本次实验一共有三个要求,统计高频词、分析词性以及画出词云,在词性分析部分为了使结果更加直观还绘制了一个饼状图用来统计最多的十种词的占比。实验用的文本文件是实验二的爬取评论结果,为了方便便直接将实验二生成的文件拿过来使用了,在文本中有许多的非中文字符(符号、表情包、数字、字母),一开始的时候是针对这个文本专门写了一个函数除去该文本中的非中文字符,再将结果存入一个新的文本“实验文本”,此后的操作便一直使用这个文本进行,但是在做完之后觉得只能局限性太大了,于是便上网查询了一下,知道了可以用正则表达式来解决这个问题,所以便另外写了一个函数去掉文本中的个非中文字符,这个函数相对于前面一个方法就要更通用一些,至此准备工作就差不多完成了。
首先是统计高频词,在这一个部分使用了jieba库将文本切割成词,将结果存起来,这样后续的任务就可以直接调用,不用每一次都切割一遍。统计高频词的时候创建了一个字典用循环的方式来存放数据,key是词语,value则是出现次数,如果字典当中存在相应的key,则value加一,若没有则新增一个键值对,key就是没有的这个词,value设定为0。在循环结束后将字典转换为了一个列表,然后使用了sort()函数对内容进行了一个降序排序,由于词有很多,为了方便便只显示了最多的二十个词。另外就是在切割出来的结果当中,会有一些比如“的”“了”之类的词,便用了一个循环去掉所有长度为1的结果。
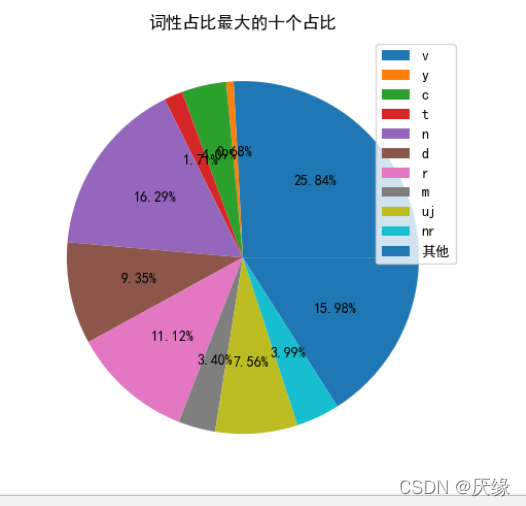
然后是分析词性,在这个部分pseg对每个词进行词性标注,然后使用统计高频词类似的方式对每个词性的词数量进行统计,根据字典的特性,一个键可以对应多个值,所以每一个词性后面都存放着该文本中这个词性所有词,于是在统计完后又新增了一个查询的功能,如果需要查询某一个词性的词的话便可以使用。在统计完后为了让结果比较直观便又新增了一个饼状图,本来还想增加条形图,但是考虑到可能会把代码弄得很乱就没有做,后续可能会在有时间的时候将代码好好整理一下继续完善,因为含有的词性也是非常的多,全部都统计出来的话饼状图的效果会非常的糟糕,密密麻麻的什么也看不行,而且由于界面大小有限,也显示不完,所以选择了统计数量最多的十种词性,剩余的就全部归为“其他”当中。
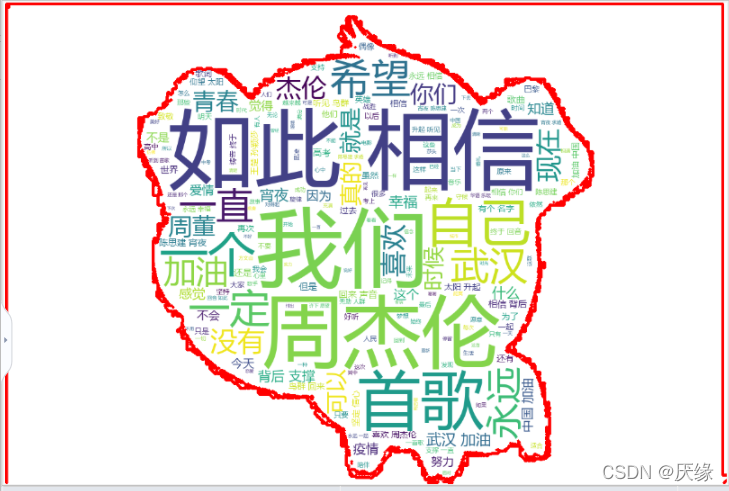
最后就是画出词云,在这个部分可以直接调用前面已经切割好的内容,但是为了让这一部分的代码更完整我选择了又切割一遍,然后创建了一个列表存入长度大于1的词,后续操作便使用这个列表进行。在制作词云的时候使用了wordcloud库,在完成了相关的参数设置后便会得到一个矩形词云,在做出来之后我想导入一个图片,将词云做出一个形状,了解过后知道了要用imread,但是我在调用的时候总是会报错,查询了很久发现可能是在版本更新的时候将一些内容更改删除了,所以才会出错,然后我便寻找其他方式,最后是使用了python自带的imageio库解决了问题,除此之外也可以使用numpy库解决问题。在使用图片做词云的时候,我发现我的编译器不能识别较复杂的图片,比如颜色很多的图片或者边框很曲折的图片,用这种图片做出来的词云效果总是不明显,于是我便找了一些简单的图片,然后用ps将其变为只有黑色和白色的样子,但是由于本人的ps技术不咋滴,毕竟是当天才下载的,所以对图案的边缘处理不是很到位,而我是给词云做了描边处理所以做出来的词云边缘看着就有一点不太好,当然也可以将边框去掉,但是我选择了保留下来。
至此本实验就差不多结束了,但是还有很多地方可以修改完善,后续如果在条件允许的情况下我会找时间完善代码和过程。
# txt = open("QQ音乐评论","r",encoding="utf-8").read()
# print(txt)
import jieba,wordcloud,re
import numpy as np
from PIL import Image
import imageio
import jieba.posseg as pseg
import matplotlib as plt
from matplotlib import pyplot
from pylab import *
from pylab import mpl
#先统计出现频率最高的前二十个词并输出
txt = open("实验文本","r",encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
#去掉长度为1的词
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
#对列表内容进行排序
items.sort(key = lambda x:x[1],reverse=True)
print("出现频率最高的20个词以及出现次数如下::")
print("词语 出现次数\n")
for i in range(20):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
txt = open("实验文本","r",encoding="utf-8").read()
words = pseg.lcut(txt)
counts = {}
for word in words:
counts[word.flag] = counts.get(word.flag,0) + 1
items = list(counts.items())
items.sort(key = lambda x:x[1],reverse=True)
print("该文本含有的词种类以及数量如下:")
for i in range(len(counts)):
flag,count = items[i]
print("{0:<10}{1:>5}".format(flag,count))
a = input("是否需要查询某种词的具体内容?(Y/N)")
while a in ['Y','y']:
b = input("请输入你要查询的词性:(输入all查看含有的词性种类)")
while b in ['all','All','ALL']:
print(counts.keys())
b = input("请输入你要查询的词性:(输入all查看含有的词性种类)")
if b in counts.keys():
for word in words:
if word.flag == b:
print(word,end=" ")
print()
b = input("是否还要继续查询?(Y/N)")
if b in ['N','n']:
break
else:
print("你的输入不正确!请重新输入!")
