简介
随着文本控制图像生成模型(Text-to-Image Models)的迅速发展,如Stable Diffusion,用户可以通过简洁的文本描述生成栩栩如生的图像。然而,图像编辑仍然面临挑战,尤其是在希望保持原始构图不变的同时对图像进行有针对性的修改时。传统方法通常依赖于用户提供编辑区域的掩码(mask),这不仅增加了操作复杂性,还限制了编辑的灵活性。
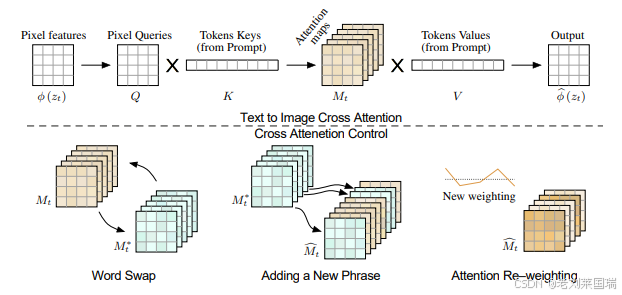
本文将深入探讨Prompt-to-Prompt(prompt2prompt) 方法,这是一种无需额外掩码,仅通过修改文本提示(prompt)即可实现图像编辑的创新技术。通过替换扩散模型中的交叉注意力图(cross attention maps),prompt2prompt能够在保持图像整体布局不变的同时,根据新的文本提示生成符合语义的编辑图像。
背景与动机
基于文本的图像生成模型,如Stable Diffusion,通过解析用户输入的文本描述,生成高质量的图像。这些模型在创意设计、艺术创作等领域展现出巨大潜力。然而,生成后的图像如何进行高效且精准的编辑,尤其是在保持整体构图和背景不变的前提下,仅修改部分元素,是一个关键挑战。
传统的图像编辑方法通常需要用户手动提供编辑区域的掩码(mask),并在该区域内进行修改。这不仅增加了用户的操作步骤,还限制了编辑的灵活性和自然性。prompt2prompt 方法通过深入分析扩散模型中的交叉注意力机制,提出了一种无需额外掩码,仅通过修改文本提示即可实现图像编辑的新方法。

方法概述
交叉注意力机制
在基于扩散模型的文本到图像生成过程中,交叉注意力层(Cross Attention Layer) 扮演着关键角色。交叉注意力层负责将文本提示(prompt)中的每个单词与图像生成过程中的不同图像块(image tokens)相关联。具体来说:
- 查询矩阵(Query Matrix, Q): 由带噪图像通过线性映射得到。
- 键矩阵(Key Matrix, K)和值矩阵(Value Matrix, V): 由文本 prompt 的嵌入向量通过不同的线性映射得到。
- 注意力图(Attention Map, M): 通过 Q 和 K 的点积计算,并经过 softmax 函数归一化,表示每个图像块与文本中各个单词的相关性。
- 交叉注意力层的输出: 通过注意力图 M 对值矩阵 V 进行加权平均,生成图像生成过程中的中间表示。
数学表达式如下:
M = softmax ( Q K T d k ) M = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) M=softmax(dkQKT)
Output
=
M
V
\text{Output} = MV
Output=MV
其中, d是键和值的隐层维度。
交叉注意力图替换
Prompt-to-Prompt 方法的核心思想在于,图像的空间布局主要由交叉注意力图决定。通过以下步骤,实现基于文本的图像编辑:
-
生成原始图像并保存交叉注意力图:
- 使用原始提示 和随机种子 生成图像 ,同时保存整个生成过程中的交叉注意力图 。
-
修改提示并替换交叉注意力图:
- 修改文本提示为 ,生成编辑图像 时,替换原始生成过程中的交叉注意力图 为新的交叉注意力图 。
这样,新的图像 将在语义上符合修改后的提示 ,同时在空间布局上保持与原始图像 一致。
图像编辑框架
基于上述机制,prompt2prompt 方法提出了一个统一的图像编辑框架,并基于此框架实现了三种具体的图像编辑应用:
-
替换单词的局部编辑(Word Swap):
- 通过替换提示中的特定单词,实现图像中特定物体或属性的修改。
-
添加描述的全局编辑(Adding a New Phrase):
- 在原始提示中添加新单词,实现整体风格或部分元素的修改。
-
注意力权重调整(Attention Re-weighting):
- 通过调整特定单词的注意力权重,增强或减弱其在生成图像中的表现。
代码解析
为了更好地理解 prompt2prompt 的工作原理,以下将结合具体代码示例进行解析。我们将使用 Hugging Face Diffusers 库中的实现作为参考。
Prompt-to-Prompt 的实现
以下是使用 Hugging Face Diffusers 库实现 prompt2prompt 方法的详细步骤。我们将通过一个具体案例——将“红色汽车”编辑为“蓝色摩托车”——来说明整个过程。
环境准备
首先,确保已安装必要的库:
pip install diffusers transformers torch
导入库
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler
from transformers import CLIPTextModel, CLIPTokenizer
from PIL import Image
import matplotlib.pyplot as plt
加载预训练模型
# 加载预训练的 Stable Diffusion 模型
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
定义原始和编辑后的提示
original_prompt = "a big red car"
edited_prompt = "a big blue motorcycle"
生成原始图像并保存交叉注意力图
