目录
目录
一、基础术语
这一章不重要,可直接跳到第二章
1、记忆力分类
sensory memory 感官记忆
short-term memory 短期记忆
long-term memory 长期记忆
2、注意力机制介绍
基本定义:由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制
3、机器学习中的一种数据处理方法
模型对输入的X每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销
4、神经网络中的定义
在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案
5、注意力机制分类
5.1 soft attention 软注意力
在选择信息的时候,不是从N个信息中只选择1个,而是计算N个输入信息的加权平均,再输入到神经网络中计算
5.2 hard attention 强注意力
Hard Attention就是指选择输入序列某一个位置上的信息,比如随机选择一个信息或者选择概率最高的信息。一般还是用soft attention来处理神经网络的问题。
soft attention:在encoder中每一个输出都会计算一个概率,例如图中的小女孩和飞盘
hard attention:encoder中只寻找需要的那个计算概率,图中只关注飞盘

二、注意力机制所需基础
1、公式理解
将公式简化为一个X的变化:softmax(XX^T)X
这里默认X为行向量
1.1 XX^T
向量内积,表示两个向量的夹角,一个向量在另一个向量上的投影
下面的运算模拟了 XX^T,查看结果的含义
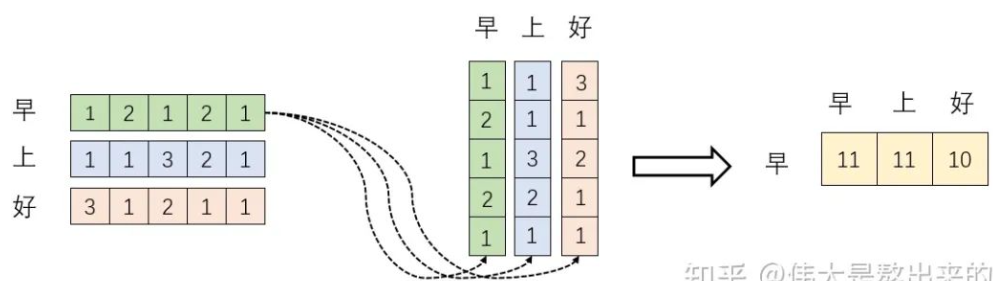
投影的值大,说明两个向量的相关性高,如果不相关,垂直则为0
1.2 softmax(XX^T)
对向量内积结果计算softmax,结果为 0.4,0.4,0.2
加入softmax的含义
- 归一化,结果的和为1
- 加权求和,分配0.4的注意力给它本身”早“,剩下0.4关注"上",0.2关注"好“
1.3 softmax(XX^T)X

新的行向量就是"早"字词向量经过注意力机制加权求和之后的表示
1.4 为什么不直接使用x,而要对其进行线性变换
提高模型的拟合能力,加入可训练参数矩阵W,起到缓冲的效果
2、注意力机制与自注意力机制的区别
Self Attention 顾名思义,指的【不是 Target 和 Source 之间的 Attention 机制】,而是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,也可以理解为 Target=Source 这种特殊情况下的注意力计算机制
