Ansible的安装与配置
1. 安装ansible
# ansible是epel源提供的,所以必须安装epel:
[root@Rocky9 ~]# yum -y install epel-release
Last metadata expiration check: 0:01:53 ago on Tue 26 Dec 2023 10:05:34 PM CST.
Dependencies resolved.
============================================================================================================================================================================================
Package Architecture Version Repository Size
============================================================================================================================================================================================
Installing:
epel-release noarch 9-7.el9 extras 19 k
Transaction Summary
============================================================================================================================================================================================
Install 1 Package
Total download size: 19 k
Installed size: 26 k
Downloading Packages:
epel-release-9-7.el9.noarch.rpm 158 kB/s | 19 kB 00:00
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Total 21 kB/s | 19 kB 00:00
Rocky Linux 9 - Extras 1.7 MB/s | 1.7 kB 00:00
Importing GPG key 0x350D275D:
Userid : "Rocky Enterprise Software Foundation - Release key 2022 <[email protected]>"
Fingerprint: 21CB 256A E16F C54C 6E65 2949 702D 426D 350D 275D
From : /etc/pki/rpm-gpg/RPM-GPG-KEY-Rocky-9
Key imported successfully
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Installing : epel-release-9-7.el9.noarch 1/1
Running scriptlet: epel-release-9-7.el9.noarch 1/1
Many EPEL packages require the CodeReady Builder (CRB) repository.
It is recommended that you run /usr/bin/crb enable to enable the CRB repository.
Verifying : epel-release-9-7.el9.noarch 1/1
Installed:
epel-release-9-7.el9.noarch
Complete!
[root@Rocky9 ~]#
# 查看ansible的信息
# Ansible Core (ansible-core): 这是 Ansible 的基础框架,包含了执行自动化脚本所需的核心功能,如任务执行引擎、模块库和插件。ansible-core 提供了 Ansible 自动化平台的基本能力,但不包括额外的模块和插件。
[root@Rocky9 ~]# dnf info ansible-core
Extra Packages for Enterprise Linux 9 - x86_64 8.3 MB/s | 20 MB 00:02
Extra Packages for Enterprise Linux 9 openh264 (From Cisco) - x86_64 1.4 kB/s | 2.5 kB 00:01
Available Packages
Name : ansible-core
Epoch : 1
Version : 2.14.9
Release : 1.el9
Architecture : x86_64
Size : 2.2 M
Source : ansible-core-2.14.9-1.el9.src.rpm
Repository : appstream
Summary : SSH-based configuration management, deployment, and task execution system
URL : http://ansible.com
License : GPLv3+
Description : Ansible is a radically simple model-driven configuration management,
: multi-node deployment, and remote task execution system. Ansible works
: over SSH and does not require any software or daemons to be installed
: on remote nodes. Extension modules can be written in any language and
: are transferred to managed machines automatically.
[root@Rocky9 ~]
# Ansible (ansible): 这是一个更完整的包,包括了 ansible-core 和一套丰富的模块与插件,这些模块和插件用于执行更复杂的自动化任务。ansible 包适用于需要广泛自动化功能的用户,因为它提供了额外的功能和更广泛的社区支持。
[root@Rocky9 ~]# dnf info ansible
Last metadata expiration check: 0:00:05 ago on Tue 26 Dec 2023 10:18:39 PM CST.
Available Packages
Name : ansible
Epoch : 1
Version : 7.7.0
Release : 1.el9
Architecture : noarch
Size : 34 M
Source : ansible-7.7.0-1.el9.src.rpm
Repository : epel
Summary : Curated set of Ansible collections included in addition to ansible-core
URL : https://ansible.com
License : GPL-3.0-or-later AND Apache-2.0 AND BSD-2-Clause AND BSD-3-Clause AND MIT AND MPL-2.0 AND PSF-2.0
Description : Ansible is a radically simple model-driven configuration management,
: multi-node deployment, and remote task execution system. Ansible works
: over SSH and does not require any software or daemons to be installed
: on remote nodes. Extension modules can be written in any language and
: are transferred to managed machines automatically.
:
: This package provides a curated set of Ansible collections included in addition
: to ansible-core.
[root@Rocky9 ~]#
# 用 dnf info 命令查看这两个包时,你会注意到它们的描述和依赖项不同。ansible-core 通常体积更小,依赖项更少,而 ansible 包含了更多的功能和组件。
# 在最近的 Ansible 版本中,开发者决定将核心部分(ansible-core)与模块/插件集合(ansible)分开,以便于维护和提供更灵活的安装选项。用户可以选择只安装核心功能,或者安装完整的 Ansible 套件,具体取决于他们的需求。
# 安装ansible
[root@rocky9 ~]#yum -y install ansible
[root@rocky9 ~]#ansible --version
ansible [core 2.14.9]
2. 生成ansible.cfg文件内容
#在一些新版本的 Ansible 中,ansible.cfg 文件默认为空。通过下面命令生成这个文件的内容:
ansible-config init --disabled > /etc/ansible/ansible.cfg
或者
ansible-config init --disabled -t all > /etc/ansible/ansible.cfg
# CentOS 7上ansible.cfg默认有内容
#inventory = /etc/ansible/hosts # 默认主机列表配置文件
#library = /usr/share/my_modules/ # 库文件存放目录
#module_utils = /usr/share/my_module_utils/
#remote_tmp = ~/.ansible/tmp # 临时py文件存放在远程主机目录
#local_tmp = ~/.ansible/tmp # 本机的临时执行目录
#plugin_filters_cfg = /etc/ansible/plugin_filters.yml
#forks = 5 # 默认并发数
#poll_interval = 15
#sudo_user = root # 默认sudo用户
#ask_sudo_pass = True # 每次执行是否询问sudo的ssh密码
#ask_pass = True # 每次执行是否询问ssh密码
#transport = smart
#remote_port = 22 # 远程主机端口
#module_lang = C
#module_set_locale = False
[root@ansible ansible]# ansible --version
ansible 2.9.27
3. 配置主机清单文件 Inventory
/etc/ansible/ansible.cfg 主配置文件
/etc/ansible/hosts 主机清单
/etc/ansible/roles/ 存放角色的目录
# CentOS 7 配置方式ssh密码方式
[web01]
10.0.0.103 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass=root
# 这里如果写成password就会报错
# Rocky 9/8 配置方式 两种方式均可
[web01]
10.0.0.103 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_password=root
10.0.0.107 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass=root
# Inventory参数说明
ansible_ssh_host #将要连接的远程主机名.与你想要设定的主机的别名不同的话,可通过此变量设置.
ansible_ssh_port #ssh端口号.如果不是默认的端口号,通过此变量设置.这种可以使用 ip:端口
192.168.1.100:2222
ansible_ssh_user #默认的 ssh 用户名
ansible_ssh_pass #ssh 密码(这种方式并不安全,我们强烈建议使用 --ask-pass 或 SSH 密钥)
ansible_sudo_pass #sudo 密码(这种方式并不安全,我们强烈建议使用 --ask-sudo-pass)
ansible_sudo_exe (new in version 1.8) #sudo 命令路径(适用于1.8及以上版本)
ansible_connection #与主机的连接类型.比如:local, ssh 或者 paramiko. Ansible 1.2 以前默认使用 paramiko.1.2 以后默认使用 'smart','smart' 方式会根据是否支持 ControlPersist, 来判断'ssh' 方式是否可行.
ansible_ssh_private_key_file #ssh 使用的私钥文件.适用于有多个密钥,而你不想使用 SSH 代理的情况.
ansible_shell_type #目标系统的shell类型.默认情况下,命令的执行使用 'sh' 语法,可设置为'csh' 或 'fish'.
ansible_python_interpreter #目标主机的 python 路径.适用于的情况: 系统中有多个 Python,或者命令路径不是"/usr/bin/python",比如 \*BSD, 或者 /usr/bin/python 不是 2.X 版本的Python.之所以不使用 "/usr/bin/env" 机制,因为这要求远程用户的路径设置正确,且要求 "python"可执行程序名不可为 python以外的名字(实际有可能名为python26).与
ansible_python_interpreter 的工作方式相同,可设定如 ruby 或 perl 的路径....
ansible主配置文件
Ansible 的配置文件可以放在多个不同地方,优先级从高到低顺序如下:
ANSIBLE_CONFIG #环境变量,注意:指定目录下的ansible.cfg文件必须存在才能生效
./ansible.cfg #当前目录下的ansible.cfg,一般一个项目对应一个专用配置文件,推荐使用
~/.ansible.cfg #当前用户家目录下的.ansible.cfg
/etc/ansible/ansible.cfg #系统默认配置文件
4. ansible命令用法
格式:
ansible <host-pattern> [-m module_name] [-a args]
选项说明:
-h, --help: 显示帮助信息。
--version: 显示程序版本号、配置文件位置、配置的模块搜索路径、模块位置、可执行文件位置并退出。
-v, --verbose: 增加详细输出级别,可通过多次使用(例如 -vvv)来增加详细程度。
-b, --become: 使用特权提升执行操作(默认不提示密码)。
--become-method BECOME_METHOD: 指定特权提升使用的方法(默认为 sudo)。
--become-user BECOME_USER: 指定执行操作时的目标用户(默认为 root)。
-K, --become-password-file BECOME_PASSWORD_FILE: 指定特权提升密码文件。
-i INVENTORY, --inventory INVENTORY, --inventory-file INVENTORY: 指定清单文件的路径或主机列表。--inventory-file 是旧用法,不推荐使用。
--list-hosts: 输出匹配的主机列表,不执行任何其他操作。
-l SUBSET, --limit SUBSET: 进一步限制选择的主机范围。
-P POLL_INTERVAL, --poll POLL_INTERVAL: 设置轮询间隔,用于异步任务。
-B SECONDS, --background SECONDS: 异步运行任务,超过指定秒数后认为失败(默认不使用)。
-o, --one-line: 将输出压缩为一行。