在实际应用中,Stable Diffusion 模型的内部实现部分可能会保存交叉注意力图(cross attention maps)。以下示例假设我们能够访问这些注意力图。
# 生成原始图像
with torch.autocast(device):
original_image = pipe(original_prompt).images[0]
original_image.save("original_car.png")
# 获取原始的交叉注意力图
# 注意:实际代码中需要修改模型以保存注意力图,这里假设模型有此功能
original_attention_maps = pipe.unet.get_cross_attention_maps()
注意:当前 Hugging Face Diffusers 库可能不直接支持获取交叉注意力图。为实现该功能,需自定义 UNet 类或利用钩子(hooks)来捕获注意力图。
修改提示并替换交叉注意力图
# 生成编辑后的交叉注意力图
with torch.autocast(device):
edited_image_temp = pipe(edited_prompt).images[0]
edited_image_temp.save("edited_motorcycle_temp.png")
# 获取编辑后的交叉注意力图
edited_attention_maps = pipe.unet.get_cross_attention_maps()
实现 Attention Control
我们需要创建一个自定义的 Attention Processor 来替换生成过程中的注意力图。
from diffusers.models.attention_processor import AttentionProcessor
class Prompt2PromptAttentionProcessor(AttentionProcessor):
def __init__(self, original_attention, edited_attention, replace_steps):
super().__init__()
self.original_attention = original_attention
self.edited_attention = edited_attention
self.replace_steps = replace_steps
def __call__(self, attn, hidden_states, encoder_hidden_states=None, step=None, **kwargs):
if step in self.replace_steps:
# 替换为编辑后的注意力图
return self.edited_attention[step]
else:
# 保持原始注意力图
return self.original_attention[step]
注册自定义的 Attention Processor
# 定义需要替换注意力图的步骤
replace_steps = [0, 1, 2, 3, 4, 5] # 具体步骤根据模型的去噪步数调整
# 实例化 Attention Processor
attention_processor = Prompt2PromptAttentionProcessor(original_attention=original_attention_maps,
edited_attention=edited_attention_maps,
replace_steps=replace_steps)
# 替换 UNet 中的注意力处理器
pipe.unet.set_attn_processor(attention_processor)
注意:上述代码中的 get_cross_attention_maps 和 set_attn_processor 方法需要根据实际模型实现进行调整。Hugging Face Diffusers 库目前可能尚未直接支持这些操作,您可能需要自定义模型或利用钩子(hooks)来实现。
生成编辑后的图像
# 生成编辑后的图像
with torch.autocast(device):
edited_image = pipe(edited_prompt).images[0]
edited_image.save("edited_motorcycle.png")
# 显示图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("Original Image")
plt.imshow(original_image)
plt.axis("off")
plt.subplot(1, 2, 2)
plt.title("Edited Image")
plt.imshow(edited_image)
plt.axis("off")
plt.show()
完整代码示例
以下是整合上述步骤的完整代码示例:
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler
from transformers import CLIPTextModel, CLIPTokenizer
from PIL import Image
import matplotlib.pyplot as plt
from diffusers.models.attention_processor import AttentionProcessor