三、注意力机制(Attention Mechanism)
1、机器翻译任务
文本翻译的需求:输入机器学习→Machine learning
2、引入soft-attention的机器翻译
2.1 Seq2Seq第一种模型用于机器翻译
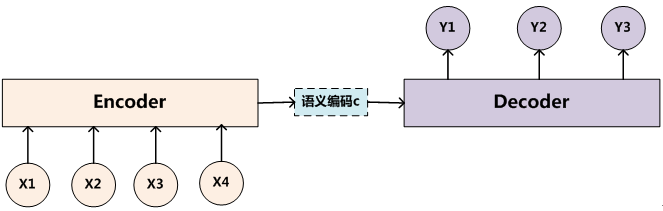
组成:Encoder、Decoder 和连接两者的 State Vector (中间状态向量) C
注:encoder与decoder见编码器总结笔记
- source 经过 Encoder,生成中间的语义编码 C
- C 经过 Decoder 之后,输出翻译后的句子
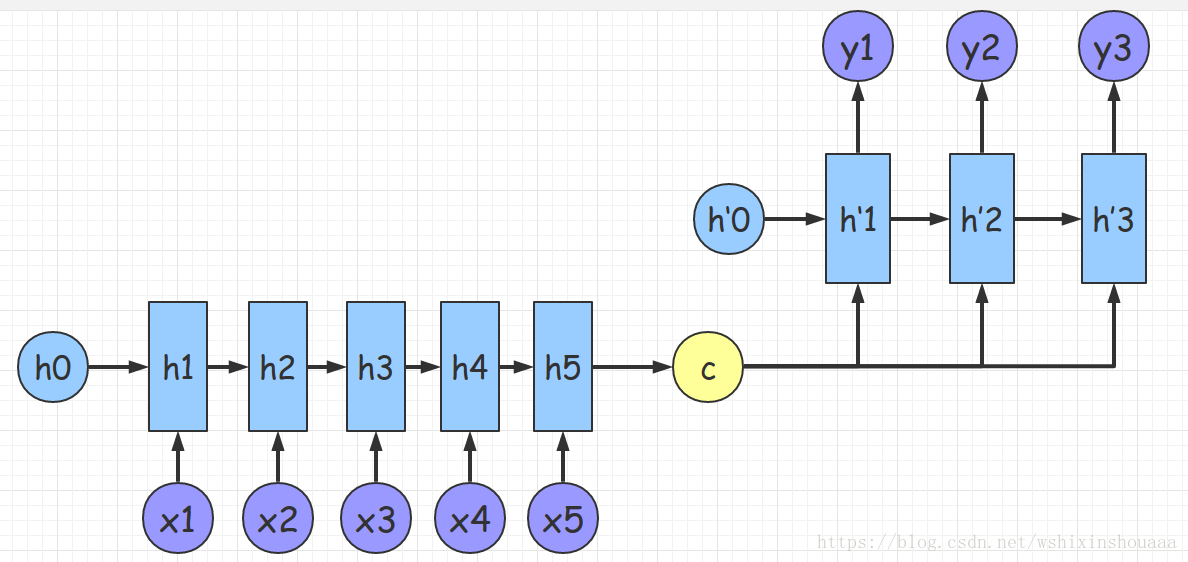
2.2 Seq2Seq的第二种模型
先根据 C 生成 y1,再基于(C,y1)生成 y2,依此类推
2.3 引入注意力机制
不同单词的影响不同,基于同一个语义编码效果不好,引入多个C
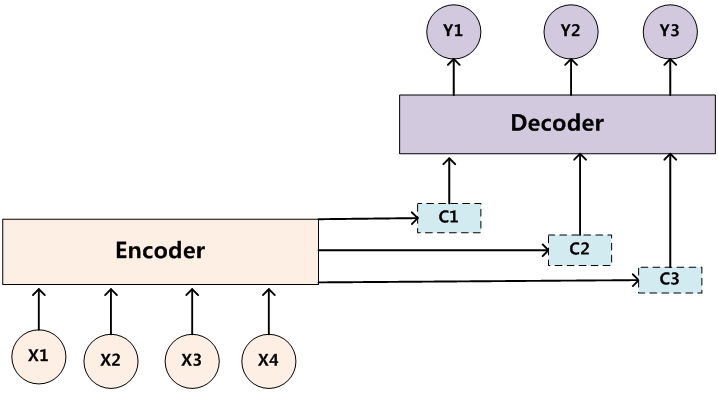
计算 C1、C2 和 C3 时,分别使用不同的权重向量:
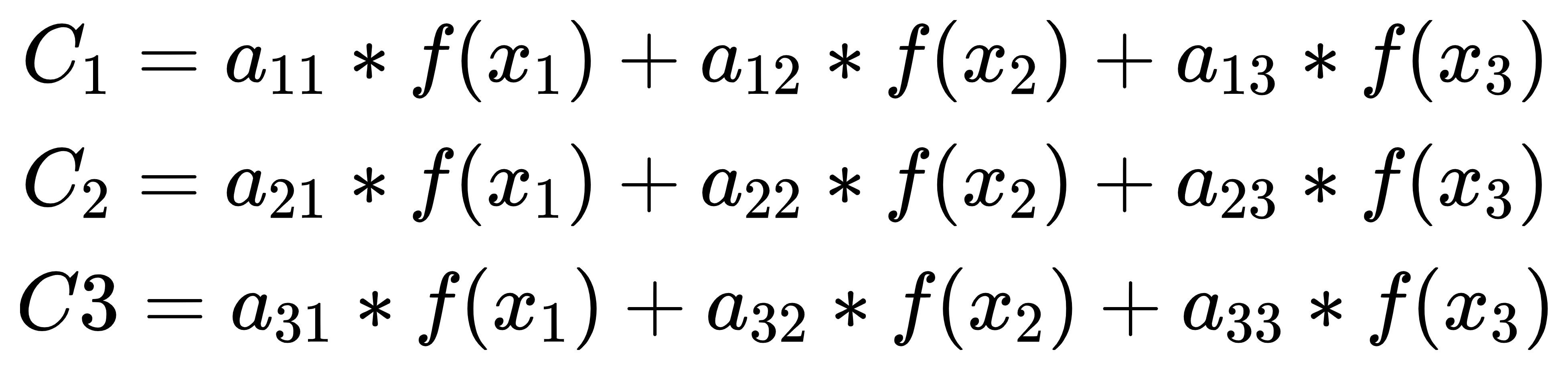
y1=g(C1,h0)
y2=g(C2,y1)
y3=g(C3,y1,y2)
3、公式
3.1 公式讲解

D_k为为向量维度,原论文为64,根号64=8。主要用来做归一化
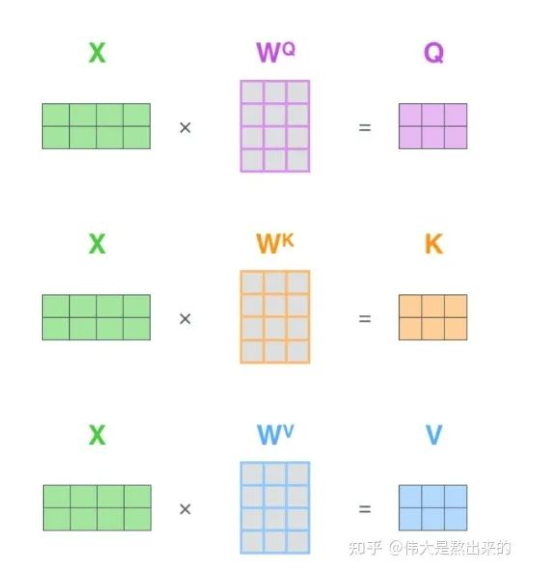
Q、K、V来源:向量X与参数矩阵的乘积
3.2 公式理解示例
在淘宝中搜索 “笔记本” 运行逻辑

4、Attention 机制的本质
可分为以下三个阶段
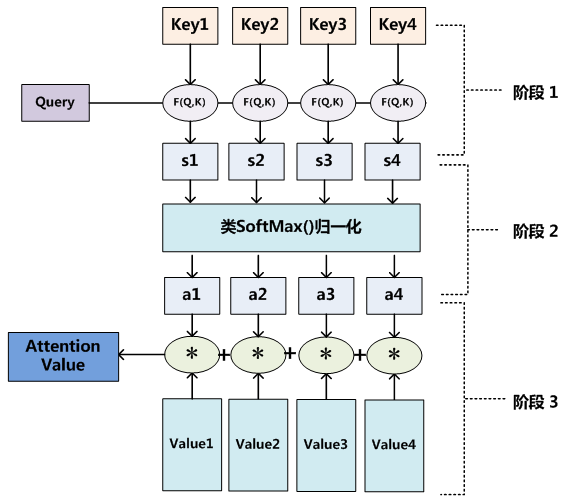
4.1 公式如下
4.2 阶段1,相似度计算
其中相似性计算可采用以下几种方式

4.3 阶段2,注意力打分机制
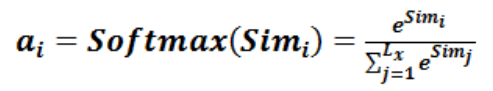
4.4 阶段3,归一化的注意力概率分配
上述公式中的 Lx 表示输入语句的长度
5 attention的优缺点
5.1 优点
- 参数少:相比于 CNN、RNN ,其复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快:Attention 解决了 RNN及其变体模型 