-t TREE, --tree TREE: 将输出记录到指定目录的树结构中。
--private-key PRIVATE_KEY_FILE, --key-file PRIVATE_KEY_FILE: 使用指定的私钥文件进行身份验证。
-u REMOTE_USER, --user REMOTE_USER: 指定远程连接时使用的用户。
-c CONNECTION, --connection CONNECTION: 指定连接类型(默认为 smart)。
-T TIMEOUT, --timeout TIMEOUT: 覆盖连接超时时间(秒,默认为 10)。
--ssh-common-args SSH_COMMON_ARGS: 指定传递给 sftp/scp/ssh 的共用参数。
--sftp-extra-args SFTP_EXTRA_ARGS: 指定额外传递给 sftp 的参数。
--scp-extra-args SCP_EXTRA_ARGS: 指定额外传递给 scp 的参数。
--ssh-extra-args SSH_EXTRA_ARGS: 指定额外传递给 ssh 的参数。
-k, --ask-pass: 执行连接时询问密码。
-C, --check: 以检查模式运行,不做任何更改,尝试预测可能发生的变化。
-D, --diff: 显示更改的小文件和模板的差异,与 --check 模式搭配效果佳。
-e EXTRA_VARS, --extra-vars EXTRA_VARS: 设置额外变量,可以是 key=value 或 YAML/JSON,如果是文件则使用 @ 符号。
--vault-id VAULT_IDS: 指定使用的 vault 身份。
--ask-vault-password, --ask-vault-pass: 在执行时询问 vault 密码。
--vault-password-file VAULT_PASSWORD_FILES, --vault-pass-file VAULT_PASSWORD_FILES: 指定 vault 密码文件。
-f FORKS, --forks FORKS: 指定并行进程数(默认为 5)。
-M MODULE_PATH, --module-path MODULE_PATH: 为模块库指定额外的路径(默认为 {{ ANSIBLE_HOME }}/plugins/modules:/usr/share/ansible/plugins/modules)。
--playbook-dir BASEDIR: 由于此工具不使用 playbook,使用此作为替代 playbook 目录。
--task-timeout TASK_TIMEOUT: 设置任务超时限制(秒)。
-a MODULE_ARGS, --args MODULE_ARGS: 以空格分隔的 k=v 格式或 JSON 字符串指定操作的选项。
-m MODULE_NAME, --module-name MODULE_NAME: 指定要执行的模块名称(默认为 command)。
# 运行控制和管理选项
-B SECONDS, --background SECONDS: 在后台异步执行操作的时间(以秒为单位)。指定这个选项后,命令会立即返回,不等待任务完成。如果设置的时间过后任务还没有完成,任务会被视为失败。这对于需要长时间运行的任务非常有用。
-P POLL_INTERVAL, --poll POLL_INTERVAL: 当使用 -B 选项启动异步任务时,这个选项允许你设置 Ansible 轮询任务状态的时间间隔(以秒为单位)。默认为 15 秒。这是控制异步任务检查频率的重要参数。
-o, --one-line: 简化输出信息,使每个输出项只占一行。这在输出简洁性非常重要时非常有用,可以更容易地解析输出。
-t TREE, --tree TREE: 将输出日志以目录树形式保存到指定的目录。这对于后续分析或记录执行结果非常有用,特别是在进行大规模操作时。
# SSH 连接选项
--private-key PRIVATE_KEY_FILE, --key-file PRIVATE_KEY_FILE: 使用指定的私钥文件进行 SSH 连接。这个选项非常重要,尤其是在使用非默认私钥进行远程连接时。
--ssh-common-args SSH_COMMON_ARGS: 设置在调用 sftp、scp 或 ssh 时传递的通用参数。例如,你可以通过这个选项设置 SSH 代理。
--sftp-extra-args SFTP_EXTRA_ARGS: 设置只传递给 sftp 的额外参数。这对于调整 sftp 命令行行为特别有用。
--scp-extra-args SCP_EXTRA_ARGS: 设置只传递给 scp 的额外参数。这可以用来调整文件传输过程中 scp 的行为。
--ssh-extra-args SSH_EXTRA_ARGS: 设置只传递给 ssh 的额外参数。这可以用来调整 SSH 连接过程中的特定行为,如端口转发。
# 安全和权限管理
-k, --ask-pass: 运行 ansible 时提示输入 SSH 密码。这对于不使用 SSH 密钥认证的环境非常有用。
-K, --ask-become-pass: 在执行需要特权提升的操作时提示输入密码。这对于 sudo 或其他特权提升方法需要密码的情况下非常必要。
# 变更检查和输出差异
-C, --check: 运行 ansible 以预测可能的变更,而不实际应用变更。这常用于生产环境前的预测试,以确保变更符合预期,不会产生意外效果。
-D, --diff: 当执行变更时,显示文件变更前后的差异。这个选项在更新配置文件或模板时非常有用,可以直观地看到哪些部分被修改。
# 环境和配置
-e EXTRA_VARS, --extra-vars EXTRA_VARS: 设置额外的变量,可以是键值对或 YAML/JSON 格式。如果提供的是文件,需要用 @ 符号作为前缀。这允许在命令行动态传递变量,非常适合临时调整或覆盖 playbook 中的变量。
--vault-id VAULT_IDS: 指定使用的 Ansible Vault 身份。这对于解密被 Vault 加密的数据非常重要。
--ask-vault-password, --ask-vault-pass: 在执行操作前提示输入 Ansible Vault 的密码。这确保了对加密数据的安全访问。
--vault-password-file VAULT_PASSWORD_FILES, --vault-pass-file VAULT_PASSWORD_FILES: 通过文件指定 Vault 密码。这对于自动化脚本非常有用,因为它避免了交互式输入密码。
5. 常用模块
Ansible 包含大量的模块,用于实现各种自动化任务。下面列出了一些最常用的模块,以及它们的基本选项和用法:
1. Command 模块
- 用途:执行单个命令。
- 选项:
cmd: 要执行的命令。chdir: 在指定目录下执行命令。creates: 如果指定文件已存在,则不执行命令。removes: 如果指定文件不存在,则不执行命令。
- 示例:
- name: Execute a command command: ls -l /var/log
2. Shell 模块
- 用途:在远程系统的shell中执行命令,支持使用管道和重定向等shell特性。
- 选项:
cmd: 要执行的命令。chdir: 在指定目录下执行命令。
- 示例:
- name: Execute shell commands shell: cat /tmp/test.txt | grep test
3. Copy 模块
- 用途:将本地文件复制到远程主机。
- 选项:
src: 本地源文件路径。dest: 远程目标路径。owner: 文件的所有者。group: 文件的组。mode: 文件的权限模式。backup: 在覆盖之前备份原文件。
- 示例:
- name: Copy file with owner and permissions copy: src: /src/dir/file.conf dest: /dest/dir/file.conf owner: root group: root mode: '0644'
4. File 模块
- 用途:设置文件的属性或创建链接。
- 选项:
path: 文件的路径。state: 文件的状态(如file,link,directory,absent)。owner: 文件的所有者。group: 文件的组。mode: 文件的权限模式。
- 示例:
- name: Ensure directory exists file: path: /some/directory state: directory mode: '0755'
5. User 模块
- 用途:管理用户账户。
- 选项:
name: 用户名。state: 确定是否应该创建(present)或删除(absent)用户。uid: 用户ID。group: 主要的用户组。groups: 用户所属的其他组。
- 示例:
- name: Add a user user: name: username state: present group: users groups: wheel,admin
6. Yum 模块
- 用途:在基于 RPM 的系统上使用 Yum 包管理器管理包。
- 选项:
name: 软件包名。state: 状态(present,absent,latest)。
- 示例:
- name: Install the latest version of nginx yum: name: nginx state: latest
7. Apt 模块
- 用途:在基于 Debian 的系统上使用 Apt 包管理器管理包。
- 选项:
name: 软件包名。state: 状态(present,absent,latest)。
- 示例:
- name: Install nginx apt: name: nginx state: present
这些只是 Ansible 支持的模块中的一小部分,Ansible 提供了广泛的模块,支持从简单的文件传输到复杂的系统配置任务。每个模块都有其特定的参数和选项,用于控制其行为。您
可以通过查阅 Ansible 官方文档获取更多模块的详细信息和使用方法。
当然,Ansible 提供了许多其他模块,用于处理各种不同的自动化任务。除了上文提及的一些基础模块之外,还有许多专门用于特定技术或环境的模块。以下是其他一些常用的 Ansible 模块及其用法:
8. Service 模块
- 用途:管理系统服务。
- 选项:
name: 服务名称。state: 服务状态,如started,stopped,restarted,reloaded。enabled: 是否应该在启动时启动服务。
- 示例:
- name: Ensure nginx is running service: name: nginx state: started enabled: yes
9. Template 模块
- 用途:基于 Jinja2 模板生成文件,并将其复制到远程系统。
- 选项:
src: 模板文件的本地路径。dest: 远程系统上生成文件的路径。
- 示例:
- name: Configure nginx template: src: /templates/nginx.conf.j2 dest: /etc/nginx/nginx.conf
10. Git 模块
- 用途:在远程主机上克隆或管理 git 仓库。
- 选项:
repo: 仓库的 URL。dest: 克隆仓库到远程主机的路径。version: 仓库的版本(分支、标签或提交)。
- 示例:
- name: Check out a GitHub repository git: repo: 'https://github.com/example/repo.git' dest: /srv/repo version: master
11. Ansible.builtin.set_fact 模块
- 用途:在 play 运行期间设置或更新变量。
- 选项:
key: 变量名称。value: 变量的值。
- 示例:
- name: Set a dynamic variable set_fact: my_variable: "value"
12. Fetch 模块
- 用途:从远程系统抓取文件到控制节点。
- 选项:
src: 远程文件的路径。dest: 控制节点上存储文件的路径。flat: 是否省略远程主机的文件路径。
- 示例:
- name: Fetch a file from remote nodes fetch: src: /var/log/nginx/access.log dest: /local/path/ flat: yes
这些模块仅仅是 Ansible 功能丰富生态系统中的一部分。不同模块适用于不同的场景,如配置管理、资源监控、代码部署等。你可以根据需要选择合适的模块来构建强大且高效的自动化解决方案。对于更特定的用途,Ansible 社区和第三方开发者还提供了大量的自定义模块。通过阅读 Ansible 文档,你可以深入了解这些模块及其用法。
继续探讨 Ansible 的其他常用模块,它们在自动化任务中同样扮演着重要的角色。这些模块可以帮助你管理文件、监测系统状态、修改文件内容等多种操作。以下是你提及的一些模块的详细说明:
13. Unarchive 模块
- 用途:从文件或URL解压缩文件到远程主机。
- 选项:
src: 要解压的文件的本地路径或URL。dest: 解压到远程主机上的目标路径。remote_src: 指定src是在远程主机上(yes)还是在控制节点上(no)。
- 示例:
- name: Extract a tarball to a target path unarchive: src: /local/path/foo.tar.gz dest: /remote/path remote_src: no
14. Group 模块
- 用途:管理远程主机上的用户组。
- 选项:
name: 用户组名。state: 指定用户组是应该存在(present)还是删除(absent)。gid: 用户组ID。
- 示例:
- name: Ensure a group exists group: name: mygroup state: present
15. Stat 模块
- 用途:检索文件或文件系统状态信息。
- 选项:
path: 要检查的文件或目录的路径。
- 示例:
- name: Get stat of a file stat: path: /path/to/file register: result - debug: msg: "The file was last modified at {{ result.stat.mtime }}"
16. Debug 模块
- 用途:打印消息或变量到输出。
- 选项:
msg: 要打印的消息。var: 要打印的变量。
- 示例:
- name: Print debug message debug: msg: "This is a debug message"
17. Lineinfile 模块
- 用途:确保文件中包含某一特定行,或确保某行不存在。
- 选项:
path: 文件的路径。line: 文件应该包含的行内容。state:present(默认)确保行存在,absent确保行不存在。
- 示例:
- name: Ensure line is in the file lineinfile: path: /path/to/file line: 'ENABLED=1' state: present
18. Replace 模块
- 用途:在整个文件中替换匹配的字符串或正则表达式。
- 选项:
path: 文件路径。regexp: 要匹配的正则表达式。replace: 替换字符串。
- 示例:
- name: Replace a text in file replace: path: /path/to/file regexp: 'foo' replace: 'bar'
这些模块涵盖了文件操作、信息获取、系统配置、文本处理等多种常见的自动化需求。通过灵活使用这些模块,你可以构建出强大而复杂的 Ansible playbook 来管理和自动化你的 IT 环境。每个模块都有其独特的选项和用法,了解和掌握这些可以大大提升你的自动化能力。
继续介绍 Ansible 中的其他常用模块,这些模块覆盖了从网络操作到系统配置的各种功能。这些模块可以帮助你自动化各种常见的系统管理任务。
19. get_url 模块
- 用途:从指定的 URL 下载文件到远程节点。
- 选项:
url: 要下载的文件的 URL。dest: 文件保存到远程系统的路径。checksum: 文件的校验和(可选),用于验证文件完整性。
- 示例:
- name: Download a file get_url: url: http://example.com/example.tar.gz dest: /tmp/example.tar.gz checksum: sha256:abcdef123456...