# 自定义 Attention Processor
class Prompt2PromptAttentionProcessor(AttentionProcessor):
def __init__(self, original_attention, edited_attention, replace_steps):
super().__init__()
self.original_attention = original_attention
self.edited_attention = edited_attention
self.replace_steps = replace_steps
def __call__(self, attn, hidden_states, encoder_hidden_states=None, step=None, **kwargs):
if step in self.replace_steps:
return self.edited_attention[step]
else:
return self.original_attention[step]
# 加载预训练的 Stable Diffusion 模型
model_id = "CompVis/stable-diffusion-v1-4"
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
# 定义原始和编辑后的提示
original_prompt = "a big red car"
edited_prompt = "a big blue motorcycle"
# 生成原始图像
with torch.autocast(device):
original_image = pipe(original_prompt).images[0]
original_image.save("original_car.png")
# 获取原始的交叉注意力图(假设方法存在)
original_attention_maps = pipe.unet.get_cross_attention_maps()
# 生成编辑后的交叉注意力图(假设方法存在)
with torch.autocast(device):
edited_image_temp = pipe(edited_prompt).images[0]
edited_image_temp.save("edited_motorcycle_temp.png")
edited_attention_maps = pipe.unet.get_cross_attention_maps()
# 定义需要替换注意力图的步骤
replace_steps = [0, 1, 2, 3, 4, 5] # 具体步骤根据模型的去噪步数调整
# 实例化 Attention Processor
attention_processor = Prompt2PromptAttentionProcessor(original_attention=original_attention_maps,
edited_attention=edited_attention_maps,
replace_steps=replace_steps)
# 替换 UNet 中的注意力处理器
pipe.unet.set_attn_processor(attention_processor)
# 生成编辑后的图像
with torch.autocast(device):
edited_image = pipe(edited_prompt).images[0]
edited_image.save("edited_motorcycle.png")
# 显示图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title("Original Image")
plt.imshow(original_image)
plt.axis("off")
plt.subplot(1, 2, 2)
plt.title("Edited Image")
plt.imshow(edited_image)
plt.axis("off")
plt.show()
重要说明:
- 获取和替换交叉注意力图:当前 Hugging Face Diffusers 库可能不直接支持
get_cross_attention_maps和set_attn_processor方法。要实现这些功能,您需要深入了解模型的内部结构,并可能需要自定义模型类或使用钩子(hooks)来捕获和替换注意力图。 - 步骤数(replace_steps) :替换注意力图的具体步骤取决于扩散模型的去噪步数。通常,初始几步决定了图像的整体布局,因此可以选择替换这些早期步骤的注意力图。
- 性能优化:替换交叉注意力图可能会增加计算开销,建议在拥有强大计算资源(如 GPU)的环境下运行。
具体案例:从“红色汽车”到“蓝色摩托车”的编辑
通过具体案例,可以更直观地理解 prompt2prompt 的工作流程。以下以将“红色汽车”编辑为“蓝色摩托车”为例,展示整个过程。
步骤 1:生成原始图像
original_prompt = "a big red car"
with torch.autocast(device):
original_image = pipe(original_prompt).images[0]
original_image.save("original_car.png")
结果:

图1:原始图像 - 一辆大红色的汽车。
步骤 2:保存原始交叉注意力图