a = input("是否需要查询某种词的具体内容?(Y/N)")
if a in ['N','n'] or b in ['N','n']:
print("感谢使用!程序退出")
else:
print("你的输入有误!程序退出!")
#绘制饼状图
#print(words)
#name = counts.keys() # 饼状图标签
#print(name)
name = list(counts.keys())
name_list = []
for i in range(10):
name_list.append(name[i])
name_list.append("其他")
# data = counts.values() # 各项的数据,与name一一对应
data = list(counts.values())
data_list = []
other = 0
for k in range(11,len(counts)):
flag, count = items[k]
other += count
for j in range(10):
data_list.append(data[j])
data_list.append(other)
lt = [] # 建立空列表,用于存放计算结果
for i in range(len(data_list)): # 遍历data,每遍历一个数据进行一次运算
result = data_list[i] / sum(data_list)
# print(result)
lt.append(result) # 将计算结果一次添加到lt中
# print(lt)
# print(lt)
mpl.rcParams['font.sans-serif'] = ['SimHei']
plt.axes(aspect=1)
plt.pie(x=lt, autopct='%1.2f%%') # x表示饼状图的数据,autopct后面的值1.2表示保留2位小数,1.1表示保留一位小数
plt.legend(name_list, loc="best") # 绘制图的图例为name,位置为最佳
plt.title("词性占比最大的十个占比") # 饼图的名称
plt.show()
# txt = open("实验文本","r",encoding="utf-8").read()
# words = pseg.lcut(txt)
# counts = {}
# for word in words:
# counts[word.flag] = counts.get(word,0) + 1
# # print(counts)
# items = list(counts.items())
# # print(items)
# # print(items[1])
# # flag,count = items[1][0]
# # print(flag,count)
# items.sort(key = lambda x:x[1],reverse=True)
# # # print(items[1])
# # # flag,count = items[1][0]
# # # print(flag,count)
# for i in range(len(counts)):
# flag,count = items[i]
# print("{0:<10}{1:>5}".format(flag,count))
# # for word in words:
# # print(word.flag)
#定义函数去除掉文本中的非汉字字符
def find_chinese(file):
pattern = re.compile(r'[^\u4e00-\u9fa5]')
chinese = re.sub(pattern,'', file)
return chinese
#定义函数获取文件文本
def getText():
txt = open("实验文本","r",encoding="utf-8").read()
txt = find_chinese(txt)
# #除去文本中的非汉字字符
# for ch in r'●━━━━━━───────⇆◁❚❚☞▷↻「」🍺🏻💗🏆~🎶🦠🇨🇳💕🙀\
# 🦘🔥🐂😁🏅️✨🕯️🌻🍄💞✊👥👫🍃💪🙏1234567890”`~!@#$%^&*()-_=+[]{}\\|;\
# :\'\",./<>?·~!@#¥%……&*()——+-=【】{}、|;:\‘\“,。《》?qwertyuiop\
# asdfghjklzxcvbnmQAZXSWEDCVFRTGBNHYUJMKIOLP年月日':
# txt = txt.replace(ch,"")
return txt
#获取文本信息并切割
txt = getText()
txt = jieba.lcut(txt)
# print(txt)
#创建一个列表,存入长度大于1的词语
words = []
for word in txt:
if len(word) == 1:
continue
else:
words.append(word)
txt = words
# print(txt)
# #创建一个新文本,存入评论内容
# f = open("实验文本","w",encoding="utf-8")
# for item in txt:
# f.write(item)
# print(f)
# pic = imageio.imread(r"C:\Users\WP\PycharmProjects\untitled3\词云\avatar3.png",pilmode="RGB")
# pic = np.array(Image.open("avatar3.png"))
pic = imageio.imread("a4.png")
txt = " ".join(txt)
w = wordcloud.WordCloud(width = 1000, height = 700,\
background_color = "white",\
font_path = "msyh.ttc",\
mask = pic,\
contour_color="red",\
contour_width=5,\
mode="RGB")
w.generate(txt)
w.to_file("experiment.png")