20. archive 模块
- 用途:将远程主机上的多个文件或目录打包成一个压缩文件。
- 选项:
path: 要包含在归档中的文件或目录列表。dest: 归档文件将被写入的完整路径。format: 归档格式(如zip,tar,gz)。
- 示例:
- name: Create archive archive: path: /path/to/files dest: /path/to/file.tar.gz format: gz
21. hostname 模块
- 用途:管理系统的主机名。
- 选项:
name: 要设置的主机名。
- 示例:
- name: Set hostname hostname: name: new-hostname
22. cron 模块
- 用途:管理 cron 作业。
- 选项:
name: 作业描述。user: 运行作业的用户。job: 要运行的命令。state: 是否添加或移除作业。
- 示例:
- name: Ensure a cron job exists cron: name: "Backup database" user: root job: "mysqldump -u user --password=password dbname | gzip > /backup/db.gz" hour: 2 minute: 0
23. selinux 模块
- 用途:管理 SELinux 策略。
- 选项:
state: 指定 SELinux 的状态(如enforcing,permissive,disabled)。
- 示例:
- name: Set SELinux to permissive selinux: state: permissive
24. sysctl 模块
- 用途:管理内核参数。
- 选项:
name: 参数名称。value: 参数值。
- 示例:
- name: Increase file watch limit sysctl: name: fs.inotify.max_user_watches value: '524288' state: present reload: yes
25. pam_limits 模块
- 用途:管理 PAM limits 文件。
- 选项:
domain: 限制适用的用户或组。limit_type: 限制类型(如soft,hard)。limit_item: 被限制的资源(如nofile,nproc)。value: 资源的限制值。
- 示例:
- name: Set nofile limit for user pam_limits: domain: username limit_type: soft limit_item: nofile value: 1024
26. apt_repository 模块
- 用途:管理 Ubuntu/Debian 系统的 APT 仓库。
- 选项:
repo: 仓库的源。state: 仓库的状态。
- 示例:
- name: Add repository apt_repository: repo: 'ppa:nginx/stable' state: present
27. apt_key 模块
-
用途:管理 Ubuntu/Debian 系统的 APT 密钥。
-
选项
:
url: 密钥的 URL。id: 密钥的 ID。state: 密钥的状态。
-
示例:
- name: Add APT key from URL
apt_key:
url: http://example.com/key.asc
state: present
28. setup 模块
在 Ansible 中,setup 模块是用于收集目标主机的系统信息的工具,这一过程也被称为 “Gathering Facts”。默认情况下,当你执行一个 playbook 时,Ansible 会自动在开始执行任何其他任务之前运行 setup 模块,以收集并创建 ansible_facts 字典,该字典包含了关于主机的详细信息,例如网络配置、操作系统、内存信息等。
用法和选项
尽管 setup 模块通常自动执行,你也可以在 playbook 中显式地调用它,以重新收集主机信息或者在特定任务中获取最新的系统数据。
显式调用 setup 模块
如果你需要在 playbook 执行中的某个点显式地刷新或获取系统信息,可以直接使用 setup 模块。
- name: Gather facts manually
hosts: all
tasks:
- name: Collect system facts
setup:
- name: Display some facts
debug:
msg: "The operating system is {{ ansible_facts['os_family'] }} and the IP address is {{ ansible_facts['default_ipv4']['address'] }}"
在这个例子中:
setup模块被显式调用,确保收集的系统信息是最新的。- 使用
debug模块显示了一些收集到的信息。
定制 Fact 收集
setup 模块允许你定制它收集的信息类型。使用 gather_subset 选项可以限制或指定你感兴趣的信息范围,这可以减少网络负载和加快任务执行速度。
- name: Gather limited subset of facts
hosts: all
tasks:
- name: Only gather hardware and virtual related facts
setup:
gather_subset:
- hardware
- virtual
这个示例中,setup 仅收集有关硬件和虚拟化相关的信息。
过滤和额外的 Fact 收集
你还可以使用 filter 选项来进一步限制收集的信息,仅包含特定模式匹配的变量。此外,gather_timeout 选项可以用来设置收集信息的超时时间。
- name: Gather only specific facts
hosts: all
tasks:
- name: Gather only facts related to memory
setup:
filter: "ansible_*_mb"
gather_timeout: 10
在此例中,filter 选项用于仅收集以 “ansible” 开头且以 “_mb” 结尾的内存相关信息,例如 ansible_memtotal_mb 和 ansible_swapfree_mb。gather_timeout 设置了收集操作的超时时间为10秒。
ansible_:这确保只匹配以 “ansible” 开头的变量。*:这表示任意数量的任何字符。_mb:这确保只匹配以 “_mb” 结尾的变量
29. ansible.builtin.user 模块
ansible.builtin.user 模块是 Ansible 的一个核心模块,用于管理系统用户。这个模块可以添加、删除、修改系统上的用户账户,并且可以配置多个用户属性,如用户的 UID、家目录、密码、所属组等。
基本选项
name: 用户的名称(必需)。state: 用户的状态,present用于确保用户存在,absent用于确保用户不存在。uid: 用户的唯一 ID。group: 用户的主组。groups: 用户的附加组列表,用逗号分隔。append: 如果设置为yes,将只添加用户到指定的组中,不会从未指定的组中移除用户。password: 用户的密码(通常是加密后的)。shell: 用户的登录 shell。home: 用户的家目录。
示例用法
- name: Add a user
ansible.builtin.user:
name: john
state: present
group: developers
groups: "wheel, docker"
append: yes
uid: 1040
home: /home/john
shell: /bin/bash
这个任务将创建或更新一个名为 john 的用户,指定他的主组为 developers,并且添加到 wheel 和 docker 组,而不影响他所属的其它组。
6. playbook
Ansible Playbook 是 Ansible 中用于编排自动化任务的核心功能。它是一个用 YAML 格式编写的脚本,可以定义一系列的任务(tasks),这些任务在一组主机上执行,并且以定义的顺序依次执行。Playbook 是声明式的,这意味着你定义的是所需的最终状态,而 Ansible 会确保执行所需的操作以达到这个状态。
Playbook 的基本结构
Playbook 通常包含以下几个基本部分:
- Hosts:指定任务将在哪些主机上执行。
- Variables:定义在 Playbook 中使用的变量。
- Tasks:要执行的具体任务列表,每个任务通常调用一个 Ansible 模块。
- Handlers:由特定的任务触发执行的任务,常用于服务的启动和重启。
- Roles:用于组织和复用 Playbook 的方式,允许将任务、变量、文件等封装起来重复使用。
在 Ansible Playbooks 中,YAML(YAML Ain’t Markup Language)是用来定义数据的主要格式。理解 YAML 中的数据类型对于编写有效的 Playbooks 是很重要的。YAML 支持多种数据类型,包括标量(scalars)、字典(dictionaries)、列表(lists)等,这些类型直接映射到 Ansible Playbook 中使用的变量和结构。
YAML语法
- 在单一文件第一行,用连续三个连字号"-" 开始,还有选择性的连续三个点号( … )用来表示文件的结尾
- 次行开始正常写Playbook的内容,一般建议写明该Playbook的功能
- 使用#号注释代码
- 缩进的级别也必须是一致的,同样的缩进代表同样的级别,程序判别配置的级别是通过缩进结合换行来实现的
- 缩进不支持tab,必须使用空格进行缩进
- 缩进的空格数不重要,只要相同层级的元素左对齐即可
- YAML文件内容是区别大小写的,key/value的值均需大小写敏感
- 多个key/value可同行写也可换行写,同行使用,分隔
- key后面冒号要加一个空格 比如: key: value
- value可是个字符串,也可是另一个列表
- YAML文件扩展名通常为yml或yaml
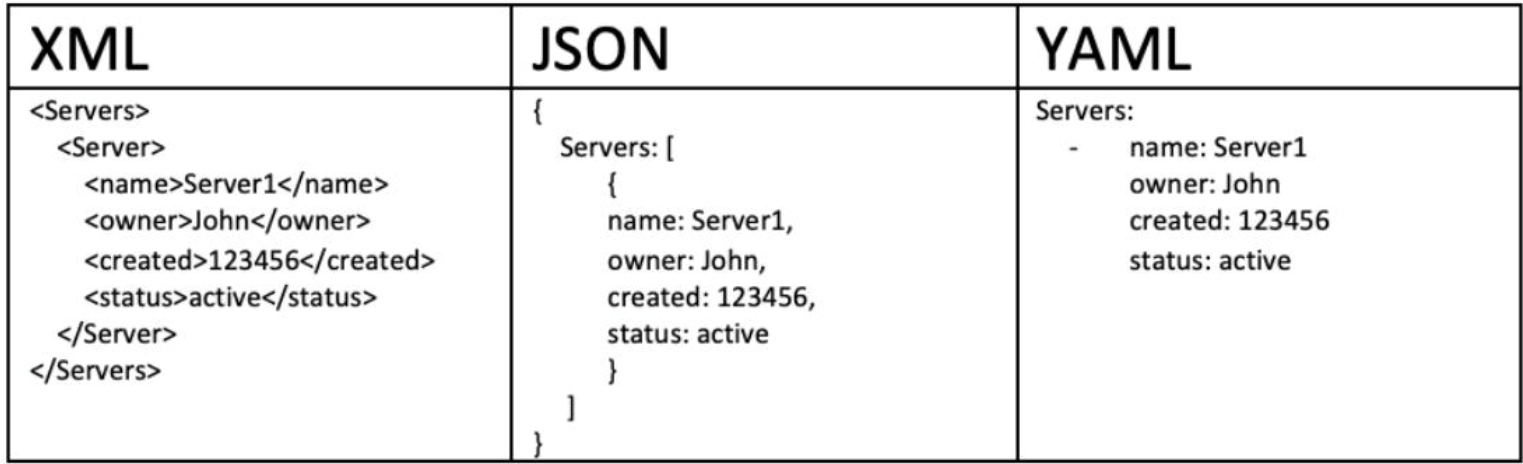
标量(Scalars)
标量是最基本的数据类型,代表单个的值。在 YAML 中,标量可以是字符串、整数、浮点数或布尔值。
-
字符串:通常不需要特别的引号,但如果包含特殊字符或关键词(如
true,false,null),则需要用单引号或双引号包围。string1: Hello, World! string2: "Yes, he said." string3: 'The path is C:\windows' -
整数:
an_integer: 42 -
浮点数:
a_float: 3.14 -
布尔值:
a_boolean: true another_boolean: false
列表(Lists)
列表是一组按顺序排列的值,通常用于表示重复的或有序的数据。在 YAML 中,列表项前面使用短横线 - 和空格。
a_list:
- item1
- item2
- item3
列表也可以包含字典或其他列表:
a_complex_list:
- name: John Doe
age: 30
- name: Jane Smith
age: 25
字典(Dictionaries)
字典或映射(maps)是一组键值对,用于表示对象或数据记录。每个键后面跟一个冒号和一个空格,然后是值。
a_dictionary:
key1: value1
key2: value2
key3: value3
字典的值可以是标量、列表、甚至另一个字典:
a_nested_dictionary:
key1: value1
key2:
subkey1: subvalue1
subkey2: subvalue2
key3:
- list_item1
- list_item2
使用这些数据类型的 Playbook 示例
---
- name: Example Playbook using various data types
hosts: all
vars:
string_var: "Hello, Ansible!"
integer_var: 100
float_var: 3.14159
boolean_var: true
list_var:
- one
- two
- three
dictionary_var:
key1: "This is a string"
key2:
- list_item1
- list_item2
tasks:
- name: Output all variables
debug:
msg: |
String: {{ string_var }}
Integer: {{ integer_var }}
Float: {{ float_var }}
Boolean: {{ boolean_var }}
List: {{ list_var }}
Dictionary: {{ dictionary_var.key1 }}
在这个 Playbook 中,我们定义了多种类型的变量并使用 debug 模块来输出这些变量的值。这种方式非常有助于理解和验证你的数据结构是否按照预期设定。
playbook命令
格式:
ansible-playbook <filename.yml> ... [options]
常见选项:
--syntax,--syntax-check #语法检查,功能相当于bash -n
-C --check #模拟执行dry run ,只检测可能会发生的改变,但不真正执行操作
--list-hosts #列出运行任务的主机
--list-tags #列出tag
--list-tasks #列出task
--limit 主机列表 #只针对主机列表中的特定主机执行
-i INVENTORY, --inventory INVENTORY #指定主机清单文件,通常一个项对应一个主机清单文件
--start-at-task START_AT_TASK #从指定task开始执行,而非从头开始,START_AT_TASK为任务的name
-v -vv -vvv #显示过程
忽略错误 ignore_errors
在 Ansible 中,ignore_errors 是一个常用的任务级别的指令,用于控制 Ansible 如何处理特定任务执行失败的情况。默认情况下,如果一个任务执行失败,Ansible 会停止当前 playbook 的执行并报错。使用 ignore_errors 可以告诉 Ansible 即使该任务失败也继续执行后续的任务。
使用场景
ignore_errors 特别有用在以下几种情况:
- 当某个任务的失败不是关键性的,且不应该阻止整个 playbook 的执行。
- 在尝试执行可能失败的操作时,例如检查某个服务是否存在或者尝试删除可能不存在的文件。
- 在开发和测试阶段,你可能希望忽略某些任务的失败以便于快速进行后续步骤。
语法和示例
在 Ansible 的任务中设置 ignore_errors 非常简单。你只需要在任务定义中添加 ignore_errors: yes。
- name: Attempt to remove a temporary file that might not exist
ansible.builtin.command: rm /tmp/tempfile.txt
ignore_errors: yes
在这个示例中,任务会尝试删除一个临时文件。如果文件不存在,rm 命令会失败,但由于设置了 ignore_errors: yes,Ansible 会忽略这个错误,并继续执行 playbook 中的后续任务。
注意事项
虽然 ignore_errors 在某些情况下非常有用,但它应该谨慎使用。忽略错误可能会掩盖真正的问题,导致在不知情的情况下继续执行,最终可能造成更大的错误或问题。因此,建议仅在确实不影响后续操作的情况下使用此选项。
可选的日志记录
有时候,你可能想要记录发生错误的信息而不仅仅是简单地忽略它们。你可以结合使用 ignore_errors 和 failed_when 条件,或者使用 rescue 部分在 block 结构中来更智能地处理错误。这样可以在忽略错误的同时记录必要的信息:
- name: Try to do something that might fail
block:
- name: Task that might fail
ansible.builtin.command: some risky command
ignore_errors: true
rescue:
- name: Handle the error
debug:
msg: "An error occurred, but we are ignoring it and moving on!"