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好:在Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
5.2 缺点
需要的数据庞大,否则根本不需要忽略非重点
四、自注意力机制self-attention
1 定义
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
2、 公式
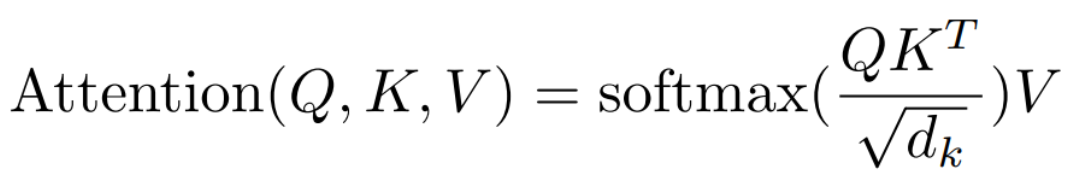
自注意力机制公式与注意力机制公式相同,但含义不同
- 注意力机制公式用于计算某个元素与其他所有元素之间的关系,通常用于在序列中寻找关键元素或者将输入序列中的信息进行汇总
- self-attention用于计算某个元素与其他所有元素之间的关系,其中所有元素,查询向量、键向量和值向量都来自于同一个序列。因此可以计算序列中每个元素与其他所有元素之间的关系
3、计算过程
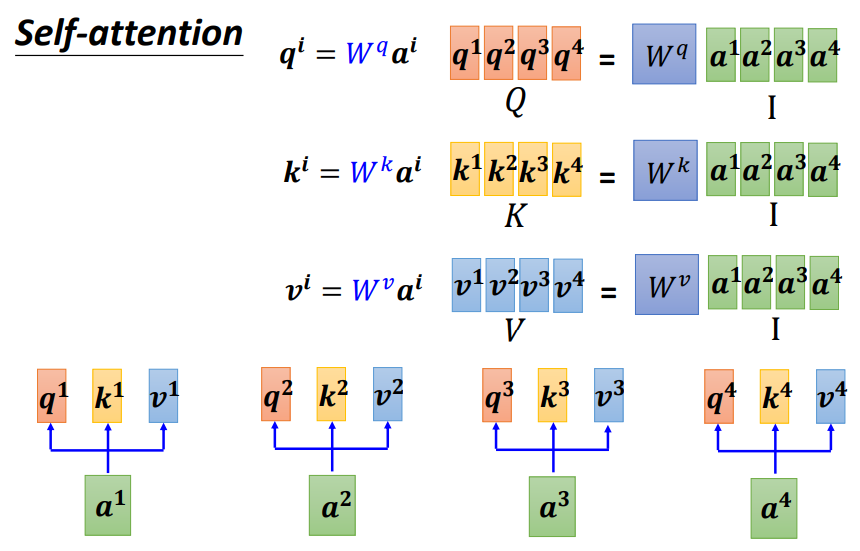
- 将输入单词转化成嵌入向量
- 对于每一个向量a,分别乘参数矩阵wq,wk,wv,得到Q,K,V三个向量,如图
