1 大小端介绍
电脑存储模式
"大端"和"小端"表示多字节值的哪一端存储在该值的起始地址处;
小端存储在起始地址处,即是小端字节序;大端存储在起始地址处,即是大端字节序。
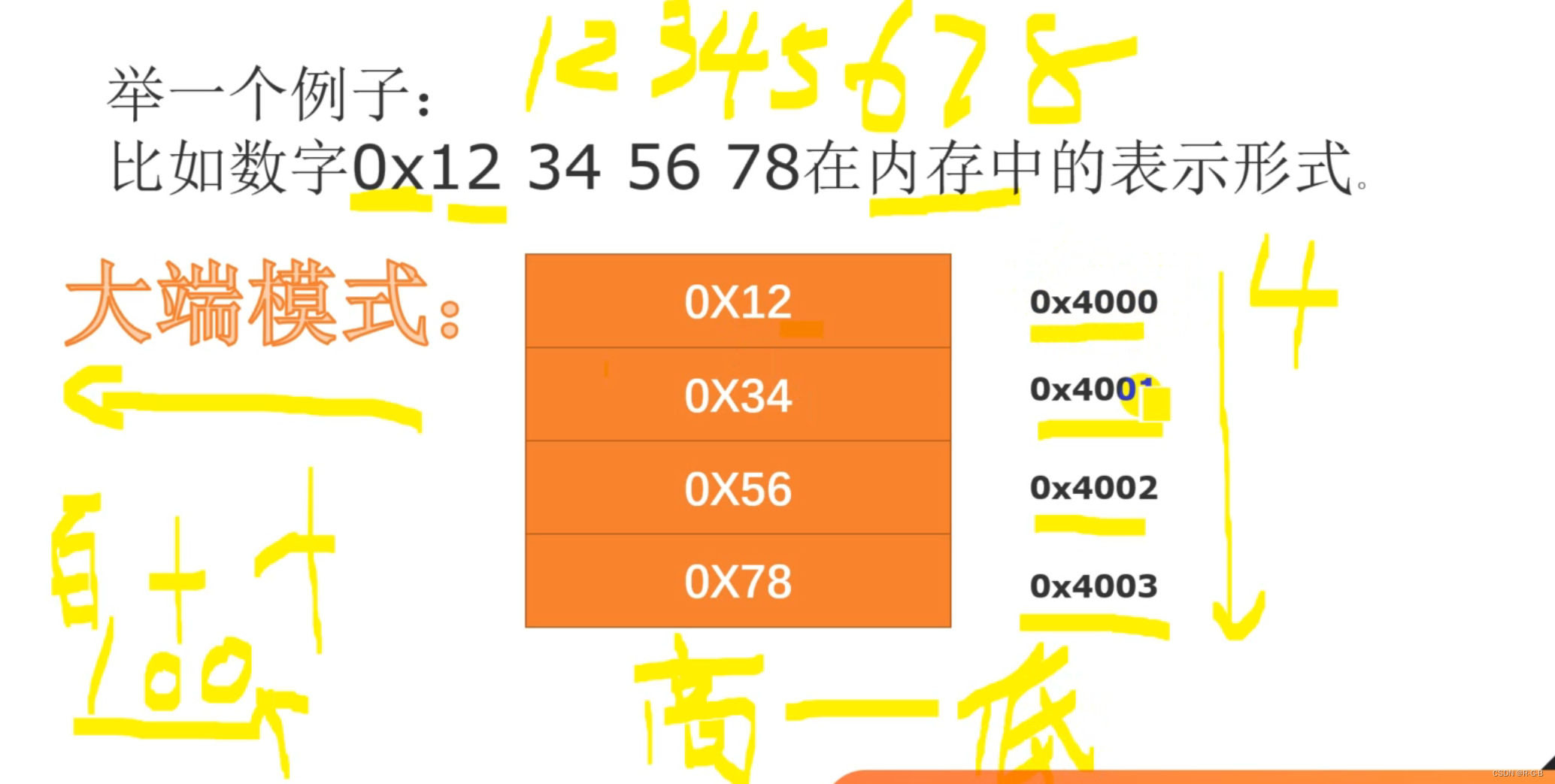
大端模式,指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,数据从高位往低位放;这和我们的阅读习惯一致。
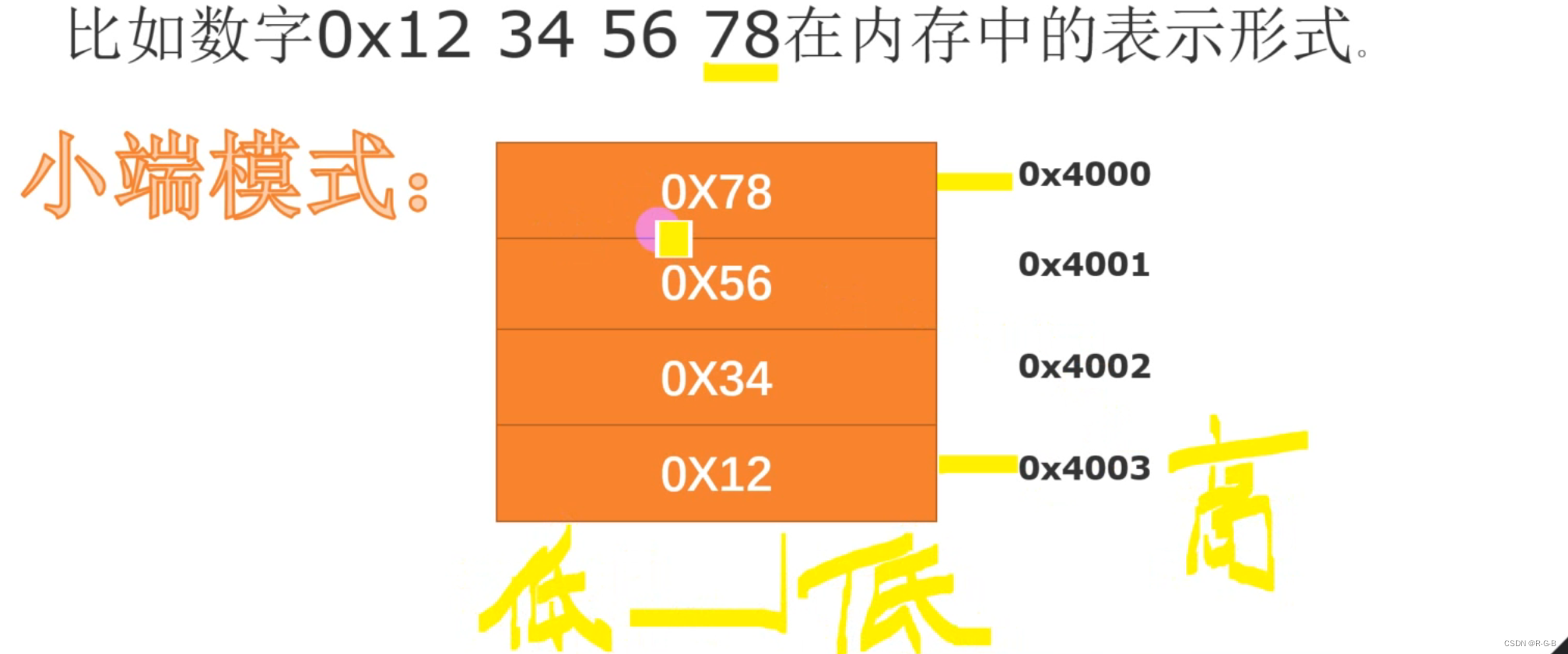
小端模式,指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
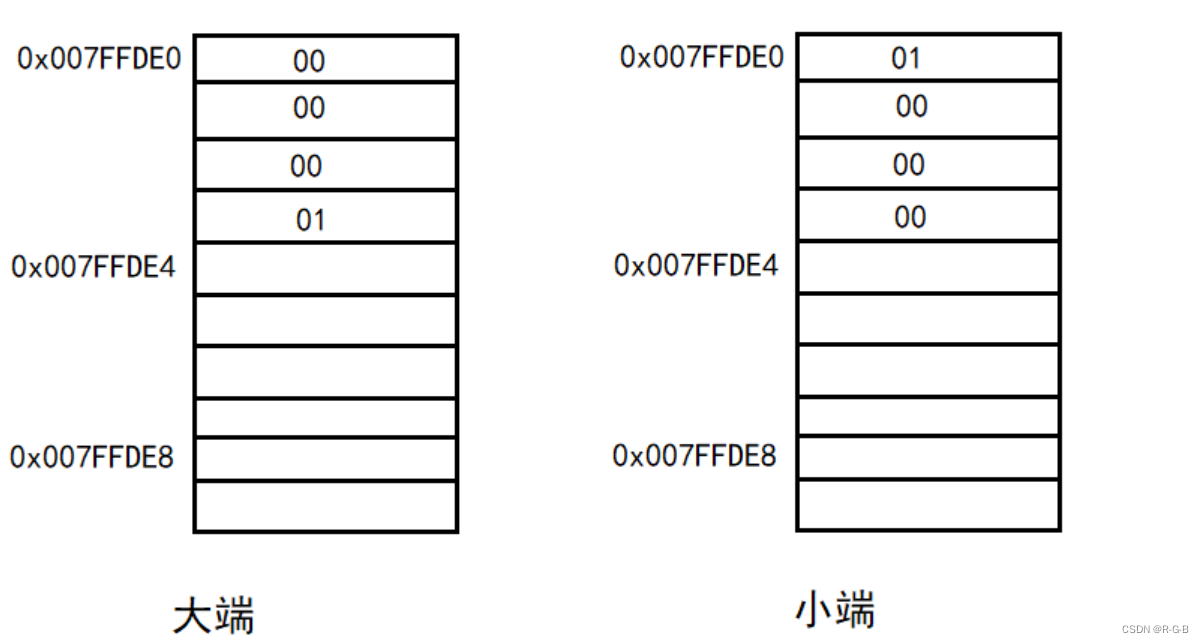
2 大小端存储举例
为什么每个内存地址存两位数据呢?
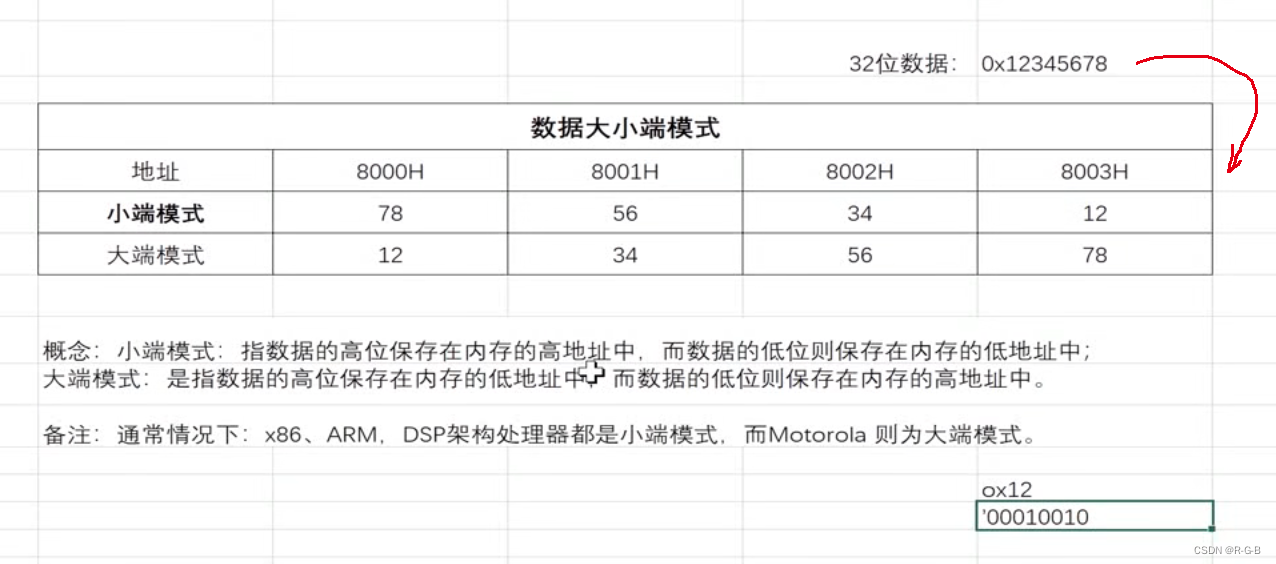
MCU最小的访问单位是字节,每两个十六进制组成一个字节。
例如:0x12 ---->0001 0010

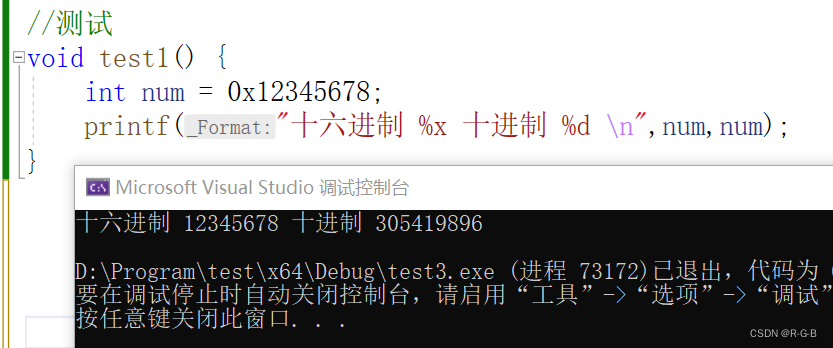
//测试
void test1() {
int num = 0x12345678;
printf("十六进制 %x 十进制 %d \n",num,num);
}
3 为什么会有大小端存储模式
3.1 cpu和编译器的不同
在计算机系统中我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit,但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题,因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。