在这个示例中,如果 risky command 失败,Ansible 将执行 rescue 部分的任务,允许你记录错误发生的事实,并且以适当的方式处理它。这种方法增加了额外的灵活性和控制力,使错误处理更加细致和精确。
handlers和notify
在 Ansible 中,handlers 和 notify 是两个关键的概念,用于管理任务的响应动作。这些机制允许你定义在特定任务执行后需要进行的额外操作,通常用于服务的重启或配置文件的重新加载。handlers 被设计为响应特定事件的操作,而这些事件由 notify 触发。
Handlers
Handlers 是在 playbook 中定义的特殊任务,它们通常用于执行像重启服务或重新加载配置这样的操作。Handlers 只会在被 notify 指令调用时执行,而且不管被 notify 多少次,每个 handler 在一个 playbook 执行周期中只会运行一次。这种行为非常适合执行像重启服务这样的操作,因为你通常只需要在一系列变更后重启一次。
Notify
Notify 是任务中的一个属性,用于触发 handler 的执行。当一个带有 notify 指令的任务发生变化(即实际发生了改动,如文件内容变更、包安装等)时,它会通知一个或多个 handlers。
示例
下面是一个包含 handlers 和 notify 的简单 playbook 示例:
---
- name: Example of handlers and notify
hosts: all
become: yes
tasks:
- name: Install nginx
ansible.builtin.yum:
name: nginx
state: latest
notify: restart nginx # Notify handler when Nginx is installed or updated
- name: Upload new nginx configuration file
ansible.builtin.copy:
src: /src/nginx.conf
dest: /etc/nginx/nginx.conf
mode: 0644
notify: reload nginx # Notify handler when the config file is changed
handlers:
- name: restart nginx
ansible.builtin.service:
name: nginx
state: restarted
enabled: yes
- name: reload nginx
ansible.builtin.service:
name: nginx
state: reloaded
说明
- Tasks:
- Install nginx: 如果 Nginx 安装或更新了,
notify会触发名为restart nginx的 handler。 - Upload new nginx configuration file: 如果配置文件被改变,
notify会触发名为reload nginx的 handler。
- Install nginx: 如果 Nginx 安装或更新了,
- Handlers:
- restart nginx: 当它被 notify 调用时,重启 nginx 服务。
- reload nginx: 当它被 notify 调用时,重新加载 nginx 配置。
注意事项
- 如果一个任务没有报告任何变更(即它的状态没有从未变更到变更),那么即使这个任务有 notify 指令,handlers 也不会被执行。
- Handlers 是在 playbook 的最后执行,所以即使多个任务通知了同一个 handler,它也只会执行一次。
- Handlers 的执行顺序是按照 playbook 中定义的顺序,而不是按 notify 的顺序
force_handlers:如果不论前面的task成功与否,都希望handlers能执行, 可以使用force_handlers: yes 强制执行handler
tags组件
在 Ansible 中,tags 是一个非常强大的功能,允许你为特定的任务、包括 roles、imports、和 includes 标记一个或多个名称。通过使用 tags,你可以在执行 playbook 时选择运行或跳过带有特定标签的部分。这样做可以极大地提升 playbook 的灵活性和效率,尤其是在大型的、复杂的环境中。
使用场景
- 有选择性地运行任务:在开发和调试过程中,你可能只想执行 playbook 的一小部分。使用 tags,你可以只运行那些具有特定标签的任务。
- 环境适应:在不同的环境中可能需要执行不同的任务。例如,某些任务只在生产环境中运行,而其他任务则适用于所有环境。
- 节省时间:对于执行时间较长的 playbook,如果你只需要重新执行一小部分任务,tags 可以帮助你节省时间。
定义 Tags
在 playbook 中,你可以在任何任务、角色或包括语句上定义 tags。这里是一些示例:
- hosts: all
tasks:
- name: Install nginx
yum:
name: nginx
state: latest
tags:
- install
- name: Configure nginx
template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
tags:
- configuration
- name: Ensure nginx is running
service:
name: nginx
state: started
tags:
- service
运行带有 Tags 的 Playbook
当运行 playbook 时,你可以使用 --tags 或 --skip-tags 选项来控制执行哪些带标签的任务。
- 只运行带有特定 tags 的任务:
ansible-playbook example.yml --tags "configuration"
这将只执行带有 configuration 标签的任务。
- 跳过带有特定 tags 的任务:
ansible-playbook example.yml --skip-tags "install"
这将执行 playbook 中除了带有 install 标签的所有任务。
- 列出标签:
ansible-playbook --list-tags example.yml
- 运行多个tags的任务:
ansible-playbook -t configuration,install example.yml
特殊 Tags
Ansible 有一些预定义的特殊标签:
- always:无论是否指定了
--tags或--skip-tags,总是执行带有always标签的任务。 - never:除非明确请求,否则永远不会执行带有
never标签的任务。
这些特殊标签允许对任务的执行进行更精细的控制。
结论
使用 tags 是一种强大的方法,可以让你精确控制 playbook 的执行流程,它非常适合在复杂或需要高度可定制的自动化环境中使用。通过合理地使用 tags,你可以确保 Ansible 的执行更加高效、灵活,并且能够满足不同环境或不同阶段的特定需求
playbook中的变量
Playbook中同样也支持变量
变量名:仅能由字母、数字和下划线组成,且只能以字母开头
变量定义
variable=value
variable: value
变量调用方式:
通过 {{ variable_name }} 调用变量,且变量名前后建议加空格,有时用"{{ variable_name }}"才生效
变量来源:
- ansible 的 setup facts 远程主机的所有变量都可直接调用
- 通过命令行指定变量,优先级最高
ansible-playbook -e varname=value test.yml
- 在playbook文件中定义
vars:
var1: value1
var2: value2
- 在独立的变量YAML文件中定义
- hosts: all
vars_files:
- vars.yml
-
在主机清单文件中定义
主机(普通)变量:主机组中主机单独定义,优先级高于公共变量
组(公共)变量:针对主机组中所有主机定义统一变量 -
在项目中针对主机和主机组定义
在项目目录中创建 host_vars和group_vars目录
- 在role中定义
register 注册变量
在 Ansible 中,register 关键字用于将任务执行的结果保存到一个变量中。这使得你可以在 playbook 的后续步骤中访问这些结果,进行条件检查、进一步的操作或调试。register 是一个非常有用的功能,它能够捕获任何 Ansible 任务的输出,并允许你根据输出内容来动态地控制 playbook 的执行流程。
使用场景
- 检查命令输出:运行 shell 命令或脚本,并根据输出来决定后续步骤。
- 处理任务结果:基于任务的执行结果(成功、失败、特定数据等)来触发其他任务。
- 调试:打印或记录任务输出,帮助理解 playbook 在执行过程中的行为。
基本用法
下面是一个使用 register 的示例,其中我们执行一个 shell 命令,并注册其结果到一个变量中:
- hosts: all
tasks:
- name: Check disk usage
command: df -h
register: disk_usage
- name: Print disk usage
debug:
msg: "{{ disk_usage.stdout }}"
在这个示例中:
- 第一个任务使用
command模块执行df -h命令,并将输出注册到disk_usage变量。 - 第二个任务使用
debug模块打印出disk_usage变量中的stdout属性,即df -h命令的输出。
可用属性
当你使用 register 保存任务输出时,Ansible 提供了多个属性来访问不同的信息:
stdout:命令的标准输出。stderr:命令的标凈错误输出。rc(return code):命令的返回码。changed:布尔值,指示任务是否引起了变更。failed:布尔值,指示任务是否失败。
进阶用法
register 不仅可用于命令执行任务,还可以用于几乎所有类型的模块,例如文件操作、网络请求等。你也可以结合条件语句来根据注册变量的值执行后续任务:
- hosts: all
tasks:
- name: Attempt to remove a file
ansible.builtin.file:
path: "/tmp/testfile"
state: absent
register: result
- name: Print result
debug:
msg: "File removed successfully"
when: result.changed
在这个示例中:
- 第一个任务尝试删除
/tmp/testfile文件,并将结果注册到result变量。 - 第二个任务检查
result.changed的值,如果为True(即文件被成功删除),则执行debug任务打印成功消息。
通过这样的方式,register 为 Ansible 提供了强大的动态执行能力,使 playbook 可以根据实时的执行情况做出响应。这增加了 playbook 的灵活性和复杂性,使其能够处理更多样化的自动化任务。
在 Playbook 命令行中定义变量
vim var2.yml
---
- hosts: webservers
remote_user: root
tasks:
- name: install package
yum: name={{ pkname }} state=present
[root@ansible ~]#ansible-playbook -e pkname=httpd var2.yml
#也可以将多个变量放在一个文件中
[root@ansible ~]#cat vars
pkname1: memcached
pkname2: vsftpd
[root@ansible ~]#vim var2.yml
---
- hosts: webservers
remote_user: root
tasks:
- name: install package {{ pkname1 }
yum: name={{ pkname1 }} state=present
- name: install package {{ pkname2 }
yum: name={{ pkname2 }} state=present
[root@ansible ~]#ansible-playbook -e pkname1=memcached -e pkname2=httpd
var5.yml
[root@ansible ~]#ansible-playbook -e '@vars' var2.yml
在 Playbook 文件中定义变量
此方式定义的是私有变量,即只能在当前playbook中使用,不能被其它Playbook共用
[root@ansible ~]#vim var3.yml
---
- hosts: webservers
remote_user: root
vars:
username: user1
groupname: group1
tasks:
- name: create group {{ groupname }}
group: name={{ groupname }} state=present
- name: create user {{ username }}
user: name={{ username }} group={{ groupname }} state=present
[root@ansible ~]#ansible-playbook -e "username=user2 groupname=group2" var3.yml
范例:变量的相互调用
[root@ansible ~]#cat var4.yaml
---
- hosts: webservers
remote_user: root
vars:
collect_info: "/data/test/{{ansible_default_ipv4['address']}}/"
tasks:
- name: create IP directory
file: name="{{collect_info}}" state=directory
#执行结果
tree /data/test/
/data/test/
└── 10.0.0.102
1 directory, 0 files
范例: 变量的相互调用
[root@ansible ansible]#cat var2.yml
---
- hosts: webservers
vars:
suffix: "txt"
file: "{{ ansible_nodename }}.{{suffix}}"
tasks:
- name: test var
file: path="/data/{{file}}" state=touch
使用专用的公共的变量文件
可以在一个独立的playbook文件中定义公共变量,在其它的playbook文件中可以引用变量文件中的变量。此方式比playbook中定义的变量优化级高
cat vars2.yml
---
var1: httpd
var2: nginx
cat var6.yml
---
- hosts: web
remote_user: root
vars_files:
- vars2.yml
tasks:
- name: create httpd log
file: name=/app/{{ var1 }}.log state=touch
- name: create nginx log
file: name=/app/{{ var2 }}.log state=touch
在主机清单中定义主机和主机组的变量
1.所有项目的主机变量
在inventory 主机清单文件中为指定的主机定义变量以便于在playbook中使用
[webservers]
www1.wang.org http_port=80 maxRequestsPerChild=808
www2.wang.org http_port=8080 maxRequestsPerChild=909
2.所有项目的组(公共)变量
在inventory 主机清单文件中赋予给指定组内所有主机上的在playbook中可用的变量,如果和主机变量是同名,优先级低于主机变量
[root@ansible ~]#vim /etc/ansible/hosts
[webservers]
10.0.0.8 hname=www1 domain=magedu.io
10.0.0.7 hname=www2
[webservers:vars]
mark="-"
[all:vars]
domain=wang.org
[root@ansible ~]#ansible webservers -m hostname -a 'name={{ hname }}{{ mark }}{{ domain }}'
#命令行指定变量:
[root@ansible ~]#ansible webservers -e domain=magedu.cn -m hostname -a 'name={{ hname }}{{ mark }}{{ domain }}'
3.针对当前项目的主机和主机组的变量
上面的方式是针对所有项目都有效,而官方更建议的方式是使用ansible特定项目的主机变量和组变量生产建议在每个项目对应的目录中创建额外的两个变量目录,分别是host_vars和group_vars
- host_vars下面的文件名和主机清单主机名一致,针对单个主机进行变量定义
格式:host_vars/hostname
- group_vars下面的文件名和主机清单中组名一致, 针对单个组进行变量定义
格式: group_vars/groupname - group_vars/all文件内定义的变量对所有组都有效
[root@ansible ansible]#pwd
/data/ansible
[root@ansible ansible]#mkdir host_vars
[root@ansible ansible]#mkdir group_vars
[root@ansible ansible]#cat host_vars/10.0.0.8
id: 2
[root@ansible ansible]#cat host_vars/10.0.0.7
id: 1
[root@ansible ansible]#cat group_vars/webservers
name: web
