一、基本信息
标题:ImageNet Classification with Deep Convolutional Neural Networks
时间:2012
出版源:Neural Information Processing Systems (NIPS)
论文领域:深度学习,计算机视觉
引用格式:Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
链接:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networ
二、研究背景
- 数据集:出现imageNet这样的大数据集,可以用来训练更复杂的模型 。
- CNN:而CNNs它们的能力可以通过改变深度和广度来控制,它们还对图像的本质(即统计的平稳性和像素依赖性的局部性)做出了强有力且基本正确的假设。与具有类似大小层的标准前馈神经网络相比,CNNs具有更少的连接和参数,因此更容易训练,而其理论上最好的性能可能只会稍微差一些。
- GPU: GPU和卷积操作结合,使得训练大型CNN网络成为可能
三、创新点
贡献点:
- 对ImageNet的子集进行了迄今为止最大的卷积神经网络训练,并取得了最好效果
- 开高度优化GPU实现2D卷积方法,后面提到网络在2块GPU并行
- 网络包含很多新的不寻常特征
- 防止过拟合
我们最终的网络包含5个卷积层和3个全连接层,这个深度似乎很重要:我们发现去掉任何卷积层(每个卷积层包含的model s参数不超过1%)都会导致性能下降。
ReLU激活
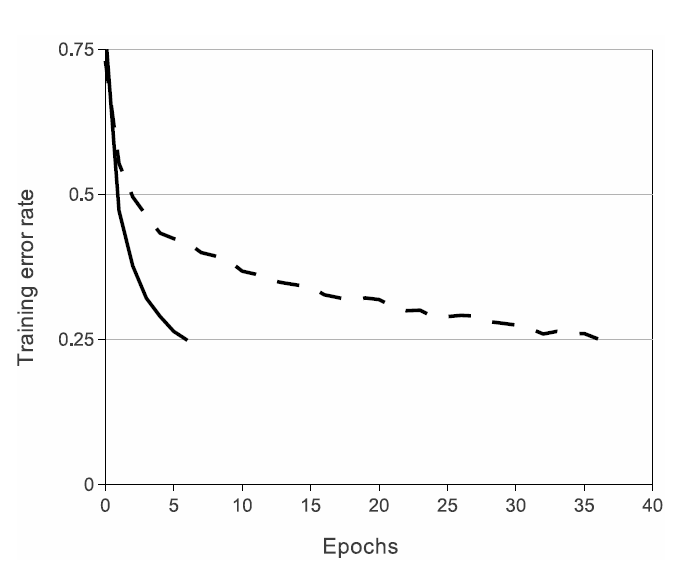
图1:使用ReLUs(实线)的四层卷积神经网络在CIFAR-10上达到25%的训练错误率,比使用tanh神经元(虚线)的同等网络快六倍。每个网络的学习率都是独立选择的,以使训练尽可能快。没有任何形式的正规化。这里演示的效果的大小随网络结构的不同而不同,但是使用ReLUs的网络始终比使用饱和神经元的网络学习速度快几倍。
Local Response Normalization 局部响应归一化
b
x
,
y
i
=
a
x
,
y
i
/
(
k
+
α
∑
j
=
max
(
0
,
i
−
n
/
2
)
min
(
N
−
1
,
i
+
n
/
2
)
(
a
x
,
y
j
)
2
)
β
b_{x, y}^{i}=a_{x, y}^{i} /\left(k+\alpha \sum_{j=\max (0, i-n / 2)}^{\min (N-1, i+n / 2)}\left(a_{x, y}^{j}\right)^{2}\right)^{\beta}