我们常用的X86结构是小端模式,很多的ARM,DSP都为小端模式,有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。而KEIL C51则为大端模式。
3.2 网络字节序
网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节,也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题。
UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处);由此可见,多字节数值在发送之前,在内存中因该是以大端法存放的, 所以说,网络字节序是大端字节序。
比如,我们经过网络发送整型数值0x12345678时,在80X86平台中,它是以小端发存放的,在发送之前需要使用系统提供的字节序转换函数htonl()将其转换成大端法存放的数值,在进行发送。
4 如何判断cpu使大端存储还是小端存储的
方法1:类型降低
把一个占字节数大的变量赋值给一个占字节数小的变量,小的那个会将大的从起始地地址偏移小的大小个长度的数据拿过来。如果是大端,小的数据拿过来就是高位的数据,如果是小端,小的数据拿过来的就是低位的数据。
比如,short big = 0xff00;char litter = big;大端litter = 0xff,小端litter = 00。
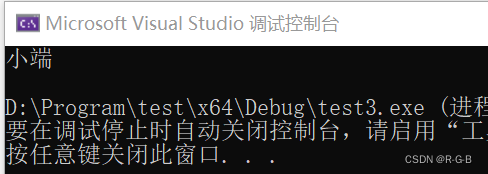
//判断大小端 方法1:类型降低
void test2() {
short big = 0xff00;