[root@ansible ansible]#cat group_vars/all
domain: wang.org
[root@ansible ansible]#tree host_vars/ group_vars/
host_vars/
├── 10.0.0.7
└── 10.0.0.8
group_vars/
├── all
└── webservers
0 directories, 4 files
[root@ansible ansible]#cat test.yml
- hosts: webservers
tasks:
- name: get variable
command: echo "{{name}}{{id}}.{{domain}}"
register: result
- name: print variable
debug:
msg: "{{result.stdout}}"
[root@ansible ansible]#ansible-playbook test.yml
PLAY [webservers]
********************************************************************************
***************************************
TASK [Gathering Facts]
********************************************************************************
*******************************
ok: [10.0.0.7]
ok: [10.0.0.8]
TASK [get variable]
********************************************************************************
**********************************
changed: [10.0.0.7]
changed: [10.0.0.8]
TASK [print variable]
********************************************************************************
********************************
ok: [10.0.0.7] => {
"msg": "web1.wang.org"
}
ok: [10.0.0.8] => {
"msg": "web2.wang.org"
}
PLAY RECAP
********************************************************************************
*******************************************
10.0.0.7 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
10.0.0.8 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Template模板
在 Ansible 中,template 模块是用于生成文件并将其复制到远程主机的强大工具。这个模块使用 Jinja2 模板引擎,允许你创建包含变量和逻辑表达式的参数化模板文件。这使得你可以生成根据主机或其他条件动态调整的配置文件。
用途
template 模块常用于生成配置文件和系统文件。例如,你可以根据特定的环境(开发、测试、生产)生成不同的配置文件,或者基于主机特定属性(如IP地址、操作系统)生成定制化的系统配置。
基本属性
- src:模板文件在控制节点上的本地路径。
- dest:生成的文件应放置在远程主机上的路径。
- owner, group, mode:指定文件的权限和所有权。
- backup:在覆盖前创建目标文件的备份。
示例
假设你有一个模板文件 nginx.conf.j2,里面包含了一些可以根据主机变量动态生成的内容。你可以使用 template 模块将其处理并复制到远程主机的指定位置。
模板文件 nginx.conf.j2 示例
server {
listen 80;
server_name {{ ansible_hostname }}; # 使用 Ansible 变量 ansible_hostname
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}
Playbook 中使用 template 模块
---
- name: Configure Nginx
hosts: webservers
tasks:
- name: Create nginx configuration file
template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
owner: root
group: root
mode: '0644'
notify: restart nginx
handlers:
- name: restart nginx
service:
name: nginx
state: restarted
enabled: yes
工作流程
- 生成:
template模块读取src指定的本地 Jinja2 模板文件。 - 渲染:模板中的变量和表达式被解析并替换为相应的值。
- 复制:生成的文件被复制到远程主机的
dest指定的路径。 - 权限设置:文件的所有权和权限被设置为指定的值。
- 重启服务:如果定义了 handler 并且模板发生变化导致任务状态为 “changed”,则触发对应的 handler(如重启 nginx)。
进阶用法
使用 template 模块时,你可以在模板中包含复杂的逻辑,如条件语句、循环等。这使得模板不仅仅是简单的配置文件,还可以根据具体情况生成高度定制化的内容。这种能力极大地扩展了自动化的可能性,使 Ansible 在配置管理方面非常强大。
Jinja2语言
Jinja2 是一个非常流行的模板引擎,广泛用于 Python 应用程序,特别是在 web 应用框架(如 Flask)和自动化工具(如 Ansible)中。Jinja2 允许开发者将变量和表达式插入到文本文件中,这些变量和表达式在运行时会被解析并替换,从而动态生成文档内容。
Jinja2 基础
在 Jinja2 中,你可以使用以下基本构件来创建动态内容:
-
变量:使用双大括号
{{ variable_name }}来渲染变量。 -
控制结构
:
- 条件语句:使用
{% if %}、{% elif %}、{% else %}来控制内容的显示。 - 循环:使用
{% for %}来遍历列表或字典。 - 宏:可以理解为函数,在模板中定义并可重复使用。
- 继承:使用
{% extends 'base.html' %}来继承其他模板。
- 条件语句:使用
-
过滤器:对变量进行处理,例如格式化、转换大小写等,使用管道符号
|应用,如{{ name | capitalize }}。
dict2items
dict2items 不是一个用户定义的名词,而是 Ansible 内置的一个过滤器,它用于将字典转换成项列表,这使得在使用 loop 进行迭代时更加方便。每个项是一个字典,包含键(key)和值(value)。
使用 dict2items
当你有一个字典,而你需要在 Ansible 的循环中迭代这个字典的每个键和值时,dict2items 非常有用。
users_dict:
alice:
uid: 1001
group: developers
bob:
uid: 1002
group: testers
使用 dict2items 转换这个字典:
- name: Create users from a dict
ansible.builtin.user:
name: "{{ item.key }}"
uid: "{{ item.value.uid }}"
group: "{{ item.value.group }}"
state: present
loop: "{{ users_dict | dict2items }}"
在这个例子中,users_dict 是一个预定义的变量,包含用户的信息。通过使用 dict2items 过滤器,我们能够在 loop 中访问每个用户的名字、UID 和组。
Jinja2 在 Ansible 中的使用
在 Ansible 中,Jinja2 主要用于模板文件(通常以 .j2 结尾)以及定义变量的默认值或构造复杂的变量。例如,使用 Ansible 的 template 模块可以根据 .j2 模板生成配置文件。
- name: Configure application
template:
src: templates/app.config.j2
dest: /etc/app/config
使用技巧
- 白空间控制:Jinja2 提供了减少渲染结果中不必要空白的功能,使用
-符号来去除标签前后的空白,例如{%- for item in items -%}。 - 安全过滤:当渲染来自用户的数据时,使用
escape过滤器或自动转义功能来防止 XSS 攻击。
循环迭代
在 Ansible 中,循环是执行任务时重复相同操作的一种方法。Ansible 提供了多种方式来处理循环,包括使用 loop 和 with_items 等。这些构造允许你在一组数据上重复执行任务,这组数据可以是列表、字典、或通过查找插件查询得到的任何可迭代对象。
loop
loop 是 Ansible 中较新的通用循环机制,推荐用于替代老式的 with_ 关键字(如 with_items、with_dict 等)。loop 提供了更清晰的语法和更好的灵活性。
- 对迭代项的引用,固定内置变量名为"item"
- 要在task中使用with_items给定要迭代的元素列表
- 注意: ansible2.5版本后,可以用loop代替with_items
列表元素格式:
- 字符串
- 字典 key: value
范例:
- name: Install multiple packages
ansible.builtin.yum:
name: "{{ item }}"
state: present
loop:
- git
- tree
- wget
在这个例子中,loop 用于安装多个包。它遍历提供的列表,并对每个列表项执行一次任务。
with_items
with_items 是 Ansible 早期版本中使用的循环语法,它特别适用于列表,并且在很多现有的 Ansible Playbooks 中仍然可以看到它的使用。尽管 with_items 在新版中被 loop 取代,但了解它依然有助于维护和理解旧的 playbook。
使用 with_items 的基本语法
- name: Install multiple packages
ansible.builtin.yum:
name: "{{ item }}"
state: present
with_items:
- git
- tree
- wget
with_items 逐一处理列表中的每个项目,并在每次迭代中将当前项存储在特殊变量 item 中。
高级循环用法
循环中的条件语句
在循环中结合使用 when 条件,以便根据条件跳过某些迭代。
- name: Install optional packages
ansible.builtin.yum:
name: "{{ item }}"
state: present
loop:
- git
- tree
- wget
when: ansible_os_family == "RedHat"
在这个例子中,只有当操作系统是基于 RedHat 时,才会执行包安装。
循环字典
使用 loop 遍历字典时,你可以访问字典的键和值。
users_dict:
alice:
uid: 1001
group: developers
bob:
uid: 1002
group: developers
dict2items 是一个 Jinja2 过滤器,它把字典转换成一个项列表(item list),每个项都是一个包含 key 和 value 的字典。转换后的数据结构便于 loop 迭代。使用 dict2items 后,users_dict 变成了如下结构:
- key: alice
value:
uid: 1001
group: developers
- key: bob
value:
uid: 1002
group: developers
在 loop 中使用这个转换后的列表,每次迭代都会处理一个用户。item.key 对应用户名,而 item.value 是一个包含 uid 和 group 的字典。
- name: Add several users
ansible.builtin.user:
name: "{{ item.key }}" # 用户名,如 alice 或 bob
uid: "{{ item.value.uid }}" # 用户 ID,如 1001 或 1002
group: "{{ item.value.group }}" # 用户组,如 developers
loop: "{{ users_dict | dict2items }}"
在每次循环中,ansible.builtin.user 模块用提供的值创建或更新用户:
name: 设置用户名。uid: 设置用户ID,这是用户的唯一标识。group: 将用户添加到特定的组。
这里,users_dict 是一个字典,其中的键是用户名,值是另一个包含 uid 和 group 的字典。dict2items 过滤器将字典转换为列表,列表中的每个元素都是键和值的组合。
虽然 with_items 和其他 with_ 循环已被 loop 取代,但理解这些概念依然对维护旧代码或理解 Ansible 的循环机制有所帮助。loop 提供了更加统一和强大的方式来处理复杂的迭代任务。
until
until 关键字用于在 Ansible 中实现重试逻辑。当你有一个可能需要多次尝试才能成功的任务时(例如,等待服务启动或等待网络资源变得可用),until 可以用来重复执行该任务直到满足某个条件。
使用 until 的基本语法
在使用 until 时,你通常会结合 retries 和 delay 参数来控制重试的次数和间隔。
- name: Wait for web service to become available
uri:
url: http://example.com/health
return_content: yes
register: result
until: result.status == 200
retries: 5
delay: 10
在这个例子中,任务使用 uri 模块检查一个 web 服务的健康状态页。until 检查返回的状态码是否为 200,表示服务可用。如果服务不可用,任务会每隔 10 秒重试,总共重试 5 次。
with_lines
with_lines 是一个用于处理命令输出行的循环构造。它会执行一个 shell 命令,并将命令的标准输出按行分割,每一行作为一个元素进行迭代。
使用 with_lines 的基本语法
- name: Add groups from command output
ansible.builtin.group:
name: "{{ item }}"
state: present
with_lines: "cat /path/to/group_list.txt"
在这个例子中,with_lines 用于执行 cat /path/to/group_list.txt 命令,该命令输出文件中的每一行。然后,对于输出的每一行,都会创建一个同名的用户组。
注意事项
- 重试任务(until): 当使用
until时,重要的是确保有一个明确的成功条件和合理的重试次数和延迟,以避免无限循环或不必要的长时间等待。 - 处理命令输出(with_lines): 当使用
with_lines时,需要注意命令输出的格式和内容,确保它们符合你的迭代逻辑和任务需求。此外,with_lines适合处理较短的输出。对于非常长的输出,使用其他方法(如临时文件)可能更有效。
条件判断when
when语句可以实现条件测试。如果需要根据变量、facts或此前任务的执行结果来做为某task执行与否的前提时要用到条件测试,通过在task后添加when子句即可使用jinja2的语法格式条件测试
基本用法
- name: Install Apache on CentOS
yum:
name: httpd
state: present
when: ansible_facts['os_family'] == "RedHat"
在这个例子中,when 语句用于判断操作系统家族是否为 “RedHat”,只有满足这个条件时,Apache 才会被安装。这是通过访问由 setup 模块收集的 ansible_facts 中的信息来完成的。
when 语句还可以支持更复杂的逻辑,包括使用 and、or 和 not 运算符:
- name: Shutdown Debian/Ubuntu system
command: /sbin/shutdown
when:
- ansible_facts['os_family'] == "Debian"
- ansible_facts['uptime_seconds'] > 7200
在这个例子中,系统会在运行了超过2小时(7200秒)并且操作系统为 Debian/Ubuntu 时进行关闭。
block - 分组块
block 用于在单个任务列表中创建一个逻辑块,这使得你可以在多个任务上应用统一的错误处理或条件。block 可以包含多个任务,并可以与 rescue 和 always 一起使用来提供类似编程语言中的 try/catch/finally 功能。
基本用法
- name: Handle errors with block
block:
- name: Attempt to delete a temporary file
file:
path: "/tmp/tempfile.txt"
state: absent
- name: Attempt to update web service
command: /usr/bin/make-webservice-call
args:
chdir: /srv/web_service/
rescue:
- name: Recover from delete error
debug:
msg: "Failed to delete temporary file."