bx,yi=ax,yi/⎝⎛k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yj)2⎠⎞β
此方案有助于泛化,CNN在未归一化的情况下,测试错误率为13%;在归一化的情况下,测试错误率为11%。
参考这篇文章吧 深入理解AlexNet网络,大致意思就是当今kernel的map的(x, y)像素位置在周围邻居相同kernel的map的(x, y)像素。也就是上面式子中的
a
(
x
,
y
)
j
a_{(x, y)}^{j}
a(x,y)j 。然后把这些邻居pixel的值平方再加和。乘以一个系数
α
\alpha
α 再加上一个常数k, 然后
β
\beta
β 次冥, 就是分母,分子 就是第次kernel对应的map的(x, y)位置的pixel值。关键是参数
α
,
β
,
k
\alpha, \beta, k
α,β,k 如何确定, 论文中说在验证集中确定, 最终确定的结果为:
k
=
2
,
n
=
5
,
α
=
1
0
−
4
,
β
=
0.75
k=2, n=5, \alpha=10^{-4}, \beta=0.75
k=2,n=5,α=10−4,β=0.75
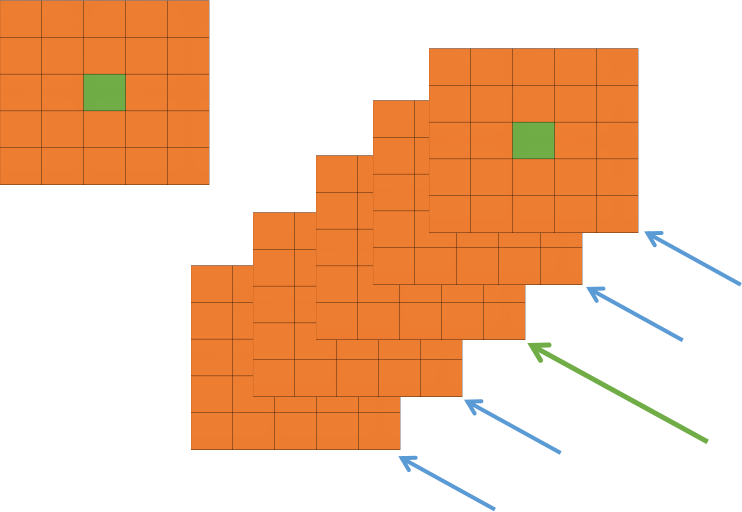
Overlapping Pooling 重叠池化
初步理解:假如池化单元为zxz
- 步长s = z,就是传统的池化
- 步长s < z,就是重叠池化
作者提到当s = 2 z = 3时,对比s = z = 2,错误率减少了0.4%(top-1) 和 0.3%(top-5)
使用重叠池化可以减少过拟合
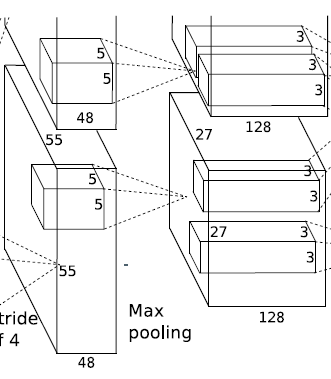
网络架构
一共8层,前5层是卷积层,后3层是全连接层:
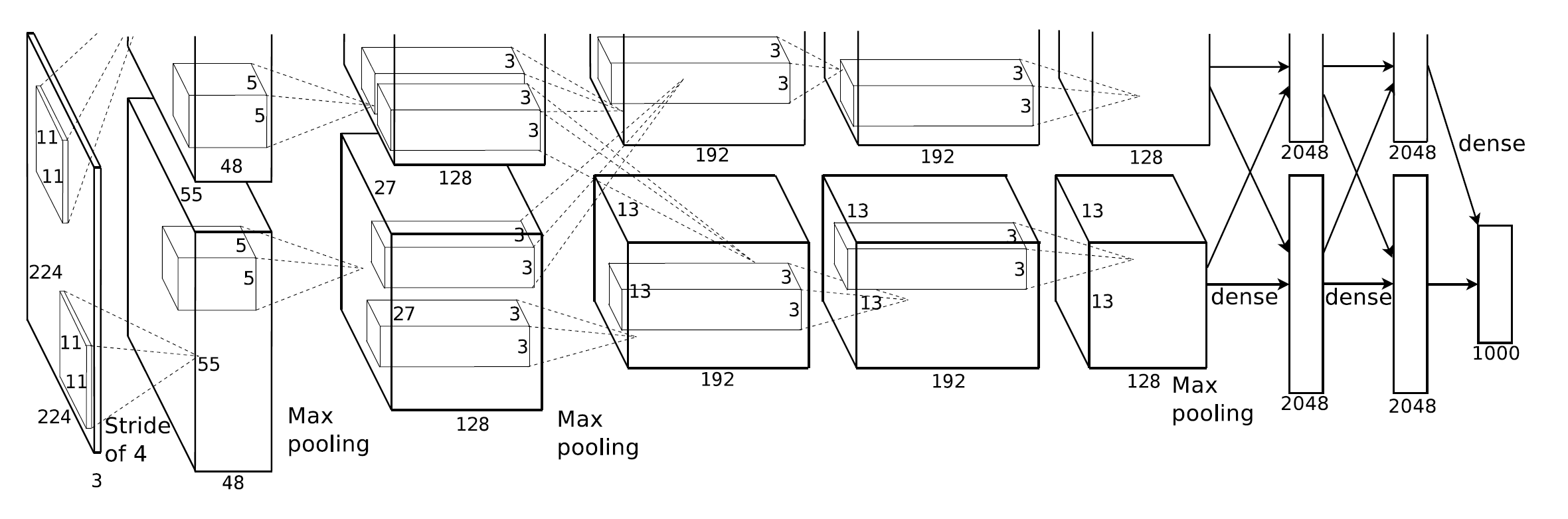
- 卷积层除了第3层,其余卷积层直接连接在同GPU上。第3层会连接第2层所有输出。
- 局部响应规范化(Local Response Normalization)层在第1层和第2层卷积层后。
- 最大池化层在响应规范化层(第1层和第2层卷积)和第5层卷积后。
- ReLU非线性激活函数应用在每个卷积和全连接层。
卷积输出计算公式,具体看这里:
设图像大小:n*n, 步长:s,卷积核大小:f,padding:p
(
n
+
2
p
−
f
s
+
1
)
∗
(
n
+
2
p
−
f
s
+
1
)
\left(\frac{n+2 p-f}{s}+1\right) *\left(\frac{n+2 p-f}{s}+1\right)
(sn+2p−f+1)∗(sn+2p−f+1)
具体参数:
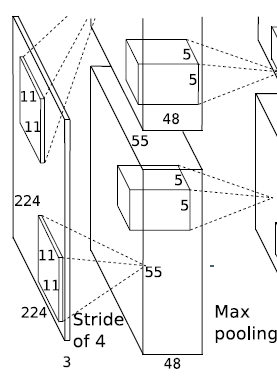
输入图片为224x224x3。

-
第1层卷积:
卷积
输入:224x224x3
卷积核大小:11 * 11 *3 步长:4(这个是11x11核的中心视野) 数目:48 * 2 = 96
输出:55 * 55 * 48 * 2
(输出为55 * 55:(224 - 11)/4 +1 = 54.25,取了上整55,48个特征map,因为有2个GPU,所以总的特征map数量是48 * 2)
ReLu激活
池化层
核大小:3 * 3 * 1 步长:2
输出:27 * 27 * 48 * 2
(输出为27 * 27 :(55 - 3) / 2 + 1 = 27)
标准化
【注】图上的结果没有进行池化 -
第2层卷积:
卷积
输入:27 * 27 * 48 * 2 扩展2个像素:31 * 31 * 48 * 2
卷积核大小:5 * 5 * 48 步长:1 数目:128 * 2 = 256(还需要连接局部响应规范化层和池化层)
输出:27 * 27 * 128 * 2
(输出为27 * 27:31 - 5 + 1 = 27,128个特征map,因为有2个GPU,所以总的特征map数量是128 * 2)
ReLu激活
池化层
核大小:3 * 3 * 1 步长:2
输出:13 * 13 * 128 * 2
(输出为13* 13:(27 - 3) / 2 + 1 = 13)
标准化 -
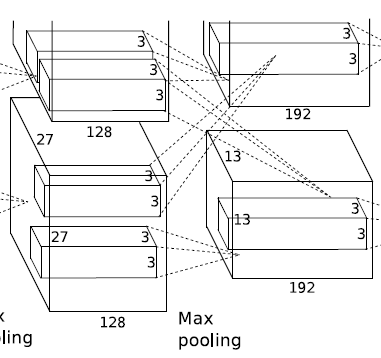
第3层卷积(这层卷积核结合了2个GPU):
卷积
输入:13 * 13 * 128 * 2 扩展1个像素:15 * 15 * 128 * 2
卷积核大小:3 * 3 * 256(GPU1:128 + GPU2:128) 步长:1 数目:192 * 2 = 384
输出:13 * 13 * 192 * 2
(输出为13 * 13:15 - 3 +1 = 13 192个特征map,因为有2个GPU,所以总的特征map数量是192 * 2)
ReLu激活 -
第4层卷积:
卷积
输入:13 * 13 * 192 * 2 扩展1个像素:15 * 15 * 192 * 2
卷积核大小:3 * 3 * 192 步长:1 数目:192 * 2 = 384
输出:13 * 13 * 192 * 2
(输出为13 * 13:15 - 3 +1 = 13 192个特征map,因为有2个GPU,所以总的特征map数量是192 * 2)
ReLu激活 -
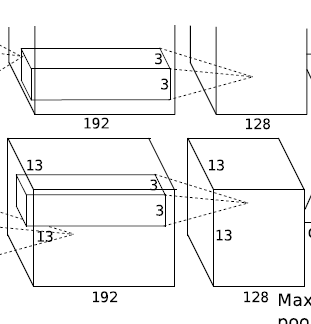
第5层卷积:
卷积
输入:13 * 13 * 192 * 2 扩展1个像素:15 * 15 * 192 * 2