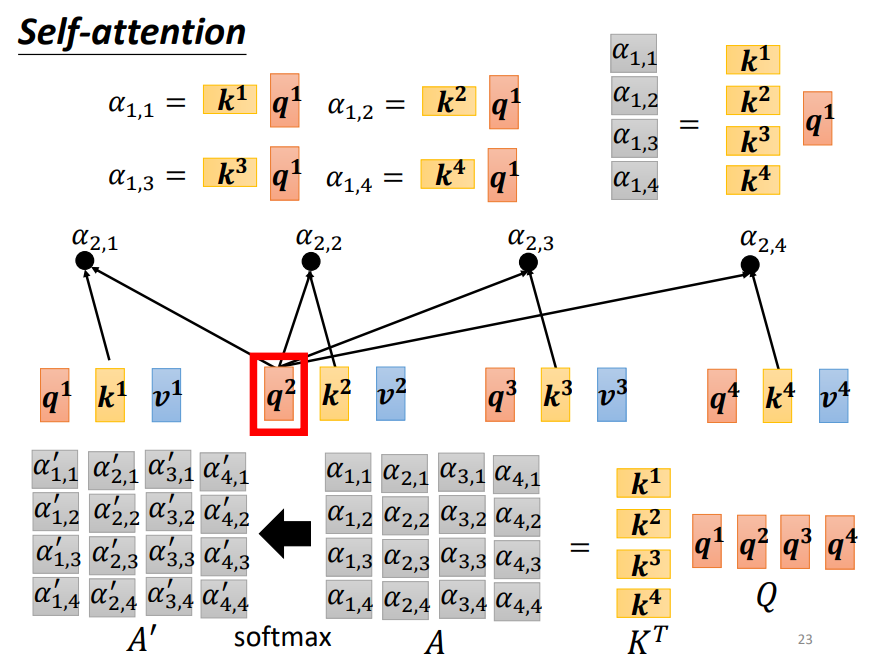
3. 利用得到的Q和K计算每两个输入向量之间的相关性,也就是计算attention的值α,α的计算方法有多种,通常采用点乘的方式。最终所有输入的相关性矩阵为A=K^T·Q
4. 为了梯度的稳定,Transformer使用了score归一化,即除以根号d_k
5. 对A矩阵进行softmax操作或者relu操作得到A',以上过程见下图
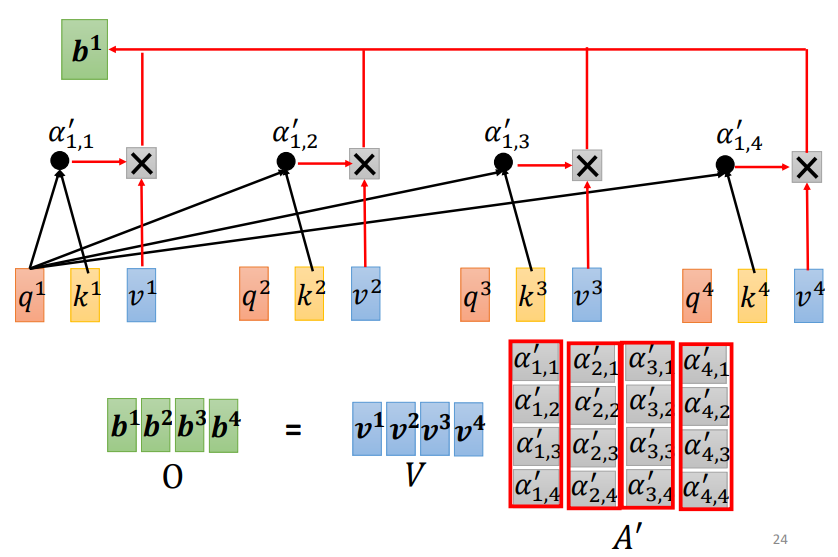
6. 利用得到的A'和V计算每个输入向量a对应的self-attention层的输出向量b
第一个向量a1对应的self-attention输出向量b1举例,如下图
五、多头注意力
1 self-attention的缺点
模型在对当前位置进行编码时,会过度的将注意力集中在自身的位置。
2 多头注意力机制的提出
我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,例如捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依赖)
多头注意力机制就是对注意力机制的简单堆叠,multi-headed Attention就是指用了很多个不同的权重矩阵计算出很多组K、Q、V
