = [] # context里面包含的一个个单词,按顺序放进去,等价于paragraph['context'].split()
char_to_word_offset = [] # context 每个字母对应的单词的offset
prev_is_whitespace = True
for c in paragraph_text: ##把text按照字母一个个输出
##如果之前是空格,则doc_tokens.append(c)是作为一个doc_tokens一个新的元素添加进去。
##如果之前不是空格,则在doc_tokens[-1]最后一个元素(str)上加上c这个字母。
##运行结果是 doc_tokens是一个个单词,效果等价于paragraph_text.split()
## ??不知道为什么这里要这么操作,而不是直接split()
## char_to_word_offset是paragraph_text每个字母对应的单词的在doc_tokens中的index
## 注意这里char_to_word_offset包含空格,空格默认和前一个单词的index一致
if is_whitespace(c):
prev_is_whitespace = True
else:
if prev_is_whitespace:
doc_tokens.append(c)
else:
doc_tokens[-1] += c
prev_is_whitespace = False
char_to_word_offset.append(len(doc_tokens) - 1)
#setp-2: 处理paragraph['qas'] 得到qas_id, question_text, orig_answer_text, start_position, end_position, is_impossible
for qa in paragraph['qas']:## qa是一个dict{answers,questions,id}
qas_id = qa['id']
question_text = qa['question']
start_position = None
end_position = None
orig_answer_text = None
is_impossible = False
if is_training:
if version_2_with_negative:## 如果是version2 SQuAD 里面包含negative info
is_impossible = qa['is_impossible']
if (len(qa['answers']) !=1) and (not is_impossible):#多个答案,且都正确
raise ValueError('For training, each question should have exactly 1 answer.')
if not is_impossible: ## 正确答案
answer = qa['answers'][0] ## qa['answers']是一个list,里面只有一个元素,该元素是一个dict{text, answer_start}
orig_answer_text = answer['text']
answer_offset = answer['answer_start']
answer_length = len(orig_answer_text) ## answer 字符串的长度
start_position = char_to_word_offset[answer_offset] # 答案在文档中的起始位置
end_position = char_to_word_offset[answer_offset + answer_length - 1] # 答案在文档中的终止位置
## 这里只添加 那些能在文档中能准确找到answer['text']的答案。
## 如果answer['text']找不到,有可能是因为奇怪的编码之类的问题导致的,遇到这种情况我们就会跳过这个样本。
## 这就意味着对于训练模式,不能保证 保存每一个训练样本。
actual_text = " ".join(doc_tokens[start_position:(end_position + 1)]) # 文中 答案所在的句子
cleaned_answer_text = " ".join(whitespace_tokenize(orig_answer_text))
## whitespace_tokenize: 得到一个text.split()之后的list, " ".join得到一个str 以" "隔开,这一行的意义是统一单词之间的间隔符
if actual_text.find(cleaned_answer_text) == -1: # 判断答案在 实际句子中是否能找到,如果不能找到则跳过,找到则放到example中。
logger.waring("Could not find answer: '%s' vs '%s'", actual_text, cleaned_answer_text)
continue
else:
start_position = -1
end_position = -1
orig_answer_text = ''
example = SquadExample(qas_id=qas_id,
question_text=question_text,
doc_tokens=doc_tokens,
orig_answer_text=orig_answer_text,
start_position=start_position,
end_position=end_position,
is_impossible=is_impossible)
examples.append(example)
return examples
2-3. 源数据转换的特征结构 InputFeatures
InputFeatures 是将源数据SQuAD 转换成用于BERT 模型的输入特征。
class InputFeatures(object):
"""A single set of features of data"""
def __init__(self, unique_id, example_index, doc_span_index,
tokens, token_to_orig_map, token_is_max_context,
input_ids, input_mask, segment_ids, cls_index,
p_mask, paragraph_len, start_position=None, end_position=None,
is_impossible=None):
self.unique_id = unique_id
self.example_index = example_index
self.doc_span_index = doc_span_index
self.tokens = tokens
self.token_to_orig_map = token_to_orig_map
self.token_is_max_context = token_is_max_context
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.cls_index = cls_index
self.p_mask = p_mask
self.paragraph_len = paragraph_len
self.start_position = start_position
self.end_position = end_position
self.is_impossible = is_impossible
其中unique_id是feature的唯一id, example_index 样本索引,用于建立feature 和example的对应,
doc_span_index是该feature在doc_span的索引,如果一个文本很长,那么肯定要对其进行截取成若干片段 转成 doc_span, doc_span里面的各个片段都会装进各个feature里面,所以一个feature就会有一个doc_span_index.