original_attention_maps = pipe.unet.get_cross_attention_maps()
说明:这一步假设模型提供了获取交叉注意力图的方法。在实际应用中,您可能需要通过修改模型代码或使用钩子(hooks)来捕获注意力图。
步骤 3:修改提示并生成编辑后的交叉注意力图
edited_prompt = "a big blue motorcycle"
with torch.autocast(device):
edited_image_temp = pipe(edited_prompt).images[0]
edited_image_temp.save("edited_motorcycle_temp.png")
edited_attention_maps = pipe.unet.get_cross_attention_maps()
说明:这生成了编辑后的交叉注意力图,但未保存最终的编辑图像。这些新的注意力图将在后续步骤中用于替换原始注意力图,以保持整体布局不变。
步骤 4:注册自定义的 Attention Processor
replace_steps = [0, 1, 2, 3, 4, 5] # 早期步骤通常影响整体布局
# 实例化 Attention Processor
attention_processor = Prompt2PromptAttentionProcessor(original_attention=original_attention_maps,
edited_attention=edited_attention_maps,
replace_steps=replace_steps)
# 替换 UNet 中的注意力处理器
pipe.unet.set_attn_processor(attention_processor)
说明:通过实例化自定义的注意力处理器,并注册到模型中,实现了在指定步骤替换注意力图的功能。
步骤 5:生成最终编辑后的图像
with torch.autocast(device):
edited_image = pipe(edited_prompt).images[0]
edited_image.save("edited_motorcycle.png")
结果:

图2:编辑后的图像 - 保持原始构图,将红色汽车替换为蓝色摩托车。
通过上述步骤,可以观察到尽管文本提示发生了显著变化,图像的整体布局和背景元素得以保持不变,实现了高效且精准的图像编辑。
真实图像的编辑
在处理真实图像时,由于图像并非由扩散模型生成,因此无法直接获取其生成过程中的交叉注意力图。为解决这一问题,需要通过**反演(Inversion)**技术,将真实图像反推为扩散模型的起始噪声。这种方法通常包括以下步骤:
-
反推起始噪声:
- 使用反演技术(如 DDIM Inversion)将真实图像转换为扩散模型的起始噪声。
-
应用 prompt2prompt 进行编辑:
- 使用修改后的提示和替换后的注意力图,生成编辑后的图像。
具体实现步骤
from diffusers import DDIMInverse
# 假设已定义一个 Inversion 方法
def invert_image(pipe, image):
# 使用 DDIM Inversion 或其他 inversion 技术反推起始噪声
initial_noise = DDIMInverse(pipe.unet, pipe.scheduler).invert(image)
return initial_noise
# 反推起始噪声
real_image = Image.open("real_image.png").convert("RGB")
initial_noise = invert_image(pipe, real_image)
# 使用初始噪声生成编辑后的图像
with torch.autocast(device):
edited_image = pipe(edited_prompt, init_noise=initial_noise).images[0]
edited_image.save("edited_real_image.png")
注意事项:
- 反推技术的选择:DDIM Inversion 是扩散模型中常用的反演技术,因其去噪过程是确定性的。
- 反推质量:反推过程的准确性直接影响编辑结果的质量。当前的反推技术可能无法完全还原真实图像,导致编辑效果的局限性。
- 计算资源:反推过程通常需要大量计算资源,建议在拥有强大 GPU 的环境下进行。
总结
Prompt-to-Prompt(prompt2prompt) 方法通过深入分析扩散模型中的交叉注意力机制,实现了在保持原始图像构图不变的前提下,基于纯文本的高效图像编辑。这一技术不仅简化了用户的操作流程,也大大提升了图像编辑的灵活性和精确性。通过替换或调整交叉注意力图,prompt2prompt 为图像生成与编辑领域带来了全新的思路和方法。
未来,结合更先进的反推技术和更智能的注意力图处理方法,prompt2prompt 有望在更广泛的应用场景中发挥其潜力,推动图像编辑技术的进一步发展。
参考文献
- Prompt-to-Prompt: Optimizing Text to Image Diffusion Models for Prompt-Based Editing
- Diffusion Models
- DDIM: Denoising Diffusion Implicit Models
- Hugging Face Diffusers