卷积核大小:3 * 3 * 192 步长:1 数目:128 * 2 = 256
输出:13 * 13 * 128 * 2
(输出为13 * 13:15 - 3 +1 = 13 128个特征map,因为有2个GPU,所以总的特征map数量是128 * 2)
ReLu激活
池化层
核大小:3 * 3 * 1 步长:2
输出:6 * 6 * 128 * 2
(输出为6* 6:(13 - 3) / 2 + 1 = 6) -
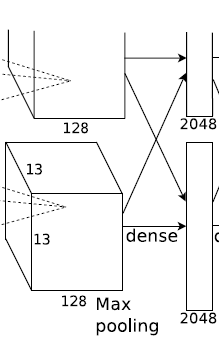
第6层全连接
输入:6 * 6 * 128 * 2
输出:2048*2个神经元
Dropout -
第7层全连接
输入:20482个神经元
输出:20482个神经元
Dropout -
第8层全连接
输入:2048*2个神经元
输出:1000个神经元

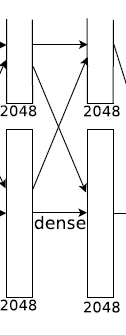
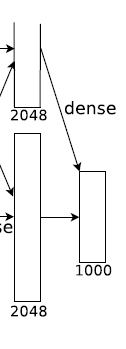
防止过拟合
增加数据
就是对图片进行装换,又很简单可以运行时在装换且在cpu上执行,作者认为这个是个free操作。
- 图像平移和翻转,具体做法:从256 * 256图片中4个角点和中心点取5个,以及它们的水平翻转 5个,一共10个图进行训练。
- 改变RGB颜色,使用PCA分解 [ p 1 , p 2 , p 3 ] [ α 1 λ 1 , α 2 λ 2 , α 3 λ 3 ] T \left[\mathbf{p}_{1}, \mathbf{p}_{2}, \mathbf{p}_{3}\right]\left[\alpha_{1} \lambda_{1}, \alpha_{2} \lambda_{2}, \alpha_{3} \lambda_{3}\right]^{T} [p1,p2,p3][α1λ1,α2λ2,α3λ3]T α \alpha α为高斯分布产生。这种方式模拟自然特性,因此可以做到光照不变性。
Dropout
这部分之前总结过:每周学习新知识1:深度学习中的Dropout
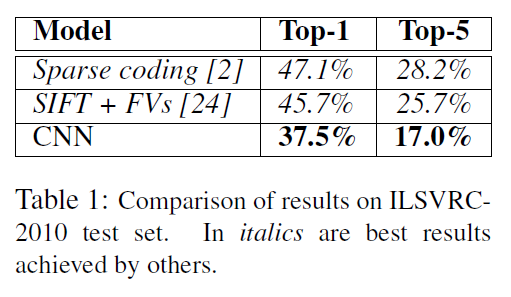
四、实验结果
五、结论与思考
作者结论
值得注意的是,如果去掉一个卷积层,我们的网络性能就会下降。例如,删除任何中间层都会导致网络的顶级性能损失约2%。所以深度对于我们取得的成果非常重要。
最后,我们希望在视频序列中使用非常大且深的卷积网络,其中时间结构提供了非常有用的信息,而这些信息在静态图像中是不存在的或不太明显的。
总结
这篇论文为后续深度学习打下了基础。
思考
深度指卷积层的深度还是全连接层的深度