tokens 该样本的token序列,token_to_orig_map是tokens里面每一个token在原始doc_token的索引,token_is_max_context是一个序列,里面的值表示该位置的token在当前span里面是否是上下文最全的。
函数:_check_is_max_contex(doc_spans, cur_span_index, position)
由于我们对长文本通过滑动窗口的方法进行切分,得到了多个doc_span, 一个单独的token 有可能出现在多个doc_span中。
E.g.
Doc: the man went to the store and bought a gallon of milk
Span A: the man went to the
Span B: to the score and bought
Span C: and bought a gallon of
'bought'这个单词将会有2个score 分别来自spans B和C. 我们只想考虑score with 'maximum context'
什么叫'maximum context'? 这个单词左右内容最多的情况。
如何算'score'? 左右内容最小值 加上文本长度的0.01 : min(len_of_left_context, len_of_right_context) +0.01 * doc_span.length
对于上面的例子,the maximum context for 'bought' 就是span C,因为在C中bought
有1个left context, 3个right context。而B中有4个left context 但是只有0个right context.
input_ids是tokens转化为token ids作为模型的输入,input_mask输入的mask(mask padding 模块),segment_ids, is_impossible。
start_position, end_position 是答案在当前tokens序列里面的位置(跟上面example中的不同,这里的位置不是整个context里面的位置),注意如果答案不在当前span里的化,start_position和end_position 均为0。
2-4. 源数据到特征的转换convert_examples_to_features
唯一需要注意的是:输入特征的格式[CLS] question_text tokens [SEP] doc_tokens [SEP]
即 [CLS] 问题 [SEP]阅读材料片段[SEP]
def convert_examples_to_features(examples, tokenizer, max_seq_length,
doc_stride, max_query_length, is_training,
cls_token_at_end=False,
cls_token='[CLS]', sep_token='[SEP]', pad_token=0,
sequence_a_segment_id=0, sequence_b_segment_id=1,
cls_token_segment_id=0, pad_token_segment_id=0,
mask_padding_with_zero=True):
""" Loads a data file into a list of 'InputBatch's. """
unique_id = 1000000000
# cnt_pos, cnt_neg = 0, 0
# max_N, max_M = 1024, 1024
# f = np.zero((max_N, max_M), dtype=np.float32)
features = []
for (example_index, example) in enumerate(examples):
# if example_index % 100 == 0:
# logger.info('Converting %s/%s pos %s neg %s', example_index, len(examples), cnt_pos, cnt_neg)
query_tokens = tokenizer.tokenize(example.question_text)
if len(query_tokens) > max_query_length:
query_tokens = query_tokens[0:max_query_length]
tok_to_orig_index = []
orig_to_tok_index = []
all_doc_tokens = []
for (i, token) in enumerate(example.doc_tokens): ## example.doc_tokens的token是一个paragraph单词组成的list['','',]
orig_to_tok_index.append(len(all_doc_tokens))
sub_tokens = tokenizer.tokenize(token) ## 这里对paragraph单词用各个模型设计的tokenizer分词法再进行分词。
for sub_token in sub_tokens:
tok_to_orig_index.append(i) ## 这里是tokenizer之后 第sub_token对应的原始 单词的index
all_doc_tokens.append(sub_token) ## 这里添加用tokenizer分词之后的tokens
## 下面这一段是得到通过model.tokenizer分词之后的答案所在位置
tok_start_position = None
tok_end_position = None
if is_training and example.is_impossible:
tok_start_position = -1
tok_end_position = -1
if is_training and not example.is_impossible:
tok_start_position = orig_to_tok_index[example.start_position]
if examples.end_position < len(example.doc_tokens) - 1:
tok_end_position = orig_to_tok_index[example.end_position]
else:
tok_end_position = len(all_doc_tokens) - 1
## 获取tokenizer之后答案所在位置
(tok_start_position, tok_end_position) = _improve_answer_span(
all_doc_tokens, tok_start_position, tok_end_position,
tokenizer, example.orig_answer_text)
# The -3 accounts for [CLS], [SEP] and [SEP] 因为句子格式[CLS]A[SEP]B[SEP]
max_tokens_for_doc = max_seq_length - len(query_tokens) - 3
# 我们有可能会有比maximum sequence length 更长的 documents,为了处理这种情况,
# 我们做一个滑动窗口,我们取一个达到我们最大长度的窗口,
_DocSpan = collections.namedtuple( # pylint: disable=invalid-name
"DocSpan", ["start", "length"])
doc_spans = []
start_offset = 0
while start_offset < len(all_doc_tokens):
length = len(all_doc_tokens) - start_offset
if length > max_tokens_for_doc:
length = max_tokens_for_doc
doc_spans.append(_DocSpan(start=start_offset, length=length))
if start_offset + length == len(all_doc_tokens):
break
start_offset += min(length, doc_stride)
for (doc_span_index, doc_span) in enumerate(doc_spans):
tokens = []
token_to_orig_map = []
token_is_max_context = {}
segment_ids = []
# p_mask: mask with 1 for token that can't be in answer(0 for token which can be in an answer)
# Original TF implem also keep the classification token(set to 0)
p_mask = []
# CLS token at the begging
if not cls_token_at_end:
tokens.append(cls_token)
segment_ids.append(cls_token_segment_id)
p_mask.append(0)
cls_index = 0
# Query
for token in query_tokens:
tokens.append(token)
segment_ids.append(sequence_a_segment_id)
p_mask.append(1)
# SEP token
tokens.append(sep_token)
segment_ids.append(sequence_a_segment_id)
p_mask.append(1)
# Paragraph
for i in range(doc_span.length):
split_token_index = doc_span.start + i
token_to_orig_map[len(tokens)] = tok_to_orig_index[split_token_index]
is_max_context = _check_is_max_contex(doc_spans, doc_span_index,
split_token_index)
token_is_max_context[len(tokens)] = is_max_context
tokens.append(all_doc_tokens[split_token_index])
segment_ids.append(sequence_b_segment_id)
p_mask.append(0)
paragraph_len = doc_span.length
# SEP token
tokens.append(sep_token)
segment_ids.append(sequence_b_segment_id)
p_mask.append(1)
# CLS token at the end
if cls_token_at_end:
tokens.append(cls_token)
segment_ids.append(cls_token_segment_id)
p_mask.append(0)
cls_index = len(tokens) - 1 # index of classification token
input_ids = tokenizer.convert_tokens_to_ids(tokens)