3、作用
多头机制赋予 attention 多种子表达方式。
每一组都是随机初始化,经过训练之后,输入向量可以被映射到不同的子表达空间中。
4、实现
4.1 单头注意力机制
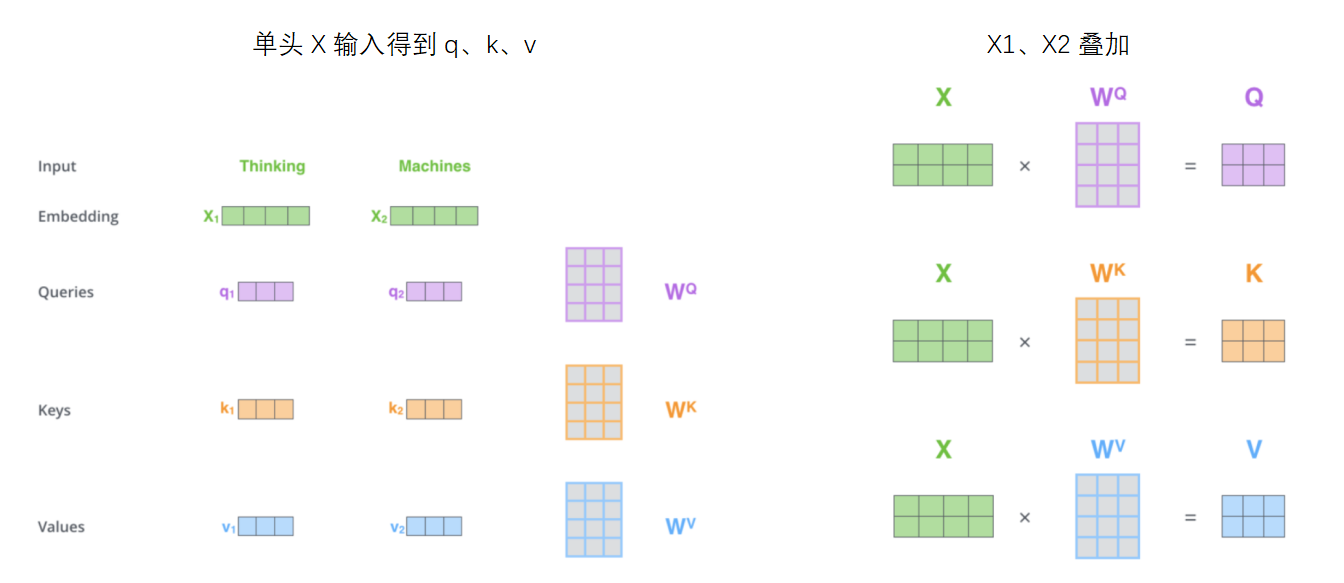
4.2 multi-headed Attention
初始化多组权重,将单头注意力叠加
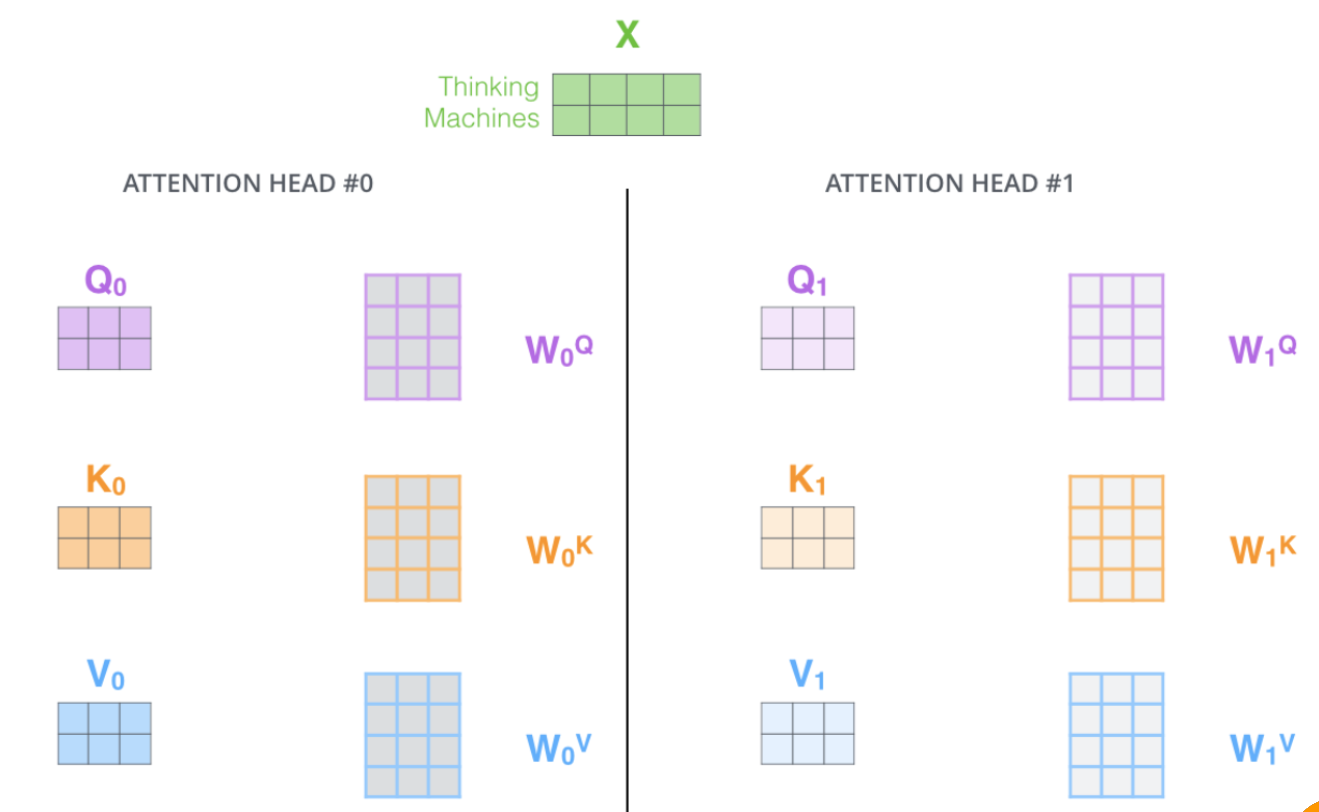
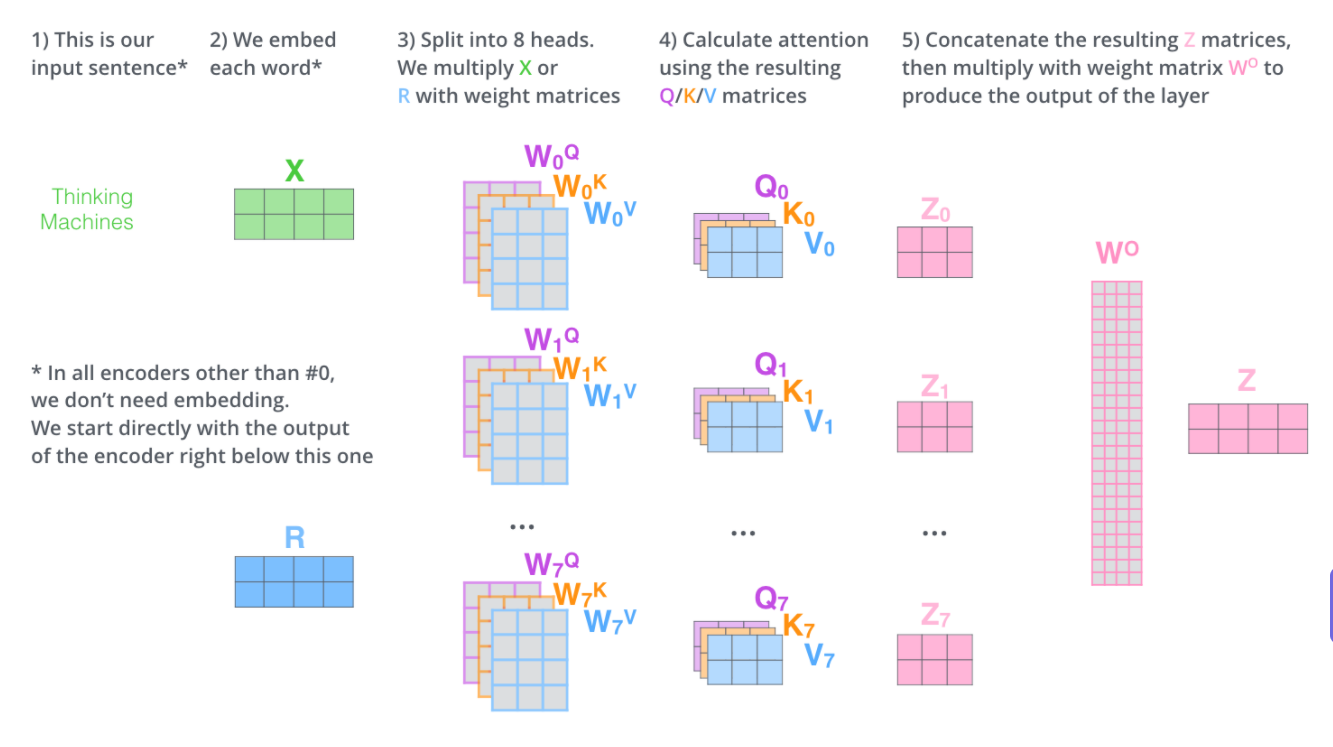
输入一批X,输出一批Z,将多个版本的Z拼接为一个长向量,
然后用一个权重矩阵相乘,压缩为一个短向量Z,用作下游任务的输入
4.3 一些问题解答
六、Transformer
七、参考资料:
1、李宏毅课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
快速直达注意力机制课件:https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
2、Self-Attention和Transformer - machine-learning-notes (gitbook.io)