- name: Recover from webservice update error
debug:
msg: "Failed to update web service."
always:
- name: Always do this
debug:
msg: "This is always executed no matter what happened before."
在这个例子中,block 包含两个任务,一个是删除文件,另一个是更新 web 服务。如果 block 中的任何任务失败,rescue 部分将执行,适用于错误处理。不管 block 执行成功还是失败,always 部分总会执行,适用于需要保证执行的清理或日志记录任务。
常见问题
1. CentOS 7在测试ping的时候可能会报一个警告,如下:
[WARNING]: Platform linux on host 10.0.0.103 is using the discovered Python interpreter at /usr/bin/python, but future installation of another Python interpreter could change this.
这个警告是关于 Ansible 使用自动发现的 Python 解释器。从 Ansible 2.8 版本开始,Ansible 引入了一种新的解释器发现功能,用于在托管节点上自动找到合适的 Python 解释器。
解决方案:
1.指定 Python 解释器:在你的 Ansible inventory 文件或者 playbook 中明确指定 Python 解释器的路径。例如,在 inventory 文件中对每个主机或主机组设置 ansible_python_interpreter 变量:
[web01]
10.0.0.103 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass=root ansible_python_interpreter=/usr/bin/python
10.0.0.107 ansible_ssh_port=22 ansible_ssh_user=root ansible_ssh_pass=root ansible_python_interpreter=/usr/bin/python
或者在 playbook 中全局设置:
- hosts: all
vars:
ansible_python_interpreter: /usr/bin/python
tasks:
...
2. 写playbook通过-C测试的时候,高版本(Rocky 8、9上)会模拟运行,如果不通会提示错误,但是如果是低版本(CentOS 7上)不会提示。
vim install_nginx.yaml
---
- hosts: web01
remote_user: root
gather_facts: no
tasks:
- name: add group nginx
group: name=nginx state=present
- name: add user nginx
user: name=nginx state=present group=nginx
- name: Install nginx
yum: name=nginx state=present
- name: web page
copy: src=files/index.html dest=/usr/share/nginx/html/index.html
- name: Start nginx
service: name=nginx state=started enabled=yes
通过-C进行验证该playbook是否有语法错误或逻辑错误。
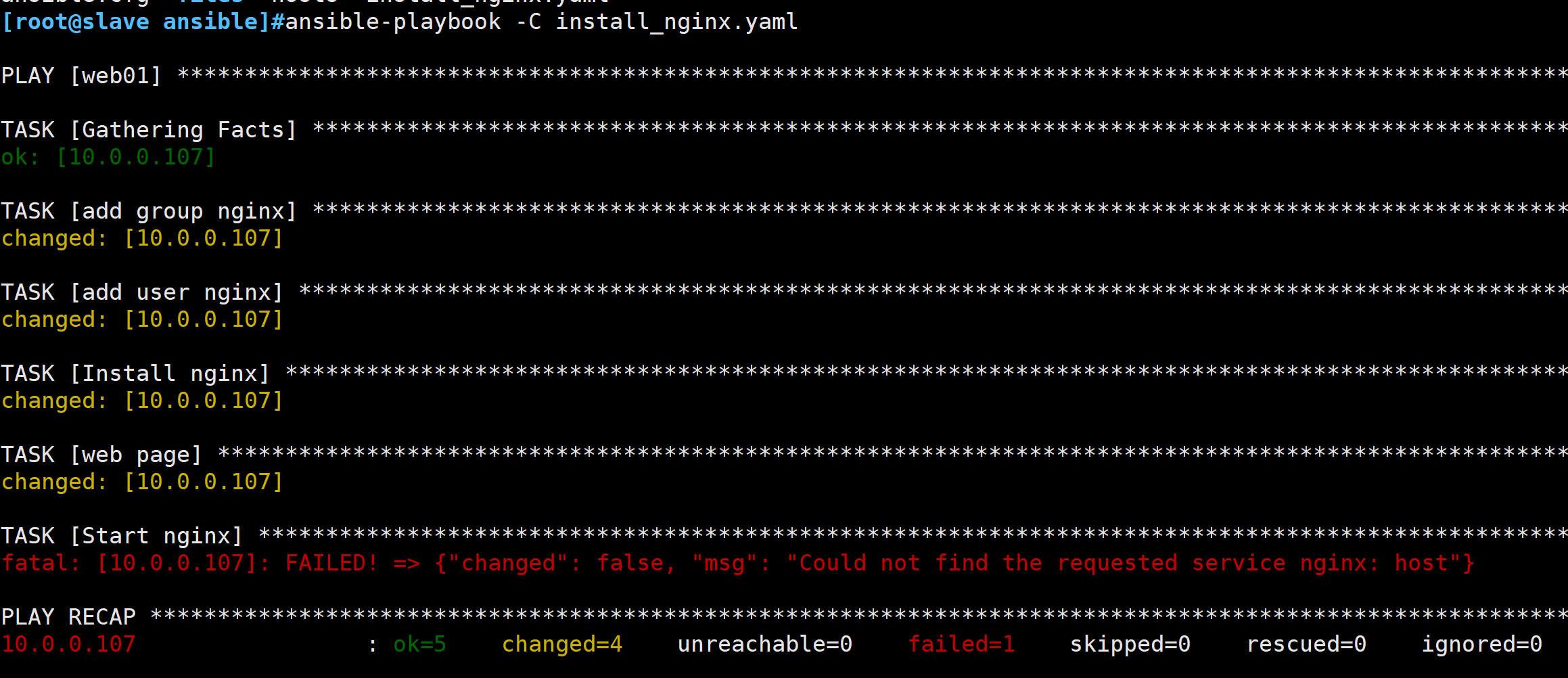
1.在Rocky Linux 9上面测试,ansible 版本2.14.9
[root@slave ansible]#ansible-playbook -C install_nginx.yaml
2.在CentOS 7 上面测试,ansible 版本2.9.27
[root@slave ansible]#ansible-playbook -C install_nginx.yaml
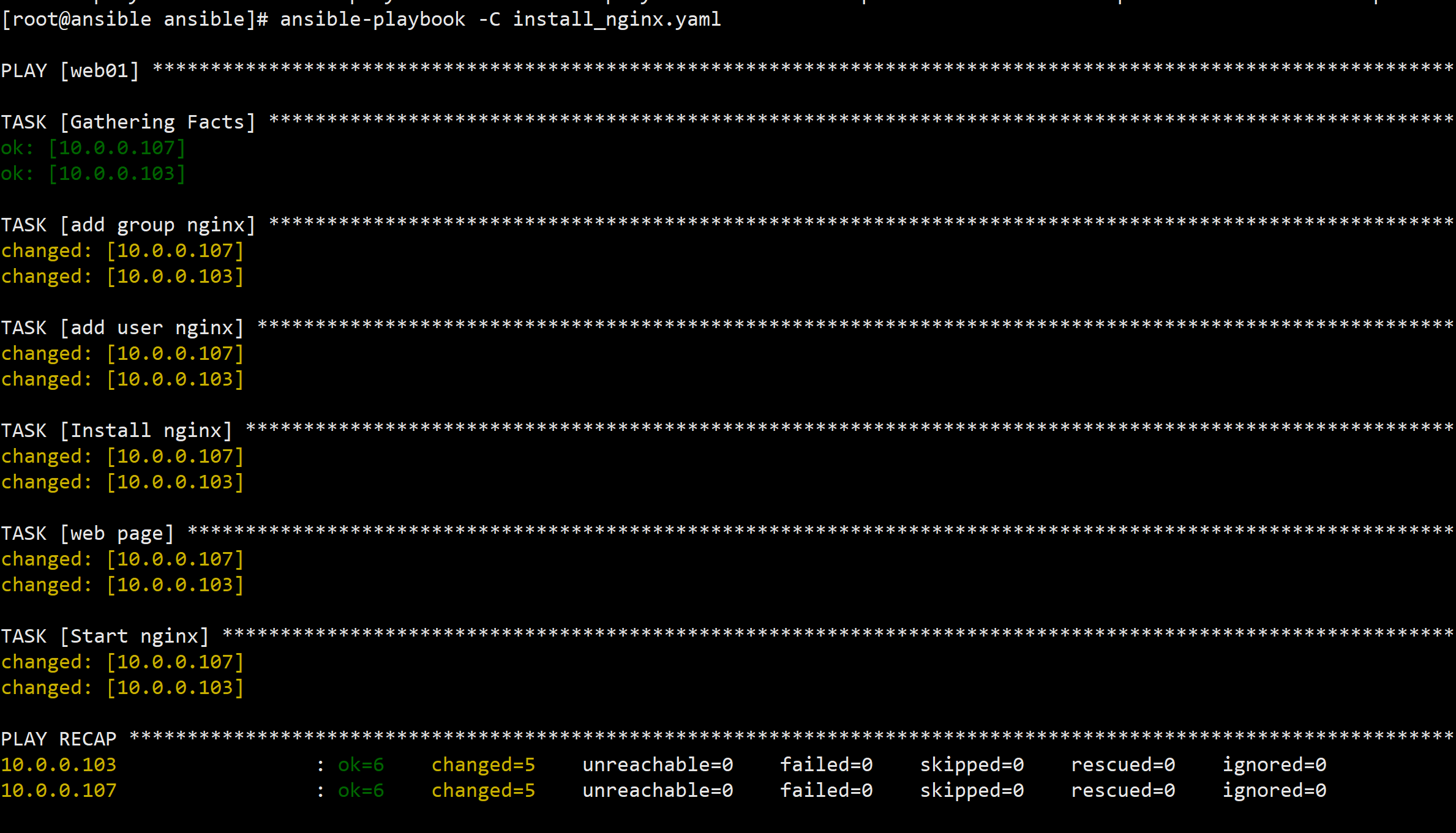
在 CentOS 7 上运行时没有出现错误可能是因为 Ansible 的不同版本处理 -C 选项的方式有所不同。在较老版本的 Ansible 中,对于一些任务,尤其是服务相关的任务,--check 模式可能不会预测到这样的问题。但是在新版本当中,ansible在模拟执行“start nginx"任务时预期会失败。
3.playbook中的ansible_facts和setup输出的信息不一致
# 先来看一个playbook
[root@ansible ansible]#cat show_ip.yml
---
- hosts: web
tasks:
- name: show eth0 ip address {{ ansible_facts["eth0"]["ipv4"]["address"] }}
debug:
msg: IP address {{ ansible_eth0.ipv4.address }}
# 执行这个playbook,发现是可以执行成功的
[root@centos7 ansible]# ansible-playbook show_ip.yaml
PLAY [web] *********************************************************************************************************************************************************************************************************************************
TASK [Gathering Facts] *********************************************************************************************************************************************************************************************************************
ok: [10.0.0.106]
ok: [10.0.0.122]
TASK [show eth0 ip address 10.0.0.122] *****************************************************************************************************************************************************************************************************
ok: [10.0.0.122] => {
"msg": "IP address 10.0.0.122"
}
ok: [10.0.0.106] => {
"msg": "IP address 10.0.0.106"
}
PLAY RECAP *********************************************************************************************************************************************************************************************************************************
10.0.0.106 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
10.0.0.122 : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
[root@centos7 ansible]#
# 这个是用来查看系统的信息,这些是可以当做变量来调用的
[root@centos7 ansible]# ansible localhost -m setup
localhost | SUCCESS => {
"ansible_facts": {
"ansible_all_ipv4_addresses": [
"10.0.0.122"
],
"ansible_default_ipv4": {
"address": "10.0.0.122",
"alias": "eth0",
"broadcast": "10.0.0.255",
"gateway": "10.0.0.2",
"interface": "eth0",
"macaddress": "00:0c:29:a5:07:6c",
"mtu": 1500,
"netmask": "255.255.255.0",
"network": "10.0.0.0",
"type": "ether"
},
"ansible_eth0": {
"active": true,
"device": "eth0",
"features": {
"busy_poll": "off [fixed]",
"fcoe_mtu": "off [fixed]",
"generic_receive_offload": "on",
"generic_segmentation_offload": "on",
"highdma": "off [fixed]",
"hw_tc_offload": "off [fixed]",
"l2_fwd_offload": "off [fixed]",
"large_receive_offload": "off [fixed]",
"loopback": "off [fixed]",
"netns_local": "off [fixed]",
"ntuple_filters": "off [fixed]",
"receive_hashing": "off [fixed]",
"rx_all": "off",
"rx_checksumming": "off",
"rx_fcs": "off",
"rx_gro_hw": "off [fixed]",
"rx_udp_tunnel_port_offload": "off [fixed]",
"rx_vlan_filter": "on [fixed]",
"rx_vlan_offload": "on",
"rx_vlan_stag_filter": "off [fixed]",
"rx_vlan_stag_hw_parse": "off [fixed]",
"scatter_gather": "on",