## the mask has 1 for real tokens and 0 for padding tokens
## tokens are attended to.
input_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
## Zero-pad up to the sequence length:添加padding
while len(input_ids) < max_seq_length:
input_ids.append(pad_token)
input_mask.append(0 if mask_padding_with_zero else 1)
segment_ids.append(pad_token_segment_id)
p_mask.append(1)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
span_is_impossible = example.is_impossible
start_position = None
end_position = None
if is_training and not span_is_impossible:
# For training, if our document chunk doesn't contain an annotation
# we throw it out, since there is nothing to predict
doc_start = doc_span.start
doc_end = doc_span.start + doc_span.length - 1
out_of_span = False
if not (tok_start_position >= doc_stride and
tok_end_position <= doc_end):
out_of_span = True
if out_of_span:
start_position = 0
end_position = 0
span_is_impossible = True
else:
doc_offset = len(query_tokens) + 2
start_position = tok_start_position - doc_start + doc_offset
end_position = tok_end_position - doc_start + doc_offset
if is_training and span_is_impossible:
start_position = cls_index
end_position = cls_index
if example_index < 20:
logger.info("*** example ***")
logger.info(" unique_id : %s" % (unique_id))
logger.info(" example_index: %s" % (example_index))
logger.info(" doc_span_index: %s" % (doc_span_index))
logger.info(" tokens: %s" % " ".join(tokens))
logger.info(" token_to_orig_map: %s" % " ".join([
"%d:%d" % (x, y) for (x, y) in token_to_orig_map.items()]))
logger.info(" token_is_max_context: %s" % " ".join([
"%d:%s" % (x, y) for (x, y) in token_is_max_context.items()
]))
logger.info(" input_ids: %s" % " ".join([str(x) for x in input_ids]))
logger.info(" input_mask: %s" % " ".join([str(x) for x in input_mask]))
logger.info(" segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
if is_training and span_is_impossible:
logger.info(" impossible example")
if is_training and not span_is_impossible:
answer_text = " ".join(tokens[start_position:(end_position + 1)])
logger.info(" start_position: %d" % (start_position))
logger.info(" end_position: %d" % (end_position))
logger.info(" answer: %s" % (answer_text))
features.append(
InputFeatures(
unique_id=unique_id,
example_index=example_index,
doc_span_index=doc_span_index,
tokens=tokens,
token_to_orig_map=token_to_orig_map,
token_is_max_context=token_is_max_context,
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
cls_index=cls_index,
p_mask=p_mask,
paragraph_len=paragraph_len,
start_position=start_position,
end_position=end_position,
is_impossible=span_is_impossible))
unique_id += 1
return features
2-5. 加载数据和特征
load_and_cache_examples
## input X
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_input_mask = torch.tensro([f.input_mask for f in features], dtype=torch.long)
all_segment_ids = torch.tensor([f.segment_ids for f in features], dtype=torch.long)
## input Y
all_start_positions = torch.tensor([f.start_position for f in features], dtype=torch.long)
all_end_positions = torch.tensor([f.end_position for f in features], dtype=torch.long)
input_ids, input_mask, segment_ids这三个元素之和作为模型的输入。而start_positions, end_positions 作为Y,知道了Y相当于知道答案位置,通过反向在阅读材料的context中去查找对应的内容就是答案。
3. model 和 loss的构建
BertForQuestionAnswering 模型在BERT 模型基础上添加了线性变换的head, 对BERT最后一层的输出hidden state(batch_size, seq_len, hidden_size)进行线性变换得logits(batch_size, seq_len, 2)(这里是num_labels是2 分别对应答案的2个位置start_logits 和end_logits值),然后分别计算start和end position的CrossEntropyLoss损失,start 和end loss的加和平均值即为模型的损失函数。
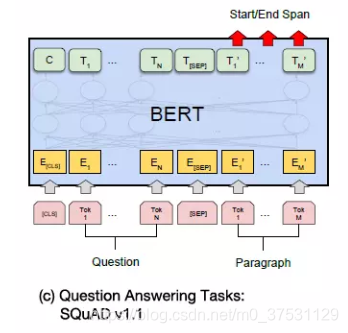
class BertForQuestionAnswering(BertPreTrainedModel):
def __init__(self, config):
super(BertForQuestionAnswering, self).__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
def forward(self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None,
start_positions=None, end_positions=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
outputs = (start_logits, end_logits,) + outputs[2:]
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions.clamp_(0, ignored_index)
end_positions.clamp_(0, ignored_index)
**loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2**
outputs = (total_loss,) + outputs
return outputs # (loss), start_logits, end_logits, (hidden_states), (attentions)
4. train 和 evaluation
train 函数中需要注意 optimizer 和schedule:
这里optimizer函数时AdamW, 是目前训练神经网络最快的方式, 是在Adam的基础上修正了权重衰减得到的优化器, 修正了Adam的收敛性得不到保证的问题. (但是其实最后证实了是因为模型超参数调的不够好,如果调好参数,Adam也可以达到很好的效果,通过Adam+L2 正则也可以, 但是效果不如权重AdamW 权重衰减) 参考: AdamW优化算法+超级收敛
#Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
-
权重衰减 : 防止过拟合
(避免过拟合的方法有很多:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)包括L1、L2(L2 regularization也叫weight decay),dropout)
L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。L2正则化就是在代价函数后面再加上一个正则化项:
其中C0代表原始的代价函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整为1。系数λ就是权重衰减系数。为什么可以对权重进行衰减? 我们可以对上面的代价函数进行求导,如下, 可以看出 L2正则对b的更新没有影响,但是对w的更新有影响.