char litter = big;
if (litter == 0xff)
printf("大端\n");
else
printf("小端\n");
}
可知我的 x64,win10,是小端存储模式
方法2:使用指针,类型强转
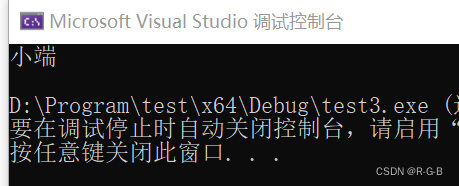
//判断大小端 方法2:使用指针,类型强转
void test3() {
short a = 0xff00;
char* b = (char*)&a;
if (*b == 0xff)
printf("大端\n");
else
printf("小端\n");
}
方法3:使用union(共用体,所有成员共用一段内存)
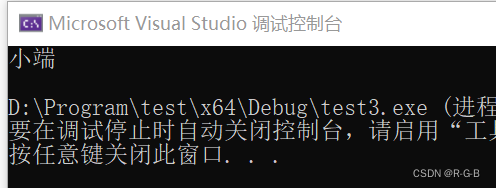
//判断大小端 方法3:使用union(共用体,所有成员共用一段内存)
union un
{
char a;
short b;
};
void test4() {
union un u;
u.b = 0xff00;
if (u.a == 0xff)
printf("大端\n");
else
printf("小端\n");
}
5 大小端使用场景
小端模式:通常情况下: x86、x64、ARM,DSP架构处理器、stm32、cc2530;
大端模式:Motorola,51单片机,网络字节序;
6 大小端模式转换
32位无符号数据为例,即4个字节.(大小端互转,通用)
方法1:char 指针,按字节替换
//大小端互转 方法2: char 指针,按字节替换:
int convert2_uint32(int n) { // 32位无符号数据为例
// 思路:将转换对象逆序赋值给,新对象