"tcp_segmentation_offload": "on",
"tx_checksum_fcoe_crc": "off [fixed]",
"tx_checksum_ip_generic": "on",
"tx_checksum_ipv4": "off [fixed]",
"tx_checksum_ipv6": "off [fixed]",
"tx_checksum_sctp": "off [fixed]",
"tx_checksumming": "on",
"tx_fcoe_segmentation": "off [fixed]",
"tx_gre_csum_segmentation": "off [fixed]",
"tx_gre_segmentation": "off [fixed]",
"tx_gso_partial": "off [fixed]",
"tx_gso_robust": "off [fixed]",
"tx_ipip_segmentation": "off [fixed]",
"tx_lockless": "off [fixed]",
"tx_nocache_copy": "off",
"tx_scatter_gather": "on",
"tx_scatter_gather_fraglist": "off [fixed]",
"tx_sctp_segmentation": "off [fixed]",
"tx_sit_segmentation": "off [fixed]",
"tx_tcp6_segmentation": "off [fixed]",
"tx_tcp_ecn_segmentation": "off [fixed]",
"tx_tcp_mangleid_segmentation": "off",
"tx_tcp_segmentation": "on",
"tx_udp_tnl_csum_segmentation": "off [fixed]",
"tx_udp_tnl_segmentation": "off [fixed]",
"tx_vlan_offload": "on [fixed]",
"tx_vlan_stag_hw_insert": "off [fixed]",
"udp_fragmentation_offload": "off [fixed]",
"vlan_challenged": "off [fixed]"
},
"hw_timestamp_filters": [],
"ipv4": {
"address": "10.0.0.122",
"broadcast": "10.0.0.255",
"netmask": "255.255.255.0",
"network": "10.0.0.0"
},
。。。。。。
这里只列出需要的一部分
# 问题1:通过查看变量信息,并没有单独的eth0模块,只有“ansible_eth0”,为什么在playbook中可以使用“{{ ansible_facts["eth0"]["ipv4"]["address"] }}”来获取ip地址呢?
# 这个问题困扰了我好久,后来想到会不会是playbook中的ansible_facts和在命令行执行ansible localhost -m setup这个命令输出的结果不一样,下面来验证一下
[root@centos7 ansible]# cat print_facts.yaml
---
- hosts: web
tasks:
- name: Print all Ansible facts
debug:
var: ansible_facts
[root@centos7 ansible]#
ok: [10.0.0.122] => {
"ansible_facts": {
"all_ipv4_addresses": [
"10.0.0.122"
],
"all_ipv6_addresses": [
"fe80::7828:2035:58c3:f879"
],
"default_ipv4": {
"address": "10.0.0.122",
"alias": "eth0",
"broadcast": "10.0.0.255",
"gateway": "10.0.0.2",
"interface": "eth0",
"macaddress": "00:0c:29:a5:07:6c",
"mtu": 1500,
"netmask": "255.255.255.0",
"network": "10.0.0.0",
"type": "ether"
},
"eth0": {
"active": true,
"device": "eth0",
"features": {
"busy_poll": "off [fixed]",
"fcoe_mtu": "off [fixed]",
"generic_receive_offload": "on",
"generic_segmentation_offload": "on",
"highdma": "off [fixed]",
"hw_tc_offload": "off [fixed]",
"l2_fwd_offload": "off [fixed]",
"large_receive_offload": "off [fixed]",
"loopback": "off [fixed]",
"netns_local": "off [fixed]",
"ntuple_filters": "off [fixed]",
"receive_hashing": "off [fixed]",
"rx_all": "off",
"rx_checksumming": "off",
"rx_fcs": "off",
"rx_gro_hw": "off [fixed]",
"rx_udp_tunnel_port_offload": "off [fixed]",
"rx_vlan_filter": "on [fixed]",
"rx_vlan_offload": "on",
"rx_vlan_stag_filter": "off [fixed]",
"rx_vlan_stag_hw_parse": "off [fixed]",
"scatter_gather": "on",
"tcp_segmentation_offload": "on",
"tx_checksum_fcoe_crc": "off [fixed]",
"tx_checksum_ip_generic": "on",
"tx_checksum_ipv4": "off [fixed]",
"tx_checksum_ipv6": "off [fixed]",
"tx_checksum_sctp": "off [fixed]",
"tx_checksumming": "on",
"tx_fcoe_segmentation": "off [fixed]",
"tx_gre_csum_segmentation": "off [fixed]",
"tx_gre_segmentation": "off [fixed]",
"tx_gso_partial": "off [fixed]",
"tx_gso_robust": "off [fixed]",
"tx_ipip_segmentation": "off [fixed]",
"tx_lockless": "off [fixed]",
"tx_nocache_copy": "off",
"tx_scatter_gather": "on",
"tx_scatter_gather_fraglist": "off [fixed]",
"tx_sctp_segmentation": "off [fixed]",
"tx_sit_segmentation": "off [fixed]",
"tx_tcp6_segmentation": "off [fixed]",
"tx_tcp_ecn_segmentation": "off [fixed]",
"tx_tcp_mangleid_segmentation": "off",
"tx_tcp_segmentation": "on",
"tx_udp_tnl_csum_segmentation": "off [fixed]",
"tx_udp_tnl_segmentation": "off [fixed]",
"tx_vlan_offload": "on [fixed]",
"tx_vlan_stag_hw_insert": "off [fixed]",
"udp_fragmentation_offload": "off [fixed]",
"vlan_challenged": "off [fixed]"
},
"hw_timestamp_filters": [],
"ipv4": {
"address": "10.0.0.122",
"broadcast": "10.0.0.255",
"netmask": "255.255.255.0",
"network": "10.0.0.0"
},
....
# 原来是playbook中的ansible_facts前面大部分是去掉了"ansible_",例如:之前的ansible_eth0,现在变成了"eth0","ansible_default_ipv4"->"default_ipv4",所以现在可以通过{{ ansible_facts["eth0"]["ipv4"]["address"] }}来获取到地址了
"ansible_default_ipv4": {
"address": "10.0.0.122",
"alias": "eth0",
"broadcast": "10.0.0.255",
"gateway": "10.0.0.2",
"interface": "eth0",
"macaddress": "00:0c:29:a5:07:6c",
"mtu": 1500,
"netmask": "255.255.255.0",
"network": "10.0.0.0",
"type": "ether"
},
[root@centos7 ansible]# ansible localhost -m setup -a "filter=ansible_default_ipv4"
localhost | SUCCESS => {
"ansible_facts": {
"ansible_default_ipv4": {
"address": "10.0.0.122",
"alias": "eth0",
"broadcast": "10.0.0.255",
"gateway": "10.0.0.2",
"interface": "eth0",
"macaddress": "00:0c:29:a5:07:6c",
"mtu": 1500,
"netmask": "255.255.255.0",
"network": "10.0.0.0",
"type": "ether"
}
},
"changed": false
}
[root@centos7 ansible]# ansible localhost -m setup -a "filter=ansible_default_ipv4["address"]"