在不使用L2正则化时,求导结果中w前系数为1,现在w前面系数为1-ηλ/n,因为η、λ、n都是正的,所以1-ηλ/n小于1,它的效果是减小w,这也就是权重衰减(weight decay)的由来。当然考虑到后面的导数项,w最终的值可能增大也可能减小。另外,需要提一下,对于基于mini-batch的随机梯度下降,w和b更新的公式跟上面给出的有点不同,对比上面w的更新公式,可以发现后面那一项变了,变成所有导数加和,乘以η再除以m,m是一个mini-batch中样本的个数。
权重衰减(L2正则化)可以避免模型过拟合问题. L2正则化项有让w变小的效果,防止过拟合的原理:(1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。 -
学习率衰减
学习率衰减(learning rate decay)就是一种可以平衡这两者之间矛盾的解决方案。学习率衰减的基本思想是:学习率随着训练的进行逐渐衰减。
学习率衰减基本有两种实现方法:(1 ) 线性衰减, 例如:每过5个epochs学习率减半。(2) 指数衰减, 例如:随着迭代轮数的增加学习率自动发生衰减,每过5个epochs将学习率乘以0.9998。具体算法如下:decayed_learning_rate=learning_rate*decay_rate^(global_step/decay_steps)
其中decayed_learning_rate为每一轮优化时使用的学习率,learning_rate为事先设定的初始学习率,decay_rate为衰减系数,decay_steps为衰减速度。
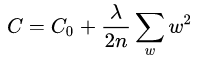
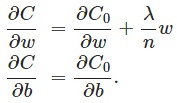
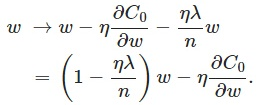
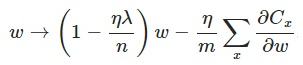
def train(args, train_dataset, model, tokenizer):
""" Train the model """
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset) ## 打乱顺序
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay}, ## 非bias, LayerNorm.weight的参数进行L2正则时
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank],
output_device=args.local_rank,
find_unused_parameters=True)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size * args.gradient_accumulation_steps * (torch.distributed.get_world_size() if args.local_rank != -1 else 1))
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 0
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0])
set_seed(args) # Added here for reproductibility (even between python 2 and 3)
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
model.train()
batch = tuple(t.to(args.device) for t in batch)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'token_type_ids': None if args.model_type == 'xlm' else batch[2],
'start_positions': batch[3],
'end_positions': batch[4]}
if args.model_type in ['xlnet', 'xlm']:
inputs.update({'cls_index': batch[5],
'p_mask': batch[6]})
outputs = model(**inputs)
loss = outputs[0] # model outputs are always tuple in pytorch-transformers (see doc)
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Log metrics
if args.local_rank == -1 and args.evaluate_during_training: # Only evaluate when single GPU otherwise metrics may not average well
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar('eval_{}'.format(key), value, global_step)
tb_writer.add_scalar('lr', scheduler.get_lr()[0], global_step)
tb_writer.add_scalar('loss', (tr_loss - logging_loss)/args.logging_steps, global_step)
logging_loss = tr_loss
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(args.output_dir, 'checkpoint-{}'.format(global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = model.module if hasattr(model, 'module') else model # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, 'training_args.bin'))
logger.info("Saving model checkpoint to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
参考博文:
权重衰减(weight decay)与学习率衰减(learning rate decay)
神经网络学习率(learning rate)的衰减
正则化方法:L1和L2 regularization、数据集扩增、dropout