int tmp = 0x00000000; // 开辟新的 int 空间用于接收转化结果
unsigned char* p = &tmp, * q = &n;
p[0] = q[3];
p[1] = q[2];
p[2] = q[1];
p[3] = q[0];
return tmp;
}
方法2:使用移位运算,效率高
使用按位与运算保留以获取每个字节,然后按位移到正确位置并拼接:
取反 > 位移 > 按位与 > 按位异或 > 按位或
注意:&优先级 < 位移,故按位与,要加括号
//大小端互转 方法1:使用移位运算,效率高
int convert_uint32(int n) { // 32位无符号数据为例
// 思路:逆置,前面和后面每两位(一字节)互换
return (((n & 0xff000000) >> 24) | // ^ 原高8位右移24位,变低8位 --->0x000000ff
((n & 0x00ff0000) >> 8) | // ^ 原高16位右移8位,变低16位 --->0x0000ff00
((n & 0x0000ff00) << 8) | // ^ 8~16位左移8位,变了(16~24位) --->0x00ff0000
((n & 0x000000ff) << 24)); // ^ 低8位(0~8位)左移24位,变高8位(24~32位)--->0xff000000
}
这种方法效率采用了移位运算,效率很高。而且该方法亦可用于小端模式转成大端模式。
有了32位的转换方法,对64位,即8个字节的转换同理。
方法3: 使用预定义好的宏函数
本条方法参考 Basic concepts on Endianness_Juan Carlos Cobas
文中提到网络上常用的套接字接口(socket API)指定了一种称为网络字节顺序的标准字节顺序,这个顺序其实就是大端模式;而当时,同时代的 x86 系列主机反而是小端模式。
所以就促使产生了如:
ntohs() convert Network order TO Host order in Short (16 bit 大转小);
ntohl() convert Network order TO Host order in Long (32 bit 大转小);
htons() convert Host order TO Network order in Short (16 bit 小转大);
htonl() convert Host order TO Network order in Long (32 bit 小转大).
所以我们这里使用 32 bit 小转大的 htonl() 宏函数来解决这个问题。
//大小端互转 方法3: 使用预定义好的宏函数
int convert(int n) {
//头文件#include<windows.h> #pragma comment(lib,"wsock32.lib")
return htonl(n);//32 bit 小转大
}
使用socket API,需要头文件
在linux的头文件
#include <arpa/inet.h>
在windows的头文件
#include <windows.h>
#pragma comment(lib, "wsock32.lib")
来自:https://zhidao.baidu.com/question/166926781.html
(亲测,只用如下的库也可行)
#include<WinSock2.h>
#pragma comment(lib,"ws2_32.lib")