localhost | SUCCESS => {
"ansible_facts": {},
"changed": false
}
[root@centos7 ansible]#
# 问题2:针对上面的setup输出的信息,我想通过命令行获取一下address的值,为什么可以获取到ansible_default_ipv4的,却获取不到address的呢?
这是因为在命令中只能获取每个映射的内容,无法获取到具体的某一个键值。在yml文件中,setup输出的信息是直接可以调用的,但是ansible_facts的信息(也就是没有ansible前缀的)条用必须使用{{ ansible_facts["eth0"]["ipv4"]["address"] }}这种方式来调用。
两种变量引用方式
当开启gather_facts: yes 下面两种方式都可以用了
- 直接引用方式(省略
ansible_facts):- 当你使用如
ansible_processor_vcpus这样的变量时,Ansible 允许你直接引用,不需要指定ansible_facts前缀。这种方式是 Ansible 的一个简化,使得 playbook 更易于阅读和编写。 - 示例:
ansible_processor_vcpus,ansible_distribution
- 当你使用如
- 使用
ansible_facts字典:- 当你使用类似
ansible_facts['processor_vcpus']或ansible_facts['distribution']的语法时,你是在从一个字典中显式地引用值。这种方式在你需要确保对变量的处理非常明确,或者在使用自动变量与其他变量可能产生名称冲突的场景中非常有用。 - 示例:
ansible_facts['processor_vcpus'],ansible_facts['distribution']
- 当你使用类似
4.yaml中的"|“和”>"区别:
在Ansible的YAML脚本中,那条竖线 | 是一个特殊的YAML字符,用于表示一个块标量,这意味着它后面的内容会被处理为单个字符串。这种方式允许你保持文本的原始格式,包括换行符和缩进,这在定义多行文本时特别有用。
在Ansible的 copy 模块中,使用竖线 | 后跟随的文本会被直接复制到目标文件中,保持你在YAML文件中书写的格式。这在创建配置文件或脚本时尤其有用,因为这些文件经常需要严格的格式规范,包括换行和缩进。
举个例子:
- copy:
content: |
[Unit]
Description=nginx - high performance web server
Documentation=http://nginx.org/en/docs/
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
PIDFile={{ ins_dir }}run/nginx.pid
ExecStart=/usr/sbin/nginx -c {{ ins_dir }}conf/nginx.conf
ExecReload=/bin/sh -c "/bin/kill -s HUP $(/bin/cat {{ ins_dir }}run/nginx.pid)"
ExecStop=/bin/sh -c "/bin/kill -s TERM $(/bin/cat {{ ins_dir }}run/nginx.pid)"
[Install]
WantedBy=multi-user.target
dest: /lib/systemd/system/nginx.service
content: 这个参数允许你直接在任务中定义文件的内容。在这个例子中,内容是systemd的服务单元文件,用于配置和管理Nginx服务。
dest: 指定文件应该被创建的目的地。在这个例子中,它是 /lib/systemd/system/nginx.service,这是systemd服务单元文件通常所在的目录。
>,它是 YAML 中的一个折叠新行的符号,允许你将一个长表达式分成多行,以提高可读性。这样做的好处是让表达式更易于理解和维护,尤其是在涉及多个条件和复杂逻辑时。
- name: Some Task
command: echo "This is a conditional task"
when: >
(ansible_facts['distribution'] == "CentOS" and
ansible_facts['distribution_major_version'] == "6") or
(ansible_facts['distribution'] == "Ubuntu" and
ansible_facts['distribution_major_version'] == "18")
5. state理解
在Ansible中,state是一个常用的属性,用于定义目标系统或对象的期望状态。这个参数的值取决于具体的模块,但它的基本目的是让你能够声明资源应该是如何的状态,而不是执行特定的命令来改变状态。这体现了"声明式编程"的理念,即指定"什么"而不是"怎么做"。以下是一些常见模块中state参数的典型用法:
file模块
在file模块中,state用于确定文件或目录的状态:
absent: 确保文件或目录不存在。directory: 确保目录存在,如果不存在则创建。file: 确保文件存在,如果不存在则创建空文件。link: 确保符号链接存在。hard: 确保硬链接存在。touch: 类似于file,但还会更新文件的访问和修改时间。
示例
- name: Ensure directory exists
ansible.builtin.file:
path: /path/to/directory
state: directory
- name: Remove file
ansible.builtin.file:
path: /path/to/file
state: absent
service模块
在service模块中,state用于控制服务的运行状态:
started: 确保服务正在运行。stopped: 确保服务停止运行。restarted: 重启服务。reloaded: 重新加载服务配置。
示例
- name: Start nginx service
ansible.builtin.service:
name: nginx
state: started
package模块
在package模块中,state用于管理包的安装状态:
present: 确保包已安装。absent: 确保包未安装。latest: 确保安装了包的最新版本。
示例
- name: Install the latest version of nginx
ansible.builtin.package:
name: nginx
state: latest
通过使用state属性,Ansible允许用户以一种直观且高效的方式来管理系统配置和服务。这有助于提高自动化脚本的可读性和可维护性。
6. setup和ansible_facts
在 Ansible 中,setup 模块和 ansible_facts 是紧密相关的,它们共同用于管理和访问关于远程系统的自动化收集信息。这些信息对于决策如何在远程系统上执行操作非常有用,尤其是当这些操作需要依赖于特定的系统属性时。
setup 模块
setup 模块是 Ansible 用来收集远程主机的系统信息的工具,这一过程通常称为 “Gathering Facts”。当你运行一个 playbook 时,默认情况下,Ansible 会在执行任何任务之前自动运行 setup 模块来收集远程主机的信息。这包括操作系统、网络接口、磁盘空间、内存使用情况、环境变量、IP 地址等详细信息。
这些信息被收集并存储在 ansible_facts 变量中,可以在 playbook 的后续任务中使用这些信息来进行条件判断或其他逻辑操作。
ansible_facts
ansible_facts 是一个字典变量,包含了 setup 模块收集的所有远程主机信息。每当 setup 模块执行后,这个字典就会被更新。你可以在 playbook 的任务中直接访问 ansible_facts 中的元素来做出基于具体主机信息的决策。
去看setup和ansible_facts输出的内容是不一样的,所以setup输出的是直接可以调用的,但是ansible_facts必须通过字典一层一层往下找。
示例使用 ansible_facts
- name: Gather facts about remote systems
hosts: all
tasks:
- name: Display operating system type
debug:
msg: "The operating system is {{ ansible_facts['os_family'] }}"
在这个例子中,ansible_facts['os_family'] 用于获取远程系统的操作系统类型,可能的值如 “RedHat”, “Debian”, “Windows” 等。
控制 Facts 的收集
虽然默认情况下 setup 模块会自动执行,但你可以控制这一行为:
- 禁用 facts 收集:在你的 playbook 中设置
gather_facts: no可以阻止自动收集 facts,这在你不需要任何系统信息或者要优化执行速度时非常有用。
- name: Run tasks without gathering facts
hosts: all
gather_facts: no
tasks:
- name: Just say hello
debug:
msg: "Hello, world!"
- 手动执行 setup 模块:如果你在某些情况下禁用了自动收集,但在流程中的某个点需要 facts,你可以手动调用
setup模块。
- name: Manually gather facts
hosts: all
gather_facts: no
tasks:
- name: Manually gather facts from the system
setup:
- name: Use a fact from the setup module
debug:
msg: "The OS is {{ ansible_facts['os_family'] }}"
- 使用
ansible_facts: 当你在 playbook 中使用setup模块收集 facts 后,所有的 facts 都会存储在ansible_facts字典中。这意味着要访问任何特定的 fact,比如默认的 IPv4 地址,你需要从这个字典中获取它,比如使用ansible_facts['default_ipv4']['address']。 - 直接使用属性名: 在某些 Ansible 的输出或特定的模块文档中,你可能会看到没有
ansible_facts前缀的属性名。这通常是因为在那些上下文中,文档或输出直接引用了字典中的内容,而不需要通过ansible_facts字典去访问它。
为什么有时候看起来不一样
- 命令行使用:当你在命令行中直接使用
ansible命令查询 facts(比如ansible localhost -m setup),输出的是整个ansible_facts字典的内容,此时看到的属性不带ansible_facts前缀。 - 在 playbook 中:在 playbook 中,为了确保 clarity 和避免命名冲突,最好通过
ansible_facts字典访问所有 facts。
案例:
- name: Set number of worker processes in Nginx config
lineinfile:
path: "{{ item.path }}"
regexp: "{{ item.regexp }}"
line: "{{ item.line }}"
with_items:
- { path: "{{ install_dir }}/conf/nginx.conf", regexp: '^worker_processes', line: "worker_processes {{ ansible_processor_vcpus }};" }
这个任务将会检查位于 {{ install_dir }}/conf/nginx.conf 的 Nginx 配置文件,并确保 worker_processes 行的内容为 worker_processes <CPU核心数>;,其中 <CPU核心数> 是通过 ansible_processor_vcpus 这个变量提供的,它直接从系统 facts 中获取处理器的核心数。
为什么可以省略 ansible_facts 前缀
- 自动变量引入:当使用
setup模块收集 facts 后(无论是自动的还是手动的),Ansible 将这些 facts 作为变量引入到 playbook 的执行环境中,使得你可以直接通过ansible_<fact_name>方式访问它们。 - 简便性:这种简化的引用方式是为了便于书写和阅读 playbook,减少了每次都需要从
ansible_facts字典中提取值的复杂性。
用 ansible_processor_vcpus 而不是 ansible_facts['processor_vcpus'] 是完全有效的,并且在很多 Ansible 文档和社区中都是推荐的简便做法。但需要注意的是,在一些特定的情况下或在使用自定义 facts 时,可能需要显式地从 ansible_facts 字典中引用相关信息。
{{ ansible_facts[‘os_family’] }}"
在这个例子中,`ansible_facts['os_family']` 用于获取远程系统的操作系统类型,可能的值如 "RedHat", "Debian", "Windows" 等。
**控制 Facts 的收集**
虽然默认情况下 `setup` 模块会自动执行,但你可以控制这一行为:
- **禁用 facts 收集**:在你的 playbook 中设置 `gather_facts: no` 可以阻止自动收集 facts,这在你不需要任何系统信息或者要优化执行速度时非常有用。
```yaml
- name: Run tasks without gathering facts
hosts: all
gather_facts: no
tasks:
- name: Just say hello
debug:
msg: "Hello, world!"
- 手动执行 setup 模块:如果你在某些情况下禁用了自动收集,但在流程中的某个点需要 facts,你可以手动调用
setup模块。
- name: Manually gather facts
hosts: all
gather_facts: no
tasks:
- name: Manually gather facts from the system
setup:
- name: Use a fact from the setup module
debug:
msg: "The OS is {{ ansible_facts['os_family'] }}"
- 使用
ansible_facts: 当你在 playbook 中使用setup模块收集 facts 后,所有的 facts 都会存储在ansible_facts字典中。这意味着要访问任何特定的 fact,比如默认的 IPv4 地址,你需要从这个字典中获取它,比如使用ansible_facts['default_ipv4']['address']。 - 直接使用属性名: 在某些 Ansible 的输出或特定的模块文档中,你可能会看到没有
ansible_facts前缀的属性名。这通常是因为在那些上下文中,文档或输出直接引用了字典中的内容,而不需要通过ansible_facts字典去访问它。
为什么有时候看起来不一样
- 命令行使用:当你在命令行中直接使用
ansible命令查询 facts(比如ansible localhost -m setup),输出的是整个ansible_facts字典的内容,此时看到的属性不带ansible_facts前缀。 - 在 playbook 中:在 playbook 中,为了确保 clarity 和避免命名冲突,最好通过
ansible_facts字典访问所有 facts。
案例:
- name: Set number of worker processes in Nginx config
lineinfile:
path: "{{ item.path }}"
regexp: "{{ item.regexp }}"
line: "{{ item.line }}"
with_items:
- { path: "{{ install_dir }}/conf/nginx.conf", regexp: '^worker_processes', line: "worker_processes {{ ansible_processor_vcpus }};" }
这个任务将会检查位于 {{ install_dir }}/conf/nginx.conf 的 Nginx 配置文件,并确保 worker_processes 行的内容为 worker_processes <CPU核心数>;,其中 <CPU核心数> 是通过 ansible_processor_vcpus 这个变量提供的,它直接从系统 facts 中获取处理器的核心数。
为什么可以省略 ansible_facts 前缀
- 自动变量引入:当使用
setup模块收集 facts 后(无论是自动的还是手动的),Ansible 将这些 facts 作为变量引入到 playbook 的执行环境中,使得你可以直接通过ansible_<fact_name>方式访问它们。 - 简便性:这种简化的引用方式是为了便于书写和阅读 playbook,减少了每次都需要从
ansible_facts字典中提取值的复杂性。
用 ansible_processor_vcpus 而不是 ansible_facts['processor_vcpus'] 是完全有效的,并且在很多 Ansible 文档和社区中都是推荐的简便做法。但需要注意的是,在一些特定的情况下或在使用自定义 facts 时,可能需要显式地从 ansible_facts 字典中引用相关信息。